Merge branch 'master' of https://github.com/datawhalechina/team-learning-program
This commit is contained in:
@@ -1,4 +1,4 @@
|
||||
# 02 C#语言基本语法结构
|
||||
# 01 C#语言基本语法结构
|
||||
|
||||
**知识结构:**
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# 03 C#面向对象设计 I
|
||||
# 02 C#面向对象设计 I
|
||||
|
||||
|
||||
**知识结构:**
|
||||
@@ -1,7 +1,7 @@
|
||||
|
||||
|
||||
|
||||
# 04 C#面向对象设计 II
|
||||
# 03 C#面向对象设计 II
|
||||
|
||||
|
||||
**知识结构:**
|
||||
@@ -1,4 +1,4 @@
|
||||
# <20><><EFBFBD><EFBFBD>
|
||||
# 01 <20><><EFBFBD><EFBFBD>
|
||||
|
||||
֪ʶ<EFBFBD>ṹ<EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
Binary file not shown.
@@ -1,6 +1,6 @@
|
||||
|
||||
|
||||
# 09 栈与递归
|
||||
# 03 栈与递归
|
||||
|
||||
**知识结构:**
|
||||
|
||||
@@ -16,7 +16,7 @@
|
||||
|
||||
插入(入栈)和删除(出栈)操作只能在一端(栈顶)进行的线性表。即先进后出(First In Last Out)的线性表。
|
||||
|
||||
例1 :线性表`$(a_0,a_1,?,a_{n-1)}$`进栈与出栈演示。
|
||||
例1 :线性表 $(a_0,a_1,?,a_{n-1)}$ 进栈与出栈演示。
|
||||
|
||||
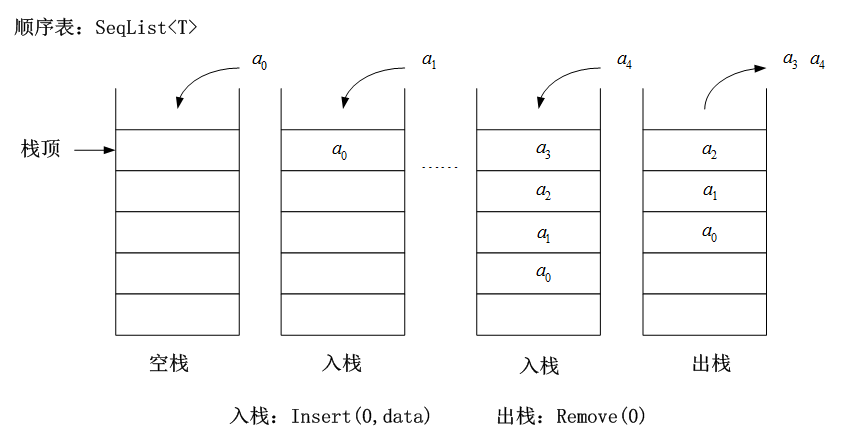
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
|
||||
# 10 队列与多线程
|
||||
# 04 队列与多线程
|
||||
|
||||
**知识结构:**
|
||||
|
||||
@@ -1,791 +0,0 @@
|
||||
|
||||
# Leetcodeͬ<65><CDAC><EFBFBD><EFBFBD>ϰ<EFBFBD><CFB0>һ<EFBFBD><D2BB>
|
||||
|
||||
## <20><>Ŀ01<30><31><EFBFBD><EFBFBD><EFBFBD><EFBFBD>֮<EFBFBD><D6AE>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>1
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/two-sum/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> `nums` <20><>һ<EFBFBD><D2BB>Ŀ<EFBFBD><C4BF>ֵ `target`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڸ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ҳ<EFBFBD><EFBFBD><EFBFBD>ΪĿ<EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD> <b><3E><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD></b><3E><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǵ<EFBFBD><C7B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>±ꡣ
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Լ<EFBFBD><EFBFBD><EFBFBD>ÿ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧһ<EFBFBD><EFBFBD><EFBFBD>𰸡<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǣ<EFBFBD><EFBFBD>㲻<EFBFBD><EFBFBD><EFBFBD>ظ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͬ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
|
||||
**ʾ<><CABE>1:**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums = [2, 7, 11, 15], target = 9
|
||||
|
||||
<EFBFBD><EFBFBD>Ϊ nums[0] + nums[1] = 2 + 7 = 9<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Է<EFBFBD><EFBFBD><EFBFBD> [0, 1]
|
||||
```
|
||||
|
||||
**ʾ<><CABE>2<EFBFBD><32>**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums = [230, 863, 916, 585, 981, 404, 316, 785, 88, 12, 70, 435, 384, 778, 887, 755, 740, 337, 86, 92, 325, 422, 815, 650, 920, 125, 277, 336, 221, 847, 168, 23, 677, 61, 400, 136, 874, 363, 394, 199, 863, 997, 794, 587, 124, 321, 212, 957, 764, 173, 314, 422, 927, 783, 930, 282, 306, 506, 44, 926, 691, 568, 68, 730, 933, 737, 531, 180, 414, 751, 28, 546, 60, 371, 493, 370, 527, 387, 43, 541, 13, 457, 328, 227, 652, 365, 430, 803, 59, 858, 538, 427, 583, 368, 375, 173, 809, 896, 370, 789], target = 542
|
||||
|
||||
<EFBFBD><EFBFBD>Ϊ nums[28] + nums[45] = 221 + 321 = 542<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Է<EFBFBD><EFBFBD><EFBFBD> [28, 45]
|
||||
```
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
˼·<EFBFBD><EFBFBD>ֱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ñ<EFBFBD><EFBFBD><EFBFBD>ƥ<EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD><EFBFBD>
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>432 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 65.82% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>30.8 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 8.67% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int[] TwoSum(int[] nums, int target)
|
||||
{
|
||||
int[] result = new int[2];
|
||||
for (int i = 0; i < nums.Length - 1; i++)
|
||||
{
|
||||
int find = target - nums[i];
|
||||
for (int j = i + 1; j < nums.Length; j++)
|
||||
{
|
||||
if (find == nums[j])
|
||||
{
|
||||
result[0] = i;
|
||||
result[1] = j;
|
||||
return result;
|
||||
}
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ02<30><32>ɾ<EFBFBD><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>е<EFBFBD><D0B5>ظ<EFBFBD><D8B8><EFBFBD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>26
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD> **<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫ<EFBFBD><D2AA> **ԭ<><D4AD>** ɾ<><C9BE><EFBFBD>ظ<EFBFBD><D8B8><EFBFBD><EFBFBD>ֵ<EFBFBD>Ԫ<EFBFBD>أ<EFBFBD>ʹ<EFBFBD><CAB9>ÿ<EFBFBD><C3BF>Ԫ<EFBFBD><D4AA>ֻ<EFBFBD><D6BB><EFBFBD><EFBFBD>һ<EFBFBD>Σ<EFBFBD><CEA3><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ƴ<EFBFBD><C6B3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>³<EFBFBD><C2B3>ȡ<EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD>Ҫʹ<EFBFBD>ö<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ռ䣬<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> **ԭ<><D4AD><EFBFBD><EFBFBD><DEB8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>** <20><><EFBFBD><EFBFBD>ʹ<EFBFBD><CAB9> O(1) <20><><EFBFBD><EFBFBD><EFBFBD>ռ<EFBFBD><D5BC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɡ<EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums = [1,1,2],
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD>÷<EFBFBD><EFBFBD><EFBFBD><EFBFBD>µij<EFBFBD><EFBFBD><EFBFBD> 2, <EFBFBD><EFBFBD><EFBFBD><EFBFBD>ԭ<EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums <EFBFBD><EFBFBD>ǰ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ر<EFBFBD><EFBFBD><EFBFBD>Ϊ 1, 2<EFBFBD><EFBFBD>
|
||||
<EFBFBD>㲻<EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>г<EFBFBD><EFBFBD><EFBFBD><EFBFBD>³<EFBFBD><EFBFBD>Ⱥ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums = [0,0,1,1,1,2,2,3,3,4],
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD>÷<EFBFBD><EFBFBD><EFBFBD><EFBFBD>µij<EFBFBD><EFBFBD><EFBFBD> 5, <EFBFBD><EFBFBD><EFBFBD><EFBFBD>ԭ<EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums <EFBFBD><EFBFBD>ǰ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ر<EFBFBD><EFBFBD><EFBFBD>Ϊ 0, 1, 2, 3, 4<EFBFBD><EFBFBD>
|
||||
<EFBFBD>㲻<EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>г<EFBFBD><EFBFBD><EFBFBD><EFBFBD>³<EFBFBD><EFBFBD>Ⱥ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
```
|
||||
|
||||
<b>˵<><CBB5></b>:
|
||||
|
||||
Ϊʲô<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ĵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>?
|
||||
|
||||
<EFBFBD><EFBFBD>ע<EFBFBD>⣬<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ԡ<EFBFBD>**<2A><><EFBFBD><EFBFBD>**<2A><><EFBFBD><EFBFBD>ʽ<EFBFBD><CABD><EFBFBD>ݵģ<DDB5><C4A3><EFBFBD><EFBFBD><EFBFBD>ζ<EFBFBD><CEB6><EFBFBD>ں<EFBFBD><DABA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><DEB8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ<EFBFBD><DAB5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǿɼ<C7BF><C9BC>ġ<EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڲ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>:
|
||||
|
||||
```c
|
||||
// nums <20><><EFBFBD>ԡ<EFBFBD><D4A1><EFBFBD><EFBFBD>á<EFBFBD><C3A1><EFBFBD>ʽ<EFBFBD><CABD><EFBFBD>ݵġ<DDB5>Ҳ<EFBFBD><D2B2><EFBFBD><EFBFBD>˵<EFBFBD><CBB5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʵ<EFBFBD><CAB5><EFBFBD><EFBFBD><EFBFBD>κο<CEBA><CEBF><EFBFBD>
|
||||
int len = removeDuplicates(nums);
|
||||
|
||||
// <20>ں<EFBFBD><DABA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><DEB8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ<EFBFBD><DAB5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǿɼ<C7BF><C9BC>ġ<EFBFBD>
|
||||
// <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĺ<EFBFBD><C4BA><EFBFBD><EFBFBD><EFBFBD><EFBFBD>صij<D8B5><C4B3><EFBFBD>, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ӡ<EFBFBD><D3A1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>иó<D0B8><C3B3>ȷ<EFBFBD>Χ<EFBFBD>ڵ<EFBFBD><DAB5><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
for (int i = 0; i < len; i++) {
|
||||
print(nums[i]);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
˼·<EFBFBD><EFBFBD>˫<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`j`<EFBFBD><EFBFBD>`i`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums[j] == nums[i]`ʱ<EFBFBD><EFBFBD>`j++`<EFBFBD>Ϳ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ظ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`i++`<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums[i] = nums[j]`<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD>ƹ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ִ<EFBFBD>е<EFBFBD>ĩβ<EFBFBD><EFBFBD><EFBFBD>ɣ<EFBFBD>ʱ<EFBFBD>临<EFBFBD>Ӷ<EFBFBD>Ϊ`O(n)`<EFBFBD><EFBFBD>
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>300 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 64.43% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>33.5 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.48% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int RemoveDuplicates(int[] nums)
|
||||
{
|
||||
if (nums.Length < 2)
|
||||
return nums.Length;
|
||||
|
||||
int i = 0;
|
||||
for (int j = 1; j < nums.Length; j++)
|
||||
{
|
||||
if (nums[j] != nums[i])
|
||||
{
|
||||
i++;
|
||||
nums[i] = nums[j];
|
||||
}
|
||||
}
|
||||
return i + 1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ03<30><33><EFBFBD>Ƴ<EFBFBD>Ԫ<EFBFBD><D4AA>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>27
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/remove-element/
|
||||
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums`<EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>ֵ`val`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫ**ԭ<><D4AD>**<2A>Ƴ<EFBFBD><C6B3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵ<EFBFBD><D6B5><EFBFBD><EFBFBD>`val`<EFBFBD><EFBFBD>Ԫ<EFBFBD>أ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ƴ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>³<EFBFBD><EFBFBD>ȡ<EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD>Ҫʹ<EFBFBD>ö<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ռ䣬<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**ԭ<><D4AD><EFBFBD><EFBFBD><DEB8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><><EFBFBD><EFBFBD>ʹ<EFBFBD><CAB9> O(1) <20><><EFBFBD><EFBFBD><EFBFBD>ռ<EFBFBD><D5BC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɡ<EFBFBD>
|
||||
|
||||
Ԫ<EFBFBD>ص<EFBFBD>˳<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ըı䡣<EFBFBD>㲻<EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>г<EFBFBD><EFBFBD><EFBFBD><EFBFBD>³<EFBFBD><EFBFBD>Ⱥ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
|
||||
**ʾ<><CABE> 1:**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums = [3,2,2,3], val = 3,
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD>÷<EFBFBD><EFBFBD><EFBFBD><EFBFBD>µij<EFBFBD><EFBFBD><EFBFBD> 2, <EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums <EFBFBD>е<EFBFBD>ǰ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ؾ<EFBFBD>Ϊ 2<EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD>㲻<EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>г<EFBFBD><EFBFBD><EFBFBD><EFBFBD>³<EFBFBD><EFBFBD>Ⱥ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
```
|
||||
|
||||
**ʾ<><CABE> 2:**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums = [0,1,2,2,3,0,4,2], val = 2,
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD>÷<EFBFBD><EFBFBD><EFBFBD><EFBFBD>µij<EFBFBD><EFBFBD><EFBFBD> 5, <EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums <EFBFBD>е<EFBFBD>ǰ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD><EFBFBD>Ϊ 0, 1, 3, 0, 4<EFBFBD><EFBFBD>
|
||||
|
||||
ע<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ؿ<EFBFBD>Ϊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>˳<EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD>㲻<EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>г<EFBFBD><EFBFBD><EFBFBD><EFBFBD>³<EFBFBD><EFBFBD>Ⱥ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
```
|
||||
|
||||
**ʾ<><CABE> 3:**
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺[] value = 0
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>0
|
||||
```
|
||||
|
||||
**ʾ<><CABE> 4:**
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺[1] value = 1
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>0
|
||||
```
|
||||
|
||||
**ʾ<><CABE> 5:**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺[4,5] value = 5
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>1
|
||||
```
|
||||
|
||||
|
||||
|
||||
**˵<EFBFBD><EFBFBD>:**
|
||||
|
||||
Ϊʲô<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ĵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>?
|
||||
|
||||
<EFBFBD><EFBFBD>ע<EFBFBD>⣬<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ԡ<EFBFBD>**<2A><><EFBFBD><EFBFBD>**<2A><><EFBFBD><EFBFBD>ʽ<EFBFBD><CABD><EFBFBD>ݵģ<DDB5><C4A3><EFBFBD><EFBFBD><EFBFBD>ζ<EFBFBD><CEB6><EFBFBD>ں<EFBFBD><DABA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><DEB8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ<EFBFBD><DAB5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǿɼ<C7BF><C9BC>ġ<EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڲ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>:
|
||||
|
||||
```c
|
||||
// nums <20><><EFBFBD>ԡ<EFBFBD><D4A1><EFBFBD><EFBFBD>á<EFBFBD><C3A1><EFBFBD>ʽ<EFBFBD><CABD><EFBFBD>ݵġ<DDB5>Ҳ<EFBFBD><D2B2><EFBFBD><EFBFBD>˵<EFBFBD><CBB5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʵ<EFBFBD><CAB5><EFBFBD><EFBFBD><EFBFBD>κο<CEBA><CEBF><EFBFBD>
|
||||
int len = removeElement(nums, val);
|
||||
|
||||
// <20>ں<EFBFBD><DABA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><DEB8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ<EFBFBD><DAB5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǿɼ<C7BF><C9BC>ġ<EFBFBD>
|
||||
// <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĺ<EFBFBD><C4BA><EFBFBD><EFBFBD><EFBFBD><EFBFBD>صij<D8B5><C4B3><EFBFBD>, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ӡ<EFBFBD><D3A1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>иó<D0B8><C3B3>ȷ<EFBFBD>Χ<EFBFBD>ڵ<EFBFBD><DAB5><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
for (int i = 0; i < len; i++) {
|
||||
print(nums[i]);
|
||||
}
|
||||
```
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
˼·<EFBFBD><EFBFBD>˫<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>˫<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`i`<EFBFBD><EFBFBD>`j`<EFBFBD><EFBFBD>`i`Ϊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϻ<EFBFBD><EFBFBD><EFBFBD>`j`Ϊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǰ<EFBFBD>塣<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums[j]!=val`<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`num[j]`<EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`num[i]`<EFBFBD><EFBFBD>ѭ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`i`ָ<EFBFBD><EFBFBD>ǰ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>أ<EFBFBD><EFBFBD><EFBFBD>Ϊ<EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>أ<EFBFBD><EFBFBD>Ӷ<EFBFBD><EFBFBD>ﵽ<EFBFBD><EFBFBD><EFBFBD>Ƴ<EFBFBD>Ԫ<EFBFBD>ص<EFBFBD>Ŀ<EFBFBD>ģ<EFBFBD>ʱ<EFBFBD>临<EFBFBD>Ӷ<EFBFBD>Ϊ `O(n)`<EFBFBD><EFBFBD>
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>272 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 94.41% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>29.9 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.21% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int RemoveElement(int[] nums, int val)
|
||||
{
|
||||
int i = 0;
|
||||
for (int j = 0; j < nums.Length; j++)
|
||||
{
|
||||
if (nums[j] != val)
|
||||
{
|
||||
nums[i] = nums[j];
|
||||
i++;
|
||||
}
|
||||
}
|
||||
return i;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ04<30><34><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>53
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/maximum-subarray/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums`<EFBFBD><EFBFBD><EFBFBD>ҵ<EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>͵<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>飨<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ٰ<EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>Ԫ<EFBFBD>أ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>͡<EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [-2,1,-3,4,-1,2,1,-5,4],
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 6
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> [4,-1,2,1] <EFBFBD>ĺ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ 6<EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [-2,1],
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1
|
||||
```
|
||||
|
||||
<b><3E><><EFBFBD><EFBFBD></b>:
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ѿ<EFBFBD>ʵ<EFBFBD>ָ<EFBFBD><EFBFBD>Ӷ<EFBFBD>Ϊ`O(n)`<EFBFBD>Ľⷨ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʹ<EFBFBD>ø<EFBFBD>Ϊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ķ<EFBFBD><EFBFBD>η<EFBFBD><EFBFBD><EFBFBD><EFBFBD>⡣
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
˼·<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ñ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD><EFBFBD>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 596 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 14.18% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 24.5 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.88% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution {
|
||||
public int MaxSubArray(int[] nums) {
|
||||
int len = nums.Length;
|
||||
if (len == 0)
|
||||
return 0;
|
||||
if (len == 1)
|
||||
return nums[0];
|
||||
int max = int.MinValue;
|
||||
|
||||
for (int i = 0; i < len; i++)
|
||||
{
|
||||
int sum = nums[i];
|
||||
if (sum > max)
|
||||
{
|
||||
max = sum;
|
||||
}
|
||||
for (int j = i + 1; j < len; j++)
|
||||
{
|
||||
sum += nums[j];
|
||||
if (sum > max)
|
||||
{
|
||||
max = sum;
|
||||
}
|
||||
}
|
||||
}
|
||||
return max;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ05<30><35>ʢ<EFBFBD><CAA2><EFBFBD><EFBFBD>ˮ<EFBFBD><CBAE><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>11
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/container-with-most-water/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`n`<EFBFBD><EFBFBD><EFBFBD>Ǹ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`a1<61><31>a2<61><32>...<2E><>an`<EFBFBD><EFBFBD>ÿ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>е<EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`(i, ai)`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڻ<EFBFBD>`n`<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֱ<EFBFBD>ߣ<EFBFBD><EFBFBD><EFBFBD>ֱ<EFBFBD><EFBFBD>`i` <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>˵<EFBFBD><CBB5>ֱ<EFBFBD>Ϊ`(i, ai)`<EFBFBD><EFBFBD>`(i, 0)`<EFBFBD><EFBFBD><EFBFBD>ҳ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>е<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ߣ<EFBFBD>ʹ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`x`<EFBFBD>Ṳͬ<EFBFBD><EFBFBD><EFBFBD>ɵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ˮ<EFBFBD><EFBFBD>
|
||||
|
||||
<b>˵<><CBB5></b><3E><><EFBFBD>㲻<EFBFBD><E3B2BB><EFBFBD><EFBFBD>б<EFBFBD><D0B1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`n`<EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ 2<><32>
|
||||
|
||||
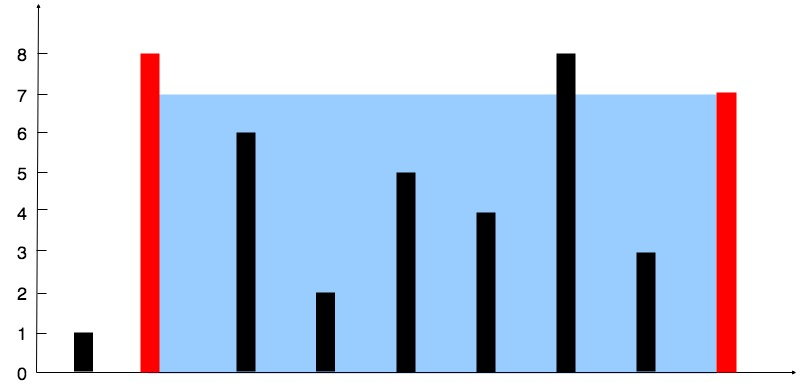
|
||||
|
||||
ͼ<EFBFBD>д<EFBFBD>ֱ<EFBFBD>ߴ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> [1,8,6,2,5,4,8,3,7]<5D><><EFBFBD>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD><EFBFBD>£<EFBFBD><C2A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܹ<EFBFBD><DCB9><EFBFBD><EFBFBD><EFBFBD>ˮ<EFBFBD><CBAE><EFBFBD><EFBFBD>ʾΪ<CABE><CEAA>ɫ<EFBFBD><C9AB><EFBFBD>֣<EFBFBD><D6A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵΪ 49<34><39>
|
||||
|
||||
<b>ʾ<><CABE></b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [1,8,6,2,5,4,8,3,7]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 49
|
||||
```
|
||||
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
˼·<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>˫<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ķ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
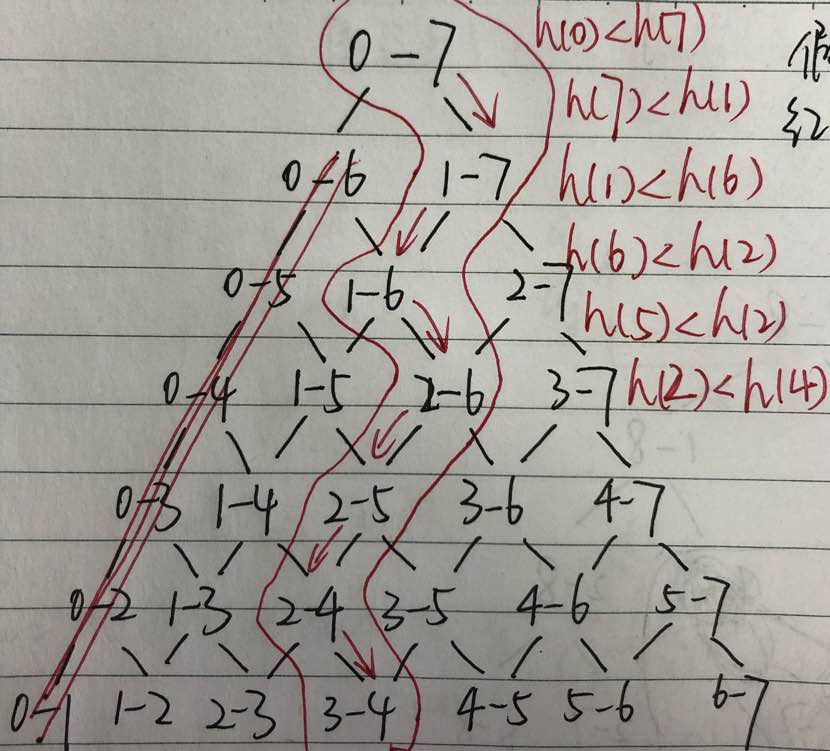
|
||||
|
||||
<EFBFBD><EFBFBD>0-7<>ߵ<EFBFBD>1-7<><37>һ<EFBFBD><D2BB>Ϊ<EFBFBD><CEAA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊʲô<CAB2><C3B4><EFBFBD><EFBFBD>0-6<><36>һ<EFBFBD><D2BB>֧<EFBFBD><D6A7>
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD>h(i)<EFBFBD><EFBFBD>ʾ<EFBFBD><EFBFBD>i<EFBFBD><EFBFBD><EFBFBD>߶εĸ߶ȣ<EFBFBD>S(ij)<EFBFBD><EFBFBD>ʾ<EFBFBD><EFBFBD>i<EFBFBD><EFBFBD><EFBFBD>߶κ͵<EFBFBD>j<EFBFBD><EFBFBD><EFBFBD>߶<EFBFBD>Ȧ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD>֪ h(0) < h(7)<EFBFBD><EFBFBD><EFBFBD>Ӷ<EFBFBD>S(07) = h(0) * 7<EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD>S(06) = min(h(0), h(6)) * 6<EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD>h(0) <= h(6)<EFBFBD><EFBFBD><EFBFBD><EFBFBD>S(06) = h(0) * 6<EFBFBD><EFBFBD>
|
||||
<EFBFBD><EFBFBD>h(0) > h(6)<EFBFBD><EFBFBD><EFBFBD><EFBFBD>S(06) = h(6) * 6<EFBFBD><EFBFBD>S(06) < h(0) * 6<EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD>ɴ˿<EFBFBD>֪<EFBFBD><EFBFBD>S(06)<EFBFBD><EFBFBD>ȻС<EFBFBD><EFBFBD>S(07)<EFBFBD><EFBFBD>
|
||||
```
|
||||
<EFBFBD><EFBFBD>ÿһ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͬ<EFBFBD><EFBFBD><EFBFBD>ķ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>֪<EFBFBD><EFBFBD><EFBFBD><EFBFBD>˫<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ߵ<EFBFBD>·<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- 50 / 50 <20><>ͨ<EFBFBD><CDA8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 144 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 99.64% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 26.6 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.45% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int MaxArea(int[] height)
|
||||
{
|
||||
int i = 0, j = height.Length - 1;
|
||||
int max = int.MinValue;
|
||||
while (i < j)
|
||||
{
|
||||
int temp = (j - i) * Math.Min(height[i], height[j]);
|
||||
if (temp > max)
|
||||
{
|
||||
max = temp;
|
||||
}
|
||||
if (height[i] < height[j])
|
||||
{
|
||||
i++;
|
||||
}
|
||||
else
|
||||
{
|
||||
j--;
|
||||
}
|
||||
}
|
||||
return max;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ06<30><36><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ת<EFBFBD><D7AA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>33
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/search-in-rotated-sorted-array/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD>谴<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԥ<EFBFBD><EFBFBD>δ֪<EFBFBD><EFBFBD>ij<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ͻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ת<EFBFBD><EFBFBD>
|
||||
|
||||
( <20><><EFBFBD>磬<EFBFBD><E7A3AC><EFBFBD><EFBFBD> [0,1,2,4,5,6,7] <20><><EFBFBD>ܱ<EFBFBD>Ϊ [4,5,6,7,0,1,2] )<29><>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ŀ<EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>д<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ŀ<EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> -1 <20><>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Լ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>в<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ظ<EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㷨ʱ<EFBFBD>临<EFBFBD>Ӷȱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`O(log n)`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: nums = [4,5,6,7,0,1,2], target = 0
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 4
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: nums = [4,5,6,7,0,1,2], target = 3
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: -1
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 3</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: nums = [5,1,3], target = 5
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 0
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 4</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: nums = [4,5,6,7,8,1,2,3], target = 8
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 4
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 5</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: nums = [3,1], target = 1
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1
|
||||
```
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
˼·<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ö<EFBFBD><EFBFBD>ַ<EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 128 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 97.17% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 23.8 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 12.00% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int Search(int[] nums, int target)
|
||||
{
|
||||
int i = 0, j = nums.Length - 1;
|
||||
while (i <= j)
|
||||
{
|
||||
int mid = (i + j) / 2;
|
||||
if (nums[mid] == target)
|
||||
return mid;
|
||||
|
||||
if (nums[mid] >= nums[i])
|
||||
{
|
||||
//<2F><><EFBFBD>벿<EFBFBD><EBB2BF><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
if (target > nums[mid])
|
||||
{
|
||||
i = mid + 1;
|
||||
}
|
||||
else
|
||||
{
|
||||
if (target == nums[i])
|
||||
return i;
|
||||
|
||||
if (target > nums[i])
|
||||
j = mid - 1;
|
||||
else
|
||||
i = mid + 1;
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
if (target < nums[mid])
|
||||
{
|
||||
j = mid - 1;
|
||||
}
|
||||
else
|
||||
{
|
||||
if (target == nums[j])
|
||||
return j;
|
||||
if (target < nums[j])
|
||||
i = mid + 1;
|
||||
else
|
||||
j = mid - 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ07<30><37><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>еĵ<D0B5>K<EFBFBD><4B><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD><D4AA>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>215
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/kth-largest-element-in-an-array/
|
||||
|
||||
<EFBFBD><EFBFBD>δ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ҵ<EFBFBD><EFBFBD><EFBFBD> `k` <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ء<EFBFBD><D8A1><EFBFBD>ע<EFBFBD>⣬<EFBFBD><E2A3AC><EFBFBD><EFBFBD>Ҫ<EFBFBD>ҵ<EFBFBD><D2B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĵ<EFBFBD> `k` <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>أ<EFBFBD><D8A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǵ<EFBFBD> `k` <20><><EFBFBD><EFBFBD>ͬ<EFBFBD><CDAC>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [3,2,1,5,6,4] <EFBFBD><EFBFBD> k = 2
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 5
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [3,2,3,1,2,4,5,5,6] <EFBFBD><EFBFBD> k = 4
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 4
|
||||
```
|
||||
|
||||
<b>˵<><CBB5></b>:
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Լ<EFBFBD><EFBFBD><EFBFBD> `k` <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ч<EFBFBD>ģ<EFBFBD><C4A3><EFBFBD> `1 <20><> k <20><> <20><><EFBFBD><EFBFBD><EFBFBD>ij<EFBFBD><C4B3><EFBFBD>`<EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
˼·<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ķ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 152 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 76.47% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 24.6 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.55% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int FindKthLargest(int[] nums, int k)
|
||||
{
|
||||
nums = nums.OrderBy(a => a).ToArray();
|
||||
return nums[nums.Length - k];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ08<30><38><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ij˻<C4B3>
|
||||
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>238
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/product-of-array-except-self/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ`n`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`n > 1`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`output`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`output[i]`<EFBFBD><EFBFBD><EFBFBD><EFBFBD> `nums`<EFBFBD>г<EFBFBD>`nums[i]`֮<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>صij˻<EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE></b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [1,2,3,4]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [24,12,8,6]
|
||||
```
|
||||
|
||||
<b>˵<><CBB5></b>: <20>벻Ҫʹ<D2AA>ó<EFBFBD><C3B3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`O(n)` ʱ<>临<EFBFBD>Ӷ<EFBFBD><D3B6><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɴ<EFBFBD><C9B4>⡣
|
||||
|
||||
<b><3E><><EFBFBD><EFBFBD></b><3E><>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڳ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ռ临<EFBFBD>Ӷ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ŀ<EFBFBD>𣿣<EFBFBD> <20><><EFBFBD>ڶԿռ临<D5BC>Ӷȷ<D3B6><C8B7><EFBFBD><EFBFBD><EFBFBD>Ŀ<EFBFBD>ģ<EFBFBD><C4A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>鲻<EFBFBD><E9B2BB><EFBFBD><EFBFBD>Ϊ<EFBFBD><CEAA><EFBFBD><EFBFBD><EFBFBD>ռ䡣<D5BC><E4A1A3>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
˼·<EFBFBD><EFBFBD><EFBFBD>˻<EFBFBD> = <20><>ǰ<EFBFBD><C7B0><EFBFBD><EFBFBD><EFBFBD>ߵij˻<C4B3> * <20><>ǰ<EFBFBD><C7B0><EFBFBD>ұߵij˻<C4B3>
|
||||
|
||||
```c
|
||||
[1, 2, 3, 4]
|
||||
<EFBFBD><EFBFBD><EFBFBD>ߵij˻<EFBFBD> [1, 1, 2, 6]
|
||||
<EFBFBD>ұߵij˻<EFBFBD> [24,12,4, 1]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD> = <EFBFBD><EFBFBD>*<EFBFBD><EFBFBD> [24,12,8, 6]
|
||||
```
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 304 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 100.00% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 34.6 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 100.00% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int[] ProductExceptSelf(int[] nums)
|
||||
{
|
||||
int len = nums.Length;
|
||||
int[] output1 = new int[len];//<2F><><EFBFBD><EFBFBD><EFBFBD>˻<EFBFBD>
|
||||
int[] output2 = new int[len];//<2F><><EFBFBD><EFBFBD><EFBFBD>˻<EFBFBD>
|
||||
output1[0] = 1;
|
||||
output2[len - 1] = 1;
|
||||
for (int i = 1; i < len; i++)
|
||||
{
|
||||
output1[i] = output1[i - 1]*nums[i - 1];
|
||||
output2[len - i - 1] = output2[len - i]*nums[len - i];
|
||||
}
|
||||
for (int i = 0; i < len; i++)
|
||||
{
|
||||
output1[i] *= output2[i];
|
||||
}
|
||||
return output1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ09<30><39>Ѱ<EFBFBD><D1B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD><CEBB>
|
||||
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>4
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/median-of-two-sorted-arrays/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>СΪ`m`<EFBFBD><EFBFBD>`n`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums1`<EFBFBD><EFBFBD>`nums2`<EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ҳ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD><EFBFBD>ʱ<EFBFBD>临<EFBFBD>Ӷ<EFBFBD>Ϊ`O(log(m + n))`<EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Լ<EFBFBD><EFBFBD><EFBFBD>`nums1`<EFBFBD><EFBFBD>`nums2`<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͬʱΪ<EFBFBD>ա<EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
```c
|
||||
nums1 = [1, 3]
|
||||
nums2 = [2]
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD><EFBFBD><EFBFBD><EFBFBD> 2.0
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
|
||||
```c
|
||||
nums1 = [1, 2]
|
||||
nums2 = [3, 4]
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD><EFBFBD><EFBFBD><EFBFBD> (2 + 3)/2 = 2.5
|
||||
```
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
˼·<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ö<EFBFBD><EFBFBD>ֲ<EFBFBD><EFBFBD>ԡ<EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD>λ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ϻ<EFBFBD><EFBFBD><EFBFBD>Ϊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȵ<EFBFBD><EFBFBD>Ӽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD>Ӽ<EFBFBD><EFBFBD>е<EFBFBD>Ԫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ǵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD>Ӽ<EFBFBD><EFBFBD>е<EFBFBD>Ԫ<EFBFBD>ء<EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĿҪ<EFBFBD><EFBFBD>ʱ<EFBFBD>临<EFBFBD>Ӷ<EFBFBD>Ϊ`O(log(m + n))`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Բ<EFBFBD><EFBFBD>ܴ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>β<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ҵ<EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӷ<EFBFBD> `O(m + n)`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫͨ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֲ<EFBFBD><EFBFBD>ԣ<EFBFBD>ͨ<EFBFBD><EFBFBD>ÿ<EFBFBD>αȽϣ<EFBFBD><EFBFBD>ܹ<EFBFBD>ֱ<EFBFBD>Ӱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ˢ<EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>֣<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ҵ<EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӷ<EFBFBD>`O(log(m + n))`<EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
```c
|
||||
nums1: [a1,a2,a3,...am]
|
||||
nums2: [b1,b2,b3,...bn]
|
||||
|
||||
[nums1[:i],nums2[:j] | nums1[i:], nums2[j:]]
|
||||
|
||||
nums1 ȡ i <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
nums2 ȡ j = (m+n+1)/2 - i <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
```
|
||||
ֻҪ<EFBFBD><EFBFBD>֤<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> <b><3E><><EFBFBD><EFBFBD></b> <20><>ͬ<EFBFBD><CDAC><EFBFBD><EFBFBD>λ<EFBFBD><CEBB><EFBFBD><EFBFBD><EFBFBD><EFBFBD> `|` <20><><EFBFBD><EFBFBD><EFBFBD>߽<EFBFBD><DFBD>Ա߲<D4B1><DFB2><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӷ<EFBFBD><D3B6><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ö<EFBFBD><C3B6>ַ<EFBFBD><D6B7>ҵ<EFBFBD><D2B5><EFBFBD><EFBFBD>ʵ<EFBFBD>`i`<EFBFBD><EFBFBD>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 160 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 99.18% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 26.8 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.05% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution {
|
||||
public double FindMedianSortedArrays(int[] nums1, int[] nums2) {
|
||||
int m = nums1.Length;
|
||||
int n = nums2.Length;
|
||||
if (m > n)
|
||||
return FindMedianSortedArrays(nums2, nums1);
|
||||
|
||||
int k = (m + n + 1)/2;
|
||||
int left = 0;
|
||||
int right = m;
|
||||
while (left < right)
|
||||
{
|
||||
int i = (left + right)/2;
|
||||
int j = k - i;
|
||||
if (nums1[i] < nums2[j - 1])
|
||||
left = i + 1;
|
||||
else
|
||||
right = i;
|
||||
}
|
||||
int m1 = left;
|
||||
int m2 = k - left;
|
||||
int c1 = Math.Max(m1 == 0 ? int.MinValue : nums1[m1 - 1],
|
||||
m2 == 0 ? int.MinValue : nums2[m2 - 1]);
|
||||
|
||||
if ((m + n)%2 == 1)
|
||||
return c1;
|
||||
|
||||
int c2 = Math.Min(m1 == m ? int.MaxValue : nums1[m1],
|
||||
m2 == n ? int.MaxValue : nums2[m2]);
|
||||
return (c1 + c2)*0.5;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ10<31><30>ȱʧ<C8B1>ĵ<EFBFBD>һ<EFBFBD><D2BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>41
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/first-missing-positive/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>δ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>飬<EFBFBD>ҳ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>û<EFBFBD>г<EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD>С<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE>1</b>:
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [1,2,0]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 3
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE>2</b>:
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [3,4,-1,1]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 2
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE>3</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [7,8,9,11,12]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE>4</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [1,1]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 2
|
||||
```
|
||||
|
||||
<b>ʵ<><CAB5>5</b>:
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: []
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1
|
||||
```
|
||||
|
||||
<b>˵<><CBB5></b>:
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD><EFBFBD>ʱ<EFBFBD>临<EFBFBD>Ӷ<EFBFBD>ӦΪO(n)<29><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֻ<EFBFBD><D6BB>ʹ<EFBFBD>ó<EFBFBD><C3B3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ŀռ䡣
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
˼·<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD>Ρ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ĺ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǣ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`i`<EFBFBD><EFBFBD><EFBFBD>ڡ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>䷶Χ<EFBFBD><EFBFBD><EFBFBD>`i`<EFBFBD><EFBFBD>Ӧ<EFBFBD>÷<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ`i - 1`<EFBFBD><EFBFBD>λ<EFBFBD><EFBFBD><EFBFBD>ϡ<EFBFBD>
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>100 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 93.75% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>24.2 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 97.44% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
|
||||
```c
|
||||
public class Solution {
|
||||
public int FirstMissingPositive(int[] nums) {
|
||||
int len = nums.Length;
|
||||
for (int i = 0; i < len; i++)
|
||||
{
|
||||
while (nums[i] != i + 1 && nums[i] <= len && nums[i] > 0 && nums[i] != nums[nums[i] - 1])
|
||||
{
|
||||
int temp = nums[i];
|
||||
nums[i] = nums[temp - 1];
|
||||
nums[temp - 1] = temp;
|
||||
}
|
||||
}
|
||||
for (int i = 0; i < len; i++)
|
||||
{
|
||||
if (nums[i] != i + 1)
|
||||
{
|
||||
return i + 1;
|
||||
}
|
||||
}
|
||||
return len + 1; //nums.Length = 0
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# 12 数组与稀疏矩阵
|
||||
# 05 数组与稀疏矩阵
|
||||
|
||||
**知识结构:**
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# 13 字符串与整数集合
|
||||
# 06 字符串与整数集合
|
||||
|
||||
**知识点:**
|
||||
|
||||
@@ -1,759 +0,0 @@
|
||||
|
||||
# Leetcodeͬ<65><CDAC><EFBFBD><EFBFBD>ϰ<EFBFBD><CFB0><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
## <20><>Ŀ01<30><31><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>9
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/palindrome-number/
|
||||
|
||||
<EFBFBD>ж<EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ƿ<EFBFBD><EFBFBD>ǻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ָ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ң<EFBFBD><EFBFBD>͵<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 121
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: true
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: -121
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: false
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҷ<EFBFBD>, Ϊ -121 <EFBFBD><EFBFBD> <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>, Ϊ 121- <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 3</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 10
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: false
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>, Ϊ 01 <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
**<EFBFBD><EFBFBD>д<EFBFBD><EFBFBD><EFBFBD><EFBFBD>**
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public bool IsPalindrome(int x)
|
||||
{
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
<b><3E><><EFBFBD><EFBFBD></b>:
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD>ܲ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>תΪ<EFBFBD>ַ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 76 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 98.90% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 14.9 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 85.12% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution {
|
||||
public bool IsPalindrome(int x) {
|
||||
if (x < 0)
|
||||
return false;
|
||||
|
||||
int bit = 1;
|
||||
while (x / bit >= 10)
|
||||
{
|
||||
bit = bit * 10;
|
||||
}
|
||||
|
||||
while (x > 0)
|
||||
{
|
||||
int left = x % 10;
|
||||
int right = x / bit;
|
||||
if (left != right)
|
||||
{
|
||||
return false;
|
||||
}
|
||||
x = (x % bit) / 10;
|
||||
bit = bit / 100;
|
||||
}
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ02<30><32>x <20><>ƽ<EFBFBD><C6BD><EFBFBD><EFBFBD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>69
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/sqrtx/
|
||||
|
||||
ʵ<EFBFBD><EFBFBD> `int sqrt(int x)` <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD>㲢<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`x`<EFBFBD><EFBFBD>ƽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`x`<EFBFBD>ǷǸ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD>ڷ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>IJ<EFBFBD><EFBFBD>֣<EFBFBD>С<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȥ<EFBFBD><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 4
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 2
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 8
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 2
|
||||
˵<EFBFBD><EFBFBD>: 8 <EFBFBD><EFBFBD>ƽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 2.82842..., <EFBFBD><EFBFBD><EFBFBD>ڷ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>С<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȥ<EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
**˼·**<2A><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ţ<EFBFBD>ٵ<EFBFBD><D9B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||

|
||||
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 48 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 100.00% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 13.7 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.40% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution {
|
||||
public int MySqrt(int x) {
|
||||
if (x < 0)
|
||||
throw new ArgumentOutOfRangeException();
|
||||
|
||||
double error = 1.0e-5;
|
||||
double cur = x;
|
||||
while (Math.Abs(cur*cur - x) > error)
|
||||
{
|
||||
cur = (cur + 1.0*x/cur)/2.0;
|
||||
}
|
||||
return (int)cur;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ03<30><33><EFBFBD><EFBFBD>¥<EFBFBD><C2A5>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>70
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/climbing-stairs/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>¥<EFBFBD>ݡ<EFBFBD><EFBFBD><EFBFBD>Ҫ n <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܵ<EFBFBD><DCB5><EFBFBD>¥<EFBFBD><C2A5><EFBFBD><EFBFBD>
|
||||
|
||||
ÿ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 1 <20><> 2 <20><>̨<EFBFBD>ס<EFBFBD><D7A1><EFBFBD><EFBFBD>ж<EFBFBD><D0B6><EFBFBD><EFBFBD>ֲ<EFBFBD>ͬ<EFBFBD>ķ<EFBFBD><C4B7><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>¥<EFBFBD><C2A5><EFBFBD>أ<EFBFBD>
|
||||
|
||||
<b>ע<><D7A2></b><3E><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> n <20><>һ<EFBFBD><D2BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b><3E><>
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺 2
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 2
|
||||
<EFBFBD><EFBFBD><EFBFBD>ͣ<EFBFBD> <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ַ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>¥<EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
1. 1 <EFBFBD><EFBFBD> + 1 <EFBFBD><EFBFBD>
|
||||
2. 2 <EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b><3E><>
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺 3
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 3
|
||||
<EFBFBD><EFBFBD><EFBFBD>ͣ<EFBFBD> <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ַ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>¥<EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
1. 1 <EFBFBD><EFBFBD> + 1 <EFBFBD><EFBFBD> + 1 <EFBFBD><EFBFBD>
|
||||
2. 1 <EFBFBD><EFBFBD> + 2 <EFBFBD><EFBFBD>
|
||||
3. 2 <EFBFBD><EFBFBD> + 1 <EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 3</b><3E><>
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺 44
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 1134903170
|
||||
```
|
||||
|
||||
**˼·**<2A><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ѭ<EFBFBD><D1AD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ŀ<EFBFBD><EFBFBD>
|
||||
- 1 <20>ף<EFBFBD>f(1) = 1 <20>ַ<EFBFBD><D6B7><EFBFBD>
|
||||
- 2 <20>ף<EFBFBD>f(2) = 2 <20>ַ<EFBFBD><D6B7><EFBFBD>
|
||||
- 3 <20>ף<EFBFBD>f(3) = 3 <20>ַ<EFBFBD><D6B7><EFBFBD>
|
||||
- 4 <20>ף<EFBFBD>f(4) = 5 <20>ַ<EFBFBD><D6B7><EFBFBD>
|
||||
- <20><><EFBFBD><EFBFBD>
|
||||
- n <20>ף<EFBFBD>f(n) = f(n-1) + f(n-2) <20>ַ<EFBFBD><D6B7><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ת<EFBFBD><EFBFBD>Ϊ쳲<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>⡣
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 52 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 97.87% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 13.7 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.98% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution {
|
||||
public int ClimbStairs(int n) {
|
||||
if (n <= 2)
|
||||
return n;
|
||||
|
||||
int first = 1;
|
||||
int second = 2;
|
||||
int result = 0;
|
||||
|
||||
for (int i = 3; i <= n; i++)
|
||||
{
|
||||
result = first + second;
|
||||
first = second;
|
||||
second = result;
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ04<30><34><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ʊ<EFBFBD><C6B1><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>121
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>飬<EFBFBD><EFBFBD><EFBFBD>ĵ<EFBFBD> i <20><>Ԫ<EFBFBD><D4AA><EFBFBD><EFBFBD>һ֧<D2BB><D6A7><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ʊ<EFBFBD><C6B1> i <20><><EFBFBD>ļ۸<C4BC><DBB8><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD>ʽ<EFBFBD><EFBFBD>ף<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ֧<EFBFBD><EFBFBD>Ʊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܻ<EFBFBD>ȡ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
ע<EFBFBD><EFBFBD><EFBFBD>㲻<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ʊǰ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ʊ<EFBFBD><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [7,1,5,3,6,4]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 5
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: <EFBFBD>ڵ<EFBFBD> 2 <EFBFBD>죨<EFBFBD><EFBFBD>Ʊ<EFBFBD>۸<EFBFBD> = 1<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>룬<EFBFBD>ڵ<EFBFBD> 5 <EFBFBD>죨<EFBFBD><EFBFBD>Ʊ<EFBFBD>۸<EFBFBD> = 6<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> = 6-1 = 5 <EFBFBD><EFBFBD>
|
||||
ע<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 7-1 = 6, <EFBFBD><EFBFBD>Ϊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>۸<EFBFBD><EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>۸<EFBFBD><EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [7,6,4,3,1]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 0
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>, û<EFBFBD>н<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>, <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ 0<EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
**˼·**<2A><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ѹ<EFBFBD>Ʊ<EFBFBD><C6B1><EFBFBD><EFBFBD><EFBFBD>ܹ<EFBFBD><EFBFBD><D7AC><EFBFBD><EFBFBD>Ǯ<EFBFBD><C7AE><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵ<EFBFBD><D6B5><EFBFBD><EFBFBD>Ϊ<EFBFBD><CEAA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 132 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 97.33% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 24 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.62% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int MaxProfit(int[] prices)
|
||||
{
|
||||
if (prices.Length <= 1)
|
||||
return 0;
|
||||
|
||||
int min = prices[0];
|
||||
int max = 0;
|
||||
for (int i = 1; i < prices.Length; i++)
|
||||
{
|
||||
int earn = prices[i] - min;
|
||||
if (earn > max)
|
||||
{
|
||||
max = earn;
|
||||
}
|
||||
if (prices[i] < min)
|
||||
{
|
||||
min = prices[i];
|
||||
}
|
||||
}
|
||||
return max;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ05<30><35><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ʊ<EFBFBD><C6B1><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1> II
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>122
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii/
|
||||
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>飬<EFBFBD><EFBFBD><EFBFBD>ĵ<EFBFBD> i <20><>Ԫ<EFBFBD><D4AA><EFBFBD><EFBFBD>һ֧<D2BB><D6A7><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ʊ<EFBFBD><C6B1> i <20><><EFBFBD>ļ۸<C4BC><DBB8><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܻ<EFBFBD>ȡ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ծ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɸ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ľ<EFBFBD><EFBFBD>ף<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ֧<EFBFBD><EFBFBD>Ʊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<b>ע<><D7A2></b><3E><><EFBFBD>㲻<EFBFBD><E3B2BB>ͬʱ<CDAC><CAB1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʽ<EFBFBD><CABD>ף<EFBFBD><D7A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ٴι<D9B4><CEB9><EFBFBD>ǰ<EFBFBD><C7B0><EFBFBD>۵<EFBFBD>֮ǰ<D6AE>Ĺ<EFBFBD>Ʊ<EFBFBD><C6B1><EFBFBD><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [7,1,5,3,6,4]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 7
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>:
|
||||
<EFBFBD>ڵ<EFBFBD> 2 <EFBFBD>죨<EFBFBD><EFBFBD>Ʊ<EFBFBD>۸<EFBFBD> = 1<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>룬<EFBFBD>ڵ<EFBFBD> 3 <EFBFBD>죨<EFBFBD><EFBFBD>Ʊ<EFBFBD>۸<EFBFBD> = 5<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>, <EFBFBD><EFBFBD><EFBFBD>ʽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> = 5-1 = 4 <EFBFBD><EFBFBD>
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ<EFBFBD> 4 <EFBFBD>죨<EFBFBD><EFBFBD>Ʊ<EFBFBD>۸<EFBFBD> = 3<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>룬<EFBFBD>ڵ<EFBFBD> 5 <EFBFBD>죨<EFBFBD><EFBFBD>Ʊ<EFBFBD>۸<EFBFBD> = 6<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>, <EFBFBD><EFBFBD><EFBFBD>ʽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> = 6-3 = 3 <EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [1,2,3,4,5]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 4
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>:
|
||||
<EFBFBD>ڵ<EFBFBD> 1 <EFBFBD>죨<EFBFBD><EFBFBD>Ʊ<EFBFBD>۸<EFBFBD> = 1<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>룬<EFBFBD>ڵ<EFBFBD> 5 <EFBFBD><EFBFBD> <EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ʊ<EFBFBD>۸<EFBFBD> = 5<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>, <EFBFBD><EFBFBD><EFBFBD>ʽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> = 5-1 = 4 <EFBFBD><EFBFBD>
|
||||
ע<EFBFBD><EFBFBD><EFBFBD>㲻<EFBFBD><EFBFBD><EFBFBD>ڵ<EFBFBD> 1 <EFBFBD><EFBFBD><EFBFBD>͵<EFBFBD> 2 <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ʊ<EFBFBD><EFBFBD>֮<EFBFBD><EFBFBD><EFBFBD>ٽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
<EFBFBD><EFBFBD>Ϊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͬʱ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>˶<EFBFBD><EFBFBD>ʽ<EFBFBD><EFBFBD>ף<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ٴι<EFBFBD><EFBFBD><EFBFBD>ǰ<EFBFBD><EFBFBD><EFBFBD>۵<EFBFBD>֮ǰ<EFBFBD>Ĺ<EFBFBD>Ʊ<EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 3</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [7,6,4,3,1]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 0
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>, û<EFBFBD>н<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>, <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ 0<EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
**˼·**<2A><>̰<EFBFBD><CCB0><EFBFBD>㷨
|
||||
|
||||
̰<EFBFBD>IJ<EFBFBD><EFBFBD>ԣ<EFBFBD>ֻҪ<EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD>۸<EFBFBD><EFBFBD><EFBFBD>ǰһ<EFBFBD><EFBFBD><EFBFBD>ߣ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǰһ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
|
||||
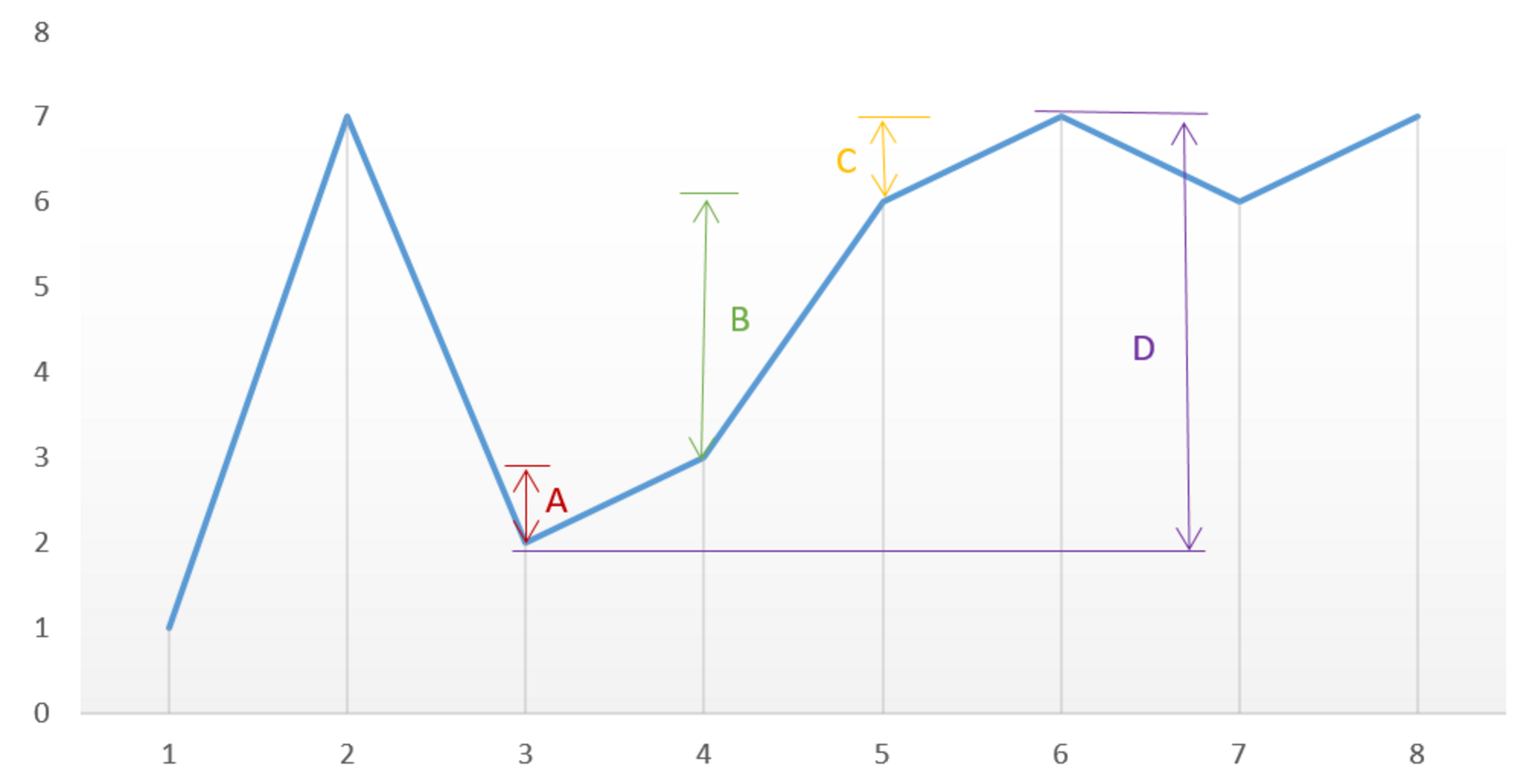
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 140 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 72.02% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 24.2 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.36% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int MaxProfit(int[] prices)
|
||||
{
|
||||
int earn = 0;
|
||||
for (int i = 0; i < prices.Length-1; i++)
|
||||
{
|
||||
earn += Math.Max(prices[i + 1] - prices[i], 0);
|
||||
}
|
||||
return earn;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ06<30><36><EFBFBD><EFBFBD>Ծ<EFBFBD><D4BE>Ϸ
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>55
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/jump-game/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD>Ǹ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>飬<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĵ<EFBFBD>һ<EFBFBD><EFBFBD>λ<EFBFBD>á<EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>е<EFBFBD>ÿ<EFBFBD><EFBFBD>Ԫ<EFBFBD>ش<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڸ<EFBFBD>λ<EFBFBD>ÿ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ծ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȡ<EFBFBD>
|
||||
|
||||
<EFBFBD>ж<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ƿ<EFBFBD><EFBFBD>ܹ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>λ<EFBFBD>á<EFBFBD>
|
||||
|
||||
**ʾ<><CABE> 1:**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [2,3,1,1,4]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: true
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: <EFBFBD><EFBFBD><EFBFBD>ǿ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 1 <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD><EFBFBD> 0 <EFBFBD><EFBFBD><EFBFBD><EFBFBD> λ<EFBFBD><EFBFBD> 1, Ȼ<EFBFBD><EFBFBD><EFBFBD>ٴ<EFBFBD>λ<EFBFBD><EFBFBD> 1 <EFBFBD><EFBFBD> 3
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>λ<EFBFBD>á<EFBFBD>
|
||||
```
|
||||
|
||||
**ʾ<><CABE> 2:**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [3,2,1,0,4]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: false
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܻᵽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ 3 <EFBFBD><EFBFBD>λ<EFBFBD>á<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD>õ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ծ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 0<EFBFBD><EFBFBD>
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Զ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>λ<EFBFBD>á<EFBFBD>
|
||||
```
|
||||
|
||||
**ʾ<><CABE> 3:**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺[0]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>true
|
||||
```
|
||||
|
||||
**˼·<EFBFBD><EFBFBD>̰<EFBFBD><EFBFBD><EFBFBD>㷨**
|
||||
|
||||
̰<EFBFBD>IJ<EFBFBD><EFBFBD>ԣ<EFBFBD>ÿ<EFBFBD>μ<EFBFBD>¼<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǰ<EFBFBD>㳬<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>false<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵ<EFBFBD>ﵽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>λ<EFBFBD>ã<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>true<EFBFBD><EFBFBD>
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>120 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 57.32% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>26.2 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 6.67% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public bool CanJump(int[] nums)
|
||||
{
|
||||
int maxlength = 0; //<2F><>¼<EFBFBD><C2BC><EFBFBD>ܵ<EFBFBD><DCB5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Զ<EFBFBD><D4B6>
|
||||
for (int i = 0; maxlength < nums.Length-1; i++)
|
||||
{
|
||||
if (i > maxlength)
|
||||
{
|
||||
return false;//<2F><><EFBFBD>˵<EFBFBD><CBB5>Ѳ<EFBFBD><D1B2>ܵ<EFBFBD><DCB5><EFBFBD><EFA3AC><EFBFBD><EFBFBD>false
|
||||
}
|
||||
maxlength = Math.Max(i + nums[i], maxlength);
|
||||
}
|
||||
return true;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ07<30><37><EFBFBD><EFBFBD><EFBFBD><EFBFBD>֮<EFBFBD><D6AE>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>15
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/3sum/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`n`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums`<EFBFBD><EFBFBD><EFBFBD>ж<EFBFBD>`nums`<EFBFBD><EFBFBD><EFBFBD>Ƿ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD><EFBFBD>`a<><61>b<EFBFBD><62>c`<EFBFBD><EFBFBD>ʹ<EFBFBD><EFBFBD>`a + b + c = 0`<EFBFBD><EFBFBD><EFBFBD>ҳ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҳ<EFBFBD><EFBFBD>ظ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>顣
|
||||
|
||||
ע<EFBFBD>⣺<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>в<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ظ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>顣
|
||||
|
||||
**ʾ<><CABE><EFBFBD><EFBFBD>**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums = [-1, 0, 1, 2, -1, -4]<EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>鼯<EFBFBD><EFBFBD>Ϊ<EFBFBD><EFBFBD>
|
||||
[
|
||||
[-1, 0, 1],
|
||||
[-1, -1, 2]
|
||||
]
|
||||
```
|
||||
|
||||
|
||||
|
||||
**˼·<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> <20><><EFBFBD><EFBFBD> + <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> <20>ķ<EFBFBD><C4B7><EFBFBD><EFBFBD><EFBFBD>**
|
||||
|
||||
Ϊ<EFBFBD>˱<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ѭ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ִ<EFBFBD><EFBFBD>Ч<EFBFBD>ʡ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȣ<EFBFBD><EFBFBD><EFBFBD>`nums`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ȼ<EFBFBD>̶<EFBFBD>3<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`i,l(left),r(right)`<EFBFBD><EFBFBD>`i`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ѭ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`l`ָ<EFBFBD><EFBFBD>`nums[i]`֮<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Сֵ<EFBFBD><EFBFBD>`r`ָ<EFBFBD><EFBFBD>`nums[i]`֮<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵ<EFBFBD><EFBFBD>ģ<EFBFBD>¿<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>˼·<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums[i] > 0`<EFBFBD>Ͳ<EFBFBD><EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ˣ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums[i] + nums[l] + nums[r]`<EFBFBD>Ƿ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㲢<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD>Ĵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㣬<EFBFBD><EFBFBD>`l`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ƶ<EFBFBD>`r`ָ<EFBFBD>룬<EFBFBD><EFBFBD><EFBFBD><EFBFBD>С<EFBFBD><EFBFBD><EFBFBD>㣬<EFBFBD><EFBFBD>`r`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ƶ<EFBFBD>`l`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㣬<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>뵽<EFBFBD>洢<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>result<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>С<EFBFBD><EFBFBD><EFBFBD>Ȼ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ŀ<EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>鲻<EFBFBD><EFBFBD><EFBFBD>ظ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڽ<EFBFBD><EFBFBD>еĹ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>м<EFBFBD><EFBFBD><EFBFBD>ȥ<EFBFBD>ؾͺá<EFBFBD>
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>348 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 99.54% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>35.8 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 6.63% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public IList<IList<int>> ThreeSum(int[] nums)
|
||||
{
|
||||
IList<IList<int>> result = new List<IList<int>>();
|
||||
|
||||
nums = nums.OrderBy(a => a).ToArray();
|
||||
int len = nums.Length;
|
||||
|
||||
for (int i = 0; i < len - 2; i++)
|
||||
{
|
||||
if (nums[i] > 0)
|
||||
break; // <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>С<EFBFBD><D0A1><EFBFBD><EFBFBD><EFBFBD>ִ<EFBFBD><D6B4><EFBFBD>0, <20><><EFBFBD><EFBFBD><EFBFBD>IJ<EFBFBD><C4B2><EFBFBD><EFBFBD>Ѿ<EFBFBD>û<EFBFBD><C3BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
if (i > 0 && nums[i - 1] == nums[i])
|
||||
continue; // <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD><D4AA><EFBFBD>е<EFBFBD>һ<EFBFBD><D2BB>Ԫ<EFBFBD>ص<EFBFBD><D8B5>ظ<EFBFBD><D8B8><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
int l = i + 1;
|
||||
int r = len - 1;
|
||||
|
||||
while (l < r)
|
||||
{
|
||||
int sum = nums[i] + nums[l] + nums[r];
|
||||
if (sum < 0)
|
||||
{
|
||||
l++;
|
||||
}
|
||||
else if (sum > 0)
|
||||
{
|
||||
r--;
|
||||
}
|
||||
else
|
||||
{
|
||||
result.Add(new List<int>() {nums[i], nums[l], nums[r]});
|
||||
// <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD><D4AA><EFBFBD>еڶ<D0B5><DAB6><EFBFBD>Ԫ<EFBFBD>ص<EFBFBD><D8B5>ظ<EFBFBD><D8B8><EFBFBD><EFBFBD><EFBFBD>
|
||||
while (l < r && nums[l] == nums[l + 1])
|
||||
{
|
||||
l++;
|
||||
}
|
||||
// <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD><D4AA><EFBFBD>е<EFBFBD><D0B5><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ص<EFBFBD><D8B5>ظ<EFBFBD><D8B8><EFBFBD><EFBFBD><EFBFBD>
|
||||
while (l < r && nums[r - 1] == nums[r])
|
||||
{
|
||||
r--;
|
||||
}
|
||||
l++;
|
||||
r--;
|
||||
}
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ08<30><38><EFBFBD><EFBFBD><EFBFBD>ӽ<EFBFBD><D3BD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>֮<EFBFBD><D6AE>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>16
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/3sum-closest/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`n`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`nums`<EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>Ŀ<EFBFBD><EFBFBD>ֵ`target`<EFBFBD><EFBFBD><EFBFBD>ҳ<EFBFBD>`nums`<EFBFBD>е<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʹ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǵĺ<EFBFBD><EFBFBD><EFBFBD>`target`<EFBFBD><EFBFBD><EFBFBD>ӽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĺ͡<EFBFBD><EFBFBD>ٶ<EFBFBD>ÿ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ψһ<EFBFBD>𰸡<EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE></b> :
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>磬<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> nums = [-1<EFBFBD><EFBFBD>2<EFBFBD><EFBFBD>1<EFBFBD><EFBFBD>-4], <EFBFBD><EFBFBD> target = 1.
|
||||
<EFBFBD><EFBFBD> target <EFBFBD><EFBFBD><EFBFBD>ӽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĺ<EFBFBD>Ϊ 2. (-1 + 2 + 1 = 2).
|
||||
```
|
||||
|
||||
|
||||
<b>˼·<CBBC><C2B7><EFBFBD><EFBFBD><EFBFBD><EFBFBD> <20><><EFBFBD><EFBFBD> + <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> <20>ķ<EFBFBD><C4B7><EFBFBD></b>
|
||||
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 132 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 100.00% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 24 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.55% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int ThreeSumClosest(int[] nums, int target)
|
||||
{
|
||||
nums = nums.OrderBy(a => a).ToArray();
|
||||
int result = nums[0] + nums[1] + nums[2];
|
||||
for (int i = 0; i < nums.Length - 2; i++)
|
||||
{
|
||||
int start = i + 1, end = nums.Length - 1;
|
||||
while (start < end)
|
||||
{
|
||||
int sum = nums[start] + nums[end] + nums[i];
|
||||
if (Math.Abs(target - sum) < Math.Abs(target - result))
|
||||
result = sum;
|
||||
if (sum > target)
|
||||
end--;
|
||||
else if (sum < target)
|
||||
start++;
|
||||
else
|
||||
return result;
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ09<30><39><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> II
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>59
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/spiral-matrix-ii/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> n<><6E><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><D2BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 1 <20><> n^2 <20><><EFBFBD><EFBFBD>Ԫ<EFBFBD>أ<EFBFBD><D8A3><EFBFBD>Ԫ<EFBFBD>ذ<EFBFBD>˳ʱ<CBB3><CAB1>˳<EFBFBD><CBB3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>е<EFBFBD><D0B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ξ<EFBFBD><CEBE><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE></b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 3
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>:
|
||||
[
|
||||
[ 1, 2, 3 ],
|
||||
[ 8, 9, 4 ],
|
||||
[ 7, 6, 5 ]
|
||||
]
|
||||
```
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 296 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 97.67% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 25 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 11.11% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int[][] GenerateMatrix(int n)
|
||||
{
|
||||
int[][] matrix = new int[n][];
|
||||
for (int i = 0; i < n; i++)
|
||||
{
|
||||
matrix[i] = new int[n];
|
||||
}
|
||||
|
||||
int start = 0;//<2F><>ʼλ<CABC><CEBB>
|
||||
int end1 = n - 1;//<2F><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD><CEBB>
|
||||
int end2 = n - 1;//<2F><><EFBFBD>±<EFBFBD>λ<EFBFBD><CEBB>
|
||||
int count = 1;
|
||||
|
||||
while (start < end1 && start < end2)
|
||||
{
|
||||
LeftToRight(start, end1, start, matrix, ref count);
|
||||
TopToBottom(start + 1, end2, end1, matrix, ref count);
|
||||
RightToLeft(end1 - 1, start, end2, matrix, ref count);
|
||||
BottomToTop(end2 - 1, start + 1, start, matrix, ref count);
|
||||
start++;
|
||||
end1 = n - 1 - start;
|
||||
end2 = n - 1 - start;
|
||||
}
|
||||
if (n%2 == 1)
|
||||
{
|
||||
matrix[start][start] = count;
|
||||
}
|
||||
return matrix;
|
||||
}
|
||||
|
||||
private void LeftToRight(int start, int end, int rowIndex, int[][] matrix, ref int from)
|
||||
{
|
||||
for (int i = start; i <= end; i++)
|
||||
{
|
||||
matrix[rowIndex][i] = from;
|
||||
from++;
|
||||
}
|
||||
}
|
||||
|
||||
private void TopToBottom(int start, int end, int colIndex, int[][] matrix, ref int from)
|
||||
{
|
||||
for (int i = start; i <= end; i++)
|
||||
{
|
||||
matrix[i][colIndex] = from;
|
||||
from++;
|
||||
}
|
||||
}
|
||||
|
||||
private void RightToLeft(int start, int end, int rowIndex, int[][] matrix, ref int from)
|
||||
{
|
||||
for (int i = start; i >= end; i--)
|
||||
{
|
||||
matrix[rowIndex][i] = from;
|
||||
from++;
|
||||
}
|
||||
}
|
||||
|
||||
private void BottomToTop(int start, int end, int colIndex, int[][] matrix, ref int from)
|
||||
{
|
||||
for (int i = start; i >= end; i--)
|
||||
{
|
||||
matrix[i][colIndex] = from;
|
||||
from++;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## <20><>Ŀ10<31><30><EFBFBD><EFBFBD>ͬ·<CDAC><C2B7>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>62
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/unique-paths/
|
||||
|
||||
һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD> m x n <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ͻ<EFBFBD> <20><><EFBFBD><EFBFBD>ʼ<EFBFBD><CABC><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͼ<EFBFBD>б<EFBFBD><D0B1><EFBFBD>Ϊ<EFBFBD><CEAA>Start<72><74> <20><><EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ÿ<EFBFBD><EFBFBD>ֻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>»<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ƶ<EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͼ<EFBFBD>ﵽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>½ǣ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͼ<EFBFBD>б<EFBFBD><EFBFBD><EFBFBD>Ϊ<EFBFBD><EFBFBD>Finish<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD>ܹ<EFBFBD><EFBFBD>ж<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͬ<EFBFBD><EFBFBD>·<EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||

|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD>磬<EFBFBD><EFBFBD>ͼ<EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>7 x 3 <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ж<EFBFBD><D0B6>ٿ<EFBFBD><D9BF>ܵ<EFBFBD>·<EFBFBD><C2B7><EFBFBD><EFBFBD>
|
||||
|
||||
<b>˵<><CBB5></b><3E><>m <20><> n <20><>ֵ<EFBFBD><D6B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 100<30><30>
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: m = 3, n = 2
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 3
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>:
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ͻǿ<EFBFBD>ʼ<EFBFBD><EFBFBD><EFBFBD>ܹ<EFBFBD><EFBFBD><EFBFBD> 3 <EFBFBD><EFBFBD>·<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ե<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>½ǡ<EFBFBD>
|
||||
1. <EFBFBD><EFBFBD><EFBFBD><EFBFBD> -> <EFBFBD><EFBFBD><EFBFBD><EFBFBD> -> <EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
2. <EFBFBD><EFBFBD><EFBFBD><EFBFBD> -> <EFBFBD><EFBFBD><EFBFBD><EFBFBD> -> <EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
3. <EFBFBD><EFBFBD><EFBFBD><EFBFBD> -> <EFBFBD><EFBFBD><EFBFBD><EFBFBD> -> <EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: m = 7, n = 3
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 28
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 3</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: m = 23, n = 12
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 193536720
|
||||
```
|
||||
|
||||
<b>˼·<CBBC><C2B7></b><3E><><EFBFBD>ö<EFBFBD>̬<EFBFBD>滮<EFBFBD><E6BBAE>
|
||||
|
||||
<EFBFBD><EFBFBD>̬<EFBFBD>滮<EFBFBD><EFBFBD><EFBFBD><EFBFBD>01<EFBFBD><EFBFBD>
|
||||
|
||||

|
||||
|
||||
<EFBFBD><EFBFBD>̬<EFBFBD>滮<EFBFBD><EFBFBD><EFBFBD><EFBFBD>02<EFBFBD><EFBFBD>
|
||||
|
||||

|
||||
|
||||
<EFBFBD><EFBFBD>̬<EFBFBD>滮<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ӽṹΪ<EFBFBD><EFBFBD>`d[i,j] = d[i-1,j] + d[i,j-1]`
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- 62 / 62 <20><>ͨ<EFBFBD><CDA8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 52 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 93.18% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 13.6 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 17.65% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
public class Solution
|
||||
{
|
||||
public int UniquePaths(int m, int n)
|
||||
{
|
||||
int[,] memo = new int[m, n];
|
||||
for (int i = 0; i < m; i++)
|
||||
{
|
||||
for (int j = 0; j < n; j++)
|
||||
{
|
||||
if (i == 0)
|
||||
{
|
||||
memo[i, j] = 1;
|
||||
}
|
||||
else if (j == 0)
|
||||
{
|
||||
memo[i, j] = 1;
|
||||
}
|
||||
else
|
||||
{
|
||||
memo[i, j] = memo[i - 1, j] + memo[i, j - 1];
|
||||
}
|
||||
}
|
||||
}
|
||||
return memo[m - 1, n - 1];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
|
||||
# 15 树
|
||||
# 07 树
|
||||
|
||||
**知识结构:**
|
||||
|
||||
@@ -1,794 +0,0 @@
|
||||
|
||||
# Leetcodeͬ<65><CDAC><EFBFBD><EFBFBD>ϰ<EFBFBD><CFB0><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
## <20><>Ŀ01<30><31><EFBFBD>ϲ<EFBFBD><CFB2><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>21
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/merge-two-sorted-lists/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ϲ<EFBFBD>Ϊһ<EFBFBD><EFBFBD><EFBFBD>µ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ء<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><EFBFBD>ƴ<EFBFBD>Ӹ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>нڵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɵġ<EFBFBD>
|
||||
|
||||
**ʾ<><CABE><EFBFBD><EFBFBD>**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺1->2->4, 1->3->4
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>1->1->2->3->4->4
|
||||
```
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>108 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 83.80% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>25.9 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.85% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* public class ListNode {
|
||||
* public int val;
|
||||
* public ListNode next;
|
||||
* public ListNode(int x) { val = x; }
|
||||
* }
|
||||
*/
|
||||
public class Solution
|
||||
{
|
||||
public ListNode MergeTwoLists(ListNode l1, ListNode l2)
|
||||
{
|
||||
ListNode pHead = new ListNode(int.MaxValue);
|
||||
ListNode temp = pHead;
|
||||
|
||||
while (l1 != null && l2 != null)
|
||||
{
|
||||
if (l1.val < l2.val)
|
||||
{
|
||||
temp.next = l1;
|
||||
l1 = l1.next;
|
||||
}
|
||||
else
|
||||
{
|
||||
temp.next = l2;
|
||||
l2 = l2.next;
|
||||
}
|
||||
temp = temp.next;
|
||||
}
|
||||
|
||||
if (l1 != null)
|
||||
temp.next = l1;
|
||||
|
||||
if (l2 != null)
|
||||
temp.next = l2;
|
||||
|
||||
return pHead.next;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ02<30><32>ɾ<EFBFBD><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>е<EFBFBD><D0B5>ظ<EFBFBD>Ԫ<EFBFBD><D4AA>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>83
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/remove-duplicates-from-sorted-list/
|
||||
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɾ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ظ<EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>أ<EFBFBD>ʹ<EFBFBD><EFBFBD>ÿ<EFBFBD><EFBFBD>Ԫ<EFBFBD><EFBFBD>ֻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD>Ρ<EFBFBD>
|
||||
|
||||
|
||||
**ʾ<><CABE> 1:**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1->1->2
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1->2
|
||||
```
|
||||
|
||||
**ʾ<><CABE> 2:**
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1->1->2->3->3
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1->2->3
|
||||
```
|
||||
|
||||
**˼·**<2A><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>˫ָ<CBAB><D6B8><EFBFBD>ķ<EFBFBD>ʽ<EFBFBD><CABD>
|
||||
|
||||
`p1`<EFBFBD><EFBFBD>Ϊǰ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ָ<EFBFBD><EFBFBD>̽·<EFBFBD><EFBFBD>`p2`<EFBFBD><EFBFBD>Ϊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ָ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ظ<EFBFBD>Ԫ<EFBFBD>أ<EFBFBD>`p2.next`<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȥ<EFBFBD><EFBFBD>`p1`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ظ<EFBFBD>Ԫ<EFBFBD>ض<EFBFBD><EFBFBD><EFBFBD>ժ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>160 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.23% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>25.9 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.72% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* public class ListNode {
|
||||
* public int val;
|
||||
* public ListNode next;
|
||||
* public ListNode(int x) { val = x; }
|
||||
* }
|
||||
*/
|
||||
|
||||
public class Solution
|
||||
{
|
||||
public ListNode DeleteDuplicates(ListNode head)
|
||||
{
|
||||
if (head == null)
|
||||
return head;
|
||||
|
||||
ListNode p1 = head.next;
|
||||
ListNode p2 = head;
|
||||
while (p1 != null)
|
||||
{
|
||||
if (p1.val == p2.val)
|
||||
p2.next = p1.next;
|
||||
else
|
||||
p2 = p2.next;
|
||||
p1 = p1.next;
|
||||
}
|
||||
return head;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ03<30><33><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>141
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/linked-list-cycle/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ж<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ƿ<EFBFBD><EFBFBD>л<EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
Ϊ<EFBFBD>˱<EFBFBD>ʾ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>еĻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʹ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`pos` <20><><EFBFBD><EFBFBD>ʾ<EFBFBD><CABE><EFBFBD><EFBFBD>β<EFBFBD><CEB2><EFBFBD>ӵ<EFBFBD><D3B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>е<EFBFBD>λ<EFBFBD>ã<EFBFBD><C3A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 0 <20><>ʼ<EFBFBD><CABC><EFBFBD><EFBFBD> <20><><EFBFBD><EFBFBD>`pos`<EFBFBD><EFBFBD> -1<><31><EFBFBD><EFBFBD><EFBFBD>ڸ<EFBFBD><DAB8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>û<EFBFBD>л<EFBFBD><D0BB><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE> 1</b><3E><>
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺head = [3,2,0,-4], pos = 1
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>true
|
||||
<EFBFBD><EFBFBD><EFBFBD>ͣ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>β<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ӵ<EFBFBD><EFBFBD>ڶ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ㡣
|
||||
```
|
||||
|
||||
|
||||
|
||||
<b>ʾ<><CABE> 2</b><3E><>
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺head = [1,2], pos = 0
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>true
|
||||
<EFBFBD><EFBFBD><EFBFBD>ͣ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>β<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ӵ<EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD>ڵ㡣
|
||||
```
|
||||
|
||||
|
||||
<b>ʾ<><CABE> 3</b><3E><>
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺head = [1], pos = -1
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>false
|
||||
<EFBFBD><EFBFBD><EFBFBD>ͣ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>û<EFBFBD>л<EFBFBD><EFBFBD><EFBFBD>
|
||||
```
|
||||

|
||||
|
||||
<b><3E><><EFBFBD><EFBFBD></b><3E><>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> O(1)<29><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
**˼·**<2A><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>˫ָ<CBAB><D6B8><EFBFBD>ķ<EFBFBD>ʽ<EFBFBD><CABD>
|
||||
|
||||
ͨ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>£<EFBFBD><EFBFBD>ж<EFBFBD><EFBFBD>Ƿ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ظ<EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>أ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʹ<EFBFBD><EFBFBD>`Hash`<EFBFBD>ķ<EFBFBD>ʽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֳ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҳ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʹ<EFBFBD><EFBFBD>˫ָ<EFBFBD><EFBFBD><EFBFBD>ķ<EFBFBD>ʽ<EFBFBD><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>ָ<EFBFBD><EFBFBD> `p1` ÿ<><C3BF><EFBFBD>ƶ<EFBFBD><C6B6><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ㣬<DAB5>ڶ<EFBFBD><DAB6><EFBFBD>ָ<EFBFBD><D6B8> `p2` ÿ<><C3BF><EFBFBD>ƶ<EFBFBD>һ<EFBFBD><D2BB><EFBFBD>ڵ㣬<DAB5><E3A3AC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڻ<EFBFBD><DABB>Ļ<EFBFBD><C4BB><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><D2BB>ָ<EFBFBD><D6B8>һ<EFBFBD><D2BB><EFBFBD><EFBFBD><EFBFBD>ٴ<EFBFBD><D9B4><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڶ<EFBFBD><DAB6><EFBFBD>ָ<EFBFBD>룬<EFBFBD><EBA3AC>֮<EFBFBD><D6AE><EFBFBD><EFBFBD><F2B2BBB4>ڻ<EFBFBD><DABB><EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD>磺`head = [1,2,3,4,5]`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
```c
|
||||
p1<EFBFBD><EFBFBD>1 3 5 2 4 1
|
||||
p2<EFBFBD><EFBFBD>1 2 3 4 5 1
|
||||
```
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD>磺`head = [1,2,3,4]`<EFBFBD><EFBFBD>ż<EFBFBD><EFBFBD>
|
||||
```c
|
||||
p1<EFBFBD><EFBFBD>1 3 1 3 1
|
||||
p2<EFBFBD><EFBFBD>1 2 3 4 1
|
||||
```
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 112 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 98.43% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 24.9 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.13% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* public class ListNode {
|
||||
* public int val;
|
||||
* public ListNode next;
|
||||
* public ListNode(int x) {
|
||||
* val = x;
|
||||
* next = null;
|
||||
* }
|
||||
* }
|
||||
*/
|
||||
public class Solution {
|
||||
public bool HasCycle(ListNode head) {
|
||||
ListNode p1 = head;
|
||||
ListNode p2 = head;
|
||||
|
||||
while (p1 != null && p1.next != null)
|
||||
{
|
||||
p1 = p1.next.next;
|
||||
p2 = p2.next;
|
||||
if (p1 == p2)
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## <20><>Ŀ04<30><34><EFBFBD><EFBFBD>ת<EFBFBD><D7AA><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>206
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/reverse-linked-list/
|
||||
|
||||
<EFBFBD><EFBFBD>תһ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
<b>ʾ<><CABE></b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1->2->3->4->5->NULL
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 5->4->3->2->1->NULL
|
||||
```
|
||||
|
||||
<b><3E><><EFBFBD><EFBFBD></b>:
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ե<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ݹ<EFBFBD><EFBFBD>ط<EFBFBD>ת<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܷ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ַ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>⣿
|
||||
|
||||
**˼·**<2A><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>˫ָ<CBAB><D6B8><EFBFBD>ķ<EFBFBD>ʽ<EFBFBD><CABD>
|
||||
|
||||
`p1`<EFBFBD><EFBFBD>Ϊǰ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ָ<EFBFBD><EFBFBD>̽·<EFBFBD><EFBFBD>`p2`<EFBFBD><EFBFBD>Ϊ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ָ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>˳<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һȦ<EFBFBD><EFBFBD><EFBFBD>㶨<EFBFBD><EFBFBD><EFBFBD>⡣
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 116 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 97.50% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 23.3 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.26% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* public class ListNode {
|
||||
* public int val;
|
||||
* public ListNode next;
|
||||
* public ListNode(int x) { val = x; }
|
||||
* }
|
||||
*/
|
||||
|
||||
public class Solution
|
||||
{
|
||||
public ListNode ReverseList(ListNode head)
|
||||
{
|
||||
if (head == null || head.next == null)
|
||||
return head;
|
||||
|
||||
ListNode p1 = head;
|
||||
ListNode p2 = null;
|
||||
while (p1 != null)
|
||||
{
|
||||
ListNode temp = p1.next;
|
||||
p1.next = p2;
|
||||
p2 = p1;
|
||||
p1 = temp;
|
||||
}
|
||||
return p2;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ05<30><35>ɾ<EFBFBD><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>еĽڵ<C4BD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>237
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/delete-node-in-a-linked-list/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>дһ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʹ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɾ<EFBFBD><EFBFBD>ij<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>и<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ģ<EFBFBD><EFBFBD><EFBFBD>ĩβ<EFBFBD><EFBFBD><EFBFBD>ڵ㣬<EFBFBD>㽫ֻ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɾ<EFBFBD><EFBFBD><EFBFBD>Ľڵ㡣
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> -- head = [4,5,1,9]<5D><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD>ʾΪ:
|
||||
|
||||

|
||||
|
||||
|
||||
<b>ʾ<><CABE> 1</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: head = [4,5,1,9], node = 5
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [4,1,9]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵΪ 5 <EFBFBD>ĵڶ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ㣬<EFBFBD><EFBFBD>ô<EFBFBD>ڵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĺ<EFBFBD><EFBFBD><EFBFBD>֮<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD><EFBFBD>Ϊ 4 -> 1 -> 9.
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: head = [4,5,1,9], node = 1
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: [4,5,9]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: <EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֵΪ 1 <EFBFBD>ĵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ㣬<EFBFBD><EFBFBD>ô<EFBFBD>ڵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĺ<EFBFBD><EFBFBD><EFBFBD>֮<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD><EFBFBD>Ϊ 4 -> 5 -> 9.
|
||||
```
|
||||
|
||||
<b>˵<><CBB5></b>:
|
||||
|
||||
- <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ٰ<EFBFBD><D9B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ㡣
|
||||
- <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>нڵ<D0BD><DAB5><EFBFBD>ֵ<EFBFBD><D6B5><EFBFBD><EFBFBD>Ψһ<CEA8>ġ<EFBFBD>
|
||||
- <20><><EFBFBD><EFBFBD><EFBFBD>Ľڵ<C4BD>Ϊ<EFBFBD><CEAA>ĩβ<C4A9>ڵ㲢<DAB5><E3B2A2>һ<EFBFBD><D2BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>е<EFBFBD>һ<EFBFBD><D2BB><EFBFBD><EFBFBD>Ч<EFBFBD>ڵ㡣
|
||||
- <20><>Ҫ<EFBFBD><D2AA><EFBFBD><EFBFBD><EFBFBD>ĺ<EFBFBD><C4BA><EFBFBD><EFBFBD>з<EFBFBD><D0B7><EFBFBD><EFBFBD>κν<CEBA><CEBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
**˼·<EFBFBD><EFBFBD>** <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD>û<EFBFBD>и<EFBFBD><D0B8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͷ<EFBFBD>ڵ㣬<DAB5><E3A3AC><EFBFBD><EFBFBD>ֱ<EFBFBD>Ӹ<EFBFBD><D3B8><EFBFBD>Ҫɾ<D2AA><C9BE><EFBFBD>Ľڵ㣬<DAB5><E3A3AC><EFBFBD><EFBFBD><EFBFBD>ǽ<EFBFBD><C7BD><EFBFBD>ԭ<EFBFBD><D4AD>ɾ<EFBFBD><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ƕ<EFBFBD><C7B6>ڸýڵ<C3BD><DAB5><EFBFBD>ǰһ<C7B0><D2BB><EFBFBD>ڵ<EFBFBD>һ<EFBFBD><D2BB><EFBFBD><EFBFBD>֪<EFBFBD><D6AA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֱ<EFBFBD><D6B1>ִ<EFBFBD><D6B4>ɾ<EFBFBD><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ˣ<EFBFBD><CBA3><EFBFBD><EFBFBD>ǽ<EFBFBD>Ҫɾ<D2AA><C9BE><EFBFBD>ڵ<EFBFBD><DAB5><EFBFBD> next <20>ڵ<EFBFBD><DAB5><EFBFBD>ֵ<EFBFBD><D6B5>ֵ<EFBFBD><D6B5>Ҫɾ<D2AA><C9BE><EFBFBD>Ľڵ㣬ת<E3A3AC><D7AA>ȥɾ<C8A5><C9BE> next <20>ڵ㣬<DAB5>Ӷ<EFBFBD><D3B6><EFBFBD><EFBFBD><EFBFBD>Ŀ<EFBFBD>ġ<EFBFBD>
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- 41 / 41 <20><>ͨ<EFBFBD><CDA8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 120 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 99.55% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 24.4 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.88% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* public class ListNode {
|
||||
* public int val;
|
||||
* public ListNode next;
|
||||
* public ListNode(int x) { val = x; }
|
||||
* }
|
||||
*/
|
||||
|
||||
public class Solution
|
||||
{
|
||||
public void DeleteNode(ListNode node)
|
||||
{
|
||||
ListNode temp = node.next;
|
||||
while (temp != null)
|
||||
{
|
||||
node.val = temp.val;
|
||||
temp = temp.next;
|
||||
if (temp != null)
|
||||
{
|
||||
node = node.next;
|
||||
}
|
||||
}
|
||||
node.next = null;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ06<30><36><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>2
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/add-two-numbers/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> <b><3E>ǿ<EFBFBD></b> <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʾ<EFBFBD><CABE><EFBFBD><EFBFBD><EFBFBD>Ǹ<EFBFBD><C7B8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>У<EFBFBD><D0A3><EFBFBD><EFBFBD>Ǹ<EFBFBD><C7B8>Ե<EFBFBD>λ<EFBFBD><CEBB><EFBFBD>ǰ<EFBFBD><C7B0><EFBFBD> <b><3E><><EFBFBD><EFBFBD></b> <20>ķ<EFBFBD>ʽ<EFBFBD>洢<EFBFBD>ģ<EFBFBD><C4A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǵ<EFBFBD>ÿ<EFBFBD><C3BF><EFBFBD>ڵ<EFBFBD>ֻ<EFBFBD>ܴ洢 <b>һλ</b> <20><><EFBFBD>֡<EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>᷵<EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD>µ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʾ<EFBFBD><EFBFBD><EFBFBD>ǵĺ͡<EFBFBD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Լ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 0 ֮<>⣬<EFBFBD><E2A3AC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD> 0 <20><>ͷ<EFBFBD><CDB7>
|
||||
|
||||
<b>ʾ<><CABE> 1</b><3E><>
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺(2 -> 4 -> 3) + (5 -> 6 -> 4)
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>7 -> 0 -> 8
|
||||
ԭ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>342 + 465 = 807
|
||||
```
|
||||
|
||||
<b>ʾ<><CABE> 2</b><3E><>
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD>룺(3 -> 7) + (9 -> 2)
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>2 -> 0 -> 1
|
||||
ԭ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>73 + 29 = 102
|
||||
```
|
||||
|
||||
**˼·**<2A><>ģ<EFBFBD><C4A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Сѧʱ<D1A7><CAB1>ѧ<EFBFBD>ļӷ<C4BC><D3B7><EFBFBD><EFBFBD>㡣<EFBFBD><E3A1A3>λ<EFBFBD><CEBB><EFBFBD>ӳ<EFBFBD><D3B3><EFBFBD>ʮ<EFBFBD><CAAE>һ<EFBFBD><D2BB>ʮλ<CAAE><CEBB><EFBFBD><EFBFBD><EFBFBD>н<EFBFBD>λ<EFBFBD><CEBB><EFBFBD><EFBFBD><EFBFBD>Ͻ<EFBFBD>λ<EFBFBD><CEBB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ơ<EFBFBD>
|
||||
|
||||
<b><3E>ο<EFBFBD><CEBF><EFBFBD><EFBFBD>룺</b>
|
||||
|
||||
- ״̬<D7B4><CCAC>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ: 144 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 97.98% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD><EFBFBD>: 26.7 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 5.07% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* public class ListNode {
|
||||
* public int val;
|
||||
* public ListNode next;
|
||||
* public ListNode(int x) { val = x; }
|
||||
* }
|
||||
*/
|
||||
public class Solution
|
||||
{
|
||||
public ListNode AddTwoNumbers(ListNode l1, ListNode l2)
|
||||
{
|
||||
ListNode result = new ListNode(-1);
|
||||
ListNode l3 = result;
|
||||
int flag = 0;
|
||||
while (l1 != null && l2 != null)
|
||||
{
|
||||
int a = l1.val;
|
||||
int b = l2.val;
|
||||
int c = a + b + flag;
|
||||
l3.next = new ListNode(c%10);
|
||||
|
||||
flag = c >= 10 ? 1 : 0;
|
||||
l1 = l1.next;
|
||||
l2 = l2.next;
|
||||
l3 = l3.next;
|
||||
}
|
||||
|
||||
while (l1 != null)
|
||||
{
|
||||
int a = l1.val + flag;
|
||||
|
||||
l3.next = new ListNode(a%10);
|
||||
|
||||
flag = a >= 10 ? 1 : 0;
|
||||
l1 = l1.next;
|
||||
l3 = l3.next;
|
||||
}
|
||||
|
||||
while (l2 != null)
|
||||
{
|
||||
int b = l2.val + flag;
|
||||
|
||||
l3.next = new ListNode(b%10);
|
||||
flag = b >= 10 ? 1 : 0;
|
||||
l2 = l2.next;
|
||||
l3 = l3.next;
|
||||
}
|
||||
|
||||
if (flag == 1)
|
||||
{
|
||||
l3.next = new ListNode(flag);
|
||||
}
|
||||
return result.next;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ07<30><37>ɾ<EFBFBD><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĵ<EFBFBD><C4B5><EFBFBD><EFBFBD><EFBFBD>N<EFBFBD><4E><EFBFBD>ڵ<EFBFBD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>19
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/remove-nth-node-from-end-of-list/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɾ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`n`<EFBFBD><EFBFBD><EFBFBD>ڵ㣬<EFBFBD><EFBFBD><EFBFBD>ҷ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͷ<EFBFBD><EFBFBD><EFBFBD>㡣
|
||||
|
||||
**ʾ<><CABE>**<EFBFBD><EFBFBD>
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1->2->3->4->5, <EFBFBD><EFBFBD> n = 2.
|
||||
|
||||
<EFBFBD><EFBFBD>ɾ<EFBFBD><EFBFBD><EFBFBD>˵<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڶ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ 1->2->3->5.
|
||||
```
|
||||
|
||||
**˵<EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`n`<EFBFBD><EFBFBD>֤<EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ч<EFBFBD>ġ<EFBFBD>
|
||||
|
||||
**<EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD>ܳ<EFBFBD><EFBFBD><EFBFBD>ʹ<EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD>ɨ<EFBFBD><EFBFBD>ʵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
**˼·<EFBFBD><EFBFBD>** ʹ<><CAB9><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ָ<EFBFBD>룬ǰ<EBA3AC><C7B0><EFBFBD><EFBFBD>ָ<EFBFBD><D6B8>`p1`<EFBFBD><EFBFBD><EFBFBD><EFBFBD>`n`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ú<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ָ<EFBFBD><EFBFBD>`p2`<EFBFBD><EFBFBD>`p1`ͬ<EFBFBD><EFBFBD><EFBFBD>ߣ<EFBFBD>`p1`<EFBFBD>ߵ<EFBFBD><EFBFBD>յ㣬`p2`<EFBFBD><EFBFBD><EFBFBD>ߵ<EFBFBD>Ҫ<EFBFBD>Ƴ<EFBFBD><EFBFBD>Ľ<EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD>á<EFBFBD>
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD>룺**
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>104 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 86.93% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>24.6 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 100.00% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* public class ListNode {
|
||||
* public int val;
|
||||
* public ListNode next;
|
||||
* public ListNode(int x) { val = x; }
|
||||
* }
|
||||
*/
|
||||
public class Solution
|
||||
{
|
||||
public ListNode RemoveNthFromEnd(ListNode head, int n)
|
||||
{
|
||||
ListNode p1 = head;
|
||||
ListNode p2 = head;
|
||||
|
||||
while (n > 0)
|
||||
{
|
||||
p1 = p1.next;
|
||||
n--;
|
||||
}
|
||||
|
||||
if (p1 == null) //<2F>Ƴ<EFBFBD>ͷ<EFBFBD><CDB7><EFBFBD><EFBFBD>
|
||||
{
|
||||
return head.next;
|
||||
}
|
||||
|
||||
while (p1.next != null)
|
||||
{
|
||||
p1 = p1.next;
|
||||
p2 = p2.next;
|
||||
}
|
||||
|
||||
p2.next = p2.next.next;
|
||||
return head;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ08<30><38><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>еĽڵ<C4BD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>24
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/swap-nodes-in-pairs/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵĽڵ㣬<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ؽ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
**<EFBFBD>㲻<EFBFBD><EFBFBD>ֻ<EFBFBD>ǵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĸı<EFBFBD><EFBFBD>ڵ<EFBFBD><EFBFBD>ڲ<EFBFBD><EFBFBD><EFBFBD>ֵ**<2A><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫʵ<D2AA>ʵĽ<CAB5><C4BD>нڵ㽻<DAB5><E3BDBB><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
**ʾ<><CABE>:**
|
||||
|
||||
> <EFBFBD><EFBFBD><EFBFBD><EFBFBD> 1->2->3->4, <20><>Ӧ<EFBFBD>÷<EFBFBD><C3B7><EFBFBD> 2->1->4->3.
|
||||
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>100 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 93.18% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>23.4 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 87.72% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
```c
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* public class ListNode {
|
||||
* public int val;
|
||||
* public ListNode next;
|
||||
* public ListNode(int x) { val = x; }
|
||||
* }
|
||||
*/
|
||||
|
||||
public class Solution
|
||||
{
|
||||
public ListNode SwapPairs(ListNode head)
|
||||
{
|
||||
if (head == null || head.next == null)
|
||||
return head;
|
||||
|
||||
head = Swap(head);
|
||||
|
||||
ListNode temp = head.next;
|
||||
|
||||
while (temp != null && temp.next != null)
|
||||
{
|
||||
temp.next = Swap(temp.next);
|
||||
if (temp.next != null)
|
||||
{
|
||||
temp = temp.next.next;
|
||||
}
|
||||
}
|
||||
return head;
|
||||
}
|
||||
|
||||
public ListNode Swap(ListNode node)
|
||||
{
|
||||
if (node == null || node.next == null)
|
||||
return node;
|
||||
|
||||
ListNode t = node.next;
|
||||
node.next = t.next;
|
||||
t.next = node;
|
||||
return t;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
## <20><>Ŀ09<30><39><EFBFBD><EFBFBD>ת<EFBFBD><D7AA><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>61
|
||||
> - <20>Ѷȣ<D1B6><C8A3>е<EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/rotate-list/
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ת<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ÿ<EFBFBD><EFBFBD><EFBFBD>ڵ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ƶ<EFBFBD> k <20><>λ<EFBFBD>ã<EFBFBD><C3A3><EFBFBD><EFBFBD><EFBFBD> k <20>ǷǸ<C7B7><C7B8><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
**ʾ<><CABE> 1:**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1->2->3->4->5->NULL, k = 2
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 4->5->1->2->3->NULL
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>:
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ת 1 <EFBFBD><EFBFBD>: 5->1->2->3->4->NULL
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ת 2 <EFBFBD><EFBFBD>: 4->5->1->2->3->NULL
|
||||
```
|
||||
|
||||
**ʾ<><CABE> 2:**
|
||||
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 0->1->2->NULL, k = 4
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 2->0->1->NULL
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>:
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ת 1 <EFBFBD><EFBFBD>: 2->0->1->NULL
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ת 2 <EFBFBD><EFBFBD>: 1->2->0->NULL
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ת 3 <EFBFBD><EFBFBD>: 0->1->2->NULL
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ת 4 <EFBFBD><EFBFBD>: 2->0->1->NULL
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>100 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 98.13% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>25.1 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 100.00% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
|
||||
```c
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* public class ListNode {
|
||||
* public int val;
|
||||
* public ListNode next;
|
||||
* public ListNode(int x) { val = x; }
|
||||
* }
|
||||
*/
|
||||
|
||||
public class Solution
|
||||
{
|
||||
public ListNode RotateRight(ListNode head, int k)
|
||||
{
|
||||
if (head == null || k == 0)
|
||||
return head;
|
||||
|
||||
int len = GetLength(head);
|
||||
int index = len - k%len;
|
||||
|
||||
if (index == len)
|
||||
return head;
|
||||
|
||||
ListNode temp1 = head;
|
||||
ListNode temp2 = head;
|
||||
for (int i = 0; i < index - 1; i++)
|
||||
{
|
||||
temp1 = temp1.next;
|
||||
}
|
||||
head = temp1.next;
|
||||
temp1.next = null;
|
||||
|
||||
temp1 = head;
|
||||
while (temp1.next != null)
|
||||
{
|
||||
temp1 = temp1.next;
|
||||
}
|
||||
temp1.next = temp2;
|
||||
return head;
|
||||
}
|
||||
|
||||
public int GetLength(ListNode head)
|
||||
{
|
||||
ListNode temp = head;
|
||||
int i = 0;
|
||||
while (temp != null)
|
||||
{
|
||||
i++;
|
||||
temp = temp.next;
|
||||
}
|
||||
return i;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
---
|
||||
## <20><>Ŀ10<31><30><EFBFBD>ϲ<EFBFBD>K<EFBFBD><4B><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
> - <20><><EFBFBD>ţ<EFBFBD>23
|
||||
> - <20>Ѷȣ<D1B6><C8A3><EFBFBD><EFBFBD><EFBFBD>
|
||||
> - https://leetcode-cn.com/problems/merge-k-sorted-lists/
|
||||
|
||||
|
||||
<EFBFBD>ϲ<EFBFBD> k <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>غϲ<D8BA><CFB2><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD>ĸ<EFBFBD><C4B8>Ӷȡ<D3B6>
|
||||
|
||||
<b>ʾ<><CABE></b>:
|
||||
```c
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>:
|
||||
[
|
||||
1->4->5,
|
||||
1->3->4,
|
||||
2->6
|
||||
]
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD>: 1->1->2->3->4->4->5->6
|
||||
```
|
||||
|
||||
<b>˼·<CBBC><C2B7></b><3E><><EFBFBD><EFBFBD><EFBFBD>ϲ<EFBFBD><CFB2>ķ<EFBFBD>ʽ<EFBFBD><CABD>
|
||||
|
||||
<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ϲ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>õ<EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD>µ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ķ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>`ListNode MergeTwoLists(ListNode l1, ListNode l2)`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʹ<EFBFBD>ø÷<EFBFBD><EFBFBD><EFBFBD><EFBFBD>ϲ<EFBFBD>ǰ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>õ<EFBFBD>һ<EFBFBD><EFBFBD><EFBFBD>µ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>֮<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ϲ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ƣ<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>õ<EFBFBD><EFBFBD>ϲ<EFBFBD>`K`<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>б<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>б<EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
**<EFBFBD>ο<EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>**<2A><>
|
||||
|
||||
- ִ<>н<EFBFBD><D0BD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>
|
||||
- ִ<><D6B4><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1>256 ms, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 36.69% <20><><EFBFBD>û<EFBFBD>
|
||||
- <20>ڴ<EFBFBD><DAB4><EFBFBD><EFBFBD>ģ<EFBFBD>29.3 MB, <20><><EFBFBD><EFBFBD><EFBFBD><EFBFBD> C# <20>ύ<EFBFBD>л<EFBFBD><D0BB><EFBFBD><EFBFBD><EFBFBD> 18.37% <20><><EFBFBD>û<EFBFBD>
|
||||
|
||||
|
||||
```c
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* public class ListNode {
|
||||
* public int val;
|
||||
* public ListNode next;
|
||||
* public ListNode(int x) { val = x; }
|
||||
* }
|
||||
*/
|
||||
public class Solution
|
||||
{
|
||||
public ListNode MergeTwoLists(ListNode l1, ListNode l2)
|
||||
{
|
||||
ListNode pHead = new ListNode(int.MaxValue);
|
||||
ListNode temp = pHead;
|
||||
|
||||
while (l1 != null && l2 != null)
|
||||
{
|
||||
if (l1.val < l2.val)
|
||||
{
|
||||
temp.next = l1;
|
||||
l1 = l1.next;
|
||||
}
|
||||
else
|
||||
{
|
||||
temp.next = l2;
|
||||
l2 = l2.next;
|
||||
}
|
||||
temp = temp.next;
|
||||
}
|
||||
|
||||
if (l1 != null)
|
||||
temp.next = l1;
|
||||
|
||||
if (l2 != null)
|
||||
temp.next = l2;
|
||||
|
||||
return pHead.next;
|
||||
}
|
||||
|
||||
public ListNode MergeKLists(ListNode[] lists) {
|
||||
if (lists.Length == 0)
|
||||
return null;
|
||||
|
||||
ListNode result = lists[0];
|
||||
for (int i = 1; i < lists.Length; i++)
|
||||
{
|
||||
result = MergeTwoLists(result, lists[i]);
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
|
||||
# 17 ͼ
|
||||
# 08 ͼ
|
||||
|
||||
**知识结构:**
|
||||
|
||||
679
DataStructureAndAlgorithm/09 排序.md
Normal file
679
DataStructureAndAlgorithm/09 排序.md
Normal file
@@ -0,0 +1,679 @@
|
||||
# 09 排序
|
||||
|
||||
**知识结构:**
|
||||
|
||||
|
||||
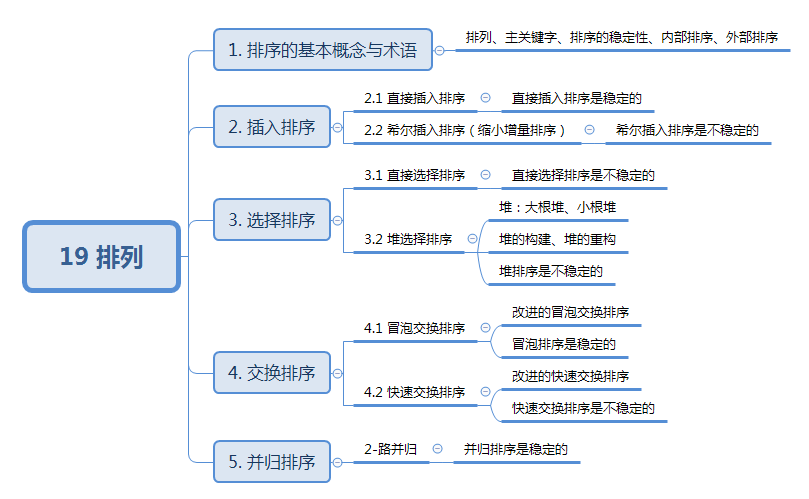
|
||||
|
||||
|
||||
## 1. 排序的基本概念与术语
|
||||
|
||||
假设含有$n$个记录的序列为$\lbrace r_1,r_2,\cdots,r_n \rbrace$,其相应的关键字分别为$\lbrace k_1,k_2,\cdots,k_n \rbrace$,需确定 的一种排列$1,2,\cdots,n$,使其相应的关键字满足$k_{p_1}\leq k_{p_2}\leq\cdots\leq k_{p_n}$的关系,即使得序列成为一个按关键字有序的序列 ,这个样的操作就称为 **排列**。
|
||||
|
||||
|
||||
能唯一标识某一记录的关键字称为 **主关键字**。
|
||||
|
||||
假设$k_i = k_j(1\leq i \leq n, 1\leq j\leq n,i\neq j)$,且在排序前的序列中$r_i$领先于$r_j$(即$i<j$ )。如果排序后$r_i$仍领先于$r_j$,则称所用的排序方法是**稳定的**;反之,若可能使得排序后的序列中$r_j$领先于$r_i$,则称所用的排序方法是**不稳定的**。
|
||||
|
||||
例如:
|
||||
|
||||
- 待排序序列:$20,30,\overline{20}$
|
||||
- 稳定的排序结果:$20,\overline{20},30$
|
||||
- 不稳定的排序结果:$\overline{20},20,30$
|
||||
|
||||
**内部排序**:排序过程都在内存中进行的排序。
|
||||
|
||||
**外部排序**:排序过程需要在内存和外存之间不断交换数据的排序。
|
||||
|
||||
根据排序过程中借助的主要操作,我们把内排序分为:**插入排序**、**选择排序**、**交换排序**和**并归排序**。可以说,这些都是比较成熟的排序技术,已经被广泛地应用于许许多多的程序语言或数据库当中,甚至它们都已经封装了关于排序算法的实现代码。因此,我们学习这些排序算法的目的不是为了去现实排序算法,而是通过学习来提高我们编写算法的能力,以便于去解决更多复杂和灵活的应用性问题。
|
||||
|
||||
|
||||
|
||||
## 2. 插入排序
|
||||
|
||||
### 2.1 直接插入排序
|
||||
|
||||
将一个记录插入到已经排好序的有序表中,从而得到一个新的记录增1的有序表。
|
||||
|
||||
即:先将序列的第1个记录看成是一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。
|
||||
|
||||
如:`int[] Key = new int[]{45,34,78,12,34,32,29,64};`
|
||||
|
||||
排序过程:
|
||||
|
||||
$init0\rightarrow [45],\overline{34},78,12,34,32,29,64$
|
||||
|
||||
$step1\rightarrow [\overline{34},45],78,12,34,32,29,64$
|
||||
|
||||
$step2\rightarrow [\overline{34},45,78],12,34,32,29,64$
|
||||
|
||||
$step3\rightarrow [12,\overline{34},45,78],34,32,29,64$
|
||||
|
||||
$step4\rightarrow [12,\overline{34},34,45,78],32,29,64$
|
||||
|
||||
$step5\rightarrow [12,32,\overline{34},34,45,78],29,64$
|
||||
|
||||
$step6\rightarrow [12,29,32,\overline{34},34,45,78],64$
|
||||
|
||||
$result\rightarrow [12,29,32,\overline{34},34,45,64,78]$
|
||||
|
||||
程序代码:
|
||||
|
||||
```c
|
||||
/// <summary>
|
||||
/// 直接插入排序
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
public static void StraightInsertSort<T>(T[] array) where T : IComparable<T>
|
||||
{
|
||||
for (int i = 1; i < array.Length; i++)
|
||||
{
|
||||
int j = i - 1;
|
||||
T current = array[i];
|
||||
|
||||
while (j >= 0 && array[j].CompareTo(current) > 0)
|
||||
{
|
||||
array[j + 1] = array[j];
|
||||
j--;
|
||||
}
|
||||
array[j + 1] = current;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
如果碰见一个和插入元素相等的,那么插入元素把想插入的元素放在相等元素的后面,所以,相等元素的前后顺序没有改变,从原无序序列出去的顺序就是排好序后的顺序,所以直接插入排序是稳定的。
|
||||
|
||||
### 2.2 希尔插入排序
|
||||
|
||||
希尔排序是1959年由D.L.Shell提出来的,相对直接插入排序有较大的改进。希尔插入排序又叫做**缩小增量排序**。
|
||||
|
||||
直接插入排序的效率在某些时候是很高的,比如我们的记录本身就是基本有序的,我们只需要少量的插入操作,就可以完成整个记录集的排序工作,此时直接插入排序很高效。还有就是记录数比较少时,直接插入的优势也比较明显。可问题在于,两个条件本身就过于苛刻,现实中记录少或者基本有序都属于特殊情况。
|
||||
|
||||
不过别着急,有条件当然是好,条件不存在,我们创造条件也是可以去做的。于是科学家希尔研究出了一种排序方法,对直接插入排序改进后可以增加效率。
|
||||
|
||||
思想:按待排序列下标的一定增量分组(如:增量序列$t_1,t_2,\cdots,t_k$,其中$t_i>t_j$,$t_k=1$),将整个待排序列分割成若干子序列,分别进行直接插入排序,随着增量逐渐减少,所分组包含的记录越来越多,到增量值减至1时,整个记录集被分成一组(这时待排序列“基本有序”),再对全体记录进行直接插入排序,算法终止(对待排序列进行了$k$趟直接插入排序)。
|
||||
|
||||
> 我所理解Shell Insertion Sort最牛的地方是,让排序算法能够并行化。
|
||||
|
||||
希尔插入排序增量的取法:
|
||||
|
||||
$delta1=\left[\frac{n}{2}\right] =\left[\frac{10}{2}\right]=5$
|
||||
|
||||
$delta2=\left[\frac{delta1}{2}\right]=\left[\frac{5}{2}\right]=2$
|
||||
|
||||
$delta3=\left[\frac{delta2}{2}\right]=\left[\frac{2}{2}\right]=1$
|
||||
|
||||
即:先将要排序的一组记录按某个增量$delta$($\left[\frac{n}{2}\right]$ ,$n$为要排序数的个数)分成若干组子序列,每组中记录的下标相差$delta$。对每组中全部元素进行直接插入排序,然后在用一个较小的增量($\left[\frac{delta}{2}\right]$ )对它进行分组,在每组中再进行直接插入排序。继续不断缩小增量直至为1,最后使用直接插入排序完成排序。
|
||||
|
||||
如:`int[] Key = new int[]{45,34,78,12,34,32,29,64};`
|
||||
|
||||
排序过程:
|
||||
|
||||
$d=4\rightarrow 45,\overline{34},78,12,34,32,29,64$
|
||||
|
||||
$d=2\rightarrow 34,32,29,12,45,\overline{34},78,64$
|
||||
|
||||
$d=1\rightarrow 29,12,34,32,45,\overline{34},78,64$
|
||||
|
||||
$result\rightarrow 12,29,32,34,\overline{34},45,64,78$
|
||||
|
||||
程序代码:
|
||||
```c
|
||||
private static void Shell<T>(int delta, T[] array) where T : IComparable<T>
|
||||
{
|
||||
//带增量的直接插入排序
|
||||
for (int i = delta; i < array.Length; i++)
|
||||
{
|
||||
int j = i - delta;
|
||||
T current = array[i];
|
||||
while (j >= 0 && array[j].CompareTo(current) > 0)
|
||||
{
|
||||
array[j + delta] = array[j];
|
||||
j = j - delta;
|
||||
}
|
||||
array[j + delta] = current;
|
||||
}
|
||||
}
|
||||
|
||||
/// <summary>
|
||||
/// 希尔插入排序
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
public static void ShellInsertSort<T>(T[] array) where T : IComparable<T>
|
||||
{
|
||||
for (int delta = array.Length/2; delta > 0; delta = delta/2)
|
||||
{
|
||||
Shell(delta, array);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
希尔插入排序时效分析很难,关键码的比较次数与记录移动次数依赖于增量因子序列$delta$的选取。目前还没有人给出选取最好的增量因子序列的方法。希尔插入排序方法是一个不稳定的排序方法。
|
||||
|
||||
## 3. 选择排序
|
||||
|
||||
### 3.1 直接选择排序
|
||||
|
||||
思想:每一趟在$n-i(i=0,1,\cdots,n-1)$个记录中选取关键字最小的记录作为有序序列中第$i$个记录。(在要排列的一组数中,选出最小的一个数与第1个位置的数交换;然后在剩下的数当中再找最小的与第2个位置的数交换,依次类推,直到第$n-1$个元素和第$n$个元素比较为止。)
|
||||
|
||||
如:`int[] Key = new int[]{45,34,78,12,34,32,29,64};`
|
||||
|
||||
排序过程:
|
||||
|
||||
$i=0\rightarrow 12,\overline{34},78,45,34,32,29,64$
|
||||
|
||||
$i=1\rightarrow 12,29,78,45,34,32,\overline{34},64$
|
||||
|
||||
$i=2\rightarrow 12,29,32,45,34,78,\overline{34},64$
|
||||
|
||||
$i=3\rightarrow 12,29,32,34,45,78,\overline{34},64$
|
||||
|
||||
$i=4\rightarrow 12,29,32,34,\overline{34},78,45,64$
|
||||
|
||||
$i=5\rightarrow 12,29,32,34,\overline{34},45,78,64$
|
||||
|
||||
$i=6\rightarrow 12,29,32,34,\overline{34},45,64,78$
|
||||
|
||||
|
||||
程序代码:
|
||||
```c
|
||||
/// <summary>
|
||||
/// 直接选择排序
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
public static void StraightSelectSort<T>(T[] array) where T : IComparable<T>
|
||||
{
|
||||
for (int i = 0; i < array.Length - 1; i++)
|
||||
{
|
||||
int minIndex = i;
|
||||
T min = array[i];
|
||||
|
||||
for (int j = i + 1; j < array.Length; j++)
|
||||
{
|
||||
if (array[j].CompareTo(min) < 0)
|
||||
{
|
||||
min = array[j];
|
||||
minIndex = j;
|
||||
}
|
||||
}
|
||||
if (minIndex != i)
|
||||
{
|
||||
array[minIndex] = array[i];
|
||||
array[i] = min;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
直接选择排序是不稳定的。
|
||||
|
||||
### 3.2 堆选择排序
|
||||
|
||||
直接选择排序并没有把每一趟的比较结果保存下来,在后一趟的比较中,许多比较在前一趟已经做过了,但由于前一趟排序时未保存这些比较结果,所以后一趟排序时又重复执行了这些比较操作,因而执行的比较次数较多。
|
||||
|
||||
如果可以做到每次在选择到最小记录的同时,并根据比较结果对其他记录做出相应的调整,那样排序的总体效率就会非常高了。而堆选择排序是一种树形选择排序,是对直接选择排序的有效改进。堆选择排序算法是Floyd和Williams在1964年共同发明的,同时,他们也发明了“堆”这样的数据结构。
|
||||
|
||||
堆的概念:具有$n$个元素的序列$K=\lbrace k_1,k_2,⋯,k_n \rbrace$当且仅当满足
|
||||
|
||||
|
||||
$$
|
||||
\begin{cases}
|
||||
k_i\leq k_{2i}\\
|
||||
k_i\leq k_{2i+1}
|
||||
\end{cases},
|
||||
\begin{cases}
|
||||
k_i\geq k_{2i}\\
|
||||
k_i\geq k_{2i+1}
|
||||
\end{cases},
|
||||
i=1,2,\cdots,\left[\frac{n}{2}\right]
|
||||
$$
|
||||
|
||||
时称之为堆。
|
||||
|
||||
若关键码的集合$K=\lbrace k_1,k_2,⋯,k_n \rbrace$,把它们按照完全二叉树的顺序存放在一维数组中。
|
||||
- 若满足$k_i\leq k_{2i}$且$k_i\leq k_{2i+1}$则称作小根堆。
|
||||
- 若满足$k_i\geq k_{2i}$且$k_i \geq k_{2i+1}$则称作大根堆。
|
||||
|
||||
小根堆:`int[] Key = new int[]{9,17,65,23,45,78,87,53,31,58,64};`
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
大根堆:`int[] Key = new int[]{94,93,75,91,85,44,51,18,48,58,10,34};`
|
||||
|
||||
|
||||
|
||||
思想(以大根堆为例):
|
||||
构建大根堆之后,输出堆顶记录,对剩余的$n-1$个记录接着构建大根堆,便可得到$n$个记录的次大值,如此反复执行,就能得到一个有序序列,这个过程称为堆选择排序。
|
||||
|
||||
堆选择排序需解决的两个问题:
|
||||
|
||||
问题1:如何建堆,对初始序列建堆的过程,就是一个反复进行筛选的过程。
|
||||
|
||||
- (1)对一棵具有$n$个结点的完全二叉树来说最后一个结点是第$[\frac{n}{2}]$个结点的子树。
|
||||
- (2)筛选从第$[\frac{n}{2}]$个结点为根的子树开始,该子树成为堆。
|
||||
- (3)之后向前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点。
|
||||
|
||||
即把序号为$[\frac{n}{2}],[\frac{n}{2}]-1,\cdots,1$,的记录作为根的子树都调整为堆。
|
||||
|
||||
问题2:输出堆顶元素后,如何调整新堆。
|
||||
|
||||
- (1)设有$n$个元素的堆,输出堆顶元素后,剩下$n-1$个元素。将堆底元素送入堆顶(最后一个元素与堆顶进行交换),堆被破坏,其原因仅是根结点不满足堆的性质。
|
||||
- (2)将根结点与左,右子树中较大元素进行交换。
|
||||
- (3)若与左子树交换:如果左子树堆被破坏,即左子树的根结点不满足堆的性质,则重复第二步。
|
||||
- (4)若与右子树交换:如果右子树堆被破坏,即右子树的根结点不满足堆的性质,则重复第二步。
|
||||
- (5)继续对不满足堆性质的子树进行上述操作,直到叶子结点,堆被重建成。
|
||||
|
||||
即:输出堆顶元素,将最后一个叶子结点放在堆顶,重新构建大根堆。
|
||||
|
||||
如:`int[] Key = new int[]{45,34,78,12,34,32,29,64};`
|
||||
|
||||
排序过程:
|
||||
|
||||
初始时:$Key1 \rightarrow -1,45,\overline{34},78,12,34,32,29,64$
|
||||
|
||||
建堆后:$Key1 \rightarrow -1,78,64,45,\overline{34},34,32,29,12$
|
||||
|
||||
|
||||
|
||||
|
||||
堆重建后:
|
||||
|
||||
$Key1 \rightarrow -1,64,\overline{34},45,12,34,32,29,[78]$
|
||||
|
||||
$Key1 \rightarrow -1,45,\overline{34},32,12,34,29,[64,78]$
|
||||
|
||||
$Key1 \rightarrow -1,\overline{34},34,32,12,29,[45,64,78]$
|
||||
|
||||
$Key1 \rightarrow -1,34,29,32,12,[\overline{34},45,64,78]$
|
||||
|
||||
$Key1 \rightarrow -1,32,29,12,[34,\overline{34},45,64,78]$
|
||||
|
||||
$Key1 \rightarrow -1,29,12,[32,34,\overline{34},45,64,78]$
|
||||
|
||||
$Key1 \rightarrow -1,12,[29,32,34,\overline{34},45,64,78]$
|
||||
|
||||
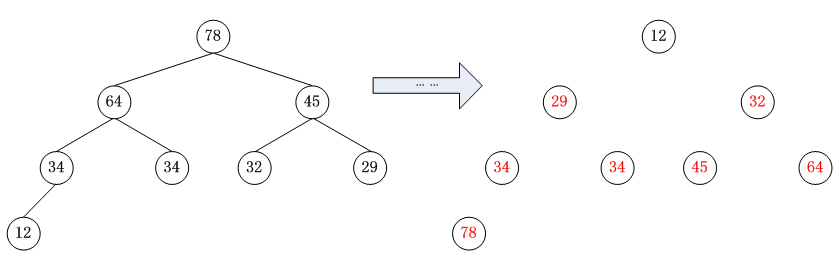
|
||||
|
||||
程序代码:
|
||||
```c
|
||||
private static void Restore<T>(T[] array, int j, int vCount) where T : IComparable<T>
|
||||
{
|
||||
//构建以结点j为根,一共有vCount个结点的大根堆
|
||||
while (j <= vCount / 2)
|
||||
{
|
||||
int m = (2 * j + 1 <= vCount && array[2 * j + 1].CompareTo(array[2 * j]) > 0)
|
||||
? 2 * j + 1
|
||||
: 2 * j;
|
||||
if (array[m].CompareTo(array[j]) > 0)
|
||||
{
|
||||
T temp = array[m];
|
||||
array[m] = array[j];
|
||||
array[j] = temp;
|
||||
j = m;
|
||||
}
|
||||
else
|
||||
{
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/// <summary>
|
||||
/// 堆选择排序
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
public static void HeapSelectSort<T>(T[] array) where T : IComparable<T>
|
||||
{
|
||||
int vCount = array.Length;
|
||||
T[] tempArray = new T[vCount + 1];
|
||||
|
||||
for (int i = 0; i < vCount; i++)
|
||||
tempArray[i + 1] = array[i];
|
||||
|
||||
//初建大根堆
|
||||
for (int i = vCount / 2; i >= 1; i--)
|
||||
Restore(tempArray, i, vCount);
|
||||
|
||||
//大根堆的重构与排序
|
||||
for (int i = vCount; i > 1; i--)
|
||||
{
|
||||
T temp = tempArray[i];
|
||||
tempArray[i] = tempArray[1];
|
||||
tempArray[1] = temp;
|
||||
Restore(tempArray, 1, i - 1);
|
||||
}
|
||||
|
||||
for (int i = 0; i < vCount; i++)
|
||||
array[i] = tempArray[i + 1];
|
||||
}
|
||||
```
|
||||
|
||||
## 4. 交换排序
|
||||
|
||||
### 4.1 冒泡交换排序
|
||||
|
||||
思想:通过相邻记录之间的比较和交换,使关键字较小的记录如气泡一般逐渐向上漂移直至水面。
|
||||
|
||||
如:`int[] Key = new int[]{45,34,78,12,34,32,29,64};`
|
||||
|
||||
$i=0\rightarrow [12],45,\overline{34},78,29,34,32,64$
|
||||
|
||||
$i=1\rightarrow [12,29],45,\overline{34},78,32,34,64$
|
||||
|
||||
$i=2\rightarrow [12,29,32],45,\overline{34},78,34,64$
|
||||
|
||||
$i=3\rightarrow [12,29,32,\overline{34}],45,34,78,64$
|
||||
|
||||
$i=4\rightarrow [12,29,32,\overline{34},34],45,64,78$
|
||||
|
||||
$i=5\rightarrow [12,29,32,\overline{34},34,45],64,78$
|
||||
|
||||
$i=6\rightarrow [12,29,32,\overline{34},34,45,64],78$
|
||||
|
||||
|
||||
程序代码:
|
||||
```c
|
||||
/// <summary>
|
||||
/// 冒泡交换排序
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
public static void BubbleExchangeSort<T>(T[] array) where T : IComparable<T>
|
||||
{
|
||||
for (int i = 0; i < array.Length - 1; i++)
|
||||
{
|
||||
for (int j = array.Length - 1; j > i; j--)
|
||||
{
|
||||
if (array[j].CompareTo(array[j - 1]) < 0)
|
||||
{
|
||||
T temp = array[j - 1];
|
||||
array[j - 1] = array[j];
|
||||
array[j] = temp;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
对冒泡排序常见的改进方法是加入一个标志性变量`flag`,用于标志某一趟排序过程是否有数据交换,如果进行某一趟排序时并没有进行数据交换,则说明数据已经按要求排列好,可立即结束排序,避免不必要的比较过程。
|
||||
|
||||
|
||||
程序代码:
|
||||
```c
|
||||
/// <summary>
|
||||
/// 改进的冒泡交换排序
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
public static void BubbleExchangeSortImproved<T>(T[] array) where T : IComparable<T>
|
||||
{
|
||||
for (int i = 0; i < array.Length - 1; i++)
|
||||
{
|
||||
bool flag = false;
|
||||
for (int j = array.Length - 1; j > i; j--)
|
||||
{
|
||||
if (array[j].CompareTo(array[j - 1]) < 0)
|
||||
{
|
||||
T temp = array[j - 1];
|
||||
array[j - 1] = array[j];
|
||||
array[j] = temp;
|
||||
flag = true;
|
||||
}
|
||||
}
|
||||
if (flag == false)
|
||||
break;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 4.2 快速交换排序
|
||||
|
||||
快速交换排序是由图灵奖获得者Tony Hoare(东尼.霍尔)所发展的一种排序算法,是采用分治策略的一个非常典型的应用。快速交换排序虽然高端,但其思想是来自冒泡交换排序的,冒泡交换排序是通过相邻元素的比较和交换把最小的冒泡到最顶端,而快速交换排序是比较和交换小数和大数,这样一来不仅小数冒泡到上面的同时也把大数沉到下面。
|
||||
|
||||
其基本思想如下:
|
||||
|
||||
- (1)选择一个基准元素,通常选择第一个元素或者最后一个元素。
|
||||
- (2)通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小,另一部分记录的元素值比基准值大。
|
||||
- (3)此时基准元素在其排好序的正确位置。
|
||||
- (4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
|
||||
|
||||
即:从待排记录中选一记录,将其放入正确的位置,然后以该位置为界,对左右两部分再做快速排序,直到划分的长度为1。
|
||||
|
||||
如:`int[] Key = new int[]{45,34,78,12,34,32,29,64};`
|
||||
|
||||
|
||||
$init\rightarrow 45,\overline{34},78,12,34,32,29,64$
|
||||
|
||||
$step1\rightarrow [32,\overline{34},29,12,34],45,[78,64]$
|
||||
|
||||
$step2\rightarrow [[29,12],32,[\overline{34},34]],45,[78,64]$
|
||||
|
||||
$step3\rightarrow [[[12],29],32,[\overline{34},34]],45,[78,64]$
|
||||
|
||||
$step4\rightarrow [[[12],29],32,[[34],\overline{34}]],45,[78,64]$
|
||||
|
||||
$step5\rightarrow [[[12],29],32,[[34],\overline{34}]],45,[[64],78]$
|
||||
|
||||
|
||||
程序代码:
|
||||
```c
|
||||
private static void QuickSort<T>(T[] array, int left, int right) where T : IComparable<T>
|
||||
{
|
||||
//快速排序递归函数
|
||||
if (left < right)
|
||||
{
|
||||
T current = array[left];
|
||||
int i = left;
|
||||
int j = right;
|
||||
while (i < j)
|
||||
{
|
||||
while (array[j].CompareTo(current) > 0 && i < j)
|
||||
j--;
|
||||
while (array[i].CompareTo(current) <= 0 && i < j)
|
||||
i++;
|
||||
if (i < j)
|
||||
{
|
||||
T temp = array[i];
|
||||
array[i] = array[j];
|
||||
array[j] = temp;
|
||||
j--;
|
||||
i++;
|
||||
}
|
||||
}
|
||||
array[left] = array[j];
|
||||
array[j] = current;
|
||||
if (left < j - 1) QuickSort(array, left, j - 1);
|
||||
if (right > j + 1) QuickSort(array, j + 1, right);
|
||||
}
|
||||
}
|
||||
|
||||
/// <summary>
|
||||
/// 快速交换排序
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
public static void QuickExchangeSort<T>(T[] array) where T : IComparable<T>
|
||||
{
|
||||
QuickSort(array, 0, array.Length - 1);
|
||||
}
|
||||
```
|
||||
|
||||
其实上面的代码还可以再优化,上面代码中基准元素已经在`current`中保存了,所以不需要每次交换都设置一个`temp`变量,在交换的时候只需要先后覆盖就可以了。这样既能较少空间的使用还能降低赋值运算的次数。
|
||||
|
||||
优化代码如下:
|
||||
|
||||
```c
|
||||
private static void QuickSortImproved<T>(T[] array, int left, int right) where T : IComparable<T>
|
||||
{
|
||||
//快速排序递归函数
|
||||
if (left < right)
|
||||
{
|
||||
T current = array[left];
|
||||
int i = left;
|
||||
int j = right;
|
||||
while (i < j)
|
||||
{
|
||||
while (array[j].CompareTo(current) > 0 && i < j)
|
||||
j--;
|
||||
array[i] = array[j];
|
||||
|
||||
while (array[i].CompareTo(current) <= 0 && i < j)
|
||||
i++;
|
||||
array[j] = array[i];
|
||||
}
|
||||
array[j] = current;
|
||||
if (left < j - 1) QuickSortImproved(array, left, j - 1);
|
||||
if (right > j + 1) QuickSortImproved(array, j + 1, right);
|
||||
}
|
||||
}
|
||||
|
||||
/// <summary>
|
||||
/// 快速交换排序
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
public static void QuickExchangeSortImproved<T>(T[] array) where T : IComparable<T>
|
||||
{
|
||||
QuickSortImproved(array, 0, array.Length - 1);
|
||||
}
|
||||
```
|
||||
|
||||
## 5. 并归排序
|
||||
|
||||
我们首先先看两个有序序列合并的例子,如:
|
||||
|
||||
```c
|
||||
int[] Key1 = new int[]{1,3,5,7,9};
|
||||
int[] Key2 = new int[]{2,4,6,8,10,12,14}
|
||||
|
||||
int[] temp = new int[Key1.Length + Key2.Length];
|
||||
```
|
||||
$temp \rightarrow 0,0,0,0,0,0,0,0,0,0,0,0$
|
||||
|
||||
$temp \rightarrow 1,2,3,4,5,6,7,8,9,0,0,0$
|
||||
|
||||
$temp \rightarrow 1,2,3,4,5,6,7,8,9,10,12,14$
|
||||
|
||||
程序代码:
|
||||
|
||||
```c
|
||||
/// <summary>
|
||||
/// 合并排序
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array1">有序记录集合1</param>
|
||||
/// <param name="array2">有序记录集合2</param>
|
||||
/// <returns>合并后的有序记录集合</returns>
|
||||
public static T[] MergeSort<T>(T[] array1,T[] array2) where T : IComparable<T>
|
||||
{
|
||||
T[] temp = new T[array1.Length + array2.Length];
|
||||
int i = 0, j = 0, k = 0;
|
||||
while (i < array1.Length && j < array2.Length)
|
||||
{
|
||||
if (array1[i].CompareTo(array2[i]) < 0)
|
||||
{
|
||||
temp[k++] = array1[i++];
|
||||
}
|
||||
else
|
||||
{
|
||||
temp[k++] = array2[j++];
|
||||
}
|
||||
}
|
||||
while (i < array1.Length)
|
||||
{
|
||||
temp[k++] = array1[i++];
|
||||
}
|
||||
while (j < array2.Length)
|
||||
{
|
||||
temp[k++] = array2[j++];
|
||||
}
|
||||
return temp;
|
||||
}
|
||||
```
|
||||
|
||||
我们接着看一个序列的并归排序。
|
||||
|
||||
首先递归划分子问题,然后合并结果。把待排序列看成由两个有序的子序列构成,然后合并两个子序列,接着把子序列看成由两个有序序列组成……。倒过来看,其实就是先两两合并,然后四四合并……最终形成有序序列。该算法是采用分治策略的一个非常典型的应用,俗称 **2-路并归**。
|
||||
|
||||
如:`int[] Key = new int[]{45,34,78,12,34,32,29,64};`
|
||||
|
||||
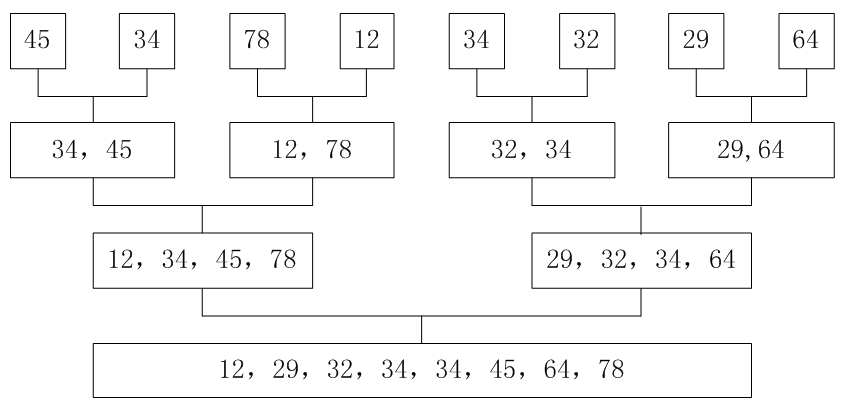
|
||||
|
||||
程序代码:
|
||||
```c
|
||||
/// <summary>
|
||||
/// 合并排序的递归合并函数
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
/// <param name="left">起点位置</param>
|
||||
/// <param name="mid">中间位置</param>
|
||||
/// <param name="right">终点位置</param>
|
||||
private static void Merge<T>(T[] array, int left, int mid, int right) where T : IComparable<T>
|
||||
{
|
||||
T[] temp = new T[right - left + 1];
|
||||
int i = left;
|
||||
int j = mid + 1;
|
||||
int k = 0;
|
||||
while (i <= mid && j <= right)
|
||||
{
|
||||
if (array[i].CompareTo(array[j]) < 0)
|
||||
{
|
||||
temp[k++] = array[i++];
|
||||
}
|
||||
else
|
||||
{
|
||||
temp[k++] = array[j++];
|
||||
}
|
||||
}
|
||||
while (i <= mid)
|
||||
{
|
||||
temp[k++] = array[i++];
|
||||
}
|
||||
while (j <= right)
|
||||
{
|
||||
temp[k++] = array[j++];
|
||||
}
|
||||
for (int n = 0; n < temp.Length; n++)
|
||||
{
|
||||
array[left + n] = temp[n];
|
||||
}
|
||||
}
|
||||
|
||||
/// <summary>
|
||||
/// 合并排序的递归分治函数
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
/// <param name="left">起点位置</param>
|
||||
/// <param name="right">终点位置</param>
|
||||
private static void MergeSort<T>(T[] array, int left, int right) where T : IComparable<T>
|
||||
{
|
||||
if (left >= right)
|
||||
return;
|
||||
|
||||
int mid = (left + right) / 2;
|
||||
MergeSort(array, left, mid); //递归排序左边
|
||||
MergeSort(array, mid + 1, right); //递归排序右边
|
||||
Merge(array, left, mid, right); //合并
|
||||
}
|
||||
|
||||
|
||||
/// <summary>
|
||||
/// 合并排序
|
||||
/// </summary>
|
||||
/// <typeparam name="T">需要排序记录的类型</typeparam>
|
||||
/// <param name="array">需要排序的记录集合</param>
|
||||
public static void MergeSort<T>(T[] array) where T : IComparable<T>
|
||||
{
|
||||
MergeSort(array, 0, array.Length - 1);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
398
DataStructureAndAlgorithm/精选练习50题.md
Normal file
398
DataStructureAndAlgorithm/精选练习50题.md
Normal file
@@ -0,0 +1,398 @@
|
||||
# <20><>ѡ<EFBFBD><D1A1>ϰ50
|
||||
|
||||
**01<30><31><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڼ<EFBFBD><DABC><EFBFBD><EFBFBD><EFBFBD><EFBFBD>еı<D0B5>ʾ<EFBFBD><CABE>Ϊ<EFBFBD><CEAA><EFBFBD>ݵ<EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD>洢<EFBFBD>ṹ
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ṹ
|
||||
- <20><>C<EFBFBD><43>˳<EFBFBD><CBB3><EFBFBD>ṹ
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><DFBC>ṹ
|
||||
|
||||
**02<30><32><EFBFBD><EFBFBD>һ<EFBFBD><D2BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD><E3B7A8><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>B<EFBFBD><42>ȷ<EFBFBD><C8B7><EFBFBD><EFBFBD>
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
**03<30><33><EFBFBD><EFBFBD><EFBFBD>¶<EFBFBD><C2B6><EFBFBD><EFBFBD><EFBFBD>ʽ<EFBFBD>洢<EFBFBD>ṹ<EFBFBD><E1B9B9><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>д<EFBFBD><D0B4><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><DFBC><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵĽ<DAB5><C4BD>㣬<EFBFBD><E3A3AC><EFBFBD><EFBFBD><EFBFBD>ϲ<EFBFBD><CFB2><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8><EFBFBD><EFBFBD><EFBFBD>㣬ֱ<E3A3AC><D6B1>ȷ<EFBFBD><C8B7><EFBFBD><EFBFBD>i<EFBFBD><69><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ĵ洢<C4B4><E6B4A2>ַ
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD><EFBFBD>롢ɾ<EBA1A2><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㣬<EFBFBD><E3A3AC><EFBFBD>ش<EFBFBD><D8B4><EFBFBD><EFBFBD>ƶ<EFBFBD><C6B6><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ָ<EFBFBD><D6B8><EFBFBD>洢<F2A3ACB4>ܶ<EFBFBD>С<EFBFBD><D0A1>˳<EFBFBD><CBB3><EFBFBD>洢<EFBFBD>ṹ
|
||||
|
||||
**04<30><34><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD><D4B1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>У<EFBFBD><D0A3><EFBFBD><EFBFBD><EFBFBD>ȷ<EFBFBD><C8B7><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD><D4B1><EFBFBD><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD>洢ʱ<E6B4A2><CAB1><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ռ<EFBFBD><D5BC>һƬ<D2BB><C6AC><EFBFBD><EFBFBD><EFBFBD>Ĵ洢<C4B4><E6B4A2>Ԫ
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD><D4B1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʽ<EFBFBD>洢ʱ<E6B4A2><CAB1><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫռ<D2AA><D5BC>һƬ<D2BB><C6AC><EFBFBD><EFBFBD><EFBFBD>Ĵ洢<C4B4><E6B4A2>Ԫ
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD><D4B1><EFBFBD><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD>洢ʱ<E6B4A2><CAB1><EFBFBD><EFBFBD><EFBFBD>ڽ<EFBFBD><DABD>в<EFBFBD><D0B2><EFBFBD><EFBFBD><EFBFBD>ɾ<EFBFBD><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD><D4B1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʽ<EFBFBD>洢ʱ<E6B4A2><CAB1><EFBFBD><EFBFBD><EFBFBD>ڽ<EFBFBD><DABD>в<EFBFBD><D0B2><EFBFBD><EFBFBD><EFBFBD>ɾ<EFBFBD><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
**05<30><35><EFBFBD><EFBFBD>һ<EFBFBD><D2BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>У<EFBFBD><D0A3><EFBFBD>P<EFBFBD><50>ָ<EFBFBD><D6B8><EFBFBD>㲻<EFBFBD><E3B2BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㣬<EFBFBD><E3A3AC>P֮<50><D6AE><EFBFBD><EFBFBD><EFBFBD><EFBFBD>S<EFBFBD><53>ָ<EFBFBD><D6B8><EFBFBD>㣬<EFBFBD><E3A3AC>ִ<EFBFBD><D6B4>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>S.Next=P; P.Next=S;
|
||||
- <20><>B<EFBFBD><42>S.Next=P.Next; P.Next=S;
|
||||
- <20><>C<EFBFBD><43>S.Next=P.Next; P =S;
|
||||
- <20><>D<EFBFBD><44>P.Next=S; S.Next=P;
|
||||
|
||||
|
||||
|
||||
**06<30><36><EFBFBD><EFBFBD>˫<EFBFBD><CBAB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>У<EFBFBD>ɾ<EFBFBD><C9BE>P<EFBFBD><50>ָ<EFBFBD>Ľ<EFBFBD><C4BD>㣬<EFBFBD><E3A3AC>ִ<EFBFBD><D6B4>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>P.Next.Prior=P.Prior; P.Prior.Next=P.Next;
|
||||
- <20><>B<EFBFBD><42>P.Next.Prior=P.Prior; P.Prior=P.Next;
|
||||
- <20><>C<EFBFBD><43>P.Prior.Next=P; P.Prior =P.Prior.Prior;
|
||||
- <20><>D<EFBFBD><44>P.Prior=P.Next.Next; P.Next=P.Prior.Prior;
|
||||
|
||||
|
||||
|
||||
**07<30><37><EFBFBD><EFBFBD>һ<EFBFBD><D2BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊn<CEAA><6E>˳<EFBFBD><CBB3><EFBFBD><EFBFBD><EFBFBD>У<EFBFBD><D0A3>ڵ<EFBFBD>i<EFBFBD><69>Ԫ<EFBFBD>أ<EFBFBD>1<EFBFBD><31>i<EFBFBD><69>n+1<><31>֮ǰ<D6AE><C7B0><EFBFBD><EFBFBD>һ<EFBFBD><D2BB><EFBFBD><EFBFBD>Ԫ<EFBFBD><D4AA>ʱ<EFBFBD><CAB1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ƶ<EFBFBD>______<5F><5F>Ԫ<EFBFBD>ء<EFBFBD>**
|
||||
- <20><>A<EFBFBD><41>n-i
|
||||
- <20><>B<EFBFBD><42>n-i+1
|
||||
- <20><>C<EFBFBD><43>n-i-1
|
||||
- <20><>D<EFBFBD><44>i
|
||||
|
||||
|
||||
|
||||
**08<30><38>ջ<EFBFBD><D5BB><EFBFBD>ص<EFBFBD><D8B5><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD>Ƚ<EFBFBD><C8BD>ȳ<EFBFBD>
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȳ<EFBFBD>
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڳ<EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڽ<EFBFBD>
|
||||
|
||||
|
||||
|
||||
**09<30><39><EFBFBD>ӵ<EFBFBD><D3B5>ص<EFBFBD><D8B5><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD>Ƚ<EFBFBD><C8BD>ȳ<EFBFBD>
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȳ<EFBFBD>
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڳ<EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڽ<EFBFBD>
|
||||
|
||||
|
||||
|
||||
**10<31><30>ջ<EFBFBD>Ͷ<EFBFBD><CDB6>еĹ<D0B5>ͬ<EFBFBD><CDAC><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ƚ<EFBFBD><C8BD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ƚ<EFBFBD><C8BD>ȳ<EFBFBD>
|
||||
- <20><>C<EFBFBD><43>ֻ<EFBFBD><D6BB><EFBFBD><EFBFBD><EFBFBD>ڶ˵㴦<CBB5><E3B4A6><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɾ<EFBFBD><C9BE>Ԫ<EFBFBD><D4AA>
|
||||
- <20><>D<EFBFBD><44>û<EFBFBD>й<EFBFBD>ͬ<EFBFBD><CDAC>
|
||||
|
||||
|
||||
|
||||
**11<31><31><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F><EFBFBD><EFBFBD>ջ<EFBFBD>Ļ<EFBFBD><C4BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㡣**
|
||||
- <20><>A<EFBFBD><41>ɾ<EFBFBD><C9BE>ջ<EFBFBD><D5BB>Ԫ<EFBFBD><D4AA>
|
||||
- <20><>B<EFBFBD><42>ɾ<EFBFBD><C9BE>ջ<EFBFBD><D5BB>Ԫ<EFBFBD><D4AA>
|
||||
- <20><>C<EFBFBD><43><EFBFBD>ж<EFBFBD>ջ<EFBFBD>Ƿ<EFBFBD>Ϊ<EFBFBD><CEAA>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD>ջ<EFBFBD><D5BB>Ϊ<EFBFBD><CEAA>ջ
|
||||
|
||||
|
||||
|
||||
**12<31><32><EFBFBD><EFBFBD>ջS<D5BB>Ͷ<EFBFBD><CDB6><EFBFBD>Q<EFBFBD>ij<EFBFBD>ʼ״̬Ϊ<CCAC>գ<EFBFBD>Ԫ<EFBFBD><D4AA>a<EFBFBD><61>b<EFBFBD><62>c<EFBFBD><63>d<EFBFBD><64>e<EFBFBD><65>f<EFBFBD><66><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8>ջS<D5BB><53>һ<EFBFBD><D2BB>Ԫ<EFBFBD>س<EFBFBD>ջ<EFBFBD><EFBFBD><F3BCB4BD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Q<EFBFBD><51><EFBFBD><EFBFBD><EFBFBD><EFBFBD>6<EFBFBD><36>Ԫ<EFBFBD>س<EFBFBD><D8B3>ӵ<EFBFBD>˳<EFBFBD><CBB3><EFBFBD><EFBFBD>b<EFBFBD><62>d<EFBFBD><64>c<EFBFBD><63>f<EFBFBD><66>e<EFBFBD><65>a<EFBFBD><61>ջS<D5BB><53><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD><D3A6>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>2
|
||||
- <20><>B<EFBFBD><42>3
|
||||
- <20><>C<EFBFBD><43>4
|
||||
- <20><>D<EFBFBD><44>5
|
||||
|
||||
|
||||
|
||||
**13<31><33>1<EFBFBD><31>2<EFBFBD><32>3<EFBFBD><33>4<EFBFBD>ĸ<EFBFBD>Ԫ<EFBFBD>ذ<EFBFBD>˳<EFBFBD><CBB3><EFBFBD><EFBFBD>ջ<EFBFBD><D5BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܵij<DCB5>ջ˳<D5BB><CBB3>Ϊ______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>1<EFBFBD><31>2<EFBFBD><32>3<EFBFBD><33>4
|
||||
- <20><>B<EFBFBD><42>2<EFBFBD><32>3<EFBFBD><33>4<EFBFBD><34>1
|
||||
- <20><>C<EFBFBD><43>1<EFBFBD><31>4<EFBFBD><34>3<EFBFBD><33>2
|
||||
- <20><>D<EFBFBD><44>3<EFBFBD><33>1<EFBFBD><31>4<EFBFBD><34>2
|
||||
|
||||
|
||||
|
||||
**14<31><34><EFBFBD>ڽ<EFBFBD><DABD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ӡ<EFBFBD><D3A1>֮<EFBFBD><D6AE><EFBFBD>ٶȲ<D9B6>ƥ<EFBFBD><C6A5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱͨ<CAB1><CDA8><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><D2BB><EFBFBD><EFBFBD>ӡ<EFBFBD><D3A1><EFBFBD>ݻ<EFBFBD><DDBB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫ<EFBFBD><D2AA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>д<EFBFBD><D0B4><EFBFBD>û<EFBFBD><C3BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ӡ<EFBFBD><D3A1><EFBFBD><EFBFBD><EFBFBD>Ӹû<D3B8><C3BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȡ<EFBFBD><C8A1><EFBFBD><EFBFBD><EFBFBD>ݴ<EFBFBD>ӡ<EFBFBD><D3A1><EFBFBD>û<EFBFBD><C3BB><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD><D3A6><EFBFBD><EFBFBD>һ<EFBFBD><D2BB>______<5F>ṹ<EFBFBD><E1B9B9>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD>ջ
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD>
|
||||
|
||||
**15<31><35><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʾ<EFBFBD><CABE><EFBFBD>Ա<EFBFBD><D4B1><EFBFBD><EFBFBD>ŵ<EFBFBD><C5B5><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȡ
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD>ѵĴ洢<C4B4>ռ<EFBFBD><D5BC><EFBFBD>˳<EFBFBD><CBB3><EFBFBD>洢<EFBFBD><E6B4A2>
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD><EFBFBD>ڲ<EFBFBD><DAB2><EFBFBD><EFBFBD><EFBFBD>ɾ<EFBFBD><C9BE>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ԫ<EFBFBD>ص<EFBFBD><D8B5><EFBFBD><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD><EFBFBD><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD><EFBFBD>ͬ
|
||||
|
||||
|
||||
|
||||
**16<31><36><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD>洢<EFBFBD><E6B4A2><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD><D4B1><EFBFBD><EFBFBD><EFBFBD><EFBFBD>䳤<EFBFBD><E4B3A4>Ϊn<CEAA><6E><EFBFBD><EFBFBD><EFBFBD>κ<EFBFBD>λ<EFBFBD><CEBB><EFBFBD>ϲ<EFBFBD><CFB2><EFBFBD><EFBFBD><EFBFBD>ɾ<EFBFBD><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǵȸ<C7B5><C8B8>ʵġ<CAB5><C4A1><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><D2BB>Ԫ<EFBFBD><D4AA>ʱƽ<CAB1><C6BD>Ҫ<EFBFBD>ƶ<EFBFBD><C6B6><EFBFBD><EFBFBD>е<EFBFBD>______<5F><5F>Ԫ<EFBFBD>ء<EFBFBD>**
|
||||
- <20><>A<EFBFBD><41>n/2
|
||||
- <20><>B<EFBFBD><42>(n+1)/2
|
||||
- <20><>C<EFBFBD><43>(n-1)/2
|
||||
- <20><>D<EFBFBD><44>n
|
||||
|
||||
|
||||
|
||||
**17<31><37><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD>洢<EFBFBD><E6B4A2><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD><D4B1><EFBFBD><EFBFBD><EFBFBD><EFBFBD>䳤<EFBFBD><E4B3A4>Ϊn<CEAA><6E><EFBFBD><EFBFBD><EFBFBD>κ<EFBFBD>λ<EFBFBD><CEBB><EFBFBD>ϲ<EFBFBD><CFB2><EFBFBD><EFBFBD><EFBFBD>ɾ<EFBFBD><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǵȸ<C7B5><C8B8>ʵġ<CAB5>ɾ<EFBFBD><C9BE>һ<EFBFBD><D2BB>Ԫ<EFBFBD><D4AA>ʱƽ<CAB1><C6BD>Ҫ<EFBFBD>ƶ<EFBFBD><C6B6><EFBFBD><EFBFBD>е<EFBFBD>______<5F><5F>Ԫ<EFBFBD>ء<EFBFBD>**
|
||||
- <20><>A<EFBFBD><41>n/2
|
||||
- <20><>B<EFBFBD><42>(n+1)/2
|
||||
- <20><>C<EFBFBD><43>(n-1)/2
|
||||
- <20><>D<EFBFBD><44>n
|
||||
|
||||
|
||||
|
||||
**18<31><38>ѭ<EFBFBD><D1AD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫ<EFBFBD>ŵ<EFBFBD><C5B5><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫͷָ<CDB7><D6B8><EFBFBD>ˡ<EFBFBD>
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD>֪ij<D6AA><C4B3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>λ<EFBFBD>ú<EFBFBD><C3BA><EFBFBD><EFBFBD>ܹ<EFBFBD><DCB9><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ҵ<EFBFBD><D2B5><EFBFBD><EFBFBD><EFBFBD>ֱ<EFBFBD><D6B1>ǰ<EFBFBD><C7B0><EFBFBD><EFBFBD>
|
||||
- <20><>C<EFBFBD><43><EFBFBD>ڽ<EFBFBD><DABD>в<EFBFBD><D0B2>롢ɾ<EBA1A2><C9BE><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʱ<EFBFBD><CAB1><EFBFBD>ܸ<EFBFBD><DCB8>õı<C3B5>֤<EFBFBD><D6A4><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ͽ<EFBFBD><CFBF><EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD>ӱ<EFBFBD><D3B1>е<EFBFBD><D0B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ɨ<EFBFBD>赽<EFBFBD><E8B5BD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
**19<31><39><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ַ<EFBFBD><D6B7><EFBFBD>P<EFBFBD><50>Q<EFBFBD><51><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Q<EFBFBD><51>P<EFBFBD><50><EFBFBD>Ӵ<EFBFBD><D3B4><EFBFBD><EFBFBD><EFBFBD>Q<EFBFBD><51>P<EFBFBD><50><EFBFBD>״γ<D7B4><CEB3>ֵ<EFBFBD>λ<EFBFBD><CEBB><EFBFBD><EFBFBD>Ϊ<EFBFBD>Ӵ<EFBFBD>Q<EFBFBD><51>P<EFBFBD><50>λ<EFBFBD>õ<EFBFBD><C3B5>㷨<EFBFBD><E3B7A8>Ϊ______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>B<EFBFBD><42>ƥ<EFBFBD><C6A5>
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD><EFBFBD>Ӵ<EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
**20<32><30>ij<EFBFBD><C4B3>ά<EFBFBD><CEAC><EFBFBD><EFBFBD>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD>±<EFBFBD><C2B1>ķ<EFBFBD>Χ<EFBFBD><CEA7>0<EFBFBD><30>8<EFBFBD><38><EFBFBD><EFBFBD><EFBFBD>±<EFBFBD><C2B1>ķ<EFBFBD>Χ<EFBFBD><CEA7>0<EFBFBD><30>4<EFBFBD><34><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>е<EFBFBD>Ԫ<EFBFBD><D4AA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ڵ<EFBFBD>4<EFBFBD><34><EFBFBD>ֽڴ洢<DAB4><E6B4A2><EFBFBD>洢<EFBFBD><E6B4A2><EFBFBD><EFBFBD><EFBFBD>ֽڱ<D6BD><DAB1>롣<EFBFBD><EBA1A3><EFBFBD><EFBFBD><EFBFBD>洢<EFBFBD><E6B4A2><EFBFBD><EFBFBD>Ԫ<EFBFBD><D4AA>A[0<><30>0]<5D>ĵ<EFBFBD>һ<EFBFBD><D2BB><EFBFBD>ֽڵĵ<DAB5>ַ<EFBFBD><D6B7>0<EFBFBD><30><EFBFBD><EFBFBD><EFBFBD>洢<EFBFBD><E6B4A2><EFBFBD><EFBFBD>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><D2BB>Ԫ<EFBFBD>ص<EFBFBD>һ<EFBFBD><D2BB><EFBFBD>ֽڵĵ<DAB5>ַ<EFBFBD><D6B7>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>175
|
||||
- <20><>B<EFBFBD><42>86
|
||||
- <20><>C<EFBFBD><43>68
|
||||
- <20><>D<EFBFBD><44>176
|
||||
|
||||
|
||||
|
||||
**21<32><31>______<5F>ǡ<EFBFBD>abcd321ABCD<43><44><EFBFBD><EFBFBD><EFBFBD>Ӵ<EFBFBD><D3B4><EFBFBD>**
|
||||
- <20><>A<EFBFBD><41>abcd
|
||||
- <20><>B<EFBFBD><42>321AB
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD>abcABC<42><43>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD>21AB<41><42>
|
||||
|
||||
|
||||
|
||||
**22<32><32><EFBFBD><EFBFBD>֪һ<D6AA>ö<EFBFBD><C3B6><EFBFBD><EFBFBD><EFBFBD>ǰ<EFBFBD><C7B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>зֱ<D0B7>ΪABDEGCFH<46><48>DBGEACHF<48><46><EFBFBD><EFBFBD><EFBFBD>ö<EFBFBD><C3B6><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĺ<EFBFBD><C4BA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>GEDHFBCA
|
||||
- <20><>B<EFBFBD><42>ACBFEDHG
|
||||
- <20><>C<EFBFBD><43>ABCDEFGH
|
||||
- <20><>D<EFBFBD><44>DGEBHFCA
|
||||
|
||||
**23<32><33><EFBFBD><EFBFBD>֪ij<D6AA><C4B3><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǰ<EFBFBD><C7B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ΪABDCE<43><45><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>п<EFBFBD><D0BF><EFBFBD><EFBFBD>ǶԸö<D4B8><C3B6><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>õ<EFBFBD><C3B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>BCADE
|
||||
- <20><>B<EFBFBD><42>CBADE
|
||||
- <20><>C<EFBFBD><43>BDAEC
|
||||
- <20><>D<EFBFBD><44>BEACD
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**24<32><34><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ĺ<EFBFBD><C4BA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>DABEC<45><43><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>DEBAC<41><43><EFBFBD><EFBFBD><EFBFBD>˶<EFBFBD><CBB6><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǰ<EFBFBD><C7B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>ACBED
|
||||
- <20><>B<EFBFBD><42>DECAB
|
||||
- <20><>C<EFBFBD><43>DEABC
|
||||
- <20><>D<EFBFBD><44>CEDBA
|
||||
|
||||
|
||||
|
||||
**25<32><35><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ķ<EFBFBD>Ϊ4<CEAA><34><EFBFBD><EFBFBD><EFBFBD>ж<EFBFBD>Ϊ1<CEAA><31>2<EFBFBD><32>3<EFBFBD><33>4<EFBFBD>Ľ<EFBFBD><C4BD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֱ<EFBFBD>Ϊ5<CEAA><35>3<EFBFBD><33>2<EFBFBD><32>1<EFBFBD><31><EFBFBD><EFBFBD>ô<EFBFBD><C3B4><EFBFBD><EFBFBD>Ҷ<EFBFBD>ӽ<EFBFBD><D3BD><EFBFBD><EFBFBD>ĸ<EFBFBD><C4B8><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>8
|
||||
- <20><>B<EFBFBD><42>10
|
||||
- <20><>C<EFBFBD><43>11
|
||||
- <20><>D<EFBFBD><44>12
|
||||
|
||||
|
||||
|
||||
**26<32><36><EFBFBD><EFBFBD><EFBFBD>漸<EFBFBD><E6BCB8><EFBFBD><EFBFBD><EFBFBD>Ŵ<EFBFBD><C5B4><EFBFBD><EFBFBD>뼯<EFBFBD><EBBCAF><EFBFBD>У<EFBFBD><D0A3><EFBFBD><EFBFBD><EFBFBD>ǰ<C7B0><D7BA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>{0<><30>10<31><30>110<31><30>1111}
|
||||
- <20><>B<EFBFBD><42>{11<31><31>10<31><30>001<30><31>101<30><31>0001}
|
||||
- <20><>C<EFBFBD><43>{00<30><30>010<31><30>0110<31><30>1000}
|
||||
- <20><>D<EFBFBD><44>{B<><42>C<EFBFBD><43>AA<41><41>AC<41><43>ABA<42><41>ABB<42><42>ABC}
|
||||
|
||||
|
||||
|
||||
**27<32><37><EFBFBD><EFBFBD><EFBFBD>Ļ<EFBFBD><C4BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Կ<EFBFBD><D4BF>Է<EFBFBD>Ϊǰ<CEAA><C7B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͺ<EFBFBD><CDBA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ļ<EFBFBD><C4BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Կɷ<D4BF>Ϊǰ<CEAA><C7B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><F2A1A2BA><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֱ<EFBFBD><D6B1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǰ<EFBFBD><C7B0><EFBFBD><EFBFBD><EFBFBD>ת<EFBFBD><D7AA><EFBFBD>õ<EFBFBD><C3B5>Ķ<EFBFBD><C4B6><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ<EFBFBD><CEAA><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD>Ķ<EFBFBD><C4B6><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ȷ<EFBFBD><C8B7><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǰ<EFBFBD><C7B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD>Ķ<EFBFBD><C4B6><EFBFBD><EFBFBD><EFBFBD>ǰ<EFBFBD><C7B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͬ
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD>ĺ<EFBFBD><C4BA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD>Ķ<EFBFBD><C4B6><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͬ
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǰ<EFBFBD><C7B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӧ<EFBFBD>Ķ<EFBFBD><C4B6><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͬ
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD>϶<EFBFBD><CFB6><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
**28<32><38>n<EFBFBD><6E><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϻ<EFBFBD><CFBA>е<EFBFBD><D0B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>2n
|
||||
- <20><>B<EFBFBD><42>n-1
|
||||
- <20><>C<EFBFBD><43>n+1
|
||||
- <20><>D<EFBFBD><44>n
|
||||
|
||||
|
||||
|
||||
**29<32><39><EFBFBD><EFBFBD><EFBFBD><EFBFBD>6<EFBFBD><36><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͼ<EFBFBD><CDBC><EFBFBD><EFBFBD>Ӧ<EFBFBD><D3A6>______<5F><5F><EFBFBD>߲<EFBFBD><DFB2><EFBFBD>ȷ<EFBFBD><C8B7><EFBFBD><EFBFBD>һ<EFBFBD><D2BB>ǿ<EFBFBD><C7BF>ͨͼ<CDA8><CDBC>**
|
||||
- <20><>A<EFBFBD><41>5
|
||||
- <20><>B<EFBFBD><42>6
|
||||
- <20><>C<EFBFBD><43>7
|
||||
- <20><>D<EFBFBD><44>8
|
||||
|
||||
|
||||
|
||||
**30<33><30>һ<EFBFBD><D2BB><EFBFBD><EFBFBD><EFBFBD><EFBFBD>n<EFBFBD><6E><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8><EFBFBD><EFBFBD>ͼ<EFBFBD><CDBC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F><EFBFBD>ߡ<EFBFBD>**
|
||||
- <20><>A<EFBFBD><41>n-1
|
||||
- <20><>B<EFBFBD><42>n
|
||||
- <20><>C<EFBFBD><43>n/2
|
||||
- <20><>D<EFBFBD><44>n+1
|
||||
|
||||
|
||||
|
||||
**31<33><31><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͼ<EFBFBD>Ľ<EFBFBD><C4BD><EFBFBD><EFBFBD><EFBFBD>Ϊn<CEAA><6E><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͼ<EFBFBD><CDBC><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F><EFBFBD>ߡ<EFBFBD>**
|
||||
- <20><>A<EFBFBD><41>n-1
|
||||
- <20><>B<EFBFBD><42>n(n-1)/2
|
||||
- <20><>C<EFBFBD><43>n(n+1)/2
|
||||
- <20><>D<EFBFBD><44>n*n
|
||||
|
||||
|
||||
|
||||
**32<33><32><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͼ<EFBFBD>Ľ<EFBFBD><C4BD><EFBFBD><EFBFBD><EFBFBD>Ϊn<CEAA><6E><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͼ<EFBFBD><CDBC><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F><EFBFBD>ߡ<EFBFBD>**
|
||||
- <20><>A<EFBFBD><41>n-1
|
||||
- <20><>B<EFBFBD><42>n(n-1)
|
||||
- <20><>C<EFBFBD><43>n(n-1)/2
|
||||
- <20><>D<EFBFBD><44>n*n
|
||||
|
||||
|
||||
|
||||
**33<33><33>һ<EFBFBD><D2BB><EFBFBD><EFBFBD>n<EFBFBD><6E><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͨͼ<CDA8><CDBC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ϊ______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>0
|
||||
- <20><>B<EFBFBD><42>1
|
||||
- <20><>C<EFBFBD><43>n
|
||||
- <20><>D<EFBFBD><44>n+1
|
||||
|
||||
|
||||
|
||||
**34<33><34>һ<EFBFBD><D2BB>ͼ<EFBFBD>а<EFBFBD><D0B0><EFBFBD>k<EFBFBD><6B><EFBFBD><EFBFBD>ͨ<EFBFBD><CDA8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>н<EFBFBD><D0BD>㣬<EFBFBD><E3A3AC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD><E3B7A8>**
|
||||
- <20><>A<EFBFBD><41>k
|
||||
- <20><>B<EFBFBD><42>1
|
||||
- <20><>C<EFBFBD><43>k-1
|
||||
- <20><>D<EFBFBD><44>k+1
|
||||
|
||||
|
||||
|
||||
**35<33><35><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ͼG<CDBC><47><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>У<EFBFBD><D0A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>$v_i$<24><>$v_j$֮ǰ<D6AE><C7B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ܳ<EFBFBD><DCB3>ֵ<EFBFBD><D6B5><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>G<EFBFBD><47><EFBFBD>л<EFBFBD> $< v_i,v_j>$
|
||||
- <20><>B<EFBFBD><42>G<EFBFBD><47><EFBFBD><EFBFBD>һ<EFBFBD><D2BB>$v_i$<24><>$v_j$<24><>·<EFBFBD><C2B7>
|
||||
- <20><>C<EFBFBD><43>G<EFBFBD><47>û<EFBFBD>л<EFBFBD>$< v_i,v_j>$
|
||||
- <20><>D<EFBFBD><44>G<EFBFBD><47><EFBFBD><EFBFBD>һ<EFBFBD><D2BB>$v_j$<24><>$v_i$<24><>·<EFBFBD><C2B7>
|
||||
|
||||
|
||||
|
||||
**36<33><36><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD><D2BB><EFBFBD><EFBFBD><EFBFBD>õ<EFBFBD><C3B5><EFBFBD><EFBFBD>ݽṹ<DDBD><E1B9B9><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ؼ<EFBFBD><D8BC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>һ<EFBFBD><D2BB><EFBFBD>ѡ<EFBFBD>**
|
||||
- <20><>A<EFBFBD><41>16<31><36>72<37><32>31<33><31>23<32><33>94<39><34>53
|
||||
- <20><>B<EFBFBD><42>94<39><34>53<35><33>31<33><31>72<37><32>16<31><36>53
|
||||
- <20><>C<EFBFBD><43>16<31><36>53<35><33>23<32><33>94<39><34>31<33><31>72
|
||||
- <20><>D<EFBFBD><44>16<31><36>31<33><31>23<32><33>94<39><34>53<35><33>72
|
||||
|
||||
|
||||
|
||||
**37<33><37><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>в<EFBFBD><D0B2>Ƕѵ<C7B6><D1B5><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>100<30><30>85<38><35>98<39><38>77<37><37>80<38><30>60<36><30>82<38><32>40<34><30>20<32><30>10<31><30>66
|
||||
- <20><>B<EFBFBD><42>100<30><30>98<39><38>85<38><35>82<38><32>80<38><30>77<37><37>66<36><36>60<36><30>40<34><30>20<32><30>10
|
||||
- <20><>C<EFBFBD><43>10<31><30>20<32><30>40<34><30>60<36><30>66<36><36>77<37><37>80<38><30>82<38><32>85<38><35>98<39><38>100
|
||||
- <20><>D<EFBFBD><44>100<30><30>85<38><35>40<34><30>77<37><37>80<38><30>60<36><30>66<36><36>98<39><38>82<38><32>10<31><30>20
|
||||
|
||||
|
||||
|
||||
**38<33><38><EFBFBD>Թؼ<D4B9><D8BC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>{72<37><32>73<37><33>71<37><31>23<32><33>94<39><34>16<31><36>5<EFBFBD><35>68<36><38>76<37><36>103}<7D><><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ѣ<EFBFBD><D1A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ӽ<EFBFBD>ֵΪ______<5F>Ľ<EFBFBD><C4BD>㿪ʼ<E3BFAA><CABC>**
|
||||
- <20><>A<EFBFBD><41>103
|
||||
- <20><>B<EFBFBD><42>72
|
||||
- <20><>C<EFBFBD><43>94
|
||||
- <20><>D<EFBFBD><44>23
|
||||
|
||||
|
||||
|
||||
|
||||
**39<33><39><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD><E3B7A8><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ƚ<EFBFBD><C8BD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>¼<EFBFBD><EFBFBD><EEA3AC><EFBFBD><EFBFBD>Щ<EFBFBD><D0A9><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫ<EFBFBD><EFBFBD><F3B2BBB7>ļ<EFBFBD>¼<EFBFBD><C2BC><EFBFBD><EFBFBD>λ<EFBFBD>ã<EFBFBD>ֱ<EFBFBD><D6B1><EFBFBD>ź<EFBFBD><C5BA><EFBFBD>Ϊֹ<CEAA><D6B9><EFBFBD><EFBFBD><EFBFBD><EFBFBD><F2B7BDB7><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>C<EFBFBD><43>ѡ<EFBFBD><D1A1><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
**40<34><30><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD>аѵ<D0B0>i<EFBFBD><69><EFBFBD><EFBFBD>¼<EFBFBD><C2BC><EFBFBD>뵽ǰ<EBB5BD><C7B0><EFBFBD><EFBFBD><EFBFBD>źõļ<C3B5>¼<EFBFBD>У<EFBFBD>ʹ<EFBFBD><CAB9><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ǰi<C7B0><69><EFBFBD><EFBFBD>¼<EFBFBD><C2BC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ҫ<EFBFBD><D2AA><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><F2B7BDB7><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>C<EFBFBD><43>ѡ<EFBFBD><D1A1><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
**41<34><31><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>㷨<EFBFBD><E3B7A8>ÿ<EFBFBD>δ<EFBFBD>ȫ<EFBFBD><C8AB><EFBFBD><EFBFBD>δ<EFBFBD><CEB4><EFBFBD><EFBFBD><EFBFBD>ļ<EFBFBD>¼<EFBFBD><C2BC><EFBFBD><EFBFBD>ѡ<EFBFBD><D1A1><EFBFBD><EFBFBD>С<EFBFBD><D0A1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ļ<EFBFBD>¼<EFBFBD><EFBFBD><EEA3AC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>źõļ<C3B5>¼<EFBFBD><C2BC>ĩβ<C4A9><CEB2><EFBFBD><EFBFBD><EFBFBD><EFBFBD><F2B7BDB7><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>C<EFBFBD><43>ѡ<EFBFBD><D1A1><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
**42<34><32><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>У<EFBFBD>______<5F>ſ<EFBFBD><C5BF><EFBFBD><EFBFBD><EFBFBD>ִ<EFBFBD>е<EFBFBD>һ<EFBFBD>˿<EFBFBD><CBBF><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>õ<EFBFBD><C3B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD>С<EFBFBD>**
|
||||
- <20><>A<EFBFBD><41>{8<><38>6<EFBFBD><36>18} 19 {16<31><36>10<31><30>50}
|
||||
- <20><>B<EFBFBD><42>{6<><36>4<EFBFBD><34>8} 18 {81<38><31>19<31><39>36<33><36>18}
|
||||
- <20><>C<EFBFBD><43>{81<38><31>1<EFBFBD><31>2} 36 {99<39><39>81<38><31>69}
|
||||
- <20><>D<EFBFBD><44>{2<><32>3<EFBFBD><33>4} 89 {78<37><38>98<39><38>68}
|
||||
|
||||
|
||||
|
||||
**43<34><33><EFBFBD><EFBFBD><EFBFBD><EFBFBD>8<EFBFBD><38>Ԫ<EFBFBD>ص<EFBFBD><D8B5><EFBFBD><EFBFBD><EFBFBD>{49<34><39>38<33><38>65<36><35>97<39><37>76<37><36>13<31><33>27<32><37>50}<7D><><EFBFBD><EFBFBD>С<EFBFBD><D0A1><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ֱ<EFBFBD><D6B1>ѡ<EFBFBD><D1A1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD>˵<EFBFBD><CBB5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>13<31><33>38<33><38>65<36><35>97<39><37>76<37><36>49<34><39>27<32><37>50
|
||||
- <20><>B<EFBFBD><42>13<31><33>27<32><37>38<33><38>49<34><39>50<35><30>65<36><35>76<37><36>97
|
||||
- <20><>C<EFBFBD><43>97<39><37>76<37><36>65<36><35>50<35><30>49<34><39>38<33><38>27<32><37>13
|
||||
- <20><>D<EFBFBD><44>13<31><33>38<33><38>65<36><35>50<35><30>76<37><36>49<34><39>27<32><37>97
|
||||
|
||||
|
||||
|
||||
**44<34><34><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>{72<37><32>73<37><33>71<37><31>23<32><33>94<39><34>16<31><36>5<EFBFBD><35>68<36><38>76<37><36>103}<7D><><EFBFBD>չ<EFBFBD><D5B9><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ѵķ<D1B5>ʽ<EFBFBD><CABD>С<EFBFBD><D0A1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><F2A3ACB6><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD>˵<EFBFBD><CBB5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
|
||||
- <20><>A<EFBFBD><41>103<30><33>94<39><34>71<37><31>76<37><36>73<37><33>16<31><36>5<EFBFBD><35>68<36><38>23<32><33>72
|
||||
- <20><>B<EFBFBD><42>72<37><32>94<39><34>71<37><31>76<37><36>73<37><33>16<31><36>5<EFBFBD><35>68<36><38>23<32><33>103
|
||||
- <20><>C<EFBFBD><43>94<39><34>76<37><36>71<37><31>72<37><32>73<37><33>16<31><36>5<EFBFBD><35>68<36><38>23<32><33>103
|
||||
- <20><>D<EFBFBD><44>23<32><33>76<37><36>71<37><31>72<37><32>73<37><33>16<31><36>5<EFBFBD><35>68<36><38>94<39><34>103
|
||||
|
||||
**45<34><35><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>{72<37><32>73<37><33>71<37><31>23<32><33>94<39><34>16<31><36>5<EFBFBD><35>68<36><38>76<37><36>103}<7D><><EFBFBD><EFBFBD>delta=5<><35>С<EFBFBD><D0A1><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ϣ<EFBFBD><CFA3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>һ<EFBFBD>˵<EFBFBD><CBB5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
|
||||
- <20><>A<EFBFBD><41>103<30><33>94<39><34>71<37><31>76<37><36>73<37><33>16<31><36>5<EFBFBD><35>68<36><38>23<32><33>72
|
||||
- <20><>B<EFBFBD><42>16<31><36>5<EFBFBD><35>68<36><38>23<32><33>73<37><33>71<37><31>76<37><36>72<37><32>94<39><34>103
|
||||
- <20><>C<EFBFBD><43>16<31><36>71<37><31>68<36><38>23<32><33>94<39><34>72<37><32>73<37><33>5<EFBFBD><35>76<37><36>103
|
||||
- <20><>D<EFBFBD><44>16<31><36>5<EFBFBD><35>68<36><38>23<32><33>94<39><34>72<37><32>73<37><33>71<37><31>76<37><36>103
|
||||
|
||||
|
||||
|
||||
|
||||
**46<34><36><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD><D4B1><EFBFBD><EFBFBD>ж<EFBFBD><D0B6>ֲ<EFBFBD><D6B2><EFBFBD>ʱ<EFBFBD><CAB1>Ҫ<EFBFBD><D2AA><EFBFBD><EFBFBD><EFBFBD>Ա<EFBFBD><D4B1><EFBFBD><EFBFBD><EFBFBD>______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD><EFBFBD>ʽ<EFBFBD>洢
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʽ<EFBFBD><CABD>ʽ<EFBFBD>洢
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD><EFBFBD>ʽ<EFBFBD>洢<EFBFBD>ҽ<EFBFBD><D2BD>㰴<EFBFBD>ؼ<EFBFBD><D8BC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD><EFBFBD>ʽ<EFBFBD><CABD>ʽ<EFBFBD>洢<EFBFBD>ҽ<EFBFBD><D2BD>㰴<EFBFBD>ؼ<EFBFBD><D8BC><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
|
||||
|
||||
|
||||
**47<34><37><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD><EFBFBD>{3<><33>6<EFBFBD><36>8<EFBFBD><38>10<31><30>12<31><32>15<31><35>16<31><36>18<31><38>21<32><31>25<32><35>30}<7D>У<EFBFBD><D0A3>ö<EFBFBD><C3B6>ַ<EFBFBD><D6B7><EFBFBD><EFBFBD>ҹؼ<D2B9><D8BC><EFBFBD>11<31><31><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ĺؼ<C4B9><D8BC><EFBFBD><EFBFBD>Ƚϴ<C8BD><CFB4><EFBFBD>Ϊ______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>2
|
||||
- <20><>B<EFBFBD><42>3
|
||||
- <20><>C<EFBFBD><43>4
|
||||
- <20><>D<EFBFBD><44>5
|
||||
|
||||
|
||||
|
||||
**48<34><38><EFBFBD><EFBFBD>˳<EFBFBD><CBB3><EFBFBD><EFBFBD>{2<><32>5<EFBFBD><35>7<EFBFBD><37>10<31><30>14<31><34>15<31><35>18<31><38>23<32><33>35<33><35>41<34><31>52}<7D>У<EFBFBD><D0A3>ö<EFBFBD><C3B6>ַ<EFBFBD><D6B7><EFBFBD><EFBFBD>ҹؼ<D2B9><D8BC><EFBFBD>18<31><38><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Ĺؼ<C4B9><D8BC><EFBFBD><EFBFBD>Ƚϴ<C8BD><CFB4><EFBFBD>Ϊ______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>2
|
||||
- <20><>B<EFBFBD><42>3
|
||||
- <20><>C<EFBFBD><43>4
|
||||
- <20><>D<EFBFBD><44>5
|
||||
|
||||
|
||||
|
||||
**49<34><39><EFBFBD><EFBFBD><EFBFBD><EFBFBD>19<31><39>Ԫ<EFBFBD>ص<EFBFBD><D8B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>¼<EFBFBD><C2BC><EFBFBD><EFBFBD>Record<72><64><EFBFBD>ö<EFBFBD><C3B6>ֲ<EFBFBD><D6B2>ң<EFBFBD><D2A3><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Key=Record[3]<5D>ıȽ<C4B1><C8BD><EFBFBD><EFBFBD>е<EFBFBD><D0B5>±꣨<C2B1>±<EFBFBD><C2B1><EFBFBD>0<EFBFBD><30>ʼ<EFBFBD><CABC>Ϊ______<5F><5F>**
|
||||
- <20><>A<EFBFBD><41>9<EFBFBD><39>5<EFBFBD><35>3
|
||||
- <20><>B<EFBFBD><42>9<EFBFBD><39>5<EFBFBD><35>2<EFBFBD><32>3
|
||||
- <20><>C<EFBFBD><43>9<EFBFBD><39>4<EFBFBD><34>2<EFBFBD><32>3
|
||||
- <20><>D<EFBFBD><44>9<EFBFBD><39>4<EFBFBD><34>1<EFBFBD><31>2<EFBFBD><32>3
|
||||
|
||||
|
||||
|
||||
**50<35><30><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>______<5F><5F><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>Եõ<D4B5><C3B5><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>С<EFBFBD>**
|
||||
- <20><>A<EFBFBD><41>ǰ<EFBFBD><C7B0><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>B<EFBFBD><42><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>C<EFBFBD><43><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD><EFBFBD>
|
||||
- <20><>D<EFBFBD><44><EFBFBD><EFBFBD><EFBFBD>α<EFBFBD><CEB1><EFBFBD>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
396
IntroductionToNumpy/Task06 输入输出.md
Normal file
396
IntroductionToNumpy/Task06 输入输出.md
Normal file
@@ -0,0 +1,396 @@
|
||||
# 输入和输出
|
||||
|
||||
|
||||
|
||||
## 1. numpy 二进制文件
|
||||
|
||||
`save()`、`savez()`和`load()`函数以 numpy 专用的二进制类型(`.npy`、`.npz`)保存和读取数据,这三个函数会自动处理ndim、dtype、shape等信息,使用它们读写数组非常方便,但是`save()`和`savez()`输出的文件很难与其它语言编写的程序兼容。
|
||||
|
||||
|
||||
|
||||
|
||||
【函数】
|
||||
```python
|
||||
def save(file, arr, allow_pickle=True, fix_imports=True):
|
||||
```
|
||||
- `save()`函数:以`.npy`格式将数组保存到二进制文件中。
|
||||
- `.npy`格式:以二进制的方式存储文件,在二进制文件第一行以文本形式保存了数据的元信息(ndim,dtype,shape等),可以用二进制工具查看内容。
|
||||
|
||||
|
||||
|
||||
【函数】
|
||||
```python
|
||||
def load(file, mmap_mode=None, allow_pickle=False, fix_imports=True, encoding='ASCII'):
|
||||
```
|
||||
|
||||
- `load()`函数:从`.npy`、`.npz`或 pickled文件加载数组或pickled对象。
|
||||
- `mmap_mode: {None, ‘r+’, ‘r’, ‘w+’, ‘c’};`:读取文件的方式。
|
||||
- `allow_pickle=False`:允许加载存储在`.npy`文件中的pickled对象数组。
|
||||
- `fix_imports=True`:若为True,pickle将尝试将旧的python2名称映射到python3中使用的新名称。
|
||||
- `encoding='ASCII'`:制定编码格式,默认为“ASCII”。
|
||||
|
||||
|
||||
【例子】将一个数组保存到一个文件中。
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
outfile = r'.\test.npy'
|
||||
np.random.seed(20200619)
|
||||
x = np.random.uniform(low=0, high=1,size = [3, 5])
|
||||
np.save(outfile, x)
|
||||
y = np.load(outfile)
|
||||
print(y)
|
||||
# [[0.01123594 0.66790705 0.50212171 0.7230908 0.61668256]
|
||||
# [0.00668332 0.1234096 0.96092409 0.67925305 0.38596837]
|
||||
# [0.72342998 0.26258324 0.24318845 0.98795012 0.77370715]]
|
||||
```
|
||||
|
||||
【函数】
|
||||
```python
|
||||
def savez(file, *args, **kwds):
|
||||
```
|
||||
|
||||
- `savez()`函数:以未压缩的`.npz`格式将多个数组保存到单个文件中。
|
||||
- `.npz`格式:以压缩打包的方式存储文件,可以用压缩软件解压。
|
||||
- `savez()`函数:第一个参数是文件名,其后的参数都是需要保存的数组,也可以使用关键字参数为数组起一个名字,非关键字参数传递的数组会自动起名为`arr_0, arr_1, …`。
|
||||
- `savez()`函数:输出的是一个压缩文件(扩展名为`.npz`),其中每个文件都是一个`save()`保存的`.npy`文件,文件名对应于数组名。`load()`自动识别`.npz`文件,并且返回一个类似于字典的对象,可以通过数组名作为关键字获取数组的内容。
|
||||
|
||||
【例子】将多个数组保存到一个文件。
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
outfile = r'.\test.npz'
|
||||
x = np.linspace(0, np.pi, 5)
|
||||
y = np.sin(x)
|
||||
z = np.cos(x)
|
||||
np.savez(outfile, x, y, z_d=z)
|
||||
data = np.load(outfile)
|
||||
np.set_printoptions(suppress=True)
|
||||
print(data.files)
|
||||
# ['z_d', 'arr_0', 'arr_1']
|
||||
|
||||
print(data['arr_0'])
|
||||
# [0. 0.78539816 1.57079633 2.35619449 3.14159265]
|
||||
|
||||
print(data['arr_1'])
|
||||
# [0. 0.70710678 1. 0.70710678 0. ]
|
||||
|
||||
print(data['z_d'])
|
||||
# [ 1. 0.70710678 0. -0.70710678 -1. ]
|
||||
```
|
||||
|
||||
用解压软件打开 test.npz 文件,会发现其中有三个文件:`arr_0.npy,arr_1.npy,z_d.npy`,其中分别保存着数组`x,y,z`的内容。
|
||||
|
||||
|
||||
---
|
||||
## 2. 文本文件
|
||||
`savetxt()`,`loadtxt()`和`genfromtxt()`函数用来存储和读取文本文件(如`.TXT`,`.CSV`等)。`genfromtxt()`比`loadtxt()`更加强大,可对缺失数据进行处理。
|
||||
|
||||
|
||||
【函数】
|
||||
```python
|
||||
def savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n',header='', footer='', comments='# ', encoding=None):
|
||||
```
|
||||
- `fname`:文件路径
|
||||
- `X`:存入文件的数组。
|
||||
- `fmt='%.18e'`:写入文件中每个元素的字符串格式,默认'%.18e'(保留18位小数的浮点数形式)。
|
||||
- `delimiter=' '`:分割字符串,默认以空格分隔。
|
||||
|
||||
```python
|
||||
def loadtxt(fname, dtype=float, comments='#', delimiter=None,
|
||||
converters=None, skiprows=0, usecols=None, unpack=False,
|
||||
ndmin=0, encoding='bytes', max_rows=None):
|
||||
```
|
||||
- `fname`:文件路径。
|
||||
- `dtype=float`:数据类型,默认为float。
|
||||
- `comments='#'`: 字符串或字符串组成的列表,默认为'#',表示注释字符集开始的标志。
|
||||
- `skiprows=0`:跳过多少行,一般跳过第一行表头。
|
||||
- `usecols=None`:元组(元组内数据为列的数值索引), 用来指定要读取数据的列(第一列为0)。
|
||||
- `unpack=False`:当加载多列数据时是否需要将数据列进行解耦赋值给不同的变量。
|
||||
|
||||
|
||||
【例】写入和读出TXT文件。
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
outfile = r'.\test.txt'
|
||||
x = np.arange(0, 10).reshape(2, -1)
|
||||
np.savetxt(outfile, x)
|
||||
y = np.loadtxt(outfile)
|
||||
print(y)
|
||||
# [[0. 1. 2. 3. 4.]
|
||||
# [5. 6. 7. 8. 9.]]
|
||||
```
|
||||
|
||||
test.txt文件如下:
|
||||
|
||||
```python
|
||||
0.000000000000000000e+00 1.000000000000000000e+00 2.000000000000000000e+00 3.000000000000000000e+00 4.000000000000000000e+00
|
||||
5.000000000000000000e+00 6.000000000000000000e+00 7.000000000000000000e+00 8.000000000000000000e+00 9.000000000000000000e+00
|
||||
```
|
||||
|
||||
|
||||
【例子】写入和读出CSV文件。
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
outfile = r'.\test.csv'
|
||||
x = np.arange(0, 10, 0.5).reshape(4, -1)
|
||||
np.savetxt(outfile, x, fmt='%.3f', delimiter=',')
|
||||
y = np.loadtxt(outfile, delimiter=',')
|
||||
print(y)
|
||||
# [[0. 0.5 1. 1.5 2. ]
|
||||
# [2.5 3. 3.5 4. 4.5]
|
||||
# [5. 5.5 6. 6.5 7. ]
|
||||
# [7.5 8. 8.5 9. 9.5]]
|
||||
```
|
||||
|
||||
test.csv文件如下:
|
||||
```python
|
||||
0.000,0.500,1.000,1.500,2.000
|
||||
2.500,3.000,3.500,4.000,4.500
|
||||
5.000,5.500,6.000,6.500,7.000
|
||||
7.500,8.000,8.500,9.000,9.500
|
||||
```
|
||||
|
||||
|
||||
|
||||
【函数】
|
||||
|
||||
```python
|
||||
def genfromtxt(fname, dtype=float, comments='#', delimiter=None,
|
||||
skip_header=0, skip_footer=0, converters=None,
|
||||
missing_values=None, filling_values=None, usecols=None,
|
||||
names=None, excludelist=None,
|
||||
deletechars=''.join(sorted(NameValidator.defaultdeletechars)),
|
||||
replace_space='_', autostrip=False, case_sensitive=True,
|
||||
defaultfmt="f%i", unpack=None, usemask=False, loose=True,
|
||||
invalid_raise=True, max_rows=None, encoding='bytes'):
|
||||
```
|
||||
- `genfromtxt()`函数:从文本文件加载数据,并按指定方式处理缺少的值(是面向结构数组和缺失数据处理的。)。
|
||||
- `names=None`:设置为True时,程序将把第一行作为列名称。
|
||||
|
||||
|
||||
data.csv文件(不带缺失值)
|
||||
```python
|
||||
id,value1,value2,value3
|
||||
1,123,1.4,23
|
||||
2,110,0.5,18
|
||||
3,164,2.1,19
|
||||
```
|
||||
|
||||
【例子】
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
outfile = r'.\data.csv'
|
||||
x = np.loadtxt(outfile, delimiter=',', skiprows=1)
|
||||
print(x)
|
||||
# [[ 1. 123. 1.4 23. ]
|
||||
# [ 2. 110. 0.5 18. ]
|
||||
# [ 3. 164. 2.1 19. ]]
|
||||
|
||||
x = np.loadtxt(outfile, delimiter=',', skiprows=1, usecols=(1, 2))
|
||||
print(x)
|
||||
# [[123. 1.4]
|
||||
# [110. 0.5]
|
||||
# [164. 2.1]]
|
||||
|
||||
val1, val2 = np.loadtxt(outfile, delimiter=',', skiprows=1, usecols=(1, 2), unpack=True)
|
||||
print(val1) # [123. 110. 164.]
|
||||
print(val2) # [1.4 0.5 2.1]
|
||||
```
|
||||
|
||||
|
||||
【例子】
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
outfile = r'.\data.csv'
|
||||
x = np.genfromtxt(outfile, delimiter=',', names=True)
|
||||
print(x)
|
||||
# [(1., 123., 1.4, 23.) (2., 110., 0.5, 18.) (3., 164., 2.1, 19.)]
|
||||
|
||||
print(type(x))
|
||||
# <class 'numpy.ndarray'>
|
||||
|
||||
print(x.dtype)
|
||||
# [('id', '<f8'), ('value1', '<f8'), ('value2', '<f8'), ('value3', '<f8')]
|
||||
|
||||
print(x['id']) # [1. 2. 3.]
|
||||
print(x['value1']) # [123. 110. 164.]
|
||||
print(x['value2']) # [1.4 0.5 2.1]
|
||||
print(x['value3']) # [23. 18. 19.]
|
||||
```
|
||||
|
||||
data1.csv文件(带有缺失值)
|
||||
```python
|
||||
id,value1,value2,value3
|
||||
1,123,1.4,23
|
||||
2,110,,18
|
||||
3,,2.1,19
|
||||
```
|
||||
|
||||
【例子】
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
outfile = r'.\data1.csv'
|
||||
x = np.genfromtxt(outfile, delimiter=',', names=True)
|
||||
print(x)
|
||||
# [(1., 123., 1.4, 23.) (2., 110., nan, 18.) (3., nan, 2.1, 19.)]
|
||||
|
||||
print(type(x))
|
||||
# <class 'numpy.ndarray'>
|
||||
|
||||
print(x.dtype)
|
||||
# [('id', '<f8'), ('value1', '<f8'), ('value2', '<f8'), ('value3', '<f8')]
|
||||
|
||||
print(x['id']) # [1. 2. 3.]
|
||||
print(x['value1']) # [123. 110. nan]
|
||||
print(x['value2']) # [1.4 nan 2.1]
|
||||
print(x['value3']) # [23. 18. 19.]
|
||||
```
|
||||
|
||||
---
|
||||
## 3. 文本格式选项
|
||||
|
||||
【函数】
|
||||
```python
|
||||
def set_printoptions(precision=None, threshold=None, edgeitems=None,
|
||||
linewidth=None, suppress=None, nanstr=None, infstr=None,
|
||||
formatter=None, sign=None, floatmode=None, **kwarg):
|
||||
```
|
||||
- `set_printoptions()`函数:设置打印选项。这些选项决定浮点数、数组和其它NumPy对象的显示方式。
|
||||
- `precision=8`:设置浮点精度,控制输出的小数点个数,默认是8。
|
||||
- `threshold=1000`:概略显示,超过该值则以“…”的形式来表示,默认是1000。
|
||||
- `linewidth=75`:用于确定每行多少字符数后插入换行符,默认为75。
|
||||
- `suppress=False`:当`suppress=True`,表示小数不需要以科学计数法的形式输出,默认是False。
|
||||
- `nanstr=nan`:浮点非数字的字符串表示形式,默认`nan`。
|
||||
- `infstr=inf`:浮点无穷大的字符串表示形式,默认`inf`。
|
||||
- `formatter`:一个字典,自定义格式化用于显示的数组元素。键为需要格式化的类型,值为格式化的字符串。
|
||||
- 'bool'
|
||||
- 'int'
|
||||
- 'float'
|
||||
- 'str' : all other strings
|
||||
- 'all' : sets all types
|
||||
- ...
|
||||
|
||||
【例子】
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
np.set_printoptions(precision=4)
|
||||
x = np.array([1.123456789])
|
||||
print(x) # [1.1235]
|
||||
|
||||
np.set_printoptions(threshold=20)
|
||||
x = np.arange(50)
|
||||
print(x) # [ 0 1 2 ... 47 48 49]
|
||||
|
||||
np.set_printoptions(threshold=np.iinfo(np.int).max)
|
||||
print(x)
|
||||
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
|
||||
# 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
|
||||
# 48 49]
|
||||
|
||||
eps = np.finfo(float).eps
|
||||
x = np.arange(4.)
|
||||
x = x ** 2 - (x + eps) ** 2
|
||||
print(x)
|
||||
# [-4.9304e-32 -4.4409e-16 0.0000e+00 0.0000e+00]
|
||||
np.set_printoptions(suppress=True)
|
||||
print(x) # [-0. -0. 0. 0.]
|
||||
|
||||
x = np.linspace(0, 10, 10)
|
||||
print(x)
|
||||
# [ 0. 1.1111 2.2222 3.3333 4.4444 5.5556 6.6667 7.7778 8.8889
|
||||
# 10. ]
|
||||
np.set_printoptions(precision=2, suppress=True, threshold=5)
|
||||
print(x) # [ 0. 1.11 2.22 ... 7.78 8.89 10. ]
|
||||
|
||||
np.set_printoptions(formatter={'all': lambda x: 'int: ' + str(-x)})
|
||||
x = np.arange(3)
|
||||
print(x) # [int: 0 int: -1 int: -2]
|
||||
|
||||
np.set_printoptions() # formatter gets reset
|
||||
print(x) # [0 1 2]
|
||||
```
|
||||
|
||||
【例子】恢复默认选项
|
||||
|
||||
```python
|
||||
np.set_printoptions(edgeitems=3, infstr='inf', linewidth=75,
|
||||
nanstr='nan', precision=8, suppress=False,
|
||||
threshold=1000, formatter=None)
|
||||
```
|
||||
|
||||
|
||||
【函数】
|
||||
|
||||
```python
|
||||
def get_printoptions():
|
||||
```
|
||||
|
||||
- `get_printoptions()`函数:获取当前打印选项。
|
||||
|
||||
【例子】
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
x = np.get_printoptions()
|
||||
print(x)
|
||||
# {
|
||||
# 'edgeitems': 3,
|
||||
# 'threshold': 1000,
|
||||
# 'floatmode': 'maxprec',
|
||||
# 'precision': 8,
|
||||
# 'suppress': False,
|
||||
# 'linewidth': 75,
|
||||
# 'nanstr': 'nan',
|
||||
# 'infstr': 'inf',
|
||||
# 'sign': '-',
|
||||
# 'formatter': None,
|
||||
# 'legacy': False
|
||||
# }
|
||||
```
|
||||
|
||||
---
|
||||
## 4. 练习
|
||||
|
||||
**(1)只打印或显示numpy数组rand_arr的小数点后3位。**
|
||||
|
||||
【知识点:输入和输出】
|
||||
- 如何在numpy数组中只打印小数点后三位?
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
np.random.seed(2002)
|
||||
rand_arr = np.random.random([5,3])
|
||||
```
|
||||
|
||||
**(2)将numpy数组a中打印的项数限制为最多6个元素。**
|
||||
|
||||
【知识点:输入和输出】
|
||||
- 如何限制numpy数组输出中打印的项目数?
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
a = np.arange(15)
|
||||
```
|
||||
|
||||
**(3)打印完整的numpy数组a而不中断。**
|
||||
|
||||
【知识点:输入和输出】
|
||||
|
||||
- 如何打印完整的numpy数组而不中断?
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
a = np.arange(15)
|
||||
np.set_printoptions(threshold=6)
|
||||
print(a)
|
||||
```
|
||||
164
IntroductionToNumpy/Task10 大作业.md
Normal file
164
IntroductionToNumpy/Task10 大作业.md
Normal file
@@ -0,0 +1,164 @@
|
||||
# 大作业
|
||||
|
||||
本次练习使用 鸢尾属植物数据集`.\iris.data`,在这个数据集中,包括了三类不同的鸢尾属植物:Iris Setosa,Iris Versicolour,Iris Virginica。每类收集了50个样本,因此这个数据集一共包含了150个样本。
|
||||
|
||||
- sepallength:萼片长度
|
||||
- sepalwidth:萼片宽度
|
||||
- petallength:花瓣长度
|
||||
- petalwidth:花瓣宽度
|
||||
|
||||
以上四个特征的单位都是厘米(cm)。
|
||||
|
||||
```python
|
||||
sepallength sepalwidth petallength petalwidth species
|
||||
0 5.1 3.5 1.4 0.2 Iris-setosa
|
||||
1 4.9 3.0 1.4 0.2 Iris-setosa
|
||||
2 4.7 3.2 1.3 0.2 Iris-setosa
|
||||
3 4.6 3.1 1.5 0.2 Iris-setosa
|
||||
4 5.0 3.6 1.4 0.2 Iris-setosa
|
||||
.. ... ... ... ... ...
|
||||
145 6.7 3.0 5.2 2.3 Iris-virginica
|
||||
146 6.3 2.5 5.0 1.9 Iris-virginica
|
||||
147 6.5 3.0 5.2 2.0 Iris-virginica
|
||||
148 6.2 3.4 5.4 2.3 Iris-virginica
|
||||
149 5.9 3.0 5.1 1.8 Iris-virginica
|
||||
|
||||
[150 rows x 5 columns]
|
||||
```
|
||||
|
||||
|
||||
|
||||
**1. 导入鸢尾属植物数据集,保持文本不变。**
|
||||
|
||||
【知识点:输入和输出】
|
||||
- 如何导入存在数字和文本的数据集?
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**2. 求出鸢尾属植物萼片长度的平均值、中位数和标准差(第1列,sepallength)**
|
||||
|
||||
【知识点:统计相关】
|
||||
- 如何计算numpy数组的均值,中位数,标准差?
|
||||
|
||||
|
||||
|
||||
**3. 创建一种标准化形式的鸢尾属植物萼片长度,其值正好介于0和1之间,这样最小值为0,最大值为1(第1列,sepallength)。**
|
||||
|
||||
【知识点:统计相关】
|
||||
- 如何标准化数组?
|
||||
|
||||
|
||||
**4. 找到鸢尾属植物萼片长度的第5和第95百分位数(第1列,sepallength)。**
|
||||
|
||||
【知识点:统计相关】
|
||||
- 如何找到numpy数组的百分位数?
|
||||
|
||||
|
||||
|
||||
|
||||
**5. 把iris_data数据集中的20个随机位置修改为np.nan值。**
|
||||
|
||||
【知识点:随机抽样】
|
||||
- 如何在数组中的随机位置修改值?
|
||||
|
||||
|
||||
|
||||
**6. 在iris_data的sepallength中查找缺失值的个数和位置(第1列)。**
|
||||
|
||||
【知识点:逻辑函数、搜索】
|
||||
- 如何在numpy数组中找到缺失值的位置?
|
||||
|
||||
|
||||
**7. 筛选具有 sepallength(第1列)< 5.0 并且 petallength(第3列)> 1.5 的 iris_data行。**
|
||||
|
||||
【知识点:搜索】
|
||||
- 如何根据两个或多个条件筛选numpy数组?
|
||||
|
||||
|
||||
|
||||
**8. 选择没有任何 nan 值的 iris_data行。**
|
||||
|
||||
【知识点:逻辑函数、搜索】
|
||||
- 如何从numpy数组中删除包含缺失值的行?
|
||||
|
||||
|
||||
|
||||
|
||||
**9. 计算 iris_data 中sepalLength(第1列)和petalLength(第3列)之间的相关系数。**
|
||||
|
||||
【知识点:统计相关】
|
||||
- 如何计算numpy数组两列之间的相关系数?
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**10. 找出iris_data是否有任何缺失值。**
|
||||
|
||||
【知识点:逻辑函数】
|
||||
- 如何查找给定数组是否具有空值?
|
||||
|
||||
|
||||
|
||||
|
||||
**11. 在numpy数组中将所有出现的nan替换为0。**
|
||||
|
||||
【知识点:逻辑函数】
|
||||
- 如何在numpy数组中用0替换所有缺失值?
|
||||
|
||||
|
||||
|
||||
**12. 找出鸢尾属植物物种中的唯一值和唯一值出现的数量。**
|
||||
|
||||
【知识点:数组操作】
|
||||
- 如何在numpy数组中查找唯一值的计数?
|
||||
|
||||
|
||||
|
||||
|
||||
**13. 将 iris_data 的花瓣长度(第3列)以形成分类变量的形式显示。定义:Less than 3 --> 'small';3-5 --> 'medium';'>=5 --> 'large'。**
|
||||
|
||||
【知识点:统计相关】
|
||||
- 如何将数字转换为分类(文本)数组?
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**14. 在 iris_data 中创建一个新列,其中 volume 是 `(pi x petallength x sepallength ^ 2)/ 3`。**
|
||||
|
||||
【知识点:数组操作】
|
||||
- 如何从numpy数组的现有列创建新列?
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**15. 随机抽鸢尾属植物的种类,使得Iris-setosa的数量是Iris-versicolor和Iris-virginica数量的两倍。**
|
||||
|
||||
【知识点:随机抽样】
|
||||
- 如何在numpy中进行概率抽样?
|
||||
|
||||
|
||||
|
||||
|
||||
**16. 根据 sepallength 列对数据集进行排序。**
|
||||
|
||||
【知识点:排序】
|
||||
- 如何按列对2D数组进行排序?
|
||||
|
||||
|
||||
**17. 在鸢尾属植物数据集中找到最常见的花瓣长度值(第3列)。**
|
||||
|
||||
【知识点:数组操作】
|
||||
- 如何在numpy数组中找出出现次数最多的值?
|
||||
|
||||
|
||||
|
||||
|
||||
**18. 在鸢尾花数据集的 petalwidth(第4列)中查找第一次出现的值大于1.0的位置。**
|
||||
|
||||
【知识点:搜索】
|
||||
- 如何找到第一次出现大于给定值的位置?
|
||||
152
IntroductionToNumpy/dataset/iris.data
Normal file
152
IntroductionToNumpy/dataset/iris.data
Normal file
@@ -0,0 +1,152 @@
|
||||
sepallength,sepalwidth,petallength,petalwidth,species
|
||||
5.1,3.5,1.4,0.2,Iris-setosa
|
||||
4.9,3.0,1.4,0.2,Iris-setosa
|
||||
4.7,3.2,1.3,0.2,Iris-setosa
|
||||
4.6,3.1,1.5,0.2,Iris-setosa
|
||||
5.0,3.6,1.4,0.2,Iris-setosa
|
||||
5.4,3.9,1.7,0.4,Iris-setosa
|
||||
4.6,3.4,1.4,0.3,Iris-setosa
|
||||
5.0,3.4,1.5,0.2,Iris-setosa
|
||||
4.4,2.9,1.4,0.2,Iris-setosa
|
||||
4.9,3.1,1.5,0.1,Iris-setosa
|
||||
5.4,3.7,1.5,0.2,Iris-setosa
|
||||
4.8,3.4,1.6,0.2,Iris-setosa
|
||||
4.8,3.0,1.4,0.1,Iris-setosa
|
||||
4.3,3.0,1.1,0.1,Iris-setosa
|
||||
5.8,4.0,1.2,0.2,Iris-setosa
|
||||
5.7,4.4,1.5,0.4,Iris-setosa
|
||||
5.4,3.9,1.3,0.4,Iris-setosa
|
||||
5.1,3.5,1.4,0.3,Iris-setosa
|
||||
5.7,3.8,1.7,0.3,Iris-setosa
|
||||
5.1,3.8,1.5,0.3,Iris-setosa
|
||||
5.4,3.4,1.7,0.2,Iris-setosa
|
||||
5.1,3.7,1.5,0.4,Iris-setosa
|
||||
4.6,3.6,1.0,0.2,Iris-setosa
|
||||
5.1,3.3,1.7,0.5,Iris-setosa
|
||||
4.8,3.4,1.9,0.2,Iris-setosa
|
||||
5.0,3.0,1.6,0.2,Iris-setosa
|
||||
5.0,3.4,1.6,0.4,Iris-setosa
|
||||
5.2,3.5,1.5,0.2,Iris-setosa
|
||||
5.2,3.4,1.4,0.2,Iris-setosa
|
||||
4.7,3.2,1.6,0.2,Iris-setosa
|
||||
4.8,3.1,1.6,0.2,Iris-setosa
|
||||
5.4,3.4,1.5,0.4,Iris-setosa
|
||||
5.2,4.1,1.5,0.1,Iris-setosa
|
||||
5.5,4.2,1.4,0.2,Iris-setosa
|
||||
4.9,3.1,1.5,0.1,Iris-setosa
|
||||
5.0,3.2,1.2,0.2,Iris-setosa
|
||||
5.5,3.5,1.3,0.2,Iris-setosa
|
||||
4.9,3.1,1.5,0.1,Iris-setosa
|
||||
4.4,3.0,1.3,0.2,Iris-setosa
|
||||
5.1,3.4,1.5,0.2,Iris-setosa
|
||||
5.0,3.5,1.3,0.3,Iris-setosa
|
||||
4.5,2.3,1.3,0.3,Iris-setosa
|
||||
4.4,3.2,1.3,0.2,Iris-setosa
|
||||
5.0,3.5,1.6,0.6,Iris-setosa
|
||||
5.1,3.8,1.9,0.4,Iris-setosa
|
||||
4.8,3.0,1.4,0.3,Iris-setosa
|
||||
5.1,3.8,1.6,0.2,Iris-setosa
|
||||
4.6,3.2,1.4,0.2,Iris-setosa
|
||||
5.3,3.7,1.5,0.2,Iris-setosa
|
||||
5.0,3.3,1.4,0.2,Iris-setosa
|
||||
7.0,3.2,4.7,1.4,Iris-versicolor
|
||||
6.4,3.2,4.5,1.5,Iris-versicolor
|
||||
6.9,3.1,4.9,1.5,Iris-versicolor
|
||||
5.5,2.3,4.0,1.3,Iris-versicolor
|
||||
6.5,2.8,4.6,1.5,Iris-versicolor
|
||||
5.7,2.8,4.5,1.3,Iris-versicolor
|
||||
6.3,3.3,4.7,1.6,Iris-versicolor
|
||||
4.9,2.4,3.3,1.0,Iris-versicolor
|
||||
6.6,2.9,4.6,1.3,Iris-versicolor
|
||||
5.2,2.7,3.9,1.4,Iris-versicolor
|
||||
5.0,2.0,3.5,1.0,Iris-versicolor
|
||||
5.9,3.0,4.2,1.5,Iris-versicolor
|
||||
6.0,2.2,4.0,1.0,Iris-versicolor
|
||||
6.1,2.9,4.7,1.4,Iris-versicolor
|
||||
5.6,2.9,3.6,1.3,Iris-versicolor
|
||||
6.7,3.1,4.4,1.4,Iris-versicolor
|
||||
5.6,3.0,4.5,1.5,Iris-versicolor
|
||||
5.8,2.7,4.1,1.0,Iris-versicolor
|
||||
6.2,2.2,4.5,1.5,Iris-versicolor
|
||||
5.6,2.5,3.9,1.1,Iris-versicolor
|
||||
5.9,3.2,4.8,1.8,Iris-versicolor
|
||||
6.1,2.8,4.0,1.3,Iris-versicolor
|
||||
6.3,2.5,4.9,1.5,Iris-versicolor
|
||||
6.1,2.8,4.7,1.2,Iris-versicolor
|
||||
6.4,2.9,4.3,1.3,Iris-versicolor
|
||||
6.6,3.0,4.4,1.4,Iris-versicolor
|
||||
6.8,2.8,4.8,1.4,Iris-versicolor
|
||||
6.7,3.0,5.0,1.7,Iris-versicolor
|
||||
6.0,2.9,4.5,1.5,Iris-versicolor
|
||||
5.7,2.6,3.5,1.0,Iris-versicolor
|
||||
5.5,2.4,3.8,1.1,Iris-versicolor
|
||||
5.5,2.4,3.7,1.0,Iris-versicolor
|
||||
5.8,2.7,3.9,1.2,Iris-versicolor
|
||||
6.0,2.7,5.1,1.6,Iris-versicolor
|
||||
5.4,3.0,4.5,1.5,Iris-versicolor
|
||||
6.0,3.4,4.5,1.6,Iris-versicolor
|
||||
6.7,3.1,4.7,1.5,Iris-versicolor
|
||||
6.3,2.3,4.4,1.3,Iris-versicolor
|
||||
5.6,3.0,4.1,1.3,Iris-versicolor
|
||||
5.5,2.5,4.0,1.3,Iris-versicolor
|
||||
5.5,2.6,4.4,1.2,Iris-versicolor
|
||||
6.1,3.0,4.6,1.4,Iris-versicolor
|
||||
5.8,2.6,4.0,1.2,Iris-versicolor
|
||||
5.0,2.3,3.3,1.0,Iris-versicolor
|
||||
5.6,2.7,4.2,1.3,Iris-versicolor
|
||||
5.7,3.0,4.2,1.2,Iris-versicolor
|
||||
5.7,2.9,4.2,1.3,Iris-versicolor
|
||||
6.2,2.9,4.3,1.3,Iris-versicolor
|
||||
5.1,2.5,3.0,1.1,Iris-versicolor
|
||||
5.7,2.8,4.1,1.3,Iris-versicolor
|
||||
6.3,3.3,6.0,2.5,Iris-virginica
|
||||
5.8,2.7,5.1,1.9,Iris-virginica
|
||||
7.1,3.0,5.9,2.1,Iris-virginica
|
||||
6.3,2.9,5.6,1.8,Iris-virginica
|
||||
6.5,3.0,5.8,2.2,Iris-virginica
|
||||
7.6,3.0,6.6,2.1,Iris-virginica
|
||||
4.9,2.5,4.5,1.7,Iris-virginica
|
||||
7.3,2.9,6.3,1.8,Iris-virginica
|
||||
6.7,2.5,5.8,1.8,Iris-virginica
|
||||
7.2,3.6,6.1,2.5,Iris-virginica
|
||||
6.5,3.2,5.1,2.0,Iris-virginica
|
||||
6.4,2.7,5.3,1.9,Iris-virginica
|
||||
6.8,3.0,5.5,2.1,Iris-virginica
|
||||
5.7,2.5,5.0,2.0,Iris-virginica
|
||||
5.8,2.8,5.1,2.4,Iris-virginica
|
||||
6.4,3.2,5.3,2.3,Iris-virginica
|
||||
6.5,3.0,5.5,1.8,Iris-virginica
|
||||
7.7,3.8,6.7,2.2,Iris-virginica
|
||||
7.7,2.6,6.9,2.3,Iris-virginica
|
||||
6.0,2.2,5.0,1.5,Iris-virginica
|
||||
6.9,3.2,5.7,2.3,Iris-virginica
|
||||
5.6,2.8,4.9,2.0,Iris-virginica
|
||||
7.7,2.8,6.7,2.0,Iris-virginica
|
||||
6.3,2.7,4.9,1.8,Iris-virginica
|
||||
6.7,3.3,5.7,2.1,Iris-virginica
|
||||
7.2,3.2,6.0,1.8,Iris-virginica
|
||||
6.2,2.8,4.8,1.8,Iris-virginica
|
||||
6.1,3.0,4.9,1.8,Iris-virginica
|
||||
6.4,2.8,5.6,2.1,Iris-virginica
|
||||
7.2,3.0,5.8,1.6,Iris-virginica
|
||||
7.4,2.8,6.1,1.9,Iris-virginica
|
||||
7.9,3.8,6.4,2.0,Iris-virginica
|
||||
6.4,2.8,5.6,2.2,Iris-virginica
|
||||
6.3,2.8,5.1,1.5,Iris-virginica
|
||||
6.1,2.6,5.6,1.4,Iris-virginica
|
||||
7.7,3.0,6.1,2.3,Iris-virginica
|
||||
6.3,3.4,5.6,2.4,Iris-virginica
|
||||
6.4,3.1,5.5,1.8,Iris-virginica
|
||||
6.0,3.0,4.8,1.8,Iris-virginica
|
||||
6.9,3.1,5.4,2.1,Iris-virginica
|
||||
6.7,3.1,5.6,2.4,Iris-virginica
|
||||
6.9,3.1,5.1,2.3,Iris-virginica
|
||||
5.8,2.7,5.1,1.9,Iris-virginica
|
||||
6.8,3.2,5.9,2.3,Iris-virginica
|
||||
6.7,3.3,5.7,2.5,Iris-virginica
|
||||
6.7,3.0,5.2,2.3,Iris-virginica
|
||||
6.3,2.5,5.0,1.9,Iris-virginica
|
||||
6.5,3.0,5.2,2.0,Iris-virginica
|
||||
6.2,3.4,5.4,2.3,Iris-virginica
|
||||
5.9,3.0,5.1,1.8,Iris-virginica
|
||||
|
||||
@@ -50,7 +50,7 @@
|
||||
|
||||
## 基本信息
|
||||
|
||||
- 学习周期:11天,每天平均花费时间3小时-5小时不等,根据个人学习接受能力强弱有所浮动。
|
||||
- 学习周期:10天,每天平均花费时间3小时-5小时不等,根据个人学习接受能力强弱有所浮动。
|
||||
- 学习形式:理论学习 + 练习
|
||||
- 人群定位:有一定python编程的基础。
|
||||
- 先修内容:[Python编程语言](https://github.com/datawhalechina/team-learning-program/tree/master/PythonLanguage)
|
||||
@@ -71,7 +71,7 @@
|
||||
- 熟悉打开规则
|
||||
|
||||
|
||||
### Task01:输入输出(2天)
|
||||
### Task01:输入输出(1天)
|
||||
- 熟悉 Numpy 如何处理二进制文件和文本文件。
|
||||
|
||||
|
||||
|
||||
@@ -1,229 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2020-09-06T03:05:42.613206Z",
|
||||
"start_time": "2020-09-06T03:05:42.609217Z"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"**只打印或显示numpy数组rand_arr的小数点后3位。**\n",
|
||||
"\n",
|
||||
"- `rand_arr = np.random.random([5, 3])`\n",
|
||||
"\n",
|
||||
"【知识点:输入和输出】\n",
|
||||
"- 如何在numpy数组中只打印小数点后三位?"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2020-09-06T03:06:03.840763Z",
|
||||
"start_time": "2020-09-06T03:06:03.834778Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[[0.25106063 0.32735642 0.17623774]\n",
|
||||
" [0.85566173 0.11420437 0.53735783]\n",
|
||||
" [0.82253612 0.07625331 0.9358199 ]\n",
|
||||
" [0.97268875 0.91794448 0.61845404]\n",
|
||||
" [0.58615827 0.28096349 0.88048956]]\n",
|
||||
"[[0.251 0.327 0.176]\n",
|
||||
" [0.856 0.114 0.537]\n",
|
||||
" [0.823 0.076 0.936]\n",
|
||||
" [0.973 0.918 0.618]\n",
|
||||
" [0.586 0.281 0.88 ]]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"rand_arr = np.random.random([5, 3])\n",
|
||||
"print(rand_arr)\n",
|
||||
"# [[0.33033427 0.05538836 0.05947305]\n",
|
||||
"# [0.36199439 0.48844555 0.26309599]\n",
|
||||
"# [0.05361816 0.71539075 0.60645637]\n",
|
||||
"# [0.95000384 0.31424729 0.41032467]\n",
|
||||
"# [0.36082793 0.50101268 0.6306832 ]]\n",
|
||||
"\n",
|
||||
"np.set_printoptions(precision=3)\n",
|
||||
"print(rand_arr)\n",
|
||||
"# [[0.33 0.055 0.059]\n",
|
||||
"# [0.362 0.488 0.263]\n",
|
||||
"# [0.054 0.715 0.606]\n",
|
||||
"# [0.95 0.314 0.41 ]\n",
|
||||
"# [0.361 0.501 0.631]]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2020-09-06T03:06:22.855956Z",
|
||||
"start_time": "2020-09-06T03:06:22.850970Z"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"**将numpy数组a中打印的项数限制为最多6个元素。**\n",
|
||||
"\n",
|
||||
"【知识点:输入和输出】\n",
|
||||
"- 如何限制numpy数组输出中打印的项目数?"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2020-09-06T03:06:51.128200Z",
|
||||
"start_time": "2020-09-06T03:06:51.123215Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]\n",
|
||||
"[ 0 1 2 ... 12 13 14]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"a = np.arange(15)\n",
|
||||
"print(a)\n",
|
||||
"# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]\n",
|
||||
"np.set_printoptions(threshold=6)\n",
|
||||
"print(a)\n",
|
||||
"# [ 0 1 2 ... 12 13 14]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2020-09-06T03:07:14.131621Z",
|
||||
"start_time": "2020-09-06T03:07:14.126608Z"
|
||||
}
|
||||
},
|
||||
"source": [
|
||||
"**打印完整的numpy数组a而不中断。**\n",
|
||||
"\n",
|
||||
"【知识点:输入和输出】\n",
|
||||
"- 如何打印完整的numpy数组而不中断?"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2020-09-06T03:07:47.868079Z",
|
||||
"start_time": "2020-09-06T03:07:47.863126Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[ 0 1 2 ... 12 13 14]\n",
|
||||
"[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"a = np.arange(15)\n",
|
||||
"np.set_printoptions(threshold=6)\n",
|
||||
"print(a)\n",
|
||||
"# [ 0 1 2 ... 12 13 14]\n",
|
||||
"np.set_printoptions(threshold=np.iinfo(np.int).max)\n",
|
||||
"print(a)\n",
|
||||
"# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python35",
|
||||
"language": "python",
|
||||
"name": "python35"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.6.10"
|
||||
},
|
||||
"toc": {
|
||||
"base_numbering": 1,
|
||||
"nav_menu": {},
|
||||
"number_sections": true,
|
||||
"sideBar": true,
|
||||
"skip_h1_title": false,
|
||||
"title_cell": "Table of Contents",
|
||||
"title_sidebar": "Contents",
|
||||
"toc_cell": false,
|
||||
"toc_position": {},
|
||||
"toc_section_display": true,
|
||||
"toc_window_display": false
|
||||
},
|
||||
"varInspector": {
|
||||
"cols": {
|
||||
"lenName": 16,
|
||||
"lenType": 16,
|
||||
"lenVar": 40
|
||||
},
|
||||
"kernels_config": {
|
||||
"python": {
|
||||
"delete_cmd_postfix": "",
|
||||
"delete_cmd_prefix": "del ",
|
||||
"library": "var_list.py",
|
||||
"varRefreshCmd": "print(var_dic_list())"
|
||||
},
|
||||
"r": {
|
||||
"delete_cmd_postfix": ") ",
|
||||
"delete_cmd_prefix": "rm(",
|
||||
"library": "var_list.r",
|
||||
"varRefreshCmd": "cat(var_dic_list()) "
|
||||
}
|
||||
},
|
||||
"types_to_exclude": [
|
||||
"module",
|
||||
"function",
|
||||
"builtin_function_or_method",
|
||||
"instance",
|
||||
"_Feature"
|
||||
],
|
||||
"window_display": false
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
@@ -1,372 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# 输入和输出\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## numpy 二进制文件\n",
|
||||
"\n",
|
||||
"`save()`、`savez()`和`load()`函数以 numpy 专用的二进制类型(npy、npz)保存和读取数据,这三个函数会自动处理ndim、dtype、shape等信息,使用它们读写数组非常方便,但是`save()`输出的文件很难与其它语言编写的程序兼容。\n",
|
||||
"\n",
|
||||
"npy格式:以二进制的方式存储文件,在二进制文件第一行以文本形式保存了数据的元信息(ndim,dtype,shape等),可以用二进制工具查看内容。\n",
|
||||
"\n",
|
||||
"npz格式:以压缩打包的方式存储文件,可以用压缩软件解压。\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"- `numpy.save(file, arr, allow_pickle=True, fix_imports=True)` Save an array to a binary file in NumPy `.npy` format.\n",
|
||||
"- `numpy.load(file, mmap_mode=None, allow_pickle=False, fix_imports=True, encoding='ASCII')` Load arrays or pickled objects from ``.npy``, ``.npz`` or pickled files.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"【例】\n",
|
||||
"```python\n",
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"outfile = r'.\\test.npy'\n",
|
||||
"np.random.seed(20200619)\n",
|
||||
"x = np.random.uniform(0, 1, [3, 5])\n",
|
||||
"np.save(outfile, x)\n",
|
||||
"y = np.load(outfile)\n",
|
||||
"print(y)\n",
|
||||
"# [[0.01123594 0.66790705 0.50212171 0.7230908 0.61668256]\n",
|
||||
"# [0.00668332 0.1234096 0.96092409 0.67925305 0.38596837]\n",
|
||||
"# [0.72342998 0.26258324 0.24318845 0.98795012 0.77370715]]\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"- `numpy.savez(file, *args, **kwds)` Save several arrays into a single file in uncompressed `.npz` format.\n",
|
||||
"\n",
|
||||
"`savez()`第一个参数是文件名,其后的参数都是需要保存的数组,也可以使用关键字参数为数组起一个名字,非关键字参数传递的数组会自动起名为`arr_0, arr_1, …`。\n",
|
||||
"\n",
|
||||
"`savez()`输出的是一个压缩文件(扩展名为npz),其中每个文件都是一个`save()`保存的npy文件,文件名对应于数组名。`load()`自动识别npz文件,并且返回一个类似于字典的对象,可以通过数组名作为关键字获取数组的内容。\n",
|
||||
"\n",
|
||||
"【例】将多个数组保存到一个文件,可以使用`numpy.savez()`函数。\n",
|
||||
"```python\n",
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"outfile = r'.\\test.npz'\n",
|
||||
"x = np.linspace(0, np.pi, 5)\n",
|
||||
"y = np.sin(x)\n",
|
||||
"z = np.cos(x)\n",
|
||||
"np.savez(outfile, x, y, z_d=z)\n",
|
||||
"data = np.load(outfile)\n",
|
||||
"np.set_printoptions(suppress=True)\n",
|
||||
"print(data.files) \n",
|
||||
"# ['z_d', 'arr_0', 'arr_1']\n",
|
||||
"\n",
|
||||
"print(data['arr_0'])\n",
|
||||
"# [0. 0.78539816 1.57079633 2.35619449 3.14159265]\n",
|
||||
"\n",
|
||||
"print(data['arr_1'])\n",
|
||||
"# [0. 0.70710678 1. 0.70710678 0. ]\n",
|
||||
"\n",
|
||||
"print(data['z_d'])\n",
|
||||
"# [ 1. 0.70710678 0. -0.70710678 -1. ]\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"用解压软件打开 test.npz 文件,会发现其中有三个文件:`arr_0.npy,arr_1.npy,z_d.npy`,其中分别保存着数组`x,y,z`的内容。\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"## 文本文件\n",
|
||||
"`savetxt()`,`loadtxt()`和`genfromtxt()`函数用来存储和读取文本文件(如TXT,CSV等)。`genfromtxt()`比`loadtxt()`更加强大,可对缺失数据进行处理。\n",
|
||||
"\n",
|
||||
"- `numpy.savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\\n', header='', footer='', comments='# ', encoding=None)` Save an array to a text file.\n",
|
||||
" - fname:文件路径\n",
|
||||
" - X:存入文件的数组。\n",
|
||||
" - fmt:写入文件中每个元素的字符串格式,默认'%.18e'(保留18位小数的浮点数形式)。\n",
|
||||
" - delimiter:分割字符串,默认以空格分隔。\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"- `numpy.loadtxt(fname, dtype=float, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes', max_rows=None)` Load data from a text file. \n",
|
||||
" - fname:文件路径。\n",
|
||||
" - dtype:数据类型,默认为float。\n",
|
||||
" - comments: 字符串或字符串组成的列表,默认为# , 表示注释字符集开始的标志。\n",
|
||||
" - skiprows:跳过多少行,一般跳过第一行表头。\n",
|
||||
" - usecols:元组(元组内数据为列的数值索引), 用来指定要读取数据的列(第一列为0)。\n",
|
||||
" - unpack:当加载多列数据时是否需要将数据列进行解耦赋值给不同的变量。\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"【例】写入和读出TXT文件。\n",
|
||||
"```python\n",
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"outfile = r'.\\test.txt'\n",
|
||||
"x = np.arange(0, 10).reshape(2, -1)\n",
|
||||
"np.savetxt(outfile, x)\n",
|
||||
"y = np.loadtxt(outfile)\n",
|
||||
"print(y)\n",
|
||||
"# [[0. 1. 2. 3. 4.]\n",
|
||||
"# [5. 6. 7. 8. 9.]]\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"test.txt文件如下:\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"0.000000000000000000e+00 1.000000000000000000e+00 2.000000000000000000e+00 3.000000000000000000e+00 4.000000000000000000e+00\n",
|
||||
"5.000000000000000000e+00 6.000000000000000000e+00 7.000000000000000000e+00 8.000000000000000000e+00 9.000000000000000000e+00\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"【例】写入和读出CSV文件。\n",
|
||||
"```python\n",
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"outfile = r'.\\test.csv'\n",
|
||||
"x = np.arange(0, 10, 0.5).reshape(4, -1)\n",
|
||||
"np.savetxt(outfile, x, fmt='%.3f', delimiter=',')\n",
|
||||
"y = np.loadtxt(outfile, delimiter=',')\n",
|
||||
"print(y)\n",
|
||||
"# [[0. 0.5 1. 1.5 2. ]\n",
|
||||
"# [2.5 3. 3.5 4. 4.5]\n",
|
||||
"# [5. 5.5 6. 6.5 7. ]\n",
|
||||
"# [7.5 8. 8.5 9. 9.5]]\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"test.csv文件如下:\n",
|
||||
"```python\n",
|
||||
"0.000,0.500,1.000,1.500,2.000\n",
|
||||
"2.500,3.000,3.500,4.000,4.500\n",
|
||||
"5.000,5.500,6.000,6.500,7.000\n",
|
||||
"7.500,8.000,8.500,9.000,9.500\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"`genfromtxt()`是面向结构数组和缺失数据处理的。\n",
|
||||
"\n",
|
||||
"- `numpy.genfromtxt(fname, dtype=float, comments='#', delimiter=None, skip_header=0, skip_footer=0, converters=None, missing_values=None, filling_values=None, usecols=None, names=None, excludelist=None, deletechars=''.join(sorted(NameValidator.defaultdeletechars)), replace_space='_', autostrip=False, case_sensitive=True, defaultfmt=\"f%i\", unpack=None, usemask=False, loose=True, invalid_raise=True, max_rows=None, encoding='bytes')` Load data from a text file, with missing values handled as specified.\n",
|
||||
" - names:设置为True时,程序将把第一行作为列名称。\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"data.csv文件如下:\n",
|
||||
"```python\n",
|
||||
"id,value1,value2,value3\n",
|
||||
"1,123,1.4,23\n",
|
||||
"2,110,0.5,18\n",
|
||||
"3,164,2.1,19\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"【例】\n",
|
||||
"```python\n",
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"outfile = r'.\\data.csv'\n",
|
||||
"x = np.loadtxt(outfile, delimiter=',', skiprows=1)\n",
|
||||
"print(x)\n",
|
||||
"# [[ 1. 123. 1.4 23. ]\n",
|
||||
"# [ 2. 110. 0.5 18. ]\n",
|
||||
"# [ 3. 164. 2.1 19. ]]\n",
|
||||
"\n",
|
||||
"x = np.loadtxt(outfile, delimiter=',', skiprows=1, usecols=(1, 2))\n",
|
||||
"print(x)\n",
|
||||
"# [[123. 1.4]\n",
|
||||
"# [110. 0.5]\n",
|
||||
"# [164. 2.1]]\n",
|
||||
"\n",
|
||||
"val1, val2 = np.loadtxt(outfile, delimiter=',', skiprows=1, usecols=(1, 2), unpack=True)\n",
|
||||
"print(val1) # [123. 110. 164.]\n",
|
||||
"print(val2) # [1.4 0.5 2.1]\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"【例】\n",
|
||||
"```python\n",
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"outfile = r'.\\data.csv'\n",
|
||||
"x = np.genfromtxt(outfile, delimiter=',', names=True)\n",
|
||||
"print(x)\n",
|
||||
"# [(1., 123., 1.4, 23.) (2., 110., 0.5, 18.) (3., 164., 2.1, 19.)]\n",
|
||||
"\n",
|
||||
"print(type(x)) \n",
|
||||
"# <class 'numpy.ndarray'>\n",
|
||||
"\n",
|
||||
"print(x.dtype)\n",
|
||||
"# [('id', '<f8'), ('value1', '<f8'), ('value2', '<f8'), ('value3', '<f8')]\n",
|
||||
"\n",
|
||||
"print(x['id']) # [1. 2. 3.]\n",
|
||||
"print(x['value1']) # [123. 110. 164.]\n",
|
||||
"print(x['value2']) # [1.4 0.5 2.1]\n",
|
||||
"print(x['value3']) # [23. 18. 19.]\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"data1.csv文件\n",
|
||||
"```python\n",
|
||||
"id,value1,value2,value3\n",
|
||||
"1,123,1.4,23\n",
|
||||
"2,110,,18\n",
|
||||
"3,,2.1,19\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"【例】\n",
|
||||
"```python\n",
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"outfile = r'.\\data1.csv'\n",
|
||||
"x = np.genfromtxt(outfile, delimiter=',', names=True)\n",
|
||||
"print(x)\n",
|
||||
"# [(1., 123., 1.4, 23.) (2., 110., nan, 18.) (3., nan, 2.1, 19.)]\n",
|
||||
"\n",
|
||||
"print(type(x)) \n",
|
||||
"# <class 'numpy.ndarray'>\n",
|
||||
"\n",
|
||||
"print(x.dtype)\n",
|
||||
"# [('id', '<f8'), ('value1', '<f8'), ('value2', '<f8'), ('value3', '<f8')]\n",
|
||||
"\n",
|
||||
"print(x['id']) # [1. 2. 3.]\n",
|
||||
"print(x['value1']) # [123. 110. nan]\n",
|
||||
"print(x['value2']) # [1.4 nan 2.1]\n",
|
||||
"print(x['value3']) # [23. 18. 19.]\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"---\n",
|
||||
"## 文本格式选项\n",
|
||||
"\n",
|
||||
"- `numpy.set_printoptions(precision=None,threshold=None, edgeitems=None,linewidth=None, suppress=None, nanstr=None, infstr=None,formatter=None, sign=None, floatmode=None, **kwarg)` Set printing options.\n",
|
||||
" - `precision`:设置浮点精度,控制输出的小数点个数,默认是8。\n",
|
||||
" - `threshold`:概略显示,超过该值则以“…”的形式来表示,默认是1000。\n",
|
||||
" - `linewidth`:用于确定每行多少字符数后插入换行符,默认为75。\n",
|
||||
" - `suppress`:当`suppress=True`,表示小数不需要以科学计数法的形式输出,默认是False。\n",
|
||||
" - `nanstr`:浮点非数字的字符串表示形式,默认`nan`。\n",
|
||||
" - `infstr`:浮点无穷大的字符串表示形式,默认`inf`。\n",
|
||||
"\n",
|
||||
"These options determine the way floating point numbers, arrays and other NumPy objects are displayed.\n",
|
||||
"\n",
|
||||
"【例】\n",
|
||||
"```python\n",
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"np.set_printoptions(precision=4)\n",
|
||||
"x = np.array([1.123456789])\n",
|
||||
"print(x) # [1.1235]\n",
|
||||
"\n",
|
||||
"np.set_printoptions(threshold=20)\n",
|
||||
"x = np.arange(50)\n",
|
||||
"print(x) # [ 0 1 2 ... 47 48 49]\n",
|
||||
"\n",
|
||||
"np.set_printoptions(threshold=np.iinfo(np.int).max)\n",
|
||||
"print(x)\n",
|
||||
"# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23\n",
|
||||
"# 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47\n",
|
||||
"# 48 49]\n",
|
||||
"\n",
|
||||
"eps = np.finfo(float).eps\n",
|
||||
"x = np.arange(4.)\n",
|
||||
"x = x ** 2 - (x + eps) ** 2\n",
|
||||
"print(x) \n",
|
||||
"# [-4.9304e-32 -4.4409e-16 0.0000e+00 0.0000e+00]\n",
|
||||
"np.set_printoptions(suppress=True)\n",
|
||||
"print(x) # [-0. -0. 0. 0.]\n",
|
||||
"\n",
|
||||
"x = np.linspace(0, 10, 10)\n",
|
||||
"print(x)\n",
|
||||
"# [ 0. 1.1111 2.2222 3.3333 4.4444 5.5556 6.6667 7.7778 8.8889\n",
|
||||
"# 10. ]\n",
|
||||
"np.set_printoptions(precision=2, suppress=True, threshold=5)\n",
|
||||
"print(x) # [ 0. 1.11 2.22 ... 7.78 8.89 10. ]\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"- `numpy.get_printoptions()` Return the current print options.\n",
|
||||
"\n",
|
||||
"【例】\n",
|
||||
"```python\n",
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"x = np.get_printoptions()\n",
|
||||
"print(x)\n",
|
||||
"# {\n",
|
||||
"# 'edgeitems': 3, \n",
|
||||
"# 'threshold': 1000, \n",
|
||||
"# 'floatmode': 'maxprec', \n",
|
||||
"# 'precision': 8, \n",
|
||||
"# 'suppress': False, \n",
|
||||
"# 'linewidth': 75, \n",
|
||||
"# 'nanstr': 'nan', \n",
|
||||
"# 'infstr': 'inf', \n",
|
||||
"# 'sign': '-', \n",
|
||||
"# 'formatter': None, \n",
|
||||
"# 'legacy': False\n",
|
||||
"# }\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python35",
|
||||
"language": "python",
|
||||
"name": "python35"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.6.10"
|
||||
},
|
||||
"toc": {
|
||||
"base_numbering": 1,
|
||||
"nav_menu": {},
|
||||
"number_sections": true,
|
||||
"sideBar": true,
|
||||
"skip_h1_title": false,
|
||||
"title_cell": "Table of Contents",
|
||||
"title_sidebar": "Contents",
|
||||
"toc_cell": false,
|
||||
"toc_position": {},
|
||||
"toc_section_display": true,
|
||||
"toc_window_display": true
|
||||
},
|
||||
"varInspector": {
|
||||
"cols": {
|
||||
"lenName": 16,
|
||||
"lenType": 16,
|
||||
"lenVar": 40
|
||||
},
|
||||
"kernels_config": {
|
||||
"python": {
|
||||
"delete_cmd_postfix": "",
|
||||
"delete_cmd_prefix": "del ",
|
||||
"library": "var_list.py",
|
||||
"varRefreshCmd": "print(var_dic_list())"
|
||||
},
|
||||
"r": {
|
||||
"delete_cmd_postfix": ") ",
|
||||
"delete_cmd_prefix": "rm(",
|
||||
"library": "var_list.r",
|
||||
"varRefreshCmd": "cat(var_dic_list()) "
|
||||
}
|
||||
},
|
||||
"types_to_exclude": [
|
||||
"module",
|
||||
"function",
|
||||
"builtin_function_or_method",
|
||||
"instance",
|
||||
"_Feature"
|
||||
],
|
||||
"window_display": false
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
144
LeetCodeTencent/readme.md
Normal file
144
LeetCodeTencent/readme.md
Normal file
@@ -0,0 +1,144 @@
|
||||
|
||||
# 编程实践(LeetCode 腾讯精选练习50)
|
||||
|
||||
|
||||
开源内容:https://github.com/datawhalechina/team-learning-program/tree/master/LeetCodeTencent
|
||||
|
||||
## 基本信息
|
||||
|
||||
- 学习周期:17天,每天平均花费时间2小时-5小时不等,根据个人学习接受能力强弱有所浮动。
|
||||
- 学习形式:练习
|
||||
- 人群定位:有一定编程基础,对学习算法有需求的学员。
|
||||
- 先修内容:[Python编程语言](https://github.com/datawhalechina/team-learning-program/tree/master/PythonLanguage)、[数据结构与算法](https://github.com/datawhalechina/team-learning-program/tree/master/DataStructureAndAlgorithm)、[编程实践(LeetCode 分类练习)](https://github.com/datawhalechina/team-learning-program/tree/master/LeetCodeClassification)
|
||||
- 难度系数:中
|
||||
|
||||
## 学习目标
|
||||
|
||||
每天刷三道题,利用17天完成Leetcode腾讯精选练习50题。
|
||||
|
||||
|
||||
|
||||
## 任务安排
|
||||
|
||||
|
||||
### Task00:熟悉规则(1天)
|
||||
|
||||
- 组队、修改群昵称
|
||||
- 熟悉打卡规则
|
||||
|
||||
### Task01:完成以下三个题目并打卡(1天)
|
||||
|
||||
- [002 两数相加](https://leetcode-cn.com/problems/add-two-numbers/)
|
||||
- [004 寻找两个正序数组的中位数](https://leetcode-cn.com/problems/median-of-two-sorted-arrays/)
|
||||
- [005 最长回文子串](https://leetcode-cn.com/problems/longest-palindromic-substring/)
|
||||
|
||||
### Task02: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [007 整数反转](https://leetcode-cn.com/problems/reverse-integer/)
|
||||
- [008 字符串转换整数 (atoi)](https://leetcode-cn.com/problems/string-to-integer-atoi/)
|
||||
- [009 回文数](https://leetcode-cn.com/problems/palindrome-number/)
|
||||
|
||||
### Task03: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [011 盛最多水的容器](https://leetcode-cn.com/problems/container-with-most-water/)
|
||||
- [014 最长公共前缀](https://leetcode-cn.com/problems/longest-common-prefix/)
|
||||
- [015 三数之和](https://leetcode-cn.com/problems/3sum/)
|
||||
|
||||
### Task04: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [016 最接近的三数之和](https://leetcode-cn.com/problems/3sum-closest/)
|
||||
- [020 有效的括号](https://leetcode-cn.com/problems/valid-parentheses/)
|
||||
- [021 合并两个有序链表](https://leetcode-cn.com/problems/merge-two-sorted-lists/)
|
||||
|
||||
### Task05: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [023 合并K个排序链表](https://leetcode-cn.com/problems/merge-k-sorted-lists/)
|
||||
- [026 删除排序数组中的重复项](https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array/)
|
||||
- [033 搜索旋转排序数组](https://leetcode-cn.com/problems/search-in-rotated-sorted-array/)
|
||||
|
||||
### Task06:完成以下三个题目并打卡(1天)
|
||||
|
||||
- [043 字符串相乘](https://leetcode-cn.com/problems/multiply-strings/)
|
||||
- [046 全排列](https://leetcode-cn.com/problems/permutations/)
|
||||
- [053 最大子序和](https://leetcode-cn.com/problems/maximum-subarray/)
|
||||
|
||||
### Task07: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [054 螺旋矩阵](https://leetcode-cn.com/problems/spiral-matrix/)
|
||||
- [059 螺旋矩阵 II](https://leetcode-cn.com/problems/spiral-matrix-ii/)
|
||||
- [061 旋转链表](https://leetcode-cn.com/problems/rotate-list/)
|
||||
|
||||
### Task 08: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [062 不同路径](https://leetcode-cn.com/problems/unique-paths/)
|
||||
- [070 爬楼梯](https://leetcode-cn.com/problems/climbing-stairs/)
|
||||
- [078 子集](https://leetcode-cn.com/problems/subsets/)
|
||||
|
||||
### Task09: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [088 合并两个有序数组](https://leetcode-cn.com/problems/merge-sorted-array/)
|
||||
- [089 格雷编码](https://leetcode-cn.com/problems/gray-code/)
|
||||
- [104 二叉树的最大深度](https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/)
|
||||
|
||||
### Task10: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [121 买卖股票的最佳时机](https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock/)
|
||||
- [122 买卖股票的最佳时机 II](https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii/)
|
||||
- [124 二叉树中的最大路径和](https://leetcode-cn.com/problems/binary-tree-maximum-path-sum/)
|
||||
|
||||
### Task11: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [136 只出现一次的数字](https://leetcode-cn.com/problems/single-number/)
|
||||
- [141 环形链表](https://leetcode-cn.com/problems/linked-list-cycle/)
|
||||
- [142 环形链表 II](https://leetcode-cn.com/problems/linked-list-cycle-ii/)
|
||||
|
||||
### Task12: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [146 LRU缓存机制](https://leetcode-cn.com/problems/lru-cache/)
|
||||
- [148 排序链表](https://leetcode-cn.com/problems/sort-list/)
|
||||
- [155 最小栈](https://leetcode-cn.com/problems/min-stack/)
|
||||
|
||||
### Task13: 完成以下三个题目并打卡(1天)
|
||||
|
||||
- [160 相交链表](https://leetcode-cn.com/problems/intersection-of-two-linked-lists/)
|
||||
- [169 多数元素](https://leetcode-cn.com/problems/majority-element/)
|
||||
- [206 反转链表](https://leetcode-cn.com/problems/reverse-linked-list/)
|
||||
|
||||
|
||||
### Task14:完成以下三个题目并打卡(1天)
|
||||
|
||||
- [215 数组中的第K个最大元素](https://leetcode-cn.com/problems/kth-largest-element-in-an-array/)
|
||||
- [217 存在重复元素](https://leetcode-cn.com/problems/contains-duplicate/)
|
||||
- [230 二叉搜索树中第K小的元素](https://leetcode-cn.com/problems/kth-smallest-element-in-a-bst/)
|
||||
|
||||
### Task15:完成以下三个题目并打卡(1天)
|
||||
|
||||
- [231 2的幂](https://leetcode-cn.com/problems/power-of-two/)
|
||||
- [235 二叉搜索树的最近公共祖先](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-search-tree/)
|
||||
- [236 二叉树的最近公共祖先](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/)
|
||||
|
||||
### Task16:完成以下三个题目并打卡(1天)
|
||||
|
||||
- [237 删除链表中的节点](https://leetcode-cn.com/problems/delete-node-in-a-linked-list/)
|
||||
- [238 除自身以外数组的乘积](https://leetcode-cn.com/problems/product-of-array-except-self/)
|
||||
- [292 Nim 游戏](https://leetcode-cn.com/problems/nim-game/)
|
||||
|
||||
### Task17:完成以下三个题目并打卡(1天)
|
||||
|
||||
- [344 反转字符串](https://leetcode-cn.com/problems/reverse-string/)
|
||||
- [557 反转字符串中的单词 III](https://leetcode-cn.com/problems/reverse-words-in-a-string-iii/)
|
||||
|
||||
|
||||
# 贡献人员
|
||||
|
||||
姓名 | 博客|备注
|
||||
---|---|---
|
||||
马燕鹏|CSDN:https://lsgogroup.blog.csdn.net/<br>微信公众号:LSGO软件技术团队|华北电力大学
|
||||
韩绘锦|CSDN:https://blog.csdn.net/weixin_45569785|华北电力大学
|
||||
姚行志|CSDN:https://blog.csdn.net/soulmate______|华北电力大学
|
||||
徐韬||华北电力大学
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
2
Turtle/readme.md
Normal file
2
Turtle/readme.md
Normal file
@@ -0,0 +1,2 @@
|
||||
## 简介
|
||||
|
||||
2
ValentineDay/readme.md
Normal file
2
ValentineDay/readme.md
Normal file
@@ -0,0 +1,2 @@
|
||||
## 简介
|
||||
|
||||
@@ -13,6 +13,9 @@
|
||||
- [编程实践(Python 爬虫)](https://github.com/datawhalechina/team-learning-program/tree/master/WebSpider)
|
||||
- [编程实践(Python综合)](https://github.com/datawhalechina/team-learning-program/tree/master/ProjectPractice)
|
||||
- [编程实践(设计模式)](https://github.com/datawhalechina/team-learning-program/tree/master/DesignPattern)
|
||||
- [编程实践(欢欢喜喜情人节)](https://github.com/datawhalechina/team-learning-program/tree/master/ValentineDay)
|
||||
- [编程实践(青少年编程Turtle)](https://github.com/datawhalechina/team-learning-program/tree/master/Turtle)
|
||||
|
||||
|
||||
|
||||
## 备注
|
||||
|
||||
Reference in New Issue
Block a user