update the position of imgs
This commit is contained in:
@@ -77,7 +77,7 @@
|
||||
- BST
|
||||
- **多任务学习**
|
||||
- [多任务学习概述](ch02/ch2.2/ch2.2.5/多任务学习概述)
|
||||
- [ESMM](ch02/ch2.2/ch2.2.5/ESSM)
|
||||
- [ESMM](ch02/ch2.2/ch2.2.5/ESMM)
|
||||
- [MMOE](ch02/ch2.2/ch2.2.5/MMOE)
|
||||
- [PLE](ch02/ch2.2/ch2.2.5/PLE)
|
||||
|
||||
|
||||
@@ -52,7 +52,7 @@
|
||||
- BST
|
||||
- 2.2.5 多任务学习
|
||||
- [多任务学习概述](ch02/ch2.2/ch2.2.5/多任务学习概述)
|
||||
- [ESMM](ch02/ch2.2/ch2.2.5/ESSM)
|
||||
- [ESMM](ch02/ch2.2/ch2.2.5/ESMM)
|
||||
- [MMOE](ch02/ch2.2/ch2.2.5/MMOE)
|
||||
- [PLE](ch02/ch2.2/ch2.2.5/PLE)
|
||||
- 第三章 推荐系统实战
|
||||
|
||||
@@ -6,7 +6,13 @@
|
||||
|
||||
传统的CVR预估问题存在着两个主要的问题:**样本选择偏差**和**稀疏数据**。下图的白色背景是曝光数据,灰色背景是点击行为数据,黑色背景是购买行为数据。传统CVR预估使用的训练样本仅为灰色和黑色的数据。
|
||||
|
||||
<div align=center>
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-2f0df0f6933dd8405c478fcce91f7b6f_1440w.jpg" alt="img" style="zoom:33%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
这会导致两个问题:
|
||||
|
||||
@@ -28,21 +34,35 @@
|
||||
|
||||
三个任务之间的关系为:
|
||||
|
||||
<img src="https://pic1.zhimg.com/80/v2-7bbeb8767db5d6a157852c8cd4221548_1440w.jpg" alt="img" style="zoom: 50%;" />
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-7bbeb8767db5d6a157852c8cd4221548_1440w.jpg" alt="img" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
其中x表示曝光,y表示点击,z表示转化。针对这三个任务,设计了如图所示的模型结构:
|
||||
|
||||
<img src="https://pic1.zhimg.com/80/v2-6d8189bfe378dc4bf6f0db2ba0255eac_1440w.jpg" alt="img" style="zoom:67%;" />
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-6d8189bfe378dc4bf6f0db2ba0255eac_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
如图,主任务和辅助任务共享特征,不同任务输出层使用不同的网络,将cvr的预测值*ctr的预测值作为ctcvr任务的预测值,利用ctcvr和ctr的label构造损失函数:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic3.zhimg.com/80/v2-0098ab4556a8c67a1c12322ea3f89606_1440w.jpg" alt="img" style="zoom: 33%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
该架构具有两大特点,分别给出上述两个问题的解决方案:
|
||||
|
||||
- 帮助CVR模型在完整样本空间建模(即曝光空间X)。
|
||||
|
||||
<img src="https://pic1.zhimg.com/80/v2-0b0c6dc7d4c38fa422a2876b7c4cc638_1440w.jpg" alt="img" style="zoom:33%;" />
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-0b0c6dc7d4c38fa422a2876b7c4cc638_1440w.jpg" alt="img" style="zoom:33%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
从公式中可以看出,pCVR 可以由pCTR 和pCTCVR推导出。从原理上来说,相当于分别单独训练两个模型拟合出p CTR 和pCTCVR,再通过pCTCVR 除以pCTR 得到最终的拟合目标pCVR 。
|
||||
在训练过程中,模型只需要预测pCTCVR和pCTR,利用两种相加组成的联合loss更新参数。pCVR 只是一个中间变 量。而pCTCVR和pCTR的数据是在完整样本空间中提取的,从而相当于pCVR也是在整个曝光样本空间中建模。
|
||||
@@ -57,8 +77,10 @@
|
||||
|
||||
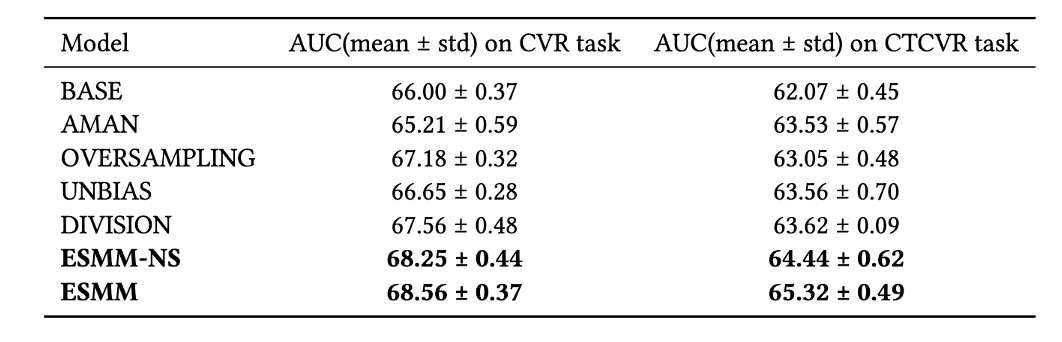
1. 能不能将乘法换成除法?
|
||||
即分别训练CTR和CTCVR模型,两者相除得到pCVR。论文提供了消融实验的结果,表中的DIVISION模型,比起BASE模型直接建模CTCVRR和CVR,有显著提高,但低于ESMM。原因是pCTR 通常很小,除以一个很小的浮点数容易引起数值不稳定问题。
|
||||
|
||||
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic3.zhimg.com/80/v2-c0b2c860bd63a680d27c911c2e1ba8a2_1440w.jpg" alt="img" style="zoom:53%;" />
|
||||
</div>
|
||||
|
||||
2. 网络结构优化,Tower模型更换?两个塔不一致?
|
||||
原论文中的子任务独立的Tower网络是纯MLP模型,事实上业界在使用过程中一般会采用更为先进的模型(例如DeepFM、DIN等),两个塔也完全可以根据自身特点设置不一样的模型。这也是ESMM框架的优势,子网络可以任意替换,非常容易与其他学习模型集成。
|
||||
@@ -71,15 +93,21 @@
|
||||
|
||||
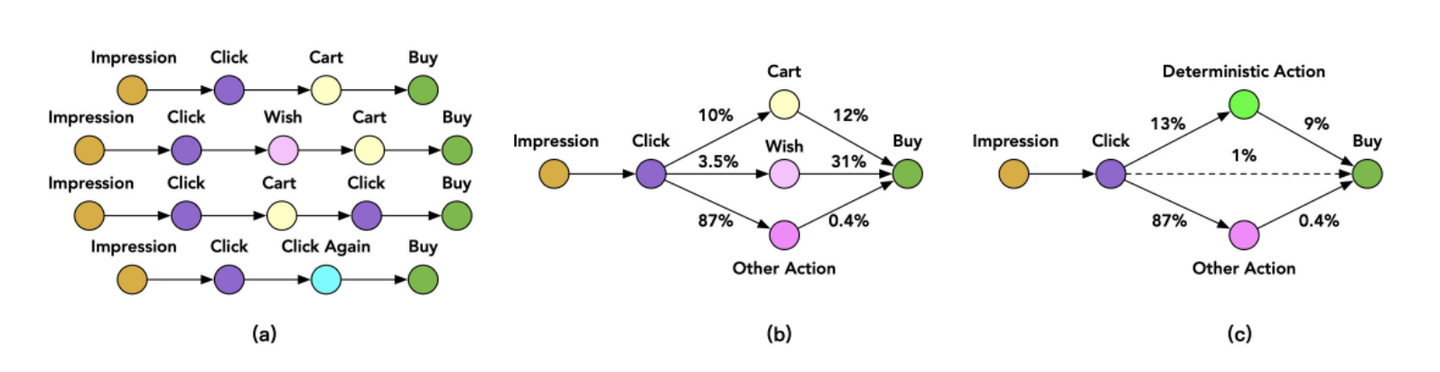
- 阿里的ESMM2: 在点击到购买之前,用户还有可能产生加入购物车(Cart)、加入心愿单(Wish)等行为。
|
||||
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-4f9f5508412086315f85d1b7fda733e9_1440w.jpg" alt="img" style="zoom:53%;" />
|
||||
</div>
|
||||
|
||||
相较于直接学习 click->buy (稀疏度约2.6%),可以通过Action路径将目标分解,以Cart为例:click->cart (稀疏度为10%),cart->buy(稀疏度为12%),通过分解路径,建立多任务学习模型来分步求解CVR模型,缓解稀疏问题,该模型同样也引入了特征共享机制。
|
||||
相较于直接学习 click->buy (稀疏度约2.6%),可以通过Action路径将目标分解,以Cart为例:click->cart (稀疏度为10%),cart->buy(稀疏度为12%),通过分解路径,建立多任务学习模型来分步求解CVR模型,缓解稀疏问题,该模型同样也引入了特征共享机制。
|
||||
|
||||
- 美团的[AITM](https://zhuanlan.zhihu.com/p/508876139/[https://cloud.tencent.com/developer/article/1868117](https://cloud.tencent.com/developer/article/1868117)):信用卡业务中,用户转化通常是一个**曝光->点击->申请->核卡->激活**的过程,具有5层的链路。
|
||||
5. - 美团的[AITM](https://zhuanlan.zhihu.com/p/508876139/[https://cloud.tencent.com/developer/article/1868117](https://cloud.tencent.com/developer/article/1868117)):信用卡业务中,用户转化通常是一个**曝光->点击->申请->核卡->激活**的过程,具有5层的链路。
|
||||
|
||||
<img src="https://pic4.zhimg.com/80/v2-0ecf42e999795511f40ac6cd7b85eccf_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
|
||||
美团提出了一种自适应信息迁移多任务(**Adaptive Information Transfer Multi-task,AITM**)框架,该框架通过自适应信息迁移(AIT)模块对用户多步转化之间的序列依赖进行建模。AIT模块可以自适应地学习在不同的转化阶段需要迁移什么和迁移多少信息。
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-0ecf42e999795511f40ac6cd7b85eccf_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
美团提出了一种自适应信息迁移多任务(**Adaptive Information Transfer Multi-task,AITM**)框架,该框架 通过自适应信息迁移(AIT)模块对用户多步转化之间的序列依赖进行建模。AIT模块可以自适应地学习在 不同的转化阶段需要迁移什么和迁移多少信息。
|
||||
|
||||
总结:
|
||||
|
||||
|
||||
@@ -32,8 +32,10 @@ PLE将共享的部分和每个任务特定的部分**显式的分开**,强化
|
||||
|
||||
网络结构如图所示,同样的特征输入分别送往三类不同的专家模型(任务A专家、任务B专家、任务共享专家),再通过门控机制加权聚合之后输入各自的Tower网络。门控网络,把原始数据和expert网络输出共同作为输入,通过单层全连接网络+softmax激活函数,得到分配给expert的加权权重,与attention机制类型。
|
||||
|
||||
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic3.zhimg.com/80/v2-c92975f7c21cc568a13cd9447adc757a_1440w.jpg" style="zoom:50%;" />
|
||||
<img src="https://pic3.zhimg.com/80/v2-c92975f7c21cc568a13cd9447adc757a_1440w.jpg" style="zoom:40%;" />
|
||||
</div>
|
||||
|
||||
任务A有 ![[公式]](https://www.zhihu.com/equation?tex=m_A) 个expert,任务B有 ![[公式]](https://www.zhihu.com/equation?tex=m_B) 个expert,另外还有 ![[公式]](https://www.zhihu.com/equation?tex=m_S) 个任务A、B共享的Expert。这样对Expert做一个显式的分割,可以让task-specific expert只受自己任务梯度的影响,不会受到其他任务的干扰(每个任务保底有一个独立的网络模型),而只有task-shared expert才受多个任务的混合梯度影响。
|
||||
@@ -45,7 +47,7 @@ MMOE则是将所有Expert一视同仁,都加权输入到每一个任务的Towe
|
||||
PLE就是上述CGC网络的多层纵向叠加,以获得更加丰富的表征能力。在分层的机制下,Gate设计成两种类型,使得不同类型Expert信息融合交互。task-share gate融合所有Expert信息,task-specific gate只融合specific expert和share expert。模型结构如图:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-ff3b4aff3511e6e56a3b509f244c5ab1_1440w.jpg" style="zoom:50%;" />
|
||||
<img src="https://pic2.zhimg.com/80/v2-ff3b4aff3511e6e56a3b509f244c5ab1_1440w.jpg" style="zoom:40%;" />
|
||||
</div>
|
||||
|
||||
将任务A、任务B和shared expert的输出输入到下一层,下一层的gate是以这三个上一层输出的结果作为门控的输入,而不是用原始input特征作为输入。这使得gate同时融合task-shares expert和task-specific expert的信息,论文实验中证明这种不同类型expert信息的交叉,可以带来更好的效果。
|
||||
@@ -55,28 +57,32 @@ PLE就是上述CGC网络的多层纵向叠加,以获得更加丰富的表征
|
||||
该论文专门讨论了loss设计的问题。在传统的多任务学习模型中,多任务的loss一般为
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-ec1a0ae2a4001fea296662a9a5a1942b_1440w.jpg" style="zoom:50%;" />
|
||||
<img src="https://pic4.zhimg.com/80/v2-ec1a0ae2a4001fea296662a9a5a1942b_1440w.jpg" style="zoom:33%;" />
|
||||
</div>
|
||||
|
||||
其中K是指任务数, ![[公式]](https://www.zhihu.com/equation?tex=w_k) 是每个任务各自对应的权重。这种loss存在两个关键问题:
|
||||
|
||||
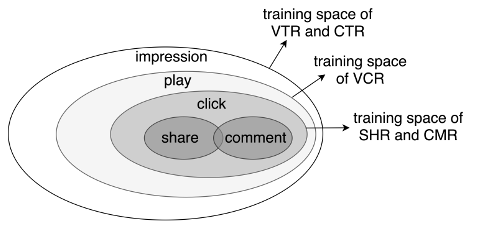
- 不同任务之间的样本空间不一致:在视频推荐场景中,目标之间的依赖关系如图,曝光→播放→点击→(分享、评论),不同任务有不同的样本空间。
|
||||
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic3.zhimg.com/80/v2-bdf39ef6fcaf000924294cb010642fce_1440w.jpg" style="zoom:63%;" />
|
||||
</div>
|
||||
|
||||
PLE将训练样本空间作为全部任务样本空间的并集,在分别针对每个任务算loss时,只考虑该任务的样本的空间,一般需对这种数据集会附带一个样本空间标签。loss公式如下:
|
||||
|
||||
|
||||
PLE将训练样本空间作为全部任务样本空间的并集,在分别针对每个任务算loss时,只考虑该任务的样本的空 间,一般需对这种数据集会附带一个样本空间标签。loss公式如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-8defd1e5d1ba896bb2d18bdb1db4e3cd_1440w.jpg" style="zoom:50%;" />
|
||||
<img src="https://pic2.zhimg.com/80/v2-8defd1e5d1ba896bb2d18bdb1db4e3cd_1440w.jpg" style="zoom:40%;" />
|
||||
</div>
|
||||
|
||||
|
||||
其中, ![[公式]](https://www.zhihu.com/equation?tex=%5Cdelta_%7Bk%7D%5E%7Bi%7D+%5Cin%5C%7B0%2C1%5C%7D%2C+%5Cdelta_%7Bk%7D%5E%7Bi%7D+) 表示样本i是否处于任务k的样本空间。
|
||||
其中, ![[公式]](https://www.zhihu.com/equation?tex=%5Cdelta_%7Bk%7D%5E%7Bi%7D+%5Cin%5C%7B0%2C1%5C%7D%2C+%5Cdelta_%7Bk%7D%5E%7Bi%7D+) 表示样本i是否处于任务k的样本空间。
|
||||
|
||||
- 不同任务各自独立的权重设定:PLE提出了一种加权的规则,它的思想是随着迭代次数的增加,任务的权重应当不断衰减。它为每个任务设定一个初始权重 ![[公式]](https://www.zhihu.com/equation?tex=w_%7Bk%2C0%7D) ,再按该公式进行更新:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-2fbd23599bd2cd62222607e76cb975ec_1440w.jpg" style="zoom:50%;" />
|
||||
<img src="https://pic1.zhimg.com/80/v2-2fbd23599bd2cd62222607e76cb975ec_1440w.jpg" style="zoom:40%;" />
|
||||
</div>
|
||||
|
||||
## 实验
|
||||
@@ -85,23 +91,39 @@ PLE将训练样本空间作为全部任务样本空间的并集,在分别针
|
||||
|
||||
第一组实验是两个关系复杂的任务VTR(回归)与VCR(分类),如表1,实验结果证明PLE可以实现多任务共赢,而其他的硬共享或者软共享机制,则会导致部分任务受损。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-4a190a8a3bcd810fbe1e810171ddc25c_1440w.jpg" alt="img" style="zoom: 33%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
第二组实验是两个关系简单清晰的任务,CTR与VCR,都是分类任务,且CTR→VCR存在任务依赖关系,如表2,这种多任务下,基本上所有参数共享的模型都能得到性能的提升,而PLE的提升效果最为明显。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-29baaf461d29a4eff32e7ea324ef7f77_1440w.jpg" alt="img" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
第三组实验则是线上的A/B Test,上面两组离线实验中,其实PLE相比于其他baseline模型,无论是回归任务的mse,还是分类任务的auc,提升都不是特别显著。在推荐场景中,评估模型性能的最佳利器还是线上的A/B Test。作者在pcg视频推荐的场景中,将部分用户随机划分到不同的实验组中,用PLE模型预估VTR和VCR,进行四周的实验。如表3所示,线上评估指标(总播放完成视频数量和总播放时间)均得到了较为显著的提升,而硬参数共享模型则带对两个指标都带来显著的下降。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic3.zhimg.com/80/v2-d6daf1d58fa5edd9fa96aefd254f71ee_1440w.jpg" alt="img" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
第四组实验中,作者引入了更多的任务,论文PLE分层结构的必要性。如表4,随着任务数量的增加,PLE对比CGC的优势更加显著。
|
||||
第四组实验中,作者引入了更多的任务,验证PLE分层结构的必要性。如表4,随着任务数量的增加,PLE对比CGC的优势更加显著。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-0b13558bc7e95f601c60a26deaff9acf_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
文中也设计实验,单独对MMOE和CGC的专家利用率进行对比分析,为了实现方便和公平,每个expert都是一个一层网络,每个expert module都只有一个expert,每一层只有3个expert。如图所示,柱子的高度和竖直短线分别表示expert权重的均值和方差。
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic4.zhimg.com/80/v2-557473be41f7f6fa5efc1ff17e21bab7_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
可以看到,无论是 MMoE 还是 ML-MMoE,不同任务在三个 Expert 上的权重都是接近的,但对于 CGC & PLE 来说,不同任务在共享 Expert 上的权重是有较大差异的。PLE针对不同的任务,能够有效利用共享 Expert 和独有 Expert 的信息,解释了为什么其能够达到比 MMoE 更好的训练结果。CGC理论上是MMOE的子集,该实验表明,现实中MMOE很难收敛成这个CGC的样子,所以PLE模型就显式的规定了CGC这样的结构。
|
||||
|
||||
@@ -113,7 +135,11 @@ CGC在结构上设计的分化,实现了专家功能的分化,而PLE则是
|
||||
|
||||
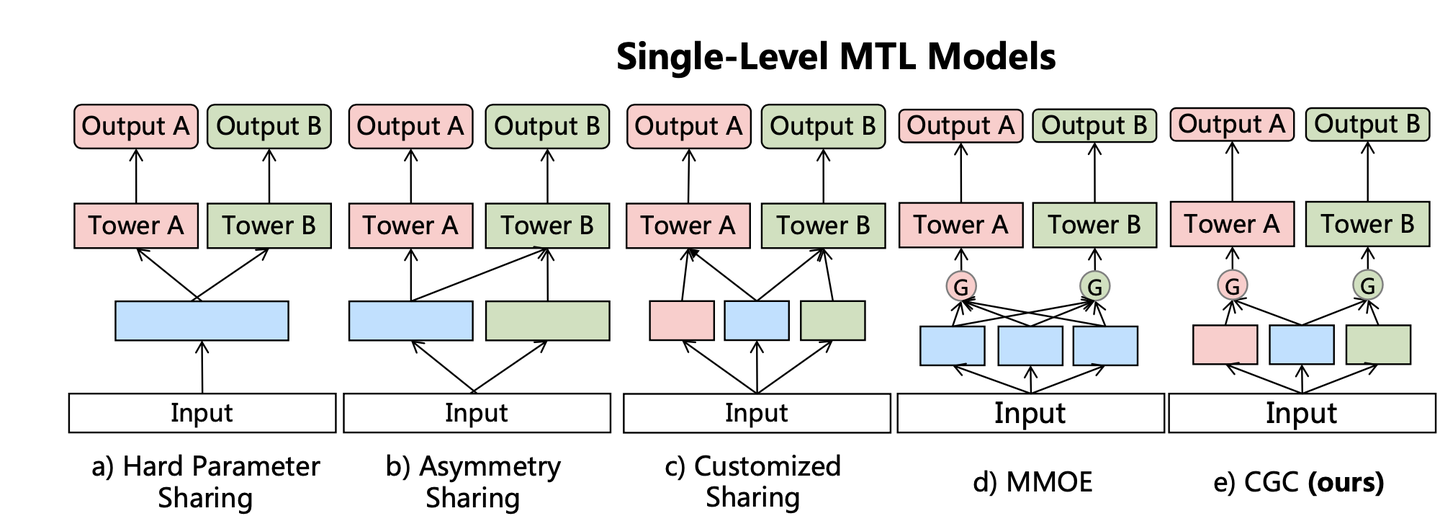
论文中也对大多数的MTL模型进行了抽象,总结如下图:
|
||||
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-d607cd8e14d4a0fadb4dbef06dc2ffa9_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
不同的MTL模型即不同的参数共享机制,CGC的结构最为灵活。
|
||||
|
||||
@@ -121,16 +147,20 @@ CGC在结构上设计的分化,实现了专家功能的分化,而PLE则是
|
||||
|
||||
1. 多任务模型线上如何打分融合?
|
||||
在论文中,作者分享了腾讯视频的一种线上打分机制
|
||||
|
||||
<img src="https://pic2.zhimg.com/80/v2-9a412b82d45877287df2429fc89afac5_1440w.jpg" alt="img" style="zoom:33%;" />
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-9a412b82d45877287df2429fc89afac5_1440w.jpg" alt="img" style="zoom:33%;" />
|
||||
</div>
|
||||
|
||||
每个目标的预估值有一个固定的权重,通过乘法进行融合,并在最后未来排除视频自身时长的影响,使用 $ f(videolen)$对视频时长进行了非线性变化。其实在业界的案例中,也基本是依赖乘法或者加法进行融合,爱奇艺曾经公开分享过他们使用过的打分方法:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic1.zhimg.com/80/v2-661030ad194ae2059eace0804ef0f774_1440w.jpg" alt="img" style="zoom: 67%;" />
|
||||
</div>
|
||||
|
||||
|
||||
每个目标的预估值有一个固定的权重,通过乘法进行融合,并在最后未来排除视频自身时长的影响,使用f(videolen)对视频时长进行了非线性变化。
|
||||
其实在业界的案例中,也基本是依赖乘法或者加法进行融合,爱奇艺曾经公开分享过他们使用过的打分方法:
|
||||
|
||||
<img src="https://pic1.zhimg.com/80/v2-661030ad194ae2059eace0804ef0f774_1440w.jpg" alt="img" style="zoom: 67%;" />
|
||||
|
||||
在业务目标较少时,通过加法方式融合新增目标可以短期内快速获得收益。但是随着目标增多,加法融合会逐步弱化各字母表的重要性影响,而乘法融合则具有一定的模板独立性,乘法机制更加灵活,效益更好。融合的权重超参一般在线上通过A/B test调试。
|
||||
在业务目标较少时,通过加法方式融合新增目标可以短期内快速获得收益。但是随着目标增多,加法融合会 逐步弱化各字母表的重要性影响,而乘法融合则具有一定的模板独立性,乘法机制更加灵活,效益更好。融 合的权重超参一般在线上通过A/B test调试。
|
||||
|
||||
2. 专家的参数如何设置?
|
||||
PLE模型存在的超参数较多,其中专家和门控网络都有两种类型。一般来说,task-specific expert每个任务1-2个,shared expert个数在任务个数的1倍以上。原论文中的gate网络即单层FC,可以适当增加,调试。
|
||||
@@ -143,7 +173,11 @@ CGC在结构上设计的分化,实现了专家功能的分化,而PLE则是
|
||||
|
||||
- 而在业界的实践案例中,更多的是两种范式的模型进行融合。例如美团在其搜索多业务排序场景上提出的模型:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-af16e969a0149aef9c2a1291de5c65d5_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
总框架是ESMM的架构,以建模下单(CVR)为主任务,CTR和CTCVR为辅助任务。在底层的模块中,则使用了CGC模块,提取多任务模式下的特征表达信息。
|
||||
|
||||
@@ -151,9 +185,13 @@ CGC在结构上设计的分化,实现了专家功能的分化,而PLE则是
|
||||
MMOE、PLE原论文中介绍的模型均是使用同样的原始特征输入各个不同的expert,也输入给第一层的gate。最顶层的Tower网络中则均是由一个gate融合所有expert输出作为输入。在实践中,可以根据业务需求进行调整。
|
||||
|
||||
- 例如上图中美团提出的模型,在CTR的tower下,设置了五个子塔:闪购子网络、买菜子网络、外卖子网络、优选子网络和团好货子网络,并且对不同的子塔有额外输入不同的特征。
|
||||
对于底层的输入给expert的特征,美团提出通过增加一个自适应的特征选择门,使得选出的特征对不同的业务权重不同。在美团业务组,例如“配送时间”这个特征对闪购业务比较重要,但对于团好货影响不是很大。模型结构如图:
|
||||
对于底层输入给expert的特征,美团提出通过增加一个自适应的特征选择门,使得选出的特征对不同的业务权重不同。例如“配送时间”这个特征对闪购业务比较重要,但对于团好货影响不是很大。模型结构如图:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://pic2.zhimg.com/80/v2-2e2370794bbd69ded636a248d8c36255_1440w.jpg" alt="img" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
特征选择门与控制expert信息融合的gate类似,由一层FC和softmax组成,输出是特征维度的权重。对于每一个特征通过该门都得到一个权重向量,权重向量点乘原始特征的embedding作为expert的输入。
|
||||
|
||||
|
||||
@@ -53,12 +53,12 @@
|
||||
## loss加权融合
|
||||
|
||||
一种最简单的实现多任务学习的方式是对不同任务的loss进行加权。例如谷歌的Youtube DNN论文中提到的一种加权交叉熵:
|
||||
|
||||
![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Bequation%7D+%5Ctext+%7B+Weighted+CE+Loss+%7D%3D-%5Csum_%7Bi%7D%5Cleft%5BT_%7Bi%7D+y_%7Bi%7D+%5Clog+p_%7Bi%7D%2B%5Cleft%281-y_%7Bi%7D%5Cright%29+%5Clog+%5Cleft%281-p_%7Bi%7D%5Cright%29%5Cright%5D+%5Cend%7Bequation%7D)
|
||||
|
||||
$$
|
||||
\text { Weighted CE Loss }=-\sum_{i}\left[T_{i} y_{i} \log p_{i}+\left(1-y_{i}\right) \log \left(1-p_{i}\right)\right]
|
||||
$$
|
||||
其中![[公式]](https://www.zhihu.com/equation?tex=T_i) 为观看时长。在原始训练数据中,正样本是视频展示后用户点击了该视频,负样本则是展示后未点击,这个一个标准的CTR预估问题。该loss通过改变训练样本的权重,让所有负样本的权重都为 1,而正样本的权重为点击后的视频观看时长 ![[公式]](https://www.zhihu.com/equation?tex=T_i) 。作者认为按点击率排序会倾向于把诱惑用户点击(用户未必真感兴趣)的视频排前面,而观看时长能更好地反映出用户对视频的兴趣,通过重新设计loss使得该模型在保证主目标点击的同时,将视频观看时长转化为样本的权重,达到优化平均观看时长的效果。
|
||||
|
||||
另一种更为简单粗暴的加权方式是人工手动调整权重,例如 ![[公式]](https://www.zhihu.com/equation?tex=0.3L%2AL%28%E7%82%B9%E5%87%BB%29%2B0.7%2AL%28%E8%A7%86%E9%A2%91%E5%AE%8C%E6%92%AD%29) 。
|
||||
另一种更为简单粗暴的加权方式是人工手动调整权重,例如 0.3\*L(点击)+0.7*L\*(视频完播)
|
||||
|
||||
这种loss加权的方式优点如下:
|
||||
|
||||
|
||||
Reference in New Issue
Block a user