15 KiB
| title | sidebar_label | toc_max_heading_level |
|---|---|---|
| 高效写入 | 高效写入 | 4 |
import Tabs from "@theme/Tabs"; import TabItem from "@theme/TabItem";
高效写入
本节介绍如何高效地向 TDengine 写入数据。
高效写入原理
客户端程序的角度
从客户端程序的角度来说,高效写入数据要考虑以下几个因素:
- 单次写入的数据量。一般来讲,每批次写入的数据量越大越高效(但超过一定阈值其优势会消失)。使用 SQL 写入 TDengine 时,尽量在一条 SQL 中拼接更多数据。目前,TDengine 支持的一条 SQL 的最大长度为 1,048,576(1MB)个字符
- 并发连接数。一般来讲,同时写入数据的并发连接数越多写入越高效(但超过一定阈值反而会下降,取决于服务端处理能力)
- 数据在不同表(或子表)之间的分布,即要写入数据的相邻性。一般来说,每批次只向同一张表(或子表)写入数据比向多张表(或子表)写入数据要更高效
- 写入方式。一般来讲:
- 参数绑定写入比 SQL 写入更高效。因参数绑定方式避免了 SQL 解析。
- SQL 写入不自动建表比自动建表更高效。因自动建表要频繁检查表是否存在。
- SQL 写入比无模式写入更高效。因无模式写入会自动建表且支持动态更改表结构。
客户端程序要充分且恰当地利用以上几个因素。在单次写入中尽量只向同一张表(或子表)写入数据,每批次写入的数据量经过测试和调优设定为一个最适合当前系统处理能力的数值,并发写入的连接数同样经过测试和调优后设定为一个最适合当前系统处理能力的数值,以实现在当前系统中的最佳写入速度。
数据源的角度
客户端程序通常需要从数据源读数据再写入 TDengine。从数据源角度来说,以下几种情况需要在读线程和写线程之间增加队列:
- 有多个数据源,单个数据源生成数据的速度远小于单线程写入的速度,但数据量整体比较大。此时队列的作用是把多个数据源的数据汇聚到一起,增加单次写入的数据量。
- 单个数据源生成数据的速度远大于单线程写入的速度。此时队列的作用是增加写入的并发度。
- 单张表的数据分散在多个数据源。此时队列的作用是将同一张表的数据提前汇聚到一起,提高写入时数据的相邻性。
如果写应用的数据源是 Kafka, 写应用本身即 Kafka 的消费者,则可利用 Kafka 的特性实现高效写入。比如:
- 将同一张表的数据写到同一个 Topic 的同一个 Partition,增加数据的相邻性
- 通过订阅多个 Topic 实现数据汇聚
- 通过增加 Consumer 线程数增加写入的并发度
- 通过增加每次 Fetch 的最大数据量来增加单次写入的最大数据量
服务器配置的角度
从服务端配置的角度,要根据系统中磁盘的数量,磁盘的 I/O 能力,以及处理器能力在创建数据库时设置适当的 vgroups 数量以充分发挥系统性能。如果 vgroups 过少,则系统性能无法发挥;如果 vgroups 过多,会造成无谓的资源竞争。常规推荐 vgroups 数量为 CPU 核数的 2 倍,但仍然要结合具体的系统资源配置进行调优。
高效写入示例
场景设计
下面的示例程序展示了如何高效写入数据,场景设计如下:
- TDengine 客户端程序从其它数据源不断读入数据,在示例程序中采用生成模拟数据的方式来模拟读取数据源,同时提供了从 Kafka 拉取数据写入 TDengine 的示例。
- 为了提高TDengine 客户端程序读取数据速度,使用多线程读取。为了避免乱序,多个读取线程读取数据对应的表集合应该不重叠。
- 为了与每个数据读取线程读取数据的速度相匹配,后台启用一组写入线程与之对应,每个写入线程都有一个独占的固定大小的消息队列。
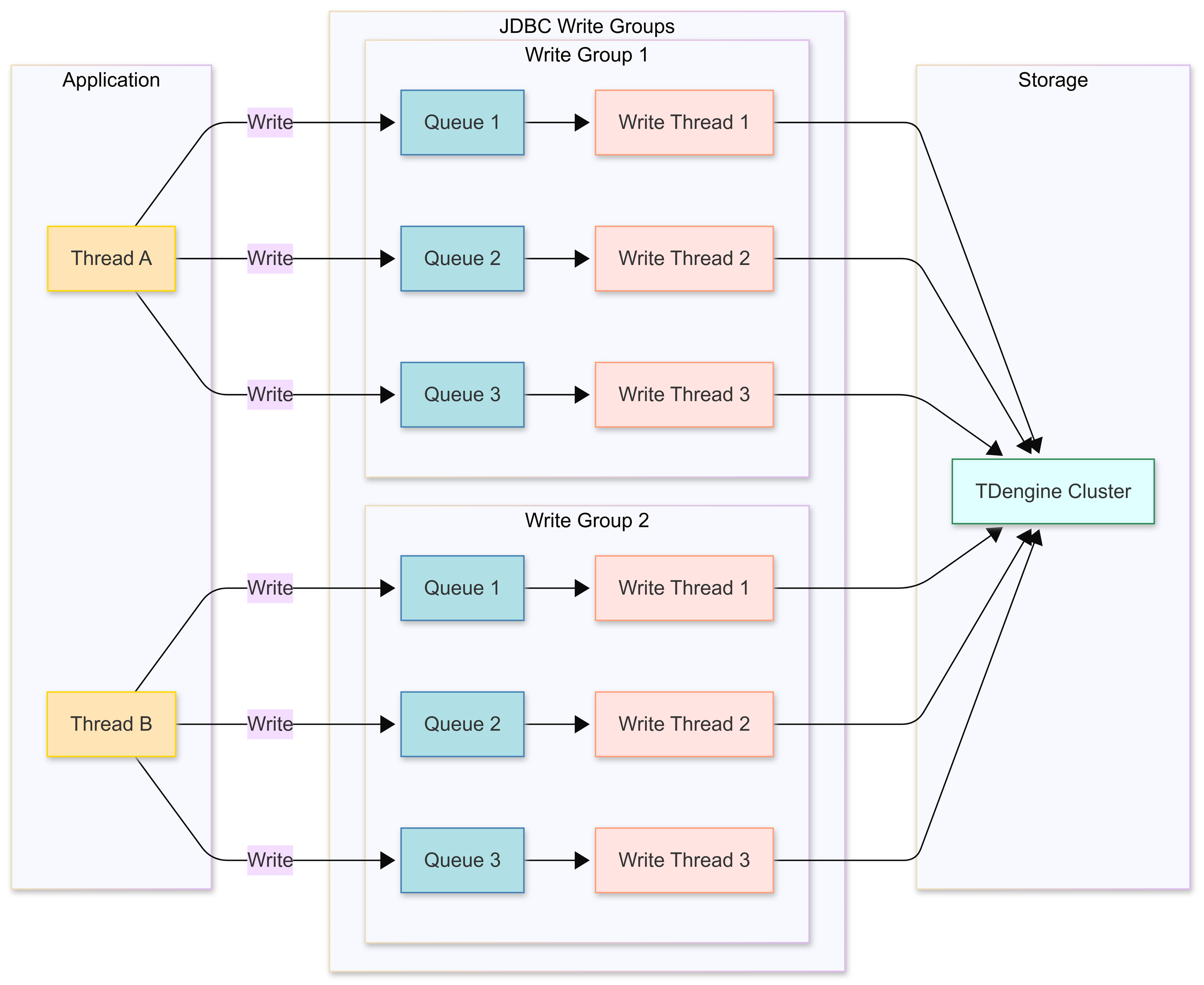
示例代码
这一部分是针对以上场景的示例代码。对于其它场景高效写入原理相同,不过代码需要适当修改。
本示例代码假设源数据属于同一张超级表(meters)的不同子表。程序在开始写入数据之前已经在 test 库创建了这个超级表,以及对应的子表。如果实际场景是多个超级表,只需按需创建多个超级表和启动多组任务。
JDBC 高效写入特性简介
JDBC 驱动从 3.6.0 版本开始,在 WebSocket 连接上提供了高效写入特性,其配置参数请参考 高效写入配置。 JDBC 驱动高效写入特性有如下特点:
- 支持 JDBC 标准参数绑定接口。
- 在资源充分条件下,写入能力跟写入线程数配置线性相关。
- 支持写入超时和连接断开重连后的重试次数和重试间隔配置。
- 支持调用 executeUpdate 接口获取写入数据条数,若写入有异常,此时可捕获。
程序清单
| 类名 | 功能说明 |
|---|---|
| FastWriteExample | 主程序,完成命令行参数解析,线程池创建,以及等待任务完成功能 |
| WorkTask | 从模拟源中读取数据,调用 JDBC 标准接口写入 |
| MockDataSource | 模拟生成一定数量 meters 子表的数据 |
| DataBaseMonitor | 统计写入速度,并每隔 10 秒把当前写入速度打印到控制台 |
| CreateSubTableTask | 根据子表范围创建子表,供主程序调用 |
| Meters | 提供了 meters 表单条数据的序列化和反序列化,供发送消息给 Kafka 和 从 Kafka 接收消息使用 |
| ProducerTask | 生产者,向 Kafka 发送消息 |
| ConsumerTask | 消费者,从 Kafka 接收消息,调用 JDBC 高效写入接口写入 TDengine,并按进度提交 offset |
| Util | 提供一些基础功能,包括创建连接,创建 Kafka topic,统计写入条数等 |
以下是各类的完整代码和更详细的功能说明。
FastWriteExample
主程序命令行参数介绍:
-b,--batchSizeByRow <arg> 指定高效写入的 batchSizeByRow 参数,默认 1000
-c,--cacheSizeByRow <arg> 指定高效写入的 cacheSizeByRow 参数,默认 10000
-d,--dbName <arg> 指定数据库名, 默认 `test`
--help 打印帮助信息
-K,--useKafka 使用 Kafka,采用创建生产者发送消息,消费者接收消息写入 TDengine 方式。否则采用工作线程订阅模拟器生成数据写入 TDengine 方式
-r,--readThreadCount <arg> 指定工作线程数,默认 5,当 Kafka 模式,此参数同时决定生产者和消费者线程数
-R,--rowsPerSubTable <arg> 指定每子表写入行数,默认 100
-s,--subTableNum <arg> 指定子表总数,默认 1000000
-w,--writeThreadPerReadThread <arg> 指定每工作线程对应写入线程数,默认 5
JDBC URL 和 Kafka 集群地址配置:
- JDBC URL 通过环境变量配置,例如:
export TDENGINE_JDBC_URL="jdbc:TAOS-WS://localhost:6041?user=root&password=taosdata" - Kafka 集群地址通过环境变量配置,例如:
KAFKA_BOOTSTRAP_SERVERS=localhost:9092
使用方式:
1. 采用模拟数据写入方式:java -jar highVolume.jar -r 5 -w 5 -b 10000 -c 100000 -s 1000000 -R 1000
2. 采用 Kafka 订阅写入方式:java -jar highVolume.jar -r 5 -w 5 -b 10000 -c 100000 -s 1000000 -R 100 -K
主程序负责:
- 解析命令行参数
- 创建子表
- 创建工作线程或 Kafka 生产者,消费者
- 统计写入速度
- 等待写入结束,释放资源
{{#include docs/examples/JDBC/highvolume/src/main/java/com/taos/example/highvolume/FastWriteExample.java}}
WorkTask
工作线程负责从模拟数据源读数据。每个读任务都关联了一个模拟数据源。每个模拟数据源可生成某个子表区间的数据。不同的模拟数据源生成不同表的数据。
工作线程采用阻塞的方式调用 JDBC 标准接口 addBatch。也就是说,一旦对应高效写入后端队列满了,写操作就会阻塞。
{{#include docs/examples/JDBC/highvolume/src/main/java/com/taos/example/highvolume/WorkTask.java}}
MockDataSource
模拟数据生成器,生成一定子表范围的数据。为了模拟真实情况,采用轮流每个子表一条数据的生成方式。
{{#include docs/examples/JDBC/highvolume/src/main/java/com/taos/example/highvolume/MockDataSource.java}}
CreateSubTableTask
根据子表范围创建子表,采用批量拼 sql 创建方式。
{{#include docs/examples/JDBC/highvolume/src/main/java/com/taos/example/highvolume/CreateSubTableTask.java}}
Meters
数据模型类,提供了发送到 Kafka 的序列化和反序列化方法。
{{#include docs/examples/JDBC/highvolume/src/main/java/com/taos/example/highvolume/Meters.java}}
ProducerTask
消息生产者,采用与 JDBC 高效写入不同的 Hash 方式,将模拟数据生成器生成的数据,写入所有分区。
{{#include docs/examples/JDBC/highvolume/src/main/java/com/taos/example/highvolume/ProducerTask.java}}
ConsumerTask
消息消费者,从 Kafka 接收消息,写入 TDengine。
{{#include docs/examples/JDBC/highvolume/src/main/java/com/taos/example/highvolume/ConsumerTask.java}}
StatTask
提供定时统计写入条数功能
{{#include docs/examples/JDBC/highvolume/src/main/java/com/taos/example/highvolume/StatTask.java}}
Util
工具类,提供连接创建,数据库创建和 topic 创建等功能。
{{#include docs/examples/JDBC/highvolume/src/main/java/com/taos/example/highvolume/Util.java}}
执行步骤
执行 Java 示例程序
本地集成开发环境执行示例程序
- clone TDengine 仓库
git clone git@github.com:taosdata/TDengine.git --depth 1 - 用集成开发环境打开
TDengine/docs/examples/JDBC/highvolume目录。 - 在开发环境中配置环境变量
TDENGINE_JDBC_URL。如果已配置了全局的环境变量TDENGINE_JDBC_URL可跳过这一步。 - 如果要运行 Kafka 示例,需要设置 Kafka 集群地址的环境变量
KAFKA_BOOTSTRAP_SERVERS。 - 指定命令行参数,如
-r 3 -w 3 -b 100 -c 1000 -s 1000 -R 100 - 运行类
com.taos.example.highvolume.FastWriteExample。
远程服务器上执行示例程序
若要在服务器上执行示例程序,可按照下面的步骤操作:
-
打包示例代码。在目录
TDengine/docs/examples/JDBC/highvolume下执行下面命令来生成highVolume.jar:mvn package -
复制程序到服务器指定目录:
scp -r .\target\highVolume.jar <user>@<host>:~/dest-path -
配置环境变量。 编辑
~/.bash_profile或~/.bashrc添加如下内容例如:export TDENGINE_JDBC_URL="jdbc:TAOS://localhost:6030?user=root&password=taosdata"以上使用的是本地部署 TDengine Server 时默认的 JDBC URL。你需要根据自己的实际情况更改。
如果想使用 Kafka 订阅模式,请再增加 Kafaka 集群环境变量配置:export KAFKA_BOOTSTRAP_SERVERS=localhost:9092 -
用 Java 命令启动示例程序,命令模板(如果用 Kafaka 订阅模式,最后可以加上
-K):java -jar highVolume.jar -r 5 -w 5 -b 10000 -c 100000 -s 1000000 -R 1000 -
结束测试程序。测试程序不会自动结束,在获取到当前配置下稳定的写入速度后,按 CTRL + C 结束程序。 下面是一次实际运行的日志输出,机器配置 40 核 + 256G + 固态硬盘。
---------------$ java -jar highVolume.jar -r 2 -w 10 -b 10000 -c 100000 -s 1000000 -R 100 [INFO ] 2025-03-24 18:03:17.980 com.taos.example.highvolume.FastWriteExample main 309 main readThreadCount=2, writeThreadPerReadThread=10 batchSizeByRow=10000 cacheSizeByRow=100000, subTableNum=1000000, rowsPerSubTable=100 [INFO ] 2025-03-24 18:03:17.983 com.taos.example.highvolume.FastWriteExample main 312 main create database begin. [INFO ] 2025-03-24 18:03:34.499 com.taos.example.highvolume.FastWriteExample main 315 main create database end. [INFO ] 2025-03-24 18:03:34.500 com.taos.example.highvolume.FastWriteExample main 317 main create sub tables start. [INFO ] 2025-03-24 18:03:34.502 com.taos.example.highvolume.FastWriteExample createSubTables 73 main create sub table task started. [INFO ] 2025-03-24 18:03:55.777 com.taos.example.highvolume.FastWriteExample createSubTables 82 main create sub table task finished. [INFO ] 2025-03-24 18:03:55.778 com.taos.example.highvolume.FastWriteExample main 319 main create sub tables end. [INFO ] 2025-03-24 18:03:55.781 com.taos.example.highvolume.WorkTask run 41 FW-work-thread-2 started [INFO ] 2025-03-24 18:03:55.781 com.taos.example.highvolume.WorkTask run 41 FW-work-thread-1 started [INFO ] 2025-03-24 18:04:06.580 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=12235906 speed=1223590 [INFO ] 2025-03-24 18:04:17.531 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=31185614 speed=1894970 [INFO ] 2025-03-24 18:04:28.490 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=51464904 speed=2027929 [INFO ] 2025-03-24 18:04:40.851 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=71498113 speed=2003320 [INFO ] 2025-03-24 18:04:51.948 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=91242103 speed=1974399