金融风控反馈修改v1
This commit is contained in:
@@ -1,19 +1,16 @@
|
||||
|
||||
# Task1 赛题理解
|
||||
## Task1 赛题理解
|
||||
Tip:本次新人赛是Datawhale与天池联合发起的0基础入门系列赛事第四场 —— 零基础入门金融风控之贷款违约预测挑战赛。
|
||||
赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款,这是一个典型的分类问题。通过这道赛题来引导大家了解金融风控中的一些业务背景,解决实际问题,帮助竞赛新人进行自我练习、自我提高。
|
||||
|
||||
Tip:本次新人赛是Datawhale与天池联合发起的0基础入门系列赛事第四场 —— 零基础入门金融风控之贷款违约预测挑战赛。
|
||||
地址:
|
||||
|
||||
赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款,这是一个典型的分类问题。通过这道赛题来引导大家了解金融风控中的一些业务背景,解决实际问题,帮助竞赛新人进行自我练习、自我提高。
|
||||
|
||||
地址:https://tianchi.aliyun.com/competition/entrance/531830/introduction
|
||||
|
||||
## 1.1 学习目标
|
||||
### 1.1 学习目标
|
||||
理解赛题数据和目标,清楚评分体系。
|
||||
|
||||
完成相应报名,下载数据和结果提交打卡(可提交示例结果),熟悉比赛流程
|
||||
|
||||
|
||||
## 1.2 了解赛题
|
||||
### 1.2 了解赛题
|
||||
- 赛题概况
|
||||
- 数据概况
|
||||
- 预测指标
|
||||
@@ -21,8 +18,7 @@ Tip:本次新人赛是Datawhale与天池联合发起的0基础入门系列赛
|
||||
|
||||
### 1.2.1 赛题概况
|
||||
|
||||
比赛要求参赛选手根据给定的数据集,建立模型,预测金融风险。
|
||||
|
||||
##### 比赛要求参赛选手根据给定的数据集,建立模型,预测金融风险。
|
||||
赛题以预测金融风险为任务,数据集报名后可见并可下载,该数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时会对employmentTitle、purpose、postCode和title等信息进行脱敏。
|
||||
|
||||
|
||||
@@ -72,7 +68,7 @@ train.csv
|
||||
|
||||
竞赛采用AUC作为评价指标。AUC(Area Under Curve)被定义为 ROC曲线 下与坐标轴围成的面积。
|
||||
|
||||
#### 分类算法常见的评估指标如下:
|
||||
##### 分类算法常见的评估指标如下:
|
||||
|
||||
1、混淆矩阵(Confuse Matrix)
|
||||
- (1)若一个实例是正类,并且被预测为正类,即为真正类TP(True Positive )
|
||||
@@ -99,7 +95,7 @@ $$F1-Score = \frac{2}{\frac{1}{Precision} + \frac{1}{Recall}}$$
|
||||
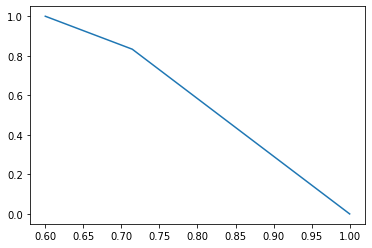
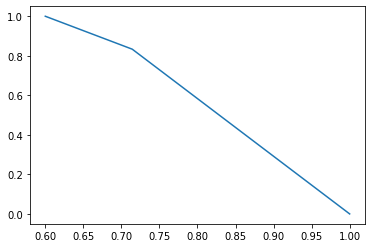
6、P-R曲线(Precision-Recall Curve)
|
||||
P-R曲线是描述精确率和召回率变化的曲线
|
||||
|
||||
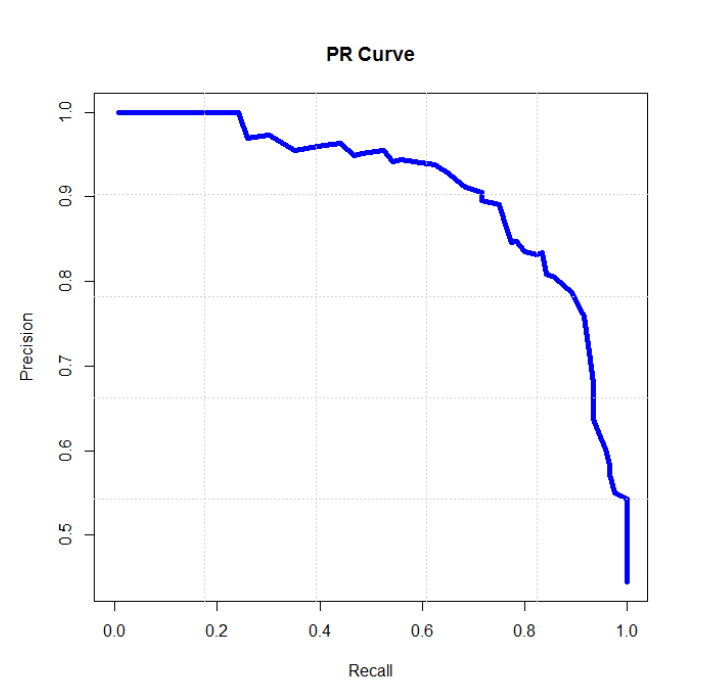
|
||||
<img src="https://img-blog.csdnimg.cn/20200913010226125.png" width = "300" height = "300" alt="p-r" align=center />
|
||||
|
||||
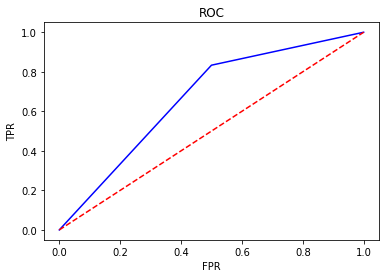
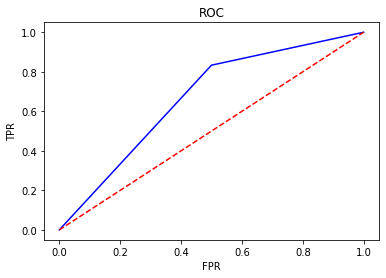
7、ROC(Receiver Operating Characteristic)
|
||||
- ROC空间将假正例率(FPR)定义为 X 轴,真正例率(TPR)定义为 Y 轴。
|
||||
@@ -109,33 +105,42 @@ $$TPR = \frac{TP}{TP + FN}$$
|
||||
FPR:在所有实际为负例的样本中,被错误地判断为正例之比率。
|
||||
$$FPR = \frac{FP}{FP + TN}$$
|
||||
|
||||
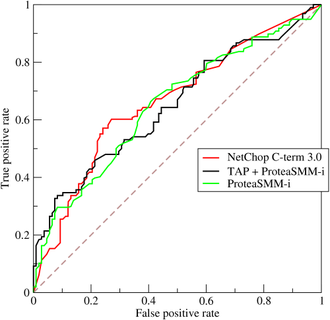
|
||||
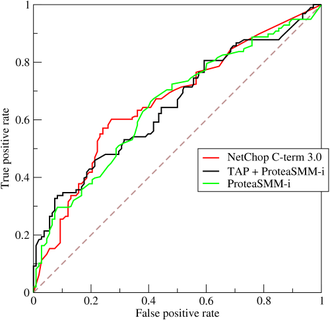
|
||||
|
||||
8、AUC(Area Under Curve)
|
||||
AUC(Area Under Curve)被定义为 ROC曲线 下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
|
||||
|
||||
|
||||
#### 对于金融风控预测类常见的评估指标如下:
|
||||
##### 对于金融风控预测类常见的评估指标如下:
|
||||
|
||||
1、KS(Kolmogorov-Smirnov)
|
||||
KS统计量由两位苏联数学家A.N. Kolmogorov和N.V. Smirnov提出。在风控中,KS常用于评估模型区分度。区分度越大,说明模型的风险排序能力(ranking ability)越强。
|
||||
K-S曲线与ROC曲线类似,不同在于
|
||||
- ROC曲线将真正例率和假正例率作为横纵轴
|
||||
- K-S曲线将真正例率和假正例率都作为纵轴,横轴则由选定的阈值来充当。
|
||||
公式如下:
|
||||
$$KS=max(TPR-FPR)$$
|
||||
KS不同代表的不同情况,一般情况KS值越大,模型的区分能力越强,但是也不是越大模型效果就越好,如果KS过大,模型可能存在异常,所以当KS值过高可能需要检查模型是否过拟合。以下为KS值对应的模型情况,但此对应不是唯一的,只代表大致趋势。
|
||||
- KS值<0.2,一般认为模型没有区分能力。
|
||||
- KS值[0.2,0.3],模型具有一定区分能力,勉强可以接受
|
||||
- KS值[0.3,0.5],模型具有较强的区分能力。
|
||||
- KS值大于0.75,往往表示模型有异常。
|
||||
|
||||
|
||||
| KS(%) | 好坏区分能力 |
|
||||
| :-----: | :------------------: |
|
||||
| 20以下 | 不建议采用 |
|
||||
| 20-40 | 较好 |
|
||||
| 41-50 | 良好 |
|
||||
| 51-60 | 很强 |
|
||||
| 61-75 | 非常强 |
|
||||
| 75以上 | 过于高,疑似存在问题 |
|
||||
|
||||
2、ROC
|
||||
|
||||
3、AUC
|
||||
|
||||
### 1.2.4. 赛题流程
|
||||
|
||||
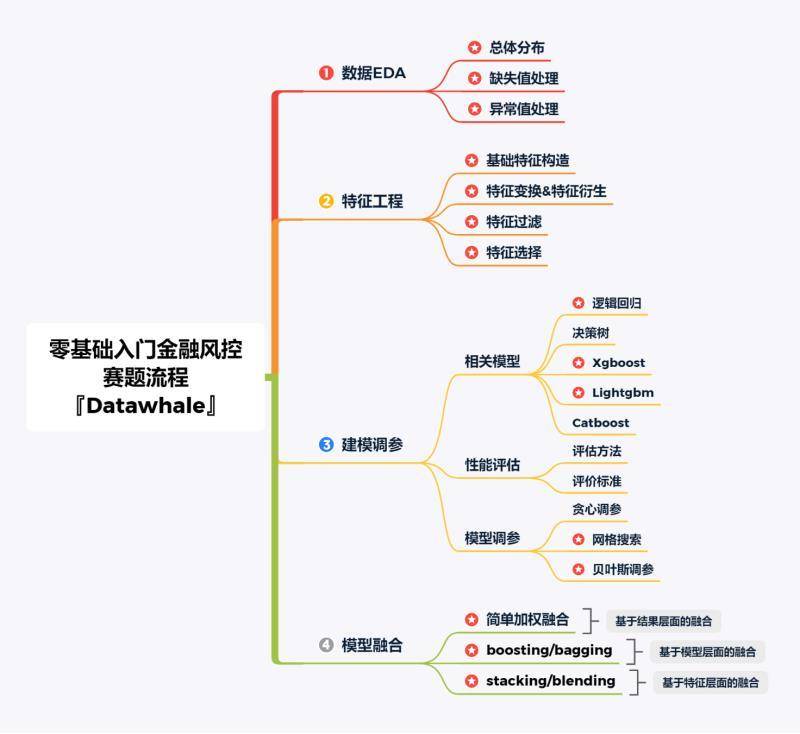
|
||||
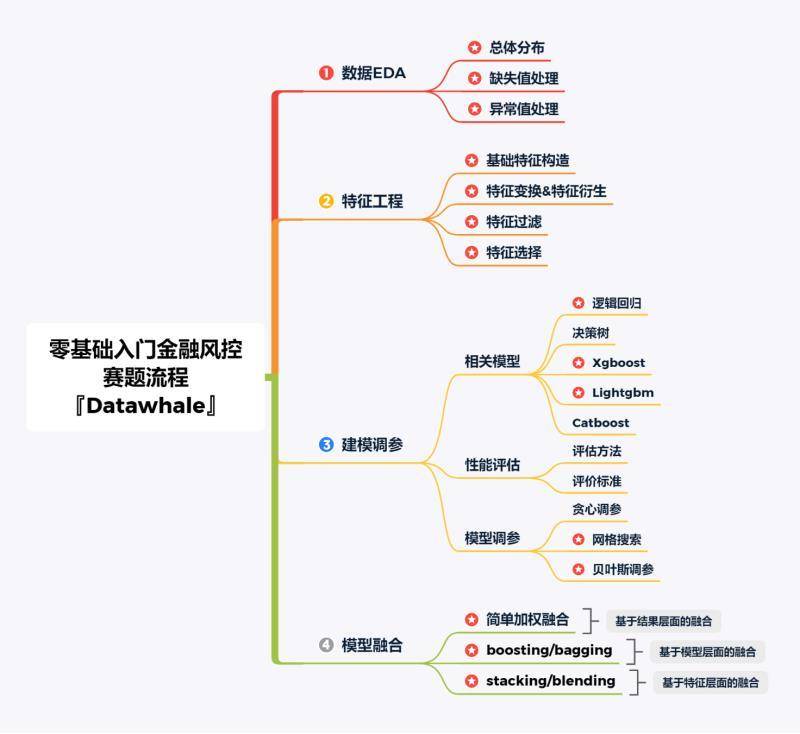
|
||||
|
||||
## 1.3 代码示例
|
||||
### 1.3 代码示例
|
||||
|
||||
本部分为对于数据读取和指标评价的示例。
|
||||
|
||||
@@ -402,8 +407,8 @@ plt.plot(precision, recall)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -424,11 +429,11 @@ plt.xlabel('FPR')
|
||||
|
||||
|
||||
Text(0.5, 0, 'FPR')
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -458,7 +463,7 @@ print('KS值:',KS)
|
||||
KS值: 0.5238095238095237
|
||||
|
||||
|
||||
## 1.4 经验总结
|
||||
### 1.4 经验总结
|
||||
赛题理解是开始比赛的第一步,赛题的理解有助于对竞赛全局的把握。通过赛题理解有助于对赛题的业务逻辑把握,对于后期的特征工程构建和模型选择都尤为重要。
|
||||
- 在开始比赛之前要对赛题进行充分的了解。
|
||||
- 比赛什么时候开始,什么时候结束,什么时候换B榜数据。
|
||||
@@ -468,7 +473,7 @@ print('KS值:',KS)
|
||||
|
||||
|
||||
|
||||
## 1.5 拓展知识——评分卡
|
||||
### 1.5 拓展知识——评分卡
|
||||
评分卡是一张拥有分数刻度会让相应阈值的表。信用评分卡是用于用户信用的一张刻度表。以下代码是一个非标准评分卡的代码流程,用于刻画用户的信用评分。评分卡是金融风控中常用的一种对于用户信用进行刻画的手段哦!
|
||||
|
||||
|
||||
@@ -484,14 +489,13 @@ def Score(prob,P0=600,PDO=20,badrate=None,goodrate=None):
|
||||
return score
|
||||
```
|
||||
|
||||
END.
|
||||
END.
|
||||
【 杨冰楠:Datawhale成员,金融风控爱好者。】
|
||||
|
||||
|
||||
关于Datawhale:
|
||||
|
||||
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale 以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
|
||||
|
||||
本次数据挖掘路径学习,专题知识将在天池分享,详情可关注Datawhale:
|
||||
|
||||

|
||||
)
|
||||
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
|
||||
# Task2 数据分析
|
||||
|
||||
此部分为零基础入门金融风控的 Task2 数据分析部分,带你来了解数据,熟悉数据,为后续的特征工程做准备,欢迎大家后续多多交流。
|
||||
@@ -12,7 +11,7 @@
|
||||
|
||||
- 3.为特征工程做准备
|
||||
|
||||
预测: https://tianchi.aliyun.com/competition/entrance/531830/introduction
|
||||
地址:https://tianchi.aliyun.com/competition/entrance/531830/introduction
|
||||
|
||||
## 2.1 学习目标
|
||||
|
||||
@@ -62,8 +61,7 @@ warnings.filterwarnings('ignore')
|
||||
|
||||
以上库都是pip install 安装就好,如果本机有python2,python3两个python环境傻傻分不清哪个的话,可以pip3 install 。或者直接在notebook中'!pip3 install ****'安装。
|
||||
|
||||
说明:
|
||||
|
||||
### 说明:
|
||||
本次数据分析探索,尤其可视化部分均选取某些特定变量进行了举例,所以它只是一个方法的展示而不是整个赛题数据分析的解决方案。
|
||||
|
||||
### 2.3.2 读取文件
|
||||
@@ -78,7 +76,8 @@ data_train = pd.read_csv('./train.csv')
|
||||
data_test_a = pd.read_csv('./testA.csv')
|
||||
```
|
||||
|
||||
读取文件的拓展知识:
|
||||
#### 2.3.2.1读取文件的拓展知识
|
||||
|
||||
|
||||
- pandas读取数据时相对路径载入报错时,尝试使用os.getcwd()查看当前工作目录。
|
||||
- TSV与CSV的区别:
|
||||
@@ -106,10 +105,9 @@ for item in chunker:
|
||||
#5
|
||||
```
|
||||
|
||||
### 2.3.3 总体了解
|
||||
### 2.3.3总体了解
|
||||
|
||||
|
||||
查看数据集的样本个数和原始特征维度
|
||||
#### 查看数据集的样本个数和原始特征维度
|
||||
|
||||
|
||||
```python
|
||||
@@ -705,7 +703,7 @@ data_train.head(3).append(data_train.tail(3))
|
||||
|
||||
|
||||
|
||||
### 2.3.4 查看数据集中特征缺失值,唯一值等
|
||||
### 2.3.4查看数据集中特征缺失值,唯一值等
|
||||
|
||||
查看缺失值
|
||||
|
||||
@@ -759,10 +757,14 @@ missing.plot.bar()
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
了解哪些列存在 “nan”, 并可以把nan的个数打印,主要的目的在于 nan存在的个数是否真的很大,如果很小一般选择填充,如果使用lgb等树模型可以直接空缺,让树自己去优化,但如果nan存在的过多、可以考虑删掉
|
||||
- 纵向了解哪些列存在 “nan”, 并可以把nan的个数打印,主要的目的在于查看某一列nan存在的个数是否真的很大,如果nan存在的过多,说明这一列对label的影响几乎不起作用了,可以考虑删掉。如果缺失值很小一般可以选择填充。
|
||||
- 另外可以横向比较,如果在数据集中,某些样本数据的大部分列都是缺失的且样本足够的情况下可以考虑删除。
|
||||
|
||||
Tips:
|
||||
比赛大杀器lgb模型可以自动处理缺失值,Task4模型会具体学习模型了解模型哦!
|
||||
|
||||
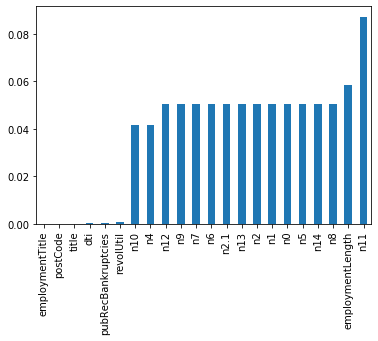
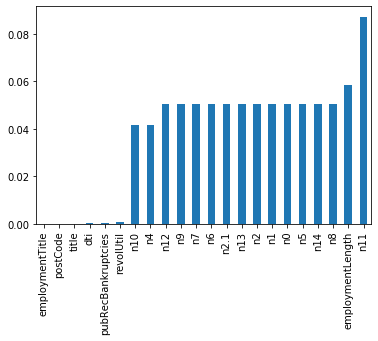
查看训练集测试集中特征属性只有一值的特征
|
||||
|
||||
@@ -810,12 +812,11 @@ print(f'There are {len(one_value_fea_test)} columns in test dataset with one uni
|
||||
There are 1 columns in test dataset with one unique value.
|
||||
|
||||
|
||||
总结:
|
||||
|
||||
### 总结:
|
||||
47列数据中有22列都缺少数据,这在现实世界中很正常。‘policyCode’具有一个唯一值(或全部缺失)。有很多连续变量和一些分类变量。
|
||||
|
||||
### 2.3.5 查看特征的数值类型有哪些,对象类型有哪些
|
||||
- 特征一般都是由类别型特征和数值型特征组成
|
||||
- 特征一般都是由类别型特征和数值型特征组成,而数值型特征又分为连续型和离散型。
|
||||
- 类别型特征有时具有非数值关系,有时也具有数值关系。比如‘grade’中的等级A,B,C等,是否只是单纯的分类,还是A优于其他要结合业务判断。
|
||||
- 数值型特征本是可以直接入模的,但往往风控人员要对其做分箱,转化为WOE编码进而做标准评分卡等操作。从模型效果上来看,特征分箱主要是为了降低变量的复杂性,减少变量噪音对模型的影响,提高自变量和因变量的相关度。从而使模型更加稳定。
|
||||
|
||||
@@ -913,9 +914,9 @@ data_train.grade
|
||||
|
||||
|
||||
|
||||
数值型变量分析,数值型肯定是包括连续型变量和离散型变量的,找出来。
|
||||
#### 数值型变量分析,数值型肯定是包括连续型变量和离散型变量的,找出来
|
||||
|
||||
- 划分数值型变量中的连续变量和分类变量
|
||||
- 划分数值型变量中的连续变量和离散型变量
|
||||
|
||||
|
||||
```python
|
||||
@@ -1132,11 +1133,12 @@ g = g.map(sns.distplot, "value")
|
||||
```
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
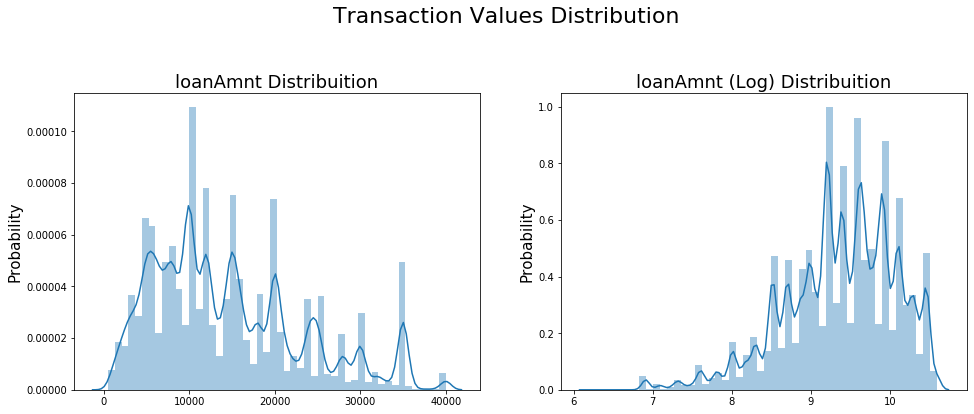
- 查看某一个数值型变量的分布,查看变量是否符合正态分布,如果不符合正太分布的变量可以log化后再观察下是否符合正态分布。
|
||||
- 如果想统一处理一批数据变标准化 必须把这些之前已经正态化的数据提出
|
||||
- 正态化的原因:一些情况下正态非正态可以让模型更快的收敛,一些模型要求数据正态(eg. GMM、KNN),保证数据不要过偏态即可,过于偏态可能会影响模型预测结果。
|
||||
|
||||
|
||||
```python
|
||||
@@ -1164,7 +1166,7 @@ sub_plot_2.set_ylabel("Probability", fontsize=15)
|
||||
|
||||
|
||||
|
||||
|
||||
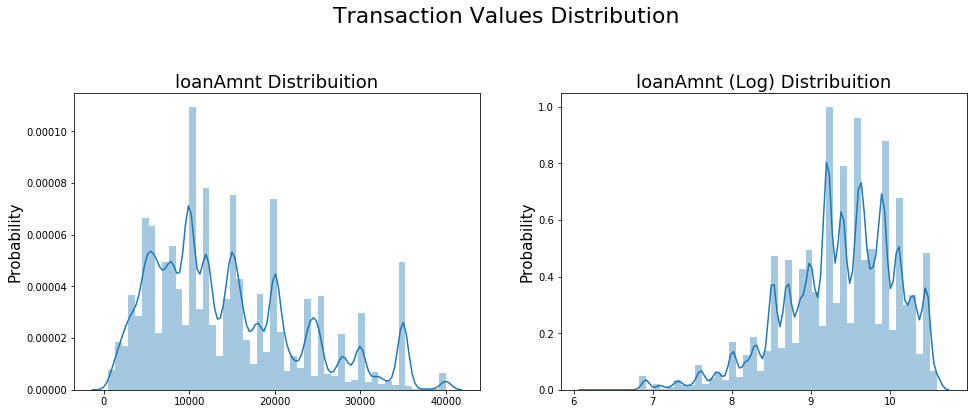
|
||||
|
||||
|
||||
- 非数值类别型变量分析
|
||||
@@ -1331,8 +1333,7 @@ data_train['isDefault'].value_counts()
|
||||
|
||||
|
||||
|
||||
总结:
|
||||
|
||||
### 总结:
|
||||
- 上面我们用value_counts()等函数看了特征属性的分布,但是图表是概括原始信息最便捷的方式。
|
||||
- 数无形时少直觉。
|
||||
- 同一份数据集,在不同的尺度刻画上显示出来的图形反映的规律是不一样的。python将数据转化成图表,但结论是否正确需要由你保证。
|
||||
@@ -1350,7 +1351,7 @@ plt.show()
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 根绝y值不同可视化x某个特征的分布
|
||||
@@ -1374,7 +1375,7 @@ plt.show()
|
||||
```
|
||||
|
||||
|
||||
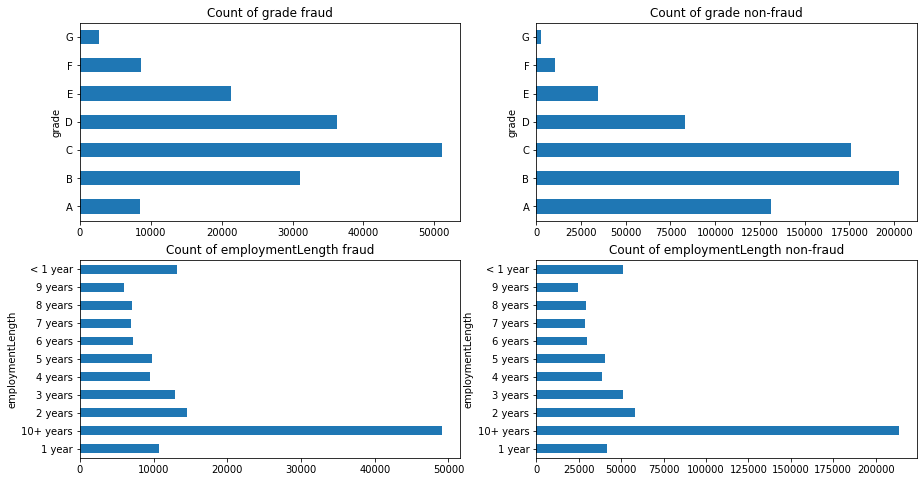
|
||||
|
||||
|
||||
|
||||
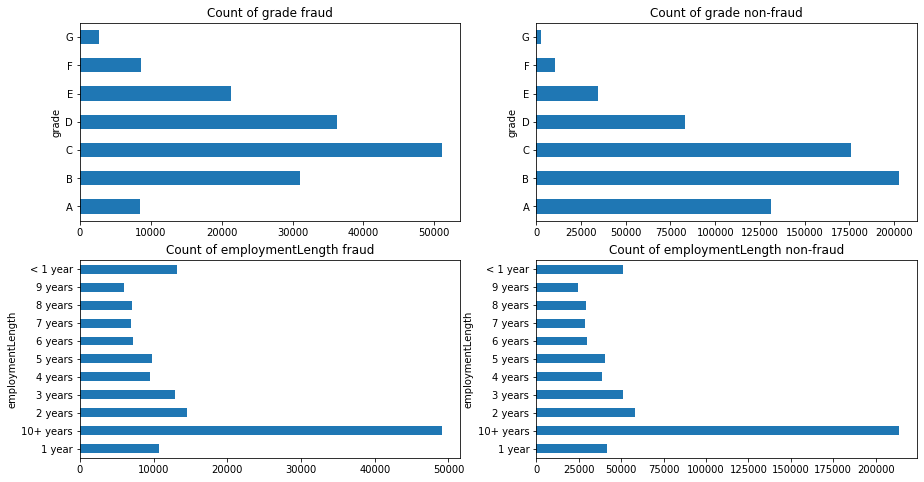
- 其次查看连续型变量在不同y值上的分布
|
||||
@@ -1408,7 +1409,7 @@ data_train.loc[data_train['isDefault'] == 0] \
|
||||
|
||||
|
||||
|
||||
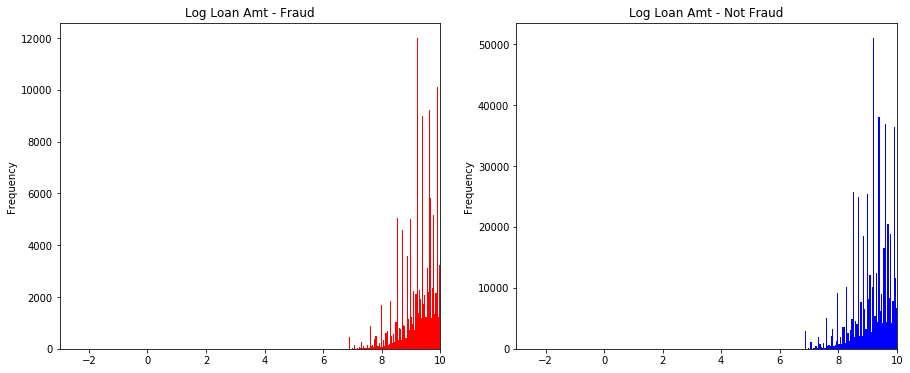
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1444,14 +1445,14 @@ for p in plot_tr_2.patches:
|
||||
```
|
||||
|
||||
|
||||
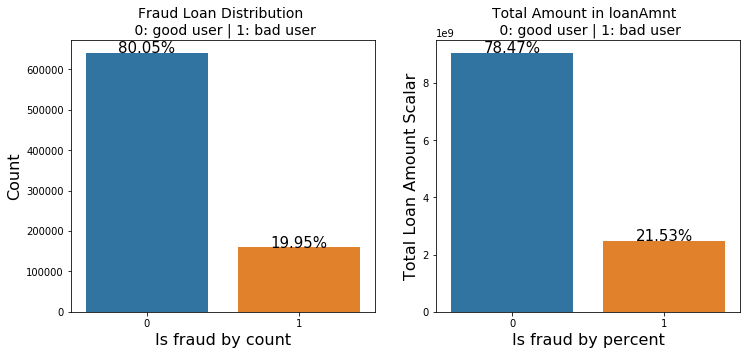
|
||||
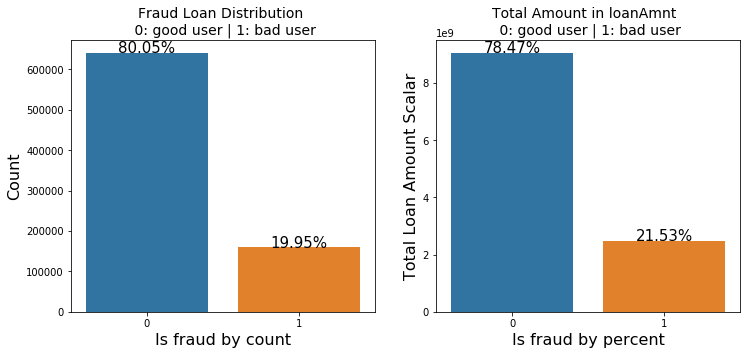
|
||||
|
||||
|
||||
### 2.3.7 时间格式数据处理及查看
|
||||
### 2.3.6 时间格式数据处理及查看
|
||||
|
||||
|
||||
```python
|
||||
#转化成时间格式
|
||||
#转化成时间格式 issueDateDT特征表示数据日期离数据集中日期最早的日期(2007-06-01)的天数
|
||||
data_train['issueDate'] = pd.to_datetime(data_train['issueDate'],format='%Y-%m-%d')
|
||||
startdate = datetime.datetime.strptime('2007-06-01', '%Y-%m-%d')
|
||||
data_train['issueDateDT'] = data_train['issueDate'].apply(lambda x: x-startdate).dt.days
|
||||
@@ -1475,10 +1476,10 @@ plt.title('Distribution of issueDateDT dates');
|
||||
```
|
||||
|
||||
|
||||
|
||||
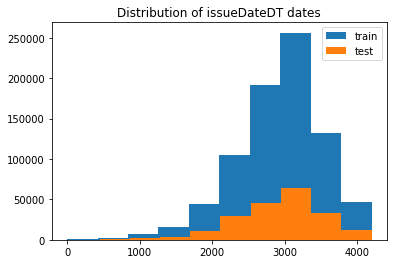
|
||||
|
||||
|
||||
### 2.3.8 掌握透视图可以让我们更好的了解数据
|
||||
### 2.3.7 掌握透视图可以让我们更好的了解数据
|
||||
|
||||
|
||||
```python
|
||||
@@ -1743,7 +1744,7 @@ pivot
|
||||
|
||||
|
||||
|
||||
### 2.3.9 用pandas_profiling生成数据报告
|
||||
### 2.3.8 用pandas_profiling生成数据报告
|
||||
|
||||
|
||||
```python
|
||||
@@ -1764,11 +1765,12 @@ END.
|
||||
【 言溪:Datawhale成员,金融风控爱好者。知乎地址:https://www.zhihu.com/people/exuding】
|
||||
|
||||
关于Datawhale:
|
||||
|
||||
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale 以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
|
||||
|
||||
本次数据挖掘路径学习,专题知识将在天池分享,详情可关注Datawhale:
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
```python
|
||||
|
||||
```
|
||||
|
||||
@@ -1,16 +1,14 @@
|
||||
# Task5 模型融合
|
||||
## Task5 模型融合
|
||||
|
||||
Tip:此部分为零基础入门金融风控的 Task5 模型融合部分,欢迎大家后续多多交流。
|
||||
赛题:零基础入门数据挖掘 - 零基础入门金融风控之贷款违约预测
|
||||
地址:https://tianchi.aliyun.com/competition/entrance/531830/introduction
|
||||
|
||||
## 5.1 学习目标
|
||||
地址:
|
||||
|
||||
### 5.1 学习目标
|
||||
将之前建模调参的结果进行模型融合。
|
||||
尝试多种融合方案,提交融合结果并打卡。(模型融合一般用于A榜比赛的尾声和B榜比赛的全程)
|
||||
|
||||
## 5.2 内容介绍
|
||||
|
||||
### 5.2 内容介绍
|
||||
模型融合是比赛后期上分的重要手段,特别是多人组队学习的比赛中,将不同队友的模型进行融合,可能会收获意想不到的效果哦,往往模型相差越大且模型表现都不错的前提下,模型融合后结果会有大幅提升,以下是模型融合的方式。
|
||||
- 平均:
|
||||
- 简单平均法
|
||||
@@ -24,41 +22,37 @@ Tip:此部分为零基础入门金融风控的 Task5 模型融合部分,欢迎
|
||||
- stacking:
|
||||
- 构建多层模型,并利用预测结果再拟合预测。
|
||||
- blending:
|
||||
- 选取部分数据预测训练得到预测结果作为新特征,带入剩下的数据中预测。Blending只有一层,而Stacking有多层
|
||||
- 选取部分数据预测训练得到预测结果作为新特征,带入剩下的数据中预测。
|
||||
- boosting/bagging(在Task4中已经提及,就不再赘述)
|
||||
|
||||
|
||||
## 5.3 stacking\blending详解
|
||||
### 5.3 stacking\blending详解
|
||||
|
||||
- stacking
|
||||
将若干基学习器获得的预测结果,将预测结果作为新的训练集来训练一个学习器。如下图 假设有五个基学习器,将数据带入五基学习器中得到预测结果,再带入模型六中进行训练预测。但是由于直接由五个基学习器获得结果直接带入模型六中,容易导致过拟合。所以在使用五个及模型进行预测的时候,可以考虑使用K折验证,防止过拟合。
|
||||
|
||||

|
||||
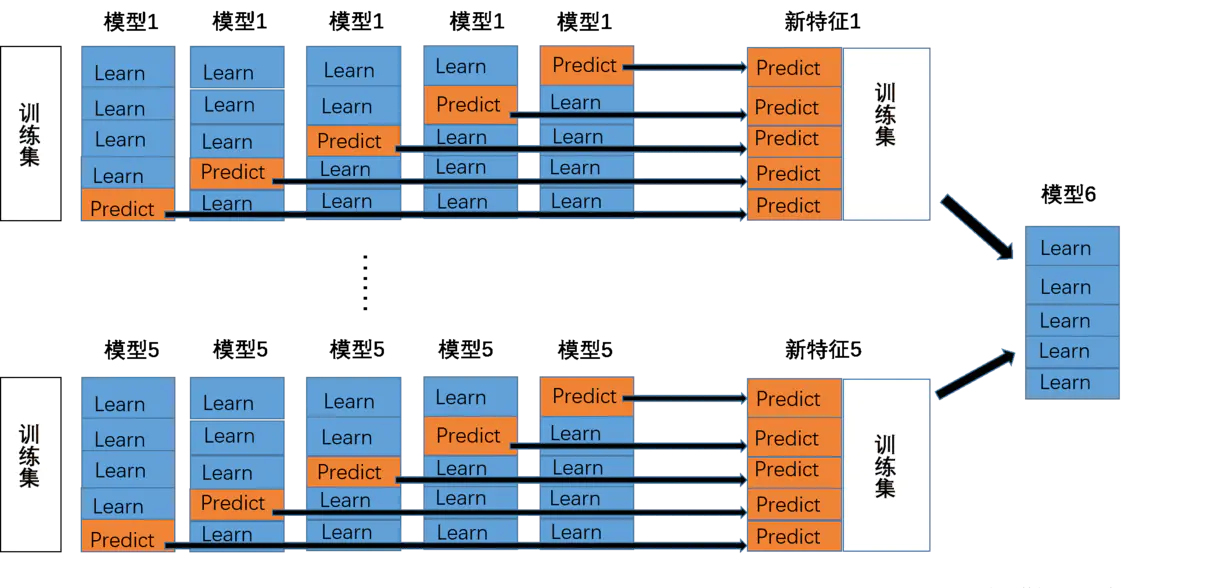
|
||||
|
||||
- blending
|
||||
与stacking不同,blending是将预测的值作为新的特征和原特征合并,构成新的特征值,用于预测。为了防止过拟合,将数据分为两部分d1、d2,使用d1的数据作为训练集,d2数据作为测试集。预测得到的数据作为新特征使用d2的数据作为训练集结合新特征,预测测试集结果。
|
||||
|
||||

|
||||
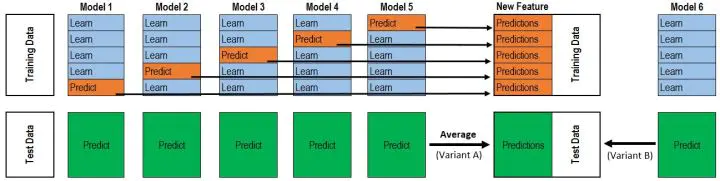
|
||||
|
||||
- Blending与stacking的不同
|
||||
- stacking
|
||||
- stacking中由于两层使用的数据不同,所以可以避免信息泄露的问题。
|
||||
- 在组队竞赛的过程中,不需要给队友分享自己的随机种子。
|
||||
- Blending
|
||||
- blending比stacking简单,不需要构建多层模型。
|
||||
- 由于blending对将数据划分为两个部分,在最后预测时有部分数据信息将被忽略。
|
||||
- 同时在使用第二层数据时可能会因为第二层数据较少产生过拟合现象。
|
||||
|
||||
|
||||
|
||||
参考资料:还是没有理解透彻吗?可以查看参考资料进一步了解哦!
|
||||
|
||||
https://blog.csdn.net/wuzhongqiang/article/details/105012739
|
||||
|
||||
## 5.4 代码示例
|
||||
|
||||
### 5.4 代码示例
|
||||
### 5.4.1 平均:
|
||||
|
||||
- 简单加权平均,结果直接融合
|
||||
求多个预测结果的平均值。pre1-pren分别是n组模型预测出来的结果,将其进行加权融
|
||||
|
||||
@@ -180,10 +174,10 @@ plt.show()
|
||||
|
||||
|
||||
|
||||
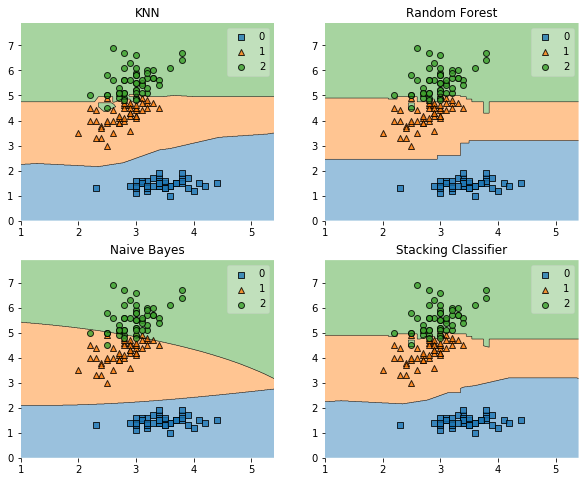
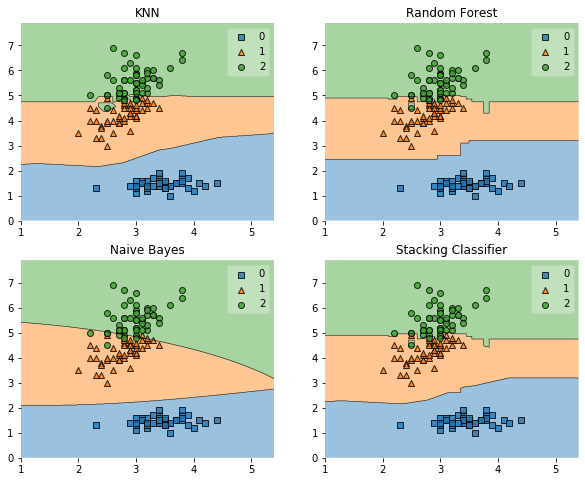
|
||||
|
||||
|
||||
|
||||
### 5.4.4 blending
|
||||
### 5.4.2 blending
|
||||
|
||||
|
||||
```python
|
||||
@@ -228,17 +222,17 @@ print("Val auc Score of Blending: %f" % (roc_auc_score(y_predict, y_submission))
|
||||
|
||||
```
|
||||
|
||||
## 5.5 经验总结
|
||||
### 5.5 经验总结
|
||||
- 简单平均和加权平均是常用的两种比赛中模型融合的方式。其优点是快速、简单。
|
||||
- stacking在众多比赛中大杀四方,但是跑过代码的小伙伴想必能感受到速度之慢,同时stacking多层提升幅度并不能抵消其带来的时间和内存消耗,所以实际环境中应用还是有一定的难度,同时在有答辩环节的比赛中,主办方也会一定程度上考虑模型的复杂程度,所以说并不是模型融合的层数越多越好的。
|
||||
- 当然在比赛中将加权平均、stacking、blending等混用也是一种策略,可能会收获意想不到的效果哦!
|
||||
|
||||
END.
|
||||
【 杨冰楠:Datawhale成员,金融风控爱好者。】
|
||||
|
||||
|
||||
---
|
||||
关于Datawhale:
|
||||
|
||||
> Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale 以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
|
||||
|
||||
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale 以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
|
||||
本次数据挖掘路径学习,专题知识将在天池分享,详情可关注Datawhale:
|
||||
|
||||

|
||||

|
||||
|
||||
Reference in New Issue
Block a user