|
|
@ -0,0 +1,384 @@
|
|||
# 新手建议
|
||||
|
||||
## 学习Linux的注意事项
|
||||
|
||||
* Linux严格区分大小写(命令全都是小写)—— 命令、文件名、选项等均区分大小写
|
||||
|
||||
* Linux中**所有内容**以文件形式保存,包括硬件
|
||||
|
||||
* 硬盘文件是/dev/sd[a-p]
|
||||
* 光盘文件是/dev/sr0等
|
||||
|
||||
* Windows通过扩展名区分文件类型,还有图标可以区分;Linux不靠扩展名区分文件类型,靠文件权限区分,但也有一些约定俗成的扩展名:
|
||||
|
||||
* 压缩包:"*.gz", "*.bz2", "*.tar.bz2", "*.tgz"等
|
||||
* 二进制软件包:".rpm"
|
||||
* 网页文件:"*.sh"
|
||||
* 配置文件:"*.conf"
|
||||
|
||||
注意:这些扩展名不是必要的,即时不加扩展名也没有影响,只是便于管理而已
|
||||
|
||||
* Linux所有存储设备都必须挂在之后用户才能使用,包括硬盘、U盘、光盘(将设备与挂载点连接的过程就是挂载)
|
||||
|
||||
* Windows下的程序不能直接在Linux中安装和运行
|
||||
|
||||
## 服务器管理和维护建议
|
||||
|
||||
### 服务器管理
|
||||
|
||||
| 目录名 | 目录作用 |
|
||||
| :----------: | :----------------------------------------------------------: |
|
||||
| /bin/ | 存放系统命令的目录,普通用户和超级用户都可以执行,不过放在/bin下的命令在单用户模式下也可以执行 |
|
||||
| /sbin/ | 保存和系统环境设置相关的命令,只有超级用户可以使用这些命令进行系统环境设置,但是有些命令可以允许普通用户查看 |
|
||||
| /usr/bin/ | 存放系统命令的目录,普通用户和超级用户都可以执行,这些命令和系统启动无关,在单用户模式下不能执行 |
|
||||
| /usr/sbin/ | 存放根文件系统不必要的系统管理命令,例如多数服务程序。只有超级用户可以使用 |
|
||||
| /boot/ | 系统启动目录,保存系统启动相关的文件,如内核文件和启动引导程序(grub)文件等 |
|
||||
| /dev/ | 设备文件保存位置,我们已经说过Linux中所有内容以文件形式保存,包括硬件,这个目录就是用来 保存所有硬件设备的 |
|
||||
| /etc/ | 配置文件保存位置,系统内所有采用默认安装方式(npm安装)的服务的配置文件全部保存在这个目录中,如用户账户和密码,服务的启动脚本,常用服务的配置文件等 |
|
||||
| /home/ | 每个用户的默认登陆位置,普通用户的home目录就是在/home下建立一个和用户名相同的目录 |
|
||||
| /lib/ | 系统调用的函数库保存位置 |
|
||||
| /lost+found/ | 当系统意外崩溃或机器意外关机时,产生的一些文件碎片放在这里,当系统启动的过程中fsck工具会对其进行检查,并修复已经损坏的文件系统。这个目录只在每个分区中出现,例如/lost+found就是根分区的备份恢复目录,/boot/lost+found就是/boot分区的备份恢复目录 |
|
||||
| /media/ | 挂载目录,系统建议是用来挂载媒体设备的,例如软盘和光盘 |
|
||||
| /mnt/ | 挂载目录,建议挂载额外设备,如U盘,移动硬盘和其他操作系统的分区 |
|
||||
| /misc/ | 挂载目录,系统建议用来挂载NFS服务的共享目录 |
|
||||
| /opt/ | 第三方安装的软件保存位置,但现在更多的是保存在/usr/local中 |
|
||||
| /proc/ | 虚拟文件系统,该目录的数据不保存到硬盘中,而是保存到内存中。主要保存系统的内核、进程、外部设备状态和网络状态灯,如/proc/cpuinfo是保存CPU信息的,/proc/devices是保存设备驱动的列表的,/proc/filesystems是保存 文件系统列表的,/proc/net/是保存网络协议信息的 |
|
||||
| /sys/ | 虚拟文件系统,主要保存内核相关信息 |
|
||||
| /root/ | 超级用户的家目录 |
|
||||
| /srv/ | 服务数据目录, 一些系统服务启动后可以在这个目录保存需要的数据 |
|
||||
| /tmp/ | 临时目录,系统存放临时文件的目录,该目录下所有用户都可以访问和写入,我们建议此目录不能保存重要数据,最好每次开机都把该目录清空 |
|
||||
| /usr/ | 系统软件资源目录,注意usr不是user的缩写,而是"Unix Software Resource"的缩写,所以不是存放用户数据,而是存放系统软件资源的目录。系统中安装的软件大多数都在这里 |
|
||||
| /var/ | 动态数据保存位置,主要保存缓存、日志以及软件运行所产生的文件 |
|
||||
|
||||
### 服务器注意事项
|
||||
|
||||
1. 远程服务器不允许关机,只能重启
|
||||
2. 重启时应该关闭服务
|
||||
3. 不要在服务器的访问高峰运行高负载命令
|
||||
4. 远程配置防火墙时不要把自己踢出服务器(可以设置每五分钟将防火墙规则重置一次,配置完之后再取消该设置)
|
||||
5. 指定合理的密码规范并定期更新
|
||||
6. 合理分配权限
|
||||
7. 定期备份重要数据和日志
|
||||
|
||||
磁盘分区是用分区编辑器在磁盘上划分几个逻辑部分,碟片一旦划分成数个分区,不同类的目录和文件 可以存储进不同的分区。
|
||||
|
||||
# 系统分区
|
||||
|
||||
## 分区类型
|
||||
|
||||
* 主分区:最多只能有4个
|
||||
* 扩展分区:
|
||||
* 最多只能有1个
|
||||
* 主分区加扩展分区最多有4个
|
||||
* 不能写入数据,只能包含逻辑分区(这种限制是硬盘的限制)
|
||||
* 逻辑分区
|
||||
|
||||
## 格式化
|
||||
|
||||
硬盘经过正确分区后仍不能写入数据,我们的硬盘还必须经过格式化之后才能写入数据。格式化又称逻辑格式化,它是根据用户选定的文件系统(如FAT16、FAT32、NTFS、EXT 2、EXT3、EXT4等),在磁盘的特定区域写入特定数据,在分区中划分出一片用于存放文件分配表、目录表等用于文件管理的磁盘空间。格式化就是按照文件系统的规则将硬盘分成等大小的数据块,我们把数据块称为block。
|
||||
|
||||
> 注:Windows可以识别的系统有FAT16、FAT32、NTFS;Linux可以识别的系统有EXT2、EXT3、EXT4
|
||||
|
||||
## 设备文件名
|
||||
|
||||
#### 硬盘设备文件名
|
||||
|
||||
Windows是直接分区——>格式化——>分配盘符即可使用,Linux需要分区——>格式化——>给分区建立设备文件名——>分配盘符才能使用。
|
||||
|
||||
| 硬件 | 设备文件名 |
|
||||
| ----------------- | ------------------- |
|
||||
| IDE硬盘 | /dev/hd[a-d] |
|
||||
| SCSI/SATA/USB硬盘 | /dev/sd[a-p] |
|
||||
| 光驱 | /dev/cdrom或dev/sr0 |
|
||||
| 软盘 | /dev/fd[0-1] |
|
||||
| 打印机(25针) | /dev/lp[0-2] |
|
||||
| 打印机(USB) | /dev/usb/lp[0-15] |
|
||||
| 鼠标 | /dev/mouse |
|
||||
|
||||
#### 分区设备文件名
|
||||
|
||||
分区设备文件名直接**在硬盘设备文件名后面加分区号**即可,如
|
||||
|
||||
* IDE硬盘接口第一个分区:/dev/hda1(如今几乎看不到)
|
||||
* SCSI硬盘接口、SATA硬盘接口的第一个分区:/dev/sda1
|
||||
|
||||
> IDE硬盘是最古老的硬盘,理论最高传输速度是133M/s
|
||||
>
|
||||
> SCSI硬盘接口与IDE硬盘同时代,更加昂贵但速度更快,理论最高传输速度可达200M/s,但这种硬盘主要用在服务器上
|
||||
>
|
||||
> 但上两种硬盘接口如今已经基本淘汰,如今使用更多的是小口的SATA串口硬盘,SATA已发展到3代,其理论传输速度最高可达500M/s,目前不管是服务器还是个人机基本使用的都是SATA硬盘接口。
|
||||
|
||||
需要留意的是,逻辑分区永远都是从5开始的
|
||||
|
||||
## 挂载
|
||||
|
||||
挂载实际上就是Windows中分配盘符的过程,盘符则被相应地称为挂载点,必须分区的分区有以下两种:
|
||||
|
||||
1. 根分区:/
|
||||
2. swap分区(交换分区):可以理解为虚拟内存,当真正内存不够用时,可以使用这部分交换分区的硬盘空间来当内存,理论上来说交换分区应该是内存的两倍,但最大不超过2GB
|
||||
|
||||
若无这两个分区,Linux不能正常使用,但我们还推荐把/boot单独分区,这是为了防止Linux系统启动不起来,一般200MB即可。
|
||||
|
||||
# 远程登陆管理工具
|
||||
|
||||
## 网络连接
|
||||
|
||||
网络连接从虚拟机设置中可以看到,一共有三种:桥接、NAT和Host-only,下面讲解其区别:
|
||||
|
||||
* 桥接:桥接意味着虚拟机如同一个单独的主机一样访问Wifi等,也可以和其他机器通信
|
||||
* NAT:虚拟机仅能和主机通信,但若主机可以访问互联网,虚拟机也可以访问互联网
|
||||
* Host-only:虚拟机仅能和主机本机通信,不能访问互联网
|
||||
|
||||
## 网络配置
|
||||
|
||||
1. 首先调成Host-only模式,使得虚拟机仅与主机连接
|
||||
2. 在主机上找到VMware Network Adapter VMnet1的IP地址,我本地地址为192.168.19.1
|
||||
3. 在虚拟机上使用`ishw -c netwowrk`命令找到logical name,此即为虚拟机的网卡名称,我的虚拟网卡名称为ens33
|
||||
4. 使用命令ifconfig [不等于IP地址] logical name,例如我使用的是`ifconfig ens33 192.168.19.2`
|
||||
5. 此时再ifconfig即可看到我们设置的已生效
|
||||
6. 我们可以在主机ping这个IP地址看到生效
|
||||
7. 使用secureCRT连接即可
|
||||
|
||||
需要注意的是,以上方法配置IP地址时不是永久生效的,也就是重新启动电脑时就失效了,若想永久生效需要改变配置文件
|
||||
|
||||
若使用NAT模式,则步骤简单很多,只需要ifconfig获得IP地址之后直接用secureCRT连接即可
|
||||
|
||||
## WinSCP
|
||||
|
||||
另外推荐一个Windows主机与Linux虚拟机进行文件传输的工具——WinSCP,操作方法与上面类似,只需输入对应的IP地址即可连接。
|
||||
|
||||
|
||||
|
||||
## 安装linux系统(以ubuntu为例)
|
||||
|
||||
- 使用vmware虚拟机安装
|
||||
|
||||
[参考此博客:VMware安装Ubuntu18.04](https://zhuanlan.zhihu.com/p/38797088)
|
||||
|
||||
- 使用win10子系统安装
|
||||
|
||||
[参考此博客:在 win10 下使用 ubuntu 子系统](https://zhuanlan.zhihu.com/p/76032647)
|
||||
|
||||
# Linux常用命令
|
||||
|
||||
## 一、最常用命令
|
||||
|
||||
这是我们**使用得最多**的命令了,**Linux最基础的命令**!
|
||||
|
||||
- 可用 `pwd`命令查看用户的当前目录
|
||||
- 可用 `cd` 命令来切换目录
|
||||
- `.`表示当前目录
|
||||
- `..` 表示当前目录的上一级目录(父目录)
|
||||
- `-`表示用 cd 命令切换目录**前**所在的目录
|
||||
- `~` 表示**用户主目录**的绝对路径名
|
||||
|
||||
**绝对路径:**
|
||||
|
||||
- 以斜线(/)开头 ,描述到文件位置的**完整说明** ,任何时候你想指定文件名的时候都可以使用
|
||||
|
||||
**相对路径 :**
|
||||
|
||||
- 不以斜线(/)开头 ,指定**相对于你的当前工作目录而言的位置** ,可以被用作指定文件名的简捷方式
|
||||
|
||||
## 二、文件处理命令
|
||||
|
||||
### 1. 命令格式与目录处理命令`ls`
|
||||
|
||||
**命令格式**:`命令[-选项][-参数]`,例:`ls -la /etc`
|
||||
|
||||
**说明**:
|
||||
|
||||
1. 个别命令使用不遵循此格式
|
||||
2. 当有多个选项时,可以写在一起
|
||||
3. 简化选项与完整选项:`-a` 等于 `--all`
|
||||
|
||||
`ls`命令的语法:
|
||||
|
||||
1. `ls -a`可以显示所有文件,包括隐藏文件(以点.开头的文件是隐藏文件)
|
||||
|
||||
2. 若希望查询的不是当前目录,可以使用`ls+其他目录`进行查询
|
||||
|
||||
3. `ls -l`可以显示更多属性(long),属性阐述如下:
|
||||
1. 第一列分为三个部分,第一部分(如d告诉我们文件的类型是一个目录,-为二进制文件,1为软链接文件),drwx表示该文件支持读写和执行操作,r,w,x分别对应读、写、执行三个权限,三列分别对应所有者,所属组,其他人的权限
|
||||
|
||||
2. 第二列的2、2、3等表示调用次数
|
||||
3. 第三列表示所有者,也就是这个文件的总负责人(拥有文件的所有权,可转让)
|
||||
4. 第四列表示所属组,也就是可以操作这个文件的人
|
||||
5. 第五列表示文件大小,默认单位是字节(很反Windows)
|
||||
6. 最后一个是文件的最后一次修改时间(Linux没有创建时间这个概念)
|
||||
|
||||
4. `ls -lh`比原先的更人性化(humanitarian),它将对应的单位也显示了出来,`-h`实际上是一个通用选项,很多命令都可以加
|
||||
|
||||
5. `-d`显示当前目录本身而不显示目录下的数据,一般与`-l`结合使用,如`ls -ld /etc`
|
||||
|
||||
6. `ls -id`可以查看当前目录对应的文件ID
|
||||
|
||||
### 2. 目录处理命令
|
||||
|
||||
##### `mkdir`
|
||||
|
||||
**语法**:`mkdir -p [目录名]`
|
||||
|
||||
**功能描述**:创建新目录,`-p`递归创建(若一个目录本身不存在,可以在创建这个目录的同时创建子目录),也可以同时创建多个目录
|
||||
|
||||
##### `cd`
|
||||
|
||||
**语法**:`cd directory`
|
||||
|
||||
**功能描述**:改变当前目录
|
||||
|
||||
##### `pwd`
|
||||
|
||||
**语法**:`pwd`
|
||||
|
||||
**功能描述**:显示当前目录(print working directory)
|
||||
|
||||
##### `rmdir`
|
||||
|
||||
**语法**:`rmdir [目录名]`
|
||||
|
||||
**功能描述**:删除空目录(若目录非空则不能删除)
|
||||
|
||||
##### `cp`
|
||||
|
||||
**语法**:`cp -rf [源文件或目录] [目标目录] -r 复制目录 -p 保留文件属性(文件创建时间等不发生变化)`
|
||||
|
||||
**功能描述**:复制文件或目录
|
||||
|
||||
##### `mv`
|
||||
|
||||
**语法**:`mv [源文件或目录] [目标目录]`
|
||||
|
||||
**功能描述**:剪切文件、改名
|
||||
|
||||
##### `rm`
|
||||
|
||||
**语法**:`rm -rf [文件或目录] -r 删除目录 -f 强制执行`
|
||||
|
||||
**功能描述**:删除文件
|
||||
|
||||
### 3. 文件处理命令
|
||||
|
||||
##### `touch`
|
||||
|
||||
**语法**:`touch [文件名]`
|
||||
|
||||
**功能描述**:创建空文件
|
||||
|
||||
##### `cat`
|
||||
|
||||
**语法**:`cat [文件名]`
|
||||
|
||||
**功能描述**:显示文件内容 `-n`可显示行号
|
||||
|
||||
##### `tac`
|
||||
|
||||
与`cat`相反,可以倒着显示
|
||||
|
||||
##### `more`
|
||||
|
||||
`cat`命令显示的往往过多,若希望分页显示可以使用`more`,用法与`cat`相同,使用时按空格可以一页页往后翻,使用q或Q退出
|
||||
|
||||
##### `less`
|
||||
|
||||
由于`more`无法向上翻,我们可以使用`less`命令,可以使用page up一页页往上翻,也可以使用上箭头一行行往上翻,其他操作与`more`相同。另外`less`还可以进行搜索,比如想要搜索关键词service,可以输入/service进行检索,页面会对这些关键词进行高亮,可以使用`n`找到其他关键词位置
|
||||
|
||||
##### `head`
|
||||
|
||||
若只想要看文件的前几行,可以使用`head -n`加指定行数,若不加则默认显示前10行
|
||||
|
||||
##### `tail`
|
||||
|
||||
与`head`类似 ,但是显示后面几行。
|
||||
|
||||
常用搭配为:`tail -f`,该命令会动态显示文件末尾内容
|
||||
|
||||
## 三、链接命令`ln`
|
||||
|
||||
**语法**:`ln -s [原文件] [目标文件] -s 创建软链接`
|
||||
|
||||
**功能描述**:生成链接文件
|
||||
|
||||
**示例**:
|
||||
|
||||
* `ln -s /etc/issue issue.soft`:生成软链接
|
||||
* `ln /etc/issue issue.hard`:生成硬链接
|
||||
|
||||
**软链接和硬链接的区别**
|
||||
|
||||
我们使用`ls -l`查看这两个文件的信息:
|
||||
|
||||
```
|
||||
-rw-r--r-- 2 root root 26 Jul 15 2020 issue.hard
|
||||
lrwxrwxrwx 1 root root 10 Jan 31 04:55 issue.soft -> /etc/issue
|
||||
```
|
||||
|
||||
我们会发现这两个文件的信息相差的非常多,软链接文件开头的文件类型是`l(link)`,三个权限都是`rwx`,即可读可写可执行,软链接文件就类似于Windows的快捷方式,用处是便于做管理,我们可以看到最后有一个箭头指向`/etc/issue`。另外我们看到这个文件只有31个字节,因为它只是一个符号链接。我们可以总结得出软链接的三个特点:
|
||||
|
||||
1. 权限是`rwx`
|
||||
2. 文件很小,只是符号链接
|
||||
3. 箭头指向源文件
|
||||
|
||||
下面我们看硬链接的特点,我们首先分别查看 这两个文件的信息:
|
||||
|
||||
```
|
||||
ls -l issue.hard
|
||||
ls -l /etc/issue
|
||||
```
|
||||
|
||||
我们可以看到这两个文件的所有信息一模一样,包括文件的大小,这类似于拷贝,似乎相当于`cp -p`,而硬链接和`cp -p`的最大不同就是硬链接可以实现同步更新,我们可以做一个简单的实验,我们先查看硬链接文件,然后往源文件中写入文件,可以发现硬链接文件也被同时修改了,当然软链接也会同步修改。
|
||||
|
||||
但当我们将源文件复制到另一个位置并删除原位置文件之后,再试图打开软链接会提示“没有那个文件或目录”,而且再显示这个目录软链接会标红并一直闪,而硬链接可以正常访问,没有影响,这就是硬链接和软连接的不同之处。
|
||||
|
||||
实际上我们可以通过命令`ls -i`来识别其`i`节点以辨别出是硬链接还是软链接,硬链接和源文件的`i`节点相同,软链接则不同。
|
||||
|
||||
硬链接相当于一个同步文件,但可以做实时备份(一个文件删了不会影响另一个文件),硬链接有两个限制,这也是硬链接和软链接的区别:
|
||||
|
||||
1. 不能跨分区
|
||||
2. 不能针对目录使用
|
||||
|
||||
## 四、权限管理命令
|
||||
|
||||
Linux用户一共分成三类,分别是所有者(U),所属组(G)和其他人(O),权限也分成三类,分别是`r`,`w`,`x`,对应读、写、执行,我们首先学习如何更改权限。
|
||||
|
||||
#### `chmod`
|
||||
|
||||
更改文件的人只能是文件所有者或者管理员root用户,更改文件权限有两种方式,第一种方式如下:
|
||||
|
||||
```
|
||||
chmod [{ugoa}{+-=}{rwx}][文件或目录]
|
||||
```
|
||||
|
||||
其中第一个花括号里`u`,`g`,`o`,`a`分别表示所有者,所属组,其他人和所有人,第二个花括号`+`和`-`分别表示增加和减少权限,`=`表示成为后面的权限。第二种方式如下:
|
||||
|
||||
```
|
||||
chmod [mod=421][文件或目录] -R 递归修改
|
||||
```
|
||||
|
||||
数字的意思只是将三个权限位分别用数字来表示,比如`r`用4表示,`w`用2表示,`x`用1表示,则若要表示`rwxrw-r--`则记为`764`
|
||||
|
||||
#### `chown`
|
||||
|
||||
命令英文原意是`change file ownership`,作用是改变文件或目录的所有者,改变文件file的所有者为user的具体用法为:
|
||||
|
||||
```
|
||||
chown user file
|
||||
```
|
||||
|
||||
要注意只有root和文件的所有者可以改变文件的权限
|
||||
|
||||
#### `chgrp`
|
||||
|
||||
命令英文原意是`change file group ownership`,作用是改变文件或目录的所属组,若具体用法和前面`chown`相同。我们可以使用`groupadd`命令添加组(使用`useradd`命令添加用户)
|
||||
|
||||
#### `umask`
|
||||
|
||||
命令英文原意是`the user file-creation mask`,作用是显示、设置文件的缺省权限,语法是:
|
||||
|
||||
```shell
|
||||
umask [-S]
|
||||
```
|
||||
|
||||
其中`-S`的作用是显示新建文件的缺省权限,但需要注意的是缺省创建文件时不可以有可执行权限的,所以当`touch`创建文件时会发现所有权限都少了`x`。
|
||||
|
||||
当我们直接使用`umask`时,比如显示0022,第一个0是特殊权限,我们暂时不涉及,第二只第四位分别是所有者、所属组和其他人,我们的最终权限实际上是`777-022=755`,也就是`rwx r-x r-x`,当然这指的是目录,如果是文件由于没有可执行权限,文件权限应当是`rw- r-- r--`,当然缺省创建的权限可以更改,直接使用`umask 077`即可将文件缺省权限更改为`rwx --- ---`,但不推荐做这种更改
|
||||
|
|
@ -0,0 +1,537 @@
|
|||
<font color='red'> 注:本教程为技术教程,不谈论且不涉及炒作任何数字货币 </font>
|
||||
|
||||
本次组队学习重点在于以太坊基础知识、以太坊客户端以及以太坊solidity编程,因此本节教程重点在于以太坊核心知识点的掌握,区块链部分的基础知识可以作为补充,请学习者量力而行。另外若学习者觉得本节内容难度太高,可以先对基本知识点有一个概览,在第二节以及第三节实战内容学习完成之后再深入学习本节内容。
|
||||
|
||||
# 一、区块链简介 #
|
||||
|
||||
## 1.1、区块链与区块链技术 ##
|
||||
|
||||
在阅读本教程之前,[大家对比特币原理不太了解同学可以先阅读下此博客~](http://blog.codinglabs.org/articles/bitcoin-mechanism-make-easy.html),大家对比特币有简单了解后对于区块链会有更好的认识。
|
||||
|
||||
**区块链**是将记录(区块)通过密码学串联并加密的链式数据结构。而**区块链技术**,是通过P2P网络和区块链来实现数据存储的**去中心化**、**不可逆**和**不可篡改**。比特币正是构建在区块链技术上的典型应用。通过区块链技术,我们可以将信息(数据、程序)保存在区块上并接入到区块链中,这样就实现了信息的去中心化存储、不可逆和不可篡改。**区块链应用**是指利用区块链技术开发的应用。
|
||||
|
||||
## 1.2、区块链历史 ##
|
||||
|
||||
2008年,一个网名叫中本聪(Satoshi Nakamoto)的人发表了一篇名为《比特币:一种点对点电子货币系统》的论文,论文中首次提到了“区块链”这一概念。2009年,中本聪创立了以区块链为底层技术的比特币网络,开发出了第一个区块,被称为“创世区块”。该阶段被称为“区块链1.0”。
|
||||
|
||||
由于比特币是一个电子货币系统,所以主要功能就是记账。但随后人们发现,区块链技术作为比特币的底层技术,功能可以远远不止于记账,许多关于“未知的信任”的问题,都可以通过区块链来解决,例如电子存证、信息记录等。于是在比特币的基础上,诞生了带有智能合约的区块链系统,即允许开发者通过编写智能合约来实现特定的逻辑,这一阶段被称为“区块链2.0”。这一阶段的主要代表是以太坊。
|
||||
|
||||
随后,人们想要提升区块链应用的性能,于是出现了EOS、ArcBlock等系统,其特点是高性能、大吞吐量,但由于引入了超级节点、云节点等特性,弱化了“去中心化”这一特点,因此受到较大的争议。这一阶段被称为“区块链3.0”。
|
||||
|
||||
由于比特币是一款电子货币,可扩展性较低,而所谓的“区块链3.0”目前受到较大争议,且部分项目的底层算法完全不同于典型的区块链,因此学习区块链2.0中的以太坊是目前学习区块链的最佳方式。
|
||||
|
||||
## 1.3、区块链基础技术与算法 ##
|
||||
|
||||
区块链技术不是单独的一项技术,而是一系列技术组成的技术栈,其具有以下的特点:
|
||||
|
||||
* 数据分布式存储
|
||||
* 存储的数据不可逆、不可篡改、可回溯
|
||||
* 数据的创建和维护由所有参与方共同参与
|
||||
|
||||
为了实现这些特点、维护区块链应用的稳定运行,区块链技术中包含了分布式存储技术、密码学技术、共识机制以及区块链2.0提出的智能合约。
|
||||
|
||||
|
||||
|
||||
### 1.3.1、区块
|
||||
|
||||
区块链由一个个区块(block)组成。区块很像数据库的记录,每次写入数据,就是创建一个区块。
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\bg2017122703.png" width="300"/>
|
||||
</center>
|
||||
<center>中心化存储</center>
|
||||
每个区块包含两个部分。
|
||||
|
||||
> - 区块头(Head):记录当前区块的特征值
|
||||
> - 区块体(Body):实际数据
|
||||
|
||||
区块头包含了当前区块的多项特征值。
|
||||
|
||||
> - 生成时间
|
||||
> - 实际数据(即区块体)的哈希
|
||||
> - 上一个区块的哈希
|
||||
> - ...
|
||||
|
||||
### 1.3.2、分布式存储技术 ###
|
||||
|
||||
与传统的数据存储技术不同,在区块链技术中,数据并不是集中存放在某个数据中心上,也不是由某个权威机构或是大多数节点来存储,而是分散存储在区块链网络中的每一个节点上。
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image2.png" width="300"/>
|
||||
</center>
|
||||
<center>中心化存储</center>
|
||||
<center class="half">
|
||||
<img src=".\pic\image3.png" width="300"/>
|
||||
</center>
|
||||
<center>分布式存储</center>
|
||||
**节点和区块的关系是什么?**
|
||||
|
||||
可以用共享文档来简单描述:所有可以访问共享文档的账号就叫做节点,当然全节点需要同步共享文档,也就是拥有全部的区块数据区块就是共享文档。每个人更新了,所有人都可以查看最新的文档
|
||||
|
||||
### 1.3.3、密码学技术 ###
|
||||
|
||||
为了实现数据的不可逆、不可篡改和可回溯,区块链技术采用了一系列密码学算法和技术,包括哈希算法、Merkle 树、非对称加密算法。
|
||||
|
||||
##### 哈希算法 #####
|
||||
|
||||
哈希算法是一个单向函数,可以将任意长度的输入数据转化为固定长度的输出数据(哈希值),哈希值就是这段输入数据唯一的数值表现。由于在计算上不可能找到哈希值相同而输入值不同的字符串,因此两段数据的哈希值相同,就可以认为这两段数据也是相同的,所以哈希算法常被用于对数据进行验证。
|
||||
|
||||
在区块链中,数据存储在区块里。每个区块都有一个区块头,区块头中存储了一个将该区块所有数据经过哈希算法得到的哈希值,同时,每个区块中还存储了前一个区块的哈希值,这样就形成了区块链。如果想要篡改某一个区块A中的数据,就会导致A的哈希值发生变化,后一个区块B就无法通过哈希值正确地指向A,这样篡改者又必须篡改B中的数据......也就是说,篡改者需要篡改被篡改的区块以及后面的所有区块,才能让所有的节点都接受篡改。
|
||||
|
||||
##### Merkle树 #####
|
||||
|
||||
Merkle树是一种树形结构,在区块链中,Merkle树的叶子节点是区块中数据的哈希值,非叶子节点是其子结点组合后的哈希值,这样由叶子节点开始逐层往上计算,最终形成一个Merkle根,记录在区块的头部,这样就可以保证每一笔交易都无法篡改。
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image4.png" width="500"/>
|
||||
</center>
|
||||
<center>Merkle 树</center>
|
||||
##### 非对称加密技术 #####
|
||||
|
||||
非对称加密技术使用两个非对称密钥:公钥和私钥。公钥和私钥具有两个特点:
|
||||
|
||||
1. 通过其中一个密钥加密信息后,使用另一个密钥才能解开
|
||||
2. 公钥一般可以公开,私钥则保密
|
||||
|
||||
在区块链中,非对称加密技术主要用于信息加密、数字签名和登录认证。在信息加密场景中,信息发送者A使用接收者B提供的公钥对信息进行加密,B收到加密的信息后再通过自己的私钥进行解密。再数字签名场景中,发送者A通过自己的私钥对信息进行加密,其他人通过A提供的公钥来对信息进行验证,证明信息确实是由A发出。在登录认证场景中,客户端使用私钥加密登录信息后进行发送,其他人通过客户端公钥来认证登录信息。
|
||||
|
||||
- RSA 算法
|
||||
|
||||
RSA加密算法是最常用的非对称加密算法,CFCA在证书服务中离不了它。但是有不少新来的同事对它不太了解,恰好看到一本书中作者用实例对它进行了简化而生动的描述,使得高深的数学理论能够被容易地理解。
|
||||
RSA是第一个比较完善的公开密钥算法,它既能用于加密,也能用于数字签名。RSA以它的三个发明者Ron Rivest, Adi Shamir, Leonard Adleman的名字首字母命名,这个算法经受住了多年深入的密码分析,虽然密码分析者既不能证明也不能否定RSA的安全性,但这恰恰说明该算法有一定的可信性,目前它已经成为最流行的公开密钥算法。
|
||||
RSA的安全基于大数分解的难度。其公钥和私钥是一对大素数(100到200位十进制数或更大)的函数。从一个公钥和密文恢复出明文的难度,等价于分解两个大素数之积(这是公认的数学难题)。
|
||||
|
||||
- ECC 椭圆曲线算法
|
||||
|
||||
具体可以参见此文章:[ECC椭圆曲线加密算法:介绍](https://zhuanlan.zhihu.com/p/36326221)
|
||||
|
||||
|
||||
|
||||
### 1.3.4、共识机制 ###
|
||||
|
||||
区块链系统是一个分布式系统,分布式系统要解决都首要问题就是一致性问题,也就是如何使多个孤立的节点达成共识。在中心化系统中,由于有一个中心服务器这样的“领导”来统一各个节点,因此达成一致性几乎没有问题。但在去中心化场景下,由于各个节点是相互独立的,就可能会出现许多不一致的问题,例如由于网络状况等因素部分节点可能会有延迟、故障甚至宕机,造成节点之间通信的不可靠,因此一致性问题是分布式系统中一个很令人头疼的问题。
|
||||
|
||||
由 Eirc Brewer 提出,Lynch 等人证明的 CAP 定理为解决分布式系统中的一致性问题提供了思路。CAP 定理的描述如下:在分布式系统中,**一致性**、**可用性**和**分区容错性**三者不可兼得。这三个术语的解释如下:
|
||||
|
||||
* 一致性(**C**onsistency):所有节点在同一时刻拥有同样的值(等同于所有节点访问同一份最新的数据副本
|
||||
* 可用性(**A**vailability):每个请求都可以在有限时间内收到确定其是否成功的响应
|
||||
* 分区容错性(**P**artition tolerance):分区是指部分节点因为网络原因无法与其他节点达成一致。分区容错性是指由网络原因导致的系统分区不影响系统的正常运行。例如,由于网络原因系统被分为 A, B, C, D 四个区,A, B 中的节点无法正常工作,但 C, D 组成的分区仍能提供正常服务。
|
||||
|
||||
在某些场景下,对一致性、可用性和分区容错性中的某一个特性要求不高时,就可以考虑弱化该特性,来保证整个系统的容错能力。区块链中常见的共识机制的基本思路正是来自 CAP 定理,部分区块链应用中用到的共识机制如下表:
|
||||
|
||||
| 共识机制 | 应用 |
|
||||
| -------- | ---------------------------------- |
|
||||
| PoW | 比特币、莱特币、以太坊的前三个阶段 |
|
||||
| PoS | PeerCoin、NXT、以太坊的第四个阶段 |
|
||||
| PBFT | Hyperledger Fabric |
|
||||
|
||||
##### PoW(Proof of Work,工作量证明) #####
|
||||
|
||||
PoW 机制的大致流程如下:
|
||||
|
||||
1. 向所有节点广播新交易和一个数学问题
|
||||
2. 最先解决了数学问题的节点将交易打包成区块,对全网广播
|
||||
3. 其他节点验证广播区块的节点是否解决了数学问题(完成了一定的工作量),验证通过则接受该区块,并将该区块的哈希值放入下一个区块中,表示承认该区块
|
||||
|
||||
由于在 PoW 机制中,区块的产生需要解决一个数学问题,也就是所谓的**挖矿**,这往往要消耗较大的算力和电力,因此节点们倾向于在**最长的链**的基础上添加区块,因为如果节点想在自己的链上添加新的区块,那么就需要重新计算 1 个或 $n$ 个这样的数学问题(每添加一个区块就需要计算一个)。因此在比特币中最长的链被认为是合法的链,这样节点间就形成了一套“共识”。
|
||||
|
||||
PoW 机制的优点是完全去中心化,缺点是需要依赖数学运算,资源的消耗会比其他的共识机制高,可监管性弱,同时每次达成共识需要全网共同参与运算,性能较低。
|
||||
|
||||
##### PoS(Proof of Stack,股权证明) #####
|
||||
|
||||
PoS 针对 PoW 的缺点做出了改进。PoS 要求参与者预先放置一些货币在区块链上用于换取“股权”,从而成为**验证者(Validator)**,验证者具有产生区块的权利。PoS 机制会按照存放货币的量和时间给验证者分配相应的利息,同时还引入了奖惩机制,打包错误区块的验证者将失去他的股权——即投入的货币以及产生区块的权利。PoS 机制的大致流程如下:
|
||||
|
||||
1. 加入 PoS 机制的都是持币人,称为验证者
|
||||
2. PoS 算法根据验证者持币的多少在验证者中挑选出一个给予产生区块的权利
|
||||
3. 如果一定时间内没有产生区块,PoS 就挑选下一个验证者,给予产生区块的权利
|
||||
4. 如果某个验证者打包了一份欺诈性交易,PoS 将剥夺他的股权
|
||||
|
||||
PoS 的优点在于:
|
||||
|
||||
1. 引入了利息,使得像比特币这样发币总数有限的通货紧缩系统在一定时间后不会“无币可发”
|
||||
2. 引入了奖惩机制使节点的运行更加可控,同时更好地防止攻击
|
||||
3. 与 PoW 相比,不需要为了生成新区块而消耗大量电力和算力
|
||||
4. 与 PoW 相比,缩短了达成共识所需的时间
|
||||
|
||||
由于 PoS 机制需要用户已经持有一定数量的货币,没有提供在区块链应用创立初始阶段处理数字货币的方法,因此使用 PoS 机制的区块链应用会在发布时预先出售货币,或在初期采用 PoW,让矿工获得货币后再转换成 PoS,例如以太坊现阶段采用的是 PoW 机制,在第四阶段“宁静”(Serenity)中将过渡到 PoS。
|
||||
|
||||
##### 拜占庭将军问题(Byzantine Generals Problem) #####
|
||||
|
||||
拜占庭将军问题是分布式网络中的通信容错问题,可以描述为:
|
||||
|
||||
> 一组拜占庭将军各领一支队伍共同围困一座城市。各支军队的行动策略限定为进攻或撤离两种。因为部分军队进攻而部分军队撤离可能会造成灾难性的后果,因此各将军决定通过投标来达成一致策略,即“共进退”。因为各将军位于城市不同方向,他们只能通过信使互相联系。在投票过程中每位将军都将自己的选择(进攻或撤退)通过信使分别通知其他所有将军,这样一来每位将军根据自己的投票和其他所有将军送来的信息就可以知道共同投票的结果,进而做出行动。
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image1.png" width="500"/>
|
||||
</center>
|
||||
|
||||
|
||||
拜占庭将军的问题在于,将军中可能出现叛徒。假设3名将军中有1名叛徒,2名忠诚将军一人投进攻票,一人投撤退票,这时叛徒可能会故意给投进攻的将军投进攻票,而给投撤退的将军投撤退票。这就导致一名将军带队发起进攻,而另外一名将军带队撤退。
|
||||
|
||||
另外,由于将军之间通过信使进行通讯,即使所有将军都忠诚,也不能排除信使被敌人截杀,甚至信使叛变等情况。
|
||||
|
||||
假设存在叛变将军或信使出问题等情况,如果忠诚将军仍然能够通过投票来决定他们的战略,便称系统达到了**拜占庭容错(Byzantine Fault Tolerance)**。
|
||||
|
||||
拜占庭问题对应到区块链中,将军就是节点,信使就是网络等通信系统,要解决的是存在恶意节点、网络错误等情况下系统的一致性问题。
|
||||
|
||||
**PBFT(Practical Byzantine Fault Tolerance)** 是第一个得到广泛应用且比较高效的拜占庭容错算法,能够在节点数量不小于 $n=3f+1$ 的情况下容忍 $f$ 个拜占庭节点(恶意节点)。
|
||||
|
||||
|
||||
|
||||
# 二、以太坊介绍 #
|
||||
|
||||
首先我们要知道我们为什么要学习以太坊,主要有以下四个原因:
|
||||
|
||||
* 以太坊是区块链2.0的代表,学习以太坊能了解到区块链技术的所有知识
|
||||
* 引入了智能合约,拓宽了区块链的应用场景
|
||||
* 对开发者友好、对用户友好,容易编写出简单的区块链应用,学习趣味性高
|
||||
* Solidity 语法与 Javascript、Go 等语言接近,易上手
|
||||
|
||||
## 2.1、以太坊简介 ##
|
||||
|
||||
区块链技术常常被认为是自互联网诞生以来最具颠覆性的技术,然而,自比特币诞生后一直没有很好的区块链应用开发平台。想要在比特币基础上开发区块链应用是非常复杂繁琐的,因为比特币仅仅是一个加密数字货币系统,无法用来实现更广阔的业务需求。以太坊是目前使用最广泛的支持完备应用开发的共有区块链系统。
|
||||
|
||||
和比特币不同,比特币只适合加密数字货币场景,不具备图灵完备性,也缺乏保存实时状态的账户概念,以及存在 PoW 机制带来的效率和资源浪费的问题,而以太坊作为区块链2.0的代表,目标是扩展智能合约和建立一个去中心化应用平台,具有图灵完备的特性、更高效的共识机制、支持智能合约等多种应用场景,使得开发者能够很方便地在以太坊上开发出基于区块链的应用。
|
||||
|
||||
### 2.1.1、以太坊的发展 ###
|
||||
|
||||
2014年, Vitalik Buterin 发表了文章《以太坊:一个下一代智能合约和去中心化应用平台》。同年,Buterin 在迈阿密比特币会议中宣布启动以太坊项目,并提出了多项创新性的区块链技术。2015年,以太坊CCO Stephan Tual 在官方博客上宣布以太坊系统诞生,主网上线。
|
||||
|
||||
以太坊发展至今经历了“前沿”(Frontier)、“家园”(Homestead)以及现在所处的“大都会”(Metropolis)三个阶段。第四阶段“宁静”(Serenity)将作为以太坊的最后一个阶段,目前尚未有计划发布日期。
|
||||
|
||||
### 2.1.2、以太坊的特点 ###
|
||||
|
||||
以太坊团队和外界对以太坊的描述都是“世界计算机”,这代表它是一个开源的、全球的去中心化计算架构。它执行称为智能合约的程序,并使用区块链来同步和存储系统状态,以及使用名为以太币的加密数字货币来计量和约束执行操作的资源成本。同时,以太坊提供了一系列的接口,使得开发者能够通过以太坊来开发去中心化 Web 应用DApps。
|
||||
|
||||
### 2.1.3、智能合约 ###
|
||||
|
||||
相比比特币,以太坊最大的特点就是引入了**智能合约**。智能合约本质上就是一段编写好的程序,可以在特定的条件下被触发并执行特定的操作。由于区块链具有不可逆和不可篡改的特点,因此智能合约与区块链结合后,就成了一份“强制执行”的合约。
|
||||
|
||||
以太坊能够作为一个去中心化应用平台和”世界计算机”,其核心就是智能合约。智能合约的引入,使得开发者能够实现许多(理论上是任何)业务逻辑。如果说比特币是通过区块链技术开发的特定计算器,那么引入了智能合约的以太坊就是基于区块链技术的通用计算机。可以简单的理解成:比特币的交易系统就是一份写死的智能合约,而以太坊则将智能合约的开发权限交给开发者。
|
||||
|
||||
以太坊提供了对智能合约的全面支持,包括编写智能合约编程语言 **Solidity** 和运行智能合约的**以太坊虚拟机(Ethereum Virtual Machine,EVM)**。
|
||||
|
||||
### 2.1.4、幽灵协议 ###
|
||||
|
||||
幽灵合约的英文是“Greedy Heaviest Observed Subtree" (GHOST) protocol,在介绍幽灵协议之前,先介绍以太坊中的叔区块、叔块奖励和叔块引用奖励这三个概念。
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image5.png" width="400"/>
|
||||
</center>
|
||||
|
||||
|
||||
假设目前以太坊区块链中的区块高度(区块链上的区块个数)为6,现在产生了一笔新的交易,矿工A先将该笔交易打包成了区块 Block 7,在矿工A将 Block 7 广播到其他节点的这段时间里,矿工B和矿工C又分别产生了 Block 8 和 Block 9。Block 7、Block 8、Block 9 都指向 Block 6,即 Block 6 是他们的父区块。由于 Block 7 是最先产生的,因此 Block 7 被认为是有效区块,Block 8 和 Block 9 就是**叔区块**(作废区块)。
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image6.png" width="300"/>
|
||||
</center>
|
||||
|
||||
|
||||
现在链上的区块高度为7,在这基础上又产生了新的交易,并被打包成了 Block 10。在以太坊中,Block 10 除了可以引用它的父区块 Block 7 外,还可以引用叔区块 Block 8 和 Block 9。并且,Block 8 和 Block 9 的矿工会因此获得一笔奖励,称为**叔块奖励**,Block 10 的矿工除了基础奖励之外,由于引用了叔区块,还会获得一笔额外的**叔块引用奖励**。
|
||||
|
||||
**幽灵协议**是以太坊的一大创新。由于在比特币中的出块时间被设计为10分钟,而以太坊为了提高出块速度,将出块时间设计为12秒(实际14~15秒左右),这样的高速出块意味着高速确认,高速确认会带来区块的**高作废率**和**低安全性**。因为区块需要花一定的时间才能广播至全网,如果矿工 A 挖出了一个区块,而矿工 B 碰巧在 A 的区块扩散至 B 之前挖出了另一个区块,矿工 B 的区块就会作废并且没有对区块链的网络安全做出贡献。此外,这样的高速确认还会带来**中心化**的问题:如果 A 拥有全网 30% 的算力而 B 拥有 10% 的算力,那么 A 将会在 70% 的时间内都在产生作废区块,而 B 在 90% 的时间内都在产生作废区块,这样,B 永远追不上 A,后果是 A 通过其算力份额拥有对挖矿过程实际上的控制权,出现了算力垄断,弱化了去中心化。
|
||||
|
||||
幽灵协议正是为了解决上述问题而引入的,协议的主要内容如下:
|
||||
|
||||
- 计算最长链时,不仅包括当前区块的父区块和祖区块,还包括祖先块的作废的后代区块(叔区块),将它们综合考虑来计算哪一个区块拥有支持其的最大工作量证明。这解决了网络安全性的问题
|
||||
- 以太坊付给以“叔区块”身份为新块确认作出贡献的废区块87.5%的奖励(叔块奖励),把它们纳入计算的“侄子区块”将获得奖励的12.5%(叔块引用奖励)。这就使得即使产生作废区块的矿工也能够参与区块链网络贡献并获得奖励,解决了中心化倾向的问题
|
||||
- 叔区块最深可以被其父母的第二代至第七代后辈区块引用。这样做是为了:
|
||||
- 降低引用叔区块的计算复杂性
|
||||
- 过多的叔块引用奖励会剥夺矿工在主链上挖矿的激励,使得矿工有转向公开攻击者链上挖矿的倾向(即公开攻击者可能会恶意产生大量作废区块,无限引用将会诱使矿工转移到攻击者的链上,从而抛弃合法的主链)
|
||||
- 计算表明带有激励的五层幽灵协议即使在出块时间为15s的情况下也实现了了95%以上的效率,而拥有25%算力的矿工从中心化得到的益处小于3%
|
||||
|
||||
### 2.1.5、以太坊的组成部分 ###
|
||||
|
||||
在以太坊中,包括了 P2P 网络、共识机制、交易、状态机、客户端这几个组成部分。
|
||||
|
||||
* P2P 网络:在以太坊主网上运行,可通过TCP端口30303访问,并运行称为 ÐΞVp2p 的协议。
|
||||
* 共识机制:以太坊目前使用名为 Ethash 的 POW 算法,计划在将来会过渡到称为 Casper 的 POS 算法。
|
||||
* 交易:以太坊中的交易本质上是网络消息,包括发送者、接收者、值和数据载荷(payload)。
|
||||
* 状态机:以太坊的状态转移由以太坊虚拟机(Ethereum Virtual Machine,EVM)处理,EVM 能够将智能合约编译成机器码并执行。
|
||||
* 客户端:用于用户和以太坊进行交互操作的软件实现,最突出的是 Go-Ethereum(Geth) 和 Parity。
|
||||
|
||||
### 2.1.6、以太坊中的概念 ###
|
||||
|
||||
* 账户:以太坊中的账户类似于银行账户、应用账户,每个账户有一个20字节的地址。账户又分为**普通账户**(又叫外部账户,External Owned Account, EOA)和**合约账户**(Contract)。普通账户是由以太坊使用者创建的账户,包含地址、余额和随机数;合约账户是创建智能合约时建立的账户,包含存储空间和合约代码
|
||||
* 状态:状态是由账户和两个账户之间价值的转移以及信息的状态转换构成的
|
||||
* 地址:地址是一个账户 ECDSA 公钥的 Keccak 散列最右边的160位,通过地址可以在以太坊上接收或发送交易。在 Etherscan 上,可以通过地址来查询一个账户的信息
|
||||
* 交易:以太坊中的交易不仅包括发送和接收以太币,还包括向合约账户发送交易来调用合约代码、向空用户发送交易来生成以交易信息为代码块的合约账户
|
||||
* Gas:Gas 是以太坊中的一种机制,用于执行智能合约或交易操作的虚拟燃料。由于以太坊是图灵完备的,为了避免开发者无意或恶意编写出死循环等浪费资源或滥用资源的情况,以太坊中的每一笔交易都需支付一定的 Gas (燃料费),即需支付一定的以太币作为 Gas。Gas 的金额通常是由交易的发起者指定并支付的
|
||||
* 挖矿:和比特币类似,以太坊同样通过挖矿来产生区块。在以太坊目前的 PoW 机制下,每当一笔交易发出并广播,就会吸引矿工来将该交易打包成区块。每产生一个区块都会有一笔**固定奖励**给矿工,目前的固定奖励是3个以太。同时,区块中所有操作所需的 Gas 也会作为奖励给矿工。与比特币不同的是,以太坊中产生叔块的矿工可能会获得叔块奖励,引用叔块的矿工会获得叔块引用奖励
|
||||
* DApp(去中心化应用):通过智能合约,开发者能够设计想要的逻辑,相当于是网站的后端。而 DApp 则相当于是一个完整的网站(前端+后端),因此 DApp = 智能合约 + Web 前端。以太坊提供了一个名为 web3.js 的 Javascript 库,通过 web3.js 可以实现 Web 与以太坊区块链的交互和与智能合约的交互,方便开发者创建 DApp
|
||||
|
||||
## 2.2、以太坊基础 ##
|
||||
|
||||
### 2.2.1、以太坊中的货币 ###
|
||||
|
||||
以太坊中的货币称为 **以太币**,单位为**以太(Ether)**,也称 ETH 或符号 Ξ。以太可以被分割为更小的单位,最小的单位是 wei,1 以太 = $10^18$ wei。以太币各单位的名称及之间的关系如下表:
|
||||
|
||||
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219000835894.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 2.2.2、以太坊钱包 ###
|
||||
|
||||
以太坊钱包是用于创建和广播交易的应用程序,常用的钱包有
|
||||
|
||||
* MetaMask,一款基于浏览器扩展的钱包,可以很方便地添加到 Chrome, FireFox 等支持扩展的浏览器中
|
||||
* Jaxx,一款跨平台、多币种的钱包
|
||||
* MyEtherWallet(MEW),一款基于 Web 的钱包,可以在任何浏览器中运行
|
||||
* Emerald Wallet,一款被设计来用于以太坊经典区块链的钱包,但也与其他以太坊区块链兼容
|
||||
|
||||
#### MetaMask 基础 ####
|
||||
|
||||
以 Chrome 为例,访问 [Google 网上应用商店](https://chrome.google.com/webstore/category/extensions),搜索 MetaMask 并添加至 Chrome
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219101124978.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
添加完成后 Chrome 会自动打开初始化页面
|
||||
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219101226095.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
|
||||
初次使用创建钱包
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219101300792.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
|
||||
为钱包设置密码
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219101332089.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
|
||||
|
||||
创建密码后,MetaMask 会生成一串密语,密语是12个随机的英文单词,用于防止密码忘记。密语可以直接当成密码使用,因此需要妥善保管
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219102028033.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
|
||||
注册完毕后就可以在 Chrome 地址栏右边的扩展程序栏点击 🦊 图标使用 MetaMask 了
|
||||
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219102255927.png"/>
|
||||
</center>
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219102322360.png"/>
|
||||
</center>
|
||||
|
||||
#### 获取测试以太 ####
|
||||
|
||||
除了以太坊主网以外,以太坊还提供了 Ropsten, Kovan, Rinkeby, Goerli 这几个公共测试网络,另外还支持局域网测试网络和自建测试网络。在这里我们切换到 Ropsten 测试网络
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219105616335.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
|
||||
|
||||
随后点击 **Buy** 按钮,点击**测试水管**下方的获取以太
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219105824087.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
|
||||
|
||||
在打开的页面中点击 request 1 ether from faucet 就可以得到1个测试以太,当然,可以多次点击。
|
||||
<center class="half">
|
||||
<img src=".\pic\image-20210219105911910.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\2021-02-19_110327.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
测试以太仅供测试使用,除此之外没有任何价值,测试完毕后剩下的以太可以发送到水龙头账户捐赠给水龙头,以供他人测试使用。
|
||||
|
||||
## 2.3、以太坊交易的数据结构
|
||||
|
||||
在以太坊网络中,交易执行属于一个事务。具有原子性、一致性、隔离性、持久性特点。
|
||||
|
||||
- 原子性: 是不可分割的最小执行单位,要么做,要么不做。
|
||||
- 一致性: 同一笔交易执行,必然是将以太坊账本从一个一致性状态变到另一个一致性状态。
|
||||
- 隔离性: 交易执行途中不会受其他交易干扰。
|
||||
- 持久性: 一旦交易提交,则对以太坊账本的改变是永久性的。后续的操作不会对其有任何影响。
|
||||
|
||||
以太坊交易的本质是由外部拥有的账户发起的签名消息,由以太坊网络传输,并被序列化后记录在以太坊区块链上,**交易是唯一可以触发状态更改或导致合约在EVM中执行的事物**
|
||||
|
||||
### 2.3.1、交易的数据结构
|
||||
|
||||
以太坊的数据结构主要可以分为四部分:`nonce`、`gas`、交易目标和消息(主要部分)、交易签名
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\transaction-struct.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
|
||||
开头是一个 uint64 类型的数字,称之为随机数。用于撤销交易、防止双花和修改以太坊账户的 Nonce 值。
|
||||
|
||||
第二部分是关于交易执行限制的设置,gas 为愿意供以太坊虚拟机运行的燃料上限。 `gasPrice` 是愿意支付的燃料单价。`gasPrcie * gas` 则为愿意为这笔交易支付的最高手续费。
|
||||
|
||||
第三部分是交易发送者输入以太坊虚拟机执行此交易的初始信息: 虚拟机操作对象(接收方 To)、从交易发送方转移到操作对象的资产(Value),以及虚拟机运行时入参(input)。其中 To 为空时,意味着虚拟机无可操作对象,**此时虚拟机将利用 input 内容部署一个新合约**。
|
||||
|
||||
第四部分是交易发送方对交易的签名结果,可以利用交易内容和签名结果反向推导出签名者,即交易发送方地址。以上总结如下:
|
||||
|
||||
* `nonce`:由发起人EOA发出的序列号,用于防止交易消息重播。
|
||||
* `gas price`:交易发起人愿意支付的gas单价(wei)。
|
||||
* `start gas`:交易发起人愿意支付的最大gas量。
|
||||
* `to`:目的以太坊地址。
|
||||
* `value`:要发送到目的地的以太数量。
|
||||
* `data`:可变长度二进制数据负载(payload)。
|
||||
* `v,r,s`:发起人EOA的ECDSA签名的三个组成部分。
|
||||
* 交易消息的结构使用递归长度前缀(RLP)编码方案进行序列化,该方案专为在以太坊中准确和字节完美的数据序列化而创建。
|
||||
|
||||
### 2.3.2、交易中的`nonce`
|
||||
|
||||
按以太坊黄皮书的定义, `nonce`是一个标量值,它等于从这个地址发送的交易数,或者对于关联code的帐户来说,是这个帐户创建合约的数量。因此`nonce`便有以下特征:
|
||||
|
||||
* `nonce`不会明确存储为区块链中帐户状态的一部分。相反,它是通过计算发送地址的已确认交易的数量来动态计算的。
|
||||
* `nonce`值还用于防止错误计算账户余额。`nonce`强制来自任何地址的交易按顺序处理,没有间隔,无论节点接收它们的顺序如何。
|
||||
* 使用`nonce`确保所有节点计算相同的余额和正确的序列交易,等同于用于防止比特币“双重支付”(“重放攻击”)的机制。但是,由于以太坊跟踪账户余额并且不单独跟踪 `UTXO` ,因此只有在错误地计算账户余额时才会发生“双重支付”。`nonce`机制可以防止这种情况发生。
|
||||
|
||||
### 2.3.3、并发和`nonce`
|
||||
|
||||
以太坊是一个允许操作(节点,客户端,DApps)并发的系统,但强制执行单例状态。例如,出块的时候只有一个系统状态。假如我们有多个独立的钱包应用或客户端,比如 MetaMask 和 Geth,它们可以使用相同的地址生成交易。如果我们希望它们都够同时发送交易,该怎么设置交易的`nonce`呢?一般有以下两种做法:
|
||||
|
||||
* 用一台服务器为各个应用分配`nonce`,先来先服务——可能出现单点故障,并且失败的交易会将后续交易阻塞。
|
||||
* 生成交易后不分配`nonce`,也不签名,而是把它放入一个队列等待。另起一个节点跟踪`nonce`并签名交易。同样会有单点故障的可能,而且跟踪`nonce`和签名的节点是无法实现真正并发的。
|
||||
|
||||
### 2.3.4、交易中的`gas`
|
||||
|
||||
Gas 中译是:瓦斯、汽油,代表一种可燃气体。 这形象地比喻以太坊的交易手续费计算模式,不同于比特币中**直接**支付比特币作为转账手续费, 以太坊视为一个去中心化的计算网络,当你发送Token、执行合约、转移以太币或者在此区块上干其他的时候,计算机在处理这笔交易时需要进行计算消耗网络资源,这样你必须支付燃油费购买燃料才能让计算机为你工作。最终燃料费作为手续费支付给矿工。
|
||||
|
||||
> 注:可以在Etherscan上查询gas price与confirmation time的关系,如下图
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\gas.jpg"/>
|
||||
</center>
|
||||
|
||||
|
||||
因为手续费等于`gasPrice * gasUsed`,用户在转账,特别是执行智能合约时 gasUsed 无法提前预知。 这样存在一个风险,当用户的交易涉及一个恶意的智能合约,该合约执行将消耗无限的燃料, 这样会导致交易方的余额全部消耗(恶意的智能合约有可能是程序Bug,如合约执行陷入一个死循环)。
|
||||
|
||||
为了避免合约中的错误引起不可预计的燃料消耗,用户需要在发送交易时设定允许消耗的燃料上限,即 gasLimit。 这样不管合约是否良好,最坏情况也只是消耗 gasLimit 量的燃料。
|
||||
|
||||
然而,一笔交易所必须支付的燃料已经在区块中通过该交易已执行的计算量记录。 如果你不想支出太多燃料,而故意设置过低的 gasLimit 是没太多帮助的。 你必须支付足够燃料来支付本交易所必要的计算资源。如果交易尚未执行完成,而燃料已用完, 将出现一个 `Out of Gas` 的错误。特别注意的是,即使交易失败,你也必须为已占用的计算资源所支付手续费。 比如,你通过合约给 TFBOYS 投票,设置 gasPrice=2 gwei,gasLimit=40000(实现投票需要40001的燃料开销), 最终你投票失败且仍然需要支付 40000*2 gwei= 80000 gwei= 0.00008 ETH。
|
||||
|
||||
另外,如果最终 gasUsed 低于 gasLimit,即燃料未用完。则剩余燃料(gasLimit - gasUsed )将在交易后退还给你。 比如你发送 1 Ether 到另一个账户B,设置 gas limit 为 400000,将有 400000 - 21000 返回给你。
|
||||
|
||||
> 注意:21000 是标准转账交易的gasUsed。因此一笔标准的转账交易你可以设置 gasLimit 为21000
|
||||
|
||||
## 2.4、以太坊账户
|
||||
|
||||
对比比特币的UTXO余额模型,以太坊使用“账户”余额模型。 以太坊丰富了账户内容,除余额外还能自定义存放任意多数据。 并利用账户数据的可维护性,构建智能合约账户。下面我们首先将比特币的UTXO余额模型与以太坊账户进行比较,说明其各自的优缺点以及适用性。
|
||||
|
||||
### 2.4.1、比特币UTXO和以太坊账户结构比较
|
||||
|
||||
在当前的区块链项目中,主要有两种记录保存方式,**一种是账户/余额模型,一种是UTXO模型**。比特币采用就是UTXO模型,以太坊、EOS等则采用的是账户/余额模型。
|
||||
|
||||
<img src="pic/utxo_com.jpg" style="zoom:67%;" />
|
||||
|
||||
### 2.4.2、比特币UTXO
|
||||
|
||||
UTXO是 Unspent Transaction Output的缩写,意思是**未花费的输出,**可以简单理解为还没有用掉的收款。比如韩梅梅收到一笔比特币,她没有用掉,这笔比特币对她来说就是一个UTXO。关于UTXO的具体介绍大家可以查看[这篇文章](https://zhuanlan.zhihu.com/p/74050135)。
|
||||
|
||||
**UTXO 核心设计思路是:它记录交易事件,而不记录最终状态。**要计算某个用户有多少比特币,就要对其钱包里所有的UTXO求和,得到结果就是他的持币数量。UTXO模型在转账交易时,是以UTXO为单位的,也就是说在支付时,调用的是整数倍UTXO,比如1个UTXO,3个UTXO,没有0.5个UTXO的说法。
|
||||
|
||||
* 比特币在基于UTXO的结构中存储有关用户余额的数据,系统的整个状态就是一组UTXO的集合,每个UTXO都有一个所有者和一个面值(就像不同的硬币),而交易会花费若干个输入的UTXO,并根据规则创建若干个新的UTXO
|
||||
* 每个引用的输入必须有效并且尚未花费,对于一个交易,必须包含有每个输入的所有者匹配的签名,总输入必须大于等于总输出值。所以系统中用户的余额是用户具有私钥的UTXO的总值
|
||||
|
||||
### 2.4.3、以太坊账户
|
||||
|
||||
为什么以太坊不用UTXO呢?显然是因为麻烦,以太坊的做法更符合直觉,以太坊中的状态就是系统中所有账户的列表,每个账户都包含了一个余额和以太坊**特殊定义的数据**(代码和内部存储)。如果发送账户有足够多的余额来进行支付,则交易有效,在这种情况下发送账户先扣款,而收款账户将记入这笔收入。**如果接受账户有相关代码,则代码会自动运行,并且它的内部存储也可能被更改,或者代码还可能向其他账户发送额外的消息,这就会导致进一步的借贷资金关系。**
|
||||
|
||||
### 2.4.4、优缺点比较
|
||||
|
||||
**比特币UTXO的优点**:
|
||||
|
||||
* 更高程度的隐私:如果用户为他们收到的每笔交易使用新地址,那么通常很难将账户互相链接。这很大程度上适用于货币,但不太适用于任何dapps,因为dapps通常涉及跟踪和用户绑定的复杂状态,可能不存在像货币那样简单的用户状态划分方案
|
||||
* 潜在的可扩展性:UTXO在理论上更符合可扩展性要求,因为我们只需要依赖拥有UTXO的那些人去维护基于Merkle树的所有权证明就够了,即使包括所有者在内的每个人都决定忘记该数据,那么也只有所有者受到对应的UTXO的损失,不影响接下来的交易。而在账户模式中,如果每个人都丢失了与账户相对应的Merkle树的部分,那将会使得和该账户有关的消息完全无法处理,包括发币给它。
|
||||
|
||||
**以太坊账户模式的优点**:
|
||||
|
||||
* 可以节省大量空间:不将UTXOs分开存储,而是合成一个账户;每个交易只需要一个输入、一个签名并产生一个输出
|
||||
* 更好的可替代性:货币本质上都是同质化、可替代的;UTXO的设计使得货币从来源分成了“可花费”和“不可花费”两类,这在实际应用中很难有对应模型
|
||||
* 更加简单:更容易编码和理解,特别是设计复杂脚本的时候,UTXO的脚本逻辑复杂时更令人费解
|
||||
* 便于维护持久轻节点:只要沿着特定方向扫描状态树,轻节点 可以很容易地随时访问账户相关的所有数据。而UTXO地每个交易都会使得状态引用发生改变,这对应节点来说长时间运行Dapp会有很大压力
|
||||
|
||||
### 2.4.5、总结
|
||||
|
||||
| | BitCoin | Ethereum |
|
||||
| ------------ | ---------------- | ---------------- |
|
||||
| **设计定位** | 现金系统 | 去中心化应用平台 |
|
||||
| **数据组成** | 交易列表(账本) | 交易和账户状态 |
|
||||
| **交易对象** | UTXO | Accounts |
|
||||
| **代码控制** | 脚本 | 智能合约 |
|
||||
|
||||
## 2.5、以太坊账户类型
|
||||
|
||||
以太坊作为智能合约操作平台,将账户划分为两类:外部账户(EOAs)和合约账户(contract account),下面分别做简要介绍:
|
||||
|
||||
<center class="half">
|
||||
<img src=".\pic\EOA_CA.png"/>
|
||||
</center>
|
||||
|
||||
|
||||
|
||||
### 2.5.1、外部账户(EOA)
|
||||
|
||||
外部账户是由人来控制的,也就是常规理解的普通账户,外部账户包含以太币余额,主要作用就是发送交易(是广义的交易,包括转币和触发合约代码),是由用户私钥控制的,没有关联代码,所有在以太坊上交易的发起者都是外部账户。
|
||||
|
||||
外部账户特点总结:
|
||||
|
||||
1. 拥有以太余额。
|
||||
2. 能发送交易,包括转账和执行合约代码。
|
||||
3. 被私钥控制。
|
||||
4. 没有相关的可执行代码。
|
||||
|
||||
### 2.5.2、合约账户(CA)
|
||||
|
||||
合约账户有时也叫内部账户,有对应的以太币余额和关联代码,它是由代码控制的,可以通过交易或来自其他合约的调用消息来触发代码执行,执行代码时可以操作自己的存储空间,也可以调用其他合约
|
||||
|
||||
合约账户特点总结:
|
||||
|
||||
1. 拥有以太余额。
|
||||
2. 有相关的可执行代码(合约代码)。
|
||||
3. 合约代码能够被交易或者其他合约消息调用。
|
||||
4. 合约代码被执行时可再调用其他合约代码。
|
||||
5. 合约代码被执行时可执行复杂运算,可永久地改变合约内部的数据存储。
|
||||
|
||||
|
||||
如果大家对概念还理解不深可以先尝试学习后面部分,本教程内容有限,推荐大家有精力阅读以下读物:
|
||||
- [区块链学习的书籍](https://www.zhihu.com/question/61156867)
|
||||
- [区块链入门教程](https://www.ruanyifeng.com/blog/2017/12/blockchain-tutorial.html)
|
||||
- [IBM教程](https://developer.ibm.com/zh/technologies/blockchain/tutorials/)
|
||||
|
||||
**参考自:**
|
||||
1. [比特币白皮书]https://www.8btc.com/wiki/bitcoin-a-peer-to-peer-electronic-cash-system)
|
||||
2. [以太坊白皮书](https://ethfans.org/posts/ethereum-whitepaper)
|
||||
3. [超级账本白皮书](https://www.chainnode.com/doc/399)
|
||||
4. [闪电网络白皮书](https://www.chainnode.com/doc/399)
|
||||
|
|
@ -0,0 +1,402 @@
|
|||
<font color='red'> 注:本教程为技术教程,不谈论且不涉及炒作任何数字货币 </font>
|
||||
|
||||
# 合约编写实战实例
|
||||
|
||||
## 一、简单代币合约
|
||||
|
||||
```javascript
|
||||
pragma solidity > 0.4.22;
|
||||
|
||||
contract Coin{
|
||||
//这里我们定义了一个address 作为key, uint做为value的hashTable balances; 我们还定义了一个address的变量minter;
|
||||
address public minter;
|
||||
mapping(address=>uint) balances;
|
||||
event Sent(address from, address to, uint amount);
|
||||
constructor(){
|
||||
//代表创建这个合约的账户地址,被赋值给变量minter.
|
||||
minter = msg.sender;
|
||||
}
|
||||
|
||||
//添加一个挖矿合约
|
||||
function mint(address receiver, uint amount) public{
|
||||
require(msg.sender == minter);
|
||||
balances[receiver] += amount;
|
||||
|
||||
}
|
||||
function send(address receiver, uint amount) public{
|
||||
require(balances[msg.sender] >= amount);
|
||||
balances[msg.sender] -= amount;
|
||||
balances[receiver] += amount;
|
||||
emit Sent(msg.sender,receiver,amount);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
解析:
|
||||
上面实现一个简单的加密货币,币在这里可以无中生有,但只有创建合约的人才能做到,且任何人都可以给他人转币,无需注册名和密码。
|
||||
|
||||
`address`类型是一个160位的值,不允许任何算数操作,这种类型适合存储合约地址或外部人员。
|
||||
|
||||
`mappings`可看作是一个哈希表,它会执行虚拟初始化,以使得所有可能存在的键都映射到一个字节表示为全零的值。
|
||||
|
||||
`event Sent(address from, address to, uint amount)`;声明了一个所谓的事件,它在send函数最后一行被发出。用户界面可以监听区块链上正在发送的事件,且不会花费太多成本,一旦它被发出,监听该事件的listener都将收到通知,而所有的事件都包含了`from`,`t`o和`amoun`t三个参数,可方便追踪事务。
|
||||
|
||||
`msg.sender`始终是当前函数或者外部函数调用的来源地址。
|
||||
|
||||
最后真正被用户和其他合约所调用的,用于完成本合约功能的方法是`mint`和`send`。若`mint`被合约创建者外的其他调用则说明都不会发生。
|
||||
|
||||
`send`函数可被任何人用于向其他人发送代币,前提是发送者拥有这些代币,若使用合约发送代币给一个地址,当在区块链浏览器上查到该地址时时看不到任何相关信息的,因为,实际上发送币和更改余额的信息仅仅存在特定合约的数据存储器中。通过使用事件,可非常简单地为新币创建一个区块链浏览器来追踪交易和余额。
|
||||
|
||||
<center>
|
||||
<img style="border-radius: 0.3125em;
|
||||
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
|
||||
src="pic/part2-15.png">
|
||||
<br>
|
||||
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
|
||||
display: inline-block;
|
||||
color: #999;
|
||||
padding: 2px;"></div>
|
||||
</center>
|
||||
|
||||
|
||||
|
||||
## 二、水龙头合约
|
||||
|
||||
在前面我们通过 Ropsten 测试网络的水龙头(Faucet)获取了一些以太币,并提到可以向水龙头账户发送以太币来捐赠以太币。实际上,水龙头账户是一个合约账户,水龙头就是一份合约,而整个网站就是合约+前端组成的DApp。下面我们通过 Remix 来编写一个简单的水龙头合约,借此了解如何创建、部署合约以及一些 Solidity 的基本语法。
|
||||
|
||||
首先打开 Remix,并新建一个名为 faucet.sol 的文件,该文件就是 Solidity 的源文件
|
||||
|
||||
<center>
|
||||
<img style="border-radius: 0.3125em;
|
||||
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
|
||||
src="pic/part2-16.png">
|
||||
<br>
|
||||
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
|
||||
display: inline-block;
|
||||
color: #999;
|
||||
padding: 2px;"></div>
|
||||
</center>
|
||||
|
||||
打开 faucet.sol,并写入如下代码
|
||||
|
||||
```javascript
|
||||
pragma solidity ^0.7.0;
|
||||
|
||||
contract faucet {
|
||||
function withdraw (uint amount) public {
|
||||
require (amount <= 1e18);
|
||||
msg.sender.transfer (amount);
|
||||
}
|
||||
|
||||
receive () external payable {}
|
||||
}
|
||||
```
|
||||
|
||||
通过这几行代码我们就实现了一个非常简单的水龙头合约。首行代码 `pragma solidity ^0.7.0 `是一个**杂注**,指定了我们的源文件使用的编译器版本不能低于 0.7.0,也不能高于 0.8.0。
|
||||
|
||||
`contract faucet{...}` 声明了一个合约对象,合约对象类似面向对象语言中的类,对象名必须跟文件名相同。
|
||||
|
||||
接下来通过 `function withdraw (uint amount) public {...}` 创建了一个名为 withdraw 的函数,该函数接收一个无符号整数(uint)作为参数,并且被声明为 public 函数,意为可以被其他合约调用。
|
||||
|
||||
withdraw 函数体中的 `require` 是 Solidity 的内置函数,用来检测括号中的条件是否满足。条件满足则继续执行合约,条件不满足则合约停止执行,回撤所有执行过的操作,并抛出异常。在这里我们通过 `require (amount <= 1e18)` 来检测输入的以太币值是否小于等于1个以太。
|
||||
|
||||
接下来的这一行 `msg.sender.transfer (amount)` 就是实际的提款操作了。`msg` 是 Solidity 中内置的对象,所有合约都可以访问,它代表触发此合约的交易。也就是说当我们调用 `withdraw` 函数的时候实际上触发了一笔交易,并用 `msg` 来表示它。`sender` 是交易 `msg` 的属性,表示了交易的发件人地址。函数 `transfer` 是一个内置函数,它接收一个参数作为以太币的数量,并将该数量的以太币从合约账户发送到调用合约的用户的地址中。
|
||||
|
||||
最后一行是一个特殊的函数 `receive` ,这是所谓的 `fallback` 或 `default` 函数。当合约中的其他函数无法处理发送到合约中的交易信息时,就会执行该函数。在这里,我们将该函数声明为 `external` 和 `payable` ,`external` 意味着该函数可以接收来自外部账户的调用,`payable` 意味着该函数可以接收来自外部账户发送的以太币。
|
||||
|
||||
这样,当我们调用合约中的 `withdraw` 并提供一个参数时,我们可以从这份合约中提出以太币;当我们向合约发送以太币时,就会调用 `receive` 函数往合约中捐赠以太币。
|
||||
|
||||
代码编写完毕后,在 Remix 左侧的功能栏中选择第二项,并点击 *Compile faucet.sol* 来编译我们的 sol 文件。
|
||||
|
||||
<center>
|
||||
<img style="border-radius: 0.3125em;
|
||||
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
|
||||
src="pic/part2-17.png">
|
||||
<br>
|
||||
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
|
||||
display: inline-block;
|
||||
color: #999;
|
||||
padding: 2px;"></div>
|
||||
</center>
|
||||
|
||||
|
||||
编译完成后会出现一个 Warning,提示我们添加 SPDX license,可以忽略。
|
||||
|
||||
随后选择 Remix 左侧工具栏的第三项,进入合约部署界面
|
||||
|
||||
<center>
|
||||
<img style="border-radius: 0.3125em;
|
||||
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
|
||||
src="pic/part2-18.png">
|
||||
<br>
|
||||
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
|
||||
display: inline-block;
|
||||
color: #999;
|
||||
padding: 2px;"></div>
|
||||
</center>
|
||||
|
||||
|
||||
首先将 ENVIRONMENT 选择为 Injected Web3,这样才能通过 MetaMask 钱包来发送交易。
|
||||
|
||||
随后点击 Deploy 部署合约,MetaMask 会弹出部署合约的交易界面
|
||||
|
||||
<center>
|
||||
<img style="border-radius: 0.3125em;
|
||||
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
|
||||
src="pic/part2-19.png">
|
||||
<br>
|
||||
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
|
||||
display: inline-block;
|
||||
color: #999;
|
||||
padding: 2px;"></div>
|
||||
</center>
|
||||
|
||||
|
||||
因为该笔交易是合约创建交易,因此我们支付的以太币为0,但仍需支付一定的 Gas 费用,可以自己设定 Gas 的价格。
|
||||
|
||||
合约部署成功后会收到 Chrome 的消息提示,并在 Remix 的 Deployed Contracts 中也会有显示
|
||||
|
||||
<center>
|
||||
<img style="border-radius: 0.3125em;
|
||||
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
|
||||
src="pic/part2-20.png">
|
||||
<br>
|
||||
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
|
||||
display: inline-block;
|
||||
color: #999;
|
||||
padding: 2px;"></div>
|
||||
</center>
|
||||
|
||||
|
||||
这样我们就完成了这个水龙头合约的部署。
|
||||
|
||||
#### 水龙头测试 ####
|
||||
|
||||
我们刚刚创建的水龙头中还没有以太坊,因此我们可以通过 MetaMask 向水龙头合约的地址中发送一些以太坊。水龙头合约的地址会显示在 Remix 中的,见上图 FAUCET AT 0X7A4...34219,可以直接复制。
|
||||
|
||||
<center>
|
||||
<img style="border-radius: 0.3125em;
|
||||
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
|
||||
src="pic/part2-21.png">
|
||||
<br>
|
||||
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
|
||||
display: inline-block;
|
||||
color: #999;
|
||||
padding: 2px;"></div>
|
||||
</center>
|
||||
|
||||
|
||||
交易被确认后,我们的水龙头中就有了0.999726个以太币,现在我们可以通过 Remix 中合约一栏的 withdraw 按钮来提取以太币了。需要注意,这里输入的以太币个数是以 wei 为单位的。
|
||||
|
||||
<center>
|
||||
<img style="border-radius: 0.3125em;
|
||||
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
|
||||
src="pic/part2-22.png">
|
||||
<br>
|
||||
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
|
||||
display: inline-block;
|
||||
color: #999;
|
||||
padding: 2px;"></div>
|
||||
</center>
|
||||
|
||||
|
||||
点击 withdraw 后,会弹出警告框
|
||||
|
||||
<center>
|
||||
<img style="border-radius: 0.3125em;
|
||||
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
|
||||
src="pic/part2-23.png">
|
||||
<br>
|
||||
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
|
||||
display: inline-block;
|
||||
color: #999;
|
||||
padding: 2px;"></div>
|
||||
</center>
|
||||
|
||||
|
||||
这是因为目前我们还没有设置这笔交易的 Gas,不用担心,点击 Send Transaction 后,在弹出的 MetaMask 中设置即可。
|
||||
|
||||
交易被确认后,我们得到了刚刚提取的0.999726个以太币
|
||||
|
||||
<center>
|
||||
<img style="border-radius: 0.3125em;
|
||||
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
|
||||
src="pic/part2-15.png">
|
||||
<br>
|
||||
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
|
||||
display: inline-block;
|
||||
color: #999;
|
||||
padding: 2px;"></div>
|
||||
</center>
|
||||
|
||||
|
||||
若大家没有执行成功可以重新做一次、查找其他资料或者[观看此视频](https://www.bilibili.com/video/BV1sJ411D72u?p=465)
|
||||
|
||||
## 三、投票合约的实现
|
||||
|
||||
<img src="pic/rating.png" style="zoom:67%;" />
|
||||
|
||||
本次教程将以一个较复杂的投票合约作为结束,我们希望实现的功能是为每个(投票)建议建立一份合约,然后作为合约的创造者-主席,主席将赋予每个成员(地址)投票权,而成员的投票权可以选择委托给其他人也可以自己投票,结束时将返回投票最多的提案。听起来很简单一个功能实现起来却较为复杂,下面我们拆分开进行讲解
|
||||
|
||||
注:
|
||||
|
||||
1. 代码可直接在Remix编辑器的已有solidity文件中找到,在contract/_Ballot.sol文件里
|
||||
2. 若学习者前面部分掌握较牢固,不妨尝试直接自行阅读代码,无需阅读本节内容
|
||||
|
||||
|
||||
首先我们定义成员类型,我们为每个投票者定义权重、是否已投票、
|
||||
|
||||
```javascript
|
||||
struct Voter {
|
||||
uint weight; // weight is accumulated by delegation
|
||||
bool voted; // if true, that person already voted
|
||||
address delegate; // person delegated to
|
||||
uint vote; // index of the voted proposal
|
||||
}
|
||||
```
|
||||
|
||||
然后我们定义提案类型,包含提案名和投票总数:
|
||||
|
||||
```javascript
|
||||
struct Proposal {
|
||||
bytes32 name; // short name (up to 32 bytes)
|
||||
uint voteCount; // number of accumulated votes
|
||||
}
|
||||
```
|
||||
|
||||
定义三个变量,主席是一个公开的地址,建立投票者与地址的映射,然后定义提案动态数组:
|
||||
|
||||
```javascript
|
||||
address public chairperson;
|
||||
mapping(address => Voter) public voters;
|
||||
Proposal[] public proposals;
|
||||
```
|
||||
|
||||
- `address public chairperson`:投票发起人,类型为 address。
|
||||
- `mapping(address => Voter) public voters`:所有投票人,类型为 `address` 到 `Voter` 的映射。
|
||||
- `Proposal[] public proposals`:所有提案,类型为动态大小的 `Proposal` 数组。
|
||||
|
||||
3 个状态变量都使用了 `public` 关键字,使得变量可以被外部访问(即通过消息调用)。事实上,编译器会自动为 `public `的变量创建同名的 `getter` 函数,供外部直接读取。
|
||||
|
||||
我们还需要为每个投票赋予初始权值,并将主席的权重设置为1。我们一般使用`constructor`赋初值,这与C++等语言类似:
|
||||
|
||||
```javascript
|
||||
constructor(bytes32[] memory proposalNames) {
|
||||
chairperson = msg.sender;
|
||||
voters[chairperson].weight = 1;
|
||||
|
||||
for (uint i = 0; i < proposalNames.length; i++) {
|
||||
proposals.push(Proposal({
|
||||
name: proposalNames[i],
|
||||
voteCount: 0
|
||||
}));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
所有提案的名称通过参数 `bytes32[] proposalNames` 传入,逐个记录到状态变量 `proposals` 中。同时用 `msg.sender` 获取当前调用消息的发送者的地址,记录为投票发起人 `chairperson`,该发起人投票权重设为 1。
|
||||
|
||||
接下来我们需要给每个投票者赋予权重:
|
||||
|
||||
```javascript
|
||||
function giveRightToVote(address voter) public {
|
||||
require(
|
||||
msg.sender == chairperson,
|
||||
"Only chairperson can give right to vote."
|
||||
);
|
||||
require(
|
||||
!voters[voter].voted,
|
||||
"The voter already voted."
|
||||
);
|
||||
require(voters[voter].weight == 0);
|
||||
voters[voter].weight = 1;
|
||||
}
|
||||
```
|
||||
|
||||
该函数给 `address voter` 赋予投票权,即将 `voter` 的投票权重设为 1,存入 `voters` 状态变量。
|
||||
|
||||
上面这个函数只有投票发起人 `chairperson` 可以调用。这里用到了 `require((msg.sender == chairperson) && !voters[voter].voted)` 函数。如果` require` 中表达式结果为 `false`,这次调用会中止,且回滚所有状态和以太币余额的改变到调用前。但已消耗的 `Gas` 不会返还。
|
||||
|
||||
下面一段是整段代码的重点,其作用是委托其他人代理投票,基本思路是:
|
||||
|
||||
1. 使用`require`判断委托人是否已投票(若投过票再委托则重复投票),并判断被委托对象是否是自己
|
||||
2. 当判断被委托人不是0地址(主席)时,被委托人代理委托人的票,【绕口警告】由于被委托人也可能委托了别人,因此这里需要一直循环直到找到最后没有委托别人的被委托人为止!
|
||||
3. 委托人找到对应的被委托人,委托人已投票(避免重复投票)
|
||||
4. 判断被委托人是否已投票,若投了票则将被委托人投的提案票数加上委托人的权重,若未投票则令被委托人的权重加上委托人的权重(以后投票自然相当于投两票)
|
||||
|
||||
注:该函数使用了 `while` 循环,这里合约编写者需要十分谨慎,防止调用者消耗过多 `Gas`,甚至出现死循环。
|
||||
|
||||
```javascript
|
||||
function delegate(address to) public {
|
||||
Voter storage sender = voters[msg.sender];
|
||||
require(!sender.voted, "You already voted.");
|
||||
require(to != msg.sender, "Self-delegation is disallowed.");
|
||||
|
||||
while (voters[to].delegate != address(0)) {
|
||||
to = voters[to].delegate;
|
||||
require(to != msg.sender, "Found loop in delegation.");
|
||||
}
|
||||
sender.voted = true;
|
||||
sender.delegate = to;
|
||||
Voter storage delegate_ = voters[to];
|
||||
if (delegate_.voted) {
|
||||
proposals[delegate_.vote].voteCount += sender.weight;
|
||||
} else {
|
||||
delegate_.weight += sender.weight;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
投票部分仅是几个简单的条件判断:
|
||||
|
||||
```javascript
|
||||
function vote(uint proposal) public {
|
||||
Voter storage sender = voters[msg.sender];
|
||||
require(sender.weight != 0, "Has no right to vote");
|
||||
require(!sender.voted, "Already voted.");
|
||||
sender.voted = true;
|
||||
sender.vote = proposal;
|
||||
proposals[proposal].voteCount += sender.weight;
|
||||
}
|
||||
```
|
||||
|
||||
用 `voters[msg.sender]` 获取投票人,即此次调用的发起人。接下来检查是否是重复投票,如果不是,进行投票后相关状态变量的更新。
|
||||
|
||||
接下来是计算获胜提案:
|
||||
|
||||
```javascript
|
||||
function winningProposal() public view
|
||||
returns (uint winningProposal_)
|
||||
{
|
||||
uint winningVoteCount = 0;
|
||||
for (uint p = 0; p < proposals.length; p++) {
|
||||
if (proposals[p].voteCount > winningVoteCount) {
|
||||
winningVoteCount = proposals[p].voteCount;
|
||||
winningProposal_ = p;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`returns (uint winningProposal)` 指定了函数的返回值类型,`constant` 表示该函数不会改变合约状态变量的值。
|
||||
|
||||
最后是查询获胜者名称:
|
||||
|
||||
```javascript
|
||||
function winnerName() public view
|
||||
returns (bytes32 winnerName_)
|
||||
{
|
||||
winnerName_ = proposals[winningProposal()].name;
|
||||
}
|
||||
```
|
||||
|
||||
这里采用内部调用 `winningProposal()` 函数的方式获得获胜提案。如果需要采用外部调用,则需要写为 `this.winningProposal()`。
|
||||
|
||||
|
||||
|
||||
**参考自:**
|
||||
|
||||
[尚硅谷区块链全套Go语言→GoWeb→以太坊→项目实战](https://www.bilibili.com/video/BV1sJ411D72u)
|
||||
[web3.js 1.0中文手册](http://cw.hubwiz.com/card/c/web3.js-1.0/)
|
||||
|
||||
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
{kind=link}
|
After Width: | Height: | Size: 6.4 KiB |
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
{kind=link}
|
After Width: | Height: | Size: 25 KiB |
{kind=link}
|
After Width: | Height: | Size: 21 KiB |
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
{kind=link}
|
After Width: | Height: | Size: 9.9 KiB |
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
{kind=link}
|
After Width: | Height: | Size: 9.8 KiB |
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
{kind=link}
|
After Width: | Height: | Size: 19 KiB |
{kind=link}
|
After Width: | Height: | Size: 153 KiB |
|
|
@ -0,0 +1 @@
|
|||
|
||||
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
{kind=link}
|
After Width: | Height: | Size: 35 KiB |
{kind=link}
|
After Width: | Height: | Size: 49 KiB |
{kind=link}
|
After Width: | Height: | Size: 34 KiB |
{kind=link}
|
After Width: | Height: | Size: 19 KiB |
{kind=link}
|
After Width: | Height: | Size: 19 KiB |
{kind=link}
|
After Width: | Height: | Size: 23 KiB |
{kind=link}
|
After Width: | Height: | Size: 80 KiB |
{kind=link}
|
After Width: | Height: | Size: 7.8 KiB |
{kind=link}
|
After Width: | Height: | Size: 23 KiB |
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
{kind=link}
|
After Width: | Height: | Size: 55 KiB |
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
{kind=link}
|
After Width: | Height: | Size: 19 KiB |
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
{kind=link}
|
After Width: | Height: | Size: 24 KiB |
{kind=link}
|
After Width: | Height: | Size: 23 KiB |
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
{kind=link}
|
After Width: | Height: | Size: 21 KiB |
{kind=link}
|
After Width: | Height: | Size: 17 KiB |
{kind=link}
|
After Width: | Height: | Size: 63 KiB |
{kind=link}
|
After Width: | Height: | Size: 58 KiB |
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
{kind=link}
|
After Width: | Height: | Size: 9.5 KiB |
{kind=link}
|
After Width: | Height: | Size: 7.1 KiB |
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
{kind=link}
|
After Width: | Height: | Size: 41 KiB |
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
{kind=link}
|
After Width: | Height: | Size: 61 KiB |
{kind=link}
|
After Width: | Height: | Size: 58 KiB |
{kind=link}
|
After Width: | Height: | Size: 61 KiB |
{kind=link}
|
After Width: | Height: | Size: 86 KiB |
{kind=link}
|
After Width: | Height: | Size: 23 KiB |
{kind=link}
|
After Width: | Height: | Size: 62 KiB |
{kind=link}
|
After Width: | Height: | Size: 25 KiB |
{kind=link}
|
After Width: | Height: | Size: 33 KiB |
{kind=link}
|
After Width: | Height: | Size: 47 KiB |
{kind=link}
|
After Width: | Height: | Size: 43 KiB |
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
{kind=link}
|
After Width: | Height: | Size: 989 B |
{kind=link}
|
After Width: | Height: | Size: 31 KiB |
{kind=link}
|
After Width: | Height: | Size: 132 KiB |
{kind=link}
|
After Width: | Height: | Size: 31 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.3 KiB |
{kind=link}
|
After Width: | Height: | Size: 7.9 KiB |
{kind=link}
|
After Width: | Height: | Size: 47 KiB |
{kind=link}
|
After Width: | Height: | Size: 51 KiB |
{kind=link}
|
After Width: | Height: | Size: 125 KiB |
{kind=link}
|
After Width: | Height: | Size: 60 KiB |
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
{kind=link}
|
After Width: | Height: | Size: 173 KiB |
{kind=link}
|
After Width: | Height: | Size: 95 KiB |
{kind=link}
|
After Width: | Height: | Size: 46 KiB |
{kind=link}
|
After Width: | Height: | Size: 31 KiB |
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
{kind=link}
|
After Width: | Height: | Size: 118 KiB |
{kind=link}
|
After Width: | Height: | Size: 185 KiB |
|
|
@ -0,0 +1 @@
|
|||
This folder contains some necessary picture
|
||||
{kind=link}
|
After Width: | Height: | Size: 84 KiB |
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
{kind=link}
|
After Width: | Height: | Size: 85 KiB |
|
|
@ -0,0 +1,46 @@
|
|||
# 1. 编程实践(区块链)
|
||||
|
||||
开源内容:https://github.com/datawhalechina/team-learning-program/tree/master/Blockchain
|
||||
|
||||
## 基本信息
|
||||
|
||||
- 贡献人员:陈锴、孙子涵、李岳昆、易远哲
|
||||
- 学习周期:12天
|
||||
- 学习形式:根据教程主线进行学习
|
||||
- 人群定位:具有至少一门编程语言基础,在开展组队学习之前能够熟悉 Linux 基本操作
|
||||
- 难度系数:较难
|
||||
|
||||
## 学习目标
|
||||
|
||||
## 任务安排
|
||||
|
||||
### Task00:熟悉规则并先修Linux(2天)
|
||||
|
||||
- 组队、修改群昵称
|
||||
- 熟悉打卡规则
|
||||
- 对Linux不太熟悉的学习者先安装Linux环境(可以是虚拟机或子系统)并掌握基本命令,其他内容可以暂不了解
|
||||
|
||||
### Task01:区块链简介与以太坊入门介绍(2天)
|
||||
|
||||
* 学习者学习区块链基础与以太坊入门介绍,该部分以了解为主
|
||||
* 学习者可以根据教程提供的各个方面内容,对某一部分深入了解并进行打卡
|
||||
* 打卡截至时间:3月16日24:00
|
||||
|
||||
### Task02:Solidity基础(3天)
|
||||
|
||||
* 学习者学习Solidity在线编辑器Remix的使用以及Solidity的基础操作,该部分需要深入掌握,学习者可以根据参考链接提供的资料进一步学习
|
||||
* 打卡内容为Task02最后的Solidity练习题部分,其他内容不作硬性要求
|
||||
* 打卡截止日期:3月19日24:00
|
||||
|
||||
### Task03:web3js基础(3天)
|
||||
|
||||
* 学习者学习以太坊客户端的使用以及Geth控制台部署智能合约
|
||||
* 打卡内容为学习者完成一个自己编写的合约的部署,并测试函数调用等
|
||||
* 打卡截止日期:3月22日24:00
|
||||
|
||||
### Task04:合约编写实战实例(2天)
|
||||
|
||||
* 学习者学习编写几个Remix官网自带的合约,并回顾 Task01的教程内容重新梳理知识点
|
||||
* 打卡内容为学习者自己的学习感悟,内容不限
|
||||
* 打卡截止日期:3月23日24:00
|
||||
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
# Chapter 0 开篇词
|
||||
|
||||
相信大家在开发项目尤其是团队合作项目中一定会遇到下面这些场景:
|
||||
|
||||
- 项目在我电脑上明明运行的很好呀!怎么在你这不行了呢?
|
||||
- 我这是用python 3.6写的,你电脑是python 2.7应该运行不了。
|
||||
- 项目的一些依赖包需要科学上网才能下载,你那没有的话赶紧下载一下才能运行。
|
||||
- 论文的代码已经公开到github上了,但是因为自己电脑环境和他的不一样,项目在自己电脑上死活跑不起来。
|
||||
|
||||
以上这些问题我相信大家并不陌生,那么通过本次Docker的组队学习,希望大家能够避免卡在科研或者开发的第一步,提高自己的生产力。
|
||||
|
||||
---
|
||||
|
||||
通过本次docker的组队学习,我们希望你能学到以下几个方面的能力:
|
||||
|
||||
- 了解什么是docker
|
||||
- docker镜像是怎么构建的
|
||||
- 如何运行一个docker容器
|
||||
- docker之间的网络通信是怎么样的
|
||||
- docker中的数据如何做持久化存储
|
||||
- 如何通过docker compose管理自己的项目
|
||||
- 如何将自己的个人项目打造成容器化部署的形式
|
||||
|
||||
祝你在docker的学习上一切顺利!
|
||||
|
|
@ -0,0 +1,176 @@
|
|||
# Chapter 4 Docker 数据管理
|
||||
|
||||
这一章介绍如何在 Docker 内部以及容器之间管理数据,在容器中管理数据主要有两种方式:
|
||||
|
||||
* 数据卷
|
||||
* 挂载主机目录
|
||||
|
||||
|
||||
## 数据卷
|
||||
|
||||
数据卷是一个可供一个或多个容器使用的特殊目录,它绕过 UFS (UNIX File System) ,可以提供很多有用的特性:
|
||||
|
||||
* 数据卷可以在容器之间共享和重用
|
||||
|
||||
* 对数据卷的修改会立马生效
|
||||
|
||||
* 对数据卷的更新,不会影响镜像
|
||||
|
||||
* 数据卷默认会一直存在,即使容器被删除
|
||||
|
||||
>注意:数据卷的使用,类似于 Linux 下对目录或文件进行 mount,镜像中的被指定为挂载点的目录中的文件会复制到数据卷中(仅数据卷为空时会复制)。
|
||||
|
||||
### 创建一个数据卷
|
||||
|
||||
```bash
|
||||
$ docker volume create datawhale
|
||||
```
|
||||
|
||||
查看所有的数据卷
|
||||
|
||||
```bash
|
||||
$ docker volume ls
|
||||
|
||||
DRIVER VOLUME NAME
|
||||
local datawhale
|
||||
```
|
||||
|
||||
在主机里使用以下命令可以查看指定数据卷的信息
|
||||
|
||||
```bash
|
||||
$ docker volume inspect datawhale
|
||||
[
|
||||
{
|
||||
"Driver": "local",
|
||||
"Labels": {},
|
||||
"Mountpoint": "/var/lib/docker/volumes/datawhale/_data",
|
||||
"Name": "datawhale",
|
||||
"Options": {},
|
||||
"Scope": "local"
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
### 启动一个挂载数据卷的容器
|
||||
|
||||
在用 `docker run` 命令的时候,使用 `--mount` 标记来将数据卷挂载到容器里。在一次 `docker run` 中可以挂载多个 `数据卷`。
|
||||
|
||||
下面创建一个名为 `web` 的容器,并加载一个数据卷到容器的 `/usr/share/nginx/html` 目录。
|
||||
|
||||
```bash
|
||||
$ docker run -d -P \
|
||||
--name web \
|
||||
--mount source=datawhale,target=/usr/share/nginx/html \
|
||||
nginx:alpine
|
||||
```
|
||||
>–-mount参数说明:
|
||||
> source :数据卷
|
||||
> target :是容器内文件系统挂载点
|
||||
|
||||
>注意,可以不需要提前创建好数据卷,直接在运行容器的时候mount 这时如果不存在指定的数据卷,docker会自动创建,自动生成。
|
||||
|
||||
### 查看数据卷的具体信息
|
||||
|
||||
在主机里使用以下命令可以查看 `web` 容器的信息
|
||||
|
||||
```bash
|
||||
$ docker inspect web
|
||||
```
|
||||
|
||||
`数据卷` 信息在 "Mounts" Key 下面
|
||||
|
||||
```json
|
||||
"Mounts": [
|
||||
{
|
||||
"Type": "volume",
|
||||
"Name": "datawhale",
|
||||
"Source": "/var/lib/docker/volumes/datawhale/_data",
|
||||
"Destination": "/usr/share/nginx/html",
|
||||
"Driver": "local",
|
||||
"Mode": "",
|
||||
"RW": true,
|
||||
"Propagation": ""
|
||||
}
|
||||
],
|
||||
```
|
||||
|
||||
### 删除数据卷
|
||||
|
||||
```bash
|
||||
$ docker volume rm datawhale #datawhale为卷名
|
||||
```
|
||||
|
||||
数据卷是被设计用来持久化数据的,它的生命周期独立于容器,Docker 不会在容器被删除后自动删除 `数据卷`,并且也不存在垃圾回收这样的机制来处理没有任何容器引用的 `数据卷`。如果需要在删除容器的同时移除数据卷。可以在删除容器的时候使用 `docker rm -v` 这个命令。
|
||||
|
||||
无主的数据卷可能会占据很多空间,要清理请使用以下命令
|
||||
|
||||
```bash
|
||||
$ docker volume prune
|
||||
```
|
||||
|
||||
## 挂载主机目录
|
||||
|
||||
### 挂载一个主机目录作为数据卷
|
||||
|
||||
使用 `--mount` 标记可以指定挂载一个本地主机的目录到容器中去。
|
||||
|
||||
```bash
|
||||
$ docker run -d -P \
|
||||
--name web \
|
||||
--mount type=bind,source=/src/webapp,target=/usr/share/nginx/html \
|
||||
nginx:alpine
|
||||
```
|
||||
|
||||
上面的命令加载主机的 `/src/webapp` 目录到容器的 `/usr/share/nginx/html`目录。这个功能在进行测试的时候十分方便,比如用户可以放置一些程序到本地目录中,来查看容器是否正常工作。本地目录的路径必须是绝对路径,以前使用 `-v` 参数时如果本地目录不存在 Docker 会自动为你创建一个文件夹,现在使用 `--mount` 参数时如果本地目录不存在,Docker 会报错。
|
||||
|
||||
Docker 挂载主机目录的默认权限是 `读写`,用户也可以通过增加 `readonly` 指定为 `只读`。
|
||||
|
||||
>注意: 如果挂载的目录不存在,创建容器时,docker 不会自动创建,此时会报错
|
||||
|
||||
```bash
|
||||
$ docker run -d -P \
|
||||
--name web \
|
||||
--mount type=bind,source=/src/webapp,target=/usr/share/nginx/html,readonly \
|
||||
nginx:alpine
|
||||
```
|
||||
|
||||
加了 `readonly` 之后,就挂载为 `只读` 了。如果你在容器内 `/usr/share/nginx/html` 目录新建文件,会显示如下错误
|
||||
|
||||
```bash
|
||||
/usr/share/nginx/html # touch new.txt
|
||||
touch: new.txt: Read-only file system
|
||||
```
|
||||
|
||||
### 查看数据卷的具体信息
|
||||
|
||||
在主机里使用以下命令可以查看 `web` 容器的信息
|
||||
|
||||
```bash
|
||||
$ docker inspect web
|
||||
```
|
||||
|
||||
`挂载主机目录` 的配置信息在 "Mounts" Key 下面
|
||||
|
||||
```json
|
||||
"Mounts": [
|
||||
{
|
||||
"Type": "bind",
|
||||
"Source": "/src/webapp",
|
||||
"Destination": "/usr/share/nginx/html",
|
||||
"Mode": "",
|
||||
"RW": true,
|
||||
"Propagation": "rprivate"
|
||||
}
|
||||
],
|
||||
```
|
||||
|
||||
### 挂载一个本地主机文件作为数据卷
|
||||
|
||||
`--mount` 标记也可以从主机挂载单个文件到容器中
|
||||
|
||||
```bash
|
||||
$ docker run --rm -it \
|
||||
--mount type=bind,source=$HOME/.bash_history,target=/root/.bash_history \
|
||||
ubuntu:18.04 \
|
||||
bash
|
||||
```
|
||||
|
|
@ -0,0 +1,783 @@
|
|||
# Chapter 5 Docker 网络
|
||||
|
||||
## 内容大纲
|
||||
|
||||
### Docker 基础网络介绍
|
||||
|
||||
- [外部访问容器](#<span id="jump">外部访问容器</span>)
|
||||
- [容器互联](#<span id="jump">容器互联</span>)
|
||||
- [配置DNS](#<span id="jump">配置DNS</span>)
|
||||
|
||||
### Docker的网络模式
|
||||
|
||||
- [Bridge 模式](#<span id="jump">Bridge模式</span>)
|
||||
- [Host 模式](#<span id="jump">Host 模式</span>)
|
||||
- [None 模式](#<span id="jump">None模式</span>)
|
||||
- [Container 模式](#<span id="jump">Container 模式</span>)
|
||||
|
||||
### Docker高级网络配置
|
||||
|
||||
- [快速配置指南](#<span id="jump">快速配置指南</span>)
|
||||
- [容器访问控制](#<span id="jump">容器访问控制</span>)
|
||||
- [端口映射实现](#<span id="jump">端口映射实现</span>)
|
||||
- [配置docker0网桥](#<span id="jump">配置 docker0 网桥</span>)
|
||||
- [自定义网桥](#<span id="jump">自定义网桥</span>)
|
||||
- [工具和示例](#<span id="jump">工具和示例</span>)
|
||||
- [编辑网络配置文件](#<span id="jump">编辑网络配置文件</span>)
|
||||
- [实例:创建一个点到点连接](#<span id="jump">实例:创建一个点到点连接</span>)
|
||||
|
||||
|
||||
|
||||
# Docker 基础网络介绍
|
||||
|
||||
- [外部访问容器](#<span id="jump">外部访问容器</span>)
|
||||
- [容器互联](#<span id="jump">容器互联</span>)
|
||||
- [配置DNS](#<span id="jump">配置DNS</span>)
|
||||
|
||||
## <span id="jump">外部访问容器</span>
|
||||
|
||||
容器中可以运行一些网络应用,要让外部也可以访问这些应用,可以通过`-P`或`-p`参数来指定端口映射。
|
||||
|
||||
当使用`-P`标记时,`Docker`会随机映射一个端口到内部容器开放的网络端口。
|
||||
使用`docker container ls`可以看到,本地主机的 32768 被映射到了容器的 80 端口。此时访问本机的 32768 端口即可访问容器内 NGINX 默认页面。
|
||||
|
||||
```
|
||||
$ docker run -d -P nginx:alpine
|
||||
|
||||
$ docker container ls -l
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
fae320d08268 nginx:alpine "/docker-entrypoint.…" 24 seconds ago Up 20 seconds 0.0.0.0:32768->80/tcp bold_mcnulty
|
||||
```
|
||||
|
||||
同样的,可以通过`docker logs`命令来查看访问记录。
|
||||
|
||||
```
|
||||
$ docker logs fa
|
||||
172.17.0.1 - - [25/Aug/2020:08:34:04 +0000] "GET / HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0" "-"
|
||||
```
|
||||
|
||||
`-p`则可以指定要映射的端口,并且,在一个指定端口上只可以绑定一个容器。支持的格式有`ip:hostPort:containerPort | ip::containerPort | hostPort:containerPort`.
|
||||
|
||||
### 映射所有接口地址
|
||||
|
||||
使用`hostPort:containerPort`格式本地的 80 端口映射到容器的 80 端口,可以执行
|
||||
|
||||
```
|
||||
$ docker run -d -p 80:80 nginx:alpine
|
||||
```
|
||||
|
||||
此时默认会绑定本地所有接口上的所有地址。
|
||||
|
||||
### 映射到指定地址的指定端口
|
||||
|
||||
可以使用`ip:hostPort:containerPort`格式指定映射使用一个特定地址,比如`localhost`地址127.0.0.1
|
||||
|
||||
```
|
||||
$ docker run -d -p 127.0.0.1:80:80 nginx:alpine
|
||||
```
|
||||
|
||||
### 映射到指定地址的任意端口
|
||||
|
||||
使用`ip::containerPort`绑定`localhost`的任意端口到容器的80端口,本地主机会自动分配一个端口。
|
||||
|
||||
```
|
||||
$ docker run -d -p 127.0.0.1::80 nginx:alpine
|
||||
```
|
||||
|
||||
还可以使用`udp`标记来指定`udp`端口
|
||||
|
||||
```
|
||||
$ docker run -d -p 127.0.0.1:80:80/udp nginx:alpine
|
||||
```
|
||||
|
||||
### 查看映射端口配置
|
||||
|
||||
使用`docker port`来查看当前映射的端口配置,也可以查看到绑定的地址
|
||||
|
||||
```
|
||||
$ docker port fa 80
|
||||
0.0.0.0:32768
|
||||
```
|
||||
|
||||
**注意:**
|
||||
容器有自己的内部网络和 ip 地址(使用`docker inspect`查看,`Docker`还可以有一个可变的网络配置。)
|
||||
`-p`标记可以多次使用来绑定多个端口
|
||||
|
||||
例如
|
||||
|
||||
```
|
||||
$ docker run -d \
|
||||
-p 80:80 \
|
||||
-p 443:443 \
|
||||
nginx:alpine
|
||||
```
|
||||
|
||||
## <span id="jump">容器互联</span>
|
||||
|
||||
如果之前有 `Docker`使用经验,可能已经习惯了使用`--link`参数来使容器互联。
|
||||
随着 `Docker` 网络的完善,强烈建议大家将容器加入自定义的`Docker`网络来连接多个容器,而不是使用 `--link`参数。
|
||||
|
||||
### 新建网络
|
||||
|
||||
下面先创建一个新的 `Docker`网络。
|
||||
|
||||
```
|
||||
$ docker network create -d bridge my-net
|
||||
```
|
||||
|
||||
`-d`参数指定`Docker`网络类型,有`bridge overlay`,其中`overlay`网络类型用于`Swarm mode`,在本小节中你可以忽略它。
|
||||
|
||||
### 连接容器
|
||||
|
||||
运行一个容器并连接到新建的`my-net`网络
|
||||
|
||||
```
|
||||
$ docker run -it --rm --name busybox1 --network my-net busybox sh
|
||||
```
|
||||
|
||||
打开新的终端,再运行一个容器并加入到 `my-net`网络
|
||||
|
||||
```
|
||||
$ docker run -it --rm --name busybox2 --network my-net busybox sh
|
||||
```
|
||||
|
||||
再打开一个新的终端查看容器信息
|
||||
|
||||
```
|
||||
$ docker container ls
|
||||
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
b47060aca56b busybox "sh" 11 minutes ago Up 11 minutes busybox2
|
||||
8720575823ec busybox "sh" 16 minutes ago Up 16 minutes busybox1
|
||||
```
|
||||
|
||||
下面通过 `ping`来证明`busybox1`容器和`busybox2`容器建立了互联关系。
|
||||
在`busybox1`容器输入以下命令
|
||||
|
||||
```
|
||||
/ # ping busybox2
|
||||
PING busybox2 (172.19.0.3): 56 data bytes
|
||||
64 bytes from 172.19.0.3: seq=0 ttl=64 time=0.072 ms
|
||||
64 bytes from 172.19.0.3: seq=1 ttl=64 time=0.118 ms
|
||||
```
|
||||
|
||||
用`ping`来测试连接`busybox2`容器,它会解析成 172.19.0.3。
|
||||
同理在`busybox2`容器执行`ping busybox1`,也会成功连接到。
|
||||
|
||||
```
|
||||
/ # ping busybox1
|
||||
PING busybox1 (172.19.0.2): 56 data bytes
|
||||
64 bytes from 172.19.0.2: seq=0 ttl=64 time=0.064 ms
|
||||
64 bytes from 172.19.0.2: seq=1 ttl=64 time=0.143 ms
|
||||
```
|
||||
|
||||
这样,`busybox1` 容器和 `busybox2` 容器建立了互联关系。
|
||||
|
||||
`Docker Compose`
|
||||
如果你有多个容器之间需要互相连接,推荐使用`Docker`Compose。
|
||||
|
||||
## <span id="jump">配置DNS</span>
|
||||
|
||||
如何自定义配置容器的主机名和 DNS 呢?秘诀就是`Docker`利用虚拟文件来挂载容器的 3个相关配置文件。
|
||||
|
||||
在容器中使用 `mount`命令可以看到挂载信息:
|
||||
|
||||
```
|
||||
$ mount
|
||||
/dev/disk/by-uuid/1fec...ebdf on /etc/hostname type ext4 ...
|
||||
/dev/disk/by-uuid/1fec...ebdf on /etc/hosts type ext4 ...
|
||||
tmpfs on /etc/resolv.conf type tmpfs ...
|
||||
```
|
||||
|
||||
这种机制可以让宿主主机 DNS 信息发生更新后,所有`Docker`容器的 DNS 配置通过 `/etc/resolv.conf`文件立刻得到更新。
|
||||
|
||||
配置全部容器的 DNS ,也可以在 `/etc/docker/daemon.json` 文件中增加以下内容来设置。
|
||||
|
||||
```
|
||||
{
|
||||
"dns" : [
|
||||
"114.114.114.114",
|
||||
"8.8.8.8"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
这样每次启动的容器 DNS 自动配置为 114.114.114.114 和8.8.8.8。使用以下命令来证明其已经生效。
|
||||
|
||||
```
|
||||
$ docker run -it --rm ubuntu:18.04 cat etc/resolv.conf
|
||||
|
||||
nameserver 114.114.114.114
|
||||
nameserver 8.8.8.8
|
||||
```
|
||||
|
||||
如果用户想要手动指定容器的配置,可以在使用`docker run`命令启动容器时加入如下参数:
|
||||
`-h HOSTNAME`或者`--hostname=HOSTNAME`设定容器的主机名,它会被写到容器内的`/etc/hostname 和 /etc/hosts`。但它在容器外部看不到,既不会在`docker container ls`中显示,也不会在其他的容器的`/etc/hosts`看到。
|
||||
|
||||
`--dns=IP_ADDRESS`添加 DNS 服务器到容器的`/etc/resolv.conf`中,让容器用这个服务器来解析所有不在 `/etc/hosts `中的主机名。
|
||||
|
||||
`--dns-search=DOMAIN`设定容器的搜索域,当设定搜索域为`.example.com`时,在搜索一个名为`host`的主机时,DNS 不仅搜索 `host`,还会搜索`host.example.com`。
|
||||
|
||||
**注意:**如果在容器启动时没有指定最后两个参数,`Docker`会默认用主机上的`/etc/resolv.conf`来配置容器。
|
||||
|
||||
# Docker的网络模式
|
||||
|
||||
- [Bridge 模式](#<span id="jump">Bridge模式</span>)
|
||||
- [Host 模式](#<span id="jump">Host 模式</span>)
|
||||
- [None 模式](#<span id="jump">None模式</span>)
|
||||
- [Container 模式](#<span id="jump">Container 模式</span>)
|
||||
|
||||
可以通过`docker network ls`查看网络,默认创建三种网络。
|
||||
|
||||
```
|
||||
[root@localhost ~]# docker network ls
|
||||
NETWORK ID NAME DRIVER SCOPE
|
||||
688d1970f72e bridge bridge local
|
||||
885da101da7d host host local
|
||||
f4f1b3cf1b7f none null local
|
||||
```
|
||||
|
||||
常见网络的含义:
|
||||
|
||||
| 网络模式 | 简介 |
|
||||
| :-------: | :----------------------------------------------------------: |
|
||||
| Bridge | 为每一个容器分配、设置 IP 等,并将容器连接到一个 `docker0` 虚拟网桥,默认为该模式。 |
|
||||
| Host | 容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口。 |
|
||||
| None | 容器有独立的 Network namespace,但并没有对其进行任何网络设置,如分配 veth pair 和网桥连接,IP 等。 |
|
||||
| Container | 新创建的容器不会创建自己的网卡和配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。 |
|
||||
|
||||
## <span id="jump">Bridge模式</span>
|
||||
|
||||
当`Docker`进程启动时,会在主机上创建一个名为`docker0`的虚拟网桥,此主机上启动的`Docker`容器会连接到这个虚拟网桥上,附加在其上的任何网卡之间都能自动转发数据包。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。从`docker0`子网中分配一个 IP 给容器使用,并设置 `docker0 `的 IP 地址为容器的默认网关。在主机上创建一对虚拟网卡`veth pair`设备,`Docker `将 `veth pair` 设备的一端放在新创建的容器中,并命名为`eth0`(容器的网卡),另一端放在主机中,以`vethxxx`这样类似的名字命名,并将这个网络设备加入到 `docker0` 网桥中。可以通过`brctl show`命令查看。
|
||||
|
||||
比如运行一个基于 `busybox` 镜像构建的容器 `bbox01`,查看 `ip addr`:
|
||||
|
||||
> busybox 被称为嵌入式 Linux 的瑞士军刀,整合了很多小的 unix 下的通用功能到一个小的可执行文件中。
|
||||
|
||||
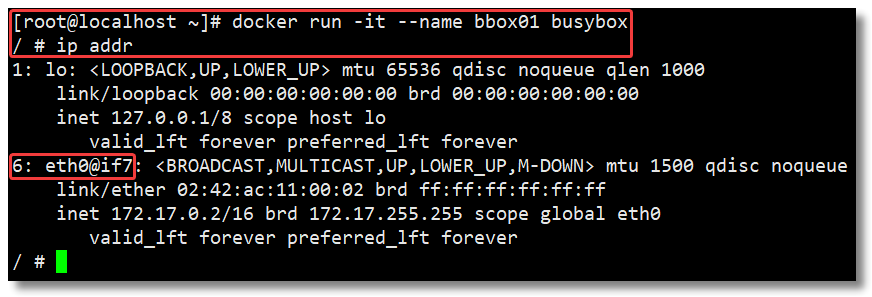
|
||||
|
||||
然后宿主机通过 `ip addr` 查看信息如下:
|
||||
|
||||

|
||||
|
||||
通过以上的比较可以发现,证实了之前所说的:守护进程会创建一对对等虚拟设备接口 `veth pair`,将其中一个接口设置为容器的 `eth0` 接口(容器的网卡),另一个接口放置在宿主机的命名空间中,以类似 `vethxxx` 这样的名字命名。
|
||||
|
||||
同时,守护进程还会从网桥 `docker0` 的私有地址空间中分配一个 IP 地址和子网给该容器,并设置 docker0 的 IP 地址为容器的默认网关。也可以安装 `yum install -y bridge-utils` 以后,通过 `brctl show` 命令查看网桥信息。
|
||||
|
||||

|
||||
|
||||
对于每个容器的 IP 地址和 Gateway 信息,可以通过 `docker inspect 容器名称|ID` 进行查看,在 `NetworkSettings` 节点中可以看到详细信息。
|
||||
|
||||

|
||||
|
||||
可以通过 `docker network inspect bridge` 查看所有 `bridge` 网络模式下的容器,在 `Containers` 节点中可以看到容器名称。
|
||||
|
||||

|
||||
|
||||
> 关于 `bridge` 网络模式的使用,只需要在创建容器时通过参数 `--net bridge` 或者 `--network bridge` 指定即可,当然这也是创建容器默认使用的网络模式,也就是说这个参数是可以省略的。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
bridge模式是 `docker `的默认网络模式,不写`–net`参数,就是bridge模式。使用`docker run -p`时,`docker `实际是在`iptables`做了`DNAT`规则,实现端口转发功能。可以使用`iptables -t nat -vnL`查看。`bridge`模式如下图所示:
|
||||

|
||||
演示:
|
||||
|
||||
```
|
||||
$ docker run -tid --net=bridge --name docker_bri1 \
|
||||
ubuntu-base:v3
|
||||
docker run -tid --net=bridge --name docker_bri2 \
|
||||
ubuntu-base:v3
|
||||
|
||||
$ brctl show
|
||||
$ docker exec -ti docker_bri1 /bin/bash
|
||||
$ ifconfig –a
|
||||
$ route –n
|
||||
```
|
||||
|
||||
|
||||
|
||||
## <span id="jump">Host 模式</span>
|
||||
|
||||
- host 网络模式需要在创建容器时通过参数 `--net host` 或者 `--network host` 指定;
|
||||
- 采用 host 网络模式的 Docker Container,可以直接使用宿主机的 IP 地址与外界进行通信,若宿主机的 eth0 是一个公有 IP,那么容器也拥有这个公有 IP。同时容器内服务的端口也可以使用宿主机的端口,无需额外进行 NAT 转换;
|
||||
- host 网络模式可以让容器共享宿主机网络栈,这样的好处是外部主机与容器直接通信,但是容器的网络缺少隔离性。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
比如基于 `host` 网络模式创建了一个基于 `busybox` 镜像构建的容器 `bbox02`,查看 `ip addr`:
|
||||
|
||||

|
||||
|
||||
然后宿主机通过 `ip addr` 查看信息如下:
|
||||
|
||||

|
||||
|
||||
对,你没有看错,返回信息一模一样,也可以肯定没有截错图,不信接着往下看。可以通过 `docker network inspect host` 查看所有 `host` 网络模式下的容器,在 `Containers` 节点中可以看到容器名称。
|
||||
|
||||

|
||||
|
||||
如果启动容器的时候使用`host`模式,那么这个容器将不会获得一个独立的`Network Namespace`,而是和宿主机共用一个`Network Namespace`。容器将不会虚拟出自己的网卡,配置自己的`IP`等,而是使用宿主机的`IP`和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。 `Host`模式如下图所示:
|
||||

|
||||
演示:
|
||||
|
||||
```
|
||||
$ docker run -tid --net=host --name docker_host1 ubuntu-base:v3
|
||||
$ docker run -tid --net=host --name docker_host2 ubuntu-base:v3
|
||||
|
||||
$ docker exec -ti docker_host1 /bin/bash
|
||||
$ docker exec -ti docker_host1 /bin/bash
|
||||
|
||||
$ ifconfig –a
|
||||
$ route –n
|
||||
```
|
||||
|
||||
## <span id="jump">None模式</span>
|
||||
|
||||
- none 网络模式是指禁用网络功能,只有 lo 接口 local 的简写,代表 127.0.0.1,即 localhost 本地环回接口。在创建容器时通过参数 `--net none` 或者 `--network none` 指定;
|
||||
- none 网络模式即不为 Docker Container 创建任何的网络环境,容器内部就只能使用 loopback 网络设备,不会再有其他的网络资源。可以说 none 模式为 Docke Container 做了极少的网络设定,但是俗话说得好“少即是多”,在没有网络配置的情况下,作为 Docker 开发者,才能在这基础做其他无限多可能的网络定制开发。这也恰巧体现了 Docker 设计理念的开放。
|
||||
|
||||
|
||||
|
||||
比如基于 `none` 网络模式创建了一个基于 `busybox` 镜像构建的容器 `bbox03`,查看 `ip addr`:
|
||||
|
||||

|
||||
|
||||
可以通过 `docker network inspect none` 查看所有 `none` 网络模式下的容器,在 `Containers` 节点中可以看到容器名称。
|
||||
|
||||

|
||||
|
||||
使用`none`模式,`Docker` 容器拥有自己的 `Network Namespace`,但是,并不为`Docker` 容器进行任何网络配置。也就是说,这个 `Docker` 容器没有网卡、IP、路由等信息。需要自己为 `Docker` 容器添加网卡、配置 IP 等。 `None`模式示意图:
|
||||

|
||||
演示:
|
||||
|
||||
```
|
||||
$ docker run -tid --net=none --name \
|
||||
docker_non1 ubuntu-base:v3
|
||||
|
||||
$ docker exec -ti docker_non1 /bin/bash
|
||||
|
||||
$ ifconfig –a
|
||||
$ route -n
|
||||
```
|
||||
|
||||
## <span id="jump">Container 模式</span>
|
||||
|
||||
- Container 网络模式是 Docker 中一种较为特别的网络的模式。在创建容器时通过参数 `--net container:已运行的容器名称|ID` 或者 `--network container:已运行的容器名称|ID` 指定;
|
||||
- 处于这个模式下的 Docker 容器会共享一个网络栈,这样两个容器之间可以使用 localhost 高效快速通信。
|
||||
|
||||

|
||||
|
||||
**Container 网络模式即新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等**。同样两个容器除了网络方面相同之外,其他的如文件系统、进程列表等还是隔离的。
|
||||
|
||||
比如基于容器 `bbox01` 创建了 `container` 网络模式的容器 `bbox04`,查看 `ip addr`:
|
||||
|
||||

|
||||
|
||||
容器 `bbox01` 的 `ip addr` 信息如下:
|
||||
|
||||

|
||||
|
||||
宿主机的 `ip addr` 信息如下:
|
||||
|
||||

|
||||
|
||||
通过以上测试可以发现,Docker 守护进程只创建了一对对等虚拟设备接口用于连接 bbox01 容器和宿主机,而 bbox04 容器则直接使用了 bbox01 容器的网卡信息。
|
||||
|
||||
这个时候如果将 bbox01 容器停止,会发现 bbox04 容器就只剩下 lo 接口了。
|
||||
|
||||

|
||||
|
||||
然后 bbox01 容器重启以后,bbox04 容器也重启一下,就又可以获取到网卡信息了。
|
||||
|
||||

|
||||
|
||||
这个模式指定新创建的容器和已经存在的一个容器共享一个`Network Namespace`,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的`IP`,而是和一个指定的容器共享`IP`、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过lo网卡设备通信。 `Container`模式示意图:
|
||||

|
||||
演示:
|
||||
|
||||
```
|
||||
$ docker run -tid --net=container:docker_bri1 \
|
||||
--name docker_con1 ubuntu-base:v3
|
||||
|
||||
$ docker exec -ti docker_con1 /bin/bash
|
||||
$ docker exec -ti docker_bri1 /bin/bash
|
||||
|
||||
$ ifconfig –a
|
||||
$ route -n
|
||||
```
|
||||
|
||||
|
||||
|
||||
# 高级网络配置
|
||||
|
||||
- [快速配置指南](#<span id="jump">快速配置指南</span>)
|
||||
- [容器访问控制](#<span id="jump">容器访问控制</span>)
|
||||
- [端口映射实现](#<span id="jump">端口映射实现</span>)
|
||||
- [配置docker0网桥](#<span id="jump">配置 docker0 网桥</span>)
|
||||
- [自定义网桥](#<span id="jump">自定义网桥</span>)
|
||||
- [工具和示例](#<span id="jump">工具和示例</span>)
|
||||
- [编辑网络配置文件](#<span id="jump">编辑网络配置文件</span>)
|
||||
- [实例:创建一个点到点连接](#<span id="jump">实例:创建一个点到点连接</span>)
|
||||
|
||||
## <span id="jump">快速配置指南</span>
|
||||
|
||||
下面是一个跟 Docker 网络相关的命令列表。
|
||||
|
||||
其中有些命令选项只有在 Docker 服务启动的时候才能配置,而且不能马上生效。
|
||||
|
||||
- `-b BRIDGE` 或 `--bridge=BRIDGE` 指定容器挂载的网桥
|
||||
- `--bip=CIDR`定制 `docker0` 的掩码
|
||||
- `-H SOCKET...` 或 `--host=SOCKET... Docker` 服务端接收命令的通道
|
||||
- `--icc=true|false` 是否支持容器之间进行通信
|
||||
- `--ip-forward=true|false` 请看下文容器之间的通信
|
||||
- `--iptables=true|false` 是否允许 Docker 添加 `iptables` 规则
|
||||
- `--mtu=BYTES` 容器网络中的 `MTU`
|
||||
|
||||
下面2个命令选项既可以在启动服务时指定,也可以在启动容器时指定。在 Docker服务启动的时候指定则会成为默认值,后面执行 `docker run` 时可以覆盖设置的默认值。
|
||||
|
||||
- `--dns=IP_ADDRESS...` 使用指定的DNS服务器
|
||||
- `--dns-search=DOMAIN...` 指定DNS搜索域
|
||||
|
||||
最后这些选项只有在 `docker run` 执行时使用,因为它是针对容器的特性内容。
|
||||
|
||||
- `-h HOSTNAME` 或 `--hostname=HOSTNAME` 配置容器主机名
|
||||
- `--link=CONTAINER_NAME:ALIAS` 添加到另一个容器的连接
|
||||
- `--net=bridge|none|container:NAME_or_ID|host` 配置容器的桥接模式
|
||||
- `-p SPEC` 或 --publish=SPEC` 映射容器端口到宿主主机
|
||||
- `-P or --publish-all=true|false` 映射容器所有端口到宿主主机
|
||||
|
||||
|
||||
|
||||
|
||||
## <span id="jump">容器访问控制</span>
|
||||
|
||||
容器的访问控制,主要通过 Linux 上的 `iptables` 防火墙来进行管理和实现。`iptables` 是 Linux 上默认的防火墙软件,在大部分发行版中都自带。
|
||||
|
||||
### 容器访问外部网络
|
||||
|
||||
容器要想访问外部网络,需要本地系统的转发支持。在Linux 系统中,检查转发是否打开。
|
||||
|
||||
|
||||
|
||||
```
|
||||
$sysctl net.ipv4.ip_forward
|
||||
net.ipv4.ip_forward = 1
|
||||
```
|
||||
|
||||
如果为 0,说明没有开启转发,则需要手动打开。
|
||||
|
||||
|
||||
|
||||
```
|
||||
$sysctl -w net.ipv4.ip_forward=1
|
||||
```
|
||||
|
||||
如果在启动 Docker 服务的时候设定 `--ip-forward=true`, Docker 就会自动设定系统的 `ip_forward` 参数为 1。
|
||||
|
||||
### 容器之间访问
|
||||
|
||||
容器之间相互访问,需要两方面的支持。
|
||||
|
||||
- 容器的网络拓扑是否已经互联。默认情况下,所有容器都会被连接到 `docker0` 网桥上。
|
||||
- 本地系统的防火墙软件 `-- iptables` 是否允许通过。
|
||||
|
||||
### 访问所有端口
|
||||
|
||||
当启动 Docker 服务(即 dockerd)的时候,默认会添加一条转发策略到本地主机 iptables 的 FORWARD 链上。策略为通过(`ACCEPT`)还是禁止(`DROP`)取决于配置`--icc=true`(缺省值)还是 `--icc=false`。当然,如果手动指定 `--iptables=false` 则不会添加 `iptables` 规则。
|
||||
|
||||
可见,默认情况下,不同容器之间是允许网络互通的。如果为了安全考虑,可以在 `/etc/docker/daemon.json` 文件中配置 `{"icc": false}` 来禁止它。
|
||||
|
||||
### 访问指定端口
|
||||
|
||||
在通过 `-icc=false` 关闭网络访问后,还可以通过 `--link=CONTAINER_NAME:ALIAS` 选项来访问容器的开放端口。
|
||||
|
||||
例如,在启动 Docker 服务时,可以同时使用 `icc=false --iptables=true` 参数来关闭允许相互的网络访问,并让 Docker 可以修改系统中的 `iptables` 规则。
|
||||
|
||||
此时,系统中的 `iptables` 规则可能是类似
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ sudo iptables -nL
|
||||
...
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
DROP all -- 0.0.0.0/0 0.0.0.0/0
|
||||
...
|
||||
```
|
||||
|
||||
之后,启动容器(`docker run`)时使用 `--link=CONTAINER_NAME:ALIAS` 选项。Docker 会在 `iptable` 中为 两个容器分别添加一条 `ACCEPT` 规则,允许相互访问开放的端口(取决于 `Dockerfile` 中的 `EXPOSE` 指令)。
|
||||
|
||||
当添加了 `--link=CONTAINER_NAME:ALIAS` 选项后,添加了 `iptables` 规则。
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ sudo iptables -nL
|
||||
...
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
ACCEPT tcp -- 172.17.0.2 172.17.0.3 tcp spt:80
|
||||
ACCEPT tcp -- 172.17.0.3 172.17.0.2 tcp dpt:80
|
||||
DROP all -- 0.0.0.0/0 0.0.0.0/0
|
||||
```
|
||||
|
||||
**注意**:`--link=CONTAINER_NAME:ALIAS` 中的 `CONTAINER_NAME` 目前必须是 Docker 分配的名字,或使用 `--name` 参数指定的名字。主机名则不会被识别。
|
||||
|
||||
|
||||
|
||||
## <span id="jump">端口映射实现</span>
|
||||
|
||||
默认情况下,容器可以主动访问到外部网络的连接,但是外部网络无法访问到容器。
|
||||
|
||||
### 容器访问外部实现
|
||||
|
||||
容器所有到外部网络的连接,源地址都会被 NAT 成本地系统的 IP 地址。这是使用 `iptables` 的源地址伪装操作实现的。
|
||||
|
||||
查看主机的 NAT 规则。
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ sudo iptables -t nat -nL
|
||||
...
|
||||
Chain POSTROUTING (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
MASQUERADE all -- 172.17.0.0/16 !172.17.0.0/16
|
||||
...
|
||||
```
|
||||
|
||||
其中,上述规则将所有源地址在 `172.17.0.0/16` 网段,目标地址为其他网段(外部网络)的流量动态伪装为从系统网卡发出。MASQUERADE 跟传统 SNAT 的好处是它能动态从网卡获取地址。
|
||||
|
||||
### 外部访问容器实现
|
||||
|
||||
容器允许外部访问,可以在 `docker run` 时候通过 `-p` 或 `-P` 参数来启用。
|
||||
|
||||
不管用那种办法,其实也是在本地的 `iptable` 的 nat 表中添加相应的规则。
|
||||
|
||||
使用 `-P` 时:
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ iptables -t nat -nL
|
||||
...
|
||||
Chain DOCKER (2 references)
|
||||
target prot opt source destination
|
||||
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:49153 to:172.17.0.2:80
|
||||
```
|
||||
|
||||
使用 `-p 80:80` 时:
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ iptables -t nat -nL
|
||||
Chain DOCKER (2 references)
|
||||
target prot opt source destination
|
||||
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80 to:172.17.0.2:80
|
||||
```
|
||||
|
||||
**注意**:
|
||||
|
||||
- 这里的规则映射了 `0.0.0.0`,意味着将接受主机来自所有接口的流量。用户可以通过 `-p IP:host_port:container_port` 或 `-p IP::port` 来指定允许访问容器的主机上的 IP、接口等,以制定更严格的规则。
|
||||
- 如果希望永久绑定到某个固定的 IP 地址,可以在 Docker 配置文件 `/etc/docker/daemon.json` 中添加如下内容。
|
||||
|
||||
|
||||
|
||||
```
|
||||
{
|
||||
"ip": "0.0.0.0"
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## <span id="jump">配置 docker0 网桥</span>
|
||||
|
||||
Docker 服务默认会创建一个 `docker0` 网桥(其上有一个 `docker0` 内部接口),它在内核层连通了其他的物理或虚拟网卡,这就将所有容器和本地主机都放到同一个物理网络。
|
||||
|
||||
Docker 默认指定了 `docker0` 接口 的 IP 地址和子网掩码,让主机和容器之间可以通过网桥相互通信,它还给出了 MTU(接口允许接收的最大传输单元),通常是 1500 Bytes,或宿主主机网络路由上支持的默认值。这些值都可以在服务启动的时候进行配置。
|
||||
|
||||
- `--bip=CIDR` IP 地址加掩码格式,例如 192.168.1.5/24
|
||||
- `--mtu=BYTES` 覆盖默认的 Docker mtu 配置
|
||||
|
||||
也可以在配置文件中配置 DOCKER_OPTS,然后重启服务。
|
||||
|
||||
由于目前 Docker 网桥是 Linux 网桥,用户可以使用 `brctl show` 来查看网桥和端口连接信息。
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ sudo brctl show
|
||||
bridge name bridge id STP enabled interfaces
|
||||
docker0 8000.3a1d7362b4ee no veth65f9
|
||||
vethdda6
|
||||
```
|
||||
|
||||
**注**:`brctl` 命令在 Debian、Ubuntu 中可以使用 `sudo apt-get install bridge-utils` 来安装。
|
||||
|
||||
每次创建一个新容器的时候,Docker 从可用的地址段中选择一个空闲的 IP 地址分配给容器的 eth0 端口。使用本地主机上 `docker0` 接口的 IP 作为所有容器的默认网关。
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ sudo docker run -i -t --rm base /bin/bash
|
||||
$ ip addr show eth0
|
||||
24: eth0: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 32:6f:e0:35:57:91 brd ff:ff:ff:ff:ff:ff
|
||||
inet 172.17.0.3/16 scope global eth0
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::306f:e0ff:fe35:5791/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
$ ip route
|
||||
default via 172.17.42.1 dev eth0
|
||||
172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.3
|
||||
```
|
||||
|
||||
|
||||
|
||||
## <span id="jump">自定义网桥</span>
|
||||
|
||||
除了默认的 `docker0` 网桥,用户也可以指定网桥来连接各个容器。
|
||||
|
||||
在启动 Docker 服务的时候,使用 `-b BRIDGE`或`--bridge=BRIDGE` 来指定使用的网桥。
|
||||
|
||||
如果服务已经运行,那需要先停止服务,并删除旧的网桥。
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ sudo systemctl stop docker
|
||||
$ sudo ip link set dev docker0 down
|
||||
$ sudo brctl delbr docker0
|
||||
```
|
||||
|
||||
然后创建一个网桥 `bridge0`。
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ sudo brctl addbr bridge0
|
||||
$ sudo ip addr add 192.168.5.1/24 dev bridge0
|
||||
$ sudo ip link set dev bridge0 up
|
||||
```
|
||||
|
||||
查看确认网桥创建并启动。
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ ip addr show bridge0
|
||||
4: bridge0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state UP group default
|
||||
link/ether 66:38:d0:0d:76:18 brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.5.1/24 scope global bridge0
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
在 Docker 配置文件 `/etc/docker/daemon.json` 中添加如下内容,即可将 Docker 默认桥接到创建的网桥上。
|
||||
|
||||
|
||||
|
||||
```
|
||||
{
|
||||
"bridge": "bridge0",
|
||||
}
|
||||
```
|
||||
|
||||
启动 Docker 服务。
|
||||
|
||||
新建一个容器,可以看到它已经桥接到了 `bridge0` 上。
|
||||
|
||||
可以继续用 `brctl show` 命令查看桥接的信息。另外,在容器中可以使用 `ip addr` 和 `ip route` 命令来查看 IP 地址配置和路由信息。
|
||||
|
||||
|
||||
|
||||
## <span id="jump">工具和示例</span>
|
||||
|
||||
在介绍自定义网络拓扑之前,你可能会对一些外部工具和例子感兴趣:
|
||||
|
||||
### **pipework**
|
||||
|
||||
Jérôme Petazzoni 编写了一个叫 [pipework](https://github.com/jpetazzo/pipework) 的 shell 脚本,可以帮助用户在比较复杂的场景中完成容器的连接。
|
||||
|
||||
### **playground**
|
||||
|
||||
Brandon Rhodes 创建了一个提供完整的 Docker 容器网络拓扑管理的 [Python库](https://github.com/brandon-rhodes/fopnp/tree/m/playground),包括路由、NAT 防火墙;以及一些提供 `HTTP` `SMTP` `POP` `IMAP` `Telnet` `SSH` `FTP` 的服务器。
|
||||
|
||||
|
||||
|
||||
## <span id="jump">编辑网络配置文件</span>
|
||||
|
||||
Docker 1.2.0 开始支持在运行中的容器里编辑 `/etc/hosts`, `/etc/hostname` 和 `/etc/resolv.conf` 文件。
|
||||
|
||||
但是这些修改是临时的,只在运行的容器中保留,容器终止或重启后并不会被保存下来,也不会被 `docker commit` 提交。
|
||||
|
||||
|
||||
|
||||
## <span id="jump">实例:创建一个点到点连接</span>
|
||||
|
||||
默认情况下,Docker 会将所有容器连接到由 `docker0` 提供的虚拟子网中。
|
||||
|
||||
用户有时候需要两个容器之间可以直连通信,而不用通过主机网桥进行桥接。
|
||||
|
||||
解决办法很简单:创建一对 `peer` 接口,分别放到两个容器中,配置成点到点链路类型即可。
|
||||
|
||||
首先启动 2 个容器:
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ docker run -i -t --rm --net=none base /bin/bash
|
||||
root@1f1f4c1f931a:/#
|
||||
$ docker run -i -t --rm --net=none base /bin/bash
|
||||
root@12e343489d2f:/#
|
||||
```
|
||||
|
||||
找到进程号,然后创建网络命名空间的跟踪文件。
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ docker inspect -f '{{.State.Pid}}' 1f1f4c1f931a
|
||||
2989
|
||||
$ docker inspect -f '{{.State.Pid}}' 12e343489d2f
|
||||
3004
|
||||
$ sudo mkdir -p /var/run/netns
|
||||
$ sudo ln -s /proc/2989/ns/net /var/run/netns/2989
|
||||
$ sudo ln -s /proc/3004/ns/net /var/run/netns/3004
|
||||
```
|
||||
|
||||
创建一对 `peer` 接口,然后配置路由
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ sudo ip link add A type veth peer name B
|
||||
|
||||
$ sudo ip link set A netns 2989
|
||||
$ sudo ip netns exec 2989 ip addr add 10.1.1.1/32 dev A
|
||||
$ sudo ip netns exec 2989 ip link set A up
|
||||
$ sudo ip netns exec 2989 ip route add 10.1.1.2/32 dev A
|
||||
|
||||
$ sudo ip link set B netns 3004
|
||||
$ sudo ip netns exec 3004 ip addr add 10.1.1.2/32 dev B
|
||||
$ sudo ip netns exec 3004 ip link set B up
|
||||
$ sudo ip netns exec 3004 ip route add 10.1.1.1/32 dev B
|
||||
```
|
||||
|
||||
现在这 2 个容器就可以相互 ping 通,并成功建立连接。点到点链路不需要子网和子网掩码。
|
||||
|
||||
此外,也可以不指定 `--net=none` 来创建点到点链路。这样容器还可以通过原先的网络来通信。
|
||||
|
||||
利用类似的办法,可以创建一个只跟主机通信的容器。但是一般情况下,更推荐使用 `--icc=false` 来关闭容器之间的通信。
|
||||
|
||||
### 参考文献
|
||||
|
||||
- Docker 网络模式详解及容器间网络通信:https://juejin.cn/post/6868086876751085581
|
||||
- Docker从基础到入门:https://yeasy.gitbook.io/docker_practice/advanced_network
|
||||
- Docker网络模式:https://www.qikqiak.com/k8s-book/docs/7.Docker%E7%9A%84%E7%BD%91%E7%BB%9C%E6%A8%A1%E5%BC%8F.html
|
||||
|
|
@ -0,0 +1,605 @@
|
|||
# Chapter 6 Docker Compose
|
||||
|
||||
相信大家学完之前的内容已经对docker的操作很熟悉了,但是有没有一种感觉,如果我一个项目要起好多个容器,每个容器之间又相互之间有一些关联,有些情况下又要修改一些容器,这种情况写起来会特别的麻烦,那么有没有一种方式能让我把项目快速的启动起来呢?
|
||||
|
||||
答案肯定是有的,接下来就让我们学习一下docker compose。
|
||||
|
||||
关于docker compose的安装请移步[docker compose安装与卸载](https://vuepress.mirror.docker-practice.com/compose/install/)或根据[docker官网](https://docs.docker.com/compose/install/)进行安装。
|
||||
|
||||
> 对于docker compose的学习推荐大家多看看一些项目的docker-compose.yml文件是怎么写的,慢慢模仿着去写很多就越来越熟练清晰了。在[Compose文件夹](https://github.com/datawhalechina/team-learning-program/tree/master/Docker/Compose)下也在网上收集了一些docker-compose.yml文件,欢迎大家一起来补充。
|
||||
|
||||
## 内容大纲
|
||||
|
||||
- 什么是docker compose
|
||||
- 如何使用docker compose
|
||||
- docker compose基本使用
|
||||
- 启动服务
|
||||
- 查看服务状态
|
||||
- 停止或删除服务
|
||||
- 进入服务
|
||||
- 查看服务输出日志
|
||||
- Compose模板文件
|
||||
- Compose命令
|
||||
|
||||
## 什么是docker compose
|
||||
|
||||
通过之前的介绍,我们知道使用一个 `Dockerfile` 模板文件,可以让用户很方便的定义一个单独的应用容器。然而,在日常工作中,经常会碰到需要多个容器相互配合来完成某项任务的情况。例如要实现一个 Web 项目,除了 Web 服务容器本身,往往还需要再加上后端的数据库服务容器,甚至还包括负载均衡容器等。
|
||||
|
||||
`Compose`恰好满足了这样的需求。它允许用户通过一个单独的 `docker-compose.yml` 模板文件(YAML 格式)来定义一组相关联的应用容器为一个项目(project)。不理解没关系,我们先看下面这样一个文件:
|
||||
|
||||

|
||||
|
||||
通过这个例子我们可以发现,这个文件里面我们好像看见了image、ports、networks这些,那么这些标签与之前docker run时候的一些指令是不是有一些关系呢?接下来就让我们继续学习。
|
||||
|
||||
## 如何使用docker compose
|
||||
|
||||
在`Compose` 中有两个重要的概念:
|
||||
|
||||
- 服务 (`service`):一个应用的容器,实际上可以包括若干运行相同镜像的容器实例。
|
||||
- 项目 (`project`):由一组关联的应用容器组成的一个完整业务单元,在 `docker-compose.yml` 文件中定义。
|
||||
|
||||
`Compose`的默认管理对象是项目,也就是通过docker-compose.yml定义的一组服务集合,通过一些命令来对项目中的一组容器进行便捷地生命周期管理。
|
||||
|
||||
下面我们来看一个真实的场景,在该场景下我们是通过Python来写一个能够记录页面访问次数的 web 网站。完整代码:[计数器](./Compose/计数器)
|
||||
|
||||
### web 应用
|
||||
|
||||
新建文件夹,在该目录中编写 `app.py` 文件
|
||||
|
||||
```python
|
||||
from flask import Flask
|
||||
from redis import Redis
|
||||
import os
|
||||
import socket
|
||||
|
||||
app = Flask(__name__)
|
||||
redis = Redis(host=os.environ.get('REDIS_HOST', '127.0.0.1'), port=6379)
|
||||
|
||||
|
||||
@app.route('/')
|
||||
def hello():
|
||||
redis.incr('hits')
|
||||
return 'Hello Container World! I have been seen %s times and my hostname is %s.\n' % (redis.get('hits'),socket.gethostname())
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
app.run(host="0.0.0.0", port=5000, debug=True)
|
||||
```
|
||||
|
||||
### Dockerfile
|
||||
|
||||
编写 `Dockerfile` 文件,内容为
|
||||
|
||||
```docker
|
||||
FROM python:2.7
|
||||
COPY . /app
|
||||
WORKDIR /app
|
||||
RUN pip install flask redis
|
||||
EXPOSE 5000
|
||||
CMD [ "python", "app.py" ]
|
||||
```
|
||||
|
||||
### docker-compose.yml
|
||||
|
||||
编写 `docker-compose.yml` 文件,这个是 Compose 使用的主模板文件。
|
||||
|
||||
```yaml
|
||||
version: "3"
|
||||
|
||||
services:
|
||||
|
||||
redis:
|
||||
image: redis
|
||||
|
||||
web:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile
|
||||
environment:
|
||||
REDIS_HOST: redis
|
||||
```
|
||||
|
||||
### 运行 compose 项目
|
||||
|
||||
```bash
|
||||
$ docker-compose up -d
|
||||
```
|
||||
|
||||
此时访问本地 `5000` 端口,每次刷新页面,计数就会加 1。
|
||||
|
||||
## docker compose基本使用
|
||||
|
||||
### 启动服务
|
||||
|
||||
在创建好`docker-compose.yml`文件后,可以通过下面这个命令将文件中定义的容器都启动起来,在docker compose中我们更习惯于将每一个容器叫做service。
|
||||
|
||||
```
|
||||
docker-compose up
|
||||
```
|
||||
|
||||
命令后会自动接一个默认值`-f docker-compose.yml`,也就是默认是使用docker-compose.yml文件的。我们也可以给文件起名为`docke-test.yml`,这样在使用时指定文件名,但是为了符合规范,还是统一为`docker-compose.yml`。
|
||||
|
||||
```
|
||||
docker-compose up -f docer-test.yml
|
||||
```
|
||||
|
||||
**但是直接通过这种方式的话会直接将启动时的输出打印到终端,所以我们常会加上`-d`参数。**
|
||||
|
||||
```bash
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
### 查看服务状态
|
||||
|
||||
接下来可以查看一下我们创建的service状态
|
||||
|
||||
```
|
||||
docker-compose ps
|
||||
```
|
||||
|
||||
要是想要查看所有service的状态可以使用-a参数:
|
||||
|
||||
```
|
||||
docker-compose ps -a
|
||||
```
|
||||
|
||||
### 停止或删除服务
|
||||
|
||||
如何停止已经运行的services呢,可以使用以下两个命令
|
||||
|
||||
```
|
||||
docker-compose stop
|
||||
docker-compose down
|
||||
```
|
||||
|
||||
其中stop是直接停止services,而down则会停止并删除创建的service,volume和network。
|
||||
|
||||
### 进入服务
|
||||
|
||||
有些情况下我们还需要进入容器来执行一些命令,可以通过如下方式进入容器
|
||||
|
||||
```
|
||||
docker-compose exec mysql bash
|
||||
```
|
||||
|
||||
exec后面接的就是我们要进入具体的service的名字,名字后面就是我们要执行的命令。
|
||||
|
||||
### 查看服务输出日志
|
||||
|
||||
有些情况下一些服务可能无法正常启动,这时可以使用命令查看日志并定位发生错误的原因
|
||||
|
||||
```
|
||||
docker-compose logs
|
||||
```
|
||||
|
||||
以上的一些操作就能满足你在大多数情况下的场景了,但是对于一些我们个人的应用还需要详细的编写dock er-compose.yml文件才行,下面我们就更详细的学习一下。
|
||||
|
||||
## Compose模板文件
|
||||
|
||||
模板文件是使用 `Compose` 的核心,涉及到的指令关键字也比较多。但大家不用担心,这里面大部分指令跟 `docker run` 相关参数的含义都是类似的。
|
||||
|
||||
*注:这里仅介绍一些较为常用的指令,更多指令请见:[Compose模板文件](https://vuepress.mirror.docker-practice.com/compose/compose_file/#cap-add-cap-drop)*
|
||||
|
||||
默认的模板文件名称为 `docker-compose.yml`,格式为 YAML 格式。
|
||||
|
||||
```yaml
|
||||
version: "3"
|
||||
|
||||
services:
|
||||
webapp:
|
||||
image: examples/web
|
||||
ports:
|
||||
- "80:80"
|
||||
volumes:
|
||||
- "/data"
|
||||
```
|
||||
|
||||
注意每个服务都必须通过 `image` 指令指定镜像或 `build` 指令(需要 Dockerfile)等来自动构建生成镜像。
|
||||
|
||||
如果使用 `build` 指令,在 `Dockerfile` 中设置的选项(例如:`CMD`, `EXPOSE`, `VOLUME`, `ENV` 等) 将会自动被获取,无需在 `docker-compose.yml` 中重复设置。
|
||||
|
||||
下面分别介绍各个指令的用法。
|
||||
|
||||
### build
|
||||
|
||||
指定 `Dockerfile` 所在文件夹的路径(可以是绝对路径,或者相对 docker-compose.yml 文件的路径)。 `Compose` 将会利用它自动构建这个镜像,然后使用这个镜像。
|
||||
|
||||
```yaml
|
||||
version: '3'
|
||||
services:
|
||||
|
||||
webapp:
|
||||
build: ./dir
|
||||
```
|
||||
|
||||
你也可以使用 `context` 指令指定 `Dockerfile` 所在文件夹的路径。使用 `dockerfile` 指令指定 `Dockerfile` 文件名。使用 `arg` 指令指定构建镜像时的变量。
|
||||
|
||||
```yaml
|
||||
version: '3'
|
||||
services:
|
||||
|
||||
webapp:
|
||||
build:
|
||||
context: ./dir
|
||||
dockerfile: Dockerfile-alternate
|
||||
args:
|
||||
buildno: 1
|
||||
```
|
||||
|
||||
使用 `cache_from` 指定构建镜像的缓存。
|
||||
|
||||
```yaml
|
||||
build:
|
||||
context: .
|
||||
cache_from:
|
||||
- alpine:latest
|
||||
- corp/web_app:3.14
|
||||
```
|
||||
|
||||
### depends_on
|
||||
|
||||
解决容器的依赖、启动先后的问题。以下例子中会先启动 `redis` `db` 再启动 `web`
|
||||
|
||||
```yaml
|
||||
version: '3'
|
||||
|
||||
services:
|
||||
web:
|
||||
build: .
|
||||
depends_on:
|
||||
- db
|
||||
- redis
|
||||
|
||||
redis:
|
||||
image: redis
|
||||
|
||||
db:
|
||||
image: postgres
|
||||
```
|
||||
|
||||
> 注意:`web` 服务不会等待 `redis` `db` 「完全启动」之后才启动。这里需要注意,如果redis启动失败,那么web依然会正常启动。
|
||||
|
||||
### environment
|
||||
|
||||
设置环境变量。你可以使用数组或字典两种格式。只给定名称的变量会自动获取运行 Compose 主机上对应变量的值,可以用来防止泄露不必要的数据。
|
||||
|
||||
```yaml
|
||||
environment:
|
||||
RACK_ENV: development
|
||||
SESSION_SECRET:
|
||||
|
||||
environment:
|
||||
- RACK_ENV=development
|
||||
- SESSION_SECRET
|
||||
```
|
||||
|
||||
如果变量名称或者值中用到 `true|false,yes|no` 等表达 [布尔 (opens new window)](https://yaml.org/type/bool.html)含义的词汇,最好放到引号里,避免 YAML 自动解析某些内容为对应的布尔语义。这些特定词汇,包括
|
||||
|
||||
```bash
|
||||
y|Y|yes|Yes|YES|n|N|no|No|NO|true|True|TRUE|false|False|FALSE|on|On|ON|off|Off|OFF
|
||||
```
|
||||
|
||||
### expose
|
||||
|
||||
暴露端口,但不映射到宿主机,只被连接的服务访问。仅可以指定内部端口为参数
|
||||
|
||||
```yaml
|
||||
expose:
|
||||
- "3000"
|
||||
- "8000"
|
||||
```
|
||||
|
||||
### ports
|
||||
|
||||
暴露端口信息。使用宿主端口:容器端口 `(HOST:CONTAINER)` 格式,或者仅仅指定容器的端口(宿主将会随机选择端口)都可以。
|
||||
|
||||
```yaml
|
||||
ports:
|
||||
- "3000"
|
||||
- "8000:8000"
|
||||
- "49100:22"
|
||||
- "127.0.0.1:8001:8001"
|
||||
```
|
||||
|
||||
*注意:当使用 `HOST:CONTAINER` 格式来映射端口时,如果你使用的容器端口小于 60 并且没放到引号里,可能会得到错误结果,因为 `YAML` 会自动解析 `xx:yy` 这种数字格式为 60 进制。为避免出现这种问题,建议数字串都采用引号包括起来的字符串格式。*
|
||||
|
||||
### secrets
|
||||
|
||||
存储敏感数据,例如 `mysql` 服务密码。
|
||||
|
||||
```yaml
|
||||
version: "3.1"
|
||||
services:
|
||||
|
||||
mysql:
|
||||
image: mysql
|
||||
environment:
|
||||
MYSQL_ROOT_PASSWORD_FILE: /run/secrets/db_root_password
|
||||
secrets:
|
||||
- db_root_password
|
||||
- my_other_secret
|
||||
|
||||
secrets:
|
||||
my_secret:
|
||||
file: ./my_secret.txt
|
||||
my_other_secret:
|
||||
external: true
|
||||
```
|
||||
|
||||
### image
|
||||
|
||||
指定为镜像名称或镜像 ID。如果镜像在本地不存在,`Compose` 将会尝试拉取这个镜像。
|
||||
|
||||
```yaml
|
||||
image: ubuntu
|
||||
image: orchardup/postgresql
|
||||
image: a4bc65fd
|
||||
```
|
||||
|
||||
### labels
|
||||
|
||||
为容器添加 Docker 元数据(metadata)信息。例如可以为容器添加辅助说明信息。
|
||||
|
||||
```yaml
|
||||
labels:
|
||||
com.startupteam.description: "webapp for a startup team"
|
||||
com.startupteam.department: "devops department"
|
||||
com.startupteam.release: "rc3 for v1.0"
|
||||
```
|
||||
|
||||
### network_mode
|
||||
|
||||
设置网络模式。使用和 `docker run` 的 `--network` 参数一样的值。
|
||||
|
||||
```yaml
|
||||
network_mode: "bridge"
|
||||
network_mode: "host"
|
||||
network_mode: "none"
|
||||
network_mode: "service:[service name]"
|
||||
network_mode: "container:[container name/id]"
|
||||
```
|
||||
|
||||
### networks
|
||||
|
||||
配置容器连接的网络。
|
||||
|
||||
```yaml
|
||||
version: "3"
|
||||
services:
|
||||
|
||||
some-service:
|
||||
networks:
|
||||
- some-network
|
||||
- other-network
|
||||
|
||||
networks:
|
||||
some-network:
|
||||
other-network:
|
||||
```
|
||||
|
||||
### volumes
|
||||
|
||||
数据卷所挂载路径设置。可以设置为宿主机路径(`HOST:CONTAINER`)或者数据卷名称(`VOLUME:CONTAINER`),并且可以设置访问模式 (`HOST:CONTAINER:ro`)。该指令中路径支持相对路径。
|
||||
|
||||
```yaml
|
||||
volumes:
|
||||
- /var/lib/mysql
|
||||
- cache/:/tmp/cache
|
||||
- ~/configs:/etc/configs/:ro
|
||||
```
|
||||
|
||||
如果路径为数据卷名称,必须在文件中配置数据卷。
|
||||
|
||||
```yaml
|
||||
version: "3"
|
||||
|
||||
services:
|
||||
my_src:
|
||||
image: mysql:8.0
|
||||
volumes:
|
||||
- mysql_data:/var/lib/mysql
|
||||
|
||||
volumes:
|
||||
mysql_data:
|
||||
```
|
||||
|
||||
## Compose命令
|
||||
|
||||
之前我们已经介绍了一些命令,已经能够满足一些基本的日常使用了,下面我们再了解一些其他命令。
|
||||
|
||||
### 命令对象与格式
|
||||
|
||||
对于 Compose 来说,大部分命令的对象既可以是项目本身,也可以指定为项目中的服务或者容器。如果没有特别的说明,命令对象将是项目,这意味着项目中所有的服务都会受到命令影响。
|
||||
|
||||
执行 `docker-compose [COMMAND] --help` 或者 `docker-compose help [COMMAND]` 可以查看具体某个命令的使用格式。
|
||||
|
||||
`docker-compose` 命令的基本的使用格式是
|
||||
|
||||
```bash
|
||||
docker-compose [-f=<arg>...] [options] [COMMAND] [ARGS...]
|
||||
```
|
||||
|
||||
### 命令选项命令选项
|
||||
|
||||
- `-f, --file FILE` 指定使用的 Compose 模板文件,默认为 `docker-compose.yml`,可以多次指定。
|
||||
- `-p, --project-name NAME` 指定项目名称,默认将使用所在目录名称作为项目名。
|
||||
- `--verbose` 输出更多调试信息。
|
||||
- `-v, --version` 打印版本并退出。
|
||||
|
||||
### build
|
||||
|
||||
格式为 `docker-compose build [options] [SERVICE...]`。
|
||||
|
||||
构建(重新构建)项目中的服务容器。
|
||||
|
||||
服务容器一旦构建后,将会带上一个标记名,例如对于 web 项目中的一个 db 容器,可能是 web_db。
|
||||
|
||||
可以随时在项目目录下运行 `docker-compose build` 来重新构建服务。
|
||||
|
||||
选项包括:
|
||||
|
||||
- `--force-rm` 删除构建过程中的临时容器。
|
||||
- `--no-cache` 构建镜像过程中不使用 cache(这将加长构建过程)。
|
||||
- `--pull` 始终尝试通过 pull 来获取更新版本的镜像。
|
||||
|
||||
### config
|
||||
|
||||
验证 Compose 文件格式是否正确,若正确则显示配置,若格式错误显示错误原因。
|
||||
|
||||
### down
|
||||
|
||||
此命令将会停止 `up` 命令所启动的容器,并移除网络
|
||||
|
||||
### exec
|
||||
|
||||
进入指定的容器。
|
||||
|
||||
### help
|
||||
|
||||
获得一个命令的帮助。
|
||||
|
||||
### images
|
||||
|
||||
列出 Compose 文件中包含的镜像。
|
||||
|
||||
### kill
|
||||
|
||||
格式为 `docker-compose kill [options] [SERVICE...]`。
|
||||
|
||||
通过发送 `SIGKILL` 信号来强制停止服务容器。
|
||||
|
||||
支持通过 `-s` 参数来指定发送的信号,例如通过如下指令发送 `SIGINT` 信号。
|
||||
|
||||
```bash
|
||||
$ docker-compose kill -s SIGINT
|
||||
```
|
||||
|
||||
### logs
|
||||
|
||||
格式为 `docker-compose logs [options] [SERVICE...]`。
|
||||
|
||||
查看服务容器的输出。默认情况下,docker-compose 将对不同的服务输出使用不同的颜色来区分。可以通过 `--no-color` 来关闭颜色。
|
||||
|
||||
该命令在调试问题的时候十分有用。
|
||||
|
||||
### pause
|
||||
|
||||
格式为 `docker-compose pause [SERVICE...]`。
|
||||
|
||||
暂停一个服务容器。
|
||||
|
||||
### port
|
||||
|
||||
格式为 `docker-compose port [options] SERVICE PRIVATE_PORT`。
|
||||
|
||||
打印某个容器端口所映射的公共端口。
|
||||
|
||||
选项:
|
||||
|
||||
- `--protocol=proto` 指定端口协议,tcp(默认值)或者 udp。
|
||||
- `--index=index` 如果同一服务存在多个容器,指定命令对象容器的序号(默认为 1)。
|
||||
|
||||
### ps
|
||||
|
||||
格式为 `docker-compose ps [options] [SERVICE...]`。
|
||||
|
||||
列出项目中目前的所有容器。
|
||||
|
||||
选项:
|
||||
|
||||
- `-q` 只打印容器的 ID 信息。
|
||||
|
||||
### pull
|
||||
|
||||
格式为 `docker-compose pull [options] [SERVICE...]`。
|
||||
|
||||
拉取服务依赖的镜像。
|
||||
|
||||
选项:
|
||||
|
||||
- `--ignore-pull-failures` 忽略拉取镜像过程中的错误。
|
||||
|
||||
### push
|
||||
|
||||
推送服务依赖的镜像到 Docker 镜像仓库。
|
||||
|
||||
### restart
|
||||
|
||||
格式为 `docker-compose restart [options] [SERVICE...]`。
|
||||
|
||||
重启项目中的服务。
|
||||
|
||||
选项:
|
||||
|
||||
- `-t, --timeout TIMEOUT` 指定重启前停止容器的超时(默认为 10 秒)。
|
||||
|
||||
### rm
|
||||
|
||||
格式为 `docker-compose rm [options] [SERVICE...]`。
|
||||
|
||||
删除所有(停止状态的)服务容器。推荐先执行 `docker-compose stop` 命令来停止容器。
|
||||
|
||||
选项:
|
||||
|
||||
- `-f, --force` 强制直接删除,包括非停止状态的容器。一般尽量不要使用该选项。
|
||||
- `-v` 删除容器所挂载的数据卷。
|
||||
|
||||
### start
|
||||
|
||||
格式为 `docker-compose start [SERVICE...]`。
|
||||
|
||||
启动已经存在的服务容器。
|
||||
|
||||
### stop
|
||||
|
||||
格式为 `docker-compose stop [options] [SERVICE...]`。
|
||||
|
||||
停止已经处于运行状态的容器,但不删除它。通过 `docker-compose start` 可以再次启动这些容器。
|
||||
|
||||
选项:
|
||||
|
||||
- `-t, --timeout TIMEOUT` 停止容器时候的超时(默认为 10 秒)。
|
||||
|
||||
### top
|
||||
|
||||
查看各个服务容器内运行的进程。
|
||||
|
||||
### unpause
|
||||
|
||||
格式为 `docker-compose unpause [SERVICE...]`。
|
||||
|
||||
恢复处于暂停状态中的服务。
|
||||
|
||||
### up
|
||||
|
||||
格式为 `docker-compose up [options] [SERVICE...]`。
|
||||
|
||||
该命令十分强大,它将尝试自动完成包括构建镜像,(重新)创建服务,启动服务,并关联服务相关容器的一系列操作。
|
||||
|
||||
链接的服务都将会被自动启动,除非已经处于运行状态。
|
||||
|
||||
可以说,大部分时候都可以直接通过该命令来启动一个项目。
|
||||
|
||||
默认情况,`docker-compose up` 启动的容器都在前台,控制台将会同时打印所有容器的输出信息,可以很方便进行调试。
|
||||
|
||||
当通过 `Ctrl-C` 停止命令时,所有容器将会停止。
|
||||
|
||||
如果使用 `docker-compose up -d`,将会在后台启动并运行所有的容器。一般推荐生产环境下使用该选项。
|
||||
|
||||
默认情况,如果服务容器已经存在,`docker-compose up` 将会尝试停止容器,然后重新创建(保持使用 `volumes-from` 挂载的卷),以保证新启动的服务匹配 `docker-compose.yml` 文件的最新内容。如果用户不希望容器被停止并重新创建,可以使用 `docker-compose up --no-recreate`。这样将只会启动处于停止状态的容器,而忽略已经运行的服务。如果用户只想重新部署某个服务,可以使用 `docker-compose up --no-deps -d ` 来重新创建服务并后台停止旧服务,启动新服务,并不会影响到其所依赖的服务。
|
||||
|
||||
选项:
|
||||
|
||||
- `-d` 在后台运行服务容器。
|
||||
- `--no-color` 不使用颜色来区分不同的服务的控制台输出。
|
||||
- `--no-deps` 不启动服务所链接的容器。
|
||||
- `--force-recreate` 强制重新创建容器,不能与 `--no-recreate` 同时使用。
|
||||
- `--no-recreate` 如果容器已经存在了,则不重新创建,不能与 `--force-recreate` 同时使用。
|
||||
- `--no-build` 不自动构建缺失的服务镜像。
|
||||
- `-t, --timeout TIMEOUT` 停止容器时候的超时(默认为 10 秒)。
|
||||
|
||||
### version
|
||||
|
||||
格式为 `docker-compose version`。
|
||||
|
||||
打印版本信息。
|
||||
|
|
@ -0,0 +1,150 @@
|
|||
# Chapter 7 综合实践
|
||||
|
||||
在本章我们希望你能通过docker的形式将您个人的项目修改为容器化部署的形式,最好可以配合上Github Action来实现CI/CD功能。
|
||||
|
||||
在没有学习docker之前,部署项目都是直接启动文件,比如java项目就是java –jar xxxx.jar的方式,python项目就是python xxxx.py。如果采用docker的方式去部署这些项目,一般有两种方式,以jar包项目为例
|
||||
|
||||
## 方式一 挂载部署
|
||||
|
||||
这种方式类似于常规部署,通过数据卷的方式将宿主机的jar包挂载到容器中,然后执行jar包的jdk选择容器中的而非采用本地的。
|
||||
|
||||
\1. 将jar包上传到服务器的指定目录,比如/root/docker/jar。
|
||||
|
||||

|
||||
|
||||
2.通过docker pull openjdk:8命令获取镜像
|
||||
|
||||

|
||||
|
||||
3.编写docker-compose.yml文件
|
||||
|
||||
```yaml
|
||||
version:'3.0'
|
||||
|
||||
services:
|
||||
|
||||
java:
|
||||
image: docker.io/openjdk
|
||||
restart:always
|
||||
container_name: myopenjdk
|
||||
ports:
|
||||
- 8080:8001
|
||||
volumes:
|
||||
- /root/docker/jar/xxxx.jar:/root:z
|
||||
- /etc/localtime:/etc/localtime
|
||||
environment:
|
||||
- TZ="Asia/Shanghai"
|
||||
entrypoint: java -jar /root/xxxx.jar
|
||||
mynetwork:
|
||||
ipv4_address: 192.168.1.13
|
||||
|
||||
networks:
|
||||
mynetwork:
|
||||
ipam:
|
||||
config:
|
||||
- subnet: 192.168.1.0/24
|
||||
```
|
||||
|
||||
参数解释:
|
||||
|
||||
build 指定dockerfile所在文件夹的路径 context指定dockerfile文件所在路径 dockerfile指定文件的具体名称
|
||||
|
||||
container_name 指定容器名称
|
||||
|
||||
volumes 挂载路径 z是用来设置selinux,或者直接在linux通过命令临时关闭或者永久关闭
|
||||
|
||||
ports 暴露端口信息
|
||||
|
||||
networks是用来给容器设置固定的ip
|
||||
|
||||
3.执行命令docker-compose up –d启动jar包, 可以通过docker ps查看容器是否在运行,需要注意的是默认查看所有运行中的容器,如果想查看所有容器,需要添加参数-a
|
||||
|
||||

|
||||
|
||||
\4. 注意如果容器启动失败或者状态异常,可以通过docker logs查看日志
|
||||
|
||||
5.通过docker inspect myopenjdk查看容器详细信息,可以看到容器ip已经设置成功
|
||||
|
||||

|
||||
|
||||
5.然后在虚拟机中打开浏览器输入jar包项目的访问地址,就可以看到运行的项目,需要注意访问端口是映射过的端口而非项目实际端口
|
||||
|
||||

|
||||
|
||||
## 方式二 构建镜像部署
|
||||
|
||||
1.将jar包上传到服务器的指定目录,比如/root/docker/jar。
|
||||
|
||||
2.在该目录下创建Dockerfile文件,通过vim等编辑工具在Dockerfile中编辑以下内容
|
||||
|
||||
```dockerfile
|
||||
FROM java:8
|
||||
MAINTAINER YHF
|
||||
LABEL description=”learn docker”
|
||||
ADD xxx.jar
|
||||
EXPOSE 8001
|
||||
ENTRYPOINT [“java”,”-jar”,”xxxx.jar”]
|
||||
```
|
||||
|
||||
参数解释:
|
||||
|
||||
FROM java:8 指定所创建镜像的基础镜像
|
||||
|
||||
MAINTAINER yhf 指定作者为yhf
|
||||
|
||||
LABEL 为生成的镜像添加元数据标签信息
|
||||
|
||||
ADD xxxx.jar 添加内容到镜像
|
||||
|
||||
EXPOSE 8080 声明镜像内服务监听的端口
|
||||
|
||||
ENTRYPOINT 指定镜像的默认入口命令,支持两种格式ENTRYPOINT[“java”,”-jar”,”xxxx.jar”];ENTRYPOINT java –jar xxxx.jar。注意每个dokcerfile中只能有一个ENTRYPOINT,如果指定多个只有最后一个生效。
|
||||
|
||||
4.Dockerfile构建完成以后可以通过命令docker build构建镜像,然后再运行容器,这里咱们用docker-compose命令直接编排构建镜像和运行容器。
|
||||
|
||||
5.编写docker-compose.yml文件
|
||||
|
||||
```yaml
|
||||
version: '3'
|
||||
|
||||
services:
|
||||
|
||||
java_2:
|
||||
restart: always
|
||||
image: yhfopenjdk:latest
|
||||
container_name: myopenjdk
|
||||
ports:
|
||||
- 8080:8001
|
||||
volumes:
|
||||
- /etc/localtime:/etc/localtime
|
||||
environment:
|
||||
- TZ="Asia/Shanghai"
|
||||
entrypoint: java -jar /root/datawhale-admin-1.0.0.jar
|
||||
networks:
|
||||
mynetwork:
|
||||
ipv4_address: 192.168.1.13
|
||||
|
||||
networks:
|
||||
mynetwork:
|
||||
ipam:
|
||||
config:
|
||||
- subnet: 192.168.1.0/24
|
||||
```
|
||||
|
||||
参数解释同方式一:
|
||||
|
||||
6.执行docker-compose up –d直接启动基于文件构建的自定义镜像,如果镜像不存在会自动构建,如果已存在那么直接启动。如果想重新构建镜像,则执行docker-compose build。如果想在执行compose文件的时候重构,则执行docker-compose up –d –build。
|
||||
|
||||

|
||||
|
||||
此使通过dockerfile文件构建的镜像已经创建
|
||||
|
||||

|
||||
|
||||
通过镜像运行的容器已经正常启动,可以通过docker ps查看容器是否在运行,需要注意的是默认查看所有运行中的容器,如果想查看所有容器,需要添加参数-a
|
||||
|
||||

|
||||
|
||||
7.在浏览器中输入访问路径可以看到项目已经正常运行
|
||||
|
||||

|
||||
|
|
@ -0,0 +1,19 @@
|
|||
```yaml
|
||||
version: "3"
|
||||
|
||||
services:
|
||||
|
||||
elastic:
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
|
||||
ports:
|
||||
- "9200:9200"
|
||||
- "9300:9300"
|
||||
volumes:
|
||||
- elastic-data:/data
|
||||
environment:
|
||||
- discovery.type=single-node
|
||||
|
||||
volumes:
|
||||
elastic-data:
|
||||
```
|
||||
|
||||
|
|
@ -0,0 +1,73 @@
|
|||
```yaml
|
||||
version: '2.2'
|
||||
services:
|
||||
es01:
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
|
||||
container_name: es01
|
||||
environment:
|
||||
- node.name=es01
|
||||
- cluster.name=es-docker-cluster
|
||||
- discovery.seed_hosts=es02,es03
|
||||
- cluster.initial_master_nodes=es01,es02,es03
|
||||
- bootstrap.memory_lock=true
|
||||
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
volumes:
|
||||
- data01:/usr/share/elasticsearch/data
|
||||
ports:
|
||||
- 9200:9200
|
||||
networks:
|
||||
- elastic
|
||||
es02:
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
|
||||
container_name: es02
|
||||
environment:
|
||||
- node.name=es02
|
||||
- cluster.name=es-docker-cluster
|
||||
- discovery.seed_hosts=es01,es03
|
||||
- cluster.initial_master_nodes=es01,es02,es03
|
||||
- bootstrap.memory_lock=true
|
||||
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
volumes:
|
||||
- data02:/usr/share/elasticsearch/data
|
||||
networks:
|
||||
- elastic
|
||||
es03:
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
|
||||
container_name: es03
|
||||
environment:
|
||||
- node.name=es03
|
||||
- cluster.name=es-docker-cluster
|
||||
- discovery.seed_hosts=es01,es02
|
||||
- cluster.initial_master_nodes=es01,es02,es03
|
||||
- bootstrap.memory_lock=true
|
||||
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
volumes:
|
||||
- data03:/usr/share/elasticsearch/data
|
||||
networks:
|
||||
- elastic
|
||||
|
||||
volumes:
|
||||
data01:
|
||||
driver: local
|
||||
data02:
|
||||
driver: local
|
||||
data03:
|
||||
driver: local
|
||||
|
||||
networks:
|
||||
elastic:
|
||||
driver: bridge
|
||||
```
|
||||
|
||||
|
|
@ -0,0 +1,53 @@
|
|||
```yaml
|
||||
version: '2'
|
||||
services:
|
||||
|
||||
etcd1:
|
||||
image: quay.io/coreos/etcd:v3.1.13
|
||||
restart: always
|
||||
ports:
|
||||
- 23791:2379
|
||||
- 23801:2380
|
||||
environment:
|
||||
ETCD_NAME: infra1
|
||||
ETCD_INITIAL_ADVERTISE_PEER_URLS: http://etcd1:2380
|
||||
ETCD_INITIAL_CLUSTER: infra3=http://etcd3:2380,infra1=http://etcd1:2380,infra2=http://etcd2:2380
|
||||
ETCD_INITIAL_CLUSTER_STATE: new
|
||||
ETCD_INITIAL_CLUSTER_TOKEN: etcd-tasting-01
|
||||
ETCD_LISTEN_CLIENT_URLS: http://etcd1:2379,http://localhost:2379
|
||||
ETCD_LISTEN_PEER_URLS: http://etcd1:2380
|
||||
ETCD_ADVERTISE_CLIENT_URLS: http://etcd1:2379
|
||||
|
||||
etcd2:
|
||||
image: quay.io/coreos/etcd:v3.1.13
|
||||
restart: always
|
||||
ports:
|
||||
- 23792:2379
|
||||
- 23802:2380
|
||||
environment:
|
||||
ETCD_NAME: infra2
|
||||
ETCD_INITIAL_ADVERTISE_PEER_URLS: http://etcd2:2380
|
||||
ETCD_INITIAL_CLUSTER: infra3=http://etcd3:2380,infra1=http://etcd1:2380,infra2=http://etcd2:2380
|
||||
ETCD_INITIAL_CLUSTER_STATE: new
|
||||
ETCD_INITIAL_CLUSTER_TOKEN: etcd-tasting-01
|
||||
ETCD_LISTEN_CLIENT_URLS: http://etcd2:2379,http://localhost:2379
|
||||
ETCD_LISTEN_PEER_URLS: http://etcd2:2380
|
||||
ETCD_ADVERTISE_CLIENT_URLS: http://etcd2:2379
|
||||
|
||||
etcd3:
|
||||
image: quay.io/coreos/etcd:v3.1.13
|
||||
restart: always
|
||||
ports:
|
||||
- 23793:2379
|
||||
- 23803:2380
|
||||
environment:
|
||||
ETCD_NAME: infra3
|
||||
ETCD_INITIAL_ADVERTISE_PEER_URLS: http://etcd3:2380
|
||||
ETCD_INITIAL_CLUSTER: infra3=http://etcd3:2380,infra1=http://etcd1:2380,infra2=http://etcd2:2380
|
||||
ETCD_INITIAL_CLUSTER_STATE: new
|
||||
ETCD_INITIAL_CLUSTER_TOKEN: etcd-tasting-01
|
||||
ETCD_LISTEN_CLIENT_URLS: http://etcd3:2379,http://localhost:2379
|
||||
ETCD_LISTEN_PEER_URLS: http://etcd3:2380
|
||||
ETCD_ADVERTISE_CLIENT_URLS: http://etcd3:2379
|
||||
```
|
||||
|
||||
|
|
@ -0,0 +1,177 @@
|
|||
### 首先创建master结点的Dockerfile
|
||||
|
||||
在编写之前我们先要创建一个配置master的my.cnf配置文件
|
||||
|
||||
```
|
||||
[mysqld]
|
||||
log_bin = mysql-bin
|
||||
server_id = 10
|
||||
```
|
||||
|
||||
之后我们创建master结点的Dockerfile
|
||||
|
||||
```
|
||||
FROM mysql:5.7
|
||||
ADD ./master/my.cnf /etc/mysql/my.cnf
|
||||
```
|
||||
|
||||
### 第二创建slave结点的Dockerfile
|
||||
|
||||
在编写之前我们先要创建一个配置slave结点my.cnf配置文件
|
||||
|
||||
```
|
||||
[mysqld]
|
||||
log_bin = mysql-bin
|
||||
server_id = 11
|
||||
relay_log = /var/lib/mysql/mysql-relay-bin
|
||||
log_slave_updates = 1
|
||||
read_only = 1
|
||||
```
|
||||
|
||||
注意要修改server_id为不同值,否则会发生错误,之后我们创建slave结点的Dockerfile
|
||||
|
||||
```
|
||||
FROM mysql:5.7
|
||||
ADD ./slave/my.cnf /etc/mysql/my.cnf
|
||||
```
|
||||
|
||||
### 最终的docker-compose.yml
|
||||
|
||||
我们创建这样一个目录结构
|
||||
|
||||

|
||||
|
||||
其中master文件夹存放关于master结点的my.cnf和Dockerfile,slave文件夹存放关于slave结点的my.cnf和Dockerfile。
|
||||
|
||||
```yaml
|
||||
version: "3"
|
||||
services:
|
||||
db-master:
|
||||
build:
|
||||
context: ./
|
||||
dockerfile: master/Dockerfile
|
||||
restart: always
|
||||
environment:
|
||||
MYSQL_DATABASE: 'db'
|
||||
# So you don't have to use root, but you can if you like
|
||||
MYSQL_USER: 'user'
|
||||
# You can use whatever password you like
|
||||
MYSQL_PASSWORD: 'password'
|
||||
# Password for root access
|
||||
MYSQL_ROOT_PASSWORD: 'password'
|
||||
ports:
|
||||
# <Port exposed> : < MySQL Port running inside container>
|
||||
- '3306:3306'
|
||||
# Where our data will be persisted
|
||||
volumes:
|
||||
- my-db-master:/var/lib/mysql
|
||||
networks:
|
||||
- net-mysql
|
||||
|
||||
db-slave:
|
||||
build:
|
||||
context: ./
|
||||
dockerfile: slave/Dockerfile
|
||||
restart: always
|
||||
environment:
|
||||
MYSQL_DATABASE: 'db'
|
||||
# So you don't have to use root, but you can if you like
|
||||
MYSQL_USER: 'user'
|
||||
# You can use whatever password you like
|
||||
MYSQL_PASSWORD: 'password'
|
||||
# Password for root access
|
||||
MYSQL_ROOT_PASSWORD: 'password'
|
||||
ports:
|
||||
# <Port exposed> : < MySQL Port running inside container>
|
||||
- '3307:3306'
|
||||
# Where our data will be persisted
|
||||
volumes:
|
||||
- my-db-slave:/var/lib/mysql
|
||||
networks:
|
||||
- net-mysql
|
||||
|
||||
# Names our volume
|
||||
volumes:
|
||||
my-db-master:
|
||||
my-db-slave:
|
||||
|
||||
|
||||
networks:
|
||||
net-mysql:
|
||||
driver: bridge
|
||||
```
|
||||
|
||||
现在我们就可以通过docker-compose来启动这两个结点了
|
||||
|
||||
```
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
接下来我们就可以看到一些镜像的构建信息,当两个结点都启动之后我们来查看一下两个结点的状态
|
||||
|
||||
```
|
||||
docker-compose ps -a
|
||||
```
|
||||
|
||||

|
||||
|
||||
可以看到两个结点的状态已经是Up了,并且主结点映射在宿主机的3306端口,从结点映射在宿主机的3307端口。我们再来查看一下这两个结点的网络信息,以便后续使用
|
||||
|
||||
```
|
||||
docker network ls
|
||||
```
|
||||
|
||||

|
||||
|
||||
这个就是我们刚才创建的网络,刚才创建的两个结点也挂载在这个网络上,我们来查看一下详细信息
|
||||
|
||||
```
|
||||
docker inspect 62fa5033ce48
|
||||
```
|
||||
|
||||
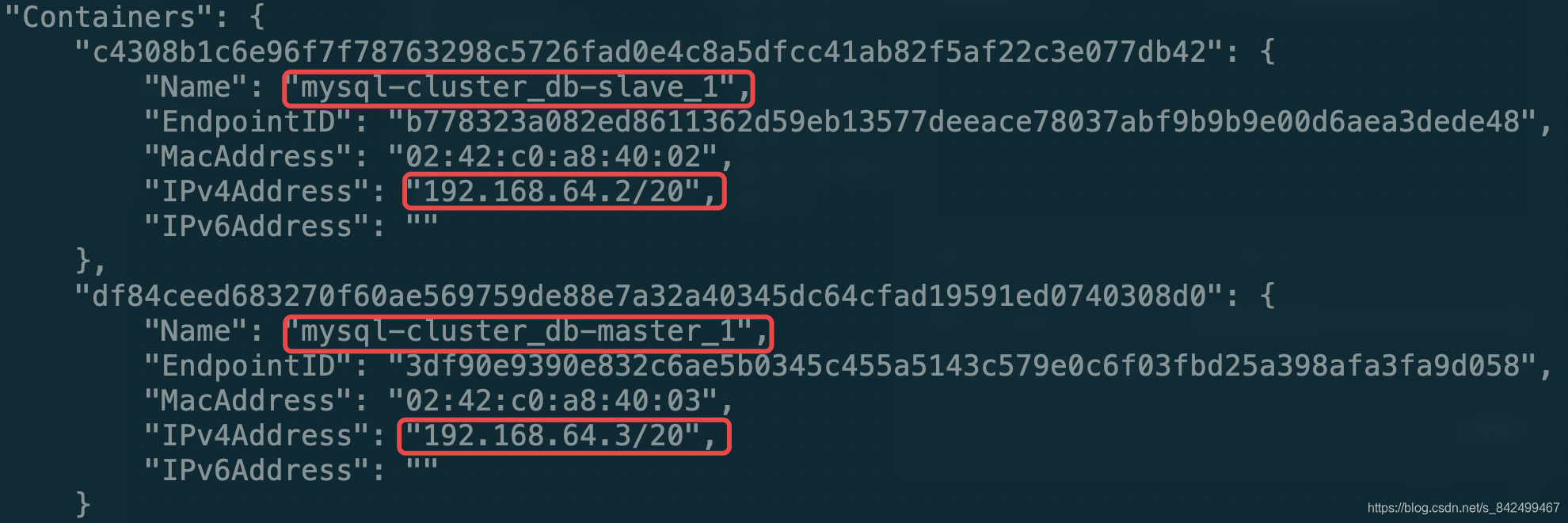
|
||||
|
||||
这样我们就差看到来两个结点的具体IP地址,因为Docker网络的配置,两个连接到同一network的容器会直接相互连通。
|
||||
|
||||
### 主从配置
|
||||
|
||||
启动之后进入从结点
|
||||
|
||||
```
|
||||
docker-compose exec db-slave bash
|
||||
```
|
||||
|
||||
进入从结点mysql中
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
```
|
||||
|
||||
在从结点上配置主节点信息,然后把当前结点设置为从结点。
|
||||
|
||||
```
|
||||
mysql> CHANGE MASTER TO MASTER_HOST='192.168.64.3', MASTER_USER='root', MASTER_PASSWORD='password', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=0;
|
||||
Query OK, 0 rows affected, 2 warnings (0.11 sec)
|
||||
|
||||
|
||||
mysql> start slave;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
```
|
||||
|
||||
正常情况我们应该创建一个用户然后赋予其相应的权限,而不是将root用户配置给他.现在查看一下从结点的状态
|
||||
|
||||
```
|
||||
mysql> show slave status\G;
|
||||
```
|
||||
|
||||

|
||||
|
||||
都显示为YES的话那么我们的主从配置已经成功,现在我们在主节点创建一个test_db3数据库
|
||||
|
||||

|
||||
|
||||
然后切换到从结点,可以看到数据已经同步到从结点了
|
||||
|
||||

|
||||
|
||||
到这里一个简单的单主节点单从结点的MySQL架构已经搭建完毕。
|
||||
|
|
@ -0,0 +1,29 @@
|
|||
```yaml
|
||||
version: "3"
|
||||
|
||||
services:
|
||||
|
||||
rabbitmq:
|
||||
image: rabbitmq:management
|
||||
hostname: myrabbitmq
|
||||
ports:
|
||||
- "5672:5672"
|
||||
- "15672:15672"
|
||||
volumes:
|
||||
- rabbitmq-data:/var/lib/rabbitmq
|
||||
|
||||
volumes:
|
||||
rabbitmq-data:
|
||||
```
|
||||
|
||||
查看服务状态
|
||||
|
||||

|
||||
|
||||
确定服务正常启动后在浏览器输入网址[http://localhost:15672](http://localhost:15672/#/),进入RabbitMQ的登陆界面
|
||||
|
||||

|
||||
|
||||
默认用户名密码都是guest。登陆之后就可以进入到主界面了
|
||||
|
||||

|
||||
|
|
@ -0,0 +1,32 @@
|
|||
```yaml
|
||||
version: '2'
|
||||
|
||||
services:
|
||||
proxy:
|
||||
image: traefik
|
||||
command: --api --docker --docker.domain=docker.localhost --logLevel=DEBUG
|
||||
networks:
|
||||
- apinetwork
|
||||
ports:
|
||||
- "80:80"
|
||||
- "8080:8080"
|
||||
volumes:
|
||||
- /var/run/docker.sock:/var/run/docker.sock
|
||||
- ./traefik.toml:/etc/traefik/traefik.toml
|
||||
|
||||
networks:
|
||||
apinetwork:
|
||||
external:
|
||||
name: fileserver
|
||||
```
|
||||
|
||||
注意需要编写traefik.toml文件
|
||||
|
||||
```
|
||||
defaultEntryPoints = ["http"]
|
||||
insecureSkipVerify = true
|
||||
[entryPoints]
|
||||
[entryPoints.http]
|
||||
address = ":80"
|
||||
```
|
||||
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
FROM python:2.7
|
||||
COPY . /app
|
||||
WORKDIR /app
|
||||
RUN pip install flask redis
|
||||
EXPOSE 5000
|
||||
CMD [ "python", "app.py" ]
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
from flask import Flask
|
||||
from redis import Redis
|
||||
import os
|
||||
import socket
|
||||
|
||||
app = Flask(__name__)
|
||||
redis = Redis(host=os.environ.get('REDIS_HOST', '127.0.0.1'), port=6379)
|
||||
|
||||
|
||||
@app.route('/')
|
||||
def hello():
|
||||
redis.incr('hits')
|
||||
return 'Hello Container World! I have been seen %s times and my hostname is %s.\n' % (redis.get('hits'),socket.gethostname())
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
app.run(host="0.0.0.0", port=5000, debug=True)
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
version: "3"
|
||||
|
||||
services:
|
||||
|
||||
redis:
|
||||
image: redis
|
||||
|
||||
redis-web:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile
|
||||
environment:
|
||||
REDIS_HOST: redis
|
||||
|
|
@ -0,0 +1,89 @@
|
|||
# Docker组队学习
|
||||
|
||||
## 简介
|
||||
|
||||
该目录用于存储Docker组队学习教程,该教程是与《[docker从入门到实践](https://vuepress.mirror.docker-practice.com/)》的合作项目,在经得作者同意的前提下,我们在原项目的基础上进行了整理与重构使得内容更适合与我们本期的Docker组队学习。
|
||||
|
||||
## 目录
|
||||
|
||||
0. 开篇词
|
||||
|
||||
1. docker简介
|
||||
|
||||
2. docker安装
|
||||
|
||||
3. docker容器与镜像
|
||||
|
||||
4. docker数据管理
|
||||
|
||||
5. docker网络
|
||||
5.1. Docker 基础网络介绍
|
||||
- 外部访问容器
|
||||
- 容器互联
|
||||
- 配置DNS
|
||||
|
||||
5.2. Docker的网络模式
|
||||
- Bridge 模式
|
||||
- Host 模式
|
||||
- None 模式
|
||||
- Container 模式
|
||||
|
||||
5.3. Docker高级网络配置
|
||||
- 快速配置指南
|
||||
- 容器访问控制
|
||||
- 端口映射实现
|
||||
- 配置docker0网桥
|
||||
- 自定义网桥
|
||||
- 工具和示例
|
||||
- 编辑网络配置文件
|
||||
- 实例:创建一个点到点连接
|
||||
|
||||
6. docker compose
|
||||
6.1. 什么是docker compose
|
||||
6.2. 如何使用docker compose
|
||||
6.3. docker compose基本使用
|
||||
6.4. Compose模板文件
|
||||
6.5. Compose命令
|
||||
6.6. [常见服务的docker-compose.yml集合]()
|
||||
|
||||
7. 综合实践
|
||||
|
||||
## 贡献人员
|
||||
感谢以下Datawhale成员对项目推进作出的贡献(排名不分先后):
|
||||
|
||||
<table align="center" style="width:80%;">
|
||||
<caption><b>贡献者名单</b></caption>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>成员</th>
|
||||
<th>个人简介及贡献</th>
|
||||
<th>个人主页</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">苏鹏</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">东北大学硕士,Datawhale成员</td>
|
||||
<td><a href="https://github.com/SuperSupeng">Github</a></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
## 项目贡献情况
|
||||
|
||||
- 项目构建与整合:苏鹏
|
||||
- 第一章:陈安东(校对:乔石)
|
||||
- 第二章:陈安东(校对:乔石)
|
||||
- 第三章:陈长沙,乔石(校对:于鸿飞,苏鹏)
|
||||
- 第四章:丁一超(校对:陈长沙)
|
||||
- 第五章:刘雯静(校对:丁一超)
|
||||
- 第六章:苏鹏(校对:刘雯静)
|
||||
- 第七章:于鸿飞(校对:苏鹏)
|
||||
|
||||
## 特别鸣谢
|
||||
特别鸣谢《docker从入门到实践》的作者[Baohua Yang](https://github.com/yeasy)对本次组队学习的支持,希望大家未来也能将自己的内容进行整理并开源出来帮助更多的人。
|
||||
|
||||
## 关注我们
|
||||
|
||||
> "Datawhale是一个专注AI领域的开源组织,以“for the learner,和学习者一起成长”为愿景,构建对学习者最有价值的开源学习社区。关注我们,一起学习成长。"
|
||||
|
||||
<img src="https://github.com/datawhalechina/team-learning-sql/blob/main/img/datawhale_code.jpeg" width="175" height= "200">
|
||||
|
|
@ -0,0 +1,52 @@
|
|||
# 编程实践(蓝桥刷题94道)
|
||||
|
||||
开源内容:https://github.com/datawhalechina/team-learning-program/tree/master/LanQiao
|
||||
|
||||
## 基本信息
|
||||
|
||||
- 学习周期:14天,每天平均花费时间2小时-5小时不等,根据个人学习接受能力强弱有所浮动。
|
||||
- 学习形式:练习
|
||||
- 人群定位:有一定编程基础,对学习算法有需求的学员。
|
||||
- 先修内容:[Python编程语言](https://github.com/datawhalechina/team-learning-program/tree/master/PythonLanguage)、[数据结构与算法](https://github.com/datawhalechina/team-learning-program/tree/master/DataStructureAndAlgorithm)、[编程实践(LeetCode 分类练习)](https://github.com/datawhalechina/team-learning-program/tree/master/LeetCodeClassification)
|
||||
- 难度系数:中
|
||||
|
||||
## 学习目标
|
||||
|
||||
每天刷三道题,利用14天对于蓝桥杯这个比赛有一个初步的了解,掌握基本的蓝桥杯赛题解法。
|
||||
|
||||

|
||||
|
||||
## 任务安排
|
||||
|
||||
### Task00:熟悉规则(1天)
|
||||
- 组队、修改群昵称
|
||||
- 熟悉打卡规则
|
||||
|
||||
### Task01:热身练习(2天)
|
||||
- 完成热身练习文件夹中的7道题目
|
||||
- 熟悉基本输入输出及蓝桥杯的练习系统的使用方法。
|
||||
|
||||
### Task02:基础练习(3天)
|
||||
- 完成基础练习文件夹中的7道题目
|
||||
|
||||
### Task03:基础练习2(3天)
|
||||
- 完成基础练习2文件夹中的8道题目
|
||||
|
||||
### Task04:真题练习(3天)
|
||||
- 完成真题练习文件夹中的10道题目
|
||||
|
||||
### Task05:真题练习2(3天)
|
||||
- 完成真题练习文件夹中的7道题目
|
||||
|
||||
|
||||
## 开源贡献者
|
||||
|
||||
韩绘锦:华北电力大学
|
||||
|
||||
- CSDN:https://blog.csdn.net/weixin_45569785
|
||||
|
||||
黄建国:华北电力大学
|
||||
|
||||
荆宝加:华北电力大学
|
||||
|
||||
吴丹飞:华北电力大学
|
||||
|
|
@ -0,0 +1,79 @@
|
|||
## 01字串
|
||||
|
||||
**问题描述**
|
||||
|
||||
```
|
||||
对于长度为5位的一个01串,每一位都可能是0或1,一共有32种可能。它们的前几个是:
|
||||
00000
|
||||
00001
|
||||
00010
|
||||
00011
|
||||
00100
|
||||
请按从小到大的顺序输出这32种01串。
|
||||
```
|
||||
|
||||
**输入格式**
|
||||
|
||||
- 本试题没有输入。
|
||||
|
||||
**输出格式**
|
||||
|
||||
- 输出32行,按从小到大的顺序每行一个长度为5的01串。
|
||||
|
||||
**样例输出**
|
||||
|
||||
```
|
||||
00000
|
||||
00001
|
||||
00010
|
||||
00011
|
||||
<以下部分省略>
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
for i in range(32):
|
||||
t1=i
|
||||
temp=[0]*5
|
||||
for j in range(5)[::-1]:
|
||||
if 2**j<=t1:
|
||||
temp[j]=1
|
||||
t1=t1-2**j
|
||||
print(''.join(map(str,reversed(temp))))
|
||||
|
||||
```
|
||||
|
||||
00000
|
||||
00001
|
||||
00010
|
||||
00011
|
||||
00100
|
||||
00101
|
||||
00110
|
||||
00111
|
||||
01000
|
||||
01001
|
||||
01010
|
||||
01011
|
||||
01100
|
||||
01101
|
||||
01110
|
||||
01111
|
||||
10000
|
||||
10001
|
||||
10010
|
||||
10011
|
||||
10100
|
||||
10101
|
||||
10110
|
||||
10111
|
||||
11000
|
||||
11001
|
||||
11010
|
||||
11011
|
||||
11100
|
||||
11101
|
||||
11110
|
||||
11111
|
||||
|
||||
|
||||