Add files via upload
This commit is contained in:
@@ -0,0 +1,657 @@
|
|||||||
|
# 1 文件自动化处理
|
||||||
|
|
||||||
|
## 1.1 读写文件
|
||||||
|
我们知道,程序运行时,可以用变量来保存运算结果,但如果希望程序运行关闭后,依然可以查看运行后的结果,就需要将数据保存到文件中。简单点,你可以将文件内容理解为一个字符串值,大小可能有几个GB。本节将学习,如何使用python在硬盘上创建、读取和保存文件。
|
||||||
|
|
||||||
|
## 1.1.1 文件与文件路径
|
||||||
|
文件的两个属性:“路径”和“文件名”,路径指明文件在计算机上的位置,文件名是指该位置的文件的名称。比如,我的电脑上,有个名字为Datawhale - 开源发展理论研究.pdf的文件,它的路径在D:\Datawhale。在windows中,路径中的D:\部分是“根文件夹”,Datawhale是文件夹名。注:Windows中文件夹名和文件名不区分大小写的。
|
||||||
|
|
||||||
|
在windows上,路径书写是使用倒斜杠'\'作为文件夹之间的分隔符,而在OS X和Linux上,是使用正斜杠'/'作为它们的路径分隔符。通常我们用`os.path.join()`函数来创建文件名称字符串。
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
os.path.join('Datawhale','docu')
|
||||||
|
```
|
||||||
|
|
||||||
|
我们可以看到返回的是('Datawhale\\\docu'),有两个斜杠,这是因为有一个斜杠是用来转义的,在OS X或Linux上调用这个函数,这个字符串就会是'Datawhale/docu'。
|
||||||
|
|
||||||
|
## 1.1.2 当前工作目录
|
||||||
|
每个运行在计算机上的程序,都有一个“当前工作目录”。利用`os.getcwd()`函数,可以取得当前工作路径的
|
||||||
|
字符串,并可以利用`os.chdir()`改变它。
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
os.getcwd() #获取当前工作目录
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.chdir('D:\\Datawhale\\python办公自动化') #改变当前工作目录
|
||||||
|
os.getcwd()
|
||||||
|
```
|
||||||
|
|
||||||
|
## 1.1.3 路径操作
|
||||||
|
|
||||||
|
### 1.1.3.1 绝对路径和相对路径
|
||||||
|
“绝对路径”,总是从根文件夹开始。
|
||||||
|
“相对路径”,相对于程序的当前工作目录。
|
||||||
|
相对路径中,单个句点“.”表示当前目录的缩写,两个句点“..”表示父文件夹。
|
||||||
|

|
||||||
|
|
||||||
|
几个常用的绝对路径和相对路径处理函数
|
||||||
|
|
||||||
|
`os.path.abspath(path)`:将相对路径转换为绝对路径,将返回参数的绝对路径的字符串。`os.path.isabs(path)`:判断是否是绝对路径,是返回True,不是则返回False
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.path.abspath('.') #当前路径转化为绝对路径。 'D:\\Datawhale\\python办公自动化'
|
||||||
|
os.path.isabs('.') #False
|
||||||
|
os.path.isabs(os.path.abspath('.')) #True
|
||||||
|
```
|
||||||
|
|
||||||
|
### 1.1.3.2 路径操作
|
||||||
|
`os.path.relpath(path,start)`:返回从start路径到path的相对路径的字符串。如果没提供start,就使用当前工作目录作为开始路径。
|
||||||
|
`os.path.dirname(path)`: 返回当前路径的目录名称。
|
||||||
|
`os.path.basename(path)`:返回当前路径的文件名称。
|
||||||
|
|
||||||
|
```
|
||||||
|
os.path.relpath('D:\\Datawhale\\python办公自动化','D:\\') #'Datawhale\\python办公自动化'
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
path = 'D:\\Datawhale\\python办公自动化\\python课程画图.pptx'
|
||||||
|
os.path.dirname(path) #'D:\\Datawhale\\python办公自动化'
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
os.path.basename(path) #'python课程画图.pptx'
|
||||||
|
```
|
||||||
|
|
||||||
|
如果同时需要一个路径的目录名称和基本名称,可以调用`os.path.split()`,获得者两个字符串的元组。
|
||||||
|
|
||||||
|
```python
|
||||||
|
caFilePath = 'D:\\Datawhale\\python办公自动化\\python课程画图.pptx'
|
||||||
|
os.path.split(caFilePath) #('D:\\Datawhale\\python办公自动化', 'python课程画图.pptx')
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
我们也可以调用os.path.dirname()和os.path.basename(),将它们的返回值放在一个元组中,从而得到同样的元组。
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
(os.path.dirname(caFilePath),os.path.basename(caFilePath)) #('D:\\Datawhale\\python办公自动化', 'python课程画图.pptx')
|
||||||
|
```
|
||||||
|
|
||||||
|
如果我们想返回每个文件夹的字符串的列表。用`os.path.split()`无法得到,我们可以用`split()`字符串方法,并根据`os.path.sep` 中的字符串进行分割。`os.path.sep` 变量设置为正确的文件夹分割斜杠。
|
||||||
|
|
||||||
|
```python
|
||||||
|
caFilePath.split(os.path.sep) #['D:', 'Datawhale', 'python办公自动化', 'python课程画图.pptx']
|
||||||
|
```
|
||||||
|
|
||||||
|
### 1.1.3.3 路径有效性检查
|
||||||
|
如果提供的路径不存在,很多Python函数就会崩溃并报错。`os.path`模块提供了一些函数,用于检测给定的路径是否存在,以及判定是文件还是文件。
|
||||||
|
|
||||||
|
`os.path.exists(path)`:如果path参数所指的文件或文件夹存在,则返回True,否则返回False。
|
||||||
|
|
||||||
|
`os.path.isfile(path)`:如果path参数存在,并且是一个文件,则返回True,否则返回False。
|
||||||
|
|
||||||
|
`os.path.isdir(path)`:如果path参数存在,并且是一个文件夹,则返回True,否则返回False。
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.path.exists('C:\\Windows')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.path.exists('C:\\else')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.path.isfile('D:\\Datawhale\\python办公自动化\\python课程画图.pptx')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.path.isfile('D:\\Datawhale\\python办公自动化')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.path.isdir('D:\\Datawhale\\python办公自动化\\python课程画图.pptx')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.path.isdir('D:\\Datawhale\\python办公自动化')
|
||||||
|
```
|
||||||
|
|
||||||
|
## 1.1.4 文件及文件夹操作
|
||||||
|
|
||||||
|
### 1.1.4.1 用os.makedirs()创建新文件夹
|
||||||
|
注:`os.makedirs()`可以创建所有必要的中间文件夹。
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
os.makedirs('D:\\Datawhale\\practice') #查看目录,已创建,若文件夹已存在,不会覆盖,会报错
|
||||||
|
```
|
||||||
|
|
||||||
|
### 1.1.4.2 查看文件大小和文件夹内容
|
||||||
|
我们已经可以处理文件路径,这是操作文件及文件夹的基础。接下来,我们可以搜集特定文件和文件夹的信息。`os.path`模块提供了一些函数,用于查看文件的字节数以及给定文件夹中的文件和子文件夹。
|
||||||
|
`os.path.getsize(path)`:返回path参数中文件的字节数。
|
||||||
|
`os.listdir(path)`:返回文件名字符串的列表,包含path参数中的每个文件。
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.path.getsize('D:\\Datawhale\\python办公自动化\\python课程画图.pptx')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.listdir('D:\\Datawhale\\python办公自动化')
|
||||||
|
```
|
||||||
|
|
||||||
|
如果想知道目录下所有文件的总字节数,可以同时使用`os.path.getsize()`和`os.listdir()`
|
||||||
|
|
||||||
|
```python
|
||||||
|
totalSize = 0
|
||||||
|
for filename in os.listdir('D:\\Datawhale\\python办公自动化'):
|
||||||
|
totalSize = totalSize + os.path.getsize(os.path.join('D:\\Datawhale\\python办公自动化',filename))
|
||||||
|
print(totalSize)
|
||||||
|
```
|
||||||
|
|
||||||
|
## 1.1.6 文件读写过程
|
||||||
|
读写文件3个步骤:
|
||||||
|
|
||||||
|
1.调用`open()`函数,返回一个File对象。
|
||||||
|
|
||||||
|
2.调用File对象的`read()`或`write()`方法。
|
||||||
|
|
||||||
|
3.调用File对象的`close()`方法,关闭该文件。
|
||||||
|
|
||||||
|
### 1.1.6.1 用open()函数打开文件
|
||||||
|
要用`open()`函数打开一个文件,就要向它传递一个字符串路径,表明希望打开的文件。这既可以是绝对路径,也可以是相对路径。`open()`函数返回一个File对象。
|
||||||
|
先用TextEdit创建一个文本文件,名为hello.txt。输入Hello World!作为该文本文件的内容,将它保存在你的用户文件夹中。
|
||||||
|
|
||||||
|
```python
|
||||||
|
helloFile = open('D:\\Datawhale\\python办公自动化\\hello.txt')
|
||||||
|
print(helloFile)
|
||||||
|
```
|
||||||
|
|
||||||
|
可以看到,调用`open()`函数将会返回一个File对象。当你需要读取或写入该文件,就可以调用helloFile变量中的File对象的方法。
|
||||||
|
|
||||||
|
### 1.1.6.2 读取文件内容
|
||||||
|
有了File对象,我们就可以开始从它读取内容。
|
||||||
|
|
||||||
|
`read()`:读取文件内容。
|
||||||
|
|
||||||
|
`readlines()`:按行读取文件中的内容,取得一个字符串列表,列表中每个字符串是文本中的一行且以\n结束。
|
||||||
|
|
||||||
|
```python
|
||||||
|
helloContent = helloFile.read()
|
||||||
|
helloContent
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
sonnetFile = open('D:\\Datawhale\\python办公自动化\\hello.txt')
|
||||||
|
sonnetFile.readlines()
|
||||||
|
```
|
||||||
|
|
||||||
|
### 1.1.6.3 写入文件
|
||||||
|
需要用“写模式”‘w’和“添加模式”'a'打开一个文件,而不能用读模式打开文件。
|
||||||
|
“写模式”将覆写原有的文件,从头开始。“添加模式”将在已有文件的末尾添加文本。
|
||||||
|
|
||||||
|
```python
|
||||||
|
baconFile = open('bacon.txt','w')
|
||||||
|
baconFile.write('Hello world!\n')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
baconFile.close() #注意,关闭后,才能完成写入,从txt文件中看到写入的内容。
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
baconFile = open('bacon.txt','a')
|
||||||
|
baconFile.write('Bacon is not a vegetable.')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
baconFile.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
baconFile = open('bacon.txt')
|
||||||
|
content = baconFile.read()
|
||||||
|
baconFile.close()
|
||||||
|
print(content)
|
||||||
|
```
|
||||||
|
|
||||||
|
注意,`write()`方法不会像print()函数那样,在字符串的末尾自动添加换行字符。必须自己添加该字符。
|
||||||
|
|
||||||
|
### 1.1.6.3 保存变量
|
||||||
|
1)、shelve模块
|
||||||
|
|
||||||
|
用`shelve`模块,可以将Python中的变量保存到二进制的`shelf`文件中。这样,程序就可以从硬盘中恢复变量的数据。
|
||||||
|
|
||||||
|
```python
|
||||||
|
import shelve
|
||||||
|
shelfFile = shelve.open('mydata')
|
||||||
|
cats = ['Zonphie','Pooka','Simon']
|
||||||
|
shelfFile['cats'] = cats
|
||||||
|
shelfFile.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
在Windows上运行前面的代码,我们会看到当前工作目录下有3个新文件:mydata.bak、mydata.dat和mydata.dir。在OS X上,只会创建一个mydata.db文件。
|
||||||
|
|
||||||
|
重新打开这些文件,取出数据。注意:`shelf`值不必用读模式或写模式打开,因为打开后,既能读又能写。
|
||||||
|
|
||||||
|
```python
|
||||||
|
shelfFile = shelve.open('mydata')
|
||||||
|
type(shelfFile)
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
shelve.DbfilenameShelf
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
shelfFile['cats']
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
shelfFile.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
就像字典一样,`shelf`值有`keys()`和`values()`方法,返回shelf中键和值的类似列表的值。但是这些方法返回类似列表的值,却不是真正的列表,所以应该将它们传递给`list()`函数,取得列表的形式。
|
||||||
|
|
||||||
|
```python
|
||||||
|
shelfFile = shelve.open('mydata')
|
||||||
|
list(shelfFile.keys())
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
list(shelfFile.values())
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
shelfFile.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
2)、用`pprint.pformat()`函数保存变量
|
||||||
|
|
||||||
|
`pprint.pformat()`函数返回要打印的内容的文本字符串,这个字符串既易于阅读,也是语法上正确的Python代码。
|
||||||
|
|
||||||
|
假如,有一个字典,保存在一个变量中,希望保存这个变量和它的内容,以便将来使用。`pprint.pformat()`函数将提供一个字符串,我们可以将它写入.py文件。这个文件可以成为我们自己的模块,如果需要使用存储其中的变量,就可以导入它。
|
||||||
|
|
||||||
|
```python
|
||||||
|
import pprint
|
||||||
|
cats = [{'name':'Zophie','desc':'chubby'},{'name':'Pooka','desc':'fluffy'}]
|
||||||
|
pprint.pformat(cats)
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
fileObj = open('myCats.py','w')
|
||||||
|
fileObj.write('cats = '+pprint.pformat(cats)+'\n')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
fileObj.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
import语句导入的模块本身就是Python脚本。如果来自pprint.pformat()的字符串保存为一个.py文件,该文件就是一个可以导入的模块。
|
||||||
|
|
||||||
|
```python
|
||||||
|
import myCats
|
||||||
|
myCats.cats
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
myCats.cats[0]
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
myCats.cats[0]['name']
|
||||||
|
```
|
||||||
|
|
||||||
|
## 1.1.7 练习
|
||||||
|
|
||||||
|
1、如果已有的文件以写模式打开,会发生什么?
|
||||||
|
|
||||||
|
2、`read()`和`readlines()`方法之间的区别是什么?
|
||||||
|
|
||||||
|
综合练习:
|
||||||
|
一、生成随机的测验试卷文件
|
||||||
|
假如你是一位地理老师, 班上有 35 名学生, 你希望进行美国各州首府的一个
|
||||||
|
小测验。不妙的是,班里有几个坏蛋, 你无法确信学生不会作弊。你希望随机调整
|
||||||
|
问题的次序, 这样每份试卷都是独一无二的, 这让任何人都不能从其他人那里抄袭答案。当然,手工完成这件事又费时又无聊。 好在, 你懂一些 Python。
|
||||||
|
|
||||||
|
下面是程序所做的事:
|
||||||
|
|
||||||
|
• 创建 35 份不同的测验试卷。
|
||||||
|
|
||||||
|
• 为每份试卷创建 50 个多重选择题,次序随机。
|
||||||
|
|
||||||
|
• 为每个问题提供一个正确答案和 3 个随机的错误答案,次序随机。
|
||||||
|
|
||||||
|
• 将测验试卷写到 35 个文本文件中。
|
||||||
|
|
||||||
|
• 将答案写到 35 个文本文件中。
|
||||||
|
|
||||||
|
这意味着代码需要做下面的事:
|
||||||
|
|
||||||
|
• 将州和它们的首府保存在一个字典中。
|
||||||
|
|
||||||
|
• 针对测验文本文件和答案文本文件,调用 open()、 write()和 close()。
|
||||||
|
|
||||||
|
• 利用 random.shuffle()随机调整问题和多重选项的次序。
|
||||||
|
|
||||||
|
## 1.2 组织文件
|
||||||
|
|
||||||
|
在上一节中,已经学习了如何使用Python创建并写入新文件。本节将介绍如何用程序组织硬盘上已经存在的文件。不知你是否经历过查找一个文件夹,里面有几十个、几百个、甚至上千个文件,需要手工进行复制、改名、移动或压缩。比如下列这样的任务:
|
||||||
|
|
||||||
|
• 在一个文件夹及其所有子文件夹中,复制所有的 pdf 文件(且只复制 pdf 文件)
|
||||||
|
|
||||||
|
• 针对一个文件夹中的所有文件,删除文件名中前导的零,该文件夹中有数百个文件,名为 spam001.txt、 spam002.txt、 spam003.txt 等。
|
||||||
|
|
||||||
|
• 将几个文件夹的内容压缩到一个 ZIP 文件中(这可能是一个简单的备份系统)
|
||||||
|
|
||||||
|
所有这种无聊的任务,正是在请求用 Python 实现自动化。通过对电脑编程来完成这些任务,你就把它变成了一个快速工作的文件职员,而且从不犯错。
|
||||||
|
|
||||||
|
### 1.2.1 shutil模块
|
||||||
|
|
||||||
|
`shutil`(或称为shell工具)模块中包含一些函数,可以在Python程序中复制、移动、改名和删除文件。要使用`shutil`的函数,首先需要`import shutil`
|
||||||
|
|
||||||
|
#### 1.2.1.1 复制文件和文件夹
|
||||||
|
|
||||||
|
`shutil.copy(source, destination)`:将路径source处的文件复制到路径 destination处的文件夹(source 和 destination 都是字符串),并返回新复制文件绝对路径字符串。
|
||||||
|
|
||||||
|
其中destination可以是:
|
||||||
|
|
||||||
|
1)、一个文件的名称,则将source文件复制为新名称的destination
|
||||||
|
|
||||||
|
2)、一个文件夹,则将source文件复制到destination中
|
||||||
|
|
||||||
|
3)、若这个文件夹不存在,则将source目标文件内的内容复制到destination中,若destination文件夹不存在,则自动生成该文件。(慎用,因为会将source文件复制为一个没有扩展名的名字为destination的文件,这往往不是我们希望的)
|
||||||
|
|
||||||
|
```python
|
||||||
|
import shutil
|
||||||
|
shutil.copy('D:\\Datawhale\\python办公自动化\\bacon.txt', 'D:\\Datawhale\\practice')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
os.getcwd()
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
shutil.copy('D:\\Datawhale\\python办公自动化\\capitalsquiz_answers1.txt', 'D:\\Datawhale\\practice\\bacon.txt')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
shutil.copy('D:\\Datawhale\\python办公自动化\\bacon.txt', 'D:\\Datawhale\\exercise')
|
||||||
|
```
|
||||||
|
|
||||||
|
`shutil.copytree(source, destination)` :将路径source处的文件夹,包括其包含的文件夹和文件,复制到路径destination处的文件夹,并返回新复制文件夹绝对路径字符串。
|
||||||
|
|
||||||
|
注:destination处的文件夹为新创建的文件夹,如已存在,则会报错
|
||||||
|
|
||||||
|
```python
|
||||||
|
import shutil
|
||||||
|
shutil.copytree('D:\\Datawhale\\python办公自动化','D:\\Datawhale\\practice')
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 1.2.1.2 文件和文件夹的移动与改名
|
||||||
|
|
||||||
|
`shutil.move(source, destination)`:将路径 source 处的文件/文件夹移动到路径destination,并返回新位置的绝对路径的字符串。
|
||||||
|
|
||||||
|
1)、如果source和destination是文件夹,且destination已存在,则会将source文件夹下所有内容复制到destination文件夹中。移动。
|
||||||
|
|
||||||
|
2)、如果source是文件夹,destination不存在,则会将source文件夹下所有内容复制到destination文件夹中,source原文件夹名称将被替换为destination文件夹名。 移动+重命名
|
||||||
|
|
||||||
|
3)、如果source和destination是文件,source处的文件将被移动到destination处的位置,并以destination处的文件名进行命名,移动+重命名。
|
||||||
|
|
||||||
|
注意:如果destination中有原来已经存在同名文件,移动后,会被覆写,所以应当特别注意。
|
||||||
|
|
||||||
|
```python
|
||||||
|
import shutil
|
||||||
|
shutil.move('D:\\Datawhale\\practice','D:\\Datawhale\\docu')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
shutil.move('D:\\Datawhale\\practice','D:\\Datawhale\\docue')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
shutil.move('D:\\Datawhale\\docue\\bacon.txt','D:\\Datawhale\\docu\\egg.txt')
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 1.2.1.3 永久删除文件和文件夹
|
||||||
|
`os.unlink(path)`: 删除path处的文件。
|
||||||
|
|
||||||
|
`os.rmdir(path)`: 删除path处的文件夹。该文件夹必须为空,其中没有任何文件和文件夹。
|
||||||
|
|
||||||
|
`shutil.rmtree(path)`:删除 path 处的文件夹,它包含的所有文件和文件夹都会被删除。
|
||||||
|
|
||||||
|
注意:使用时,需要非常小心,避免删错文件,一般在第一次运行时,注释掉这些程序,并加上`print()`函数来帮助查看是否是想要删除的文件。
|
||||||
|
|
||||||
|
```python
|
||||||
|
#建议先指定操作的文件夹,并查看
|
||||||
|
os.chdir('D:\\Datawhale\\docue')
|
||||||
|
os.getcwd()
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
for filename in os.listdir():
|
||||||
|
if filename.endswith('.dir'):
|
||||||
|
#os.unlink(filename)
|
||||||
|
print(filename)
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 1.2.1.4 用send2trash模块安全地删除
|
||||||
|
`shutil.rmtree(path)`会不可恢复的删除文件和文件夹,用起来会有危险。因此使用第三方的`send2trash`模块,可以将文件或文件夹发送到计算机的垃圾箱或回收站,而不是永久删除。因程序缺陷而用send2trash 删除的某些你不想删除的东西,稍后可以从垃圾箱恢复。
|
||||||
|
|
||||||
|
注意:使用时,需要非常小心,避免删错文件,一般在第一次运行时,注释掉这些程序,并加上`print()`函数来帮助查看是否是想要删除的文件。
|
||||||
|
|
||||||
|
```python
|
||||||
|
pip install send2trash #安装send2trash模块
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
import send2trash
|
||||||
|
send2trash.send2trash('bacon.txt')
|
||||||
|
```
|
||||||
|
|
||||||
|
## 1.2.2 遍历目录树
|
||||||
|
`os.walk(path)`:传入一个文件夹的路径,在for循环语句中使用`os.walk()`函数,遍历目录树,和range()函数遍历一个范围的数字类似。不同的是,`os.walk()`在循环的每次迭代中,返回三个值:
|
||||||
|
|
||||||
|
1)、当前文件夹称的字符串。
|
||||||
|
|
||||||
|
2)、当前文件夹中子文件夹的字符串的列表。
|
||||||
|
|
||||||
|
3)、当前文件夹中文件的字符串的列表。
|
||||||
|
|
||||||
|
注:当前文件夹,是指for循环当前迭代的文件夹。程序的当前工作目录,不会因为`os.walk()`而改变。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
按照下图目录树,创建相应的文件。
|
||||||
|
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
for folderName, subFolders,fileNames in os.walk('D:\\animals'):
|
||||||
|
print('The current folder is ' + folderName)
|
||||||
|
for subFolder in subFolders:
|
||||||
|
print('Subfolder of ' + folderName+':'+subFolder)
|
||||||
|
for filename in fileNames:
|
||||||
|
print('File Inside ' + folderName+':'+filename)
|
||||||
|
print('')
|
||||||
|
```
|
||||||
|
|
||||||
|
## 1.2.3 用zipfile模块压缩文件
|
||||||
|
|
||||||
|
为方便传输,常常将文件打包成.zip格式文件。利用zipfile模块中的函数,Python程序可以创建和打开(或解压)zip文件。
|
||||||
|
|
||||||
|
### 1.2.3.1 创建和添加到zip文件
|
||||||
|
|
||||||
|
将上述章节中animals文件夹进行压缩。创建一个example.zip的zip文件,并向其中添加文件。
|
||||||
|
|
||||||
|
`zipfile.ZipFile('filename.zip', 'w')` :以写模式创建一个压缩文件
|
||||||
|
|
||||||
|
`ZipFile` 对象的 `write('filename','compress_type=zipfile.ZIP_DEFLATED')`方法:如果向`write()`方法中传入一个路径,Python 就会压缩该路径所指的文件, 将它加到 ZIP 文件中。 如果向`write()`方法中传入一个字符串,代表要添加的文件名。第二个参数是“压缩类型”参数,告诉计算机用怎样的算法来压缩文件。可以总是将这个值设置为 `zipfile.ZIP_DEFLATED`(这指定了 deflate 压缩算法,它对各种类型的数据都很有效)。
|
||||||
|
|
||||||
|
注意:写模式会擦除zip文件中所有原有的内容。如果只希望将文件添加到原有的zip文件中,就要向`zipfile.ZipFile()`传入'a'作为第二个参数,以添加模式打开 ZIP 文件。
|
||||||
|
|
||||||
|
```python
|
||||||
|
## 1 创建一个new.zip压缩文件,并向其中添加文件
|
||||||
|
import zipfile
|
||||||
|
newZip = zipfile.ZipFile('new.zip','w')
|
||||||
|
newZip.write('Miki.txt',compress_type=zipfile.ZIP_DEFLATED)
|
||||||
|
newZip.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
newZip = zipfile.ZipFile('new.zip','w')
|
||||||
|
newZip.write('D:\\animals\\dogs\\Taidi.txt',compress_type=zipfile.ZIP_DEFLATED)
|
||||||
|
newZip.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
## 2 创建一个example.zip的压缩文件,将animals文件夹下所有文件进行压缩。
|
||||||
|
import zipfile
|
||||||
|
import os
|
||||||
|
newZip = zipfile.ZipFile('example.zip','w')
|
||||||
|
for folderName, subFolders,fileNames in os.walk('D:\\animals'):
|
||||||
|
for filename in fileNames:
|
||||||
|
newZip.write(os.path.join(folderName,filename),compress_type=zipfile.ZIP_DEFLATED)
|
||||||
|
newZip.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
### 1.2.3.2 读取zip文件
|
||||||
|
|
||||||
|
调用`zipfile.ZipFile(filename)`函数创建一个`ZipFile`对象(注意大写字母Z和F),filename是要读取zip文件的文件名。
|
||||||
|
|
||||||
|
`ZipFile`对象中的两个常用方法:
|
||||||
|
|
||||||
|
`namelis()`方法,返回zip文件中包含的所有文件和文件夹的字符串列表。
|
||||||
|
|
||||||
|
`getinfo()`方法,返回一个关于特定文件的`ZipInfo`对象。
|
||||||
|
|
||||||
|
`ZipInfo`对象的两个属性:`file_size`和`compress_size`,分别表示原来文件大小和压缩后文件大小。1.2.3.2 读取zip文件
|
||||||
|
|
||||||
|
```
|
||||||
|
import zipfile,os
|
||||||
|
exampleZip = zipfile.ZipFile('example.zip')
|
||||||
|
exampleZip.namelist()
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
catInfo = exampleZip.getinfo('animals/Miki.txt')
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
catInfo.file_size
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
catInfo.compress_size
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
print('Compressed file is %s x smaller!' %(round(catInfo.file_size/catInfo.compress_size,2)))
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
exampleZip.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
### 1.2.3.3 从zip文件中解压缩
|
||||||
|
|
||||||
|
`ZipFile` 对象的 `extractall()`方法:从zip文件中解压缩所有文件和文件夹,放到当前工作目录中。也可以向`extractall()`传递的一个文件夹名称,它将文件解压缩到那个文件夹, 而不是当前工作目录。如果传递的文件夹名称不存在,就会被创建。
|
||||||
|
|
||||||
|
`ZipFile` 对象的 `extract()`方法:从zip文件中解压单个文件。也可以向 extract()传递第二个参数, 将文件解压缩到指定的文件夹, 而不是当前工作目录。如果第二个参数指定的文件夹不存在, Python 就会创建它。extract()的返回值是被压缩后文件的绝对路径。
|
||||||
|
|
||||||
|
```python
|
||||||
|
import zipfile, os
|
||||||
|
exampleZip = zipfile.ZipFile('example.zip')
|
||||||
|
exampleZip.extractall('.\zip')
|
||||||
|
exampleZip.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
exampleZip = zipfile.ZipFile('example.zip')
|
||||||
|
exampleZip.extract('animals/Miki.txt')
|
||||||
|
exampleZip.extract('animals/Miki.txt', 'D:\\animals\\folders')
|
||||||
|
exampleZip.close()
|
||||||
|
```
|
||||||
|
|
||||||
|
## 1.2.4 练习
|
||||||
|
|
||||||
|
1)、编写一个程序,遍历一个目录树,查找特定扩展名的文件(诸如.pdf 或.jpg)。不论这些文件的位置在哪里, 将它们拷贝到一个新的文件夹中。
|
||||||
|
|
||||||
|
2) 、一些不需要的、 巨大的文件或文件夹占据了硬盘的空间, 这并不少见。如果你试图释放计算机上的空间, 那么删除不想要的巨大文件效果最好。但首先你必须找到它们。编写一个程序, 遍历一个目录树, 查找特别大的文件或文件夹, 比方说, 超过100MB 的文件(回忆一下,要获得文件的大小,可以使用 os 模块的 `os.path.getsize()`)。将这些文件的绝对路径打印到屏幕上。
|
||||||
|
|
||||||
|
3)、编写一个程序, 在一个文件夹中, 找到所有带指定前缀的文件, 诸如 spam001.txt,spam002.txt 等,并定位缺失的编号(例如存在 spam001.txt 和 spam003.txt, 但不存在 spam002.txt)。让该程序对所有后面的文件改名, 消除缺失的编号。作为附加的挑战,编写另一个程序,在一些连续编号的文件中,空出一些编号,以便加入新的文件。
|
||||||
|
|
||||||
|
## 2 自动发送电子邮件
|
||||||
|
|
||||||
|
使用Python实现自动化邮件发送,可以让你摆脱繁琐的重复性业务,节省非常多的时间。
|
||||||
|
|
||||||
|
Python有两个内置库:`smtplib`和`email`,能够实现邮件功能,`smtplib`库负责发送邮件,`email`库负责构造邮件格式和内容。
|
||||||
|
|
||||||
|
邮件发送需要遵守**SMTP**协议,Python内置对SMTP的支持,可以发送纯文本邮件、HTML邮件以及带附件的邮件。
|
||||||
|
|
||||||
|
```python
|
||||||
|
#1 先导入相关的库和方法
|
||||||
|
import smtplib #导入库
|
||||||
|
from smtplib import SMTP_SSL #加密邮件内容,防止中途被截获
|
||||||
|
from email.mime.text import MIMEText #构造邮件的正文
|
||||||
|
from email.mime.image import MIMEImage #构造邮件的图片
|
||||||
|
from email.mime.multipart import MIMEMultipart #把邮件的各个部分装在一起,邮件的主体
|
||||||
|
from email.header import Header #邮件的文件头,标题,收件人
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
#2 设置邮箱域名、发件人邮箱、邮箱授权码、收件人邮箱
|
||||||
|
host_server = 'smtp.163.com' #sina 邮箱smtp服务器 #smtp 服务器的地址
|
||||||
|
sender_163 = 'pythonauto_emai@163.com' #sender_163为发件人的邮箱
|
||||||
|
pwd = 'DYEPOGLZDZYLOMRI' #pwd为邮箱的授权码'DYEPOGLZDZYLOMRI'
|
||||||
|
#也可以自己注册个邮箱,邮箱授权码'DYEPOGLZDZYLOMRI' 获取方式可参考#http://help.163.com/14/0923/22/A6S1FMJD00754KNP.html
|
||||||
|
receiver = '********@163.com'
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
#3 构建MIMEMultipart对象代表邮件本身,可以往里面添加文本、图片、附件等
|
||||||
|
msg = MIMEMultipart() #邮件主体
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
#4 设置邮件头部内容
|
||||||
|
mail_title = 'python办公自动化邮件' # 邮件标题
|
||||||
|
msg["Subject"] = Header(mail_title,'utf-8') #装入主体
|
||||||
|
msg["From"] = sender_163 #寄件人
|
||||||
|
msg["To"] = Header("测试邮箱",'utf-8') #标题
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
#5 添加正文文本
|
||||||
|
mail_content = "您好,这是使用python登录163邮箱发送邮件的测试" #邮件的正文内容
|
||||||
|
message_text = MIMEText(mail_content,'plain','utf-8') #构造文本,参数1:正文内容,参数2:文本格式,参数3:编码方式
|
||||||
|
msg.attach(message_text) # 向MIMEMultipart对象中添加文本对象
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
#6 添加图片
|
||||||
|
image_data = open('cat.jpg','rb') # 二进制读取图片
|
||||||
|
message_image = MIMEImage(image_data.read()) # 设置读取获取的二进制数据
|
||||||
|
image_data.close() # 关闭刚才打开的文件
|
||||||
|
msg.attach(message_image) # 添加图片文件到邮件信息当中去
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 7 添加附件(excel表格)
|
||||||
|
atta = MIMEText(open('cat.xlsx', 'rb').read(), 'base64', 'utf-8') # 构造附件
|
||||||
|
atta["Content-Disposition"] = 'attachment; filename="cat.xlsx"' # 设置附件信息
|
||||||
|
msg.attach(atta) ## 添加附件到邮件信息当中去
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
#8 发送邮件
|
||||||
|
smtp = SMTP_SSL(host_server) #SSL登录 创建SMTP对象
|
||||||
|
smtp.login(sender_163,pwd) ## 登录邮箱,传递参数1:邮箱地址,参数2:邮箱授权码
|
||||||
|
smtp.sendmail(sender_163,receiver,msg.as_string()) # 发送邮件,传递参数1:发件人邮箱地址,参数2:收件人邮箱地址,参数3:把邮件内容格式改为str
|
||||||
|
print("邮件发送成功")
|
||||||
|
smtp.quit # 关闭SMTP对象
|
||||||
|
```
|
||||||
|
|
||||||
@@ -0,0 +1,396 @@
|
|||||||
|
# Python自动化之Excel
|
||||||
|
|
||||||
|
方法一:应用pip执行命令
|
||||||
|
|
||||||
|
安装**openpyxl**模块`pip install openpyxl`
|
||||||
|
|
||||||
|
方法二:在Pycharm中:File->Setting->左侧Project Interpreter
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Excel读取
|
||||||
|
|
||||||
|
#### 读取对应表格
|
||||||
|
|
||||||
|
1. 打开已经存在的Excel表格
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl imporg load_workbook
|
||||||
|
|
||||||
|
exl = load_workbook(filename = 'test.xlsx')
|
||||||
|
print(elx.sheetnames)
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 根据名称或去表格
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import load_workbook
|
||||||
|
|
||||||
|
exl_1 = load_workbook(filename = 'test.xlsx')
|
||||||
|
print(exl_1.sheetnames)
|
||||||
|
|
||||||
|
sheet = elx_1['work']
|
||||||
|
|
||||||
|
'若只有一张表则:'
|
||||||
|
sheet = elx_1.active
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 获取Excel 内容占据的大小
|
||||||
|
|
||||||
|
```
|
||||||
|
print(sheet.dimensions)
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 读取单元格
|
||||||
|
|
||||||
|
1. 获取某个单元格的具体内容
|
||||||
|
|
||||||
|
```
|
||||||
|
cell = sheet.cell(row=1,column=2) #指定行列数
|
||||||
|
print(cell.value)
|
||||||
|
|
||||||
|
cell_1 = sheet['A1'] #指定坐标
|
||||||
|
print(cell_1.value)
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 获取单元格对应的行、列和坐标
|
||||||
|
|
||||||
|
```
|
||||||
|
print(cell_1.row, cell_column, cell.coordinate)
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 读取多个格子的值
|
||||||
|
|
||||||
|
1. 指定坐标范围
|
||||||
|
|
||||||
|
```
|
||||||
|
cells = sheet['A1:C8'] #A1到C8区域的值
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 指定行的值
|
||||||
|
|
||||||
|
```
|
||||||
|
Row = sheet[1] #第1行的值
|
||||||
|
Rows = sheet[1:2] #第1到2行的值
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 指定列的值
|
||||||
|
|
||||||
|
```
|
||||||
|
Column = sheet['A'] #第A列
|
||||||
|
Columns = sheet['A:C'] #第A到C列
|
||||||
|
```
|
||||||
|
|
||||||
|
4. 指定范围的值
|
||||||
|
|
||||||
|
```
|
||||||
|
# 行获取
|
||||||
|
for row in sheet.iter_rows(min_row = 1, max_row = 5,
|
||||||
|
min_col = 2, max_col = 6):
|
||||||
|
print(row)
|
||||||
|
# 一列由多个单元格组成,若需要获取每个单元格的值则循环获取即可
|
||||||
|
for cell in row:
|
||||||
|
print(cell.value)
|
||||||
|
|
||||||
|
# 列获取
|
||||||
|
for col in sheet.iter_cols(min_row = 1, max_row = 5,
|
||||||
|
min_col = 2, max_col = 6):
|
||||||
|
print(col)
|
||||||
|
|
||||||
|
for cell in col:
|
||||||
|
print(cell.value)
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 练习题
|
||||||
|
|
||||||
|
找出text_1.xlsx中sheet1表中空着的格子,并输出这些格子的坐标
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import load_workbook
|
||||||
|
|
||||||
|
exl = load_workbood('test_1.xlsx')
|
||||||
|
sheet = exl.active
|
||||||
|
for row in sheet.iter_rows(min_row = 1, max_row = 29972,
|
||||||
|
min_col = 1, max_col = 10):
|
||||||
|
#具体查看对应表格的行列数
|
||||||
|
for cell in row:
|
||||||
|
if not cell.value:
|
||||||
|
print(cell.coordinate)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Excel写入
|
||||||
|
|
||||||
|
#### 写入单元格并保存
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import load_workbook
|
||||||
|
|
||||||
|
exl = load_workbook(filename = 'test.xlsx')
|
||||||
|
sheet = exl.active
|
||||||
|
sheet['A1'] = 'hello word'
|
||||||
|
#或者cell = sheet['A1']
|
||||||
|
#cell.value = 'hello word'
|
||||||
|
exl.save(filename = 'test.xlsx') #存入原Excel表中,若创建新文件则可命名为不同名称
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 写入行数据并保存
|
||||||
|
|
||||||
|
1. 写入一行数据并保存
|
||||||
|
|
||||||
|
```
|
||||||
|
import wlwt
|
||||||
|
# 应用write中的参数,对应 行, 列, 值
|
||||||
|
sheet.write(1,0, label = 'this is test')
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 写入多行数据并保存
|
||||||
|
|
||||||
|
```
|
||||||
|
#应用sheet.append()
|
||||||
|
data = [['hello',22,'hi'],
|
||||||
|
['hell',23,'h'],
|
||||||
|
['he',25,'him']]
|
||||||
|
for i in data:
|
||||||
|
sheet.append(i)
|
||||||
|
exl.save(filename = 'test.xlsx')
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 将公式写入单元格保存
|
||||||
|
|
||||||
|
```
|
||||||
|
sheet['A2'] = 'SUM(A1:D1)'
|
||||||
|
exl.save(filename='test.xlsx')
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 插入列数据
|
||||||
|
|
||||||
|
1. 插入一列
|
||||||
|
|
||||||
|
```
|
||||||
|
sheet.insert_cols(idx=2) #idx=2第2列,第2列前插入一列
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 插入多列
|
||||||
|
|
||||||
|
```
|
||||||
|
#第2列前插入5列作为举例
|
||||||
|
sheet.insert_cols(idx=2, amount=5)
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 插入行数据
|
||||||
|
|
||||||
|
第2行前上面插入一行(或多行)
|
||||||
|
|
||||||
|
```
|
||||||
|
#插入一行
|
||||||
|
sheet.insert_cols(idx=2)
|
||||||
|
#插入多行
|
||||||
|
sheet.insert_cols(idx=2, amount=5)
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 删除
|
||||||
|
|
||||||
|
1. 删除多列
|
||||||
|
|
||||||
|
```
|
||||||
|
sheet.delete_cols(idx=5, amount=2) #第5列前删除2列
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 删除多行
|
||||||
|
|
||||||
|
```
|
||||||
|
sheet.delete_rows(idx=2, amount=5)
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 移动
|
||||||
|
|
||||||
|
当数字为正即向下或向右,为负即为向上或向左
|
||||||
|
|
||||||
|
```
|
||||||
|
sheet.move_range('C5:F10', row=2, cols=-3)
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Sheet表操作
|
||||||
|
|
||||||
|
1. 创建新的sheet
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import load_workbook
|
||||||
|
|
||||||
|
exl = load_workbook(filename = 'test.xlsx')
|
||||||
|
print(exl.sheetnames)
|
||||||
|
|
||||||
|
exl.create_sheet('new_sheet')
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 复制已有的sheet
|
||||||
|
|
||||||
|
```
|
||||||
|
exl.copy_worksheet(sheet)
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 修改sheet表名
|
||||||
|
|
||||||
|
```
|
||||||
|
sheet = exl.active
|
||||||
|
sheet.title = 'newname'
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 创建新的Excel表
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import load_workbook
|
||||||
|
|
||||||
|
workbook = Workbook()
|
||||||
|
sheet = workbook.active
|
||||||
|
workbook.save(filename = 'newtest.xlsx')
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Excel 样式
|
||||||
|
|
||||||
|
#### 设置字体样式
|
||||||
|
|
||||||
|
1. 设置字体样式
|
||||||
|
|
||||||
|
`Font(name字体名称,size大小,bold粗体,italic斜体,color颜色)`
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import Workbook
|
||||||
|
from openpyxl.styles import Font
|
||||||
|
|
||||||
|
workbook = Workbook()
|
||||||
|
sheet = workbook.active
|
||||||
|
cell = sheet['A1']
|
||||||
|
font = Font(name='字体', sizee=10, bold=True, italic=True, color='FF0000')
|
||||||
|
cell.font = font
|
||||||
|
workbook.save(filename='new_test')
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 设置多个格子的字体样式
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import Workbook
|
||||||
|
from openpyxl.styles import Font
|
||||||
|
|
||||||
|
workbook = Workbook()
|
||||||
|
sheet = workbook.active
|
||||||
|
cells = sheet[2]
|
||||||
|
font = Font(name='字体', sizee=10, bold=True, italic=True, color='FF000000')
|
||||||
|
for cell in cells:
|
||||||
|
cell.font = font
|
||||||
|
workbook.save(filename='new_test')
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 设置对其样式
|
||||||
|
|
||||||
|
水平对齐:`distributed, justify, center, left, fill, centerContinuous, right, general`
|
||||||
|
|
||||||
|
垂直对齐:`bottom, distributed, justify, center, top`
|
||||||
|
|
||||||
|
1. 设置单元格边框样式
|
||||||
|
|
||||||
|
`Side(style变现样式, color边线颜色)`
|
||||||
|
|
||||||
|
`Border(左右上下边线)`
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import Workbook
|
||||||
|
from openpyxl.styles import Font
|
||||||
|
|
||||||
|
workbook = Workbook()
|
||||||
|
sheet = workbook.active
|
||||||
|
cell = sheet['A1']
|
||||||
|
side = Side(style='thin', color='FF000000')
|
||||||
|
#先定好side的格式
|
||||||
|
border = Border(left=side, right=side, top=side, bottom=side)
|
||||||
|
#代入边线中
|
||||||
|
cell.border = border
|
||||||
|
workbook.save(filename='new_test')
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 设置单元格边框样式
|
||||||
|
|
||||||
|
变现样式:`double, mediumDashDotDot, slantDashDot, dashDotDot, dotted, hair, mediumDashed, dashed, dashDot, thin, mediumDashDot, medium, thick `
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import Workbook
|
||||||
|
from openpyxl.styles import Font
|
||||||
|
|
||||||
|
workbook = Workbook()
|
||||||
|
sheet = workbook.active
|
||||||
|
cell = sheet['A1']
|
||||||
|
pattern_fill = PatternFill(fill_type='solid', fgColor
|
||||||
|
cell1.fill = pattern_fill
|
||||||
|
#单色填充
|
||||||
|
cell2 = sheet['A3']
|
||||||
|
gradient_fill = GradientFill(stop=('FFFFFF', '99ccff','000000'))
|
||||||
|
cell2.fill = gradient_fill
|
||||||
|
#渐变填充
|
||||||
|
workbook.save(filename='new_test')
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 设置行高与列宽
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import Workbook
|
||||||
|
|
||||||
|
workbook = Workbook()
|
||||||
|
sheet = workbook.active
|
||||||
|
sheet.row_dimensions[1].height = 50
|
||||||
|
sheet.column_dimensions['C'].width = 20 workbook.save(filename='new_test')
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 合并、取消合并单元格
|
||||||
|
|
||||||
|
```
|
||||||
|
sheet.merge_cells('A1:B2')
|
||||||
|
sheet.merge_cells(start_row=1, start_column=3,
|
||||||
|
end_row=2, end_column=4)
|
||||||
|
|
||||||
|
sheet.unmerge_cells('A1:B2')
|
||||||
|
sheet.unmerge_cells(start_row=1, start_column=3,
|
||||||
|
end_row=2, end_column=4)
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 练习题
|
||||||
|
|
||||||
|
```
|
||||||
|
from openpyxl import load_workbook
|
||||||
|
from openpyxl.styles import Font, Side, Border
|
||||||
|
|
||||||
|
workbook = load_workbook('./test.xlsx')
|
||||||
|
sheet = workbook.active
|
||||||
|
buy_mount = sheet['F']
|
||||||
|
row_lst = []
|
||||||
|
|
||||||
|
for cell in buy_mount:
|
||||||
|
if isinstance(cell.value, int) and cell.value > 5:
|
||||||
|
print(cell.row)
|
||||||
|
row_lst.append(cell.row)
|
||||||
|
|
||||||
|
side = Side(style='thin', color='FF000000')
|
||||||
|
border = Border(left=side, right=side, top=side, bottom=side)
|
||||||
|
font = Font(bold=True, color='FF0000')
|
||||||
|
for row in row_lst:
|
||||||
|
for cell in sheet[row]:
|
||||||
|
cell.font = font
|
||||||
|
cell.border = border
|
||||||
|
workbook.save('new_test'.xlsx')
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@@ -0,0 +1,444 @@
|
|||||||
|
# python自动化之word操作
|
||||||
|
|
||||||
|
[TOC]
|
||||||
|
|
||||||
|
|
||||||
|
## 一、课前准备
|
||||||
|
|
||||||
|
> python 处理 Word 需要用到 python-docx 库,终端执行如下安装命令:
|
||||||
|
|
||||||
|
```pyhton
|
||||||
|
pip3 install python-docx
|
||||||
|
```
|
||||||
|
|
||||||
|
> 或在pycharm的setting操作安装(示意如下):
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 二、知识要点
|
||||||
|
|
||||||
|
> 说明:
|
||||||
|
> 1. 通过小试牛刀初步认识docx,然后系统学习python对word的操作;
|
||||||
|
> 2. 预估每个知识点需要讲解的时间;
|
||||||
|
> 3. 研发逻辑就是讲解逻辑,一般从上往下,遵循:`What - Why - How` 或 `Why - What - How` 思路;
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 1.预热:初步认识docx
|
||||||
|
|
||||||
|
相信同学们都进行过word的操作。话不多说,直接上python对word简单操作的代码,先有个直观的感觉,然后再系统学习!
|
||||||
|
|
||||||
|
#### (1)新建空白word并插入文字
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 导入库
|
||||||
|
from docx import Document
|
||||||
|
|
||||||
|
# 新建空白文档
|
||||||
|
doc_1 = Document()
|
||||||
|
|
||||||
|
# 添加标题(0相当于文章的题目,默认级别是1,级别范围为0-9)
|
||||||
|
doc_1.add_heading('新建空白文档标题,级别为0',level = 0)
|
||||||
|
doc_1.add_heading('新建空白文档标题,级别为1',level = 1)
|
||||||
|
doc_1.add_heading('新建空白文档标题,级别为2',level = 2)
|
||||||
|
|
||||||
|
# 新增段落
|
||||||
|
paragraph_1 = doc_1.add_paragraph('这是第一段文字的开始\n请多多关照!')
|
||||||
|
# 加粗
|
||||||
|
paragraph_1.add_run('加粗字体').bold = True
|
||||||
|
paragraph_1.add_run('普通字体')
|
||||||
|
# 斜体
|
||||||
|
paragraph_1.add_run('斜体字体').italic =True
|
||||||
|
|
||||||
|
# 新段落(当前段落的下方)
|
||||||
|
paragraph_2 = doc_1.add_paragraph('新起的第二段文字。')
|
||||||
|
|
||||||
|
# 新段落(指定端的上方)
|
||||||
|
prior_paragraph = paragraph_1.insert_paragraph_before('在第一段文字前插入的段落')
|
||||||
|
|
||||||
|
# 添加分页符(可以进行灵活的排版)
|
||||||
|
doc_1.add_page_break()
|
||||||
|
# 新段落(指定端的上方)
|
||||||
|
paragraph_3 = doc_1.add_paragraph('这是第二页第一段文字!')
|
||||||
|
|
||||||
|
# 保存文件(当前目录下)
|
||||||
|
doc_1.save('doc_1.docx')
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 2. 正式:python自动化之word操作
|
||||||
|
|
||||||
|
上节只是小试牛刀一下,接下来我们系统地学习python自动化之word操作。
|
||||||
|
|
||||||
|
在操作之前,我们需要了解 Word 文档的<font color=red>页面结构</font> :
|
||||||
|
|
||||||
|
- 文档 - Document
|
||||||
|
- 段落 - Paragraph
|
||||||
|
- 文字块 - Run
|
||||||
|
|
||||||
|
**`python-docx`**将整个文章看做是一个**`Document`**对象 ,其基本结构如下:
|
||||||
|
|
||||||
|
- 每个**`Document`**包含许多个代表“段落”的**`Paragraph`**对象,存放在**`document.paragraphs`**中。
|
||||||
|
- 每个**`Paragraph`**都有许多个代表"行内元素"的**`Run`**对象,存放在**`paragraph.runs`**中。
|
||||||
|
|
||||||
|
在**`python-docx`**中,**`run`**是最基本的单位,每个**`run`**对象内的文本样式都是一致的,也就是说,在从**`docx`**文件生成文档对象时,**`python-docx`**会根据样式的变化来将文本切分为一个个的`Run`对象。
|
||||||
|
|
||||||
|
#### (1)整体页面结构介绍
|
||||||
|
|
||||||
|
我们以一个小案例为主线把文档,段落和文字块串一下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 导入库
|
||||||
|
from docx import Document
|
||||||
|
from docx.shared import RGBColor, Pt,Inches,Cm
|
||||||
|
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
|
||||||
|
from docx.oxml.ns import qn
|
||||||
|
|
||||||
|
# 新建文档(Datawhale)
|
||||||
|
doc_1 = Document()
|
||||||
|
|
||||||
|
# 字体设置(全局)
|
||||||
|
'''只更改font.name是不够的,还需要调用._element.rPr.rFonts的set()方法。'''
|
||||||
|
|
||||||
|
doc_1.styles['Normal'].font.name = u'宋体'
|
||||||
|
doc_1.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
|
||||||
|
|
||||||
|
# 添加标题(0相当于文章的题目,默认级别是1,级别范围为0-9,0时候自动带下划线)
|
||||||
|
heading_1 = doc_1.add_heading('周杰伦',level = 0)
|
||||||
|
heading_1.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中对齐,默认居左对齐
|
||||||
|
|
||||||
|
# 新增段落
|
||||||
|
paragraph_1 = doc_1.add_paragraph()
|
||||||
|
'''
|
||||||
|
设置段落格式:首行缩进0.75cm,居左,段后距离1.0英寸,1.5倍行距。
|
||||||
|
'''
|
||||||
|
paragraph_1.paragraph_format.first_line_indent = Cm(0.75)
|
||||||
|
paragraph_1.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT
|
||||||
|
paragraph_1.paragraph_format.space_after = Inches(1.0)
|
||||||
|
paragraph_1.paragraph_format.line_spacing = 1.5
|
||||||
|
|
||||||
|
text = '中国台湾华语流行歌手、' \
|
||||||
|
'音乐创作家、作曲家、作词人、' \
|
||||||
|
'制作人、杰威尔音乐公司老板之一、导演。' \
|
||||||
|
'近年涉足电影行业。周杰伦是2000年后亚洲流行乐坛最具革命性与指标' \
|
||||||
|
'性的创作歌手,有“亚洲流行天王”之称。他突破原有亚洲音乐的主题、形' \
|
||||||
|
'式,融合多元的音乐素材,创造出多变的歌曲风格,尤以融合中西式曲风的嘻哈' \
|
||||||
|
'或节奏蓝调最为著名,可说是开创华语流行音乐“中国风”的先声。周杰伦的' \
|
||||||
|
'出现打破了亚洲流行乐坛长年停滞不前的局面,为亚洲流行乐坛翻开了新的一页!'
|
||||||
|
|
||||||
|
r_1 = paragraph_1.add_run(text)
|
||||||
|
r_1.font.size =Pt(10) #字号
|
||||||
|
r_1.font.bold =True #加粗
|
||||||
|
r_1.font.color.rgb =RGBColor(255,0,0) #颜色
|
||||||
|
|
||||||
|
# 保存文件(当前目录下)
|
||||||
|
doc_1.save('周杰伦.docx')
|
||||||
|
```
|
||||||
|
通过上例我们可以看到,最小的操作对象为文字块,通过run的指定进行操作。比如字号,颜色等;而再上一个层级--段落是的格式是通过paragraph_format进行设置;
|
||||||
|
|
||||||
|
#### (2)字体设置
|
||||||
|
|
||||||
|
通过(1),同学们已经注意到,字体的设置是全局变量。如果我想在不同的部分进行不同字体的设置,那该怎么办呢?这就需要在应用前操作设置一下。
|
||||||
|
|
||||||
|
```python
|
||||||
|
'''字体设置1.py'''
|
||||||
|
#导入库
|
||||||
|
from docx import Document
|
||||||
|
from docx.oxml.ns import qn
|
||||||
|
from docx.enum.style import WD_STYLE_TYPE
|
||||||
|
|
||||||
|
document = Document() # 新建docx文档
|
||||||
|
|
||||||
|
# 设置宋体字样式
|
||||||
|
style_font = document.styles.add_style('宋体', WD_STYLE_TYPE.CHARACTER)
|
||||||
|
style_font.font.name = '宋体'
|
||||||
|
document.styles['宋体']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
|
||||||
|
|
||||||
|
# 设置楷体字样式
|
||||||
|
style_font = document.styles.add_style('楷体', WD_STYLE_TYPE.CHARACTER)
|
||||||
|
style_font.font.name = '楷体'
|
||||||
|
document.styles['楷体']._element.rPr.rFonts.set(qn('w:eastAsia'), u'楷体') # 将段落中的所有字体
|
||||||
|
|
||||||
|
# 设置华文中宋字样式
|
||||||
|
style_font = document.styles.add_style('华文中宋', WD_STYLE_TYPE.CHARACTER)
|
||||||
|
style_font.font.name = '华文中宋'
|
||||||
|
document.styles['华文中宋']._element.rPr.rFonts.set(qn('w:eastAsia'), u'华文中宋')
|
||||||
|
|
||||||
|
paragraph1 = document.add_paragraph() # 添加段落
|
||||||
|
run = paragraph1.add_run(u'aBCDefg这是中文', style='宋体') # 设置宋体样式
|
||||||
|
|
||||||
|
font = run.font #设置字体
|
||||||
|
font.name = 'Cambira' # 设置西文字体
|
||||||
|
paragraph1.add_run(u'aBCDefg这是中文', style='楷体').font.name = 'Cambira'
|
||||||
|
paragraph1.add_run(u'aBCDefg这是中文', style='华文中宋').font.name = 'Cambira'
|
||||||
|
|
||||||
|
document.save('字体设置1.docx')
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
'''字体设置2.py'''
|
||||||
|
#导入库
|
||||||
|
from docx import Document
|
||||||
|
from docx.oxml.ns import qn
|
||||||
|
from docx.enum.style import WD_STYLE_TYPE
|
||||||
|
|
||||||
|
#定义字体设置函数
|
||||||
|
def font_setting(doc,text,font_cn):
|
||||||
|
style_add = doc.styles.add_style(font_cn, WD_STYLE_TYPE.CHARACTER)
|
||||||
|
style_add.font.name = font_cn
|
||||||
|
doc.styles[font_cn]._element.rPr.rFonts.set(qn('w:eastAsia'), font_cn)
|
||||||
|
par = doc.add_paragraph()
|
||||||
|
text = par.add_run(text, style=font_cn)
|
||||||
|
|
||||||
|
doc = Document()
|
||||||
|
a = '小朋友 你是否有很多问号'
|
||||||
|
b = '为什么 别人在那看漫画'
|
||||||
|
c = '我却在学画画 对着钢琴说话'
|
||||||
|
|
||||||
|
font_setting(doc,a,'宋体')
|
||||||
|
font_setting(doc,b,'华文中宋')
|
||||||
|
font_setting(doc,c,'黑体')
|
||||||
|
|
||||||
|
doc.save('字体设置2.docx')
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
我们很容易地看出来,字体设置1.py与字体设置2.py的区别在于是否为同一段落,同时字体设置2.py中自定义了一个函数。同学们可以在实际工作中看具体场景进行选择。
|
||||||
|
|
||||||
|
#### (3) 插入图片与表格
|
||||||
|
|
||||||
|
```python
|
||||||
|
#导入库
|
||||||
|
from docx import Document
|
||||||
|
from docx.shared import Inches
|
||||||
|
|
||||||
|
#打开文档
|
||||||
|
doc_1 = Document('周杰伦.docx') #上面脚本存储的文档
|
||||||
|
#新增图片
|
||||||
|
doc_1.add_picture('周杰伦.jpg',width=Inches(1.0), height=Inches(1.0))
|
||||||
|
|
||||||
|
# 创建3行1列表格
|
||||||
|
table1 = doc_1.add_table(rows=2, cols=1)
|
||||||
|
table1.style='Medium Grid 1 Accent 1' #表格样式很多种,如,Light Shading Accent 1等
|
||||||
|
|
||||||
|
# 修改第2行第3列单元格的内容为营口
|
||||||
|
table1.cell(0, 0).text = '营口'
|
||||||
|
# 修改第3行第4列单元格的内容为人民
|
||||||
|
table1.rows[1].cells[0].text = '人民'
|
||||||
|
|
||||||
|
# 在表格底部新增一行
|
||||||
|
row_cells = table1.add_row().cells
|
||||||
|
# 新增行的第一列添加内容
|
||||||
|
row_cells[0].text = '加油'
|
||||||
|
|
||||||
|
doc_1.save('周杰伦为营口加油.docx')
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
#### (4)设置页眉页脚
|
||||||
|
|
||||||
|
在python-docx包中则要使用节(section)中的页眉(header)和页脚(footer)对象来具体设置。
|
||||||
|
|
||||||
|
```python
|
||||||
|
from docx import Document
|
||||||
|
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
|
||||||
|
|
||||||
|
document = Document() # 新建文档
|
||||||
|
|
||||||
|
header = document.sections[0].header # 获取第一个节的页眉
|
||||||
|
print('页眉中默认段落数:', len(header.paragraphs))
|
||||||
|
paragraph = header.paragraphs[0] # 获取页眉的第一个段落
|
||||||
|
paragraph.add_run('这是第一节的页眉') # 添加页面内容
|
||||||
|
footer = document.sections[0].footer # 获取第一个节的页脚
|
||||||
|
paragraph = footer.paragraphs[0] # 获取页脚的第一个段落
|
||||||
|
paragraph.add_run('这是第一节的页脚') # 添加页脚内容
|
||||||
|
|
||||||
|
|
||||||
|
'''在docx文档中又添加了2个节,共计3个节,页面和页脚会显示了“与上一节相同”。
|
||||||
|
如果不使用上一节的内容和样式要将header.is_linked_to_previous的属性或footer.is_linked_to_previous的属性设置为False,
|
||||||
|
用于解除“链接上一节页眉”或者“链接上一节页脚”。'''
|
||||||
|
document.add_section() # 添加一个新的节
|
||||||
|
document.add_section() # 添加第3个节
|
||||||
|
header = document.sections[1].header # 获取第2个节的页眉
|
||||||
|
header.is_linked_to_previous = False # 不使用上节内容和样式
|
||||||
|
|
||||||
|
#对齐设置
|
||||||
|
header = document.sections[1].header # 获取第2个节的页眉
|
||||||
|
header.is_linked_to_previous = False # 不使用上节内容和样式
|
||||||
|
paragraph = header.paragraphs[0]
|
||||||
|
paragraph.add_run('这是第二节的页眉')
|
||||||
|
paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 设置页眉居中对齐
|
||||||
|
document.sections[1].footer.is_linked_to_previous = False
|
||||||
|
footer.paragraphs[0].add_run('这是第二节的页脚') # 添加第2节页脚内容
|
||||||
|
footer.paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 设置第2节页脚居中对齐
|
||||||
|
header = document.sections[2].header # 获取第3个节的页眉
|
||||||
|
header.is_linked_to_previous = False # 不使用上节的内容和样式
|
||||||
|
paragraph = header.paragraphs[0] # 获取页眉中的段落
|
||||||
|
paragraph.add_run('这是第三节的页眉')
|
||||||
|
paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT # 设置页眉右对齐
|
||||||
|
document.sections[2].footer.is_linked_to_previous = False
|
||||||
|
footer.paragraphs[0].add_run('这是第三节的页脚') # 添加第3节页脚内容
|
||||||
|
footer.paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT # 设置第3节页脚右对齐
|
||||||
|
document.save('页眉页脚1.docx') # 保存文档
|
||||||
|
```
|
||||||
|
|
||||||
|
结果如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### (5)代码延伸
|
||||||
|
|
||||||
|
```python
|
||||||
|
'''对齐设置'''
|
||||||
|
from docx.enum.text import WD_ALIGN_PARAGRAPH
|
||||||
|
#LEFT: 左对齐
|
||||||
|
#CENTER: 文字居中
|
||||||
|
#RIGHT: 右对齐
|
||||||
|
#JUSTIFY: 文本两端对齐
|
||||||
|
|
||||||
|
'''设置段落行距'''
|
||||||
|
from docx.shared import Length
|
||||||
|
# SINGLE :单倍行距(默认)
|
||||||
|
#ONE_POINT_FIVE : 1.5倍行距
|
||||||
|
# DOUBLE2 : 倍行距
|
||||||
|
#AT_LEAST : 最小值
|
||||||
|
#EXACTLY:固定值
|
||||||
|
# MULTIPLE : 多倍行距
|
||||||
|
|
||||||
|
paragraph.line_spacing_rule = WD_LINE_SPACING.EXACTLY #固定值
|
||||||
|
paragraph_format.line_spacing = Pt(18) # 固定值18磅
|
||||||
|
paragraph.line_spacing_rule = WD_LINE_SPACING.MULTIPLE #多倍行距
|
||||||
|
paragraph_format.line_spacing = 1.75 # 1.75倍行间距
|
||||||
|
|
||||||
|
'''设置字体属性'''
|
||||||
|
from docx.shared import RGBColor,Pt
|
||||||
|
#all_caps:全部大写字母
|
||||||
|
#bold:加粗
|
||||||
|
#color:字体颜色
|
||||||
|
|
||||||
|
#double_strike:双删除线
|
||||||
|
#hidden : 隐藏
|
||||||
|
#imprint : 印记
|
||||||
|
#italic : 斜体
|
||||||
|
#name :字体
|
||||||
|
#shadow :阴影
|
||||||
|
#strike : 删除线
|
||||||
|
#subscript :下标
|
||||||
|
#superscript :上标
|
||||||
|
#underline :下划线
|
||||||
|
```
|
||||||
|
|
||||||
|
## 三、项目实践
|
||||||
|
|
||||||
|
### 一、需求
|
||||||
|
|
||||||
|
> 你是公司的行政人员,对合作伙伴进行邀请,参加公司的会议;
|
||||||
|
>
|
||||||
|
> 参会人名单如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
拟定的邀请函样式如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**根据参会人名单,利用python批量生成邀请函。**
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 二、需求分析
|
||||||
|
|
||||||
|
> 逻辑相对简单:
|
||||||
|
>
|
||||||
|
> - 获取 Excel 文件中每一行的信息,提取 参数;结合获取的参数设计邀请函样式并输出
|
||||||
|
> - 设计word段落及字体等样式。
|
||||||
|
|
||||||
|
### 三、代码
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 导入库
|
||||||
|
from openpyxl import load_workbook
|
||||||
|
from docx import Document
|
||||||
|
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
|
||||||
|
from docx.shared import RGBColor, Pt,Inches,Cm
|
||||||
|
from docx.oxml.ns import qn
|
||||||
|
|
||||||
|
|
||||||
|
path = r'D:\idea\cloud_analyse_game_sentiment\word自动化'
|
||||||
|
# 路径为Excel 文件所在的位置,可按实际情况更改
|
||||||
|
|
||||||
|
workbook = load_workbook(path + r'\excel到word.xlsx')
|
||||||
|
sheet = workbook.active #默认的WorkSheet
|
||||||
|
|
||||||
|
n = 0 #为了不遍历标题(excel的第一行)
|
||||||
|
for row in sheet.rows:
|
||||||
|
if n:
|
||||||
|
company = row[0].value
|
||||||
|
office = row[1].value
|
||||||
|
name = row[2].value
|
||||||
|
date = str(row[3].value).split()[0]
|
||||||
|
print(company, office, name, date)
|
||||||
|
|
||||||
|
|
||||||
|
doc = Document()
|
||||||
|
heading_1 = '邀 请 函'
|
||||||
|
paragraph_1 = doc.add_heading(heading_1, level=1)
|
||||||
|
# 居中对齐
|
||||||
|
paragraph_1.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
|
||||||
|
# 单独修改较大字号
|
||||||
|
for run in paragraph_1.runs:
|
||||||
|
run.font.size = Pt(17)
|
||||||
|
|
||||||
|
greeting_word_1 = '尊敬的'
|
||||||
|
greeting_word_2 = '公司'
|
||||||
|
greeting_word_3 = ',您好:'
|
||||||
|
paragraph_2 = doc.add_paragraph()
|
||||||
|
|
||||||
|
paragraph_2.add_run(greeting_word_1)
|
||||||
|
r_1 = paragraph_2.add_run(company)
|
||||||
|
r_1.font.bold = True # 加粗
|
||||||
|
r_1.font.underline = True #下划线
|
||||||
|
|
||||||
|
paragraph_2.add_run(greeting_word_2)
|
||||||
|
|
||||||
|
r_2 = paragraph_2.add_run(office)
|
||||||
|
r_2.font.bold = True # 加粗
|
||||||
|
r_2.font.underline = True #下划线
|
||||||
|
|
||||||
|
r_3 = paragraph_2.add_run(name)
|
||||||
|
r_3.font.bold = True # 加粗
|
||||||
|
r_3.font.underline = True #下划线
|
||||||
|
paragraph_2.add_run(greeting_word_3)
|
||||||
|
|
||||||
|
paragraph_3 = doc.add_paragraph()
|
||||||
|
paragraph_3.add_run('现诚挚的邀请您于2021年10月27日参加DataWhale主办的享受开源2050活动,地点在北京鸟巢,希望您届时莅临参加。')
|
||||||
|
paragraph_3.paragraph_format.first_line_indent = Cm(0.75)
|
||||||
|
paragraph_3.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT
|
||||||
|
paragraph_3.paragraph_format.space_after = Inches(1.0)
|
||||||
|
paragraph_3.paragraph_format.line_spacing = 1.5
|
||||||
|
|
||||||
|
paragraph_4 = doc.add_paragraph()
|
||||||
|
date_word_1 = '邀请时间:'
|
||||||
|
paragraph_4.add_run(date_word_1)
|
||||||
|
paragraph_4.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
|
||||||
|
sign_date = "{}年{}月{}日".format(date.split('-')[0], date.split('-')[1], date.split('-')[2])
|
||||||
|
paragraph_4.add_run(sign_date).underline = True
|
||||||
|
paragraph_4.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
|
||||||
|
|
||||||
|
#设置全文字体
|
||||||
|
for paragraph in doc.paragraphs:
|
||||||
|
for run in paragraph.runs:
|
||||||
|
run.font.color.rgb = RGBColor(0, 0, 0)
|
||||||
|
run.font.name = '楷体'
|
||||||
|
r = run._element.rPr.rFonts
|
||||||
|
r.set(qn('w:eastAsia'), '楷体')
|
||||||
|
doc.save(path + "\{}-邀请函.docx".format(name))
|
||||||
|
n = n + 1
|
||||||
|
```
|
||||||
|
|
||||||
|
### 四、总结
|
||||||
|
|
||||||
|
> 本案例也可适用于批量生产固定格式的word,如工资条,通知单等
|
||||||
@@ -0,0 +1,519 @@
|
|||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### Python 操作 PDF
|
||||||
|
|
||||||
|
PDF 操作是本次自动化办公的最后一个知识点,初级的 PDF 自动化包括 PDF 文档的拆分、合并、提取等操作,更高级的还包括 WORD与PDF互转等
|
||||||
|
|
||||||
|
初级操作一般比较常用,也可以解决较多的办公内容,所以本节将会主要介绍 PDF 的初级操作,具体内容将会从以下几个小节展开:
|
||||||
|
|
||||||
|
1. 相关介绍
|
||||||
|
2. 批量拆分
|
||||||
|
3. 批量合并
|
||||||
|
4. 提取文字内容
|
||||||
|
5. 提起表格内容
|
||||||
|
6. 提起图片内容
|
||||||
|
7. 转换为PDF图片
|
||||||
|
8. 添加水印
|
||||||
|
9. 加密与解码
|
||||||
|
|
||||||
|
下面直接开始本节内容。
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
#### 1. 相关介绍
|
||||||
|
|
||||||
|
Python 操作 PDF 会用到两个库,分别是:PyPDF2 和 pdfplumber
|
||||||
|
|
||||||
|
其中 **PyPDF2** 可以更好的读取、写入、分割、合并PDF文件,而 **pdfplumber** 可以更好的读取 PDF 文件中内容和提取 PDF 中的表格
|
||||||
|
|
||||||
|
对应的官网分别是:
|
||||||
|
|
||||||
|
> PyPDF2:https://pythonhosted.org/PyPDF2/
|
||||||
|
>
|
||||||
|
> pdfplumber:https://github.com/jsvine/pdfplumber
|
||||||
|
|
||||||
|
由于这两个库都不是 Python 的标准库,所以在使用之前都需要单独安装
|
||||||
|
|
||||||
|
win+r 后输入 cmd 打开 command 窗口,依次输入如下命令进行安装:
|
||||||
|
|
||||||
|
> pip install PyPDF2
|
||||||
|
>
|
||||||
|
> pip install pdfplumber
|
||||||
|
|
||||||
|
安装完成后显示 success 则表示安装成功
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
#### 2. 批量拆分
|
||||||
|
|
||||||
|
将一个完整的 PDF 拆分成几个小的 PDF,因为主要涉及到 PDF 整体的操作,所以本小节需要用到 PyPDF2 这个库
|
||||||
|
|
||||||
|
拆分的大概思路如下:
|
||||||
|
|
||||||
|
- 读取 PDF 的整体信息、总页数等
|
||||||
|
- 遍历每一页内容,以每个 step 为间隔将 PDF 存成每一个小的文件块
|
||||||
|
- 将小的文件块重新保存为新的 PDF 文件
|
||||||
|
|
||||||
|
需要注意的是,在拆分的过程中,可以手动设置间隔,例如:每5页保存成一个小的 PDF 文件
|
||||||
|
|
||||||
|
拆分的代码如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
def split_pdf(filename, filepath, save_dirpath, step=5):
|
||||||
|
"""
|
||||||
|
拆分PDF为多个小的PDF文件,
|
||||||
|
@param filename:文件名
|
||||||
|
@param filepath:文件路径
|
||||||
|
@param save_dirpath:保存小的PDF的文件路径
|
||||||
|
@param step: 每step间隔的页面生成一个文件,例如step=5,表示0-4页、5-9页...为一个文件
|
||||||
|
@return:
|
||||||
|
"""
|
||||||
|
if not os.path.exists(save_dirpath):
|
||||||
|
os.mkdir(save_dirpath)
|
||||||
|
pdf_reader = PdfFileReader(filepath)
|
||||||
|
# 读取每一页的数据
|
||||||
|
pages = pdf_reader.getNumPages()
|
||||||
|
for page in range(0, pages, step):
|
||||||
|
pdf_writer = PdfFileWriter()
|
||||||
|
# 拆分pdf,每 step 页的拆分为一个文件
|
||||||
|
for index in range(page, page+step):
|
||||||
|
if index < pages:
|
||||||
|
pdf_writer.addPage(pdf_reader.getPage(index))
|
||||||
|
# 保存拆分后的小文件
|
||||||
|
save_path = os.path.join(save_dirpath, filename+str(int(page/step)+1)+'.pdf')
|
||||||
|
print(save_path)
|
||||||
|
with open(save_path, "wb") as out:
|
||||||
|
pdf_writer.write(out)
|
||||||
|
|
||||||
|
print("文件已成功拆分,保存路径为:"+save_dirpath)
|
||||||
|
```
|
||||||
|
|
||||||
|
以“易方达中小盘混合型证券投资基金2020年中期报告”为例,整个 PDF 文件一共 46 页,每5页为间隔,最终生成了10个小的 PDF 文件
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
**需要注意的是:**
|
||||||
|
|
||||||
|
如果你是第一次运行代码,在运行过程中,会直接报如下的错误
|
||||||
|
|
||||||
|
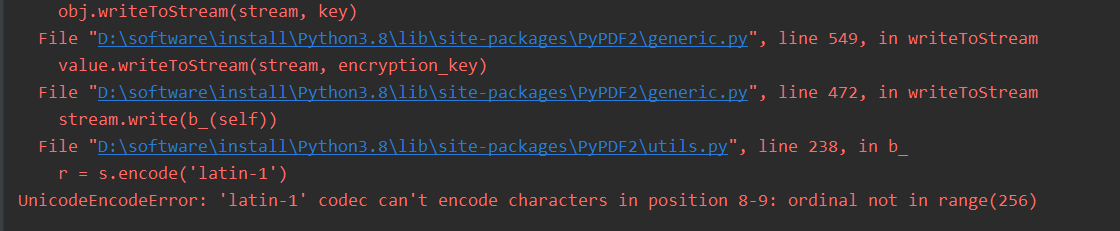
|
||||||
|
|
||||||
|
如果是在 Pycharm 下,直接通过报错信息,点击 utils.py 文件,定位到第 238 行原文
|
||||||
|
|
||||||
|
原文中是这样的:
|
||||||
|
|
||||||
|
```python
|
||||||
|
r = s.encode('latin-1')
|
||||||
|
if len(s) < 2:
|
||||||
|
bc[s] = r
|
||||||
|
return r
|
||||||
|
```
|
||||||
|
|
||||||
|
修改为:
|
||||||
|
|
||||||
|
```python
|
||||||
|
try:
|
||||||
|
r = s.encode('latin-1')
|
||||||
|
if len(s) < 2:
|
||||||
|
bc[s] = r
|
||||||
|
return r
|
||||||
|
except Exception as e:
|
||||||
|
r = s.encode('utf-8')
|
||||||
|
if len(s) < 2:
|
||||||
|
bc[s] = r
|
||||||
|
return r
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你使用的是 **anaconda**,对应的文件路径应该为:anaconda\Lib\site-packages\PyPDF2\utils.py,进行同样的修改操作即可
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
#### 3. 批量合并
|
||||||
|
|
||||||
|
比起拆分来,合并的思路更加简单:
|
||||||
|
|
||||||
|
- 确定要合并的 **文件顺序**
|
||||||
|
- 循环追加到一个文件块中
|
||||||
|
- 保存成一个新的文件
|
||||||
|
|
||||||
|
对应的代码比较简单,基本不会出现问题:
|
||||||
|
|
||||||
|
```python
|
||||||
|
def concat_pdf(filename, read_dirpath, save_filepath):
|
||||||
|
"""
|
||||||
|
合并多个PDF文件
|
||||||
|
@param filename:文件名
|
||||||
|
@param read_dirpath:要合并的PDF目录
|
||||||
|
@param save_filepath:合并后的PDF文件路径
|
||||||
|
@return:
|
||||||
|
"""
|
||||||
|
pdf_writer = PdfFileWriter()
|
||||||
|
# 对文件名进行排序
|
||||||
|
list_filename = os.listdir(read_dirpath)
|
||||||
|
list_filename.sort(key=lambda x: int(x[:-4].replace(filename, "")))
|
||||||
|
for filename in list_filename:
|
||||||
|
print(filename)
|
||||||
|
filepath = os.path.join(read_dirpath, filename)
|
||||||
|
# 读取文件并获取文件的页数
|
||||||
|
pdf_reader = PdfFileReader(filepath)
|
||||||
|
pages = pdf_reader.getNumPages()
|
||||||
|
# 逐页添加
|
||||||
|
for page in range(pages):
|
||||||
|
pdf_writer.addPage(pdf_reader.getPage(page))
|
||||||
|
# 保存合并后的文件
|
||||||
|
with open(save_filepath, "wb") as out:
|
||||||
|
pdf_writer.write(out)
|
||||||
|
print("文件已成功合并,保存路径为:"+save_filepath)
|
||||||
|
```
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
#### 4. 提取文字内容
|
||||||
|
|
||||||
|
涉及到具体的 PDF 内容 操作,本小节需要用到 pdfplumber 这个库
|
||||||
|
|
||||||
|
在进行文字提取的时候,主要用到 extract_text 这个函数
|
||||||
|
|
||||||
|
具体代码如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
def extract_text_info(filepath):
|
||||||
|
"""
|
||||||
|
提取PDF中的文字
|
||||||
|
@param filepath:文件路径
|
||||||
|
@return:
|
||||||
|
"""
|
||||||
|
with pdfplumber.open(filepath) as pdf:
|
||||||
|
# 获取第2页数据
|
||||||
|
page = pdf.pages[1]
|
||||||
|
print(page.extract_text())
|
||||||
|
```
|
||||||
|
|
||||||
|
可以看到,直接通过下标即可定位到相应的页码,从而通过 extract_text 函数提取该也的所有文字
|
||||||
|
|
||||||
|
而如果想要提取所有页的文字,只需要改成:
|
||||||
|
|
||||||
|
```python
|
||||||
|
with pdfplumber.open(filepath) as pdf:
|
||||||
|
# 获取全部数据
|
||||||
|
for page in pdf.pages
|
||||||
|
print(page.extract_text())
|
||||||
|
```
|
||||||
|
|
||||||
|
例如,提取“易方达中小盘混合型证券投资基金2020年中期报告” 第一页的内容时,源文件是这样的:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
运行代码后提取出来是这样的:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
> 拓展一下:此处可以结合前面 word 小节,将内容写入 word 文件中
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
#### 5. 提取表格内容
|
||||||
|
|
||||||
|
同样的,本节是对具体内容的操作,所以也需要用到 pdfplumber 这个库
|
||||||
|
|
||||||
|
和提取文字十分类似的是,提取表格内容只是将 extract_text 函数换成了 extract_table 函数
|
||||||
|
|
||||||
|
对应的代码如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
def extract_table_info(filepath):
|
||||||
|
"""
|
||||||
|
提取PDF中的图表数据
|
||||||
|
@param filepath:
|
||||||
|
@return:
|
||||||
|
"""
|
||||||
|
with pdfplumber.open(filepath) as pdf:
|
||||||
|
# 获取第18页数据
|
||||||
|
page = pdf.pages[17]
|
||||||
|
# 如果一页有一个表格,设置表格的第一行为表头,其余为数据
|
||||||
|
table_info = page.extract_table()
|
||||||
|
df_table = pd.DataFrame(table_info[1:], columns=table_info[0])
|
||||||
|
df_table.to_csv('dmeo.csv', index=False, encoding='gbk')
|
||||||
|
```
|
||||||
|
|
||||||
|
上面代码可以获取到第 18 页的第一个表格内容,并且将其保存为 csv 文件存在本地
|
||||||
|
|
||||||
|
> 但是,如果说第 18 页有多个表格内容呢?
|
||||||
|
|
||||||
|
因为读取的表格会被存成二维数组,而多个二维数组就组成一个三维数组
|
||||||
|
|
||||||
|
遍历这个三位数组,就可以得到该页的每一个表格数据,对应的将 extract_table 函数 改成 extract_tables 即可
|
||||||
|
|
||||||
|
具体代码如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 如果一页有多个表格,对应的数据是一个三维数组
|
||||||
|
tables_info = page.extract_tables()
|
||||||
|
for index in range(len(tables_info)):
|
||||||
|
# 设置表格的第一行为表头,其余为数据
|
||||||
|
df_table = pd.DataFrame(tables_info[index][1:], columns=tables_info[index][0])
|
||||||
|
print(df_table)
|
||||||
|
# df_table.to_csv('dmeo.csv', index=False, encoding='gbk')
|
||||||
|
```
|
||||||
|
|
||||||
|
以“易方达中小盘混合型证券投资基金2020年中期报告” 第 xx 页的第一个表格为例:
|
||||||
|
|
||||||
|
源文件中的表格是这样的:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
提取并存入 excel 之后的表格是这样的:
|
||||||
|
|
||||||
|
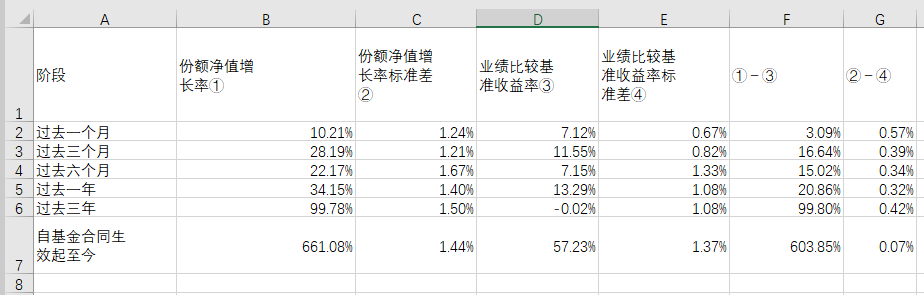
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
#### 6. 提取图片内容
|
||||||
|
|
||||||
|
提取 PDF 中的图片和将 PDF 转存为图片是不一样的(下一小节),需要区分开。
|
||||||
|
|
||||||
|
提取图片:顾名思义,就是将内容中的图片都提取出来;转存为图片:则是将每一页的 PDF 内容存成一页一页的图片,下一小节会详细说明
|
||||||
|
|
||||||
|
转存为图片中,需要用到一个模块叫 fitz,fitz 的最新版 1.18.13,非最新版的在部分函数名称上存在差异,代码中会标记出来
|
||||||
|
|
||||||
|
使用 fitz 需要先安装 PyMuPDF 模块,安装方式如下:
|
||||||
|
|
||||||
|
> pip install PyMuPDF
|
||||||
|
|
||||||
|
提取图片的整体逻辑如下:
|
||||||
|
|
||||||
|
- 使用 fitz 打开文档,获取文档详细数据
|
||||||
|
- 遍历每一个元素,通过正则找到图片的索引位置
|
||||||
|
- 使用 Pixmap 将索引对应的元素生成图片
|
||||||
|
- 通过 size 函数过滤较小的图片
|
||||||
|
|
||||||
|
实现的具体代码如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
if not os.path.exists(pic_dirpath):
|
||||||
|
os.makedirs(pic_dirpath)
|
||||||
|
# 使用正则表达式来查找图片
|
||||||
|
check_XObject = r"/Type(?= */XObject)"
|
||||||
|
check_Image = r"/Subtype(?= */Image)"
|
||||||
|
img_count = 0
|
||||||
|
|
||||||
|
"""1. 打开pdf,打印相关信息"""
|
||||||
|
pdf_info = fitz.open(filepath)
|
||||||
|
# 1.16.8版本用法 xref_len = doc._getXrefLength()
|
||||||
|
# 最新版本写法
|
||||||
|
xref_len = pdf_info.xref_length()
|
||||||
|
# 打印PDF的信息
|
||||||
|
print("文件名:{}, 页数: {}, 对象: {}".format(filepath, len(pdf_info), xref_len-1))
|
||||||
|
|
||||||
|
"""2. 遍历PDF中的对象,遇到是图像才进行下一步,不然就continue"""
|
||||||
|
for index in range(1, xref_len):
|
||||||
|
# 1.16.8版本用法 text = doc._getXrefString(index)
|
||||||
|
# 最新版本
|
||||||
|
text = pdf_info.xref_object(index)
|
||||||
|
|
||||||
|
is_XObject = re.search(check_XObject, text)
|
||||||
|
is_Image = re.search(check_Image, text)
|
||||||
|
# 如果不是对象也不是图片,则不操作
|
||||||
|
if is_XObject or is_Image:
|
||||||
|
img_count += 1
|
||||||
|
# 根据索引生成图像
|
||||||
|
pix = fitz.Pixmap(pdf_info, index)
|
||||||
|
pic_filepath = os.path.join(pic_dirpath, 'img_' + str(img_count) + '.png')
|
||||||
|
"""pix.size 可以反映像素多少,简单的色素块该值较低,可以通过设置一个阈值过滤。以阈值 10000 为例过滤"""
|
||||||
|
# if pix.size < 10000:
|
||||||
|
# continue
|
||||||
|
|
||||||
|
"""三、 将图像存为png格式"""
|
||||||
|
if pix.n >= 5:
|
||||||
|
# 先转换CMYK
|
||||||
|
pix = fitz.Pixmap(fitz.csRGB, pix)
|
||||||
|
# 存为PNG
|
||||||
|
pix.writePNG(pic_filepath)
|
||||||
|
```
|
||||||
|
|
||||||
|
以本节示例的“易方达中小盘混合型证券投资基金2020年中期报告” 中的图片为例,代码运行后提取的图片如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
这个结果和文档中的共 1 张图片的 **结果符合**
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
#### 7. 转换为图片
|
||||||
|
|
||||||
|
转换为照片比较简单,就是将一页页的 PDF 转换为一张张的图片。大致过程如下:
|
||||||
|
|
||||||
|
##### 7.1 安装 pdf2image
|
||||||
|
|
||||||
|
首先需要安装对应的库,最新的 pdf2image 库版本应该是 1.14.0
|
||||||
|
|
||||||
|
它的 github地址 为:https://github.com/Belval/pdf2image ,感兴趣的可以自行了解
|
||||||
|
|
||||||
|
安装方式如下:
|
||||||
|
|
||||||
|
> pip install pdf2image
|
||||||
|
|
||||||
|
##### 7.2 安装组件
|
||||||
|
|
||||||
|
对于不同的平台,需要安装相应的组件,这里以 windows 平台和 mac 平台为例:
|
||||||
|
|
||||||
|
**Windows 平台**
|
||||||
|
|
||||||
|
对于 windows 用户需要安装 poppler for Windows,安装链接是:http://blog.alivate.com.au/poppler-windows/
|
||||||
|
|
||||||
|
另外,还需要添加环境变量, 将 bin 文件夹的路径添加到环境变量 PATH 中
|
||||||
|
|
||||||
|
> 注意这里配置之后需要重启一下电脑才会生效,不然会报如下错误:
|
||||||
|
|
||||||
|
**Mac**
|
||||||
|
|
||||||
|
对于 mac 用户,需要安装 poppler for Mac,具体可以参考这个链接:http://macappstore.org/poppler/
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
详细代码如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
if not os.path.exists(pic_dirpath):
|
||||||
|
os.makedirs(pic_dirpath)
|
||||||
|
|
||||||
|
images = convert_from_bytes(open(filepath, 'rb').read())
|
||||||
|
# images = convert_from_path(filepath, dpi=200)
|
||||||
|
for image in images:
|
||||||
|
# 保存图片
|
||||||
|
pic_filepath = os.path.join(pic_dirpath, 'img_'+str(images.index(image))+'.png')
|
||||||
|
image.save(pic_filepath, 'PNG')
|
||||||
|
```
|
||||||
|
|
||||||
|
以本节示例的“易方达中小盘混合型证券投资基金2020年中期报告” 中的图片为例,该文档共 46 页,保存后的 PDF 照片如下:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
一共 46 张图片
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
#### 8. 添加水印
|
||||||
|
|
||||||
|
PDF 中添加水印,首先需要一个水印PDF文件,然后依次通过 mergePage 操作将每一页的 PDF 文件合并到水印文件上,据此,每一页的 PDF 文件将是一个带有水印的 PDF 文件
|
||||||
|
|
||||||
|
最后,将每一页的水印 PDF 合并成一个 PDF 文件即可
|
||||||
|
|
||||||
|
**生成水印**
|
||||||
|
|
||||||
|
生成水印的方式比较多,例如在图片添加水印,然后将图片插入到 word 中,最后将 word 保存成 PDF 文件即可
|
||||||
|
|
||||||
|
生成一张 A4 纸大小的空白图片,参考这篇文章:[Python 批量加水印!轻松搞定!](https://mp.weixin.qq.com/s/_oJA6lbsdMlRRsBf6DPxsg) 给图片添加水印,最终的水印背景图片是这样的:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
然后将图片插入到 word 中并最终生成一个水印 PDF 文档
|
||||||
|
|
||||||
|
PDF 文档添加水印的主要代码如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
watermark = PdfFileReader(watermark_filepath)
|
||||||
|
watermark_page = watermark.getPage(0)
|
||||||
|
|
||||||
|
pdf_reader = PdfFileReader(filepath)
|
||||||
|
pdf_writer = PdfFileWriter()
|
||||||
|
|
||||||
|
for page_index in range(pdf_reader.getNumPages()):
|
||||||
|
current_page = pdf_reader.getPage(page_index)
|
||||||
|
# 封面页不添加水印
|
||||||
|
if page_index == 0:
|
||||||
|
new_page = current_page
|
||||||
|
else:
|
||||||
|
new_page = copy(watermark_page)
|
||||||
|
new_page.mergePage(current_page)
|
||||||
|
pdf_writer.addPage(new_page)
|
||||||
|
# 保存水印后的文件
|
||||||
|
with open(save_filepath, "wb") as out:
|
||||||
|
pdf_writer.write(out)
|
||||||
|
```
|
||||||
|
|
||||||
|
以本节示例的“易方达中小盘混合型证券投资基金2020年中期报告” 为例,添加水印后的文档如下:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
#### 9. 文档加密与解密
|
||||||
|
|
||||||
|
你可能在打开部分 PDF 文件的时候,会弹出下面这个界面:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
这种就是 PDF 文件被加密了,在打开的时候需要相应的密码才行
|
||||||
|
|
||||||
|
本节所提到的也只是基于 PDF 文档的加密解密,而不是所谓的 PDF 密码破解。
|
||||||
|
|
||||||
|
在对 PDF 文件加密需要使用 encrypt 函数,对应的加密代码也比较简单:
|
||||||
|
|
||||||
|
```python
|
||||||
|
pdf_reader = PdfFileReader(filepath)
|
||||||
|
pdf_writer = PdfFileWriter()
|
||||||
|
|
||||||
|
for page_index in range(pdf_reader.getNumPages()):
|
||||||
|
pdf_writer.addPage(pdf_reader.getPage(page_index))
|
||||||
|
|
||||||
|
# 添加密码
|
||||||
|
pdf_writer.encrypt(passwd)
|
||||||
|
with open(save_filepath, "wb") as out:
|
||||||
|
pdf_writer.write(out)
|
||||||
|
```
|
||||||
|
|
||||||
|
代码执行成功后再次打开 PDF 文件则需要输入密码才行
|
||||||
|
|
||||||
|
根据这个思路,破解 PDF 也可以通过暴力求解实现,例如:通过本地密码本一个个去尝试,或者根据数字+字母的密码形式循环尝试,最终成功打开的密码就是破解密码
|
||||||
|
|
||||||
|
> 上述破解方法耗时耗力,不建议尝试
|
||||||
|
|
||||||
|
<br>
|
||||||
|
|
||||||
|
另外,针对已经加密的 PDF 文件,也可以使用 decrypt 函数进行解密操作
|
||||||
|
|
||||||
|
解密代码如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
pdf_reader = PdfFileReader(filepath)
|
||||||
|
# PDF文档解密
|
||||||
|
pdf_reader.decrypt('xiaoyi')
|
||||||
|
|
||||||
|
pdf_writer = PdfFileWriter()
|
||||||
|
for page_index in range(pdf_reader.getNumPages()):
|
||||||
|
pdf_writer.addPage(pdf_reader.getPage(page_index))
|
||||||
|
|
||||||
|
with open(save_filepath, "wb") as out:
|
||||||
|
pdf_writer.write(out)
|
||||||
|
```
|
||||||
|
|
||||||
|
解密完成后的 PDF 文档打开后不再需要输入密码,如需加密可再次执行加密代码。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
----
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**END.**
|
||||||
|
|
||||||
|
--- By: xiaoyi
|
||||||
|
|
||||||
|
>**Datawhale成员,数据分析从业者,金融风控爱好者**
|
||||||
|
>
|
||||||
|
>**公众号:小一的学习笔记**
|
||||||
|
|
||||||
|
关于Datawhale:
|
||||||
|
|
||||||
|
> Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。
|
||||||
|
>
|
||||||
|
> Datawhale 以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。
|
||||||
|
>
|
||||||
|
> 同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
|
||||||
@@ -0,0 +1,658 @@
|
|||||||
|
# Task5 爬虫入门与综合应用
|
||||||
|
|
||||||
|
对于自动化办公而言,网络数据的批量获取完数据可以节约相当的时间,因此爬虫在自动化办公中占据了一个比较重要的位置。
|
||||||
|
|
||||||
|
因而本节针对爬虫项目进行一个介绍,力求最大程度还原实际的办公场景。
|
||||||
|
|
||||||
|
## **Requests简介**
|
||||||
|
|
||||||
|
Requests是一款目前非常流行的http请求库,使用python编写,能非常方便的对网页Requests进行爬取,也是爬虫最常用的发起请求第三方库。
|
||||||
|
|
||||||
|
安装方法:
|
||||||
|
|
||||||
|
```
|
||||||
|
pip install requests
|
||||||
|
或者conda安装
|
||||||
|
conda install requests
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
re.status_code 响应的HTTP状态码
|
||||||
|
re.text 响应内容的字符串形式
|
||||||
|
rs.content 响应内容的二进制形式
|
||||||
|
rs.encoding 响应内容的编码
|
||||||
|
```
|
||||||
|
|
||||||
|
试一试对百度首页进行数据请求:
|
||||||
|
|
||||||
|
项目难度:⭐
|
||||||
|
|
||||||
|
```python
|
||||||
|
import requests
|
||||||
|
# 发出http请求
|
||||||
|
re=requests.get("https://www.baidu.com")
|
||||||
|
# 查看响应状态
|
||||||
|
print(re.status_code)
|
||||||
|
#输出:200
|
||||||
|
#200就是响应的状态码,表示请求成功
|
||||||
|
#我们可以通过res.status_code的值来判断请求是否成功。
|
||||||
|
```
|
||||||
|
|
||||||
|
**res.text** 返回的是服务器响应内容的字符串形式,也就是文本内容
|
||||||
|
|
||||||
|
例:用爬虫下载孔乙己的文章,网址是https://apiv3.shanbay.com/codetime/articles/mnvdu
|
||||||
|
|
||||||
|
我们打开这个网址 可以看到是鲁迅的文章
|
||||||
|
|
||||||
|
我们尝试着用爬虫保存文章的内容
|
||||||
|
|
||||||
|
项目难度:⭐
|
||||||
|
|
||||||
|
```python
|
||||||
|
import requests
|
||||||
|
# 发出http请求
|
||||||
|
re = requests.get('https://apiv3.shanbay.com/codetime/articles/mnvdu')
|
||||||
|
# 查看响应状态
|
||||||
|
print('网页的状态码为%s'%re.status_code)
|
||||||
|
with open('鲁迅文章.txt', 'w') as file:
|
||||||
|
# 将数据的字符串形式写入文件中
|
||||||
|
print('正在爬取小说')
|
||||||
|
file.write(re.text)
|
||||||
|
```
|
||||||
|
|
||||||
|
re.txt就是网页中的内容,将内容保存到txt文件中
|
||||||
|
|
||||||
|
**re.text用于文本内容的获取、下载
|
||||||
|
re.content用于图片、视频、音频等内容的获取、下载**
|
||||||
|
|
||||||
|
项目难度:⭐⭐
|
||||||
|
|
||||||
|
```python
|
||||||
|
import requests
|
||||||
|
# 发出http请求
|
||||||
|
#下载图片
|
||||||
|
res=requests.get('https://img-blog.csdnimg.cn/20210424184053989.PNG')
|
||||||
|
# 以二进制写入的方式打开一个名为 info.jpg 的文件
|
||||||
|
with open('datawhale.png','wb') as ff:
|
||||||
|
# 将数据的二进制形式写入文件中
|
||||||
|
ff.write(res.content)
|
||||||
|
```
|
||||||
|
|
||||||
|
**re.encoding** 爬取内容的编码形似,常见的编码方式有 ASCII、GBK、UTF-8 等。如果用和文件编码不同的方式去解码,我们就会得到一些乱码。
|
||||||
|
|
||||||
|
## HTML解析和提取
|
||||||
|
|
||||||
|
**浏览器工作原理:**
|
||||||
|
|
||||||
|
向浏览器中输入某个网址,浏览器回向服务器发出请求,然后服务器就会作出响应。其实,服务器返回给浏览器的这个结果就是HTML代码,浏览器会根据这个HTML代码将网页解析成平时我们看到的那样
|
||||||
|
|
||||||
|
比如我们来看看百度的html页面
|
||||||
|
|
||||||
|
```python
|
||||||
|
import requests
|
||||||
|
res=requests.get('https://baidu.com')
|
||||||
|
print(res.text)
|
||||||
|
```
|
||||||
|
|
||||||
|
将会看到很多带有标签的信息
|
||||||
|
|
||||||
|
**HTML(Hyper Text Markup Language)**是一种超文本标记语言,是由一堆标记组成。
|
||||||
|
|
||||||
|
例如
|
||||||
|
|
||||||
|
```html
|
||||||
|
<html>
|
||||||
|
<head>
|
||||||
|
<title>我的网页</title>
|
||||||
|
</head>
|
||||||
|
<body>
|
||||||
|
Hello,World
|
||||||
|
</body>
|
||||||
|
</html>
|
||||||
|
```
|
||||||
|
|
||||||
|
上面即为一个最简单的html,我们所需要的信息就是夹在标签中
|
||||||
|
|
||||||
|
想对html有根据深入的了解,可以html菜鸟教程
|
||||||
|
|
||||||
|
https://www.runoob.com/html/html-tutorial.html
|
||||||
|
|
||||||
|
那么我们如何解析html页面呢?
|
||||||
|
|
||||||
|
## BeautifulSoup简介
|
||||||
|
|
||||||
|
我们一般会使用BeautifulSoup这个第三方库
|
||||||
|
|
||||||
|
安装方法:
|
||||||
|
|
||||||
|
```
|
||||||
|
pip install bs4
|
||||||
|
或
|
||||||
|
conda install bs4
|
||||||
|
```
|
||||||
|
|
||||||
|
我们来解析豆瓣读书 Top250
|
||||||
|
|
||||||
|
它的网址是:https://book.douban.com/top250
|
||||||
|
|
||||||
|
项目难度:⭐⭐
|
||||||
|
|
||||||
|
```python
|
||||||
|
import io
|
||||||
|
import sys
|
||||||
|
import requests
|
||||||
|
from bs4 import BeautifulSoup
|
||||||
|
###运行出现乱码时可以修改编码方式
|
||||||
|
#sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
|
||||||
|
###
|
||||||
|
headers = {
|
||||||
|
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
|
||||||
|
}
|
||||||
|
res = requests.get('https://book.douban.com/top250', headers=headers)
|
||||||
|
soup = BeautifulSoup(res.text, 'lxml')
|
||||||
|
print(soup)
|
||||||
|
```
|
||||||
|
|
||||||
|
python 打印信息时会有限制 我们将打印的编码改成gb18030
|
||||||
|
|
||||||
|
headers表示我们的请求网页的头,对于没有headers的请求可能会被服务器判定为爬虫而拒绝提供服务
|
||||||
|
|
||||||
|
通过 from bs4 import BeautifulSoup 语句导入 BeautifulSoup
|
||||||
|
|
||||||
|
然后使用 BeautifulSoup(res.text, lxmlr’) 语句将网页源代码的字符串形式解析成了 BeautifulSoup 对象
|
||||||
|
|
||||||
|
解析成了 BeautifulSoup 对象可以较为方便的提取我们需要的信息
|
||||||
|
|
||||||
|
那么如何提取信息呢?
|
||||||
|
|
||||||
|
BeautifulSoup 为我们提供了一些方法
|
||||||
|
|
||||||
|
**find()方法**和**find_all()方法**:
|
||||||
|
|
||||||
|
- **find()** 返回符合条件的**首个**数据
|
||||||
|
- **find_all()** 返回符合条件的所有**数据
|
||||||
|
|
||||||
|
```python
|
||||||
|
import io
|
||||||
|
import sys
|
||||||
|
import requests
|
||||||
|
from bs4 import BeautifulSoup
|
||||||
|
#如果出现了乱码报错,可以修改编码形式
|
||||||
|
#sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
|
||||||
|
#
|
||||||
|
headers = {
|
||||||
|
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
|
||||||
|
}
|
||||||
|
res = requests.get('https://book.douban.com/top250', headers=headers)
|
||||||
|
soup = BeautifulSoup(res.text, 'lxml')
|
||||||
|
print(soup.find('a'))
|
||||||
|
#<a class="nav-login" href="https://accounts.douban.com/passport/login?source=book" rel="nofollow">登录/注册</a>
|
||||||
|
print(soup.find_all('a'))
|
||||||
|
#返回一个列表 包含了所有的<a>标签
|
||||||
|
```
|
||||||
|
|
||||||
|
除了传入 HTML 标签名称外,BeautifulSoup 还支持熟悉的定位
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 定位div开头 同时id为'doubanapp-tip的标签
|
||||||
|
soup.find('div', id='doubanapp-tip')
|
||||||
|
# 定位a抬头 同时class为rating_nums的标签
|
||||||
|
soup.find_all('span', class_='rating_nums')
|
||||||
|
#class是python中定义类的关键字,因此用class_表示HTML中的class
|
||||||
|
```
|
||||||
|
|
||||||
|
HTML定位方法:https://www.cnblogs.com/bosslv/p/8992410.html
|
||||||
|
|
||||||
|
理论看百遍,不如上手一练
|
||||||
|
|
||||||
|
## 实践项目1:自如公寓数据抓取
|
||||||
|
|
||||||
|
> 首先是先说一声抱歉,在课程设计时,没有想到自如公寓在价格上增加一定程度的反爬措施,因此自如公寓的价格在本节不讨论,在以后的课程中,我们会详细讲解相关的方法。
|
||||||
|
>
|
||||||
|
> 本节内容为作者原创的项目,整体爬取过程有4星的难度,建议读者跟着课程一步一步的来,如果有不明白的地方,可以在群里面与其他伙伴进行交流。
|
||||||
|
>
|
||||||
|
> 在输出本节内容时,请注明来源,Datawhale自动化办公课程,谢谢~
|
||||||
|
|
||||||
|
日前 , 国务院办公厅印发《关于加快培育和发展住房租赁市场的若干意见》,你是某新媒体公司的一名员工,老板希望对武汉的租房情况进行深度调研与分析,你想调查自如公寓的数据情况。根据工作的安排,你调研的是自如公寓武汉房屋出租分析的任务。
|
||||||
|
|
||||||
|
项目难度:⭐⭐⭐⭐
|
||||||
|
|
||||||
|
自如公寓官网:https://wh.ziroom.com/z/z/
|
||||||
|
|
||||||
|
通过观察官网你发现
|
||||||
|
|
||||||
|
第1页的网页为:https://wh.ziroom.com/z/p1/
|
||||||
|
|
||||||
|
第2页的网页为:https://wh.ziroom.com/z/p2/
|
||||||
|
|
||||||
|
第3页的网页为:https://wh.ziroom.com/z/p3/
|
||||||
|
|
||||||
|
...
|
||||||
|
|
||||||
|
第50页的网页为:https://wh.ziroom.com/z/p50/
|
||||||
|
|
||||||
|
你继续观察,发现
|
||||||
|
|
||||||
|
房屋的信息网页为类似于:https://wh.ziroom.com/x/741955798.html
|
||||||
|
|
||||||
|
即:https://wh.ziroom.com/x/XXXX.html
|
||||||
|
|
||||||
|
因此你有了思路,通过访问自如公寓的网站,获取每个房间后面的数字号 然后通过数字号访问房屋的直接信息,然后抓取房屋的信息保存在excel中
|
||||||
|
|
||||||
|
于是你访问了房屋的网页:https://wh.ziroom.com/x/741955798.html
|
||||||
|
|
||||||
|
通过观察房屋的网页,你发现是这些信息是你需要的
|
||||||
|
|
||||||
|
房屋的名称,房屋的面积,房屋的朝向,房屋的户型,房屋的位置,房屋的楼层,是否有电梯,房屋的年代,门锁情况,绿化情况
|
||||||
|
|
||||||
|
但是你遇到了困难,不知道这些信息的标签信息,不能用beautifulsoup对他们进行定位
|
||||||
|
|
||||||
|
通过百度查询,浏览器按F12时能进入源代码模式 或者 点击右键进入审查元素
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
点击左上角的箭头,可以定位到元素的位置
|
||||||
|
|
||||||
|
方法掌握后你开始写代码了
|
||||||
|
|
||||||
|
```python
|
||||||
|
import requests
|
||||||
|
from bs4 import BeautifulSoup
|
||||||
|
import random
|
||||||
|
import time
|
||||||
|
import csv
|
||||||
|
```
|
||||||
|
|
||||||
|
写到这里的时候,你想到,我多次访问自如的官网,如果只用一个UA头岂不是很容易被反爬虫识别
|
||||||
|
|
||||||
|
你想到,我可以做很多个UA头,然后每次访问的时候可以随机选一个,想到这里,你直呼自己是个天才
|
||||||
|
|
||||||
|
于是,你到网上找到了很多UA头信息
|
||||||
|
|
||||||
|
```python
|
||||||
|
#这里增加了很多user_agent
|
||||||
|
#能一定程度能保护爬虫
|
||||||
|
user_agent = [
|
||||||
|
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
|
||||||
|
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
|
||||||
|
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
|
||||||
|
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
|
||||||
|
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
|
||||||
|
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
|
||||||
|
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
|
||||||
|
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
|
||||||
|
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
|
||||||
|
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)"]
|
||||||
|
```
|
||||||
|
|
||||||
|
现在开始正式开始爬取数据了
|
||||||
|
|
||||||
|
房屋的名称,房屋的价格,房屋的面积,房屋的朝向,房屋的户型,房屋的位置,房屋的楼层,是否有电梯,房屋的年代,门锁情况,绿化情况
|
||||||
|
|
||||||
|
你思考爬取的信息应该保存到csv文件中,于是你导入了csv包 并简单的了解了CSV包的用法
|
||||||
|
|
||||||
|
第一步,是要获取房屋的数字标签
|
||||||
|
|
||||||
|
于是你打开了自如的官网,用浏览器的元素进行定位
|
||||||
|
|
||||||
|
发现房屋的信息标签都是这个
|
||||||
|
|
||||||
|
< a href="dd//wh.ziroom.com/x/741955798.html" target="_blank"> 房屋名称< /a >
|
||||||
|
|
||||||
|
聪明的你,随手写下了这个代码,便能爬取自如前50页
|
||||||
|
|
||||||
|
```python
|
||||||
|
def get_info():
|
||||||
|
csvheader=['名称','面积','朝向','户型','位置','楼层','是否有电梯','建成时间',' 门锁','绿化']
|
||||||
|
with open('wuhan_ziru.csv', 'a+', newline='') as csvfile:
|
||||||
|
writer = csv.writer(csvfile)
|
||||||
|
writer.writerow(csvheader)
|
||||||
|
for i in range(1,50): #总共有50页
|
||||||
|
print('正在爬取自如第%s页'%i)
|
||||||
|
timelist=[1,2,3]
|
||||||
|
print('有点累了,需要休息一下啦(¬㉨¬)')
|
||||||
|
time.sleep(random.choice(timelist)) #休息1-3秒,防止给对方服务器过大的压力!!!
|
||||||
|
url='https://wh.ziroom.com/z/p%s/'%i
|
||||||
|
headers = {'User-Agent': random.choice(user_agent)}
|
||||||
|
r = requests.get(url, headers=headers)
|
||||||
|
r.encoding = r.apparent_encoding
|
||||||
|
soup = BeautifulSoup(r.text, 'lxml')
|
||||||
|
all_info = soup.find_all('div', class_='info-box')
|
||||||
|
print('开始干活咯(๑><๑)')
|
||||||
|
for info in all_info:
|
||||||
|
href = info.find('a')
|
||||||
|
if href !=None:
|
||||||
|
href='https:'+href['href']
|
||||||
|
try:
|
||||||
|
print('正在爬取%s'%href)
|
||||||
|
house_info=get_house_info(href)
|
||||||
|
writer.writerow(house_info)
|
||||||
|
except:
|
||||||
|
print('出错啦,%s进不去啦( •̥́ ˍ •̀ू )'%href)
|
||||||
|
```
|
||||||
|
|
||||||
|
通过研究发现了你需要定位的信息 通过标签头 h1 li span 和class的值对标签进行定位
|
||||||
|
|
||||||
|
```
|
||||||
|
<h1 class="Z_name"><i class="status iconicon_sign"></i>自如友家·电建地产盛世江城·4居室-05卧</h1>
|
||||||
|
----
|
||||||
|
<div class="Z_home_info">
|
||||||
|
<div class="Z_home_b clearfix">
|
||||||
|
<dl class="">
|
||||||
|
<dd>8.4㎡</dd>
|
||||||
|
<dt>使用面积</dt>
|
||||||
|
</dl>
|
||||||
|
<dl class="">
|
||||||
|
<dd>朝南</dd>
|
||||||
|
<dt>朝向</dt>
|
||||||
|
</dl>
|
||||||
|
<dl class="">
|
||||||
|
<dd>4室1厅</dd>
|
||||||
|
<dt>户型</dt>
|
||||||
|
</dl>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
----
|
||||||
|
<ul class="Z_home_o">
|
||||||
|
<li>
|
||||||
|
<span class="la">位置</span><span class="va">
|
||||||
|
<span class="ad">小区距2号线长港路站步行约231米</span>
|
||||||
|
</li>
|
||||||
|
<span class="la">楼层</span><span class="va">6/43</span>
|
||||||
|
</li>
|
||||||
|
<li>
|
||||||
|
<span class="la">电梯</span><span class="va">有</span>
|
||||||
|
</li>
|
||||||
|
<li>
|
||||||
|
<span class="la">年代</span><span class="va">2016年建成</span>
|
||||||
|
</li>
|
||||||
|
<li>
|
||||||
|
<span class="la">门锁</span><span class="va">智能门锁</span>
|
||||||
|
</li>
|
||||||
|
<li>
|
||||||
|
<span class="la">绿化</span><span class="va">35%</span>
|
||||||
|
</li>
|
||||||
|
</ul>
|
||||||
|
```
|
||||||
|
|
||||||
|
通过对上面标签的研究你完成了所有的代码
|
||||||
|
|
||||||
|
```python
|
||||||
|
import requests
|
||||||
|
from bs4 import BeautifulSoup
|
||||||
|
import random
|
||||||
|
import time
|
||||||
|
import csv
|
||||||
|
|
||||||
|
#这里增加了很多user_agent
|
||||||
|
#能一定程度能保护爬虫
|
||||||
|
user_agent = [
|
||||||
|
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
|
||||||
|
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
|
||||||
|
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
|
||||||
|
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
|
||||||
|
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
|
||||||
|
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
|
||||||
|
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
|
||||||
|
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
|
||||||
|
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
|
||||||
|
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)"]
|
||||||
|
|
||||||
|
def get_info():
|
||||||
|
csvheader=['名称','面积','朝向','户型','位置','楼层','是否有电梯','建成时间',' 门锁','绿化']
|
||||||
|
with open('wuhan_ziru.csv', 'a+', newline='') as csvfile:
|
||||||
|
writer = csv.writer(csvfile)
|
||||||
|
writer.writerow(csvheader)
|
||||||
|
for i in range(1,50): #总共有50页
|
||||||
|
print('正在爬取自如第%s页'%i)
|
||||||
|
timelist=[1,2,3]
|
||||||
|
print('有点累了,需要休息一下啦(¬㉨¬)')
|
||||||
|
time.sleep(random.choice(timelist)) #休息1-3秒,防止给对方服务器过大的压力!!!
|
||||||
|
url='https://wh.ziroom.com/z/p%s/'%i
|
||||||
|
headers = {'User-Agent': random.choice(user_agent)}
|
||||||
|
r = requests.get(url, headers=headers)
|
||||||
|
r.encoding = r.apparent_encoding
|
||||||
|
soup = BeautifulSoup(r.text, 'lxml')
|
||||||
|
all_info = soup.find_all('div', class_='info-box')
|
||||||
|
print('开始干活咯(๑><๑)')
|
||||||
|
for info in all_info:
|
||||||
|
href = info.find('a')
|
||||||
|
if href !=None:
|
||||||
|
href='https:'+href['href']
|
||||||
|
try:
|
||||||
|
print('正在爬取%s'%href)
|
||||||
|
house_info=get_house_info(href)
|
||||||
|
writer.writerow(house_info)
|
||||||
|
except:
|
||||||
|
print('出错啦,%s进不去啦( •̥́ ˍ •̀ू )'%href)
|
||||||
|
|
||||||
|
def get_house_info(href):
|
||||||
|
#得到房屋的信息
|
||||||
|
time.sleep(1)
|
||||||
|
headers = {'User-Agent': random.choice(user_agent)}
|
||||||
|
response = requests.get(url=href, headers=headers)
|
||||||
|
response=response.content.decode('utf-8', 'ignore')
|
||||||
|
soup = BeautifulSoup(response, 'lxml')
|
||||||
|
name = soup.find('h1', class_='Z_name').text
|
||||||
|
sinfo=soup.find('div', class_='Z_home_b clearfix').find_all('dd')
|
||||||
|
area=sinfo[0].text
|
||||||
|
orien=sinfo[1].text
|
||||||
|
area_type=sinfo[2].text
|
||||||
|
dinfo=soup.find('ul',class_='Z_home_o').find_all('li')
|
||||||
|
location=dinfo[0].find('span',class_='va').text
|
||||||
|
loucen=dinfo[1].find('span',class_='va').text
|
||||||
|
dianti=dinfo[2].find('span',class_='va').text
|
||||||
|
niandai=dinfo[3].find('span',class_='va').text
|
||||||
|
mensuo=dinfo[4].find('span',class_='va').text
|
||||||
|
lvhua=dinfo[5].find('span',class_='va').text
|
||||||
|
['名称','面积','朝向','户型','位置','楼层','是否有电梯','建成时间',' 门锁','绿化']
|
||||||
|
room_info=[name,area,orien,area_type,location,loucen,dianti,niandai,mensuo,lvhua]
|
||||||
|
return room_info
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
get_info()
|
||||||
|
```
|
||||||
|
|
||||||
|
运行完成后,会在文件夹中看到刚才爬取好的信息保存在wuhan_ziru.csv中
|
||||||
|
|
||||||
|
## 实践项目2:36kr信息抓取与邮件发送
|
||||||
|
|
||||||
|
> 本节内容为作者原创的项目,课程难度为5星,建议读者跟着课程一步一步的来,如果有不明白的地方,可以在群里面与其他伙伴进行交流。
|
||||||
|
>
|
||||||
|
> 在输出本节内容时,请注明来源,Datawhale自动化办公课程,谢谢~
|
||||||
|
|
||||||
|
项目难度:⭐⭐⭐⭐⭐
|
||||||
|
|
||||||
|
完成了上面的实践项目1后,你膨胀到不行,觉得自己太厉害了。通过前面的学习,你了解到使用python进行电子邮件的收发,突然有一天你想到,如果我用A账户进行发送,同时用B账户进行接受,在手机上安装一个邮件接受的软件,这样就能完成信息从pc端投送到移动端。
|
||||||
|
|
||||||
|
在这样的思想上,就可以对动态变化的信息进行监控,一旦信息触发了发送的条件,可以将信息通过邮件投送到手机上,从而让自己最快感知到。
|
||||||
|
|
||||||
|
具体路径是:
|
||||||
|
|
||||||
|
python爬虫-->通过邮件A发送-->服务器--->通过邮件B接收
|
||||||
|
|
||||||
|
因此我们本节的内容就是爬取36kr的信息然后通过邮件发送
|
||||||
|
|
||||||
|
36kr官网:https://36kr.com/newsflashes
|
||||||
|
|
||||||
|
通过python发送邮件需要获得pop3的授权码
|
||||||
|
|
||||||
|
具体获取方式可参考:
|
||||||
|
|
||||||
|
https://blog.csdn.net/wateryouyo/article/details/51766345
|
||||||
|
|
||||||
|
接下来就爬取36Kr的网站
|
||||||
|
|
||||||
|
通过观察我们发现 消息的标签为
|
||||||
|
|
||||||
|
```
|
||||||
|
<a class="item-title" rel="noopener noreferrer" target="_blank" href="/newsflashes/1218249313424001" sensors_operation_list="page_flow">中国平安:推动新方正集团聚集医疗健康等核心业务发展</a>
|
||||||
|
```
|
||||||
|
|
||||||
|
因此我们爬取的代码为
|
||||||
|
|
||||||
|
需要注意的是,邮箱发送消息用的HTML的模式,而HTML模式下换行符号为 < br>
|
||||||
|
|
||||||
|
```python
|
||||||
|
def main():
|
||||||
|
print('正在爬取数据')
|
||||||
|
url = 'https://36kr.com/newsflashes'
|
||||||
|
headers = {'User-Agent': random.choice(user_agent)}
|
||||||
|
response = requests.get(url, headers=headers)
|
||||||
|
response=response.content.decode('utf-8', 'ignore')
|
||||||
|
soup = BeautifulSoup(response, 'lxml')
|
||||||
|
news = soup.find_all('a', class_='item-title')
|
||||||
|
news_list=[]
|
||||||
|
for i in news:
|
||||||
|
title=i.get_text()
|
||||||
|
href='https://36kr.com'+i['href']
|
||||||
|
news_list.append(title+'<br>'+href)
|
||||||
|
info='<br></br>'.join(news_list)
|
||||||
|
```
|
||||||
|
|
||||||
|
接下来就是配置邮箱的发送信息
|
||||||
|
|
||||||
|
```python
|
||||||
|
smtpserver = 'smtp.qq.com'
|
||||||
|
|
||||||
|
# 发送邮箱用户名密码
|
||||||
|
user = ''
|
||||||
|
password = ''
|
||||||
|
|
||||||
|
# 发送和接收邮箱
|
||||||
|
sender = ''
|
||||||
|
receive = ''
|
||||||
|
|
||||||
|
def send_email(content):
|
||||||
|
# 通过QQ邮箱发送
|
||||||
|
title='36kr快讯'
|
||||||
|
subject = title
|
||||||
|
msg = MIMEText(content, 'html', 'utf-8')
|
||||||
|
msg['Subject'] = Header(subject, 'utf-8')
|
||||||
|
msg['From'] = sender
|
||||||
|
msg['To'] = receive
|
||||||
|
# SSL协议端口号要使用465
|
||||||
|
smtp = smtplib.SMTP_SSL(smtpserver, 465) # 这里是服务器端口!
|
||||||
|
# HELO 向服务器标识用户身份
|
||||||
|
smtp.helo(smtpserver)
|
||||||
|
# 服务器返回结果确认
|
||||||
|
smtp.ehlo(smtpserver)
|
||||||
|
# 登录邮箱服务器用户名和密码
|
||||||
|
smtp.login(user, password)
|
||||||
|
smtp.sendmail(sender, receive, msg.as_string())
|
||||||
|
smtp.quit()
|
||||||
|
```
|
||||||
|
|
||||||
|
最后我们的整个代码文件为
|
||||||
|
|
||||||
|
```python
|
||||||
|
import requests
|
||||||
|
import random
|
||||||
|
from bs4 import BeautifulSoup
|
||||||
|
import smtplib # 发送邮件模块
|
||||||
|
from email.mime.text import MIMEText # 定义邮件内容
|
||||||
|
from email.header import Header # 定义邮件标题
|
||||||
|
|
||||||
|
smtpserver = 'smtp.qq.com'
|
||||||
|
|
||||||
|
# 发送邮箱用户名密码
|
||||||
|
user = ''
|
||||||
|
password = ''
|
||||||
|
|
||||||
|
# 发送和接收邮箱
|
||||||
|
sender = ''
|
||||||
|
receive = ''
|
||||||
|
|
||||||
|
user_agent = [
|
||||||
|
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
|
||||||
|
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
|
||||||
|
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
|
||||||
|
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
|
||||||
|
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
|
||||||
|
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
|
||||||
|
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
|
||||||
|
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
|
||||||
|
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
|
||||||
|
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
|
||||||
|
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)"]
|
||||||
|
|
||||||
|
def main():
|
||||||
|
print('正在爬取数据')
|
||||||
|
url = 'https://36kr.com/newsflashes'
|
||||||
|
headers = {'User-Agent': random.choice(user_agent)}
|
||||||
|
response = requests.get(url, headers=headers)
|
||||||
|
response=response.content.decode('utf-8', 'ignore')
|
||||||
|
soup = BeautifulSoup(response, 'lxml')
|
||||||
|
news = soup.find_all('a', class_='item-title')
|
||||||
|
news_list=[]
|
||||||
|
for i in news:
|
||||||
|
title=i.get_text()
|
||||||
|
href='https://36kr.com'+i['href']
|
||||||
|
news_list.append(title+'<br>'+href)
|
||||||
|
info='<br></br>'.join(news_list)
|
||||||
|
print('正在发送信息')
|
||||||
|
send_email(info)
|
||||||
|
|
||||||
|
def send_email(content):
|
||||||
|
# 通过QQ邮箱发送
|
||||||
|
title='36kr快讯'
|
||||||
|
subject = title
|
||||||
|
msg = MIMEText(content, 'html', 'utf-8')
|
||||||
|
msg['Subject'] = Header(subject, 'utf-8')
|
||||||
|
msg['From'] = sender
|
||||||
|
msg['To'] = receive
|
||||||
|
# SSL协议端口号要使用465
|
||||||
|
smtp = smtplib.SMTP_SSL(smtpserver, 465) # 这里是服务器端口!
|
||||||
|
# HELO 向服务器标识用户身份
|
||||||
|
smtp.helo(smtpserver)
|
||||||
|
# 服务器返回结果确认
|
||||||
|
smtp.ehlo(smtpserver)
|
||||||
|
# 登录邮箱服务器用户名和密码
|
||||||
|
smtp.login(user, password)
|
||||||
|
smtp.sendmail(sender, receive, msg.as_string())
|
||||||
|
smtp.quit()
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
```
|
||||||
|
|
||||||
|
**Task5 END.**
|
||||||
|
|
||||||
|
--- By: 牧小熊
|
||||||
|
|
||||||
|
> 华中农业大学研究生,Datawhale成员, Datawhale优秀原创作者
|
||||||
|
>
|
||||||
|
> 知乎:https://www.zhihu.com/people/muxiaoxiong
|
||||||
|
|
||||||
|
关于Datawhale: Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale 以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。 本次数据挖掘路径学习,专题知识将在天池分享,详情可关注Datawhale:
|
||||||
|
|
||||||
|
[](https://camo.githubusercontent.com/8578ee173c78b587d5058439bbd0b98fa39c173def229a8c3d957e62aac0b649/68747470733a2f2f696d672d626c6f672e6373646e696d672e636e2f323032303039313330313032323639382e706e67237069635f63656e746572)
|
||||||
Reference in New Issue
Block a user