添加新闻推荐系统实践内容
This commit is contained in:
@@ -95,28 +95,34 @@
|
||||
- [排序模型&模型融合](/推荐系统实战/竞赛实践/markdown/排序模型+模型融合)
|
||||
|
||||
#### 新闻推荐系统实践
|
||||
- 新闻推荐系统流程的构建视频讲解【已完成】
|
||||
- 离线物料系统的构建
|
||||
- Mysql基础【已完成】
|
||||
- MongoDB基础【已完成】
|
||||
- Redis基础【已完成】
|
||||
- Scrapy基础及新闻爬取实战【已完成】
|
||||
- 自动化构建用户及物料画像【已完成】
|
||||
- 前后端基础及交互
|
||||
- 前端基础及Vue实战【已完成】
|
||||
- flask简介及基础【已完成】
|
||||
- 前后端交互【已完成】
|
||||
- 推荐流程的构建【已完成】
|
||||
- 召回
|
||||
- 规则类召回
|
||||
- 热度召回【完成一半,待优化】
|
||||
- 地域召回【完成一半,待优化】
|
||||
- 模型类召回
|
||||
- YoutubeDNN召回【已完成,待优化】
|
||||
- DSSM召回【已完成,待优化】
|
||||
- DeepFM排序模型【已完成,待优化】
|
||||
- 规则与重排【完成一半,待优化】
|
||||
- 任务监控与调度【完成一半,待优化】
|
||||
- **视频**
|
||||
- [新闻推荐系统流程的构建视频讲解](https://datawhale.feishu.cn/minutes/obcnzns778b725r5l535j32o)
|
||||
- **文档**
|
||||
- **离线物料系统的构建**
|
||||
- [Mysql基础](/推荐系统实战/新闻推荐系统实践/mysql基础)
|
||||
- [MongoDB基础](/推荐系统实战/新闻推荐系统实践/MongoDB基础)
|
||||
- [Redis基础](/推荐系统实战/新闻推荐系统实践/Redis基础)
|
||||
- [Scrapy基础及新闻爬取实战](/推荐系统实战/新闻推荐系统实践/Scrapy基础及新闻爬取实战)
|
||||
- [自动化构建用户及物料画像](/推荐系统实战/新闻推荐系统实践/自动化构建用户及物料画像)
|
||||
- **前后端基础及交互**
|
||||
- [前端基础及Vue实战](/推荐系统实战/新闻推荐系统实践/前端基础及Vue实战)
|
||||
- [flask简介及基础](/推荐系统实战/新闻推荐系统实践/flask简介及基础)
|
||||
- [前后端交互](/推荐系统实战/新闻推荐系统实践/前后端交互)
|
||||
- [推荐系统流程的构建](/推荐系统实战/新闻推荐系统实践/推荐系统流程的构建)
|
||||
- 召回
|
||||
- 规则类召回
|
||||
- 热度召回【完成一半,待优化】
|
||||
- 地域召回【完成一半,待优化】
|
||||
- 模型类召回
|
||||
- YoutubeDNN召回【已完成,待优化】
|
||||
- DSSM召回【已完成,待优化】
|
||||
- DeepFM排序模型【已完成,待优化】
|
||||
- 规则与重排【完成一半,待优化】
|
||||
- 任务监控与调度【完成一半,待优化】
|
||||
- **当前问题汇总**
|
||||
- [熟悉推荐系统基本流程问答整理](/推荐系统实战/新闻推荐系统实践/熟悉推荐系统基本流程问答整理)
|
||||
- [数据库的基本使用问答整理](/推荐系统实战/新闻推荐系统实践/数据库的基本使用问答整理)
|
||||
- [离线物料系统的构建问答整理](/推荐系统实战/新闻推荐系统实践/离线物料系统的构建问答整理)
|
||||
|
||||
### 推荐系统算法面经
|
||||
- [ML与DL基础](/推荐算法面经/ML与DL基础)
|
||||
|
||||
@@ -66,16 +66,16 @@
|
||||
* [排序模型&模型融合](/推荐系统实战/竞赛实践/markdown/排序模型&模型融合)
|
||||
* [新闻推荐系统的实践]()
|
||||
* [离线物料系统的构建]()
|
||||
* [Mysql基础]()
|
||||
* [MongoDB基础]()
|
||||
* [Redis基础]()
|
||||
* [Scrapy基础及新闻爬取实战]()
|
||||
* [自动化构建用户及物料画像]()
|
||||
* [Mysql基础](/推荐系统实战/新闻推荐系统实践/mysql基础)
|
||||
* [MongoDB基础](/推荐系统实战/新闻推荐系统实践/MongoDB基础)
|
||||
* [Redis基础](/推荐系统实战/新闻推荐系统实践/Redis基础)
|
||||
* [Scrapy基础及新闻爬取实战](/推荐系统实战/新闻推荐系统实践/Scrapy基础及新闻爬取实战)
|
||||
* [自动化构建用户及物料画像](/推荐系统实战/新闻推荐系统实践/自动化构建用户及物料画像)
|
||||
* [前后端基础及交互]()
|
||||
* [前端基础及Vue实战]()
|
||||
* [flask简介及基础]()
|
||||
* [前后端交互]()
|
||||
* [推荐流程的构建]()
|
||||
* [前端基础及Vue实战](/推荐系统实战/新闻推荐系统实践/前端基础及Vue实战)
|
||||
* [flask简介及基础](/推荐系统实战/新闻推荐系统实践/flask简介及基础)
|
||||
* [前后端交互](/推荐系统实战/新闻推荐系统实践/前后端交互)
|
||||
* [推荐系统流程的构建](/推荐系统实战/新闻推荐系统实践/推荐系统流程的构建)
|
||||
* [召回]()
|
||||
- [规则类召回]()
|
||||
- [热度召回]()
|
||||
@@ -86,6 +86,10 @@
|
||||
* [DeepFM排序]()
|
||||
* [规则与重排]()
|
||||
* [任务调度与监控]()
|
||||
* [当前问题汇总]()
|
||||
* [熟悉推荐系统基本流程问答整理](/推荐系统实战/新闻推荐系统实践/熟悉推荐系统基本流程问答整理)
|
||||
* [数据库的基本使用问答整理](/推荐系统实战/新闻推荐系统实践/数据库的基本使用问答整理)
|
||||
* [离线物料系统的构建问答整理](/推荐系统实战/新闻推荐系统实践/离线物料系统的构建问答整理)
|
||||
* [推荐系统算法面经]()
|
||||
* [ML与DL基础](/推荐算法面经/ML与DL基础)
|
||||
* [推荐模型相关](/推荐算法面经/推荐模型相关)
|
||||
|
||||
1243
docs/推荐系统实战/新闻推荐系统实践/MongoDB基础.md
Normal file
1243
docs/推荐系统实战/新闻推荐系统实践/MongoDB基础.md
Normal file
File diff suppressed because it is too large
Load Diff
2313
docs/推荐系统实战/新闻推荐系统实践/Mysql基础.md
Normal file
2313
docs/推荐系统实战/新闻推荐系统实践/Mysql基础.md
Normal file
File diff suppressed because it is too large
Load Diff
1238
docs/推荐系统实战/新闻推荐系统实践/Redis基础.md
Normal file
1238
docs/推荐系统实战/新闻推荐系统实践/Redis基础.md
Normal file
File diff suppressed because it is too large
Load Diff
549
docs/推荐系统实战/新闻推荐系统实践/flask简介及基础.md
Normal file
549
docs/推荐系统实战/新闻推荐系统实践/flask简介及基础.md
Normal file
@@ -0,0 +1,549 @@
|
||||
本文属于新闻推荐实战—前后端交互—后端构建之Flask。Flask作为该项目中会用来作为系统的后台框架,作为一个算法工程师需要了解一些关于开发的知识,因为在实际的工作中经常调试线上的代码来调用策略或模型。本文将对Flask以及一些基本的使用进行了简单的介绍,方便大家快速理解项目中的相关内容。
|
||||
|
||||
# Flask简介
|
||||
|
||||
Flask是一个轻量级的可定制框架,使用Python语言编写,较其他同类型框架更为灵活、轻便、安全且容易上手。它可以很好地结合MVC模式进行开发,开发人员分工合作,小型团队在短时间内就可以完成功能丰富的中小型网站或Web服务的实现。
|
||||
|
||||
Flask是目前十分流行的web框架,采用Python编程语言来实现相关功能。Flask框架的主要特征是核心构成比较简单,但具有很强的扩展性和兼容性,程序员可以使用Python语言快速实现一个网站或Web服务。一般情况下,它不会指定数据库和模板引擎等对象,用户可以根据需要自己选择各种数据库。
|
||||
|
||||
|
||||
[百度百科]: https://baike.baidu.com/item/Flask/1241509
|
||||
[维基百科]: https://zh.wikipedia.org/zh-hans/Flask
|
||||
|
||||
|
||||
|
||||
# 一、 准备工作
|
||||
|
||||
在学习Flask之前,已经假设你对python已经有了一定的基础,并且对于计算机知识有了一定的掌握。
|
||||
|
||||
## 1.1 环境配置
|
||||
|
||||
为了保持全局环境的干净,指定不同的依赖版本,我们可以利用virtualenv来构建虚拟的环境,类似于anaconda。
|
||||
|
||||
```bash
|
||||
pip install virtualenv
|
||||
```
|
||||
|
||||
通过上述指令安装virtualenv,之后将在文件夹中创建新的虚拟环境。
|
||||
|
||||
```bash
|
||||
mkdir newproj
|
||||
cd newproj
|
||||
virtualenv venv
|
||||
```
|
||||
|
||||
要在Linux激活相应的环境。
|
||||
|
||||
```bash
|
||||
venv/bin/activate
|
||||
```
|
||||
|
||||
接下来就可以在这个环境中安装 Flask,当然如果你也可以选择使用下述指令直接在全局环境中安装Flask。
|
||||
|
||||
```bash
|
||||
pip install Flask
|
||||
```
|
||||
|
||||
## 1.2 测试安装
|
||||
|
||||
为了测试装的Flask是否能正常使用,可以在编译器中输入一下代码:
|
||||
|
||||
```python
|
||||
from flask import Flask
|
||||
app = Flask(__name__)
|
||||
|
||||
@app.route('/')
|
||||
def hello_world():
|
||||
return 'Hello World'
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run()
|
||||
```
|
||||
|
||||
运行上述代码,在浏览器中打开**localhost: 5000**,将显示**Hello World**`消息。
|
||||
|
||||
```python
|
||||
python Hello.py
|
||||
```
|
||||
|
||||
上述代码中,Flask将(__name__)作为参数,即Flask在当前模块运行,route()函数是一个装饰器,将请求的url映射到对应的函数上。上述代码将'/'与hello_world()函数进行绑定,因此在请求localhost:5000时,网页显示 Hello World 结果。
|
||||
|
||||
程序的启动是用过Flask类的run()方法在本地启动服务器应用程序。
|
||||
|
||||
```python
|
||||
app.run(host, port, debug, options)
|
||||
```
|
||||
|
||||
其中参数是可选的。
|
||||
|
||||
| 序号 | 参数与描述 |
|
||||
| ---- | ------------------------------------------------------------ |
|
||||
| 1 | **host** 要监听的主机名。 默认为127.0.0.1(localhost)。设置为“0.0.0.0”以使服务器在外部可用 |
|
||||
| 2 | **port** 默认值为5000 |
|
||||
| 3 | **debug** 默认为false。 如果设置为true,则提供调试信息 |
|
||||
| 4 | **options** 要转发到底层的Werkzeug服务器。 |
|
||||
|
||||
# 二、主要内容
|
||||
|
||||
## 2.1 路由
|
||||
|
||||
在Flask中,路由是指用户请求的*URL*与*视图函数*之间的映射。Flask通过利用路由表将URL映射到对应的视图函数,根据视图函数的执行结果返回给WSGI服务器。路由表的内容是由开发者进行填充,主要有一下两个方式。
|
||||
|
||||
- **route装饰器**:使用Flask应用实例的*route*装饰器将一个URL规则绑定到 一个视图函数上。
|
||||
|
||||
```python
|
||||
@app.route('/test')
|
||||
def test():
|
||||
return 'this is response of test function.'
|
||||
```
|
||||
|
||||
通过装饰器的方式,Flask框架会将URL规则<i>/test</i> 绑定到视图函数 <i>test()</i>上。
|
||||
|
||||
- **add_url_rule()** :该方法直接会在路由表中注册映射关系。其实*route*装饰器内部也是通过调用<i>add_url_rule()</i>方法实现的路由注册。
|
||||
|
||||
```python
|
||||
def test():
|
||||
return 'this is response of test function.'
|
||||
app.add_url_rule('/test',view_func=test)
|
||||
```
|
||||
|
||||
### 2.1.1 指定HTTP方法
|
||||
|
||||
默认情况下,Flask的路由支持HTTP的*GET*请求,如果需要视图函数支持HTTP的其他方法,可以通过*methods*关键字参数进行设置。关键字参数*methods*的类型为*list*,可以同时指定多种HTTP方法。
|
||||
|
||||
```python
|
||||
@app.route('/user', methods = ['POST', 'GET'])
|
||||
def get_users():
|
||||
if request.method == 'GET':
|
||||
return ... # 返回用户列表
|
||||
else:
|
||||
return ... # 创建新用户
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 2.1.2 匹配动态URL
|
||||
|
||||
动态URL用于当需要将*同一类URL*映射到同一个视图函数处理,比如,使用同一个视图函数 来显示不同用户的个人信息。那么可以将URL中的可变部分*使用一对小括号*<>声明为变量, 并为视图函数声明同名的参数:
|
||||
|
||||
```python
|
||||
@app.route('/user/<uname>')
|
||||
def get_userInfo(uname):
|
||||
return '%s\'s Informations' % uname
|
||||
```
|
||||
|
||||
除了上述方式来设置参数,还可以在URL参数前添加转换器来转换参数类型:
|
||||
|
||||
```python
|
||||
@app.route('/user/<int:uname>')
|
||||
def get_userInfo(uname):
|
||||
return '%s\'s Informations' % uname
|
||||
```
|
||||
|
||||
使用该方法时,请求的参数必须是属于int类型,否则将会出现404错误。目前支持的参数类型转换器有:
|
||||
|
||||
| 类型转换器 | 作用 |
|
||||
| :--------- | :------------------- |
|
||||
| 缺省 | 字符型,但不能有斜杠 |
|
||||
| int: | 整型 |
|
||||
| float: | 浮点型 |
|
||||
| path: | 字符型,可有斜杠 |
|
||||
|
||||
|
||||
|
||||
### 2.1.3 匹配动态URL
|
||||
|
||||
为了满足一个视图函数可以解决多个问题,因此每个视图函数可以配置多个路由规则。
|
||||
|
||||
```python
|
||||
@app.route('/user')
|
||||
@app.route('/user/<uname>')
|
||||
@app.route('/user/<int:uname>')
|
||||
def get_userInfo(uname=None):
|
||||
if uname:
|
||||
return '%s\'s Informations' % uname
|
||||
else:
|
||||
return 'this is all informations of users'
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 2.1.4 URL构建方法
|
||||
|
||||
在很多时候,在一个实用的视图中需要指向其他视图的连接,为了防止路径出现问题,我们可以让Flask框架帮我们计算链接URL。简单地给url_for()函数传入一个访问点,它返回将是一个可靠的URL地址:
|
||||
|
||||
```python
|
||||
@app.route('/')
|
||||
def hello():
|
||||
return 'Hello world!'
|
||||
|
||||
@app.route('/user/<uname>')
|
||||
def get_userInfo(uname=None):
|
||||
if uname: return '%s\'s Informations' % uname
|
||||
else: return 'this is all informations of users'
|
||||
@app.route('/test')
|
||||
def test_url_for():
|
||||
print(url_for('hello')) # 输出:/
|
||||
```
|
||||
|
||||
添加URL变量 : 如果指定访问点对应的视图函数接收参数,那么关键字参数将生成对应的参数URL。下面的 示例将生成 /user/zhangsan:
|
||||
|
||||
```python
|
||||
@app.route('/')
|
||||
def hello():
|
||||
return 'Hello world!'
|
||||
|
||||
@app.route('/user/<uname>')
|
||||
def get_userInfo(uname=None):
|
||||
if uname:
|
||||
return '%s\'s Informations' % uname
|
||||
else:
|
||||
return 'this is all informations of users'
|
||||
|
||||
@app.route('/test')
|
||||
def test_url_for():
|
||||
print(url_for('get_userInfo', uname='zhangsan')) # 输出:/user/zhangsan
|
||||
print(url_for('test_url_for', num=2)) # 输出:/test?num=2
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 2.2 请求,响应及会话
|
||||
|
||||
对于一个完整的HTTP请求,包括了来自客户端的请求对象(Request),服务器端的响应对象(Respose)和会话对象(Session)等。在Flask框架中,当然也具有这些对象,这些对象不仅可以在请求函数中使用,同时也可以在模板中使用。那我们来简单看看这些对象具体怎么使用。
|
||||
|
||||
### 2.2.1 请求对象 request
|
||||
|
||||
在Flask包中,可以直接引入request对象,其中包含**Form**,**args** ,**Cookies** ,**files** 等属性。**Form** 是一个字典对象,包含表单当中所有参数及其值的键和值对;**args** 是解析查询字符串的内容,它是问号(?)之后的URL的一部分,当使用get请求时,通过URL传递参数时可以通过**args**属性获取;**Cookies** 是用来保存Cookie名称和值的字典对象;**files** 属性和上传文件有关的数据。我们以一个登陆的例子看看如何搭配使用这些属性
|
||||
|
||||
```python
|
||||
from flask import request, session, make_response
|
||||
|
||||
@app.route('/login', methods=['POST', 'GET'])
|
||||
def login():
|
||||
if request.method == 'POST':
|
||||
if request.form['username'] == 'admin':
|
||||
session['username'] = request.form['username']
|
||||
response = make_response('Admin login successfully!')
|
||||
response.set_cookie('login_time', time.strftime('%Y-%m-%d %H:%M:%S'))
|
||||
return 'Admin login successfully!'
|
||||
else:
|
||||
return 'No such user!'
|
||||
elif request.method == 'GET':
|
||||
if request.args.get("username") == 'admin':
|
||||
session['username'] = request.form['username']
|
||||
return 'Admin login successfully!'
|
||||
else:
|
||||
return 'No such user!'
|
||||
|
||||
app.secret_key = '123456'
|
||||
```
|
||||
|
||||
上述代码中,可以根据method属性判断当前请求的类型,通过form属性可以获取表单信息,并通过session来存储用户登陆信息。特别提醒,使用session时一定要设置一个密钥`app.secret_key`,并且密钥要尽量复杂。
|
||||
|
||||
我们可以使用make_response的方法就是用来构建`response`对象的第二个参数代表响应状态码,缺省就是”200”。`response`对象的详细使用可参阅Flask的[官方API文档](http://flask.pocoo.org/docs/0.10/api/#response-objects)。通过创建的`response`对象可以使用`response.set_cookie()`函数,来设置Cookie项,之后这个项值会被保存在浏览器中,等下次请求时可以从request对象中获取到cookies对象。
|
||||
|
||||
由于现在前后端的交互会采用json的数据格式进行传输,因此当前端请求的数据是json类型的时候,可以使用get_data()方法来获取。
|
||||
|
||||
```python
|
||||
from flask import Flask, jsonify, request
|
||||
@app.route('/login', methods=["POST"])
|
||||
def login():
|
||||
request_str = request.get_data()
|
||||
request_dict = json.loads(request_str)
|
||||
```
|
||||
|
||||
获取json数据之后,可以使用flask中的jsonify对象来处理json类型数据。
|
||||
|
||||
|
||||
|
||||
### 2.2.2 响应对象 response
|
||||
|
||||
如果视图函数想向前端返回数据,必须是`Response`的对象, 主要讲返回数据的几种方式:
|
||||
|
||||
**视图函数 return 多个值**
|
||||
|
||||
```python
|
||||
@app.route("/user_one")
|
||||
def user_one():
|
||||
return "userInfo.html", "200 Ok", {"name": "zhangsan"; "age":"20"}
|
||||
```
|
||||
|
||||
当return多个值的时候,第一个是字符串,也是网页的内容;"200 Ok"表示状态码及解析;{"name": "zhangsan"; "age":"20"} 表示请求头。其中前面两个值是必须要的并且顺序不能改变,请求头不是必须要的,这样Flask会自动将返回值转换成一个相应的Response对象。如果仅返回一个字符串,则返回的Response对象会将该字符串作为body,状态码置为200。
|
||||
|
||||
**使用Response()构造Response对象**
|
||||
|
||||
可以使用Response()手动构造一个Response对象,配置其参数后返回该对象。
|
||||
|
||||
```python
|
||||
from flask import Response
|
||||
|
||||
@app.route("/user_one")
|
||||
def user_one():
|
||||
response = Response("user_one")
|
||||
response.status_code = 200
|
||||
response.status = "200 ok"
|
||||
response.data = {"name": "zhangsan"; "age":"20"}
|
||||
return response
|
||||
```
|
||||
|
||||
**使用make_response函数构造Response对象**
|
||||
|
||||
`make_response` 函数可以传递三个参数 第一个是一个字符串,第二个传状态码,第三个传请求头。
|
||||
|
||||
```python
|
||||
@app.route("/user_one")
|
||||
def user_one():
|
||||
response = make_response('user_one', 200, {"name": "zhangsan"; "age":"20"})
|
||||
return response
|
||||
```
|
||||
|
||||
由于现在前后端交互往往采用的是json的数据格式,因此可以将数据通过 jsonify 函数将其转化成json格式,再通过response对象发送给前端。
|
||||
|
||||
```python
|
||||
@app.route('/hot_list', methods=["GET"])
|
||||
def hot_list():
|
||||
if request.method == "GET":
|
||||
user_id = request.args.get('user_id')
|
||||
page_id = request.args.get('page_id')
|
||||
if user_id is None or page_id is None:
|
||||
return make_response(jsonify({"code": 2000, "msg": "user_id or page_id is none!"}), 200)
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 2.3 重定向与错误处理
|
||||
|
||||
### 2.3.1重定向
|
||||
|
||||
当一个请求过来后可能还需要再请求另一个视图函数才能达到目的,那么就可以调用`redirect(location, code=302, Response=None)`函数指定重定向页面。
|
||||
|
||||
```python
|
||||
from flask import Flask, redirect, url_for
|
||||
|
||||
app = Flask(__name__)
|
||||
|
||||
@app.route("/demo")
|
||||
def demo():
|
||||
url = url_for("demo2") # 路由反转,根据视图函数名获取路由地址
|
||||
return redirect(url)
|
||||
|
||||
@app.route("/demo2")
|
||||
def demo2():
|
||||
return "this is demo2 page"
|
||||
|
||||
@app.route("/")
|
||||
def index():
|
||||
# 使用方法:redirect(location, code=302, Response=None)
|
||||
return redirect("/demo", 301)
|
||||
```
|
||||
|
||||
#### 常用重定向状态码
|
||||
|
||||
| 状态码 | 说明 |
|
||||
| ------ | ----------------------------- |
|
||||
| 300 | Multiple Choice,让用户选择 |
|
||||
| 301 | Moved Permanently,永久重定向 |
|
||||
| 302 | Found,临时重定向 |
|
||||
| 303 | See Other,查看其它位置 |
|
||||
| 304 | Not Modified,资源未发生变化 |
|
||||
| 305 | Use Proxy,需要通过代理访问 |
|
||||
|
||||
|
||||
|
||||
### 2.3.2错误处理
|
||||
|
||||
当请求或服务器出现错误的时候,我们希望遇到特定错误代码时重写错误页面,可以使用 **errorhandler()** 装饰器:
|
||||
|
||||
```python
|
||||
from flask import render_template
|
||||
|
||||
@app.errorhandler(404)
|
||||
def page_not_found(error):
|
||||
return render_template('page_not_found.html'), 404
|
||||
```
|
||||
|
||||
当遇到404错误时,会调用page_not_found()函数,返回元组数据,第一个元素是”page_not_found.html”的模板页,第二个元素代表错误代码,返回值会自动转成 response 对象。
|
||||
|
||||
## 2.4 SQLAlchemy
|
||||
|
||||
SQLAlchemy 是一个功能强大的Python ORM 工具包,为应用程序开发人员提供了SQL的全部功能和ORM操作。其中ORM (Object Relation Mapping)指的是将对象参数映射到底层RDBMS表结构的技术,ORM API提供了执行CRUD操作的方法,不需要程序员编写原始SQL语句。
|
||||
|
||||
### 2.4.1安装
|
||||
|
||||
通过下面指令可以进行安装:
|
||||
|
||||
```shell
|
||||
pip install SQLalchemy
|
||||
```
|
||||
|
||||
在连接数据库时,我们使用pymysql框架进行连接,因此还需要使用下面指令下载pymysql框架:
|
||||
|
||||
```shell
|
||||
pip install pymysql
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 2.4.2 创建连接
|
||||
|
||||
```python
|
||||
from sqlalchemy import create_engine
|
||||
|
||||
def mysql_db(host='127.0.0.1',dbname='3306'):
|
||||
engine = create_engine("mysql+pymysql://root:123456@{}:49168/{}?charset=utf8".format(host,dbname))
|
||||
print(engine) # Engine(mysql+pymysql://root:***@127.0.0.1:49168/3306?charset=utf8)
|
||||
```
|
||||
|
||||
通过create_engine函数已经创建了Engine,在Engine内部实际上会创建一个Pool(连接池)和Dialect(方言),并且可以发现此时Engine并不会建立连接,只会等到执行到具体的语句时才会连接到数据库。上述代码默认本地已经存在并开启mysql服务。
|
||||
|
||||
对于 create_engine 函数可以有以下参数
|
||||
|
||||
```javascript
|
||||
create_engine("mysql://user:password@hostname/dbname?charset=utf8",
|
||||
echo=True,
|
||||
pool_size=8,
|
||||
pool_recycle=60*30)
|
||||
```
|
||||
|
||||
第一个参数是和框架表明连接数据库所需的信息,"数据库+数据库连接框架://用户名:密码@IP地址:端口号/数据库名称?连接参数";echo是设置当前ORM语句是否转化为SQL打印;pool_size是用来设置连接池大小,默认值为5;pool_recycle设置连接失效的时间,超过时间连接池会自动断开。
|
||||
|
||||
### 2.4.3 **创建数据库表类**
|
||||
|
||||
由于SQLAlchemy 是对象关系映射,在操作数据库表时需要通过操作对象实现,因此就需要创建一个数据库表类。
|
||||
|
||||
```python
|
||||
from sqlalchemy import create_engine, Column, Integer, String
|
||||
from sqlalchemy.ext.declarative import declarative_base
|
||||
|
||||
Base = declarative_base()
|
||||
|
||||
class User(Base):
|
||||
__tablename__ = 'UserInfo'
|
||||
index = Column(Integer(), primary_key=True)
|
||||
user_id = Column(Integer(), unique=True)
|
||||
username = Column(String(30))
|
||||
passwd = Column(String(500))
|
||||
|
||||
def __init__(self,index, user_id, username, passwd):
|
||||
self.index = index
|
||||
self.user_id = user_id
|
||||
self.username = username
|
||||
self.passwd = passwd
|
||||
```
|
||||
|
||||
通过declarative_base()函数,可以将python类和数据库表进行关联映射,并通过 \__tablename\__ 属性将数据库模型类和表进行管理。其中Column() 表示数据表中的列,Integer()和String()表示数据库的数据类型。
|
||||
|
||||
### 2.4.4 **操作数据库**
|
||||
|
||||
创建完连接之后,我们需要借助sqlalchemy中的session来创建程序与数据库之间的会话。换句话来说,需要通过session才能利用程序对数据库进行CURD。这里我们可以通过 sessionmaker() 函数来创建会话。
|
||||
|
||||
```python
|
||||
from sqlalchemy import create_engine
|
||||
from sqlalchemy.ext.declarative import declarative_base
|
||||
from sqlalchemy.orm import sessionmaker
|
||||
|
||||
Base = declarative_base()
|
||||
|
||||
def mysql_db(host='127.0.0.1',dbname='test'):
|
||||
engine = create_engine("mysql+pymysql://root:123456@{}:49168/{}?charset=utf8mb4".format(host,dbname))
|
||||
|
||||
session = sessionmaker(bind=engine)
|
||||
Base.metadata.create_all(engine)
|
||||
return engine, session()
|
||||
```
|
||||
|
||||
session常用的方法如下:
|
||||
|
||||
- flush:预提交,提交到数据库文件,还未写入数据库文件中
|
||||
- commit:提交了一个事务
|
||||
- rollback:回滚
|
||||
- close:关闭session连接
|
||||
|
||||
**增加数据**
|
||||
|
||||
增加一个用户:
|
||||
|
||||
```python
|
||||
engine, session = mysql_db()
|
||||
user = User("100","zhangsan","11111")
|
||||
session.add(user)
|
||||
session.commit()
|
||||
```
|
||||
|
||||
注意一点,session.add()不会直接提交到数据库,而是在 commit 时才会提交到数据库。add操作会把user加入当前session维护的持久空间(可以从session.dirty看到)中。
|
||||
|
||||
也可以通过add_all() 进行批量提交。
|
||||
|
||||
```python
|
||||
engine, session = mysql_db()
|
||||
user1 = User("101","lisi","11111")
|
||||
user2 = User("102","wangwu","22222")
|
||||
session.add_all([user1,user2])
|
||||
session.commit()
|
||||
```
|
||||
|
||||
**查询数据**
|
||||
|
||||
```python
|
||||
engine, session = mysql_db()
|
||||
users = session.query(User).filter_by(passwd='11111').all()
|
||||
|
||||
for item in users:
|
||||
print(item.username,item.passwd)
|
||||
```
|
||||
|
||||
通过上面代码可以查询获取数据,通过 **session.query()** 我们查询返回了一个Query对象,此时没有去数据库查询,只有等到.count() .first() .all() 具体函数时才会去数据库执行。还可以使用 **filter()** 方法查询,与 **filter_by()** 的区别如下:
|
||||
|
||||
| | |
|
||||
| :----------------------------------------- | :--------------------------- |
|
||||
| filter | filter_by |
|
||||
| 支持所有比较运算符,相等比较用比较用== | 只能使用"=","!="和"><" |
|
||||
| 过滤用类名.属性名 | 过滤用属性名 |
|
||||
| 不支持组合查询,只能连续调用filter变相实现 | 参数是**kwargs,支持组合查询 |
|
||||
| 支持and,or和in等 | |
|
||||
|
||||
**修改数据**
|
||||
|
||||
通过 query 中的 update() 方法:
|
||||
|
||||
```python
|
||||
session.query(User).filter_by(username="zhangsan").update({'passwd': "123456"})
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```python
|
||||
users = session.query(User).filter_by(username="zhangsan").first()
|
||||
users.username = "zhangsan-test"
|
||||
session.add(users)
|
||||
session.commit()
|
||||
```
|
||||
|
||||
**删除数据**
|
||||
|
||||
通过 query 中的 delete() 方法:
|
||||
|
||||
```python
|
||||
session.query(User).filter(User.username == "zhangsan-test").delete()
|
||||
session.commit()
|
||||
```
|
||||
|
||||
或者 通过 session.delete() 方法
|
||||
|
||||
```python
|
||||
users = session.query(User).filter(User.username == "lisi").first()
|
||||
if users:
|
||||
session.delete(users)
|
||||
session.commit()
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 参考资料
|
||||
|
||||
1. [Flask教程](https://www.w3cschool.cn/flask/flask_sqlalchemy.html)
|
||||
|
||||
2. [[SQLAlchemy 1.4 Documentation](https://www.osgeo.cn/sqlalchemy/index.html)
|
||||
|
||||
|
||||
511
docs/推荐系统实战/新闻推荐系统实践/scrapy基础及新闻爬取实战.md
Normal file
511
docs/推荐系统实战/新闻推荐系统实践/scrapy基础及新闻爬取实战.md
Normal file
@@ -0,0 +1,511 @@
|
||||
本文属于新闻推荐实战-数据层-构建物料池之scrapy爬虫框架基础。对于开源的推荐系统来说数据的不断获取是非常重要的,scrapy是一个非常易用且强大的爬虫框架,有固定的文件结构、类和方法,在实际使用过程中我们只需要按照要求实现相应的类方法,就可以完成我们的爬虫任务。文中给出了新闻推荐系统中新闻爬取的实战代码,希望读者可以快速掌握scrapy的基本使用方法,并能够举一反三。
|
||||
|
||||
## Scrapy基础及新闻爬取实战
|
||||
|
||||
### python环境的安装
|
||||
|
||||
python 环境,使用miniconda搭建,安装miniconda的参考链接:https://blog.csdn.net/pdcfighting/article/details/111503057。
|
||||
|
||||
在安装完miniconda之后,创建一个新闻推荐的虚拟环境,我这边将其命名为news_rec_py3,**这个环境将会在整个新闻推荐项目中使用。**
|
||||
|
||||
```C++
|
||||
conda create -n news_rec_py3 python==3.8
|
||||
```
|
||||
|
||||
### Scrapy的简介与安装
|
||||
|
||||
Scrapy 是一种快速的高级 web crawling 和 web scraping 框架,**用于对网站内容进行爬取,并从其页面提取结构化数据**。
|
||||
|
||||
Ubuntu下安装Scrapy,需要先安装依赖Linux依赖
|
||||
|
||||
```C++
|
||||
sudo apt-get install python3 python3-dev python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
|
||||
```
|
||||
|
||||
在新闻推荐系统虚拟conda环境中安装scrapy
|
||||
|
||||
```C++
|
||||
pip install scrapy
|
||||
```
|
||||
|
||||
#### scrapy项目结构
|
||||
|
||||
默认情况下,所有scrapy项目的项目结构都是相似的,在指定目录对应的命令行中输入如下命令,就会在当前目录创建一个scrapy项目
|
||||
|
||||
```
|
||||
scrapy startproject myproject
|
||||
```
|
||||
|
||||
项目的目录结构如下:
|
||||
|
||||
```C++
|
||||
myproject/
|
||||
scrapy.cfg
|
||||
|
||||
myproject/
|
||||
__init__.py
|
||||
items.py
|
||||
middlewares.py
|
||||
pipelines.py
|
||||
settings.py
|
||||
spiders/
|
||||
__init__.py
|
||||
```
|
||||
|
||||
- scrapy.cfg: 项目配置文件
|
||||
- myproject/ : 项目python模块, 代码将从这里导入
|
||||
- **myproject/ items.py: 项目items文件,**
|
||||
- **myproject/ pipelines.py: 项目管道文件,将爬取的数据进行持久化存储**
|
||||
- myproject/ settings.py: 项目配置文件,可以配置数据库等
|
||||
- **myproject/ spiders/: 放置spider的目录,爬虫的具体逻辑就是在这里实现的(具体逻辑写在spider.py文件中),可以使用命令行创建spider,也可以直接在这个文件夹中创建spider相关的py文件**
|
||||
- myproject/ middlewares:中间件,请求和响应都将经过他,可以配置请求头、代理、cookie、会话维持等
|
||||
|
||||
#### spider
|
||||
|
||||
**spider是定义一个特定站点(或一组站点)如何被抓取的类,包括如何执行抓取(即跟踪链接)以及如何从页面中提取结构化数据(即抓取项)。换言之,spider是为特定站点(或者在某些情况下,一组站点)定义爬行和解析页面的自定义行为的地方。**
|
||||
|
||||
爬行器是自己定义的类,Scrapy使用它从一个网站(或一组网站)中抓取信息。它们必须继承 `Spider` 并定义要做出的初始请求,可选的是如何跟随页面中的链接,以及如何解析下载的页面内容以提取数据。
|
||||
|
||||
对于spider来说,抓取周期是这样的:
|
||||
|
||||
1. 首先生成对第一个URL进行爬网的初始请求,然后指定一个回调函数,该函数使用从这些请求下载的响应进行调用。要执行的第一个请求是通过调用 `start_requests()` 方法,该方法(默认情况下)生成 `Request` 中指定的URL的 `start_urls` 以及 `parse` 方法作为请求的回调函数。
|
||||
2. 在回调函数中,解析响应(网页)并返回 [item objects](https://www.osgeo.cn/scrapy/topics/items.html#topics-items) , `Request` 对象,或这些对象的可迭代。这些请求还将包含一个回调(可能相同),然后由Scrapy下载,然后由指定的回调处理它们的响应。
|
||||
3. 在回调函数中,解析页面内容,通常使用 [选择器](https://www.osgeo.cn/scrapy/topics/selectors.html#topics-selectors) (但您也可以使用beautifulsoup、lxml或任何您喜欢的机制)并使用解析的数据生成项。
|
||||
4. 最后,从spider返回的项目通常被持久化到数据库(在某些 [Item Pipeline](https://www.osgeo.cn/scrapy/topics/item-pipeline.html#topics-item-pipeline) )或者使用 [Feed 导出](https://www.osgeo.cn/scrapy/topics/feed-exports.html#topics-feed-exports) .
|
||||
|
||||
**下面是官网给出的Demo:**
|
||||
|
||||
```python
|
||||
import scrapy
|
||||
|
||||
class QuotesSpider(scrapy.Spider):
|
||||
name = "quotes" # 表示一个spider 它在一个项目中必须是唯一的,即不能为不同的spider设置相同的名称。
|
||||
|
||||
# 必须返回请求的可迭代(您可以返回请求列表或编写生成器函数),spider将从该请求开始爬行。后续请求将从这些初始请求中相继生成。
|
||||
def start_requests(self):
|
||||
urls = [
|
||||
'http://quotes.toscrape.com/page/1/',
|
||||
'http://quotes.toscrape.com/page/2/',
|
||||
]
|
||||
for url in urls:
|
||||
yield scrapy.Request(url=url, callback=self.parse) # 注意,这里callback调用了下面定义的parse方法
|
||||
|
||||
# 将被调用以处理为每个请求下载的响应的方法。Response参数是 TextResponse 它保存页面内容,并具有进一步有用的方法来处理它。
|
||||
def parse(self, response):
|
||||
# 下面是直接从response中获取内容,为了更方便的爬取内容,后面会介绍使用selenium来模拟人用浏览器,并且使用对应的方法来提取我们想要爬取的内容
|
||||
page = response.url.split("/")[-2]
|
||||
filename = f'quotes-{page}.html'
|
||||
with open(filename, 'wb') as f:
|
||||
f.write(response.body)
|
||||
self.log(f'Saved file {filename}')
|
||||
```
|
||||
|
||||
#### Xpath
|
||||
|
||||
**XPath 是一门在 XML 文档中查找信息的语言,XPath 可用来在 XML 文档中对元素和属性进行遍历。在爬虫的时候使用xpath来选择我们想要爬取的内容是非常方便的**,这里就提一下xpath中需要掌握的内容,参考资料中的内容更加的详细(建议花一个小时看看)。
|
||||
|
||||
要了解xpath, 需要先了解一下HTML(是用来描述网页的一种语言), 这个的细节就不详细展开
|
||||
|
||||
**划重点:**
|
||||
|
||||
1. **xpath路径表达式:**XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
|
||||
|
||||
2. **了解如何使用xpath语法选取我们想要的内容,所以需要熟悉xpath的基本语法**
|
||||
|
||||
#### scrapy爬取新闻内容实战
|
||||
|
||||
在介绍这个项目之前先说一下这个项目的基本逻辑。
|
||||
|
||||
**环境准备:**
|
||||
|
||||
1. 首先Ubuntu系统里面需要安装好MongoDB数据库,这个可以参考开源项目MongoDB基础
|
||||
2. python环境中安装好了scrapy, pymongo包
|
||||
|
||||
**项目逻辑:**
|
||||
|
||||
1. 每天定时从新浪新闻网站上爬取新闻数据存储到mongodb数据库中,并且需要监控每天爬取新闻的状态(比如某天爬取的数据特别少可能是哪里出了问题,需要进行排查)
|
||||
2. 每天爬取新闻的时候只爬取当天日期的新闻,主要是为了防止相同的新闻重复爬取(当然这个也不能完全避免爬取重复的新闻,爬取新闻之后需要有一些单独的去重的逻辑)
|
||||
3. 爬虫项目中实现三个核心文件,分别是sina.py(spider),items.py(抽取数据的规范化及字段的定义),pipelines.py(数据写入数据库)
|
||||
|
||||
因为新闻爬取项目和新闻推荐系统是放在一起的,为了方便提前学习,下面直接给出项目的目录结构以及重要文件中的代码实现,最终的项目将会和新闻推荐系统一起开源出来
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211103214124327.png" alt="image-20211103214124327" style="zoom: 80%;" />
|
||||
|
||||
1. **创建一个scrapy项目:**
|
||||
|
||||
```shell
|
||||
scrapy startproject sinanews
|
||||
```
|
||||
|
||||
2. **实现items.py逻辑**
|
||||
|
||||
```python
|
||||
# Define here the models for your scraped items
|
||||
#
|
||||
# See documentation in:
|
||||
# https://docs.scrapy.org/en/latest/topics/items.html
|
||||
|
||||
import scrapy
|
||||
from scrapy import Item, Field
|
||||
|
||||
# 定义新闻数据的字段
|
||||
class SinanewsItem(scrapy.Item):
|
||||
"""数据格式化,数据不同字段的定义
|
||||
"""
|
||||
title = Field() # 新闻标题
|
||||
ctime = Field() # 新闻发布时间
|
||||
url = Field() # 新闻原始url
|
||||
raw_key_words = Field() # 新闻关键词(爬取的关键词)
|
||||
content = Field() # 新闻的具体内容
|
||||
cate = Field() # 新闻类别
|
||||
```
|
||||
|
||||
3. **实现sina.py (spider)逻辑**
|
||||
|
||||
这里需要注意的一点,这里在爬取新闻的时候选择的是一个比较简洁的展示网站进行爬取的,相比直接去最新的新浪新闻观光爬取新闻简单很多,简洁的网站大概的链接:https://news.sina.com.cn/roll/#pageid=153&lid=2509&k=&num=50&page=1
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211103213354334.png" alt="image-20211103213354334" style="zoom: 50%;" />
|
||||
|
||||
```python
|
||||
# -*- coding: utf-8 -*-
|
||||
import re
|
||||
import json
|
||||
import random
|
||||
import scrapy
|
||||
from scrapy import Request
|
||||
from ..items import SinanewsItem
|
||||
from datetime import datetime
|
||||
|
||||
|
||||
class SinaSpider(scrapy.Spider):
|
||||
# spider的名字
|
||||
name = 'sina_spider'
|
||||
|
||||
def __init__(self, pages=None):
|
||||
super(SinaSpider).__init__()
|
||||
|
||||
self.total_pages = int(pages)
|
||||
# base_url 对应的是新浪新闻的简洁版页面,方便爬虫,并且不同类别的新闻也很好区分
|
||||
self.base_url = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid={}&k=&num=50&page={}&r={}'
|
||||
# lid和分类映射字典
|
||||
self.cate_dict = {
|
||||
"2510": "国内",
|
||||
"2511": "国际",
|
||||
"2669": "社会",
|
||||
"2512": "体育",
|
||||
"2513": "娱乐",
|
||||
"2514": "军事",
|
||||
"2515": "科技",
|
||||
"2516": "财经",
|
||||
"2517": "股市",
|
||||
"2518": "美股"
|
||||
}
|
||||
|
||||
def start_requests(self):
|
||||
"""返回一个Request迭代器
|
||||
"""
|
||||
# 遍历所有类型的新闻
|
||||
for cate_id in self.cate_dict.keys():
|
||||
for page in range(1, self.total_pages + 1):
|
||||
lid = cate_id
|
||||
# 这里就是一个随机数,具体含义不是很清楚
|
||||
r = random.random()
|
||||
# cb_kwargs 是用来向解析函数parse中传递参数的
|
||||
yield Request(self.base_url.format(lid, page, r), callback=self.parse, cb_kwargs={"cate_id": lid})
|
||||
|
||||
def parse(self, response, cate_id):
|
||||
"""解析网页内容,并提取网页中需要的内容
|
||||
"""
|
||||
json_result = json.loads(response.text) # 将请求回来的页面解析成json
|
||||
# 提取json中我们想要的字段
|
||||
# json使用get方法比直接通过字典的形式获取数据更方便,因为不需要处理异常
|
||||
data_list = json_result.get('result').get('data')
|
||||
for data in data_list:
|
||||
item = SinanewsItem()
|
||||
|
||||
item['cate'] = self.cate_dict[cate_id]
|
||||
item['title'] = data.get('title')
|
||||
item['url'] = data.get('url')
|
||||
item['raw_key_words'] = data.get('keywords')
|
||||
|
||||
# ctime = datetime.fromtimestamp(int(data.get('ctime')))
|
||||
# ctime = datetime.strftime(ctime, '%Y-%m-%d %H:%M')
|
||||
|
||||
# 保留的是一个时间戳
|
||||
item['ctime'] = data.get('ctime')
|
||||
|
||||
# meta参数传入的是一个字典,在下一层可以将当前层的item进行复制
|
||||
yield Request(url=item['url'], callback=self.parse_content, meta={'item': item})
|
||||
|
||||
def parse_content(self, response):
|
||||
"""解析文章内容
|
||||
"""
|
||||
item = response.meta['item']
|
||||
content = ''.join(response.xpath('//*[@id="artibody" or @id="article"]//p/text()').extract())
|
||||
content = re.sub(r'\u3000', '', content)
|
||||
content = re.sub(r'[ \xa0?]+', ' ', content)
|
||||
content = re.sub(r'\s*\n\s*', '\n', content)
|
||||
content = re.sub(r'\s*(\s)', r'\1', content)
|
||||
content = ''.join([x.strip() for x in content])
|
||||
item['content'] = content
|
||||
yield item
|
||||
```
|
||||
|
||||
4. **数据持久化实现,piplines.py**
|
||||
|
||||
这里需要注意的就是实现SinanewsPipeline类的时候,里面很多方法都是固定的,不是随便写的,不同的方法又不同的功能,这个可以参考scrapy官方文档。
|
||||
|
||||
```python
|
||||
# Define your item pipelines here
|
||||
#
|
||||
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
|
||||
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
|
||||
# useful for handling different item types with a single interface
|
||||
import time
|
||||
import datetime
|
||||
import pymongo
|
||||
from pymongo.errors import DuplicateKeyError
|
||||
from sinanews.items import SinanewsItem
|
||||
from itemadapter import ItemAdapter
|
||||
|
||||
|
||||
# 新闻item持久化
|
||||
class SinanewsPipeline:
|
||||
"""数据持久化:将数据存放到mongodb中
|
||||
"""
|
||||
def __init__(self, host, port, db_name, collection_name):
|
||||
self.host = host
|
||||
self.port = port
|
||||
self.db_name = db_name
|
||||
self.collection_name = collection_name
|
||||
|
||||
@classmethod
|
||||
def from_crawler(cls, crawler):
|
||||
"""自带的方法,这个方法可以重新返回一个新的pipline对象,并且可以调用配置文件中的参数
|
||||
"""
|
||||
return cls(
|
||||
host = crawler.settings.get("MONGO_HOST"),
|
||||
port = crawler.settings.get("MONGO_PORT"),
|
||||
db_name = crawler.settings.get("DB_NAME"),
|
||||
# mongodb中数据的集合按照日期存储
|
||||
collection_name = crawler.settings.get("COLLECTION_NAME") + \
|
||||
"_" + time.strftime("%Y%m%d", time.localtime())
|
||||
)
|
||||
|
||||
def open_spider(self, spider):
|
||||
"""开始爬虫的操作,主要就是链接数据库及对应的集合
|
||||
"""
|
||||
self.client = pymongo.MongoClient(self.host, self.port)
|
||||
self.db = self.client[self.db_name]
|
||||
self.collection = self.db[self.collection_name]
|
||||
|
||||
def close_spider(self, spider):
|
||||
"""关闭爬虫操作的时候,需要将数据库断开
|
||||
"""
|
||||
self.client.close()
|
||||
|
||||
def process_item(self, item, spider):
|
||||
"""处理每一条数据,注意这里需要将item返回
|
||||
注意:判断新闻是否是今天的,每天只保存当天产出的新闻,这样可以增量的添加新的新闻数据源
|
||||
"""
|
||||
if isinstance(item, SinanewsItem):
|
||||
try:
|
||||
# TODO 物料去重逻辑,根据title进行去重,先读取物料池中的所有物料的title然后进行去重
|
||||
|
||||
cur_time = int(item['ctime'])
|
||||
str_today = str(datetime.date.today())
|
||||
min_time = int(time.mktime(time.strptime(str_today + " 00:00:00", '%Y-%m-%d %H:%M:%S')))
|
||||
max_time = int(time.mktime(time.strptime(str_today + " 23:59:59", '%Y-%m-%d %H:%M:%S')))
|
||||
if cur_time > min_time and cur_time <= max_time:
|
||||
self.collection.insert(dict(item))
|
||||
except DuplicateKeyError:
|
||||
"""
|
||||
说明有重复
|
||||
"""
|
||||
pass
|
||||
return item
|
||||
```
|
||||
|
||||
5. 配置文件,settings.py
|
||||
|
||||
```python
|
||||
# Scrapy settings for sinanews project
|
||||
#
|
||||
# For simplicity, this file contains only settings considered important or
|
||||
# commonly used. You can find more settings consulting the documentation:
|
||||
#
|
||||
# https://docs.scrapy.org/en/latest/topics/settings.html
|
||||
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
|
||||
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
|
||||
|
||||
from typing import Collection
|
||||
|
||||
BOT_NAME = 'sinanews'
|
||||
|
||||
SPIDER_MODULES = ['sinanews.spiders']
|
||||
NEWSPIDER_MODULE = 'sinanews.spiders'
|
||||
|
||||
|
||||
# Crawl responsibly by identifying yourself (and your website) on the user-agent
|
||||
#USER_AGENT = 'sinanews (+http://www.yourdomain.com)'
|
||||
|
||||
# Obey robots.txt rules
|
||||
ROBOTSTXT_OBEY = True
|
||||
|
||||
# Configure maximum concurrent requests performed by Scrapy (default: 16)
|
||||
#CONCURRENT_REQUESTS = 32
|
||||
|
||||
# Configure a delay for requests for the same website (default: 0)
|
||||
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
|
||||
# See also autothrottle settings and docs
|
||||
# DOWNLOAD_DELAY = 3
|
||||
# The download delay setting will honor only one of:
|
||||
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
|
||||
#CONCURRENT_REQUESTS_PER_IP = 16
|
||||
|
||||
# Disable cookies (enabled by default)
|
||||
#COOKIES_ENABLED = False
|
||||
|
||||
# Disable Telnet Console (enabled by default)
|
||||
#TELNETCONSOLE_ENABLED = False
|
||||
|
||||
# Override the default request headers:
|
||||
#DEFAULT_REQUEST_HEADERS = {
|
||||
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
|
||||
# 'Accept-Language': 'en',
|
||||
#}
|
||||
|
||||
# Enable or disable spider middlewares
|
||||
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
|
||||
#SPIDER_MIDDLEWARES = {
|
||||
# 'sinanews.middlewares.SinanewsSpiderMiddleware': 543,
|
||||
#}
|
||||
|
||||
# Enable or disable downloader middlewares
|
||||
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
|
||||
#DOWNLOADER_MIDDLEWARES = {
|
||||
# 'sinanews.middlewares.SinanewsDownloaderMiddleware': 543,
|
||||
#}
|
||||
|
||||
# Enable or disable extensions
|
||||
# See https://docs.scrapy.org/en/latest/topics/extensions.html
|
||||
#EXTENSIONS = {
|
||||
# 'scrapy.extensions.telnet.TelnetConsole': None,
|
||||
#}
|
||||
|
||||
# Configure item pipelines
|
||||
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
|
||||
# 如果需要使用itempipline来存储item的话需要将这段注释打开
|
||||
ITEM_PIPELINES = {
|
||||
'sinanews.pipelines.SinanewsPipeline': 300,
|
||||
}
|
||||
|
||||
# Enable and configure the AutoThrottle extension (disabled by default)
|
||||
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
|
||||
#AUTOTHROTTLE_ENABLED = True
|
||||
# The initial download delay
|
||||
#AUTOTHROTTLE_START_DELAY = 5
|
||||
# The maximum download delay to be set in case of high latencies
|
||||
#AUTOTHROTTLE_MAX_DELAY = 60
|
||||
# The average number of requests Scrapy should be sending in parallel to
|
||||
# each remote server
|
||||
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
|
||||
# Enable showing throttling stats for every response received:
|
||||
#AUTOTHROTTLE_DEBUG = False
|
||||
|
||||
# Enable and configure HTTP caching (disabled by default)
|
||||
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
|
||||
#HTTPCACHE_ENABLED = True
|
||||
#HTTPCACHE_EXPIRATION_SECS = 0
|
||||
#HTTPCACHE_DIR = 'httpcache'
|
||||
#HTTPCACHE_IGNORE_HTTP_CODES = []
|
||||
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
|
||||
|
||||
MONGO_HOST = "127.0.0.1"
|
||||
MONGO_PORT = 27017
|
||||
DB_NAME = "SinaNews"
|
||||
COLLECTION_NAME = "news"
|
||||
```
|
||||
|
||||
6. 监控脚本,monitor_news.py
|
||||
|
||||
```python
|
||||
# -*- coding: utf-8 -*-
|
||||
import sys, time
|
||||
import pymongo
|
||||
import scrapy
|
||||
from sinanews.settings import MONGO_HOST, MONGO_PORT, DB_NAME, COLLECTION_NAME
|
||||
|
||||
if __name__ == "__main__":
|
||||
news_num = int(sys.argv[1])
|
||||
time_str = time.strftime("%Y%m%d", time.localtime())
|
||||
|
||||
# 实际的collection_name
|
||||
collection_name = COLLECTION_NAME + "_" + time_str
|
||||
|
||||
# 链接数据库
|
||||
client = pymongo.MongoClient(MONGO_HOST, MONGO_PORT)
|
||||
db = client[DB_NAME]
|
||||
collection = db[collection_name]
|
||||
|
||||
# 查找当前集合中所有文档的数量
|
||||
cur_news_num = collection.count()
|
||||
|
||||
print(cur_news_num)
|
||||
if cur_news_num < news_num:
|
||||
print("the news nums of {}_{} collection is less then {}".\
|
||||
format(COLLECTION_NAME, time_str, news_num))
|
||||
```
|
||||
|
||||
7. 运行脚本,run_scrapy_sina.sh
|
||||
|
||||
```python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
新闻爬取及监控脚本
|
||||
"""
|
||||
|
||||
# 设置python环境
|
||||
python="/home/recsys/miniconda3/envs/news_rec_py3/bin/python"
|
||||
|
||||
# 新浪新闻网站爬取的页面数量
|
||||
page="1"
|
||||
min_news_num="1000" # 每天爬取的新闻数量少于500认为是异常
|
||||
|
||||
# 爬取数据
|
||||
scrapy crawl sina_spider -a pages=${page}
|
||||
if [ $? -eq 0 ]; then
|
||||
echo "scrapy crawl sina_spider --pages ${page} success."
|
||||
else
|
||||
echo "scrapy crawl sina_spider --pages ${page} fail."
|
||||
fi
|
||||
|
||||
# 检查今天爬取的数据是否少于min_news_num篇文章,这里也可以配置邮件报警
|
||||
python monitor_news.py ${min_news_num}
|
||||
if [ $? -eq 0 ]; then
|
||||
echo "run python monitor_news.py success."
|
||||
else
|
||||
echo "run python monitor_news.py fail."
|
||||
fi
|
||||
```
|
||||
|
||||
8. 运行项目命令
|
||||
|
||||
```
|
||||
sh run_scrapy_sina.sh
|
||||
```
|
||||
|
||||
最终查看数据库中的数据:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211103214611171.png" alt="image-20211103214611171" style="zoom:80%;" />
|
||||
|
||||
### 参考资料
|
||||
|
||||
1. [MongoDB基础](https://github.com/datawhalechina/fun-rec/blob/master/docs/%E7%AC%AC%E4%BA%8C%E7%AB%A0%20%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E5%AE%9E%E6%88%98/2.2%E6%96%B0%E9%97%BB%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E5%AE%9E%E6%88%98/docs/MongoDB%E5%9F%BA%E7%A1%80.md)
|
||||
2. [Scrapy框架新手入门教程](https://blog.csdn.net/sxf1061700625/article/details/106866547/)
|
||||
3. [scrapy中文文档](https://www.osgeo.cn/scrapy/index.html)
|
||||
4. [Xpath教程](https://www.w3school.com.cn/xpath/index.asp)
|
||||
5. https://github.com/Ingram7/NewsinaSpider
|
||||
|
||||
6. https://www.cnblogs.com/zlslch/p/6931838.html
|
||||
|
||||
448
docs/推荐系统实战/新闻推荐系统实践/前后端交互.md
Normal file
448
docs/推荐系统实战/新闻推荐系统实践/前后端交互.md
Normal file
@@ -0,0 +1,448 @@
|
||||
本文属于新闻推荐实战—前后端基础及交互—前后端交互部分。在前两节,我们分别简单的介绍了与本项目相关的前后的基础知识,目的是为了让大家更加细致的了解整个系统的前后端交互细节,以及更全面的了解一个推荐系统所需的组成部分。本文将从前后端的交互逻辑出发,更加全面的为大家讲解系统的每个细节,了解一个简单的推荐系统内的内部组成。
|
||||
|
||||
|
||||
|
||||
### 项目样式展现
|
||||
|
||||
下面主要展现的是项目的整体部分,主要分为推荐页,热门页以及新闻详情页。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211203154557244.png" alt="image-20211203154557244" style="zoom:70%;" /><img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211203155028564.png" alt="image-20211203155028564" style="zoom:70%;" /><img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211203155058020.png" alt="image-20211203155058020" style="zoom:70%;" />
|
||||
|
||||
|
||||
|
||||
## 后端目录结构
|
||||
|
||||
```
|
||||
news_rec_sys/
|
||||
conf/
|
||||
dao_config.py
|
||||
controller/
|
||||
dao/
|
||||
materials/
|
||||
news_scrapy/
|
||||
user_proccess/
|
||||
material_proccess
|
||||
recpocess/
|
||||
recall/
|
||||
rank/
|
||||
online.py
|
||||
offline.py
|
||||
scheduler/
|
||||
server.py
|
||||
```
|
||||
|
||||
- **conf/dao_config.py: 候选整体配置文件**
|
||||
- **controller/ : 项目中用于操作数据库的接口**
|
||||
- **dao/ : 项目的实体类,对应数据库表**
|
||||
- **materials/: 项目的物料部分,主要用户爬取物料以及处理用户画像和新闻画像**
|
||||
- **recpocess/: 项目的推荐模块,主要包含召回和排序,以及一些线上服务和线下处理部分**
|
||||
- scheduler: 项目的定时任务的脚本部分,
|
||||
- server.py: 项目后端的入口部分,主要包含项目整体的后端接口部分。
|
||||
|
||||
在该项目中,前端主要使用的是Vue框架+mint-ui,后端主要使用的是Flask+Mysql+Mongodb+Redis来完成的,并且前后端采用分离的方式,通过json格式进行数据传递。其中该项目后端的主要逻辑在在server.py中,其中主要包含用户注册和登录,推荐列表,热门列表,获取新闻详情页以及用户的行为等功能。接下来将主要按照这几部分详细的介绍一下前后端如何进行交互。
|
||||
|
||||
|
||||
|
||||
### 1、用户注册登录
|
||||
为了能够对用户进行千人千面的推荐,因此需要每个使用该系统的人都需要明确先进行注册登入,为每个用户生成唯一的用户id,根据用户的历史行为,实现对用户进行个性化推荐的效果。
|
||||
|
||||
**注册部分:**
|
||||
|
||||
```python
|
||||
def register():
|
||||
"""用户注册"""
|
||||
request_str = request.get_data()
|
||||
request_dict = json.loads(request_str)
|
||||
|
||||
user = RegisterUser()
|
||||
user.username = request_dict["username"]
|
||||
user.passwd = request_dict["passwd"]
|
||||
|
||||
# 查询当前用户名是否已经被用过了
|
||||
result = UserAction().user_is_exist(user, "register")
|
||||
if result != 0:
|
||||
return jsonify({"code": 500, "mgs": "this username is exists"})
|
||||
|
||||
user.userid = snowflake.client.get_guid() # 雪花算法生成唯一的用户id
|
||||
|
||||
user.age = request_dict["age"]
|
||||
user.gender = request_dict["gender"]
|
||||
user.city = request_dict["city"]
|
||||
|
||||
save_res = UserAction().save_user(user) # 将注册用户信息加入mysql
|
||||
if not save_res:
|
||||
return jsonify({"code": 500, "mgs": "register fail."})
|
||||
|
||||
return jsonify({"code": 200, "msg": "register success."})
|
||||
```
|
||||
|
||||
可以看到,上面的注册部分主要是记录一些用户的一些基础属性,并将用户的注册信息写入msyql表当中。值得注意的是,为了防止并发问题导致用户id出现冲突,这里采用了Twitter的雪花算法来为每个用户生成一个唯一的id。
|
||||
|
||||
**登录部分:**
|
||||
|
||||
```python
|
||||
@app.route('/recsys/login', methods=["POST"])
|
||||
def login():
|
||||
"""用户登录
|
||||
"""
|
||||
request_str = request.get_data()
|
||||
request_dict = json.loads(request_str)
|
||||
|
||||
user = RegisterUser()
|
||||
user.username = request_dict["username"]
|
||||
user.passwd = request_dict["passwd"]
|
||||
|
||||
# 查询数据库中的用户名或者密码是否存在
|
||||
try:
|
||||
result = UserAction().user_is_exist(user, "login")
|
||||
# print(result,"login")
|
||||
if result == 1:
|
||||
return jsonify({"code": 200, "msg": "login success"})
|
||||
elif result == 2:
|
||||
# 密码错误
|
||||
return jsonify({"code": 500, "msg": "passwd is error"})
|
||||
else:
|
||||
return jsonify({"code": 500, "msg": "this username is not exist!"})
|
||||
except Exception as e:
|
||||
return jsonify({"code": 500, "mgs": "login fail."})
|
||||
```
|
||||
|
||||
用户登陆部分,前端通过将输入的账号密码通过POST请求传给 /recsys/login,通过UserAction().user_is_exist()方法查询数据库中的用户名或者密码是否存在,其中1表示账号密码正确,2表示密码错误,0表示用户不存在。
|
||||
|
||||
|
||||
|
||||
### 2、推荐页列表
|
||||
|
||||
在项目样式展现的部分中,第一张图就是推荐页列表的样式,通过瀑布流的方式将新闻内容进行展现。
|
||||
|
||||
```python
|
||||
@app.route('/recsys/rec_list', methods=["GET"])
|
||||
def rec_list():
|
||||
"""推荐页"""
|
||||
user_name = request.args.get('user_id')
|
||||
page_id = request.args.get('page_id')
|
||||
|
||||
# 查询用户的id
|
||||
user_id = UserAction().get_user_id_by_name(user_name)
|
||||
if not user_id:
|
||||
return False
|
||||
|
||||
if user_id is None or page_id is None:
|
||||
return jsonify({"code": 2000, "msg": "user_id or page_id is none!"})
|
||||
try:
|
||||
# 获取推荐列表新闻信息
|
||||
rec_news_list = recsys_server.get_rec_list(user_id, page_id)
|
||||
if len(rec_news_list) == 0:
|
||||
return jsonify({"code": 500, "msg": "rec_list data is empty."})
|
||||
return jsonify({"code": 200, "msg": "request rec_list success.", "data": rec_news_list, "user_id": user_id})
|
||||
except Exception as e:
|
||||
print(str(e))
|
||||
return jsonify({"code": 500, "msg": "redis fail."})
|
||||
```
|
||||
|
||||
该部分的主要逻辑是前端通过请求 "/recsys/rec_list" 接口,后端通过前端传递过来的用户姓名,从数据库中获取用户id,再根据用户id去推荐服务(recsys_server)中获取到推荐列表。
|
||||
|
||||
|
||||
|
||||
#### 2.1、获取用户推荐列表
|
||||
|
||||
我们知道用户的推荐列表是通过推荐服务的 get_rec_list(user_id, page_id) 接口获取到的。其中需要两个参数:
|
||||
|
||||
- user_id:通过用户id,我们可以去redis中查找已经给用户构建好的新闻列表,将新闻信息返回给前端。
|
||||
- page_id:通过page id定位到目前已经给用户推荐到列表的位置,然后在从该位置之后去新的新闻内容。
|
||||
|
||||
```python
|
||||
def get_rec_list(self, user_id, page_id):
|
||||
"""给定页面的展示范围进行展示 user_id 后面做个性化推荐的时候需要用到"""
|
||||
# 根据page id计算需要获取redis中哪些范围的news_id, 假设每一页展示10个新闻
|
||||
s = (int(page_id) - 1) * 10
|
||||
e = s + 9
|
||||
|
||||
# 返回的是一个news_id列表
|
||||
news_id_list = self.reclist_redis_db.zrange("rec_list", start=s, end=e)
|
||||
|
||||
# 根据news_id获取新闻的具体内容,并返回一个列表,列表中的元素是按照顺序展示的新闻信息字典
|
||||
news_info_list = []
|
||||
news_expose_list = []
|
||||
for news_id in news_id_list:
|
||||
news_info_dict = self._get_news_simple(news_id)
|
||||
news_info_list.append(news_info_dict)
|
||||
news_expose_list.append(news_info_dict["news_id"]) # 记录在用户曝光表上[user_exposure]
|
||||
|
||||
self._save_user_exposure(user_id,news_expose_list) # 曝光落表
|
||||
return news_info_list
|
||||
```
|
||||
|
||||
这里的逻辑,主要是先根据page id,计算从redis中推荐列表取的范围。在得到新闻id列表之后,通过_get_news_simple() 方法从mysql何redis中获取新闻列表所需的展现内容。
|
||||
|
||||
为了提高用户体验,这里考虑将已经在推荐列表中给用户曝光过的新闻,当天内不会再通过热门页对用户进行曝光。因此这里需要利用_save_user_exposure()方法来将已经曝光过的新闻存储到redis中,这样在热门推荐中,针对用户的曝光会对热门推荐的内容进行过滤。
|
||||
|
||||
返回的数据格式如下:
|
||||
|
||||
```json
|
||||
"data": [
|
||||
{
|
||||
"news_id": "4bfb8aab-bcd8-4c74-b7fd-92b28ca5df69",
|
||||
"cate": "国内",
|
||||
"read_num": 0,
|
||||
"likes": 0,
|
||||
"collections": 0,
|
||||
"ctime": "2021-11-30 12:07",
|
||||
"title": "北京市政协十三届五次会议将于2022年1月5日召开"
|
||||
},
|
||||
...
|
||||
{
|
||||
"news_id": "4ded60ac-aa2f-408b-af4d-09ca0c58b50a",
|
||||
"cate": "国内",
|
||||
"read_num": 6,
|
||||
"likes": 1,
|
||||
"collections": 0,
|
||||
"ctime": "2021-11-30 10:44",
|
||||
"title": "江西万载县委原书记胡全顺获刑十一年六个月"
|
||||
}]
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 3、热门推荐页
|
||||
热门推荐页部分,前端通过请求'/recsys/hot_list'接口,通过传递用户姓名和当前页号来获取热门新闻列表。主要的逻辑和获取推荐页相同,区别在于热门新闻信息主要是通过推荐服务(recsys_server)中的get_hot_list()方法来获取到热门新闻推荐列表。
|
||||
|
||||
```python
|
||||
@app.route('/recsys/hot_list', methods=["GET"])
|
||||
def hot_list():
|
||||
"""热门页面"""
|
||||
if request.method == "GET":
|
||||
user_name = request.args.get('user_id')
|
||||
page_id = request.args.get('page_id')
|
||||
|
||||
if user_name is None or page_id is None:
|
||||
return jsonify({"code": 2000, "msg": "user_name or page_id is none!"})
|
||||
|
||||
# 查询用户的id
|
||||
user_id = UserAction().get_user_id_by_name(user_name)
|
||||
if not user_id:
|
||||
return False
|
||||
|
||||
try:
|
||||
# # 获取热门列表新闻信息
|
||||
rec_news_list = recsys_server.get_hot_list(user_id)
|
||||
|
||||
if len(rec_news_list) == 0:
|
||||
return jsonify({"code": 200, "msg": "request redis data fail."})
|
||||
# rec_news_list = recsys_server.get_hot_list(user_id, page_id)
|
||||
return jsonify({"code": 200, "msg": "request hot_list success.", "data": rec_news_list, "user_id": user_id})
|
||||
except Exception as e:
|
||||
print(str(e))
|
||||
return jsonify({"code": 2000, "msg": "request hot_list fail."})
|
||||
```
|
||||
|
||||
可以看到这里其实在后端逻辑上和推荐列表部分相似,主要在于get_hot_list()和get_rec_list()的区别;而热门推荐部分内在的细节内容,将会在后面详细介绍,这里不再赘述。
|
||||
|
||||
|
||||
|
||||
### 4、 新闻详情页
|
||||
|
||||
在项目样式展现的部分中,第三附图就是新闻详情页的样式。该部分主要包含一些新闻的详细信息,其中还有两个按钮,用于收集用户的显性反馈,用户可以根据自己对该文章的喜好程度进行喜欢和收藏的反馈内容。
|
||||
|
||||
```python
|
||||
@app.route('/recsys/news_detail', methods=["GET"])
|
||||
def news_detail():
|
||||
"""一篇文章的详细信息"""
|
||||
user_name = request.args.get('user_name')
|
||||
news_id = request.args.get('news_id')
|
||||
|
||||
user_id = UserAction().get_user_id_by_name(user_name)
|
||||
|
||||
# if news_id is None or user_id is None:
|
||||
if news_id is None or user_name is None:
|
||||
return jsonify({"code": 2000, "msg": "news_id is none or user_name is none!"})
|
||||
try:
|
||||
news_detail = recsys_server.get_news_detail(news_id)
|
||||
|
||||
if UserAction().get_likes_counts_by_user(user_id,news_id) > 0:
|
||||
news_detail["likes"] = True
|
||||
else:
|
||||
news_detail["likes"] = False
|
||||
|
||||
if UserAction().get_coll_counts_by_user(user_id,news_id) > 0:
|
||||
news_detail["collections"] = True
|
||||
else:
|
||||
news_detail["collections"] = False
|
||||
# print("test",news_detail)
|
||||
return jsonify({"code": 0, "msg": "request news_detail success.", "data": news_detail})
|
||||
except Exception as e:
|
||||
print(str(e))
|
||||
return jsonify({"code": 2000, "msg": "error"})
|
||||
```
|
||||
|
||||
上面就是详情页的后端逻辑,通过用户名字从mysql中获取用户id信息。防止用户id或者 page id出现空值的情况,需要进行判断。紧接着通过recsys_server服务的get_news_detail()方法,根据新闻的id进行获取内容。
|
||||
|
||||
如果用户对该新闻之前点击过喜欢或收藏,再次点击该新闻应该在喜欢或收藏按钮应该是点亮状态,因此还需要根据mysql中再次查询用户与该新闻是否存在记录,并将结果返回给前端,将其进行点亮展示。这里采用两个字段likes和collections,通过True,False来判断用户对该文章之前是否点击过喜欢或收藏。
|
||||
|
||||
返回的数据格式如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"code": 0,
|
||||
"data": {
|
||||
"news_id": "4ded60ac-aa2f-408b-af4d-09ca0c58b50a",
|
||||
"cate": "军事",
|
||||
"title": "运-20加油机首次现身台海上空 堪称“战力倍增器”",
|
||||
"content": "原标题:视频丨运-20加油机首次现身台海上空,堪称“战力倍增器”据台湾“中央社”报道,台防务部门晚间发布最新动态,11月28日白天解放军空军有27架次多型战机出现在了台湾所谓“西南空域”。首度被台媒披露现身台海的运油-20,是以国产运-20大型远程运输机为平台改装的空中加油机。据媒体测算,运油-20加油机装载燃油超过100吨,能大幅提升战机的空中续航能力,堪称“战力倍增器”。",
|
||||
"collections": true,
|
||||
"read_num": 6,
|
||||
"likes": true,
|
||||
"ctime": "2021-11-30 10:44",
|
||||
"url": "https://news.sina.com.cn/c/2021-11-30/doc-ikyakumx1093113.shtml"
|
||||
},
|
||||
"msg": "request news_detail success."
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 5、用户的行为
|
||||
|
||||
在该系统中,用户在看新闻时主要会留下三种用户行为:一是阅读,即用户在点击一篇新闻的详细页时,用户产生的行为;二是喜欢,在新闻详情页下面会存在喜欢按钮,用户可以通过点击按钮触发系统记录该行为;三是收藏,和喜欢行为同理,需要通过用户主动的方式来触发。
|
||||
|
||||
因此在用户点进一篇新闻的详情页时候,前端会发送一个请求,并给后端传递一个json格式数据:
|
||||
|
||||
```json
|
||||
{
|
||||
"user_name":"wang",
|
||||
"news_id":"0a745412-db48-4e37-bf13-9a5b56028f7e",
|
||||
"action_time":1638532127190,
|
||||
"action_type":"read"
|
||||
}
|
||||
```
|
||||
|
||||
在点击喜欢或收藏按钮的时候同样会产生一个请求,并发送json数据:
|
||||
|
||||
```json
|
||||
//点击喜欢
|
||||
{
|
||||
"user_name":"wang",
|
||||
"news_id":"0a745412-db48-4e37-bf13-9a5b56028f7e",
|
||||
"action_time":1638532127190,
|
||||
"action_type":"like:ture"
|
||||
}
|
||||
|
||||
//点击收藏
|
||||
{
|
||||
"user_name":"wang",
|
||||
"news_id":"0a745412-db48-4e37-bf13-9a5b56028f7e",
|
||||
"action_time":1638532127190,
|
||||
"action_type":"collections:true"
|
||||
}
|
||||
```
|
||||
|
||||
通过前端的传递的数据,后端对应的接口可以通过传递的参数对用户行为进行记录:
|
||||
|
||||
```python
|
||||
@app.route('/recsys/action', methods=["POST"])
|
||||
def actions():
|
||||
"""用户的行为:阅读,点赞,收藏"""
|
||||
request_str = request.get_data()
|
||||
request_dict = json.loads(request_str)
|
||||
|
||||
username = request_dict.get('user_name')
|
||||
newsid = request_dict.get('news_id')
|
||||
actiontype = request_dict.get("action_type")
|
||||
actiontime = request_dict.get("action_time")
|
||||
|
||||
userid = UserAction().get_user_id_by_name(username) # 获取用户 id
|
||||
if not userid:
|
||||
return jsonify({"code": 2000, "msg": "user not register"})
|
||||
|
||||
action_type_list = actiontype.split(":")
|
||||
|
||||
if len(action_type_list) == 2:
|
||||
_action_type = action_type_list[0]
|
||||
if action_type_list[1] == "false": # 如果这个参数为false的话, 表示数据库中存在记录 需要删除数据
|
||||
if _action_type=="likes":
|
||||
UserAction().del_likes_by_user(userid,newsid) # 删除用户喜欢记录
|
||||
elif _action_type=="collections":
|
||||
UserAction().del_coll_by_user(userid,newsid) # 删除用户收藏记录
|
||||
else:
|
||||
if _action_type=="likes": # 如果这个参数为true的话, 表示数据库中不存在记录 需要添加数据
|
||||
userlikes = UserLikes()
|
||||
userlikes.new(userid,username,newsid)
|
||||
UserAction().save_one_action(userlikes) # 记录用户喜欢记录
|
||||
elif _action_type=="collections":
|
||||
usercollections = UserCollections()
|
||||
usercollections.new(userid,username,newsid)
|
||||
UserAction().save_one_action(usercollections) # 记录用户收藏记录
|
||||
|
||||
try:
|
||||
# 落日志
|
||||
logitem = LogItem()
|
||||
logitem.new(userid,newsid,action_type_list[0])
|
||||
LogController().save_one_log(logitem)
|
||||
|
||||
# 更新redis中的展示数据 新闻侧
|
||||
recsys_server.update_news_dynamic_info(news_id=newsid,action_type=action_type_list)
|
||||
return jsonify({"code": 200, "msg": "action success"})
|
||||
|
||||
except Exception as e:
|
||||
print(str(e))
|
||||
return jsonify({"code": 2000, "msg": "action error"})
|
||||
```
|
||||
|
||||
上述代码中主要存在三部分内容:
|
||||
|
||||
|
||||
|
||||
**用户行为记录:**
|
||||
|
||||
在前端传递过来的数据中存在一个字段 "action_type":"like:ture" 或 "action_type":"like:false"(收藏行为类似),对于action_type参数,其值会是一个组合字符串,冒号前面表示用户的具体行为,冒号后面表示用户当前的行为是点击喜欢还是取消喜欢(例如用户误触导致,用户再次点击则会取消)。
|
||||
|
||||
通过**true**和**false**我们不仅可以知道当前用户是点击还是取消,其实还可以知道在数据库中是否存在该用户对该新闻的行为记录。原因是当传递来的是**false**时,表明**like**的状态是从**true**变为**false**,因此数据库中肯定会存在该记录,如果是**true**,表明like的状态是从**false**变为**true**,表明此时数据库中不存在该用户对该新闻的行为记录。通过这样的方式,我们可以比较简单的对数据库进行操作,记录用户的行为。
|
||||
|
||||
|
||||
|
||||
**用户行为落日志:**
|
||||
|
||||
在企业中,任何系统都会有日志的存在,其中最主要的作用是,日志相当于一个监控器,可以随时监测系统是否出现故障,通过日志可以及时定位系统中可能存在的问题。但是我们说的日志还有所区别,我们这里所说的日志主要是记录的一些线上信息,通过日志的方式进行记录,类似于我们这个系统,用户线上存在的行为,对于我们来说是十分具有意义的,我们需要通过分析这样的用户行为来更好的了解用户兴趣,从而进行更加个性化的推荐。因此我们可以借助日志的方式来记录有意义的用户数据,通过日志数据去分析数据,构建模型,这对于一个算法工程师来说是十分重要的内容。
|
||||
|
||||
当然在我们这个新闻推荐系统中,我们这么做的原因有一下几点:
|
||||
|
||||
- 通过这样的方式让大家体会到日志的意义,我们可以直接通过日志获取一些线上有意义的用户数据。
|
||||
- 通过日志数据,可以帮助我们更新用户画像中的一些动态特征。
|
||||
- 在后面构建模型时,我们也能获取到用户的一些点击率,收藏率的建模,为后面的工作提供数据基础。
|
||||
|
||||
上诉代码中,我们通过 LogController() 的 save_one_log() 方法对数据进行了存储到了mysql中。
|
||||
|
||||
|
||||
|
||||
**新闻动态数据更新**
|
||||
|
||||
由于我们在展现时会显示该新闻的阅读人数、喜欢人数和收藏人数,因此用户的行为实际上会改变新闻这三个属性。因此我们需要更新redis中新闻的这些动态的数据。
|
||||
|
||||
主要是通过推荐服务里面的 update_news_dynamic_info()方法进行更新。
|
||||
|
||||
```python
|
||||
def update_news_dynamic_info(self, news_id,action_type):
|
||||
"""更新新闻展示的详细信息"""
|
||||
news_dynamic_info_str = self.dynamic_news_info_redis_db.get("dynamic_news_detail:" + news_id)
|
||||
news_dynamic_info_str = news_dynamic_info_str.replace("'", '"' ) # 将单引号都替换成双引号
|
||||
news_dynamic_info_dict = json.loads(news_dynamic_info_str)
|
||||
|
||||
if len(action_type) == 2:
|
||||
if action_type[1] == "true":
|
||||
news_dynamic_info_dict[action_type[0]] +=1
|
||||
elif action_type[1] == "false":
|
||||
news_dynamic_info_dict[action_type[0]] -=1
|
||||
else:
|
||||
news_dynamic_info_dict["read_num"] +=1
|
||||
|
||||
news_dynamic_info_str = json.dumps(news_dynamic_info_dict)
|
||||
|
||||
news_dynamic_info_str = news_dynamic_info_str.replace('"', "'" )
|
||||
res = self.dynamic_news_info_redis_db.set("dynamic_news_detail:" + news_id, news_dynamic_info_str)
|
||||
return res
|
||||
```
|
||||
|
||||
上述代码主要是新闻动态特征更新的部分,主要是获取redis中的信息,根据前端传递过来的行为来更新对应新闻属性的值。更改完之后,将结果重新存储到redis中。
|
||||
|
||||
|
||||
|
||||
865
docs/推荐系统实战/新闻推荐系统实践/前端基础及Vue实战.md
Normal file
865
docs/推荐系统实战/新闻推荐系统实践/前端基础及Vue实战.md
Normal file
@@ -0,0 +1,865 @@
|
||||
## 1.Web 前端
|
||||
|
||||
Web 前端网页主要由文字、图像和超链接等元素构成。当然,除了这些元素,网页中还可以包含音频、视频以及 Flash 等。
|
||||
|
||||
### 1.1 什么是 Web
|
||||
|
||||
Web(World Wide Web)即全球广域网,也称为万维网,它是一种基于超文本和 HTTP 的、全球性的、动态交互的、跨平台的分布式图形信息系统。是建立在 Internet 上的一种网络服务,为浏览者在 Internet 上查找和浏览信息提供了图形化的、易于访问的直观界面,其中的文档及超级链接将 Internet 上的信息节点组织成一个互为关联的网状结构。
|
||||
|
||||
Web 前端主要是通 `HTML`,`CSS`,`JS`,`ajax`,`DOM` 等前端技术,实现网站在客服端的正确显示及交互功能。
|
||||
|
||||
### 1.2 Web 标准构成
|
||||
|
||||
主要包括结构(Structure)、表现(Presentation)和行为(Behavior)三个方面。
|
||||
|
||||
- **结构标准**:结构用于对网页元素进行整理和分类,对于网页来说最重要的一部分 。通过对语义的分析,可以对其划分结构。具有了结构的内容,将更容易阅读
|
||||
- **表现标准**:表现用于设置网页元素的版式、颜色、大小等外观样式,主要指的是 CSS 。为了让网页能展现出灵活多样的显示效果
|
||||
|
||||
- **行为标准**:行为是指网页模型的定义及交互的编写 。使用户对网页进行操作,网页可以做出响应性的变化
|
||||
|
||||
总的来说,
|
||||
|
||||
- Web 标准有三层结构,分别是结构(`HTML`)、表现(`CSS`)和行为(`JS`)
|
||||
- 结构类似人的身体, 表现类似人的着装, 行为类似人的行为动作
|
||||
|
||||
- 理想状态下,他们三层都是独立的, 放到不同的文件里面
|
||||
|
||||
### 1.2.1 HTML
|
||||
|
||||
- `HTML` 指的是超文本标记语言 (**H**yper **T**ext **M**arkup **L**anguage)是用来描述网页的一种语言。
|
||||
- `HTML` 不是一种编程语言,而是一种标记语言 (markup language)
|
||||
- 标记语言是一套标记标签 (markup tag)
|
||||
|
||||
##### 1.2.1.1 超文本的含义
|
||||
|
||||
- **超越文本限制**:可以加入图片、声音、动画、多媒体等内容
|
||||
- **超级链接文本**:可以从一个文件跳转到另一个文件,与世界各地主机的文件连接
|
||||
|
||||
##### 1.2.1.2 语法骨架格式
|
||||
|
||||
```html
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<meta charset="utf-8">
|
||||
<title>我的第一个页面</title>
|
||||
</head>
|
||||
<body>
|
||||
<h1>一个一级标题</h1>
|
||||
<p>一个段落。</p>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
- `<!DOCTYPE html>` 声明为 HTML5 文档
|
||||
- `<html>` 元素是 HTML 页面的根元素
|
||||
- `<head>` 元素包含了文档的元(meta)数据
|
||||
- `<meta charset="utf-8">` 定义网页编码格式
|
||||
- `<title>` 元素描述了文档的标题
|
||||
- `<body>` 元素包含了可见的页面内容
|
||||
|
||||
- `<h1>` 元素定义一个标题
|
||||
- `<p>` 元素定义一个段落
|
||||
|
||||
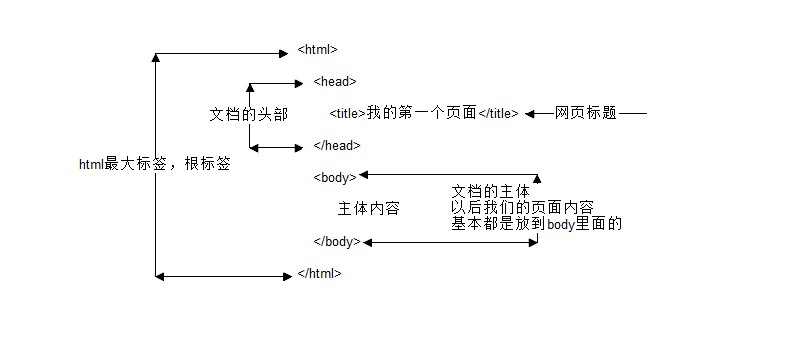
|
||||
|
||||
#### 1.2.2 CSS
|
||||
|
||||
- `CSS`(**C**ascading **S**tyle **S**heets) ,通常称为 `CSS` 样式表或层叠样式表(级联样式表)
|
||||
- `CSS` 主要用于设置 `HTML` 页面中的文本内容(字体、大小、对齐方式等)、图片的外形(宽高、边框样式、边距等)以及版面的布局和外观显示样式。
|
||||
- `CSS` 以 `HTML` 为基础,提供了丰富的功能,如字体、颜色、背景的控制及整体排版等,而且还可以针对不同的浏览器设置不同的样式。
|
||||
|
||||
##### 1.2.2.1 CSS 规则
|
||||
|
||||
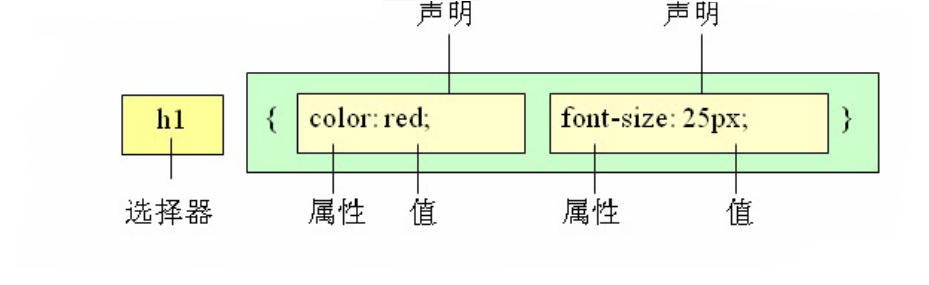
|
||||
|
||||
- **选择器**:需要改变样式的 HTML 元素
|
||||
|
||||
- **声明**:由一个属性和一个值组成。声明之间用分号结束
|
||||
|
||||
- 属性:希望设置的样式属性。每个属性有一个值。属性和值用冒号分开
|
||||
|
||||
##### 1.2.2.2 语法格式
|
||||
|
||||
```html
|
||||
<标签名 style="属性1:属性值1; 属性2:属性值2; 属性3:属性值3;"> 内容 </标签名>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```css
|
||||
<style>
|
||||
/*选择器{属性:值;}*/
|
||||
p {
|
||||
color:#06C;
|
||||
font-size:14px;
|
||||
}
|
||||
/*文字的颜色是 蓝色*/
|
||||
h4 {
|
||||
color:#900;
|
||||
}
|
||||
h1 {
|
||||
color:#090;
|
||||
font-size:16px;
|
||||
}
|
||||
body {
|
||||
background:url(bg2.jpg);
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
#### 1.2.3 JS
|
||||
|
||||
- `JS` (**J**ava**S**cript)是 Web 的编程语言,是一种基于对象和事件驱动并具有相对安全性的客户端脚本语言。同时也是一种广泛用于客户端 Web 开发的脚本语言,常常用来给 `HTML` 网页添加动态效果,从而实现人机交互的网页
|
||||
- 脚本语言不需要编译,在运行过程中由 `js` 解释器逐行来进行解释并执行
|
||||
|
||||
##### 1.2.3.1 JS 的组成
|
||||
|
||||

|
||||
|
||||
- **ECMAScript**: 是由 ECMA 国际( 原欧洲计算机制造商协会)进行标准化的一门编程语言,这种语言在万维网上应用广泛,它往往被称为 JavaScript 或 JScript,但实际上后两者是 ECMAScript 语言的实现和扩展
|
||||
- **DOM**:文档对象模型(DocumentObject Model,简称 DOM),是 W3C 组织推荐的处理可扩展标记语言的标准编程接口。通过 DOM 提供的接口可以对页面上的各种元素进行操作(大小、位置、颜色等)
|
||||
- **BOM**:浏览器对象模型(Browser Object Model,简称 BOM) 是指浏览器对象模型,它提供了独立于内容的、可以与浏览器窗口进行互动的对象结构。通过 BOM 可以操作浏览器窗口,比如弹出框、控制浏览器跳转、获取分辨率等
|
||||
|
||||
##### 1.2.3.2 书写位置
|
||||
|
||||
**1.行内式**
|
||||
|
||||
```html
|
||||
<input type="button" value="点我试试" onclick="alert('Hello World')" />
|
||||
```
|
||||
|
||||
- 可以将单行或少量 `JS` 代码写在 `HTML` 标签的事件属性中(以 `on` 开头的属性),如:`onclick`
|
||||
- 可读性差, 在 `HTML` 中编写 `JS` 大量代码时,不方便阅读
|
||||
- 引号易错,引号多层嵌套匹配时,非常容易弄混
|
||||
|
||||
**2.内嵌式**
|
||||
|
||||
```html
|
||||
<script>
|
||||
alert('Hello World~!');
|
||||
</script>
|
||||
```
|
||||
|
||||
- 可以将多行`JS`代码写到 `script` 标签中
|
||||
|
||||
**3.外部 JS 文件**
|
||||
|
||||
```html
|
||||
<script src="myScript.js"></script>
|
||||
```
|
||||
|
||||
```javascript
|
||||
//myScript.js文件内容
|
||||
function myFunction()
|
||||
{
|
||||
document.getElementById("demo").innerHTML="我的第一个 JavaScript 函数";
|
||||
}
|
||||
```
|
||||
|
||||
- 利于`HTML`页面代码结构化,把大段 `JS`代码独立到 `HTML` 页面之外,既美观,也方便文件级别的复用
|
||||
- 引用外部 `JS`文件的 `script` 标签中间不可以写代码
|
||||
- 适合于`JS` 代码量比较大的情况
|
||||
|
||||
---
|
||||
|
||||
## 2. Vue 简介
|
||||
|
||||
`Vue` 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,`Vue` 被设计为可以自底向上逐层应用。`Vue` 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与现代化的工具链以及各种支持类库结合使用时,`Vue` 也完全能够为复杂的单页应用提供驱动。
|
||||
|
||||
### 2.1 安装
|
||||
|
||||
#### 2.1.1 通过< script>标签引入
|
||||
|
||||
直接下载并用 `<script>` 标签引入,`Vue` 会被注册为一个全局变量。
|
||||
|
||||
- **开发版本**:https://cn.vuejs.org/js/vue.js
|
||||
|
||||
- **生产版本**:https://cn.vuejs.org/js/vue.min.js
|
||||
|
||||
#### 2.1.2 通过 CDN 安装
|
||||
|
||||
- **制作原型或学习**:
|
||||
|
||||
```html
|
||||
<script src="https://cdn.jsdelivr.net/npm/vue@2.6.14/dist/vue.js"></script>
|
||||
```
|
||||
|
||||
- **用于生产环境**:
|
||||
|
||||
```html
|
||||
<script src="https://cdn.jsdelivr.net/npm/vue@2.6.14"></script>
|
||||
```
|
||||
|
||||
- **使用原生 ES Modules**:
|
||||
|
||||
```html
|
||||
<script type="module">
|
||||
import Vue from 'https://cdn.jsdelivr.net/npm/vue@2.6.14/dist/vue.esm.browser.js'
|
||||
</script>
|
||||
```
|
||||
|
||||
#### 2.1.3 通过 npm 安装
|
||||
|
||||
在用 `Vue` 构建大型应用时推荐使用 `npm` 安装。`npm` 能很好地和诸如 `webpack`模块打包器配合使用。同时 `Vue` 也提供配套工具来开发单文件组件。
|
||||
|
||||
1.npm 版本需要大于 3.0,如果低于此版本需要升级它:
|
||||
|
||||
```shell
|
||||
# 查看版本
|
||||
npm -v
|
||||
|
||||
#升级 npm
|
||||
npm install npm -g
|
||||
```
|
||||
|
||||
2.安装 Vue
|
||||
|
||||
```shell
|
||||
# 使用npm安装
|
||||
npm install vue
|
||||
```
|
||||
|
||||
### 2.2 创建一个 Vue 实例
|
||||
|
||||
每个 `Vue` 应用都需要通过实例化 `Vue` 来实现。
|
||||
|
||||
#### 2.2.1 语法格式
|
||||
|
||||
```javascript
|
||||
var vm = new Vue({
|
||||
// 选项
|
||||
})
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```html
|
||||
<div id="example">
|
||||
<h1>title : {{title}}</h1>
|
||||
<h1>url : {{url}}</h1>
|
||||
</div>
|
||||
<script>
|
||||
var vm = new Vue({
|
||||
el: '#example',
|
||||
data: {
|
||||
title: "一个Vue实例",
|
||||
url: "https://cn.vuejs.org/",
|
||||
},
|
||||
methods: {
|
||||
details: function() {
|
||||
return this.title + " ------";
|
||||
}
|
||||
}
|
||||
})
|
||||
</script>
|
||||
```
|
||||
|
||||
在 `Vue` 构造器中有一个`el` 参数,它是 `DOM` 元素中的 `id`。在上面实例中 `id` 为 `example`,这表示接下来的改动全部在以上指定的 `div` 内,`div` 外部不受影响。
|
||||
|
||||
#### 2.2.2 定义数据对象
|
||||
|
||||
在上述`Vue`实例中:
|
||||
|
||||
- `data` :定义属性,实例中有 2 个属性分别为:`title`、`url`。
|
||||
|
||||
- `methods` :定义的函数,可以通过 `return` 来返回函数值。
|
||||
|
||||
- `{{ }}` :输出对象属性和函数返回值。
|
||||
|
||||
当一个 `Vue` 实例被创建时,它向 `Vue` 的响应式系统中加入了其 `data` 对象中能找到的所有的属性。当这些属性的值发生改变时,`html` 视图将也会产生相应的变化。
|
||||
|
||||
### 2.3 Vue 的生命周期
|
||||
|
||||
每个 `Vue` 实例在被创建时都要经过一系列的初始化过程——例如,需要设置数据监听、编译模板、将实例挂载到 `DOM` 并在数据变化时更新 `DOM` 等。同时在这个过程中也会运行一些叫做**生命周期钩子**的函数,这给了用户在不同阶段添加自己的代码的机会。
|
||||
|
||||
下图是一个 `Vue` 实例的生命周期:
|
||||
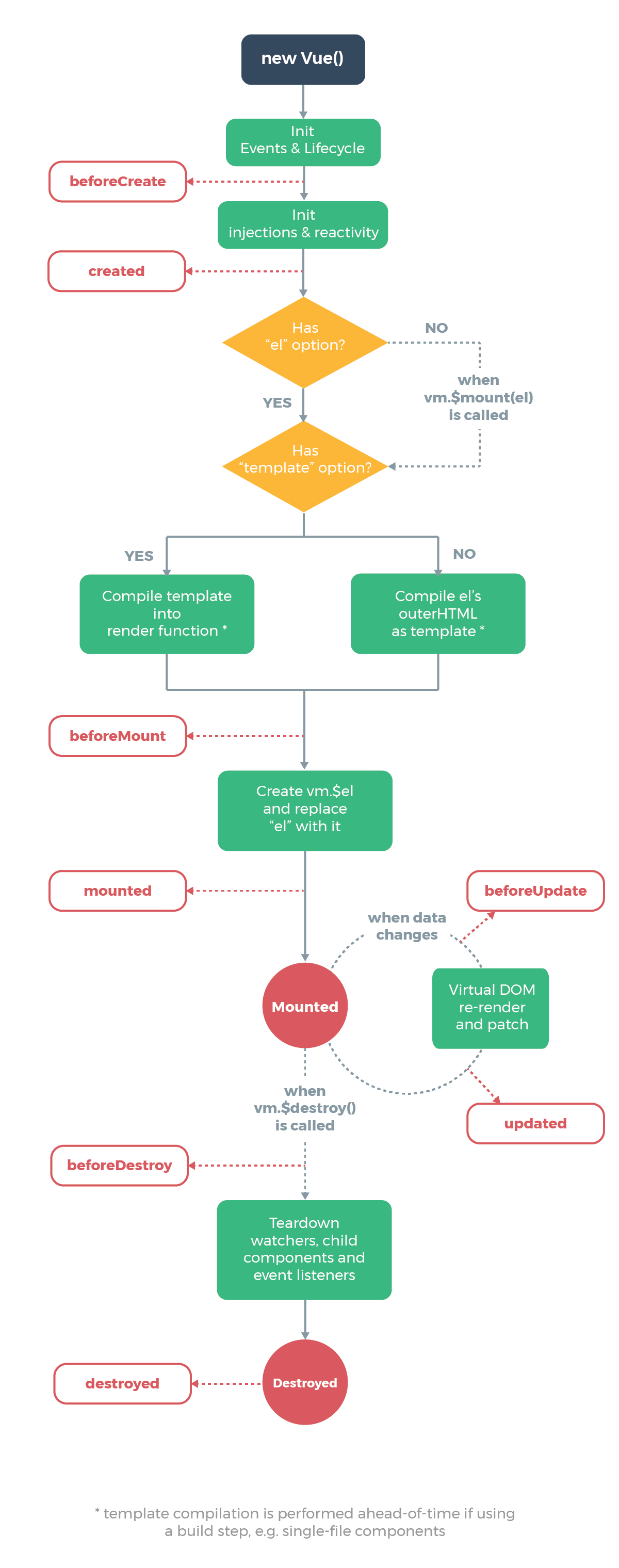
|
||||
|
||||
#### 2.3.1 beforeCreate
|
||||
|
||||
在实例初始化之后,进行数据侦听和事件/侦听器的配置之前同步调用。
|
||||
|
||||
此时组件的选项对象还未创建,`el` 和 `data` 并未初始化,因此无法访问`methods`, `data`, `computed`等上的方法和数据。
|
||||
|
||||
#### 2.3.2 created
|
||||
|
||||
在实例创建完成后被立即调用。
|
||||
|
||||
实例已完成对选项的处理,以下内容已被配置完毕:数据侦听、计算属性、方法、事件/侦听器的回调函数。然而,挂载阶段还没开始,且 `$el` 目前尚不可用。
|
||||
|
||||
在这一步中可以调用`methods`中的方法,改变`data`中的数据,并且修改可以通过 `Vue` 的响应式绑定体现在页面上,获取`computed`中的计算属性等等,通常我们可以在这里对实例进行预处理。但需要注意的是,这个周期中是没有什么方法来对实例化过程进行拦截的,因此假如有某些数据必须获取才允许进入页面的话,并不适合在这个方法发请求,建议在组件路由钩子`beforeRouteEnter`中完成。
|
||||
|
||||
#### 2.3.3 beforeMount
|
||||
|
||||
在挂载开始之前被调用:相关的 `render` 函数首次被调用(虚拟 `DOM`)。
|
||||
|
||||
实例已完成以下的配置: 编译模板,把`data`里面的数据和模板生成`HTML`,完成了`el`和`data` 初始化,但此时还没有挂在`HTML`到页面上。
|
||||
|
||||
#### 2.3.4 mounted
|
||||
|
||||
实例被挂载后调用,这时 `el` 被新创建的 `vm.$el` 替换了。
|
||||
|
||||
模板中的`HTML`渲染到`HTML`页面中,此时一般可以做一些`ajax`操作,`mounted`只会执行一次。
|
||||
|
||||
但`mounted` 不会保证所有的子组件也都被挂载完成。如果希望等到整个视图都渲染完毕再执行某些操作,可以在 `mounted` 内部使用 `vm.$nextTick`:
|
||||
|
||||
```javascript
|
||||
mounted: function () {
|
||||
this.$nextTick(function () {
|
||||
// 仅在整个视图都被渲染之后才会运行的代码
|
||||
})
|
||||
}
|
||||
//生命周期钩子的 this 上下文指向调用它的 Vue 实例。
|
||||
```
|
||||
|
||||
#### 2.3.5 beforeUpdate
|
||||
|
||||
在数据发生改变后,`DOM` 被更新之前被调用。
|
||||
|
||||
适合在现有 `DOM` 将要被更新之前访问它,比如移除手动添加的事件监听器。可以在该钩子中进一步地更改状态,不会触发附加地重渲染过程.
|
||||
|
||||
#### 2.3.6 updated
|
||||
|
||||
在数据更改导致的虚拟 `DOM` 重新渲染和更新完毕之后被调用。
|
||||
|
||||
当这个钩子被调用时,组件 `DOM` 已经更新,所以可以执行依赖于`DOM`的操作,然后在大多是情况下,应该避免在此期间更改状态,因为这可能会导致更新无限循环。
|
||||
|
||||
但`updated` 不会保证所有的子组件也都被重新渲染完毕。如果希望等到整个视图都渲染完毕,可以在 `updated` 里使用 `vm.$nextTick`:
|
||||
|
||||
```javascript
|
||||
updated: function () {
|
||||
this.$nextTick(function () {
|
||||
// 仅在整个视图都被重新渲染之后才会运行的代码
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
#### 2.3.7 beforeDestroy
|
||||
|
||||
实例销毁之前调用。在这一步,实例仍然完全可用。
|
||||
|
||||
这一步还可以用`this`来获取实例,一般用来做一些重置的操作,比如清除掉组件中的定时器和监听的`DOM`事件。
|
||||
|
||||
#### 2.3.8 destroyed
|
||||
|
||||
实例销毁后调用。该钩子被调用后,对应 `Vue` 实例的所有指令都被解绑,所有的事件监听器被移除,所有的子实例也都被销毁。
|
||||
|
||||
## 3 创建 Vue 项目
|
||||
|
||||
`Vue CLI` 是一个基于 `Vue.js` 进行快速开发的完整系统,提供:
|
||||
|
||||
- 通过 `@vue/cli` 实现的交互式的项目脚手架
|
||||
- 通过 `@vue/cli` + `@vue/cli-service-global` 实现的零配置原型开发
|
||||
- 一个运行时依赖 (`@vue/cli-service`),该依赖
|
||||
- 可升级
|
||||
- 基于 `webpack` 构建,并带有合理的默认配置
|
||||
- 可以通过项目内的配置文件进行配置
|
||||
- 可以通过插件进行扩展
|
||||
- 一个丰富的官方插件集合,集成了前端生态中最好的工具
|
||||
- 一套完全图形化的创建和管理 `Vue.js` 项目的用户界面
|
||||
|
||||
`Vue CLI` 致力于将 `Vue` 生态中的工具基础标准化。它确保了各种构建工具能够基于智能的默认配置即可平稳衔接。与此同时,它也为每个工具提供了调整配置的灵活性
|
||||
|
||||
### 3.1 安装 vue CLI
|
||||
|
||||
Vue CLI 的包名称由 `vue-cli` 改成了 `@vue/cli`。 如果已经全局安装了旧版本的 `vue-cli` (1.x 或 2.x),需要先通过 `npm uninstall vue-cli -g`卸载它。
|
||||
|
||||
1.安装新的包
|
||||
|
||||
```shell
|
||||
npm install -g @vue/cli
|
||||
```
|
||||
|
||||
2.检查其版本是否正确
|
||||
|
||||
```shell
|
||||
vue --version
|
||||
```
|
||||
|
||||
3.升级包
|
||||
|
||||
```shell
|
||||
npm update -g @vue/cli
|
||||
```
|
||||
|
||||
### 3.2 创建 Vue 项目
|
||||
|
||||
#### 3.2.1 通过 vue create 创建
|
||||
|
||||
```shell
|
||||
vue create hello-world
|
||||
```
|
||||
|
||||
- **默认配置**:包含了基本的 Babel + ESLint 设置。适合快速创建一个新项目的原型。
|
||||
|
||||
|
||||
|
||||
- **手动选择特性**:选取需要的特性。适合面向生产的项目。
|
||||
|
||||
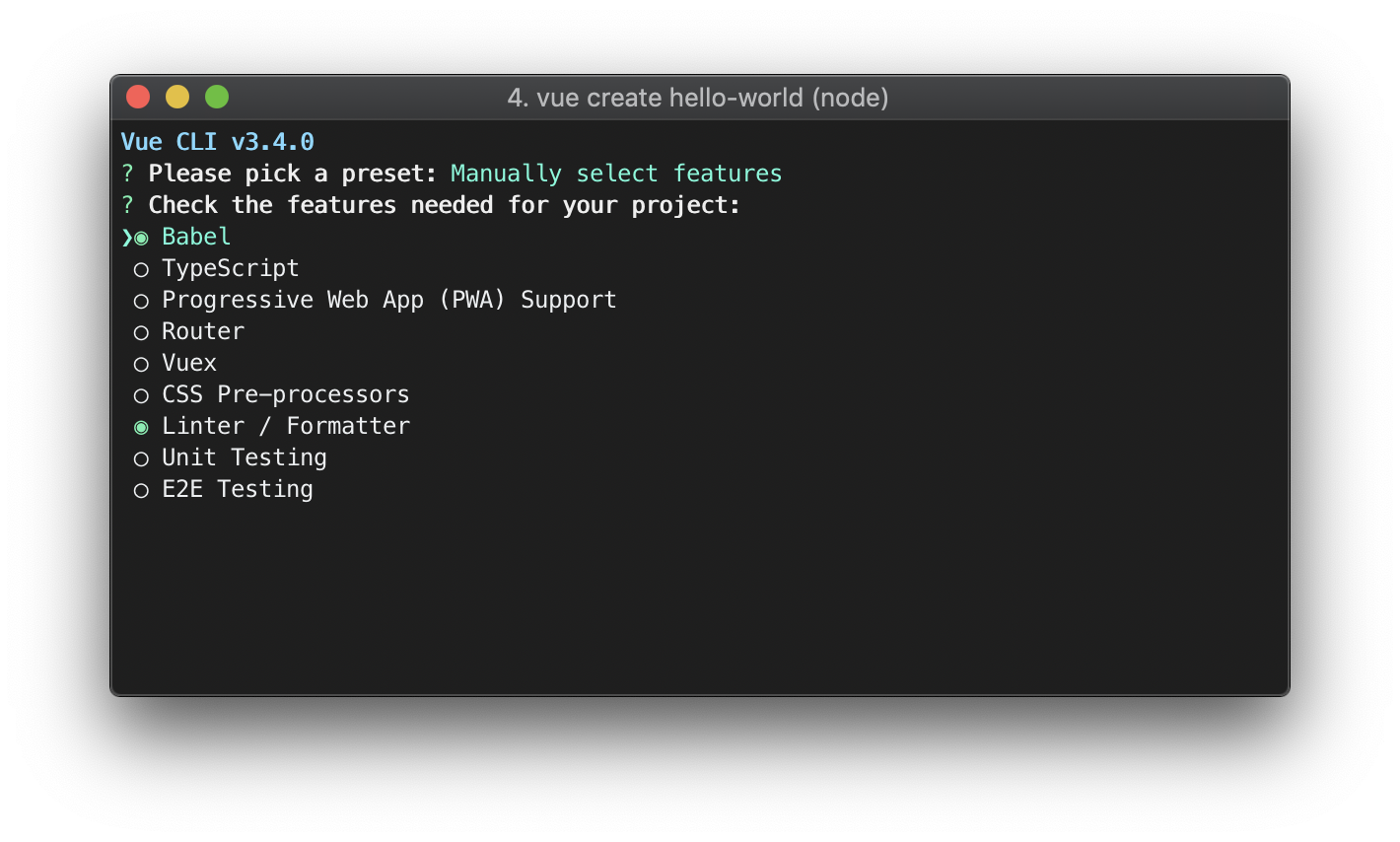
|
||||
|
||||
```shell
|
||||
# 进入项目具体路径
|
||||
cd hello-world
|
||||
|
||||
# 下载依赖
|
||||
npm install
|
||||
|
||||
# 启动运行项目
|
||||
npm run serve
|
||||
|
||||
# 项目打包
|
||||
npm run build
|
||||
```
|
||||
|
||||
#### 3.2.2 使用图形化界面创建
|
||||
|
||||
```shell
|
||||
vue ui
|
||||
```
|
||||
|
||||
打开一个浏览器窗口,并以图形化界面将你引导至项目创建的流程。
|
||||

|
||||
|
||||
#### 3.2.3 使用 2.x 模板 (旧版本)创建
|
||||
|
||||
```shell
|
||||
# 全局安装一个桥接工具
|
||||
npm install -g @vue/cli-init
|
||||
|
||||
# `vue init` 的运行效果将会跟 `vue-cli@2.x` 相同
|
||||
vue init webpack vue_map_test
|
||||
```
|
||||
|
||||
|
||||
|
||||
```shell
|
||||
# 进入项目具体路径
|
||||
cd vue_map_test
|
||||
|
||||
# 下载依赖
|
||||
npm install
|
||||
|
||||
# 启动运行项目,默认为8080端口
|
||||
npm run dev
|
||||
|
||||
# 项目打包
|
||||
npm run build
|
||||
```
|
||||
|
||||
### 3.3 Vue 项目目录
|
||||
|
||||
```
|
||||
├── v-proj
|
||||
| ├── node_modules // 当前项目所有依赖,一般不可以移植给其他电脑环境
|
||||
| ├── public
|
||||
| | ├── favicon.ico // 标签图标
|
||||
| | └── index.html // 当前项目唯一的页面
|
||||
| ├── src
|
||||
| | ├── assets // 静态资源img、css、js
|
||||
| | ├── components // 小组件
|
||||
| | ├── App.vue // 根组件
|
||||
| | ├── main.js // 全局脚本文件(项目的入口)
|
||||
| | └── router.js // 路由脚本文件
|
||||
| ├── README.md
|
||||
└ └── package.json //配置文件,使用npm install安装
|
||||
```
|
||||
|
||||
#### 3.3.1 public
|
||||
|
||||
可以理解为入口目录。
|
||||
|
||||
##### **favicon.ico**
|
||||
|
||||
用于作为缩略的网站标志,它显示位于浏览器的地址栏或者在标签上,用于显示网站的 logo。
|
||||
|
||||
##### **index.html**
|
||||
|
||||
首页入口文件,可以添加一些 `meta` 信息或统计代码。
|
||||
|
||||
```html
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<meta http-equiv="X-UA-Compatible" content="ie=edge">
|
||||
<title>Title</title>
|
||||
</head>
|
||||
<body style="background-color: #fff;">
|
||||
<div id="app" >
|
||||
|
||||
</div>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
#### 3.3.2 src
|
||||
|
||||
是整个项目的主文件夹 ,代码大部分都在这里完成。
|
||||
|
||||
##### **assets**
|
||||
|
||||
放置一些资源文件。比如`js` 、`css`、`image`等。
|
||||
|
||||
|
||||
|
||||
##### **components**
|
||||
|
||||
放置组件文件。一个`Vue`项目就是由一个个的组件拼装起来的。
|
||||
|
||||
例如:
|
||||
|
||||
```html
|
||||
<template>
|
||||
<div class="test">
|
||||
|
||||
</div>
|
||||
</template>
|
||||
|
||||
<script>
|
||||
export default {
|
||||
name: "Test"
|
||||
}
|
||||
</script>
|
||||
|
||||
<style scoped>
|
||||
|
||||
</style>
|
||||
```
|
||||
|
||||
- `<template>` 有且只有一个根标签(Vue2)
|
||||
- `<script>` 必须将组件对象导出
|
||||
- `<style>` 标签明确 scoped 属性,代表该样式只在组件内部起作用(样式的组件化)
|
||||
|
||||
##### **App.vue**
|
||||
|
||||
是整个项目的入口文件,相当于包裹整个页面的最外层的`div`。
|
||||
|
||||
```html
|
||||
<template>
|
||||
<div id="app">
|
||||
<router-view/>
|
||||
</div>
|
||||
</template>
|
||||
|
||||
<script>
|
||||
export default {
|
||||
name: 'App'
|
||||
components:{
|
||||
|
||||
},
|
||||
}
|
||||
</script>
|
||||
|
||||
<style>
|
||||
#app {
|
||||
font-family: 'Avenir', Helvetica, Arial, sans-serif;
|
||||
-webkit-font-smoothing: antialiased;
|
||||
-moz-osx-font-smoothing: grayscale;
|
||||
text-align: center;
|
||||
color: #2c3e50;
|
||||
}
|
||||
|
||||
</style>
|
||||
```
|
||||
|
||||
##### **main.js**
|
||||
|
||||
是项目的主`JS`,全局的使用的各种变量、插件 都在这里引入定义。
|
||||
|
||||
```js
|
||||
import Vue from 'vue'
|
||||
import App from './App.vue'
|
||||
import router from './router'
|
||||
|
||||
new Vue({
|
||||
router,
|
||||
render: h => h(App)
|
||||
}).$mount('#app')
|
||||
```
|
||||
|
||||
##### **router.js**
|
||||
|
||||
路由脚本文件(配置路由 url 链接 与 页面组件的映射关系)
|
||||
|
||||
```javascript
|
||||
// 导入VueRoute路由组件
|
||||
import VueRouter from 'vue-router'
|
||||
|
||||
|
||||
// 导入各个组件
|
||||
import homePage from "./components/homePage.vue";
|
||||
import test from "./components/test.vue";
|
||||
|
||||
// 创建路由对象
|
||||
let routerObj = new VueRouter({
|
||||
routes: [
|
||||
{path: '/', component: homePage},
|
||||
{path: '/test', component: test},
|
||||
],
|
||||
});
|
||||
|
||||
// 把routerObj对象暴漏出去。main.js导入这个数据
|
||||
export default routerObj
|
||||
```
|
||||
|
||||
#### 3.3.3 README.md
|
||||
|
||||
项目的说明文档,markdown 格式
|
||||
|
||||
```markdown
|
||||
## 项目依赖下载
|
||||
|
||||
npm install
|
||||
|
||||
## 项目启动
|
||||
|
||||
npm run serve
|
||||
|
||||
## 项目打包
|
||||
|
||||
npm run build
|
||||
```
|
||||
|
||||
#### 3.3.4 package.json
|
||||
|
||||
是整个项目用的到的所有的插件的 json 的格式,比如插件的名称、版本号。 当在项目里使用 npm install 时 node 会自动安装文件里的所有插件。
|
||||
|
||||
```javascript
|
||||
{
|
||||
"name": "test",
|
||||
"version": "0.1.0",
|
||||
"private": true,
|
||||
"scripts": {
|
||||
"serve": "vue-cli-service serve",
|
||||
"build": "vue-cli-service build",
|
||||
"lint": "vue-cli-service lint"
|
||||
},
|
||||
"dependencies": {
|
||||
"core-js": "^3.6.5",
|
||||
"vue": "^3.0.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@vue/cli-plugin-babel": "~4.5.0",
|
||||
"@vue/cli-plugin-eslint": "~4.5.0",
|
||||
"@vue/cli-service": "~4.5.0",
|
||||
"@vue/compiler-sfc": "^3.0.0",
|
||||
"babel-eslint": "^10.1.0",
|
||||
"eslint": "^6.7.2",
|
||||
"eslint-plugin-vue": "^7.0.0"
|
||||
},
|
||||
"eslintConfig": {
|
||||
"root": true,
|
||||
"env": {
|
||||
"node": true
|
||||
},
|
||||
"extends": [
|
||||
"plugin:vue/vue3-essential",
|
||||
"eslint:recommended"
|
||||
],
|
||||
"parserOptions": {
|
||||
"parser": "babel-eslint"
|
||||
},
|
||||
"rules": {}
|
||||
},
|
||||
"browserslist": [
|
||||
"> 1%",
|
||||
"last 2 versions",
|
||||
"not dead"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4.基于 Vue 的移动端 H5 项目
|
||||
|
||||
### 4.1 什么是 H5
|
||||
|
||||
`HTML5` 是第五代 `HTML` 的标准,可以说,`H5` 是基于 `HTML5` 实现的,是当前互联网前端开发的主流语言。`H5` 页面与普通 `web` 页面相比,最大的区别在于 `HTML5` 页面可以与不同大小的移动设备相匹配,支持市场上不同浏览器的兼容。移动网络和移动设备的快速发展,使得 `H5` 在移动设备上能够被更好的应用。
|
||||
|
||||
`H5` 页面有以下特点:
|
||||
|
||||
- **具有移动端自适应能力**,`H5` 页面会根据不同的手机屏幕尺寸进行适配,以达到不同屏幕的最佳显示效果
|
||||
- **支持多媒体功能**,支持背景音乐,视频播放等多种多媒体功能
|
||||
- **页面素材预加载**,为了保证整个页面的播放流畅,`H5` 页面都搭配预加载功能,即用户点击之前就完成了页面的加载,保证阅读流畅性
|
||||
- **支持滑动翻页**,每个页面内容单独成页
|
||||
- **使用滚动侦测特效,**即滑动页面的同时,大量文字或图片会自动加载出来,造成一种动态美感
|
||||
|
||||
|
||||
### 4.2 使用 Vue 开发 H5 页面
|
||||
|
||||
#### 4.2.1 创建 Vue 项目
|
||||
|
||||
```shell
|
||||
# vue create创建项目
|
||||
vue create test
|
||||
|
||||
# 进入项目具体路径
|
||||
cd test
|
||||
|
||||
# 下载依赖
|
||||
npm install
|
||||
|
||||
# 启动运行项目
|
||||
npm run serve
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 4.2.2 自适应布局
|
||||
|
||||
移动端的布局相对 PC 较为简单,关键在于对不同设备的适配。
|
||||
|
||||
1.根据屏幕大小 / 750 = 所求字体 / 基准字体大小比值相等,动态调节`html`的`font-size`大小。
|
||||
|
||||
2.根据设备设备像素比设置`scale`的值,保持视口`device-width`始终等于设备物理像素,接着根据屏幕大小动态计算根字体大小,具体是将屏幕划分为 10 等分,每份为 a,1rem 就等于 10a。
|
||||
|
||||
这里主要用到两种单位:
|
||||
|
||||
- **vw**: viewport width,相对于视口的宽度,1vw 为视口宽度的 1%,100vw 为设备的宽度
|
||||
|
||||
- **rem**: 相对于根元素 html 的字体大小的单位,比如 2rem=2 倍的根字体大小
|
||||
。rem 的基本原理是根据屏幕不同的分辨率,动态修改根字体的大小,让所有的用 rem 单位的元素跟着屏幕尺寸一起缩放,从而达到自适应的效果。
|
||||
|
||||
#### 4.2.3 路由配置
|
||||
|
||||
##### 下载 vue-router
|
||||
|
||||
```shell
|
||||
npm install vue-router
|
||||
```
|
||||
|
||||
##### 配置 router.js
|
||||
|
||||
```javascript
|
||||
//新建router.js文件
|
||||
|
||||
import Vue from 'vue'
|
||||
import Router from 'vue-router'
|
||||
import HelloWorld from "@/components/HelloWorld"
|
||||
|
||||
Vue.use(Router)
|
||||
|
||||
export default new Router({
|
||||
routes: [
|
||||
{
|
||||
path: "/",
|
||||
component: HelloWorld
|
||||
},
|
||||
]
|
||||
})
|
||||
```
|
||||
|
||||
```javascript
|
||||
//main.js中引入router
|
||||
|
||||
import Vue from 'vue'
|
||||
import App from './App.vue'
|
||||
import router from '../router'
|
||||
|
||||
new Vue({
|
||||
router,
|
||||
render: h => h(App),
|
||||
}).$mount('#app')
|
||||
```
|
||||
|
||||
#### 4.2.4 数据请求
|
||||
|
||||
##### 安装 axios
|
||||
|
||||
```shell
|
||||
npm install axios
|
||||
```
|
||||
|
||||
##### 引入 axios
|
||||
|
||||
在`msin.js`中引用
|
||||
|
||||
```javascript
|
||||
// 导入axios
|
||||
import axios from 'axios'
|
||||
import VueAxios from 'vue-axios'
|
||||
Vue.use(VueAxios, axios);
|
||||
|
||||
// axios公共基路径,以后所有的请求都会在前面加上这个路径
|
||||
// axios.defaults.baseURL = "http://**********"
|
||||
|
||||
```
|
||||
|
||||
##### 使用 axios
|
||||
|
||||
修改`HelloWorld.vue`文件
|
||||
|
||||
```html
|
||||
<template>
|
||||
<div @click="login">index page</div>
|
||||
</template>
|
||||
<script>
|
||||
export default {
|
||||
methods: {
|
||||
anysc login() {
|
||||
let url = '/login';
|
||||
let data = {username: 'user', passwd: '123'};
|
||||
let successData = await this.axios.post(url, data).then(res => {
|
||||
return res
|
||||
})
|
||||
console.log(successData)
|
||||
}
|
||||
}
|
||||
</script>
|
||||
```
|
||||
|
||||
#### 4.2.5 UI 组件库
|
||||
|
||||
UI 设计组件(UI KIT),直译过来就是用户界面成套元件,是界面设计常用控件或元件,「组」是设计元素的组合方式,「件」由不同的元件组成。
|
||||
|
||||
组件有如下优势:
|
||||
|
||||
- **保证一致性**
|
||||
|
||||
与现实生活一致:与现实生活的流程、逻辑保持一致,遵循用户习惯的语言和概念;在界面中一致:所有的元素和结构需保持一致,比如:设计样式、图标和文本、元素的位置等。
|
||||
|
||||
- **反馈用户**
|
||||
|
||||
控制反馈:通过界面样式和交互动效让用户可以清晰的感知自己的操作;页面反馈:操作后,通过页面元素的变化清晰地展现当前状态。
|
||||
|
||||
- **提高效率,减少成本**
|
||||
|
||||
简化流程:设计简洁直观的操作流程;清晰明确:语言表达清晰且表意明确,让用户快速理解进而作出决策;帮助用户识别:界面简单直白,让用户快速识别而非回忆,减少用户记忆负担。
|
||||
|
||||
##### Vant
|
||||
|
||||
**下载地址**:https://youzan.github.io/vant
|
||||
|
||||
是有赞前端团队基于有赞统一的规范实现的 Vue 组件库,提供了一整套 UI 基础组件和业务组件。
|
||||
|
||||
- 60+ 高质量组件
|
||||
- 90% 单元测试覆盖率
|
||||
- 完善的中英文文档和示例
|
||||
- 支持按需引入
|
||||
- 支持主题定制
|
||||
- 支持国际化
|
||||
- 支持 TS
|
||||
- 支持 SSR
|
||||
|
||||

|
||||
|
||||
 
|
||||
|
||||
---
|
||||
### **参考资料:**
|
||||
|
||||
https://www.runoob.com/html/html-tutorial.html
|
||||
|
||||
https://www.w3school.com.cn/html/index.asp
|
||||
|
||||
https://www.runoob.com/css/css-tutorial.html
|
||||
|
||||
https://www.w3school.com.cn/css/index.asp
|
||||
|
||||
https://www.runoob.com/js/js-tutorial.html
|
||||
|
||||
https://vuejs.org/guide/introduction.html
|
||||
200
docs/推荐系统实战/新闻推荐系统实践/推荐系统流程的构建.md
Normal file
200
docs/推荐系统实战/新闻推荐系统实践/推荐系统流程的构建.md
Normal file
@@ -0,0 +1,200 @@
|
||||
|
||||
|
||||

|
||||
|
||||
本篇文章主要是讲解推荐系统流程构建,主要包括Offline和Online两个部分。
|
||||
|
||||
# Offline
|
||||
|
||||
offline部分主要是基于前面存储好的物料画像和用户画像进行离线计算, 为每个用户提供一个热门页列表和推荐页列表并进行缓存, 方便online服务的列表获取。 所以下面主要帮大家梳理这两个列表的生成以及缓存到redis的流程。
|
||||
|
||||
## 热门页列表
|
||||
|
||||
当用户进入系统, 点击热门按钮时, online服务就会为当前用户获取热门页列表, 而这个列表是在用户登录进入的时候, 离线部分事先为用户生成好缓存到了redis中。online服务获取,只需要从redis中拉取即可。
|
||||
|
||||
所谓热门页, 就是对于每篇文章,会根据它的发布时间,用户对它的行为记录(获得的点赞数,收藏数和阅读数)去计算该文章的热度信息, 然后根据热度值进行排序得到, 所以计算文章的热门记录, 只需要文章画像的动静态信息即可,天级更新, 逻辑如下:
|
||||
|
||||
每天凌晨物料处理完,会得到每篇文章的发布时间(静态特征)以及每篇文章目前为止累计的获赞数,被收藏数和被阅读数(动态特征),这时候,我们就可以遍历物料池中的每篇文章, 拿到文章的发布时间,与当前时间作差得到文章的时效性,然后根据时效性过滤掉发布太久的文章,然后再结合文章的动态特征,基于热度公式,就能计算文章的热度值。每篇文章都有一个热度值,根据热度值排序,就可以得到文章热门列表,把该列表以zset的形式缓存到redis,之所以zset,是因为可以帮助我们根据hot value自动排好序。 这是一份公共的热门列表,这个可以作为每个用户热门列表的初始化状态。
|
||||
|
||||
由于每个用户的喜好兴趣不同,对于同一个热门页,点击的文章可能会有所不同,而我们给用户曝光的时候,往往是会先过滤掉对用户曝光过的内容,所以为了每个用户的个性化曝光,当用户登录的时候,我们会给每个用户单独生成一个热门页列表, 初始化状态就是上面的公共列表。之后,用户再去点击热门的时候,就从自己的热门页列表中获取文章了,当然这块是online服务, 我们放后面详细说。
|
||||
|
||||
所以,离线热门页列表生成过程总结起来,就是每天遍历物料池, 对于每篇文章,基于动态信息和静态特征计算热度值,并进行热度值排序,生成公共热门模板,作为每个用户单独热门列表的初始。代码如下:
|
||||
|
||||
```python
|
||||
def get_hot_rec_list(self):
|
||||
"""获取物料的点赞,收藏和创建时间等信息,计算热度并生成热度推荐列表存入redis
|
||||
"""
|
||||
# 遍历物料池里面的所有文章
|
||||
for item in self.feature_protrail_collection.find():
|
||||
news_id = item['news_id']
|
||||
news_cate = item['cate']
|
||||
news_ctime = item['ctime']
|
||||
news_likes_num = item['likes']
|
||||
news_collections_num = item['collections']
|
||||
news_read_num = item['read_num']
|
||||
news_hot_value = item['hot_value']
|
||||
|
||||
#print(news_id, news_cate, news_ctime, news_likes_num, news_collections_num, news_read_num, news_hot_value)
|
||||
|
||||
# 时间转换与计算时间差 前提要保证当前时间大于新闻创建时间,目前没有捕捉异常
|
||||
news_ctime_standard = datetime.strptime(news_ctime, "%Y-%m-%d %H:%M")
|
||||
cur_time_standard = datetime.now()
|
||||
time_day_diff = (cur_time_standard - news_ctime_standard).days
|
||||
time_hour_diff = (cur_time_standard - news_ctime_standard).seconds / 3600
|
||||
|
||||
# 只要最近3天的内容
|
||||
if time_day_diff > 3:
|
||||
continue
|
||||
|
||||
# 计算热度分,这里使用魔方秀热度公式, 可以进行调整, read_num 上一次的 hot_value 上一次的hot_value用加? 因为like_num这些也都是累加上来的, 所以这里计算的并不是增值,而是实时热度吧
|
||||
# news_hot_value = (news_likes_num * 6 + news_collections_num * 3 + news_read_num * 1) * 10 / (time_hour_diff+1)**1.2
|
||||
# 72 表示的是3天,
|
||||
news_hot_value = (news_likes_num * 0.6 + news_collections_num * 0.3 + news_read_num * 0.1) * 10 / (1 + time_hour_diff / 72)
|
||||
|
||||
#print(news_likes_num, news_collections_num, time_hour_diff)
|
||||
|
||||
# 更新物料池的文章hot_value
|
||||
item['hot_value'] = news_hot_value
|
||||
self.feature_protrail_collection.update({'news_id':news_id}, item)
|
||||
|
||||
#print("news_hot_value: ", news_hot_value)
|
||||
|
||||
# 保存到redis中
|
||||
self.reclist_redis.zadd('hot_list', {'{}_{}'.format(news_cate, news_id): news_hot_value}, nx=True)
|
||||
```
|
||||
|
||||
### 推荐页列表
|
||||
|
||||
当用户进入系统, 映入眼帘的就是推荐页, online服务会给当前用户获取推荐页列表, 这个列表同样是用户进入的时候,离线事先生成缓存到redis中。
|
||||
|
||||
推荐页,也正是我们推荐系统发挥效用的部分,对于每个用户,我们会生成不同的推荐页面,这就是我们所知悉的"千人千面",如何做到这一点? 就需要借助已经存好的用户画像和物品画像,制作特征,然后通过模型预测排序,做到所谓的个性化。 当然,对于一个新来的用户,由于我们事先没有存储好用户画像,这就意味着可能没法走个性化推荐流程,这里我们当做冷启动处理。所以这块分成了冷启动和个性化推荐两块进行梳理,逻辑如下:
|
||||
|
||||
- 冷启动: 冷启动主要是针对新用户,我们没有太详细的用户画像信息,所以只能通过一些粗略的信息,比如年龄,性别(用户注册时会获取到)等,获取到一些大类别下的文章(适合该年龄,该性别看的文章),然后再根据文章的热度信息,给新用户生成一份冷启动推荐列表。 当然这里只是说了一种简单的方式,冷启动其实也是一种比较复杂的场景,感兴趣同学可以查阅一些其他资料,也欢迎和我们讨论。这里是根据用户的年龄和性别自定义分成了四类人群
|
||||
|
||||
```python
|
||||
def generate_cold_start_news_list_to_redis_for_register_user(self):
|
||||
"""给已经注册的用户制作冷启动新闻列表
|
||||
"""
|
||||
for user_info in self.register_user_sess.query(RegisterUser).all():
|
||||
if int(user_info.age) < 23 and user_info.gender == "female":
|
||||
redis_key = "cold_start_group:{}".format(str(1))
|
||||
self.copy_redis_sorted_set(user_info.userid, redis_key)
|
||||
elif int(user_info.age) >= 23 and user_info.gender == "female":
|
||||
redis_key = "cold_start_group:{}".format(str(2))
|
||||
self.copy_redis_sorted_set(user_info.userid, redis_key)
|
||||
elif int(user_info.age) < 23 and user_info.gender == "male":
|
||||
redis_key = "cold_start_group:{}".format(str(3))
|
||||
self.copy_redis_sorted_set(user_info.userid, redis_key)
|
||||
elif int(user_info.age) >= 23 and user_info.gender == "male":
|
||||
redis_key = "cold_start_group:{}".format(str(4))
|
||||
self.copy_redis_sorted_set(user_info.userid, redis_key)
|
||||
else:
|
||||
pass
|
||||
print("generate_cold_start_news_list_to_redis_for_register_user.")
|
||||
```
|
||||
|
||||
- 个性化: 个性化推荐主要是针对老用户,我们通过正常推荐流程, 捕捉其兴趣爱好,做到个性推荐,优化用户体验。 所以这块走正常推荐流程,比如我们所熟知的召回→排序→重排→个性化列表生成, 召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快,精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准。 而重排侧,主要是结合精排的结果,再加上各种业务策略,比如去重,插入,打散,多样性保证等,主要是技术产品策略主导或改善用户体验的。 所以这几个环节组合起来,以"迅雷不及掩耳漏斗之势",组成了个性化推荐系统的整个架构。由于这是推荐的重点环节, 每个模块都有非常丰富的知识细节,这里就不过多介绍了,后面有机会的话单独整理。
|
||||
|
||||
所以, 推荐页列表生成过程总结起来, 首先先根据用户的类型分成两波, 如果是新用户, 就走冷启动推荐流程,通过用户粗略信息,给用户生成一份冷启动推荐列表。 如果是老用户, 就走个性化推荐流程, 通过召回→排序→重排等,给老用户生成一份个性化列表。最终都存储到Redis中。
|
||||
|
||||
至此, offline流程结束, 通过offline, 对于每个用户, 我们离线生成好热门页列表, 推荐页列表。
|
||||
|
||||
接下来,我们看online。
|
||||
|
||||
# Online
|
||||
|
||||
Online是为用户在使用APP或者系统的过程中触发的行为提供一系列服务,当用户刚进入系统的时候, 会进入新闻的推荐页面,此时系统会为该用户获取推荐页文章并进行展示,当用户进入热门页, 系统就会为该用户获取热门页列表并进行展示, 下面主要介绍这两块线上获取过程中的一些细节。
|
||||
|
||||
- 获取推荐页列表: 这个服务在用户刚进入系统,以及在推荐页中浏览文章刷新下拉过程中进行触发,当系统触发该服务的时候, 首先会判断该用户是新用户还是老用户
|
||||
- 如果是新用户, 就从离线存储好的冷启动列表中读取推荐列表, 选择指定的数目(比如一次触发给用户推荐10篇)的文章推荐,但推荐之前,需要去除已曝光的文章(避免重复曝光,影响用户体验),所以对于每个用户,我们还会记录一份已曝光列表,方便我们去重, 同时,当批文章曝光出去,还要即使更新我们的曝光列表。
|
||||
- 如果是老用户, 就从离线存储好的个性化推荐列表中读取, 和上面一样, 选择指定数目的文章,去掉曝光,生成最终推荐列表,同时更新用户曝光记录。
|
||||
- 这样就完成了推荐页的推荐服务。
|
||||
|
||||
- 获取热门页列表: 这个服务是用户点击热门页,以及在热门页中浏览文章刷新下来过程中进行触发,当该服务触发的时候,依然会判断新用户和老用户
|
||||
- 如果是新用户, 需要从离线存储好的公共冷启动模板中为该用户生成一份热门页列表,然后获取,选择指定数目文章推荐,和上面一样,去曝光,生成最终推荐列表,更新曝光记录。
|
||||
- 如果是老用户, 从离线存储好的该用户热门列表中读取,选择指定数目文章推荐,去曝光,生成最终推荐列表,更新曝光记录。
|
||||
- 这样就完成了热门页的推荐服务。
|
||||
|
||||
代码如下:
|
||||
|
||||
```python
|
||||
def get_hot_list(self, user_id):
|
||||
"""热门页列表结果"""
|
||||
hot_list_key_prefix = "user_id_hot_list:"
|
||||
hot_list_user_key = hot_list_key_prefix + str(user_id)
|
||||
|
||||
user_exposure_prefix = "user_exposure:"
|
||||
user_exposure_key = user_exposure_prefix + str(user_id)
|
||||
|
||||
# 当数据库中没有这个用户的数据,就从热门列表中拷贝一份
|
||||
if self.reclist_redis_db.exists(hot_list_user_key) == 0: # 存在返回1,不存在返回0
|
||||
print("copy a hot_list for {}".format(hot_list_user_key))
|
||||
# 给当前用户重新生成一个hot页推荐列表, 也就是把hot_list里面的列表复制一份给当前user, key换成user_id
|
||||
self.reclist_redis_db.zunionstore(hot_list_user_key, ["hot_list"])
|
||||
|
||||
# 一页默认10个item, 但这里候选20条,因为有可能有的在推荐页曝光过
|
||||
article_num = 200
|
||||
|
||||
# 返回的是一个news_id列表 zrevrange排序分值从大到小
|
||||
candiate_id_list = self.reclist_redis_db.zrevrange(hot_list_user_key, 0, article_num-1)
|
||||
|
||||
if len(candiate_id_list) > 0:
|
||||
# 根据news_id获取新闻的具体内容,并返回一个列表,列表中的元素是按照顺序展示的新闻信息字典
|
||||
news_info_list = []
|
||||
selected_news = [] # 记录真正被选了的
|
||||
cou = 0
|
||||
|
||||
# 曝光列表
|
||||
print("self.reclist_redis_db.exists(key)",self.exposure_redis_db.exists(user_exposure_key))
|
||||
if self.exposure_redis_db.exists(user_exposure_key) > 0:
|
||||
exposure_list = self.exposure_redis_db.smembers(user_exposure_key)
|
||||
news_expose_list = set(map(lambda x: x.split(':')[0], exposure_list))
|
||||
else:
|
||||
news_expose_list = set()
|
||||
|
||||
for i in range(len(candiate_id_list)):
|
||||
candiate = candiate_id_list[i]
|
||||
news_id = candiate.split('_')[1]
|
||||
|
||||
# 去重曝光过的,包括在推荐页以及hot页
|
||||
if news_id in news_expose_list:
|
||||
continue
|
||||
|
||||
# TODO 有些新闻可能获取不到静态的信息,这里应该有什么bug
|
||||
# bug 原因是,json.loads() redis中的数据会报错,需要对redis中的数据进行处理
|
||||
# 可以在物料处理的时候过滤一遍,json无法load的新闻
|
||||
try:
|
||||
news_info_dict = self.get_news_detail(news_id)
|
||||
except Exception as e:
|
||||
with open("/home/recsys/news_rec_server/logs/news_bad_cases.log", "a+") as f:
|
||||
f.write(news_id + "\n")
|
||||
print("there are not news detail info for {}".format(news_id))
|
||||
continue
|
||||
# 需要确认一下前端接收的json,key需要是单引号还是双引号
|
||||
news_info_list.append(news_info_dict)
|
||||
news_expose_list.add(news_id)
|
||||
# 注意,原数的key中是包含了类别信息的
|
||||
selected_news.append(candiate)
|
||||
cou += 1
|
||||
if cou == 10:
|
||||
break
|
||||
|
||||
if len(selected_news) > 0:
|
||||
# 手动删除读取出来的缓存结果, 这个很关键, 返回被删除的元素数量,用来检测是否被真的被删除了
|
||||
removed_num = self.reclist_redis_db.zrem(hot_list_user_key, *selected_news)
|
||||
print("the numbers of be removed:", removed_num)
|
||||
|
||||
# 曝光重新落表
|
||||
self._save_user_exposure(user_id,news_expose_list)
|
||||
return news_info_list
|
||||
else:
|
||||
#TODO 临时这么做,这么做不太好
|
||||
self.reclist_redis_db.zunionstore(hot_list_user_key, ["hot_list"])
|
||||
print("copy a hot_list for {}".format(hot_list_user_key))
|
||||
# 如果是把所有内容都刷完了再重新拷贝的数据,还得记得把今天的曝光数据给清除了
|
||||
self.exposure_redis_db.delete(user_exposure_key)
|
||||
return self.get_hot_list(user_id)
|
||||
```
|
||||
|
||||
至此, Online部分的推荐相关流程结束, Online的推荐流程,主要为用户的推荐页以及热门页产生推荐列表进行服务。
|
||||
|
||||
149
docs/推荐系统实战/新闻推荐系统实践/数据库的基本使用问答整理.md
Normal file
149
docs/推荐系统实战/新闻推荐系统实践/数据库的基本使用问答整理.md
Normal file
@@ -0,0 +1,149 @@
|
||||
## Task02问答整理
|
||||
|
||||
## 1. Task02整体流程(外加录屏整理)
|
||||
|
||||
- 需要掌握:
|
||||
|
||||
- 了解不同数据库的特点
|
||||
- 掌握linux下数据库的安装
|
||||
- 了解linux下数据库的常用命令(增删改查)
|
||||
- 熟练python调用数据库相关包的用法,对于不同的数据库可能有不同的包,包中的方法也只需要掌握增删改查
|
||||
|
||||
- 具体详见https://github.com/datawhalechina/fun-rec/blob/master/docs/%E7%AC%AC%E4%BA%8C%E7%AB%A0%20%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E5%AE%9E%E6%88%98/2.2%E6%96%B0%E9%97%BB%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E5%AE%9E%E6%88%98/readme.md
|
||||
|
||||
- 交流会议:
|
||||
|
||||
录屏:https://share.weiyun.com/u3ZIjZfg
|
||||
|
||||
- 作业分享:https://relph1119.github.io/my-team-learning/#/recommender_system32/task02
|
||||
|
||||
## 2. 问题解答
|
||||
|
||||
- 问:如果出现年龄显示的问题怎么办?
|
||||
|
||||
答:将`\\d`改为`\d`
|
||||
|
||||
|
||||
|
||||
- 问:请问这个报错是缺少什么?
|
||||
|
||||

|
||||
|
||||
答:需要下载`drive`驱动才可以正常运行。
|
||||
|
||||
|
||||
|
||||
- 问:为什么热门文章一直显示在加载中呀?
|
||||
|
||||
答:你这个问题应该是没有往下跑后面几个代码,要跑完才能正常加载。
|
||||
|
||||
问:可以跑完了还是在加载中?
|
||||
|
||||
答:你的redis中有数据吗?
|
||||
|
||||
问:应该是有
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
- 问:为什么有`package.json`这个文件还是报文件缺失错误?
|
||||
|
||||
答:路径不对,要进`vue`才行,往下再进一层。
|
||||
|
||||
|
||||
|
||||
- 问:请问注册的时候发现注册不通过怎么办?
|
||||
|
||||
答:后端开起了吗?后端+`snowflake`服务要同时开起来。
|
||||
|
||||
问:都开了,我好像是端口映射错了,还是不行。
|
||||
|
||||
答:可以用`postman`测试一下后端请求是否能正常返回东西。
|
||||
|
||||
问:搞定了,是因为`main.js`没有填写公网地址,填写`0.0.0.0`就行
|
||||
|
||||
|
||||
|
||||
- 问:`python process material.py`需要`redis`验证怎么解决,有没有除了取消密码之外的解决方式。
|
||||
|
||||

|
||||
|
||||
答:估计是设置了`redis`的用户和密码,这个没有办法,只能取消密码。或者修改代码,连接`redis`
|
||||
|
||||
问:我修改了,但是还是`mongo`没有数据,奇怪了,之前是远程连接`redis`没有修改配置,现在修改了但是爬取还是不太像,不行。
|
||||
|
||||
答:`mongodb`的哪个库没有数据?估计是爬虫问题,没有爬取到数据,请单独执行`run.py`脚本。另外,搭建`Linux`环境的小伙伴,在启动项目,如遇到问题,也可参考`windows`环境搭建步骤进行。
|
||||
|
||||
|
||||
|
||||
- 问:请问如何解决登陆后一刷新没有数据的问题?
|
||||
|
||||
答:`main.js`中有几个地方要修改,主要是换公网`ip`
|
||||
|
||||
```
|
||||
package.json
|
||||
"scripts": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1",
|
||||
"dev": "webpack-dev-server --open --port 8686 --contentBase src --hot --host 0.0.0.0",
|
||||
"start": "nodemon src/main.js"
|
||||
},
|
||||
```
|
||||
|
||||
|
||||
|
||||
- 问:用户注册没有反应怎么办?
|
||||
|
||||
答:修改此处代码。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
- 问:有没有试过在本地访问`vm`虚拟机里面的前端,这个时候`ip`应该填什么?
|
||||
|
||||
答:虚拟机的`IP`地址
|
||||
|
||||
问:可是不行,虚拟机里面的端口我改为了`0.0.0.0`,访问`url`改为虚拟机后端服务的`IP+端口`。前端还是无法访问。
|
||||
|
||||
答:那是端口映射问题。
|
||||
|
||||
问:虚拟机的`IP`不是公网`IP`,本地虽然能`Ping`通,我也感觉是端口映射问题,没接触过。
|
||||
|
||||
|
||||
|
||||
- 问:请问运行新代码的时候,是否会出现这个问题,来源于`python process_user.py`
|
||||
|
||||
答:问题是系统设计上有问题,当删除用户之后,表格还会保留用户的喜好,然后数据就不会空,但是实际表格数据已经不存在了。
|
||||
|
||||
|
||||
|
||||
- 问:想问一下这个对字段 age按降序排序,为啥写成 `mydoc = mycol.find().sort("alexa", -1)`
|
||||
|
||||
答:`alexa`改成`age`?
|
||||
|
||||
问:然后我试了一下结果`age`和`alexa`都可以把`age`按降序排序,我还以为`alexa`在`mongodb`中有特殊含义。
|
||||
|
||||
答:如果按照不存在的`field`排序,应该按照`null`处理,然后这个排序会`fallback`到`_id`排序上。这里解释的比较清楚:https://docs.mongodb.com/manual/reference/method/cursor.sort/#std-label-return-natural-order
|
||||
|
||||
|
||||
|
||||
- 问:计算热度值公式处出错怎么办?
|
||||
|
||||
答:计算热度值的公式,最初公式为`Hacker News`算法,大家可以替换成其他的排名算法。
|
||||
|
||||
|
||||
|
||||
- 问:请教一下,`pymysql`如何进行跨库查询?
|
||||
|
||||
答:库名.表名
|
||||
|
||||
问:游标不是会制定数据库吗?怎么连接两个数据库呢?
|
||||
|
||||
答:连`MySQL`地址不要写库名,然后`SQL`里面加上库名。类似`scheme`概念,模式名.表名
|
||||
|
||||
|
||||
|
||||
- 问:`ORM`是什么意思?
|
||||
|
||||
答:`ORM`是对象关系映射,类似于在`DAO`层的东西,如果类比`JAVA`的话,就是`Hibernate`这种
|
||||
280
docs/推荐系统实战/新闻推荐系统实践/熟悉推荐系统基本流程问答整理.md
Normal file
280
docs/推荐系统实战/新闻推荐系统实践/熟悉推荐系统基本流程问答整理.md
Normal file
@@ -0,0 +1,280 @@
|
||||
## Task01问答整理
|
||||
|
||||
## 1. Task01整体流程(外加录屏整理)
|
||||
|
||||
- 本次组队学习的内容以github上第二章第二节为主,具体每次的学习内容和重点已经在对应章节下的README.md中,大家忘记的可以随时取查看。
|
||||
https://github.com/datawhalechina/fun-rec
|
||||
|
||||
- 可以先体验一下本次学习内容的成果
|
||||
fun-rec项目中的新闻推荐系统开方测试了,地址:http://47.108.56.188:8686/,由于服务器比较拉胯,大家刷内容的时候可能会比较慢希望大家理解(第一次进系统尤其的慢),目前仍然可能存在一些bug,希望大家发现bug之后及时跟我们反馈呀。
|
||||
|
||||
- 最新的代码也已经上传到了github上面,感兴趣的可以去看看
|
||||
https://github.com/datawhalechina/fun-rec
|
||||
|
||||
- 作者寄语:
|
||||
|
||||
和DWer和准DWer们一起花了近两个月实现了一个新闻推荐系统的demo,这段时间真的辛苦大家了,很多系统出问题调bug都是拉个腾讯会议讨论解决方案,包括现在每天起来的一件事就是查看一下系统挂了没有,哪里不正常。
|
||||
|
||||
内容虽然没有任何商业价值,但是对于还是学生的我们来说,挑战还是非常大的,需要大家一起齐心协力的合作,用现有的技术组装出一个能正常跑起来的推荐系统。
|
||||
|
||||
本次内容量比较多,要想更好的完成本次组队学习任务也需要每个队伍的同学互相帮助,比如大家也可以考虑分工,最后互相分享的学习。相信大家在本次的组队学习中收获的不仅仅是系统中涉及到的相关技术,还能收获到一群和自己志同道合的朋友。
|
||||
|
||||
最后就是我们其实也是做系统的外行,代码或者系统的逻辑肯定存在很多问题。如果大家有更好的建议,我们也可以进一步交流,互相学习。
|
||||
|
||||
- Task01录屏(罗如意)
|
||||
|
||||
https://datawhale.feishu.cn/minutes/obcnzns778b725r5l535j32o
|
||||
|
||||
- 环境配置(windows)交流会议:
|
||||
|
||||
操作系统:Windows10
|
||||
MySQL:8.0.25
|
||||
Redis:5.0.14
|
||||
Mongodb:5.0.5
|
||||
Python:3.8
|
||||
|
||||
录屏:https://share.weiyun.com/u3ZIjZfg
|
||||
|
||||
- 作业分享:https://relph1119.github.io/my-team-learning/#/recommender_system32/task01
|
||||
|
||||
- 总结:https://share.weiyun.com/u3ZIjZfg
|
||||
|
||||
## 2. 问题解答
|
||||
|
||||
- 问:在执行`Scrapy`进行新闻爬取实战的时候,写不进去`mongdb`数据库
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
答:`mongodb`安装是否成功?有没有报错之类的。
|
||||
|
||||
问:成功安装。爬虫已经成功,我看`title content`已经有数据了
|
||||
|
||||

|
||||
|
||||
答:你这里是不是什么都没有,你退出`mongo`命令行重新进入查看一下呢?
|
||||
|
||||

|
||||
|
||||
问:对,我是在`windows`下做的,还是没有
|
||||
|
||||

|
||||
|
||||
答:你看下这个路径是不是有问题,我这里好像忘记改成`fun-rec`的路径了,你改成`fun-rec`下的路径再试试,有可能这里没有的参数没有导入进去。
|
||||
|
||||
问:是`setting`这个表吗?
|
||||
|
||||
答:你看看,应该是数据库那块的参数配置有问题。
|
||||
|
||||
问:`setting`在,在`settings`里面固化了的。
|
||||
|
||||
答:你这个代码是不是很早之前就下载的。嗷,想起来了。文档里面的内容没改。不过应该不影响。
|
||||
|
||||
问:就是开课的时候下载的。
|
||||
|
||||
答:不过应该不影响,代码你是自己单独写呢?还是运行的`fun-rec`下的`code代`码?你检查下pipline下面,看参数配置是否有问题,写一点print查看一下,然后在这里单独使用`insert`方法插入点东西查看是否有问题。
|
||||
|
||||

|
||||
|
||||
问(解决):找到问题了,在`copy piplines`文件的时候,`def`类没有对齐。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
- 问:`linux`一般软件安装都放在哪个目录下面啊?是`usr/local`吗?
|
||||
|
||||
答:这个看自己的习惯
|
||||
|
||||
|
||||
|
||||
- 问:出现跨域问题如何解决?
|
||||
|
||||
答:还需要启动`snowflaske`服务,启动代码为:
|
||||
|
||||
```
|
||||
snowflake_start_server --address=127.0.0.1 --port=8910 --dc=1 --worker=1
|
||||
```
|
||||
|
||||
|
||||
|
||||
- 问:如何修改redis配置?
|
||||
|
||||
答:https://blog.csdn.net/qq_39007083/article/details/105083156
|
||||
|
||||
|
||||
|
||||
- 问:`stop-writes-on-bgsave-error no`报错
|
||||
|
||||
答:这个可能和安装有关
|
||||
|
||||
|
||||
|
||||
- 问:服务没启动问题
|
||||
|
||||

|
||||
|
||||
答:对,需要安装,启动这个服务,已经加入到文档中。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
- 问:`redis key`的问题如何处理?
|
||||
|
||||
答:https://github.com/datawhalechina/fun-rec/blob/master/codes/news_recsys/news_rec_server/recprocess/README.md
|
||||
|
||||
|
||||
|
||||
- 问:`No module named 'conf.dao_config' `没有正确识别包,怎么办?
|
||||
|
||||
答1:看一下自己的路径是不是正确导入了,有可能跟系统有关,需要自己调整一下。
|
||||
|
||||
答2:这个问题,我遇到过,直接执行sh,在Windows下会出现,目前采用手动执行py脚本方式。
|
||||
|
||||
答:嗯嗯,我也先手动。
|
||||
|
||||
答:查到解决方法了,把出问题的地方`sys.path.append("")`换成`sys.path.append(os.path.dirname(os.path.dirname(os.path.realpath(__file__))))`就可以了
|
||||
|
||||
|
||||
|
||||
- 问:是否可能在教程中强调一下`node`版本的约束?前端部分很多`dependency`较老,比如`node-sass`包在较新`node`环境会编译错误。
|
||||
|
||||
答:直播时强调了,`linux`最好用项目目录下的那个`node`版本
|
||||
|
||||
|
||||
|
||||
- 问:`linux`时间是2021-7-20。结果redis用make编译的时候提示创建不完善(我是windows下的redis文件传到linux,结果显示安装文件是未来的文件)
|
||||
|
||||
答:`clock screw`问题可以通过touch修正一下错误的文件时间就可以了
|
||||
|
||||
|
||||
|
||||
- 问:在终端执行:`snowflake_start_server [--dc=DC_ID] [--worker=WORKER_ID] [--host=ADDRESS] [--port=PORT]`,报错显示`-bash: snowflake_start_server: `未找到命令,怎么解决。
|
||||
|
||||
答:看一下是否安装呢?运行的时候没有带参数吗?
|
||||
|
||||
问:带了参数,是`snowflake_start_server --address=127.0.0.1 --port=8910 --dc=1 --worker=1`
|
||||
|
||||
答:检查`path`里面是否有`user site`,试一试这个指令`export PATH=$PATH:"$(python3.8 -c 'import site; print(site.USER_BASE)')/bin"`
|
||||
|
||||
答:有反应了,可以修复,谢谢。
|
||||
|
||||
|
||||
|
||||
- 问:如何手动爬取信息?
|
||||
|
||||
答:手动方式,文档中有写,直接运行单独的py脚本即可。
|
||||
|
||||
https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
|
||||
|
||||
|
||||
|
||||
- 问:请问`pip install`的报错如何改正
|
||||
|
||||
答:指令修改为:
|
||||
|
||||
`npm install -g cnpm --registry=https://registry.npm.taobao.org`
|
||||
`cnpm install`
|
||||
|
||||
问:还是不行,有两条指令只报了`warning`,装完之后`npm install`还是会报找不到`python`和`pemition deny`
|
||||
|
||||
答:把`node modules`删掉重新用cnpm装一下试试,代码如下:
|
||||
|
||||
`npm install rimraf -g `
|
||||
|
||||
`rimraf node_modules`
|
||||
|
||||
问:还是报`python`错误,经过面向搜索引擎开发,有提到用`sudo`,但是发现还是不行,实际原因是由于用的是`root`账户权限执行`npm`,而`npm`默认是不适用`root`权限创建内容,因此会出现权限问题而导致失败,加上参数`--unsafe-perm=true --allow-root`即可解决问题。
|
||||
|
||||
答:步骤是:首先要装`py2`:`apt install python2`。然后换`cnpm`:`npm install -g cnpm --registry=https://registry.npm.taobao.org`, `cnpm install`。然后删掉`modules`:`npm install rimraf -g` ,`rimraf node_modules`。然后root用户的话`npm install --production --unsafe-perm=true --allow-root`。非root:`sudo npm install`
|
||||
|
||||
|
||||
|
||||
- 问:TODO: 设置开机自启动
|
||||
启动mongodb(服务器断电之后就会断开链接):
|
||||
sudo ./mongod --dbpath=/usr/local/mongodb/data/ --fork --logpath=/usr/local/mongodb/log
|
||||
|
||||
TODO: 设置开机自启动
|
||||
启动redis
|
||||
redis-server --daemonize yes --port 6378 --requirepass 123456
|
||||
redis-cli --raw
|
||||
|
||||
./mongod 这个是在哪里的?
|
||||
|
||||
答:就是你安装的mongdb的目录下面的bin文件里面的东西,你得看一下是安装到哪里了,找到对应的可执 行 脚本就行。
|
||||
|
||||
问:没有userinfo这个库是否需要先建库?
|
||||
|
||||
答:需要。表的话代码里面有这块的内容,会自动构建。你可以先测试`sqlalchemy`是否可以正常创建表。
|
||||
|
||||
|
||||
|
||||
- 问:`sh: 1: webpack-dev-server: not found`,开启前端服务报这个错
|
||||
|
||||
答:`cnpm install`一下就好了
|
||||
|
||||
|
||||
|
||||
- 问:外网访问的这个,除了设置`main.js`里的`axios.defaults.baseURL = "http://服务i去公网ip:3000"`,然后防火墙开`3000`端口和`8686`端口之外还有什么要设置的么
|
||||
|
||||
答:`flask 0.0.0.0`、`vue 0.0.0.0`和`外网访问`
|
||||
|
||||
|
||||
|
||||
- 问:跨域问题是啥意思?
|
||||
|
||||
答:https://blog.csdn.net/qq_38128179/article/details/84956552
|
||||
|
||||
|
||||
|
||||
- 问:为什么我的项目都启动了,用户也注册成功了,但是`datagrip`里面`MongoDB`下没有那两个数据库,`mysql`两个数据库下面没有对应的表?
|
||||
|
||||
答:数据库,右键刷新一下就出来了
|
||||
|
||||
问:都有了,反应有点慢
|
||||
|
||||
|
||||
|
||||
- 问:加载比较慢怎么办?
|
||||
|
||||
答:如果初始化就很慢的话可以把`router.js`里引入`component`的方式换成`component: () => import('./components/recLists.vue')`,会快一点点
|
||||
|
||||
|
||||
|
||||
- 问:为什么这一次运行`process_user.py`会报错,没这表啊?看报错好像是语法格式的问题。
|
||||
|
||||
答:数据库版本问题
|
||||
|
||||
|
||||
|
||||
- 问:关于服务:
|
||||
|
||||
答:服务器从`8686`发送`html`到`browser`渲染和执行代码,本地`browser`向服务器`3000`端口发送请求,所以后端服务器要`bind`到`0.0.0.0`保证公网可以访问。
|
||||
|
||||
|
||||
|
||||
- 问:`Datagrip`连接`mongodb`之后数据库显示`current database is not introspected`可能是什么原因导致的?
|
||||
|
||||
答:不用管,如果没有数据,这个库是不会显示的。
|
||||
|
||||
|
||||
|
||||
- 问:运行后端`server`遇到过这个报错吗?
|
||||
|
||||

|
||||
|
||||
答:重新安装下`cryptography`这个包
|
||||
|
||||
问:还是不行
|
||||
|
||||
答:有可能包冲突导致的,重建一个本地python环境
|
||||
|
||||
|
||||
|
||||
- 问:爬虫的时候报`cryptography`的错误,但是后端`server`服务是可以开启的,是什么原因?
|
||||
|
||||
答:`pip install -l cryptography == 35.0.0`可以解决。
|
||||
|
||||
|
||||
85
docs/推荐系统实战/新闻推荐系统实践/离线物料系统的构建问答整理.md
Normal file
85
docs/推荐系统实战/新闻推荐系统实践/离线物料系统的构建问答整理.md
Normal file
@@ -0,0 +1,85 @@
|
||||
## Task03问答整理
|
||||
|
||||
## 1. Task03整体流程(外加录屏整理)
|
||||
|
||||
- 学习2.2.1.5 自动化构建用户及物料画像,学习具体的代码的时候建议先把项目中所有文件中的README.md先看看,了解每个包大概是在干什么,然后再根据教程一点一点去理解流程,建议先梳理代码流程,等到最后自己觉得整个流程自己比较熟悉了,就可以慢慢的去看代码的实现细节。
|
||||
|
||||
具体详见https://github.com/datawhalechina/fun-rec/blob/master/docs/第二章 推荐系统实战/2.2新闻推荐系统实战/docs/2.2.1.5 自动化构建用户及物料画像.md
|
||||
|
||||
- 交流会议:
|
||||
|
||||
录屏:https://share.weiyun.com/u3ZIjZfg
|
||||
|
||||
- 作业分享:https://relph1119.github.io/my-team-learning/#/recommender_system32/task03
|
||||
|
||||
## 2. 问题解答
|
||||
|
||||
- 问:请问这样处理会不会时间复杂度较大?
|
||||
|
||||

|
||||
|
||||
答:不容易吧,爬取的文章判断重复怎么用`id`啊?如果式唯一性`id`必然是跟时间相关的。
|
||||
|
||||
问:有没有一种方式可以直接遍历?
|
||||
|
||||
答:不能全部遍历,这里是为后面准备的,比如后面有召回,排序,最后剩下的那些id才需要添加到redis中。
|
||||
|
||||
|
||||
|
||||
- 问:请教下大家,正常这两个`col`的大小是不是一样的?
|
||||
|
||||

|
||||
|
||||
答:不是一样大,你看一下具体内容就知道了,
|
||||
|
||||
问:前端的阅读数,点赞数、收藏数是来自哪一张表的?好像是`mysql`里面的,我想一下。
|
||||
|
||||
答:遍历`redis`的动态画像,把`mongodb`中对应的动态画像更新`mongodb`上面的应该大一些。
|
||||
|
||||
问:实时的用户的操作是`redis`去记录,然后一天结束后,把`redis`的用户操作推到`mongoDB`的`redisprotrail`,这样理解对吗?所以`redisprotrail`是记录`n-1`天内物料用户行为发生的变化,那是不是要是这个新闻没有被点开的话,这个新闻就不会进入`redisprotrail`里面呀?
|
||||
|
||||
答:应该不是的,`redisprotrail`应该是一天的数据,`featureprotrail`是多天的数据。
|
||||
|
||||
问:`redisprotrail`是参与图里面的哪一步呢?
|
||||
|
||||
答:这一步
|
||||
|
||||

|
||||
|
||||
问:这一步不是用`redis`的动态去更新`mongo`的`featureprotrail`吗?
|
||||
|
||||
答:你说的是左边那一块
|
||||
|
||||
问:按照3.1的描述,是不是`featureprotrail`和`redisprotrail`存的新闻条数应该是一样多的。
|
||||
|
||||
答:现在是的,后面如果有召回和排序的话,可能就不是。
|
||||
|
||||
问:`update_redis_mongo_protrail_data`这个函数是遍历`material_collection`,也就是`mongo_server.get_feature_protrail_collection()`也就是`featureprotrail`应该是和`featureprotrail`一样多的。
|
||||
|
||||

|
||||
|
||||
答:理解一样多没有问题,后面会修改。
|
||||
|
||||
|
||||
|
||||
- 问:用户的喜欢,收藏,点击是直接落到`mysql`里面吗?
|
||||
|
||||

|
||||
|
||||
答:是的,前端点击阅读、喜欢、收藏会实时更新。
|
||||
|
||||
|
||||
|
||||
- 问:这个关键词属于长尾是什么意思?
|
||||
|
||||

|
||||
|
||||
答:个别关键词的类别占了大量数目,以至于前三一直是那几个,长尾现象。
|
||||
|
||||
|
||||
|
||||
- 问:请教下大家,这个`user_exposure.py`是用来建`exposure_日期`这个表的么
|
||||
|
||||

|
||||
|
||||
答:是的。
|
||||
650
docs/推荐系统实战/新闻推荐系统实践/自动化构建用户及物料画像.md
Normal file
650
docs/推荐系统实战/新闻推荐系统实践/自动化构建用户及物料画像.md
Normal file
@@ -0,0 +1,650 @@
|
||||

|
||||
|
||||
# 自动化构建用户及物料画像
|
||||
|
||||
本节内容主要讲的是上图中红框框起来的部分,也就是离线自动化构建用户和物料的画像,这部分内容在新闻推荐系统中是为系统源源不断添加新物料的途径,由于我们的物料是通过爬虫获取的,所以还需要对爬取的数据进行处理,也就是构造新闻的画像。对于用户侧的画像则是需要每天将新注册的用户添加到用户画像库中,对于在系统中产生了行为的用户,我们还需要定期的更新用户的画像(长短期)。下面分别从物料侧和用户侧两个方面来详细解释这两类画像在系统中是如何自动化构建的。
|
||||
|
||||
## 物料侧画像的构建
|
||||
|
||||
**新物料来源**
|
||||
|
||||
首先要说的就是新物料的来源,物料是通过每天在新闻网站上爬取获取的,爬取新闻详细的内容在[2.2.1.4 Scrapy基础及新闻爬取实战](https://github.com/datawhalechina/fun-rec/blob/master/docs/第二章 推荐系统实战/2.2新闻推荐系统实战/docs/2.2.1.4 scrapy基础及新闻爬取实战.md)中已经详细的聊过了,这里要说明的一点就是,新闻爬取是每天凌晨的时候爬取前一天的新闻,这么做的原因是可以爬到更多的物料,缺点就是物料的时效性会延迟一天,新爬取的物料存储在MongoDB中。
|
||||
|
||||
**物料画像的更新**
|
||||
|
||||
物料画像的更新主要有一下几个方面:
|
||||
|
||||
1. 新物料画像添加到物料库中
|
||||
2. 旧物料画像,通过用户的交互记录进行更新
|
||||
|
||||
首先说一下新物料添加到物料库的逻辑是什么,新物料添加到物料库这件事情肯定是发生在新闻爬取之后的,然后要将新物料添加到物料库还需要对新物料做一些简单的画像处理,目前我们定义的画像字段如下(处理后的画像存储在Mongodb):
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211203150212960.png" alt="image-20211203150212960" style="zoom: 80%;" />
|
||||
|
||||
具体的逻辑就是遍历今天爬取的所有文章,然后通过文章的title来判断这篇文章是否已经在物料库中(新闻网站有可能有些相同的文章会出现在多天)来去重。然后再根据我们定义的一些字段,给画像相应的字段初始化,最后就是存入画像物料池中。
|
||||
|
||||
关于旧物料画像的更新,这里就需要先了解一下旧物料哪些字段会被用户的行为更新。下面是新闻列表展示页,我们会发现前端会展示新闻的阅读、喜欢及收藏次数。而用户的交互(阅读、点赞和收藏)会改变这些值。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211203150835056.png" alt="image-20211203150835056" style="zoom:80%;" />
|
||||
|
||||
为了能够实时的在前端显示新闻的这些动态行为信息,我们提前将新闻的动态信息存储到了redis中,线上获取的时候是直接从redis中获取新闻的数据,并且如果用户对新闻产生了交互,那么这些动态信息就会被更新,我们也是直接更新redis中的值,这样做主要是为了能够让前端可以实时的获取的新闻最新的动态画像信息。
|
||||
|
||||
通过上面的内容我们了解到,新闻的动态画像的更新是在redis中进行的,而redis又是一个内存数据库,资源是非常宝贵的,我们不能一直将新闻的信息存储在里面,而是每天进行一次更新,只更新哪些今天可能会被用来展示的新闻(有些新闻可能从发表到现在太久了,由于新闻的时效性就没有必要再展示了)。所以为了能够保存新闻历史的动态信息,系统还需要每天将redis中的动态新闻信息更新到mongodb存储的新闻画像库中,这里的逻辑也是每天会定时触发,这里的逻辑会放在更新完新物料的画像之后,当然这里两个的先后顺序并没有什么影响,只需要注意更新物料动态画像的时候一定得再redis数据清空之前。
|
||||
|
||||
其实这里还有个逻辑需要说明一下,新闻的画像库其实是有两个的,一个被称为是特征库FeatureProtrail, 它存储了物料的所有字段。还有一个是存储前端展示内容的画像库RedisProtrail, 这个画像库中的物料是一样的多,只不过每个物料存储的内容不一样,这个特征库的内容每天都会被更新,作为存储再redis中的新闻内容的备份内容。所以在完成了新、旧物料画像的更新之后,我们需要将最新的物料库中的新闻信息往RedisProtrail物料库中写一份,并去掉一些前端展示不需要的字段内容。
|
||||
|
||||
关于物料画像的更新的核心代码:
|
||||
|
||||
```python
|
||||
# -*- coding: utf-8 -*-
|
||||
from re import S
|
||||
import sys
|
||||
import json
|
||||
sys.path.append("../")
|
||||
from material_process.utils import get_key_words
|
||||
from dao.mongo_server import MongoServer
|
||||
from dao.redis_server import RedisServer
|
||||
|
||||
"""
|
||||
新闻画像中包含的字段:
|
||||
0. news_id 新闻的id
|
||||
1. title 标题
|
||||
2. raw_key_words (爬下来的关键词,可能有缺失)
|
||||
3. manual_key_words (根据内容生成的关键词)
|
||||
4. ctime 时间
|
||||
5. content 新闻具体内容
|
||||
6. cate 新闻类别
|
||||
7. likes 新闻点赞数量
|
||||
8. collections 新闻收藏数量
|
||||
9. read_nums 阅读次数
|
||||
10. url 新闻原始链接
|
||||
"""
|
||||
|
||||
class NewsProtraitServer:
|
||||
def __init__(self):
|
||||
"""初始化相关参数
|
||||
"""
|
||||
self.mongo_server = MongoServer()
|
||||
self.sina_collection = self.mongo_server.get_sina_news_collection()
|
||||
self.material_collection = self.mongo_server.get_feature_protrail_collection()
|
||||
self.redis_mongo_collection = self.mongo_server.get_redis_mongo_collection()
|
||||
self.news_dynamic_feature_redis = RedisServer().get_dynamic_news_info_redis()
|
||||
|
||||
def _find_by_title(self, collection, title):
|
||||
"""从数据库中查找是否有相同标题的新闻数据
|
||||
数据库存在当前标题的数据返回True, 反之返回Flase
|
||||
"""
|
||||
# find方法,返回的是一个迭代器
|
||||
find_res = collection.find({"title": title})
|
||||
if len(list(find_res)) != 0:
|
||||
return True
|
||||
return False
|
||||
|
||||
def _generate_feature_protrail_item(self, item):
|
||||
"""生成特征画像数据,返回一个新的字典
|
||||
"""
|
||||
news_item = dict()
|
||||
news_item['news_id'] = item['news_id']
|
||||
news_item['title'] = item['title']
|
||||
# 从新闻内容中提取的关键词没有原始新闻爬取时的关键词准确,所以手动提取的关键词
|
||||
# 只是作为一个补充,当原始新闻中没有提供关键词的时候可以使用
|
||||
news_item['raw_key_words'] = item['raw_key_words']
|
||||
key_words_list = get_key_words(item['content'])
|
||||
news_item['manual_key_words'] = ",".join(key_words_list)
|
||||
news_item['ctime'] = item['ctime']
|
||||
news_item['content'] = item['content']
|
||||
news_item['cate'] = item['cate']
|
||||
news_item['url'] = item['url']
|
||||
news_item['likes'] = 0
|
||||
news_item['collections'] = 0
|
||||
news_item['read_num'] = 0
|
||||
news_item['hot_value'] = 1000 # 初始化一个比较大的热度值,会随着时间进行衰减
|
||||
|
||||
return news_item
|
||||
|
||||
def update_new_items(self):
|
||||
"""将今天爬取的数据构造画像存入画像数据库中
|
||||
"""
|
||||
# 遍历今天爬取的所有数据
|
||||
for item in self.sina_collection.find():
|
||||
# 根据标题进行去重
|
||||
if self._find_by_title(self.material_collection, item["title"]):
|
||||
continue
|
||||
news_item = self._generate_feature_protrail_item(item)
|
||||
# 插入物料池
|
||||
self.material_collection.insert_one(news_item)
|
||||
|
||||
print("run update_new_items success.")
|
||||
|
||||
def update_redis_mongo_protrail_data(self):
|
||||
"""每天都需要将新闻详情更新到redis中,并且将前一天的redis数据删掉
|
||||
"""
|
||||
# 每天先删除前一天的redis展示数据,然后再重新写入
|
||||
self.redis_mongo_collection.drop()
|
||||
print("delete RedisProtrail ...")
|
||||
# 遍历特征库
|
||||
for item in self.material_collection.find():
|
||||
news_item = dict()
|
||||
news_item['news_id'] = item['news_id']
|
||||
news_item['title'] = item['title']
|
||||
news_item['ctime'] = item['ctime']
|
||||
news_item['content'] = item['content']
|
||||
news_item['cate'] = item['cate']
|
||||
news_item['url'] = item['url']
|
||||
news_item['likes'] = 0
|
||||
news_item['collections'] = 0
|
||||
news_item['read_num'] = 0
|
||||
|
||||
self.redis_mongo_collection.insert_one(news_item)
|
||||
print("run update_redis_mongo_protrail_data success.")
|
||||
|
||||
def update_dynamic_feature_protrail(self):
|
||||
"""用redis的动态画像更新mongodb的画像
|
||||
"""
|
||||
# 遍历redis的动态画像,将mongodb中对应的动态画像更新
|
||||
news_list = self.news_dynamic_feature_redis.keys()
|
||||
for news_key in news_list:
|
||||
news_dynamic_info_str = self.news_dynamic_feature_redis.get(news_key)
|
||||
news_dynamic_info_str = news_dynamic_info_str.replace("'", '"' ) # 将单引号都替换成双引号
|
||||
news_dynamic_info_dict = json.loads(news_dynamic_info_str)
|
||||
|
||||
# 查询mongodb中对应的数据,并将对应的画像进行修改
|
||||
news_id = news_key.split(":")[1]
|
||||
mongo_info = self.material_collection.find_one({"news_id": news_id})
|
||||
new_mongo_info = mongo_info.copy()
|
||||
new_mongo_info['likes'] = news_dynamic_info_dict["likes"]
|
||||
new_mongo_info['collections'] = news_dynamic_info_dict["collections"]
|
||||
new_mongo_info['read_num'] = news_dynamic_info_dict["read_num"]
|
||||
|
||||
self.material_collection.replace_one(mongo_info, new_mongo_info, upsert=True) # upsert为True的话,没有就插入
|
||||
print("update_dynamic_feature_protrail success.")
|
||||
|
||||
|
||||
# 系统最终执行的不是这个脚本,下面的代码是用来测试的
|
||||
if __name__ == "__main__":
|
||||
news_protrait = NewsProtraitServer()
|
||||
# 新物料画像的更新
|
||||
news_protrait.update_new_items()
|
||||
# 更新动态特征
|
||||
news_protrait.update_dynamic_feature_protrail()
|
||||
# redis展示新闻内容的备份
|
||||
news_protrait.update_redis_mongo_protrail_data()
|
||||
```
|
||||
|
||||
|
||||
|
||||
上面的内容说完了物料的更新,接下来介绍一下对于更新完的物料是如何添加到redis数据库中去的。关于新闻内容在redis中的存储,我们将新闻的信息拆成了两部分,一部分是新闻不会发生变化的属性(例如,创建时间、标题、新闻内容等),还有一部分是物料的动态属性,在redis中存储的key的标识分别为:static_news_detail:news_id和dynamic_news_detail:news_id 下面是redis中存储的真实内容
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211203153841222.png" alt="image-20211203153841222" style="zoom:67%;" />
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211203153958220.png" alt="image-20211203153958220" style="zoom:70%;" />
|
||||
|
||||
这么做的目的是为了线上实时更改物料动态信息的时候更加高效一点。当需要获取某篇新闻的详细信息的时候需要查这两份数据并将数据这两部分数据拼起来最终才发送给前端展示。这部分的代码逻辑如下:
|
||||
|
||||
```python
|
||||
import sys
|
||||
sys.path.append("../../")
|
||||
from dao.mongo_server import MongoServer
|
||||
from dao.redis_server import RedisServer
|
||||
|
||||
|
||||
class NewsRedisServer(object):
|
||||
def __init__(self):
|
||||
self.rec_list_redis = RedisServer().get_reclist_redis()
|
||||
self.static_news_info_redis = RedisServer().get_static_news_info_redis()
|
||||
self.dynamic_news_info_redis = RedisServer().get_dynamic_news_info_redis()
|
||||
|
||||
self.redis_mongo_collection = MongoServer().get_redis_mongo_collection()
|
||||
|
||||
# 删除前一天redis中的内容
|
||||
self._flush_redis_db()
|
||||
|
||||
def _flush_redis_db(self):
|
||||
"""每天都需要删除redis中的内容,更新当天新的内容上去
|
||||
"""
|
||||
try:
|
||||
self.rec_list_redis.flushall()
|
||||
except Exception:
|
||||
print("flush redis fail ... ")
|
||||
|
||||
def _get_news_id_list(self):
|
||||
"""获取物料库中所有的新闻id
|
||||
"""
|
||||
# 获取所有数据的news_id,
|
||||
# 暴力获取,直接遍历整个数据库,得到所有新闻的id
|
||||
# TODO 应该存在优化方法可以通过查询的方式只返回new_id字段
|
||||
news_id_list = []
|
||||
for item in self.redis_mongo_collection.find():
|
||||
news_id_list.append(item["news_id"])
|
||||
return news_id_list
|
||||
|
||||
def _set_info_to_redis(self, redisdb, content):
|
||||
"""将content添加到指定redis
|
||||
"""
|
||||
try:
|
||||
redisdb.set(*content)
|
||||
except Exception:
|
||||
print("set content fail".format(content))
|
||||
|
||||
def news_detail_to_redis(self):
|
||||
"""将需要展示的画像内容存储到redis
|
||||
静态不变的特征存到static_news_info_db_num
|
||||
动态会发生改变的特征存到dynamic_news_info_db_num
|
||||
"""
|
||||
news_id_list = self._get_news_id_list()
|
||||
|
||||
for news_id in news_id_list:
|
||||
news_item_dict = self.redis_mongo_collection.find_one({"news_id": news_id}) # 返回的是一个列表里面套了一个字典
|
||||
news_item_dict.pop("_id")
|
||||
|
||||
# 分离动态属性和静态属性
|
||||
static_news_info_dict = dict()
|
||||
static_news_info_dict['news_id'] = news_item_dict['news_id']
|
||||
static_news_info_dict['title'] = news_item_dict['title']
|
||||
static_news_info_dict['ctime'] = news_item_dict['ctime']
|
||||
static_news_info_dict['content'] = news_item_dict['content']
|
||||
static_news_info_dict['cate'] = news_item_dict['cate']
|
||||
static_news_info_dict['url'] = news_item_dict['url']
|
||||
static_content_tuple = "static_news_detail:" + str(news_id), str(static_news_info_dict)
|
||||
self._set_info_to_redis(self.static_news_info_redis, static_content_tuple)
|
||||
|
||||
dynamic_news_info_dict = dict()
|
||||
dynamic_news_info_dict['likes'] = news_item_dict['likes']
|
||||
dynamic_news_info_dict['collections'] = news_item_dict['collections']
|
||||
dynamic_news_info_dict['read_num'] = news_item_dict['read_num']
|
||||
dynamic_content_tuple = "dynamic_news_detail:" + str(news_id), str(dynamic_news_info_dict)
|
||||
self._set_info_to_redis(self.dynamic_news_info_redis, dynamic_content_tuple)
|
||||
|
||||
print("news detail info are saved in redis db.")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 每次创建这个对象的时候都会把数据库中之前的内容删除
|
||||
news_redis_server = NewsRedisServer()
|
||||
# 将最新的前端展示的画像传到redis
|
||||
news_redis_server.news_detail_to_redis()
|
||||
```
|
||||
|
||||
|
||||
|
||||
**到此位置,离线物料画像的更新逻辑就介绍完了,最后把上面的逻辑用代码全部串起来的话就如下代码:**下面的代码是会在每天定时运行的,这样就将物料侧的画像构建逻辑穿起来了
|
||||
|
||||
```python
|
||||
from material_process.news_protrait import NewsProtraitServer
|
||||
from material_process.news_to_redis import NewsRedisServer
|
||||
|
||||
def process_material():
|
||||
"""物料处理函数
|
||||
"""
|
||||
# 画像处理
|
||||
protrail_server = NewsProtraitServer()
|
||||
# 处理最新爬取新闻的画像,存入特征库
|
||||
protrail_server.update_new_items()
|
||||
# 更新新闻动态画像, 需要在redis数据库内容清空之前执行
|
||||
protrail_server.update_dynamic_feature_protrail()
|
||||
# 生成前端展示的新闻画像,并在mongodb中备份一份
|
||||
protrail_server.update_redis_mongo_protrail_data()
|
||||
|
||||
# 新闻数据写入redis, 注意这里处理redis数据的时候是会将前一天的数据全部清空
|
||||
news_redis_server = NewsRedisServer()
|
||||
# 将最新的前端展示的画像传到redis
|
||||
news_redis_server.news_detail_to_redis()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
process_material()
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 用户侧画像的构建
|
||||
|
||||
对于用户画像的更新来说主要分为两方面:
|
||||
|
||||
1. 新注册用户画像的更新
|
||||
2. 老用户画像的更新
|
||||
|
||||
由于我们系统中将所有注册过的用户都放到了一个表里面(新、老用户),所以每次更新画像的话只需要遍历一遍注册表中的所有用户。再说具体的画像构建逻辑之前,得先了解一下用户画像中包含哪些字段,下面是直接从mongo中查出来的
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211203163848668.png" alt="image-20211203163848668" style="zoom:80%;" />
|
||||
|
||||
从上面可以看出,主要是用户的基本信息和用户历史信息相关的一些标签,对于用户的基本属性特征这个可以直接从注册表中获取,那么对于跟用户历史阅读相关的信息,需要统计用户历史的所有阅读、喜欢和收藏的新闻详细信息。为了得到跟用户历史兴趣相关的信息,我们需要对用户的历史阅读、喜欢和收藏这几个历史记录给存起来,其实这些信息都可以从日志信息中获取得到,但是这里有个工程上的事情得先说明一下,先看下面这个图,对于每个用户点进一篇新闻的详情页
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20211203164332062.png" alt="image-20211203164332062" style="zoom: 80%;" />
|
||||
|
||||
最底部有个喜欢和收藏,这个前端展示的结果是从后端获取的数据,那就意味着后端需要维护一个用户历史点击及收藏过的文章列表,这里我们使用了mysql来存储,主要是怕redis不够用。其实这两个表不仅仅可以用来前端展示用的,还可以用来分析用户的画像,这都给我们整理好了用户历史喜欢和收藏了。
|
||||
|
||||
此外前面也提到了我们可以使用用户历史阅读的文章做用户画像,为了更好处理和理解,我们也维护了一份用户历史阅读过的所有文章的mysql表(维护表的核心逻辑就是每天跑一边用户日志,更新一下用户历史阅读的记录),那么此时我们其实已经有了用户的阅读、点赞和收藏三个用户行为表了,接下来就直接可以通过这三个表来做具体的用户兴趣相关的画像了,实现的具体逻辑如下:
|
||||
|
||||
```python
|
||||
import sys
|
||||
import datetime
|
||||
from collections import Counter, defaultdict
|
||||
|
||||
from sqlalchemy.sql.expression import table
|
||||
sys.path.append("../../")
|
||||
from dao.mongo_server import MongoServer
|
||||
from dao.mysql_server import MysqlServer
|
||||
from dao.entity.register_user import RegisterUser
|
||||
from dao.entity.user_read import UserRead
|
||||
from dao.entity.user_likes import UserLikes
|
||||
from dao.entity.user_collections import UserCollections
|
||||
|
||||
|
||||
class UserProtrail(object):
|
||||
def __init__(self):
|
||||
self.user_protrail_collection = MongoServer().get_user_protrail_collection()
|
||||
self.material_collection = MongoServer().get_feature_protrail_collection()
|
||||
self.register_user_sess = MysqlServer().get_register_user_session()
|
||||
self.user_collection_sess = MysqlServer().get_user_collection_session()
|
||||
self.user_like_sess = MysqlServer().get_user_like_session()
|
||||
self.user_read_sess = MysqlServer().get_user_read_session()
|
||||
|
||||
def _user_info_to_dict(self, user):
|
||||
"""将mysql查询出来的结果转换成字典存储
|
||||
"""
|
||||
info_dict = dict()
|
||||
|
||||
# 基本属性特征
|
||||
info_dict["userid"] = user.userid
|
||||
info_dict["username"] = user.username
|
||||
info_dict["passwd"] = user.passwd
|
||||
info_dict["gender"] = user.gender
|
||||
info_dict["age"] = user.age
|
||||
info_dict["city"] = user.city
|
||||
|
||||
# 兴趣爱好
|
||||
behaviors=["like","collection"]
|
||||
time_range = 15
|
||||
_, feature_dict = self.get_statistical_feature_from_history_behavior(user.userid,time_range,behavior_types=behaviors)
|
||||
for type in feature_dict.keys():
|
||||
if feature_dict[type]:
|
||||
info_dict["{}_{}_intr_cate".format(type,time_range)] = feature_dict[type]["intr_cate"] # 历史喜欢最多的Top3的新闻类别
|
||||
info_dict["{}_{}_intr_key_words".format(type,time_range)] = feature_dict[type]["intr_key_words"] # 历史喜欢新闻的Top3的关键词
|
||||
info_dict["{}_{}_avg_hot_value".format(type,time_range)] = feature_dict[type]["avg_hot_value"] # 用户喜欢新闻的平均热度
|
||||
info_dict["{}_{}_news_num".format(type,time_range)] = feature_dict[type]["news_num"] # 用户15天内喜欢的新闻数量
|
||||
else:
|
||||
info_dict["{}_{}_intr_cate".format(type,time_range)] = "" # 历史喜欢最多的Top3的新闻类别
|
||||
info_dict["{}_{}_intr_key_words".format(type,time_range)] = "" # 历史喜欢新闻的Top3的关键词
|
||||
info_dict["{}_{}_avg_hot_value".format(type,time_range)] = 0 # 用户喜欢新闻的平均热度
|
||||
info_dict["{}_{}_news_num".format(type,time_range)] = 0 # 用户15天内喜欢的新闻数量
|
||||
|
||||
return info_dict
|
||||
|
||||
def update_user_protrail_from_register_table(self):
|
||||
"""每天都需要将当天注册的用户添加到用户画像池中
|
||||
"""
|
||||
# 遍历注册用户表
|
||||
for user in self.register_user_sess.query(RegisterUser).all():
|
||||
user_info_dict = self._user_info_to_dict(user)
|
||||
old_user_protrail_dict = self.user_protrail_collection.find_one({"username": user.username})
|
||||
if old_user_protrail_dict is None:
|
||||
self.user_protrail_collection.insert_one(user_info_dict)
|
||||
else:
|
||||
# 使用参数upsert设置为true对于没有的会创建一个
|
||||
# replace_one 如果遇到相同的_id 就会更新
|
||||
self.user_protrail_collection.replace_one(old_user_protrail_dict, user_info_dict, upsert=True)
|
||||
|
||||
|
||||
def get_statistical_feature_from_history_behavior(self, user_id, time_range, behavior_types):
|
||||
"""获取用户历史行为的统计特征 ["read","like","collection"] """
|
||||
fail_type = []
|
||||
sess, table_obj, history = None, None, None
|
||||
feature_dict = defaultdict(dict)
|
||||
|
||||
end = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
||||
start = (datetime.datetime.now()+datetime.timedelta(days=-time_range)).strftime("%Y-%m-%d %H:%M:%S")
|
||||
|
||||
for type in behavior_types:
|
||||
if type == "read":
|
||||
sess = getattr(self,"user_{}_sess".format(type))
|
||||
table_obj = UserRead
|
||||
elif type == "like":
|
||||
sess = getattr(self,"user_{}_sess".format(type))
|
||||
table_obj = UserLikes
|
||||
elif type == "collection":
|
||||
sess = getattr(self,"user_{}_sess".format(type))
|
||||
table_obj = UserCollections
|
||||
try:
|
||||
history = sess.query(table_obj).filter(table_obj.userid==user_id).filter(table_obj.curtime>=start).filter(table_obj.curtime<=end).all()
|
||||
except Exception as e:
|
||||
print(str(e))
|
||||
fail_type.append(type)
|
||||
continue
|
||||
|
||||
feature_dict[type] = self._gen_statistical_feature(history)
|
||||
|
||||
return fail_type, feature_dict
|
||||
|
||||
def _gen_statistical_feature(self,history):
|
||||
""""""
|
||||
# 为history 获取特征
|
||||
if not len(history): return None
|
||||
history_new_id = []
|
||||
history_hot_value = []
|
||||
history_new_cate = []
|
||||
history_key_word = []
|
||||
for h in history:
|
||||
news_id = h.newid
|
||||
newsquery = {"news_id":news_id}
|
||||
result = self.material_collection.find_one(newsquery)
|
||||
history_new_id.append(result["news_id"])
|
||||
history_hot_value.append(result["hot_value"])
|
||||
history_new_cate.append(result["cate"])
|
||||
history_key_word += result["manual_key_words"].split(",")
|
||||
|
||||
feature_dict = dict()
|
||||
# 计算平均热度
|
||||
feature_dict["avg_hot_value"] = 0 if sum(history_hot_value) < 0.001 else sum(history_hot_value) / len(history_hot_value)
|
||||
|
||||
# 计算Top3的类别
|
||||
cate_dict = Counter(history_new_cate)
|
||||
cate_list= sorted(cate_dict.items(),key = lambda d: d[1], reverse=True)
|
||||
cate_str = ",".join([item[0] for item in cate_list[:3]] if len(cate_list)>=3 else [item[0] for item in cate_list] )
|
||||
feature_dict["intr_cate"] = cate_str
|
||||
|
||||
# 计算Top3的关键词
|
||||
word_dict = Counter(history_key_word)
|
||||
word_list= sorted(word_dict.items(),key = lambda d: d[1], reverse=True)
|
||||
# TODO 关键字属于长尾 如果关键字的次数都是一次 该怎么去前3
|
||||
word_str = ",".join([item[0] for item in word_list[:3]] if len(cate_list)>=3 else [item[0] for item in word_list] )
|
||||
feature_dict["intr_key_words"] = word_str
|
||||
# 新闻数目
|
||||
feature_dict["news_num"] = len(history_new_id)
|
||||
|
||||
return feature_dict
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
user_protrail = UserProtrail().update_user_protrail_from_register_table()
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
到此位置用户画像的基本逻辑就介绍完了,下面是用户画像更新的总体逻辑代码:
|
||||
|
||||
```python
|
||||
from user_process.user_to_mysql import UserMysqlServer
|
||||
from user_process.user_protrail import UserProtrail
|
||||
|
||||
"""
|
||||
1. 将用户的曝光数据从redis落到mysql中。
|
||||
2. 更新用户画像
|
||||
"""
|
||||
|
||||
def process_users():
|
||||
"""将用户数据落 Mysql
|
||||
"""
|
||||
# 用户mysql存储
|
||||
user_mysql_server = UserMysqlServer()
|
||||
# 用户曝光数据落mysql
|
||||
user_mysql_server.user_exposure_to_mysql()
|
||||
|
||||
# 更新用户画像
|
||||
user_protrail = UserProtrail()
|
||||
user_protrail.update_user_protrail_from_register_table()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
process_users()
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 画像自动化构建
|
||||
|
||||
上面分别对用户侧和物料侧的画像构建进行了介绍,接下来就是要将上面所有的过程都自动化运行,并且设置好定时任务,其实最核心的一点就是一定要在清除redis数据之前,完成用户和物料画像的构建,下面是构建整个自动化的流程。
|
||||
|
||||
|
||||
|
||||
**物料更新脚本:process_material.py**
|
||||
|
||||
```python
|
||||
from material_process.news_protrait import NewsProtraitServer
|
||||
from material_process.news_to_redis import NewsRedisServer
|
||||
|
||||
|
||||
def process_material():
|
||||
"""物料处理函数
|
||||
"""
|
||||
# 画像处理
|
||||
protrail_server = NewsProtraitServer()
|
||||
# 处理最新爬取新闻的画像,存入特征库
|
||||
protrail_server.update_new_items()
|
||||
# 更新新闻动态画像, 需要在redis数据库内容清空之前执行
|
||||
protrail_server.update_dynamic_feature_protrail()
|
||||
# 生成前端展示的新闻画像,并在mongodb中备份一份
|
||||
protrail_server.update_redis_mongo_protrail_data()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
process_material()
|
||||
```
|
||||
|
||||
|
||||
|
||||
**用户画像更新脚本: process_user.py**
|
||||
|
||||
```python
|
||||
from user_process.user_to_mysql import UserMysqlServer
|
||||
from user_process.user_protrail import UserProtrail
|
||||
|
||||
"""
|
||||
1. 将用户的曝光数据从redis落到mysql中。
|
||||
2. 更新用户画像
|
||||
"""
|
||||
|
||||
|
||||
def process_users():
|
||||
"""将用户数据落 Mysql
|
||||
"""
|
||||
# 用户mysql存储
|
||||
user_mysql_server = UserMysqlServer()
|
||||
# 用户曝光数据落mysql
|
||||
user_mysql_server.user_exposure_to_mysql()
|
||||
|
||||
# 更新用户画像
|
||||
user_protrail = UserProtrail()
|
||||
user_protrail.update_user_protrail_from_register_table()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
process_users()
|
||||
```
|
||||
|
||||
|
||||
|
||||
**redis数据更新脚本:update_redis.py**
|
||||
|
||||
```python
|
||||
from material_process.news_protrait import NewsProtraitServer
|
||||
from material_process.news_to_redis import NewsRedisServer
|
||||
|
||||
|
||||
def update():
|
||||
"""物料处理函数
|
||||
"""
|
||||
# 新闻数据写入redis, 注意这里处理redis数据的时候是会将前一天的数据全部清空
|
||||
news_redis_server = NewsRedisServer()
|
||||
# 将最新的前端展示的画像传到redis
|
||||
news_redis_server.news_detail_to_redis()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
update()
|
||||
```
|
||||
|
||||
|
||||
|
||||
**最后将上面三个脚本穿起来的shell脚本offline_material_and_user_process.sh:**
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
|
||||
python=/home/recsys/miniconda3/envs/news_rec_py3/bin/python
|
||||
news_recsys_path="/home/recsys/news_rec_server"
|
||||
|
||||
echo "$(date -d today +%Y-%m-%d-%H-%M-%S)"
|
||||
|
||||
# 为了更方便的处理路径的问题,可以直接cd到我们想要运行的目录下面
|
||||
cd ${news_recsys_path}/materials
|
||||
|
||||
# 更新物料画像
|
||||
${python} process_material.py
|
||||
if [ $? -eq 0 ]; then
|
||||
echo "process_material success."
|
||||
else
|
||||
echo "process_material fail."
|
||||
fi
|
||||
|
||||
# 更新用户画像
|
||||
${python} process_user.py
|
||||
if [ $? -eq 0 ]; then
|
||||
echo "process_user.py success."
|
||||
else
|
||||
echo "process_user.py fail."
|
||||
fi
|
||||
|
||||
# 清除前一天redis中的数据,更新最新今天最新的数据
|
||||
${python} update_redis.py
|
||||
if [ $? -eq 0 ]; then
|
||||
echo "update_redis success."
|
||||
else
|
||||
echo "update_redis fail."
|
||||
fi
|
||||
|
||||
|
||||
echo " "
|
||||
```
|
||||
|
||||
|
||||
|
||||
**crontab定时任务:**
|
||||
|
||||

|
||||
|
||||
将定时任务拆解一下:
|
||||
|
||||
```vim
|
||||
0 0 * * * /home/recsys/news_rec_server/scheduler/crawl_news.sh >> /home/recsys/news_rec_server/logs/offline_material_process.log &&
|
||||
|
||||
/home/recsys/news_rec_server/scheduler/offline_material_and_user_process.sh >> /home/recsys/news_rec_server/logs/material_and_user_process.log &&
|
||||
|
||||
/home/recsys/news_rec_server/scheduler/run_offline.sh >> /home/recsys/news_rec_server/logs/offline_rec_list_to_redis.log
|
||||
```
|
||||
|
||||
前面的crontab语法表示的是每天0点运行下面这一串脚本,上面命令中的 && 表示的是先运行完符号前面的内容再运行后面的命令,所以这里的&&是为了将上面三个任务串联起来,大致的执行逻辑就是:
|
||||
|
||||
1. 先爬取新闻数据,这里需要注意的是,虽然是今天零点爬数据,但是实际上爬的是前一天的新闻
|
||||
2. 数据爬完之后,离线更新用户画像,物料画像及线上要存储再redis中的画像
|
||||
3. 最后其实是离线推荐的流程,离线将用户的排序列表存到redis中,线上直接取就行了
|
||||
|
||||
|
||||
|
||||
# 总结
|
||||
|
||||
这篇文章主要讲解了新闻推荐系统离线如何通过自动化的形式构建物料和用户的画像,文章比较长,但是整体上把文章最上面的那张图中的逻辑讲清楚了(细节方面的可能需要看代码了)。
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user