5.3 KiB
高效查询数据
主要查询功能
TDengine采用SQL作为查询语言,应用程序可以通过C/C++, JDBC, GO, Python连接器发送SQL查询语句,用户还可以通过TAOS Shell直接手动执行SQL即席查询,十分方便。支持如下查询功能:
- 查询单列、或多列查询
- 支持值过滤条件:>, <, =, <> 大于,小于,等于,不等于等等
- 支持对标签的模糊匹配
- 支持Group by, Order by, Limit, Offset
- 支持列之间的四则运算
- 支持时间戳对齐的JOIN操作
- 支持多种函数: count, max, min, avg, sum, twa, stddev, leastsquares, top, bottom, first, last, percentile, apercentile, last_row, spread, diff
例如:在TAOS Shell中,从表d1001中查询出vlotage >215的记录,按时间降序排列,仅仅输出2条。
taos> select * from d1001 where voltage > 215 order by ts desc limit 2;
ts | current | voltage | phase |
======================================================================================
2018-10-03 14:38:16.800 | 12.30000 | 221 | 0.31000 |
2018-10-03 14:38:15.000 | 12.60000 | 218 | 0.33000 |
Query OK, 2 row(s) in set (0.001100s)
为满足物联网场景的需求,TDengine支持几个特殊的函数,比如twa(时间加权平均),spread (最大值与最小值的差),last_row(最后一条记录)等,更多与物联网场景相关的函数将添加进来。TDengine还支持连续查询。
具体的查询语法请看TAOS SQL。
多表聚合查询
TDengine对每个数据采集点单独建表,但应用经常需要对数据点之间进行聚合。为高效的进行聚合操作,TDengine引入超级表(STable)的概念。超级表用来代表一特定类型的数据采集点,它是表的集合,包含多张表。这集合里每张表的Schema是一样的,但每张表都带有自己的静态标签,标签可以多个,可以随时增加、删除和修改。
应用可通过指定标签的过滤条件,对一个STable下的全部或部分表进行聚合或统计操作,这样大大简化应用的开发。其具体流程如下图所示:
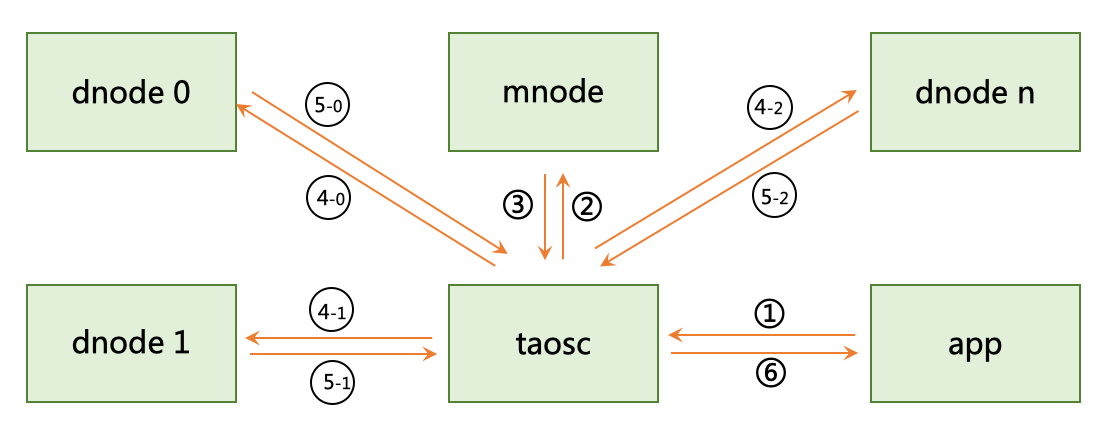 多表聚合查询原理图
多表聚合查询原理图
1:应用将一个查询条件发往系统;2: taosc将超级表的名字发往Meta Node(管理节点);3:管理节点将超级表所拥有的vnode列表发回taosc;4:taosc将计算的请求连同标签过滤条件发往这些vnode对应的多个数据节点;5:每个vnode先在内存里查找出自己节点里符合标签过滤条件的表的集合,然后扫描存储的时序数据,完成相应的聚合计算,将结果返回给taosc;6:taosc将多个数据节点返回的结果做最后的聚合,将其返回给应用。
由于TDengine在vnode内将标签数据与时序数据分离存储,通过先在内存里过滤标签数据,将需要扫描的数据集大幅减少,大幅提升了聚合计算速度。同时,由于数据分布在多个vnode/dnode,聚合计算操作在多个vnode里并发进行,又进一步提升了聚合的速度。
对普通表的聚合函数以及绝大部分操作都适用于超级表,语法完全一样,细节请看TAOS SQL。
比如:在TAOS Shell,查找所有智能电表采集的电压平均值,并按照location分组
taos> select avg(voltage) from meters group by location;
avg(voltage) | location |
=============================================================
222.000000000 | Beijing.Haidian |
219.200000000 | Beijing.Chaoyang |
Query OK, 2 row(s) in set (0.002136s)
降采样查询、插值
物联网场景里,经常需要做down sampling,需要将采集的数据按时间段进行聚合。TDengine提供了一个简便的关键词interval让操作变得极为简单。比如:将智能电表d1001采集的电流值每10秒钟求和
taos> SELECT sum(current) FROM d1001 interval(10s) ;
ts | sum(current) |
======================================================
2018-10-03 14:38:00.000 | 10.300000191 |
2018-10-03 14:38:10.000 | 24.900000572 |
Query OK, 2 row(s) in set (0.000883s)
降采样操作还适用于超级表,比如:将所有智能电表采集的电流值每秒钟求和
taos> SELECT sum(current) FROM meters interval(1s) ;
ts | sum(current) |
======================================================
2018-10-03 14:38:04.000 | 10.199999809 |
2018-10-03 14:38:05.000 | 32.900000572 |
2018-10-03 14:38:06.000 | 11.500000000 |
2018-10-03 14:38:15.000 | 12.600000381 |
2018-10-03 14:38:16.000 | 36.000000000 |
Query OK, 5 row(s) in set (0.001538s)
物联网场景里,每个数据采集点采集数据的时间是难同步的,但很多分析算法(比如FFT)需要把采集的数据严格按照时间等间隔的对齐,在很多系统里,需要应用自己写程序来处理,但使用TDengine的降采样操作就轻松解决。如果一个时间间隔里,没有采集的数据,TDengine还提供插值计算的功能。
语法规则细节请见TAOS SQL。