添加多任务学习模块
This commit is contained in:
112
codes/CGC.py
Normal file
112
codes/CGC.py
Normal file
@@ -0,0 +1,112 @@
|
||||
"""
|
||||
Reference:
|
||||
[1] Tang H, Liu J, Zhao M, et al. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations[C]//Fourteenth ACM Conference on Recommender Systems. 2020.(https://arxiv.org/abs/1804.07931)
|
||||
"""
|
||||
import tensorflow as tf
|
||||
|
||||
from deepctr.feature_column import build_input_features, input_from_feature_columns
|
||||
from deepctr.layers.core import PredictionLayer, DNN
|
||||
from deepctr.layers.utils import combined_dnn_input, reduce_sum
|
||||
|
||||
def CGC(dnn_feature_columns, num_tasks=None, task_types=None, task_names=None, num_experts_specific=8, num_experts_shared=4,
|
||||
expert_dnn_units=[64,64], gate_dnn_units=None, tower_dnn_units_lists=[[16,16],[16,16]],
|
||||
l2_reg_embedding=1e-5, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False):
|
||||
"""Instantiates the Customized Gate Control block of Progressive Layered Extraction architecture.
|
||||
|
||||
:param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
|
||||
:param num_tasks: integer, number of tasks, equal to number of outputs, must be greater than 1.
|
||||
:param task_types: list of str, indicating the loss of each tasks, ``"binary"`` for binary logloss, ``"regression"`` for regression loss. e.g. ['binary', 'regression']
|
||||
:param task_names: list of str, indicating the predict target of each tasks
|
||||
|
||||
:param num_experts_specific: integer, number of task-specific experts.
|
||||
:param num_experts_shared: integer, number of task-shared experts.
|
||||
|
||||
:param expert_dnn_units: list, list of positive integer, its length must be greater than 1, the layer number and units in each layer of expert DNN
|
||||
:param gate_dnn_units: list, list of positive integer or None, the layer number and units in each layer of gate DNN, default value is None. e.g.[8, 8].
|
||||
:param tower_dnn_units_lists: list, list of positive integer list, its length must be euqal to num_tasks, the layer number and units in each layer of task-specific DNN
|
||||
|
||||
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
|
||||
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN
|
||||
:param seed: integer ,to use as random seed.
|
||||
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
|
||||
:param dnn_activation: Activation function to use in DNN
|
||||
:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN
|
||||
:return: a Keras model instance
|
||||
"""
|
||||
|
||||
if num_tasks <= 1:
|
||||
raise ValueError("num_tasks must be greater than 1")
|
||||
if len(task_types) != num_tasks:
|
||||
raise ValueError("num_tasks must be equal to the length of task_types")
|
||||
|
||||
for task_type in task_types:
|
||||
if task_type not in ['binary', 'regression']:
|
||||
raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
|
||||
|
||||
if num_tasks != len(tower_dnn_units_lists):
|
||||
raise ValueError("the length of tower_dnn_units_lists must be euqal to num_tasks")
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
|
||||
l2_reg_embedding, seed)
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
|
||||
expert_outputs = []
|
||||
#build task-specific expert layer
|
||||
for i in range(num_tasks):
|
||||
for j in range(num_experts_specific):
|
||||
expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='task_'+task_names[i]+'_expert_specific_'+str(j))(dnn_input)
|
||||
expert_outputs.append(expert_network)
|
||||
|
||||
#build task-shared expert layer
|
||||
for i in range(num_experts_shared):
|
||||
expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='expert_shared_'+str(i))(dnn_input)
|
||||
expert_outputs.append(expert_network)
|
||||
|
||||
#build one Extraction Layer
|
||||
cgc_outs = []
|
||||
for i in range(num_tasks):
|
||||
#concat task-specific expert and task-shared expert
|
||||
cur_expert_num = num_experts_specific + num_experts_shared
|
||||
cur_experts = expert_outputs[i * num_experts_specific:(i + 1) * num_experts_specific] + expert_outputs[-int(num_experts_shared):] #task_specific + task_shared
|
||||
expert_concat = tf.keras.layers.concatenate(cur_experts, axis=1, name='expert_concat_'+task_names[i])
|
||||
expert_concat = tf.keras.layers.Reshape([cur_expert_num, expert_dnn_units[-1]], name='expert_reshape_'+task_names[i])(expert_concat)
|
||||
|
||||
#build gate layers
|
||||
if gate_dnn_units!=None:
|
||||
gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='gate_'+task_names[i])(dnn_input)
|
||||
gate_input = gate_network
|
||||
else: #in origin paper, gate is one Dense layer with softmax.
|
||||
gate_input = dnn_input
|
||||
|
||||
gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax', name='gate_softmax_'+task_names[i])(gate_input)
|
||||
gate_out = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
#gate multiply the expert
|
||||
gate_mul_expert = tf.keras.layers.Multiply(name='gate_mul_expert_'+task_names[i])([expert_concat, gate_out])
|
||||
gate_mul_expert = tf.keras.layers.Lambda(lambda x: reduce_sum(x, axis=1, keep_dims=True))(gate_mul_expert)
|
||||
cgc_outs.append(gate_mul_expert)
|
||||
|
||||
task_outs = []
|
||||
for task_type, task_name, tower_dnn, cgc_out in zip(task_types, task_names, tower_dnn_units_lists, cgc_outs):
|
||||
#build tower layer
|
||||
tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(cgc_out)
|
||||
logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit)
|
||||
task_outs.append(output)
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=task_outs)
|
||||
return model
|
||||
|
||||
if __name__ == "__main__":
|
||||
from utils import get_mtl_data
|
||||
dnn_feature_columns, train_model_input, test_model_input, y_list = get_mtl_data()
|
||||
|
||||
model = CGC(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=['income','marital'],
|
||||
num_experts_specific=4, num_experts_shared=4, expert_dnn_units=[16], gate_dnn_units=None, tower_dnn_units_lists=[[8],[8]])
|
||||
model.compile("adam", loss=["binary_crossentropy", "binary_crossentropy"], metrics=['AUC'])
|
||||
history = model.fit(train_model_input, y_list, batch_size=256, epochs=5, verbose=2, validation_split=0.0 )
|
||||
|
||||
64
codes/ESSM.py
Normal file
64
codes/ESSM.py
Normal file
@@ -0,0 +1,64 @@
|
||||
"""
|
||||
Reference:
|
||||
[1] Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.(https://arxiv.org/abs/1804.07931)
|
||||
"""
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
from deepctr.feature_column import build_input_features, input_from_feature_columns
|
||||
from deepctr.layers.core import PredictionLayer, DNN
|
||||
from deepctr.layers.utils import combined_dnn_input
|
||||
|
||||
|
||||
def ESSM(dnn_feature_columns, task_type='binary', task_names=['ctr', 'ctcvr'],
|
||||
tower_dnn_units_lists=[[128, 128],[128, 128]], l2_reg_embedding=0.00001, l2_reg_dnn=0,
|
||||
seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False):
|
||||
"""Instantiates the Entire Space Multi-Task Model architecture.
|
||||
|
||||
:param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
|
||||
:param task_type: str, indicating the loss of each tasks, ``"binary"`` for binary logloss or ``"regression"`` for regression loss.
|
||||
:param task_names: list of str, indicating the predict target of each tasks. default value is ['ctr', 'ctcvr']
|
||||
|
||||
:param tower_dnn_units_lists: list, list of positive integer, the length must be equal to 2, the layer number and units in each layer of task-specific DNN
|
||||
|
||||
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
|
||||
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN
|
||||
:param seed: integer ,to use as random seed.
|
||||
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
|
||||
:param dnn_activation: Activation function to use in DNN
|
||||
:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN
|
||||
:return: A Keras model instance.
|
||||
"""
|
||||
if len(task_names)!=2:
|
||||
raise ValueError("the length of task_names must be equal to 2")
|
||||
|
||||
if len(tower_dnn_units_lists)!=2:
|
||||
raise ValueError("the length of tower_dnn_units_lists must be equal to 2")
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed)
|
||||
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
|
||||
ctr_output = DNN(tower_dnn_units_lists[0], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
|
||||
cvr_output = DNN(tower_dnn_units_lists[1], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
|
||||
|
||||
ctr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(ctr_output)
|
||||
cvr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(cvr_output)
|
||||
|
||||
ctr_pred = PredictionLayer(task_type, name=task_names[0])(ctr_logit)
|
||||
cvr_pred = PredictionLayer(task_type)(cvr_logit)
|
||||
|
||||
ctcvr_pred = tf.keras.layers.Multiply(name=task_names[1])([ctr_pred, cvr_pred])#CTCVR = CTR * CVR
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=[ctr_pred, ctcvr_pred])
|
||||
return model
|
||||
|
||||
if __name__ == "__main__":
|
||||
from utils import get_mtl_data
|
||||
dnn_feature_columns, train_model_input, test_model_input, y_list = get_mtl_data()
|
||||
model = ESSM(dnn_feature_columns, task_type='binary', task_names=['label_marital', 'label_income'], tower_dnn_units_lists=[[8],[8]])
|
||||
model.compile("adam", loss=["binary_crossentropy", "binary_crossentropy"], metrics=['AUC'])
|
||||
history = model.fit(train_model_input, y_list, batch_size=256, epochs=5, verbose=2, validation_split=0.0 )
|
||||
103
codes/MMOE.py
Normal file
103
codes/MMOE.py
Normal file
@@ -0,0 +1,103 @@
|
||||
"""
|
||||
Reference:
|
||||
[1] Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.(https://dl.acm.org/doi/abs/10.1145/3219819.3220007)
|
||||
"""
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
from deepctr.feature_column import build_input_features, input_from_feature_columns
|
||||
from deepctr.layers.core import PredictionLayer, DNN
|
||||
from deepctr.layers.utils import combined_dnn_input, reduce_sum
|
||||
|
||||
def MMOE(dnn_feature_columns, num_tasks=None, task_types=None, task_names=None, num_experts=4,
|
||||
expert_dnn_units=[32,32], gate_dnn_units=None, tower_dnn_units_lists=[[16,8],[16,8]],
|
||||
l2_reg_embedding=1e-5, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False):
|
||||
"""Instantiates the Multi-gate Mixture-of-Experts multi-task learning architecture.
|
||||
|
||||
:param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
|
||||
:param num_tasks: integer, number of tasks, equal to number of outputs, must be greater than 1.
|
||||
:param task_types: list of str, indicating the loss of each tasks, ``"binary"`` for binary logloss, ``"regression"`` for regression loss. e.g. ['binary', 'regression']
|
||||
:param task_names: list of str, indicating the predict target of each tasks
|
||||
|
||||
:param num_experts: integer, number of experts.
|
||||
:param expert_dnn_units: list, list of positive integer, its length must be greater than 1, the layer number and units in each layer of expert DNN
|
||||
:param gate_dnn_units: list, list of positive integer or None, the layer number and units in each layer of gate DNN, default value is None. e.g.[8, 8].
|
||||
:param tower_dnn_units_lists: list, list of positive integer list, its length must be euqal to num_tasks, the layer number and units in each layer of task-specific DNN
|
||||
|
||||
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
|
||||
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN
|
||||
:param seed: integer ,to use as random seed.
|
||||
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
|
||||
:param dnn_activation: Activation function to use in DNN
|
||||
:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN
|
||||
:return: a Keras model instance
|
||||
"""
|
||||
|
||||
if num_tasks <= 1:
|
||||
raise ValueError("num_tasks must be greater than 1")
|
||||
|
||||
if len(task_types) != num_tasks:
|
||||
raise ValueError("num_tasks must be equal to the length of task_types")
|
||||
|
||||
for task_type in task_types:
|
||||
if task_type not in ['binary', 'regression']:
|
||||
raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
|
||||
|
||||
if num_tasks != len(tower_dnn_units_lists):
|
||||
raise ValueError("the length of tower_dnn_units_lists must be euqal to num_tasks")
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
|
||||
l2_reg_embedding, seed)
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
|
||||
#build expert layer
|
||||
expert_outs = []
|
||||
for i in range(num_experts):
|
||||
expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='expert_'+str(i))(dnn_input)
|
||||
expert_outs.append(expert_network)
|
||||
expert_concat = tf.keras.layers.concatenate(expert_outs, axis=1, name='expert_concat')
|
||||
expert_concat = tf.keras.layers.Reshape([num_experts, expert_dnn_units[-1]], name='expert_reshape')(expert_concat) #(num_experts, output dim of expert_network)
|
||||
|
||||
mmoe_outs = []
|
||||
for i in range(num_tasks): #one mmoe layer: nums_tasks = num_gates
|
||||
#build gate layers
|
||||
if gate_dnn_units!=None:
|
||||
gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='gate_'+task_names[i])(dnn_input)
|
||||
gate_input = gate_network
|
||||
else: #in origin paper, gate is one Dense layer with softmax.
|
||||
gate_input = dnn_input
|
||||
gate_out = tf.keras.layers.Dense(num_experts, use_bias=False, activation='softmax', name='gate_softmax_'+task_names[i])(gate_input)
|
||||
gate_out = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
#gate multiply the expert
|
||||
gate_mul_expert = tf.keras.layers.Multiply(name='gate_mul_expert_'+task_names[i])([expert_concat, gate_out])
|
||||
gate_mul_expert = tf.keras.layers.Lambda(lambda x: reduce_sum(x, axis=1, keep_dims=True))(gate_mul_expert)
|
||||
mmoe_outs.append(gate_mul_expert)
|
||||
|
||||
task_outs = []
|
||||
for task_type, task_name, tower_dnn, mmoe_out in zip(task_types, task_names, tower_dnn_units_lists, mmoe_outs):
|
||||
#build tower layer
|
||||
tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(mmoe_out)
|
||||
|
||||
logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit)
|
||||
task_outs.append(output)
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=task_outs)
|
||||
return model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
from utils import get_mtl_data
|
||||
dnn_feature_columns, train_model_input, test_model_input, y_list = get_mtl_data()
|
||||
|
||||
model = MMOE(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=['income','marital'],
|
||||
num_experts=8, expert_dnn_units=[16], gate_dnn_units=None, tower_dnn_units_lists=[[8],[8]])
|
||||
model.compile("adam", loss=["binary_crossentropy", "binary_crossentropy"], metrics=['AUC'])
|
||||
history = model.fit(train_model_input, y_list, batch_size=256, epochs=5, verbose=2, validation_split=0.0 )
|
||||
|
||||
|
||||
153
codes/PLE.py
Normal file
153
codes/PLE.py
Normal file
@@ -0,0 +1,153 @@
|
||||
"""
|
||||
Reference:
|
||||
[1] Tang H, Liu J, Zhao M, et al. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations[C]//Fourteenth ACM Conference on Recommender Systems. 2020.(https://dl.acm.org/doi/10.1145/3383313.3412236)
|
||||
"""
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
from deepctr.feature_column import build_input_features, input_from_feature_columns
|
||||
from deepctr.layers.core import PredictionLayer, DNN
|
||||
from deepctr.layers.utils import combined_dnn_input, reduce_sum
|
||||
|
||||
def PLE(dnn_feature_columns, num_tasks=None, task_types=None, task_names=None, num_levels=2, num_experts_specific=8, num_experts_shared=4,
|
||||
expert_dnn_units=[64,64], gate_dnn_units=None, tower_dnn_units_lists=[[16,16],[16,16]],
|
||||
l2_reg_embedding=1e-5, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False):
|
||||
"""Instantiates the multi level of Customized Gate Control of Progressive Layered Extraction architecture.
|
||||
|
||||
:param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
|
||||
:param num_tasks: integer, number of tasks, equal to number of outputs, must be greater than 1.
|
||||
:param task_types: list of str, indicating the loss of each tasks, ``"binary"`` for binary logloss, ``"regression"`` for regression loss. e.g. ['binary', 'regression']
|
||||
:param task_names: list of str, indicating the predict target of each tasks
|
||||
|
||||
:param num_levels: integer, number of CGC levels.
|
||||
:param num_experts_specific: integer, number of task-specific experts.
|
||||
:param num_experts_shared: integer, number of task-shared experts.
|
||||
|
||||
:param expert_dnn_units: list, list of positive integer, its length must be greater than 1, the layer number and units in each layer of expert DNN.
|
||||
:param gate_dnn_units: list, list of positive integer or None, the layer number and units in each layer of gate DNN, default value is None. e.g.[8, 8].
|
||||
:param tower_dnn_units_lists: list, list of positive integer list, its length must be euqal to num_tasks, the layer number and units in each layer of task-specific DNN.
|
||||
|
||||
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector.
|
||||
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN.
|
||||
:param seed: integer ,to use as random seed.
|
||||
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
|
||||
:param dnn_activation: Activation function to use in DNN.
|
||||
:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN.
|
||||
:return: a Keras model instance.
|
||||
"""
|
||||
|
||||
if num_tasks <= 1:
|
||||
raise ValueError("num_tasks must be greater than 1")
|
||||
if len(task_types) != num_tasks:
|
||||
raise ValueError("num_tasks must be equal to the length of task_types")
|
||||
|
||||
for task_type in task_types:
|
||||
if task_type not in ['binary', 'regression']:
|
||||
raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
|
||||
|
||||
if num_tasks != len(tower_dnn_units_lists):
|
||||
raise ValueError("the length of tower_dnn_units_lists must be euqal to num_tasks")
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
|
||||
l2_reg_embedding, seed)
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
|
||||
#single Extraction Layer
|
||||
def cgc_net(inputs, level_name, is_last=False):
|
||||
#inputs: [task1, task2, ... taskn, shared task]
|
||||
expert_outputs = []
|
||||
#build task-specific expert layer
|
||||
for i in range(num_tasks):
|
||||
for j in range(num_experts_specific):
|
||||
expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'task_'+task_names[i]+'_expert_specific_'+str(j))(inputs[i])
|
||||
expert_outputs.append(expert_network)
|
||||
|
||||
#build task-shared expert layer
|
||||
for i in range(num_experts_shared):
|
||||
expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'expert_shared_'+str(i))(inputs[-1])
|
||||
expert_outputs.append(expert_network)
|
||||
|
||||
#task_specific gate (count = num_tasks)
|
||||
cgc_outs = []
|
||||
for i in range(num_tasks):
|
||||
#concat task-specific expert and task-shared expert
|
||||
cur_expert_num = num_experts_specific + num_experts_shared
|
||||
cur_experts = expert_outputs[i * num_experts_specific:(i + 1) * num_experts_specific] + expert_outputs[-int(num_experts_shared):] #task_specific + task_shared
|
||||
|
||||
expert_concat = tf.keras.layers.concatenate(cur_experts, axis=1, name=level_name+'expert_concat_specific_'+task_names[i])
|
||||
expert_concat = tf.keras.layers.Reshape([cur_expert_num, expert_dnn_units[-1]], name=level_name+'expert_reshape_specific_'+task_names[i])(expert_concat)
|
||||
|
||||
#build gate layers
|
||||
if gate_dnn_units!=None:
|
||||
gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'gate_specific_'+task_names[i])(inputs[i]) #gate[i] for task input[i]
|
||||
gate_input = gate_network
|
||||
else: #in origin paper, gate is one Dense layer with softmax.
|
||||
gate_input = dnn_input
|
||||
gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax', name=level_name+'gate_softmax_specific_'+task_names[i])(gate_input)
|
||||
gate_out = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
#gate multiply the expert
|
||||
gate_mul_expert = tf.keras.layers.Multiply(name=level_name+'gate_mul_expert_specific_'+task_names[i])([expert_concat, gate_out])
|
||||
gate_mul_expert = tf.keras.layers.Lambda(lambda x: reduce_sum(x, axis=1, keep_dims=True))(gate_mul_expert)
|
||||
cgc_outs.append(gate_mul_expert)
|
||||
|
||||
#task_shared gate, if the level not in last, add one shared gate
|
||||
if not is_last:
|
||||
cur_expert_num = num_tasks * num_experts_specific + num_experts_shared
|
||||
cur_experts = expert_outputs #all the expert include task-specific expert and task-shared expert
|
||||
|
||||
expert_concat = tf.keras.layers.concatenate(cur_experts, axis=1, name=level_name+'expert_concat_shared_'+task_names[i])
|
||||
expert_concat = tf.keras.layers.Reshape([cur_expert_num, expert_dnn_units[-1]], name=level_name+'expert_reshape_shared_'+task_names[i])(expert_concat)
|
||||
|
||||
#build gate layers
|
||||
if gate_dnn_units!=None:
|
||||
gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'gate_shared_'+str(i))(inputs[-1])#gate for shared task input
|
||||
gate_input = gate_network
|
||||
else: #in origin paper, gate is one Dense layer with softmax.
|
||||
gate_input = dnn_input
|
||||
|
||||
gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax', name=level_name+'gate_softmax_shared_'+str(i))(gate_input)
|
||||
gate_out = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
#gate multiply the expert
|
||||
gate_mul_expert = tf.keras.layers.Multiply(name=level_name+'gate_mul_expert_shared_'+task_names[i])([expert_concat, gate_out])
|
||||
gate_mul_expert = tf.keras.layers.Lambda(lambda x: reduce_sum(x, axis=1, keep_dims=True))(gate_mul_expert)
|
||||
cgc_outs.append(gate_mul_expert)
|
||||
return cgc_outs
|
||||
|
||||
#build Progressive Layered Extraction
|
||||
ple_inputs = [dnn_input]*(num_tasks+1) #[task1, task2, ... taskn, shared task]
|
||||
ple_outputs = []
|
||||
for i in range(num_levels):
|
||||
if i == num_levels-1: #the last level
|
||||
ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_'+str(i)+'_', is_last=True)
|
||||
break
|
||||
else:
|
||||
ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_'+str(i)+'_', is_last=False)
|
||||
ple_inputs = ple_outputs
|
||||
|
||||
task_outs = []
|
||||
for task_type, task_name, tower_dnn, ple_out in zip(task_types, task_names, tower_dnn_units_lists, ple_outputs):
|
||||
#build tower layer
|
||||
tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(ple_out)
|
||||
logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit)
|
||||
task_outs.append(output)
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=task_outs)
|
||||
return model
|
||||
|
||||
if __name__ == "__main__":
|
||||
from utils import get_mtl_data
|
||||
dnn_feature_columns, train_model_input, test_model_input, y_list = get_mtl_data()
|
||||
|
||||
model = PLE(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=['income','marital'],
|
||||
num_levels=2, num_experts_specific=4, num_experts_shared=4, expert_dnn_units=[16],
|
||||
gate_dnn_units=None,tower_dnn_units_lists=[[8],[8]])
|
||||
model.compile("adam", loss=["binary_crossentropy", "binary_crossentropy"], metrics=['AUC'])
|
||||
history = model.fit(train_model_input, y_list, batch_size=256, epochs=5, verbose=2, validation_split=0.0 )
|
||||
|
||||
72
codes/Shared_Bottom.py
Normal file
72
codes/Shared_Bottom.py
Normal file
@@ -0,0 +1,72 @@
|
||||
"""
|
||||
Reference:
|
||||
[1] Caruana R. Multitask learning[J]. Machine learning, 1997.(http://reports-archive.adm.cs.cmu.edu/anon/1997/CMU-CS-97-203.pdf)
|
||||
"""
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
from deepctr.feature_column import build_input_features, input_from_feature_columns
|
||||
from deepctr.layers.core import PredictionLayer, DNN
|
||||
from deepctr.layers.utils import combined_dnn_input
|
||||
|
||||
def Shared_Bottom(dnn_feature_columns, num_tasks=None, task_types=None, task_names=None,
|
||||
bottom_dnn_units=[128, 128], tower_dnn_units_lists=[[64,32], [64,32]],
|
||||
l2_reg_embedding=0.00001, l2_reg_dnn=0, seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False):
|
||||
"""Instantiates the Shared_Bottom multi-task learning Network architecture.
|
||||
|
||||
:param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
|
||||
:param num_tasks: integer, number of tasks, equal to number of outputs, must be greater than 1.
|
||||
:param task_types: list of str, indicating the loss of each tasks, ``"binary"`` for binary logloss or ``"regression"`` for regression loss. e.g. ['binary', 'regression']
|
||||
:param task_names: list of str, indicating the predict target of each tasks
|
||||
|
||||
:param bottom_dnn_units: list,list of positive integer or empty list, the layer number and units in each layer of shared-bottom DNN
|
||||
:param tower_dnn_units_lists: list, list of positive integer list, its length must be euqal to num_tasks, the layer number and units in each layer of task-specific DNN
|
||||
|
||||
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
|
||||
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN
|
||||
:param seed: integer ,to use as random seed.
|
||||
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
|
||||
:param dnn_activation: Activation function to use in DNN
|
||||
:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN
|
||||
:return: A Keras model instance.
|
||||
"""
|
||||
if num_tasks <= 1:
|
||||
raise ValueError("num_tasks must be greater than 1")
|
||||
if len(task_types) != num_tasks:
|
||||
raise ValueError("num_tasks must be equal to the length of task_types")
|
||||
|
||||
for task_type in task_types:
|
||||
if task_type not in ['binary', 'regression']:
|
||||
raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
|
||||
|
||||
if num_tasks != len(tower_dnn_units_lists):
|
||||
raise ValueError("the length of tower_dnn_units_lists must be euqal to num_tasks")
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed)
|
||||
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
shared_bottom_output = DNN(bottom_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
|
||||
|
||||
tasks_output = []
|
||||
for task_type, task_name, tower_dnn in zip(task_types, task_names, tower_dnn_units_lists):
|
||||
tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(shared_bottom_output)
|
||||
|
||||
logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit) #regression->keep, binary classification->sigmoid
|
||||
tasks_output.append(output)
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=tasks_output)
|
||||
return model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
from utils import get_mtl_data
|
||||
dnn_feature_columns, train_model_input, test_model_input, y_list = get_mtl_data()
|
||||
model = Shared_Bottom(dnn_feature_columns, num_tasks=2, task_types= ['binary', 'binary'],
|
||||
task_names=['label_income','label_marital'], bottom_dnn_units=[16],
|
||||
tower_dnn_units_lists=[[8],[8]])
|
||||
model.compile("adam", loss=["binary_crossentropy", "binary_crossentropy"], metrics=['AUC'])
|
||||
history = model.fit(train_model_input, y_list, batch_size=256, epochs=5, verbose=2, validation_split=0.0 )
|
||||
@@ -4,3 +4,49 @@ from collections import namedtuple
|
||||
SparseFeat = namedtuple('SparseFeat', ['name', 'vocabulary_size', 'embedding_dim'])
|
||||
DenseFeat = namedtuple('DenseFeat', ['name', 'dimension'])
|
||||
VarLenSparseFeat = namedtuple('VarLenSparseFeat', ['name', 'vocabulary_size', 'embedding_dim', 'maxlen'])
|
||||
|
||||
#产生多任务学习模型的数据 工具函数
|
||||
def get_mtl_data():
|
||||
import pandas as pd
|
||||
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
|
||||
from deepctr.feature_column import SparseFeat, DenseFeat,get_feature_names
|
||||
|
||||
CENSUS_COLUMNS = ['age','workclass','fnlwgt','education','education_num','marital_status','occupation','relationship','race','gender','capital_gain','capital_loss','hours_per_week','native_country','income_bracket']
|
||||
df_train = pd.read_csv('./data/adult_train.csv',header=None,names=CENSUS_COLUMNS)
|
||||
df_test = pd.read_csv('./data/adult_test.csv',header=None,names=CENSUS_COLUMNS)
|
||||
data = pd.concat([df_train, df_test], axis=0)
|
||||
#构造两个label
|
||||
data['label_income'] = data['income_bracket'].map({' >50K.':1, ' >50K':1, ' <=50K.':0, ' <=50K':0})
|
||||
data['label_marital'] = data['marital_status'].apply(lambda x: 1 if x==' Never-married' else 0)
|
||||
data.drop(labels=['marital_status', 'income_bracket'], axis=1, inplace=True)
|
||||
|
||||
#构造dict输入
|
||||
#define dense and sparse features
|
||||
columns = data.columns.values.tolist()
|
||||
dense_features = ['fnlwgt', 'education_num', 'capital_gain', 'capital_loss', 'hours_per_week']
|
||||
sparse_features = [col for col in columns if col not in dense_features and col not in ['label_income', 'label_marital']]
|
||||
|
||||
data[sparse_features] = data[sparse_features].fillna('-1', )
|
||||
data[dense_features] = data[dense_features].fillna(0, )
|
||||
mms = MinMaxScaler(feature_range=(0, 1))
|
||||
data[dense_features] = mms.fit_transform(data[dense_features])
|
||||
|
||||
for feat in sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
data[feat] = lbe.fit_transform(data[feat])
|
||||
|
||||
fixlen_feature_columns = [SparseFeat(feat, data[feat].max()+1, embedding_dim=16)for feat in sparse_features] \
|
||||
+ [DenseFeat(feat, 1,) for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = fixlen_feature_columns
|
||||
|
||||
feature_names = get_feature_names(dnn_feature_columns)
|
||||
|
||||
n_train = df_train.shape[0]
|
||||
train = data[:n_train]
|
||||
test = data[n_train:]
|
||||
train_model_input = {name: train[name] for name in feature_names}
|
||||
test_model_input = {name: test[name] for name in feature_names}
|
||||
y_list = [data['label_income'].values[:n_train], data['label_marital'].values[:n_train]]
|
||||
|
||||
return dnn_feature_columns, train_model_input, test_model_input, y_list
|
||||
357
docs/第一章 推荐系统基础/1.3深度推荐模型前沿/1.3.4 多任务学习.md
Normal file
357
docs/第一章 推荐系统基础/1.3深度推荐模型前沿/1.3.4 多任务学习.md
Normal file
@@ -0,0 +1,357 @@
|
||||
# 多任务学习
|
||||
|
||||
## 1. 动机
|
||||
|
||||
在当下的推荐系统中,预测目标往往不止一个,比如电商场景需要预估商品的点击率和转化率,短视频场景需要预估点击、播放时间、转发、评论、分享等。一般的做法,对不同的预测目标,建立不同的模型,再融合使用,但是存在两个问题:1.模型越多,参数越多,所需要的计算资源也越多,不一定能满足上线需求。2.不同任务之间也许存在互相促进的作用,单独训练忽略了这种任务之间的关系信息。多任务学习框架恰好可以解决这两个问题,训练一个模型,同时优化多个任务的loss,完成多任务的建模。
|
||||
|
||||
## 2. Shared-Bottom
|
||||
|
||||
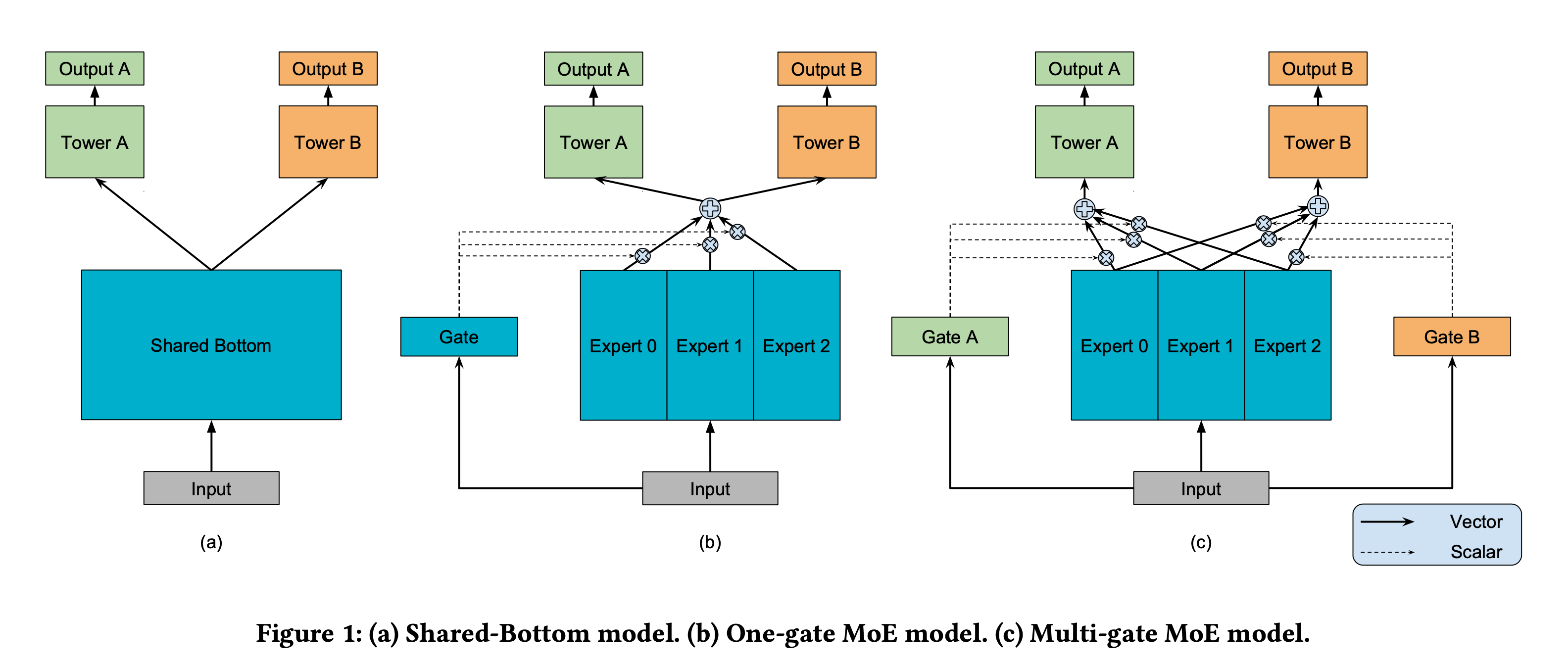
最简单的多任务学习框架便是共享底层(Shared-bottom),结构如下图a所示。所有任务共享特征输入层,中间的网络可以换成DeepFM、DCN等等,再往上每个tower代表一个任务,tower的结构一般是全连接层组成的网络。
|
||||
|
||||
|
||||
|
||||
```python
|
||||
def Shared_Bottom(dnn_feature_columns, num_tasks=None, task_types=None, task_names=None,
|
||||
bottom_dnn_units=[128, 128], tower_dnn_units_lists=[[64,32], [64,32]],
|
||||
l2_reg_embedding=0.00001, l2_reg_dnn=0, seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False):
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed)
|
||||
#共享输入特征
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
#共享底层网络
|
||||
shared_bottom_output = DNN(bottom_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
|
||||
#任务输出层
|
||||
tasks_output = []
|
||||
for task_type, task_name, tower_dnn in zip(task_types, task_names, tower_dnn_units_lists):
|
||||
tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(shared_bottom_output)
|
||||
|
||||
logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit)
|
||||
tasks_output.append(output)
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=tasks_output)
|
||||
return model
|
||||
```
|
||||
|
||||
## 3. MMOE
|
||||
|
||||
底层特征共享方式的一大特点是在任务之间都比较相似或者相关性比较大的场景下能带来很好的效果。如果两个任务不大相关,那么任务A的训练可能会对任务B的训练造成干扰。谷歌提出了利用MoE结构,由一组专家系统组成的网络替代原来的shared-bottom模块。如上图b所示,每一个expert就是一个独立的网络,gate就是对多个不同expert的输出进行加权融合。MoE结构里,所有的任务共用一个gate,也就是对expert网络的利用是一致的,谷歌进一步提出了MMOE结构,即为每个任务单独使用一个gate网络。
|
||||
|
||||
下面是代码实现,gate在原文中是一层以softmax为激活函数的全连接层,实际上expert网络与gate网络一样,可以是任意结构。gate网络的输出与expert网络的输出作元素积,实现信息的加权融合。
|
||||
|
||||
```python
|
||||
def MMOE(dnn_feature_columns, num_tasks=None, task_types=None, task_names=None, num_experts=4,
|
||||
expert_dnn_units=[32,32], gate_dnn_units=None, tower_dnn_units_lists=[[16,8],[16,8]],
|
||||
l2_reg_embedding=1e-5, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False):
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
|
||||
l2_reg_embedding, seed)
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
|
||||
#构建专家网络层
|
||||
expert_outs = []
|
||||
for i in range(num_experts):
|
||||
expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='expert_'+str(i))(dnn_input)
|
||||
expert_outs.append(expert_network)
|
||||
expert_concat = tf.keras.layers.concatenate(expert_outs, axis=1, name='expert_concat')
|
||||
expert_concat = tf.keras.layers.Reshape([num_experts, expert_dnn_units[-1]], name='expert_reshape')(expert_concat) #(num_experts, output dim of expert_network)
|
||||
|
||||
#构建MMOE层
|
||||
mmoe_outs = []
|
||||
for i in range(num_tasks): #one mmoe layer: nums_tasks = num_gates
|
||||
#build gate layers
|
||||
if gate_dnn_units!=None:
|
||||
gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='gate_'+task_names[i])(dnn_input)
|
||||
gate_input = gate_network
|
||||
else: #in origin paper, gate is one Dense layer with softmax.
|
||||
gate_input = dnn_input
|
||||
gate_out = tf.keras.layers.Dense(num_experts, use_bias=False, activation='softmax', name='gate_softmax_'+task_names[i])(gate_input)
|
||||
gate_out = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
#gate multiply the expert
|
||||
gate_mul_expert = tf.keras.layers.Multiply(name='gate_mul_expert_'+task_names[i])([expert_concat, gate_out])
|
||||
gate_mul_expert = tf.keras.layers.Lambda(lambda x: reduce_sum(x, axis=1, keep_dims=True))(gate_mul_expert)
|
||||
mmoe_outs.append(gate_mul_expert)
|
||||
|
||||
#构建输出层
|
||||
task_outs = []
|
||||
for task_type, task_name, tower_dnn, mmoe_out in zip(task_types, task_names, tower_dnn_units_lists, mmoe_outs):
|
||||
#build tower layer
|
||||
tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(mmoe_out)
|
||||
|
||||
logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit)
|
||||
task_outs.append(output)
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=task_outs)
|
||||
return model
|
||||
```
|
||||
|
||||
## 4. PLE
|
||||
|
||||
前面的MMOE模型存在以下两方面的缺点
|
||||
|
||||
- MMOE中所有的Expert是被所有任务所共享的,这可能无法捕捉到任务之间更复杂的关系,从而给部分任务带来一定的噪声
|
||||
- 不同的Expert之间没有交互,联合优化的效果有所折扣
|
||||
|
||||
腾讯进一步在MMOE的基础上提出了两点结构的改进,提出了PLE模型。第一个是自定义门控结构CGC,在MMOE中所有专家网络一视同仁,PLE将expert网络和gate网络都分成了两类:
|
||||
|
||||
- 任务独立型:专门预测某个特定任务
|
||||
- 任务共享型:所有任务共享
|
||||
|
||||
CGC的结构就是说,每个任务有各自独立的gate,这个gate聚合了该任务独立的expert和任务共享型expert的输出信息。
|
||||
|
||||
<img src="https://laimc.oss-cn-shanghai.aliyuncs.com/blog/20210712231607.png" alt="cgc" style="zoom: 33%;" />
|
||||
|
||||
第二个是分层萃取模型PLE,本质上就是多层GCC, 考虑了不同类型expert的交互,下一层的任务独立的expert融合了上一层对应任务的expert和共享expert的信息,下一层的任务共享expert则融合了上一层所有expert的信息。在中间层除了有任务独立型的gate之外,还有一个任务共享型的gate,对所有的expert做融合。最后一层输出层,不需要任务共享型gate。
|
||||
|
||||
<img src="https://laimc.oss-cn-shanghai.aliyuncs.com/blog/20210712231636.png" alt="ple" style="zoom: 33%;" />
|
||||
|
||||
单一的CGC模块
|
||||
|
||||
```python
|
||||
def CGC(dnn_feature_columns, num_tasks=None, task_types=None, task_names=None, num_experts_specific=8, num_experts_shared=4,
|
||||
expert_dnn_units=[64,64], gate_dnn_units=None, tower_dnn_units_lists=[[16,16],[16,16]],
|
||||
l2_reg_embedding=1e-5, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False):
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
|
||||
l2_reg_embedding, seed)
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
|
||||
expert_outputs = []
|
||||
#build task-specific expert layer
|
||||
for i in range(num_tasks):
|
||||
for j in range(num_experts_specific):
|
||||
expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='task_'+task_names[i]+'_expert_specific_'+str(j))(dnn_input)
|
||||
expert_outputs.append(expert_network)
|
||||
|
||||
#build task-shared expert layer
|
||||
for i in range(num_experts_shared):
|
||||
expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='expert_shared_'+str(i))(dnn_input)
|
||||
expert_outputs.append(expert_network)
|
||||
|
||||
#build one Extraction Layer
|
||||
cgc_outs = []
|
||||
for i in range(num_tasks):
|
||||
#concat task-specific expert and task-shared expert
|
||||
cur_expert_num = num_experts_specific + num_experts_shared
|
||||
cur_experts = expert_outputs[i * num_experts_specific:(i + 1) * num_experts_specific] + expert_outputs[-int(num_experts_shared):] #task_specific + task_shared
|
||||
expert_concat = tf.keras.layers.concatenate(cur_experts, axis=1, name='expert_concat_'+task_names[i])
|
||||
expert_concat = tf.keras.layers.Reshape([cur_expert_num, expert_dnn_units[-1]], name='expert_reshape_'+task_names[i])(expert_concat)
|
||||
|
||||
#build gate layers
|
||||
if gate_dnn_units!=None:
|
||||
gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='gate_'+task_names[i])(dnn_input)
|
||||
gate_input = gate_network
|
||||
else: #in origin paper, gate is one Dense layer with softmax.
|
||||
gate_input = dnn_input
|
||||
|
||||
gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax', name='gate_softmax_'+task_names[i])(gate_input)
|
||||
gate_out = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
#gate multiply the expert
|
||||
gate_mul_expert = tf.keras.layers.Multiply(name='gate_mul_expert_'+task_names[i])([expert_concat, gate_out])
|
||||
gate_mul_expert = tf.keras.layers.Lambda(lambda x: reduce_sum(x, axis=1, keep_dims=True))(gate_mul_expert)
|
||||
cgc_outs.append(gate_mul_expert)
|
||||
|
||||
task_outs = []
|
||||
for task_type, task_name, tower_dnn, cgc_out in zip(task_types, task_names, tower_dnn_units_lists, cgc_outs):
|
||||
#build tower layer
|
||||
tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(cgc_out)
|
||||
logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit)
|
||||
task_outs.append(output)
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=task_outs)
|
||||
return model
|
||||
```
|
||||
|
||||
多层CGC,PLE完整模型 (将num_levels参数设置为1,则等价于CGC):
|
||||
|
||||
```python
|
||||
def PLE(dnn_feature_columns, num_tasks=None, task_types=None, task_names=None, num_levels=2, num_experts_specific=8, num_experts_shared=4,
|
||||
expert_dnn_units=[64,64], gate_dnn_units=None, tower_dnn_units_lists=[[16,16],[16,16]],
|
||||
l2_reg_embedding=1e-5, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False):
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
|
||||
l2_reg_embedding, seed)
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
|
||||
#single Extraction Layer
|
||||
def cgc_net(inputs, level_name, is_last=False):
|
||||
#inputs: [task1, task2, ... taskn, shared task]
|
||||
expert_outputs = []
|
||||
#build task-specific expert layer
|
||||
for i in range(num_tasks):
|
||||
for j in range(num_experts_specific):
|
||||
expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'task_'+task_names[i]+'_expert_specific_'+str(j))(inputs[i])
|
||||
expert_outputs.append(expert_network)
|
||||
|
||||
#build task-shared expert layer
|
||||
for i in range(num_experts_shared):
|
||||
expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'expert_shared_'+str(i))(inputs[-1])
|
||||
expert_outputs.append(expert_network)
|
||||
|
||||
#task_specific gate (count = num_tasks)
|
||||
cgc_outs = []
|
||||
for i in range(num_tasks):
|
||||
#concat task-specific expert and task-shared expert
|
||||
cur_expert_num = num_experts_specific + num_experts_shared
|
||||
cur_experts = expert_outputs[i * num_experts_specific:(i + 1) * num_experts_specific] + expert_outputs[-int(num_experts_shared):] #task_specific + task_shared
|
||||
|
||||
expert_concat = tf.keras.layers.concatenate(cur_experts, axis=1, name=level_name+'expert_concat_specific_'+task_names[i])
|
||||
expert_concat = tf.keras.layers.Reshape([cur_expert_num, expert_dnn_units[-1]], name=level_name+'expert_reshape_specific_'+task_names[i])(expert_concat)
|
||||
|
||||
#build gate layers
|
||||
if gate_dnn_units!=None:
|
||||
gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'gate_specific_'+task_names[i])(inputs[i]) #gate[i] for task input[i]
|
||||
gate_input = gate_network
|
||||
else: #in origin paper, gate is one Dense layer with softmax.
|
||||
gate_input = dnn_input
|
||||
gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax', name=level_name+'gate_softmax_specific_'+task_names[i])(gate_input)
|
||||
gate_out = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
#gate multiply the expert
|
||||
gate_mul_expert = tf.keras.layers.Multiply(name=level_name+'gate_mul_expert_specific_'+task_names[i])([expert_concat, gate_out])
|
||||
gate_mul_expert = tf.keras.layers.Lambda(lambda x: reduce_sum(x, axis=1, keep_dims=True))(gate_mul_expert)
|
||||
cgc_outs.append(gate_mul_expert)
|
||||
|
||||
#task_shared gate, if the level not in last, add one shared gate
|
||||
if not is_last:
|
||||
cur_expert_num = num_tasks * num_experts_specific + num_experts_shared
|
||||
cur_experts = expert_outputs #all the expert include task-specific expert and task-shared expert
|
||||
|
||||
expert_concat = tf.keras.layers.concatenate(cur_experts, axis=1, name=level_name+'expert_concat_shared_'+task_names[i])
|
||||
expert_concat = tf.keras.layers.Reshape([cur_expert_num, expert_dnn_units[-1]], name=level_name+'expert_reshape_shared_'+task_names[i])(expert_concat)
|
||||
|
||||
#build gate layers
|
||||
if gate_dnn_units!=None:
|
||||
gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'gate_shared_'+str(i))(inputs[-1])#gate for shared task input
|
||||
gate_input = gate_network
|
||||
else: #in origin paper, gate is one Dense layer with softmax.
|
||||
gate_input = dnn_input
|
||||
|
||||
gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax', name=level_name+'gate_softmax_shared_'+str(i))(gate_input)
|
||||
gate_out = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
|
||||
|
||||
#gate multiply the expert
|
||||
gate_mul_expert = tf.keras.layers.Multiply(name=level_name+'gate_mul_expert_shared_'+task_names[i])([expert_concat, gate_out])
|
||||
gate_mul_expert = tf.keras.layers.Lambda(lambda x: reduce_sum(x, axis=1, keep_dims=True))(gate_mul_expert)
|
||||
cgc_outs.append(gate_mul_expert)
|
||||
return cgc_outs
|
||||
|
||||
#build Progressive Layered Extraction
|
||||
ple_inputs = [dnn_input]*(num_tasks+1) #[task1, task2, ... taskn, shared task]
|
||||
ple_outputs = []
|
||||
for i in range(num_levels):
|
||||
if i == num_levels-1: #the last level
|
||||
ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_'+str(i)+'_', is_last=True)
|
||||
break
|
||||
else:
|
||||
ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_'+str(i)+'_', is_last=False)
|
||||
ple_inputs = ple_outputs
|
||||
|
||||
task_outs = []
|
||||
for task_type, task_name, tower_dnn, ple_out in zip(task_types, task_names, tower_dnn_units_lists, ple_outputs):
|
||||
#build tower layer
|
||||
tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(ple_out)
|
||||
logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
|
||||
output = PredictionLayer(task_type, name=task_name)(logit)
|
||||
task_outs.append(output)
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=task_outs)
|
||||
return model
|
||||
```
|
||||
|
||||
## 5. ESSM
|
||||
|
||||
不同的目标由于业务逻辑,有显式的依赖关系,比如CTR和CVR,用户必然是先点击了商品,才有可能购买转化。阿里提出了ESSM结构,显式建模具有依赖关系的任务联合训练。
|
||||
|
||||
在CVR预测任务中通常存在两个问题:
|
||||
|
||||
- 样本选择偏差(SSB):广告的pipline是曝光->点击->转化。传统CVR模型的正负样本集合={点击后未转化的负样本+点击后转化的正样本},但是线上预估的时候是样本一旦曝光,就需要预测出CVR,样本集合={展现的样本}。不符合机器学习中训练数据和测试数据独立同分布的假设。
|
||||
- 训练数据稀疏:点击样本只占整个曝光样本的很小一部分,而转化样本又只占点击样本的很小一部分。
|
||||
|
||||
ESMM基于CTR、CVR、CTCVR(点击然后转化)的关联:
|
||||
|
||||
<img src="https://laimc.oss-cn-shanghai.aliyuncs.com/blog/20210808002104.png" alt="image-20210808002059230" style="zoom: 50%;" />
|
||||
|
||||
其中x表示曝光,y表示点击,z表示转化,提出了利用两个辅助任务CTR和CTCVR来建模主任务CVR的网络结构。
|
||||
|
||||
主任务和辅助任务共享特征,输出层用不同的网络,将cvr的预测值*ctr的预测值作为ctcvr任务的预测值,利用ctcvr和ctr的label构造损失函数:
|
||||
|
||||
<img src="/Users/lmc/Library/Application Support/typora-user-images/image-20210808002418336.png" alt="image-20210808002418336" style="zoom:50%;" />
|
||||
|
||||
模型训练完成后,可以同时预测cvr、ctr、ctcvr三个任务。
|
||||
|
||||
<img src="https://laimc.oss-cn-shanghai.aliyuncs.com/blog/20210712231527.png" alt="esmm" style="zoom: 33%;" />
|
||||
|
||||
由于CVR的训练也是基于全部曝光样本的空间,所以解决了样本选择偏差的问题;由于共享embedding的机制,训练cvr模型时引入了更多的样本(未点击样本),通过CTR*CVR=CTCVR公式来得到CVR的预估结果,相当于间接通过更丰富的样本训练了CVR模型,一定程度缓解了样本稀疏的问题。
|
||||
|
||||
```python
|
||||
def ESSM(dnn_feature_columns, task_type='binary', task_names=['ctr', 'ctcvr'],
|
||||
tower_dnn_units_lists=[[128, 128],[128, 128]], l2_reg_embedding=0.00001, l2_reg_dnn=0,
|
||||
seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False):
|
||||
|
||||
features = build_input_features(dnn_feature_columns)
|
||||
inputs_list = list(features.values())
|
||||
|
||||
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed)
|
||||
|
||||
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
|
||||
|
||||
ctr_output = DNN(tower_dnn_units_lists[0], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
|
||||
cvr_output = DNN(tower_dnn_units_lists[1], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
|
||||
|
||||
ctr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(ctr_output)
|
||||
cvr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(cvr_output)
|
||||
|
||||
ctr_pred = PredictionLayer(task_type, name=task_names[0])(ctr_logit)
|
||||
cvr_pred = PredictionLayer(task_type)(cvr_logit)
|
||||
|
||||
ctcvr_pred = tf.keras.layers.Multiply(name=task_names[1])([ctr_pred, cvr_pred])#CTCVR = CTR * CVR
|
||||
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=[ctr_pred, ctcvr_pred])
|
||||
return model
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 6. 示例
|
||||
|
||||
代码示例中,使用adult数据集,完成两个任务的预测,任务1预测该用户收入是否大于50K,任务2预测该用户的婚姻是否未婚。两个任务均为二分类任务,使用交叉熵作为损失函数。在ESMM框架下,我们把任务1作为CTR任务,任务2作为CTCVR任务。
|
||||
|
||||
因为涉及网络层比较多,为了让网络结构尽量清晰,使用了开源框架DeepCTR的一些网络层,运行代码需要先安装deepctr。
|
||||
|
||||
```shell
|
||||
pip install deepctr
|
||||
```
|
||||
|
||||
|
||||
|
||||
参考:
|
||||
|
||||
1. https://zhuanlan.zhihu.com/p/291406172
|
||||
|
||||
2. Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.(https://dl.acm.org/doi/abs/10.1145/3219819.3220007)
|
||||
3. Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.(https://arxiv.org/abs/1804.07931)
|
||||
4. Tang H, Liu J, Zhao M, et al. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations[C]//Fourteenth ACM Conference on Recommender Systems. 2020.(https://arxiv.org/abs/1804.07931)
|
||||
5. Caruana R. Multitask learning[J]. Machine learning, 1997.(http://reports-archive.adm.cs.cmu.edu/anon/1997/CMU-CS-97-203.pdf)
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user