Merge branch 'master' of https://github.com/datawhalechina/fun-rec
This commit is contained in:
0
codes/funrec/__init__.py
Normal file
0
codes/funrec/__init__.py
Normal file
9
codes/funrec/data/readme.md
Normal file
9
codes/funrec/data/readme.md
Normal file
@@ -0,0 +1,9 @@
|
||||
|
||||
## 数据集介绍
|
||||
|
||||
1. taobao电商数据,用于测试序列、图相关模型。下载链接:https://tianchi.aliyun.com/dataset/dataDetail?dataId=649&userId=1
|
||||
2. criteo数据,用于测特征交叉和wide&deep系列模型,链接:https://pan.baidu.com/s/15-xG7u2Rq1Mr9A-abrjtqw (提取码:htb7)
|
||||
3. 人口普查收录数据,用于测试多任务学习模型,下载链接:https://archive.ics.uci.edu/ml/datasets/census+income
|
||||
4. movielens(ml-1m)数据集,用于测试召回相关模型,下载链接:https://grouplens.org/datasets/movielens/
|
||||
|
||||
注意:测试的时候数据仍然比较大,可以通过对数据采样测试。
|
||||
61
codes/funrec/examples/preprocess.py
Normal file
61
codes/funrec/examples/preprocess.py
Normal file
@@ -0,0 +1,61 @@
|
||||
from random import sample, seed
|
||||
import sys
|
||||
sys.path.append("..")
|
||||
import os
|
||||
import time
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
from datetime import date, datetime
|
||||
from sklearn.preprocessing import LabelEncoder
|
||||
from features import DenseFeat, SparseFeat, VarLenSparseFeat
|
||||
|
||||
|
||||
def process_data(sample_num=5000000):
|
||||
train_data_path = "./data/train"
|
||||
print("read train data ...")
|
||||
train_data_df = pd.read_csv(train_data_path, sep=',', nrows=sample_num)
|
||||
|
||||
all_df = train_data_df
|
||||
all_df['hour'] = all_df['hour'].astype(str)
|
||||
|
||||
# 构造时间相关的特征
|
||||
def _convert_weekday(timestamp):
|
||||
dt = date(int('20' + timestamp[0:2]), int(timestamp[2:4]), int(timestamp[4:6]))
|
||||
return int(dt.strftime('%w'))
|
||||
|
||||
def _convert_weekend(timestamp):
|
||||
dt = date(int('20' + timestamp[0:2]), int(timestamp[2:4]), int(timestamp[4:6]))
|
||||
return 1 if dt.strftime('%w') in ['6', '0'] else 0
|
||||
|
||||
"""
|
||||
is_weekend: 是否是周末
|
||||
weekday: 星期几
|
||||
hour: 几点
|
||||
"""
|
||||
all_df['is_weekend'] = all_df['hour'].apply(lambda x: _convert_weekend(x))
|
||||
all_df['weekday'] = all_df['hour'].apply(lambda x: _convert_weekday(x))
|
||||
all_df['hour_v2'] = all_df['hour'].apply(lambda x: int(x[6:8]))
|
||||
del all_df['hour']
|
||||
|
||||
sparse_features = ['id', 'C1', 'banner_pos', 'site_id', 'site_domain',
|
||||
'site_category', 'app_id', 'app_domain', 'app_category', 'device_id',
|
||||
'device_ip', 'device_model', 'device_type', 'device_conn_type', 'C14',
|
||||
'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21', 'is_weekend',
|
||||
'weekday', 'hour_v2']
|
||||
|
||||
print("start label encode ... ")
|
||||
feature_max_index_dict = {}
|
||||
for feat in sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
all_df[feat] = lbe.fit_transform(all_df[feat]) + 1 # 让id从1开始,0可能会被做掩码
|
||||
feature_max_index_dict[feat] = all_df[feat].max() + 1
|
||||
|
||||
train_df = all_df
|
||||
feature_names = train_df.columns
|
||||
train_input_dict = {}
|
||||
for name in feature_names:
|
||||
train_input_dict[name] = np.array(train_df[name].values)
|
||||
|
||||
train_label = np.array(train_df['click'])
|
||||
train_df.pop('click')
|
||||
return feature_max_index_dict, train_input_dict, train_label
|
||||
58
codes/funrec/examples/run_autoint.py
Normal file
58
codes/funrec/examples/run_autoint.py
Normal file
@@ -0,0 +1,58 @@
|
||||
import sys
|
||||
sys.path.append("..")
|
||||
import os
|
||||
import time
|
||||
from sklearn.preprocessing import LabelEncoder
|
||||
from features import DenseFeat, SparseFeat, VarLenSparseFeat
|
||||
from models import AutoInt
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.callbacks import TensorBoard
|
||||
from preprocess import process_data
|
||||
|
||||
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# feature_max_index_dict, train_input_dict, train_label = process_data(sample_num=5000000)
|
||||
feature_max_index_dict, train_input_dict, train_label = process_data(sample_num=1000)
|
||||
|
||||
embed_dim = 4
|
||||
|
||||
# linear_feature_names = ['C1', 'banner_pos', 'site_category', 'app_category',
|
||||
# 'device_type', 'device_conn_type', 'C15','C16','C18','C19','C21',
|
||||
# 'is_weekend','weekday','hour_v2']
|
||||
|
||||
linear_feature_names = ['is_weekend','weekday','hour_v2']
|
||||
|
||||
dnn_feature_names = ['id', 'C1', 'banner_pos', 'site_id', 'site_domain',
|
||||
'site_category', 'app_id', 'app_domain', 'app_category', 'device_id',
|
||||
'device_ip', 'device_model', 'device_type','device_conn_type', 'C14',
|
||||
'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21', 'is_weekend', 'weekday',
|
||||
'hour_v2']
|
||||
|
||||
linear_feature_columns = [SparseFeat(name, vocabulary_size=feature_max_index_dict[name],
|
||||
embedding_dim=embed_dim, embedding_name=name) for name in linear_feature_names]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(name, vocabulary_size=feature_max_index_dict[name],
|
||||
embedding_dim=embed_dim, embedding_name=name, group_name='pnn') for name in dnn_feature_names]
|
||||
|
||||
model = AutoInt(linear_feature_columns, dnn_feature_columns)
|
||||
model.summary()
|
||||
|
||||
model.compile(
|
||||
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
|
||||
loss=tf.keras.losses.BinaryCrossentropy(),
|
||||
metrics=[tf.keras.metrics.AUC()])
|
||||
|
||||
model_name = "autoint-{}".format(int(time.time()))
|
||||
tensorboard = TensorBoard(
|
||||
log_dir='logs/{}'.format(model_name),
|
||||
update_freq='batch')
|
||||
|
||||
model.fit(train_input_dict, train_label,
|
||||
batch_size=1024, epochs=2, verbose=1,
|
||||
validation_split=0.2, callbacks=[tensorboard])
|
||||
|
||||
# evaluation = model.evaluate(test_input_dict, test_label, batch_size=2048,
|
||||
# verbose=1, return_dict=True, callbacks=[tensorboard])
|
||||
# print(evaluation)
|
||||
59
codes/funrec/examples/run_deepfm.py
Normal file
59
codes/funrec/examples/run_deepfm.py
Normal file
@@ -0,0 +1,59 @@
|
||||
from random import seed
|
||||
import sys
|
||||
sys.path.append("..")
|
||||
import os
|
||||
import time
|
||||
from sklearn.preprocessing import LabelEncoder
|
||||
from features import DenseFeat, SparseFeat, VarLenSparseFeat
|
||||
from models import DeepFM
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.callbacks import TensorBoard
|
||||
from preprocess import process_data
|
||||
|
||||
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
feature_max_index_dict, train_input_dict, train_label = process_data(sample_num=5000000)
|
||||
# feature_max_index_dict, train_input_dict, train_label = process_data(sample_num=1000)
|
||||
|
||||
embed_dim = 4
|
||||
|
||||
# linear_feature_names = ['C1', 'banner_pos', 'site_category', 'app_category',
|
||||
# 'device_type', 'device_conn_type', 'C15','C16','C18','C19','C21',
|
||||
# 'is_weekend','weekday','hour_v2']
|
||||
|
||||
linear_feature_names = ['is_weekend','weekday','hour_v2']
|
||||
|
||||
dnn_feature_names = ['id', 'C1', 'banner_pos', 'site_id', 'site_domain',
|
||||
'site_category', 'app_id', 'app_domain', 'app_category', 'device_id',
|
||||
'device_ip', 'device_model', 'device_type','device_conn_type', 'C14',
|
||||
'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21', 'is_weekend', 'weekday',
|
||||
'hour_v2']
|
||||
|
||||
linear_feature_columns = [SparseFeat(name, vocabulary_size=feature_max_index_dict[name],
|
||||
embedding_dim=embed_dim, embedding_name=name) for name in linear_feature_names]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(name, vocabulary_size=feature_max_index_dict[name],
|
||||
embedding_dim=embed_dim, embedding_name=name, group_name='fm') for name in dnn_feature_names]
|
||||
|
||||
model = DeepFM(linear_feature_columns, dnn_feature_columns)
|
||||
model.summary()
|
||||
|
||||
model.compile(
|
||||
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
|
||||
loss=tf.keras.losses.BinaryCrossentropy(),
|
||||
metrics=[tf.keras.metrics.AUC()])
|
||||
|
||||
model_name = "deepfm-{}".format(int(time.time()))
|
||||
tensorboard = TensorBoard(
|
||||
log_dir='logs/{}'.format(model_name),
|
||||
update_freq='batch')
|
||||
|
||||
model.fit(train_input_dict, train_label,
|
||||
batch_size=1024, epochs=2, verbose=1,
|
||||
validation_split=0.2, callbacks=[tensorboard])
|
||||
|
||||
# evaluation = model.evaluate(test_input_dict, test_label, batch_size=2048,
|
||||
# verbose=1, return_dict=True, callbacks=[tensorboard])
|
||||
# print(evaluation)
|
||||
147
codes/funrec/examples/run_dssm.py
Normal file
147
codes/funrec/examples/run_dssm.py
Normal file
@@ -0,0 +1,147 @@
|
||||
import sys
|
||||
sys.path.append("..")
|
||||
import random
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
import pandas as pd
|
||||
from sklearn.preprocessing import LabelEncoder
|
||||
from features import DenseFeat, SparseFeat, VarLenSparseFeat
|
||||
from models import DSSM
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.preprocessing.sequence import pad_sequences
|
||||
|
||||
def process_data(data_path, max_len=50, neg_sample=0, type='random'):
|
||||
"""读取数据
|
||||
"""
|
||||
data_df = pd.read_csv(data_path, sep=',')
|
||||
|
||||
"""
|
||||
print(data_df.head())
|
||||
user_id movie_id rating timestamp title genres gender age occupation zip
|
||||
0 1 1193 5 978300760 One Flew Over the Cuckoo's Nest (1975) Drama F 1 10 48067
|
||||
1 1 661 3 978302109 James and the Giant Peach (1996) Animation|Children's|Musical F 1 10 48067
|
||||
2 1 914 3 978301968 My Fair Lady (1964) Musical|Romance F 1 10 48067
|
||||
3 1 3408 4 978300275 Erin Brockovich (2000) Drama F 1 10 48067
|
||||
4 1 2355 5 978824291 Bug's Life, A (1998) Animation|Children's|Comedy F 1 10 48067
|
||||
"""
|
||||
use_features = ['user_id', 'movie_id', 'gender', 'age', 'occupation', 'zip']
|
||||
|
||||
# 特征转换, 类别编码
|
||||
feature_max_index_dict = {}
|
||||
for feat in use_features:
|
||||
lbe = LabelEncoder()
|
||||
data_df[feat] = lbe.fit_transform(data_df[feat]) + 1 # 让id从1开始,0可能会被做掩码
|
||||
feature_max_index_dict[feat] = data_df[feat].max() + 1
|
||||
|
||||
user_profile = data_df[["user_id", "gender", "age", "occupation", "zip"]].drop_duplicates('user_id')
|
||||
item_profile = data_df[["movie_id"]].drop_duplicates('movie_id')
|
||||
|
||||
print(user_profile.head())
|
||||
|
||||
# 构建数据标签
|
||||
# 将数据按照时间进行排序, 默认是升序
|
||||
data_df.sort_values("timestamp", inplace=True)
|
||||
|
||||
unique_item_ids = data_df['movie_id'].unique()
|
||||
|
||||
train_data_list = []
|
||||
test_data_list = []
|
||||
# 设置最短历史序列长度
|
||||
min_seq_len = 1
|
||||
# 遍历每个用户构建正负样本
|
||||
for user_id, hist_df in data_df.groupby('user_id'):
|
||||
pos_list = hist_df['movie_id'].to_list()
|
||||
rating_list = hist_df['rating'].to_list()
|
||||
|
||||
if neg_sample > 0:
|
||||
candidate_list = list(set(unique_item_ids) - set(pos_list))
|
||||
# 每个正样本对应多个负样本
|
||||
neg_list = np.random.choice(candidate_list, size=len(pos_list) * neg_sample,
|
||||
replace=True) # 设置为True表示可以取相同的元素
|
||||
|
||||
# 历史序列长度最少为1,这里也可以设置为更长
|
||||
for i in range(min_seq_len, len(pos_list)):
|
||||
hist = pos_list[:i]
|
||||
if i != len(pos_list) - min_seq_len:
|
||||
# 构造样本
|
||||
# 样本的数据格式:user_id, hist_movid_id, pos_movie_id, label, hist_len
|
||||
train_data_list.append((user_id, hist[::-1], pos_list[i], 1, len(hist[::-1]), rating_list[i]))
|
||||
for negi in range(neg_sample):
|
||||
train_data_list.append((user_id, hist[::-1], neg_list[i*neg_sample + i], 0, len(hist[::-1]), rating_list[i]))
|
||||
else:
|
||||
test_data_list.append((user_id, hist[::-1], pos_list[i], 1, len(hist[::-1]), rating_list[i]))
|
||||
|
||||
random.shuffle(train_data_list)
|
||||
random.shuffle(test_data_list)
|
||||
|
||||
# 将输入的特征转换成字典的形式
|
||||
train_data_dict = {}
|
||||
test_data_dict = {}
|
||||
|
||||
# 构建训练集数据
|
||||
train_data_dict['user_id'] = np.array([line[0] for line in train_data_list])
|
||||
# 由于这个是不定长,所以不能直接转np,需要先对其进行padding
|
||||
# train_hist_movie_id = [line[1] for line in train_data_list]
|
||||
# train_data_dict['hist_movie_ids'] = pad_sequences(train_hist_movie_id,
|
||||
# maxlen=max_len, padding='post', truncating='post', value=0)
|
||||
train_data_dict['movie_id'] = np.array([line[2] for line in train_data_list])
|
||||
train_data_dict['label'] = np.array([line[3] for line in train_data_list])
|
||||
# train_data_dict['hist_len'] = np.array([line[4] for line in train_data_list])
|
||||
# train_data_dict['rating'] = np.array([line[5] for line in train_data_list])
|
||||
for key in ["gender", "age", "occupation", "zip"]:
|
||||
# 将样本中所有user_id对应的其他的特征都索引到
|
||||
tmp_list = []
|
||||
for i in range(len(train_data_dict['user_id'])):
|
||||
tmp_list.append(user_profile[user_profile['user_id'] ==
|
||||
train_data_dict['user_id'][i]][key])
|
||||
train_data_dict[key] = np.array(tmp_list)
|
||||
|
||||
# 构建测试集数据
|
||||
test_data_dict['user_id'] = np.array([line[0] for line in test_data_list])
|
||||
# 由于这个是不定长,所以不能直接转np,需要先对其进行padding
|
||||
# train_hist_movie_id = [line[1] for line in test_data_list]
|
||||
# test_data_dict['hist_movie_ids'] = pad_sequences(train_hist_movie_id,
|
||||
# maxlen=max_len, padding='post', truncating='post', value=0)
|
||||
test_data_dict['movie_id'] = np.array([line[2] for line in test_data_list])
|
||||
test_data_dict['label'] = np.array([line[3] for line in test_data_list])
|
||||
# test_data_dict['hist_len'] = np.array([line[4] for line in test_data_list])
|
||||
# test_data_dict['rating'] = np.array([line[5] for line in test_data_list])
|
||||
|
||||
for key in ["gender", "age", "occupation", "zip"]:
|
||||
# 将样本中所有user_id对应的其他的特征都索引到
|
||||
tmp_list = []
|
||||
for i in range(len(test_data_dict['user_id'])):
|
||||
tmp_list.append(user_profile[user_profile['user_id'] ==
|
||||
test_data_dict['user_id'][i]][key])
|
||||
test_data_dict[key] = np.array(tmp_list)
|
||||
|
||||
|
||||
return feature_max_index_dict, train_data_dict, test_data_dict
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
data_path = '/home/ryluo/recsys/data/movielens_sample.txt'
|
||||
|
||||
feature_max_index_dict, train_data_dict, test_data_dict = process_data(data_path)
|
||||
train_label = train_data_dict['label']
|
||||
print(train_data_dict.keys())
|
||||
train_data_dict.pop("label")
|
||||
embedding_dim = 4
|
||||
user_feature_columns = [SparseFeat('user_id', feature_max_index_dict['user_id'], embedding_dim),
|
||||
SparseFeat("gender", feature_max_index_dict['gender'], embedding_dim),
|
||||
SparseFeat("age", feature_max_index_dict['age'], embedding_dim),
|
||||
SparseFeat("occupation", feature_max_index_dict['occupation'], embedding_dim),
|
||||
SparseFeat("zip", feature_max_index_dict['zip'], embedding_dim),
|
||||
# VarLenSparseFeat(SparseFeat('hist_movie_id', feature_max_idx['movie_id'], embedding_dim,
|
||||
# embedding_name="movie_id"), SEQ_LEN, 'mean', 'hist_len'),
|
||||
]
|
||||
|
||||
item_feature_columns = [SparseFeat('movie_id', feature_max_index_dict['movie_id'], embedding_dim)]
|
||||
print(user_feature_columns + item_feature_columns)
|
||||
|
||||
model = DSSM(user_feature_columns, item_feature_columns)
|
||||
|
||||
model.compile(optimizer="adam", loss='binary_crossentropy', metrics=[tf.keras.metrics.AUC])
|
||||
|
||||
model.fit(train_data_dict, train_label, # train_label,
|
||||
batch_size=256, epochs=1, verbose=1, validation_split=0.1, )
|
||||
53
codes/funrec/examples/run_fibinet.py
Normal file
53
codes/funrec/examples/run_fibinet.py
Normal file
@@ -0,0 +1,53 @@
|
||||
from random import seed
|
||||
import sys
|
||||
sys.path.append("..")
|
||||
import os
|
||||
import time
|
||||
from sklearn.preprocessing import LabelEncoder
|
||||
from features import DenseFeat, SparseFeat, VarLenSparseFeat
|
||||
from models import FiBiNet
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.callbacks import TensorBoard
|
||||
from preprocess import process_data
|
||||
|
||||
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
feature_max_index_dict, train_input_dict, train_label = process_data(sample_num=1000)
|
||||
embed_dim = 4
|
||||
|
||||
linear_feature_names = ['is_weekend','weekday','hour_v2']
|
||||
|
||||
dnn_feature_names = ['id', 'C1', 'banner_pos', 'site_id', 'site_domain',
|
||||
'site_category', 'app_id', 'app_domain', 'app_category', 'device_id',
|
||||
'device_ip', 'device_model', 'device_type','device_conn_type', 'C14',
|
||||
'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21', 'is_weekend', 'weekday',
|
||||
'hour_v2']
|
||||
|
||||
linear_feature_columns = [SparseFeat(name, vocabulary_size=feature_max_index_dict[name],
|
||||
embedding_dim=embed_dim, embedding_name=name) for name in linear_feature_names]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(name, vocabulary_size=feature_max_index_dict[name],
|
||||
embedding_dim=embed_dim, embedding_name=name, group_name='bilinear') for name in dnn_feature_names]
|
||||
|
||||
model = FiBiNet(linear_feature_columns, dnn_feature_columns, bilinear_type='each')
|
||||
# model.summary()
|
||||
|
||||
model.compile(
|
||||
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
|
||||
loss=tf.keras.losses.BinaryCrossentropy(),
|
||||
metrics=[tf.keras.metrics.AUC()])
|
||||
|
||||
model_name = "fibinet-{}".format(int(time.time()))
|
||||
tensorboard = TensorBoard(
|
||||
log_dir='logs/{}'.format(model_name),
|
||||
update_freq='batch')
|
||||
|
||||
model.fit(train_input_dict, train_label,
|
||||
batch_size=2048, epochs=5, verbose=1,
|
||||
validation_split=0.2, callbacks=[tensorboard])
|
||||
|
||||
# evaluation = model.evaluate(test_input_dict, test_label, batch_size=2048,
|
||||
# verbose=1, return_dict=True, callbacks=[tensorboard])
|
||||
# print(evaluation)
|
||||
59
codes/funrec/examples/run_pnn.py
Normal file
59
codes/funrec/examples/run_pnn.py
Normal file
@@ -0,0 +1,59 @@
|
||||
from random import seed
|
||||
import sys
|
||||
sys.path.append("..")
|
||||
import os
|
||||
import time
|
||||
from sklearn.preprocessing import LabelEncoder
|
||||
from features import DenseFeat, SparseFeat, VarLenSparseFeat
|
||||
from models import PNN
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.callbacks import TensorBoard
|
||||
from preprocess import process_data
|
||||
|
||||
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# feature_max_index_dict, train_input_dict, train_label = process_data(sample_num=5000000)
|
||||
feature_max_index_dict, train_input_dict, train_label = process_data(sample_num=1000)
|
||||
|
||||
embed_dim = 4
|
||||
|
||||
# linear_feature_names = ['C1', 'banner_pos', 'site_category', 'app_category',
|
||||
# 'device_type', 'device_conn_type', 'C15','C16','C18','C19','C21',
|
||||
# 'is_weekend','weekday','hour_v2']
|
||||
|
||||
linear_feature_names = ['is_weekend','weekday','hour_v2']
|
||||
|
||||
dnn_feature_names = ['id', 'C1', 'banner_pos', 'site_id', 'site_domain',
|
||||
'site_category', 'app_id', 'app_domain', 'app_category', 'device_id',
|
||||
'device_ip', 'device_model', 'device_type','device_conn_type', 'C14',
|
||||
'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21', 'is_weekend', 'weekday',
|
||||
'hour_v2']
|
||||
|
||||
linear_feature_columns = [SparseFeat(name, vocabulary_size=feature_max_index_dict[name],
|
||||
embedding_dim=embed_dim, embedding_name=name) for name in linear_feature_names]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(name, vocabulary_size=feature_max_index_dict[name],
|
||||
embedding_dim=embed_dim, embedding_name=name, group_name='pnn') for name in dnn_feature_names]
|
||||
|
||||
model = PNN(linear_feature_columns, dnn_feature_columns)
|
||||
model.summary()
|
||||
|
||||
model.compile(
|
||||
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
|
||||
loss=tf.keras.losses.BinaryCrossentropy(),
|
||||
metrics=[tf.keras.metrics.AUC()])
|
||||
|
||||
model_name = "pnn-{}".format(int(time.time()))
|
||||
tensorboard = TensorBoard(
|
||||
log_dir='logs/{}'.format(model_name),
|
||||
update_freq='batch')
|
||||
|
||||
model.fit(train_input_dict, train_label,
|
||||
batch_size=1024, epochs=2, verbose=1,
|
||||
validation_split=0.2, callbacks=[tensorboard])
|
||||
|
||||
# evaluation = model.evaluate(test_input_dict, test_label, batch_size=2048,
|
||||
# verbose=1, return_dict=True, callbacks=[tensorboard])
|
||||
# print(evaluation)
|
||||
117
codes/funrec/feature_column.py
Normal file
117
codes/funrec/feature_column.py
Normal file
@@ -0,0 +1,117 @@
|
||||
import tensorflow as tf
|
||||
from collections import namedtuple
|
||||
from tensorflow.keras.initializers import RandomNormal
|
||||
|
||||
# 默认分组名称
|
||||
DEFAULT_GROUP_NAME="default_group"
|
||||
|
||||
# 定义feature columns父类
|
||||
BaseDenseFeat = namedtuple('DenseFeat',
|
||||
['name', 'dimension', 'dtype', 'transform_fn'])
|
||||
BaseSparseFeat = namedtuple('SparseFeat',
|
||||
['name', 'vocabulary_size', 'embedding_dim',
|
||||
'use_hash', 'vocabulary_path', 'dtype',
|
||||
'embeddings_initializer','embedding_name',
|
||||
'group_name', 'trainable'])
|
||||
BaseVarLenSparseFeat = namedtuple('VarLenSparseFeat',
|
||||
['sparsefeat', 'maxlen', 'combiner',
|
||||
'length_name', 'weight_name', 'weight_norm'])
|
||||
|
||||
class DenseFeat(BaseDenseFeat):
|
||||
""" Dense feature
|
||||
Args:
|
||||
name: feature name,
|
||||
dimension: dimension of the feature, default = 1.
|
||||
dtype: dtype of the feature, default="float32".
|
||||
transform_fn: If not `None` , a function that can be used to transform
|
||||
values of the feature. the function takes the input Tensor as its
|
||||
argument, and returns the output Tensor.
|
||||
(e.g. lambda x: (x - 3.0) / 4.2).
|
||||
"""
|
||||
# 加上__slots__ = ()限制,在生成实例的时候,不会为实例生成一个属性字典,
|
||||
# 可以节省内存
|
||||
__slots__ = ()
|
||||
|
||||
def __new__(cls, name, dimension=1, dtype="float32", transform_fn=None):
|
||||
return super(DenseFeat, cls).__new__(
|
||||
cls, name, dimension, dtype, transform_fn)
|
||||
|
||||
def __hash__(self):
|
||||
return self.name.__hash__()
|
||||
|
||||
|
||||
class SparseFeat(BaseSparseFeat):
|
||||
__slots__ = ()
|
||||
|
||||
def __new__(cls, name, vocabulary_size, embedding_dim=4, use_hash=False,
|
||||
vocabulary_path=None, dtype="int32", embeddings_initializer=None,
|
||||
embedding_name=None, group_name=DEFAULT_GROUP_NAME, trainable=True):
|
||||
|
||||
if embedding_dim == "auto":
|
||||
embedding_dim = 6 * int(pow(vocabulary_size, 0.25))
|
||||
if embeddings_initializer is None:
|
||||
# 随机初始化
|
||||
embeddings_initializer = RandomNormal(
|
||||
mean=0.0, stddev=0.0001, seed=2020)
|
||||
|
||||
if embedding_name is None:
|
||||
embedding_name = name
|
||||
|
||||
return super(SparseFeat, cls).__new__(cls, name, vocabulary_size,
|
||||
embedding_dim, use_hash, vocabulary_path, dtype,
|
||||
embeddings_initializer, embedding_name, group_name, trainable)
|
||||
|
||||
def __hash__(self):
|
||||
return self.name.__hash__()
|
||||
|
||||
|
||||
class VarLenSparseFeat(BaseVarLenSparseFeat):
|
||||
__slots__ = ()
|
||||
|
||||
def __new__(cls, sparsefeat, maxlen, combiner="mean", length_name=None,
|
||||
weight_name=None, weight_norm=True):
|
||||
return super(VarLenSparseFeat, cls).__new__(cls, sparsefeat, maxlen,
|
||||
combiner, length_name, weight_name, weight_norm)
|
||||
|
||||
@property
|
||||
def name(self):
|
||||
return self.sparsefeat.name
|
||||
|
||||
@property
|
||||
def vocabulary_size(self):
|
||||
return self.sparsefeat.vocabulary_size
|
||||
|
||||
@property
|
||||
def embedding_dim(self):
|
||||
return self.sparsefeat.embedding_dim
|
||||
|
||||
@property
|
||||
def use_hash(self):
|
||||
return self.sparsefeat.use_hash
|
||||
|
||||
@property
|
||||
def vocabulary_path(self):
|
||||
return self.sparsefeat.vocabulary_path
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
return self.sparsefeat.dtype
|
||||
|
||||
@property
|
||||
def embeddings_initializer(self):
|
||||
return self.sparsefeat.embeddings_initializer
|
||||
|
||||
@property
|
||||
def embedding_name(self):
|
||||
return self.sparsefeat.embedding_name
|
||||
|
||||
@property
|
||||
def group_name(self):
|
||||
return self.sparsefeat.group_name
|
||||
|
||||
@property
|
||||
def trainable(self):
|
||||
return self.sparsefeat.trainable
|
||||
|
||||
def __hash__(self):
|
||||
return self.name.__hash__()
|
||||
250
codes/funrec/features.py
Normal file
250
codes/funrec/features.py
Normal file
@@ -0,0 +1,250 @@
|
||||
from ast import Add
|
||||
from copy import copy, deepcopy
|
||||
from itertools import chain
|
||||
import pandas as pd
|
||||
from collections import OrderedDict, defaultdict
|
||||
import tensorflow as tf
|
||||
from feature_column import DenseFeat, SparseFeat, VarLenSparseFeat
|
||||
from layers import NoMask, PoolingLayer
|
||||
from tensorflow.keras.layers import Input, Embedding, Flatten, \
|
||||
Concatenate, Dense
|
||||
from tensorflow.keras.regularizers import l2
|
||||
from tensorflow.keras.initializers import Zeros
|
||||
|
||||
|
||||
def get_linear_logits(linear_dense_list, linear_input_sparse_list):
|
||||
logits_list = []
|
||||
if len(linear_dense_list) > 0:
|
||||
linear_dense_feature = Concatenate(axis=-1)(linear_dense_list)
|
||||
linear_logits = Dense(1, use_bias=False)(linear_dense_feature)
|
||||
logits_list.append(linear_logits)
|
||||
if len(linear_input_sparse_list) > 0:
|
||||
linear_sparse_feature = Flatten()(Concatenate(axis=1)(
|
||||
linear_input_sparse_list))
|
||||
linear_sparse_logits = tf.reduce_sum(linear_sparse_feature, axis=-1,
|
||||
keepdims=True)
|
||||
logits_list.append(linear_sparse_logits)
|
||||
if len(logits_list) == 0:
|
||||
raise ValueError("")
|
||||
elif len(logits_list) == 1:
|
||||
return logits_list[0]
|
||||
return tf.keras.layers.add(logits_list)
|
||||
|
||||
|
||||
class FeatureMap(object):
|
||||
"""将feature columns转换成Input层
|
||||
分为三种情况:
|
||||
1. DenseFeat, 这是用来处理dense特征,例如数值特征,向量特征(图片、搜索兴趣等)
|
||||
2. SparseFeat, 这是用来处理id特征,例如商品类别,用户的职业等
|
||||
3. VarLenSparseFeat, 这是用来处理序列特征,对于序列特征可以是有序的,例如用户
|
||||
的行为序列,也可以是多兴趣或多标签特征,例如multi-hot相关的无序标签id特征
|
||||
【对于序列特征,可能还会伴随着序列每个位置的权重,或者序列长度等特征】
|
||||
注:这里返回的是一个字典,字典的key对应的是特征的名字,网络层的名字也命名为对
|
||||
应特征的名字
|
||||
"""
|
||||
def __init__(self, feature_columns):
|
||||
self.feature_columns = feature_columns
|
||||
self.feature_input_layer_dict = self._create_keras_input_layers()
|
||||
|
||||
def _create_keras_input_layers(self):
|
||||
feature_input_layer_dict = OrderedDict()
|
||||
for fc in self.feature_columns:
|
||||
if isinstance(fc, DenseFeat):
|
||||
feature_input_layer_dict[fc.name] = Input(shape=(fc.dimension,),
|
||||
name=fc.name, dtype=fc.type)
|
||||
elif isinstance(fc, SparseFeat):
|
||||
feature_input_layer_dict[fc.name] = Input(shape=(1, ),
|
||||
name=fc.name, dtype=fc.dtype)
|
||||
elif isinstance(fc, VarLenSparseFeat):
|
||||
feature_input_layer_dict[fc.name] = Input(shape=(fc.maxlen, ),
|
||||
name=fc.name, dtype=fc.dtype)
|
||||
# 判断序列特征中是否包含权重和序列长度
|
||||
if fc.weight_name is not None:
|
||||
feature_input_layer_dict[fc.weight_name] = Input(shape=(
|
||||
fc.maxlen,), name=fc.weight_name,
|
||||
dtype='float32')
|
||||
if fc.length_name is not None:
|
||||
feature_input_layer_dict[fc.length_name] = Input(shape=(1,),
|
||||
name=fc.length_name, dtype='int32')
|
||||
else:
|
||||
raise TypeError("Invalid feature column type:", type(fc))
|
||||
return feature_input_layer_dict
|
||||
|
||||
|
||||
class FeatureEncoder(object):
|
||||
"""特征编码
|
||||
主要的目标是:将特征按照三种类型进行分组,并将id类特征的Input层与对应的Embedding
|
||||
层关联,最终可以生成三类特征的字典,给不同模型的特征处理部分用
|
||||
|
||||
这个类中需要先调用FeatureMap类获取到不同特征的Input层
|
||||
|
||||
相关方法:
|
||||
1. _filter_feature_columns:过滤出不同类型的特征,便于对不同特征进行处理
|
||||
2. get_linear_sparse_feature:这个是将应用于线性层的id特征,将他们的初始化维度
|
||||
设置为1,一般用在Wide & Deep系列模型的Wide侧
|
||||
3. create_embedding_layers_dict:根据SparseFeat、VarLenSparseFeat的配置信息,
|
||||
创建Embedding层,这里的一些关键参数包括,模型是否可训练、模型是否用0填充等
|
||||
最终返回一个Embedding层的字典,字典的key是embedding_name, 而不是feature_name
|
||||
4. embedding_look_up:将不同的id特征的Input层与其对应的Embedding层进行关联,
|
||||
这里对于SparseFeat特征,我们采用了嵌套字典,方便不同的id特征做不同的特征
|
||||
处理,对于VarLenSparseFeat特征,直接用单层字典存储
|
||||
5. encode_to_dict:将三类特征分别封装成字典的形式
|
||||
"""
|
||||
def __init__(self, feature_column_list, linear_sparse_feature=None):
|
||||
"""
|
||||
linear_sparse_feature:对于某些模型可能需要单独这个参数进来处理,因为
|
||||
模型底层的Input都是一样的,所以需要在这里一起将这类特征处理了,否则在
|
||||
外面就非常不方便处理
|
||||
"""
|
||||
self.feature_column_list = feature_column_list
|
||||
self.feature_map = FeatureMap(feature_columns=feature_column_list)
|
||||
self.feature_input_layer_dict = self.feature_map.\
|
||||
feature_input_layer_dict
|
||||
|
||||
# 过滤出不同类型的特征,方便后续统一处理
|
||||
self._filter_feature_columns()
|
||||
|
||||
# 单独处理linear sparse特征
|
||||
if linear_sparse_feature is not None:
|
||||
self.linear_sparse_feature_dict = self.get_linear_sparse_feature(
|
||||
linear_sparse_feature
|
||||
)
|
||||
|
||||
# 处理三类不同的特征
|
||||
self.dense_feature_dict, self.sparse_feature_dict, \
|
||||
self.varlen_sparse_feature_dict = self.encode_to_dict()
|
||||
|
||||
def _filter_feature_columns(self):
|
||||
"""过滤不同的特征
|
||||
"""
|
||||
self.dense_feature_columns = [fc for fc in self.feature_column_list
|
||||
if isinstance(fc, DenseFeat)]
|
||||
self.sparse_feature_columns = [fc for fc in self.feature_column_list
|
||||
if isinstance(fc, SparseFeat)]
|
||||
self.varlen_sparse_feature_columns = [fc for fc in
|
||||
self.feature_column_list if isinstance(fc, VarLenSparseFeat)]
|
||||
|
||||
def create_embedding_layers_dict(self, sparse_feature_columns,
|
||||
varlen_sparse_feature_columns=None, l2_reg=1e-5, seed=2022,
|
||||
seq_mask_zeros=True, prefix='sparse_'):
|
||||
"""创建 Embedding 层,返回一个字典
|
||||
注意:创建Embedding层的时候,可能包含序列特征,这里以一个单独的参数传进来
|
||||
方便后续处理
|
||||
"""
|
||||
embedding_layers_dict = {}
|
||||
for fc in sparse_feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
emb = Embedding(fc.vocabulary_size,
|
||||
fc.embedding_dim,
|
||||
embeddings_initializer=fc.embeddings_initializer,
|
||||
embeddings_regularizer=l2(l2_reg),
|
||||
name=prefix + fc.name + '_emb')
|
||||
emb.trainable = fc.trainable
|
||||
embedding_layers_dict[fc.embedding_name] = emb
|
||||
|
||||
if varlen_sparse_feature_columns is not None:
|
||||
for fc in varlen_sparse_feature_columns:
|
||||
if isinstance(fc, VarLenSparseFeat):
|
||||
emb = Embedding(fc.vocabulary_size,
|
||||
fc.embedding_dim,
|
||||
embeddings_initializer=fc.embeddings_initializer,
|
||||
embeddings_regularizer=l2(l2_reg),
|
||||
name=prefix + fc.name + '_emb',
|
||||
mask_zero=seq_mask_zeros) # 变长序列的差异,长度不够用0填充
|
||||
emb.trainable = emb.trainable
|
||||
# 这里对于在sparse_feature_columns中出现的emb,如果embedding_name相同就会
|
||||
# 将上述的embedding覆盖,对于sparsefeat特征,使用带有mask的embedding
|
||||
# 效果是一样的,只不过在输出的向量里面会包含masking,这个可以在输出之后通
|
||||
# 过NoMask()去掉,这样就不会随着后面的计算不断地传播
|
||||
embedding_layers_dict[fc.embedding_name] = emb
|
||||
|
||||
return embedding_layers_dict
|
||||
|
||||
def embedding_look_up(self, sparse_feature_columns, embedding_layers_dict,
|
||||
is_varlen=False):
|
||||
"""将Input层和Embedding层串起来
|
||||
这里有两种情况:
|
||||
1. SparseFeat:此时需要考虑id特征之间的分组,所以返回的是一个嵌套的字典
|
||||
2. VarLenSparseFeat:直接返回一个字典,方便后续聚合或者序列特征的提取
|
||||
"""
|
||||
if not is_varlen:
|
||||
group_embedding_feature_dict = defaultdict(dict)
|
||||
else:
|
||||
varlen_embedding_feature_dict = {}
|
||||
|
||||
for fc in sparse_feature_columns:
|
||||
feature_name = fc.name
|
||||
embedding_name = fc.embedding_name
|
||||
input_layer = self.feature_input_layer_dict[feature_name]
|
||||
embedding_layer = embedding_layers_dict[embedding_name]
|
||||
emb_feat = embedding_layer(input_layer)
|
||||
if not is_varlen:
|
||||
group_embedding_feature_dict[fc.group_name][embedding_name]=emb_feat
|
||||
else:
|
||||
varlen_embedding_feature_dict[feature_name] = emb_feat
|
||||
|
||||
if not is_varlen:
|
||||
return group_embedding_feature_dict
|
||||
|
||||
return varlen_embedding_feature_dict
|
||||
|
||||
def get_linear_sparse_feature(self, linear_sparse_feature):
|
||||
"""id特征输入到linear层中
|
||||
1. 需要先拷贝一份SparseFeat特征的配置信息,并将embedding_dim重置为1,
|
||||
2. 然后在单独创建这类特征的Embedding层,并将其与对应的Input层关联
|
||||
"""
|
||||
# linear_sparse_feature_copy = copy(linear_sparse_feature)
|
||||
new_linear_sparse_feature_list = []
|
||||
# 重置SparseFeat的embedding_dim=1,这里需要先拷贝一分
|
||||
for fc in linear_sparse_feature:
|
||||
new_fc = copy(fc)
|
||||
new_fc = fc._replace(embedding_dim=1, embeddings_initializer=Zeros())
|
||||
new_linear_sparse_feature_list.append(new_fc)
|
||||
|
||||
print(new_linear_sparse_feature_list)
|
||||
|
||||
# 构建embedding层并将对应的Input层进行关联
|
||||
linear_embedding_layers_dict = self.create_embedding_layers_dict(
|
||||
new_linear_sparse_feature_list, prefix="linear_")
|
||||
# 因为所有特征的输入都是一样的,只不过后续的特征走向不一样,所以都使用的是
|
||||
# 同一份Input层,self.feature_input_layer_dict
|
||||
linear_sparse_feature_dict = self.embedding_look_up(
|
||||
new_linear_sparse_feature_list, linear_embedding_layers_dict,
|
||||
is_varlen=False)
|
||||
|
||||
return linear_sparse_feature_dict
|
||||
|
||||
def encode_to_dict(self):
|
||||
dense_feature_dict = {}
|
||||
if len(self.dense_feature_columns) > 0:
|
||||
for fc in self.feature_column_list:
|
||||
if isinstance(fc, DenseFeat):
|
||||
dense_feature_dict[fc.name] = \
|
||||
self.feature_input_layer_dict[fc.name]
|
||||
|
||||
embedding_layers_dict = {}
|
||||
if len(self.sparse_feature_columns) > 0 or \
|
||||
len(self.varlen_sparse_feature_columns) > 0:
|
||||
embedding_layers_dict = self.create_embedding_layers_dict(
|
||||
self.sparse_feature_columns,
|
||||
self.varlen_sparse_feature_columns
|
||||
)
|
||||
|
||||
sparse_feature_dict = {}
|
||||
varlen_sparse_feature_dict = {}
|
||||
if len(embedding_layers_dict) > 0:
|
||||
if len(self.sparse_feature_columns) > 0:
|
||||
sparse_feature_dict = self.embedding_look_up(
|
||||
self.feature_column_list, embedding_layers_dict,
|
||||
is_varlen=False)
|
||||
|
||||
if len(self.varlen_sparse_feature_columns) > 0:
|
||||
varlen_sparse_feature_dict = self.embedding_look_up(
|
||||
self.varlen_sparse_feature_columns, embedding_layers_dict,
|
||||
is_varlen=True)
|
||||
|
||||
return dense_feature_dict, sparse_feature_dict, varlen_sparse_feature_dict
|
||||
|
||||
|
||||
# TODO
|
||||
# 将tfrecord的FeatureMap和FeatureEncoder完善,可以方便用于实际的大规模训练
|
||||
11
codes/funrec/layers/__init__.py
Normal file
11
codes/funrec/layers/__init__.py
Normal file
@@ -0,0 +1,11 @@
|
||||
from .core import DNN
|
||||
from .core import CosinSimilarity
|
||||
from .core import PredictLayer
|
||||
from .utils import NoMask
|
||||
from .sequence import PoolingLayer
|
||||
from .interaction import FM
|
||||
from .interaction import InnerProduct
|
||||
from .interaction import OuterProduct
|
||||
from .interaction import SENetLayer
|
||||
from .interaction import BilinearInteractionLayer
|
||||
from .interaction import SelfAttentionInteraction
|
||||
135
codes/funrec/layers/core.py
Normal file
135
codes/funrec/layers/core.py
Normal file
@@ -0,0 +1,135 @@
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import Layer, Dense, Activation, Dropout, \
|
||||
BatchNormalization
|
||||
from tensorflow.keras.initializers import Zeros
|
||||
|
||||
|
||||
class DNN(Layer):
|
||||
def __init__(self, hidden_unit, activation='relu', use_bias=True,
|
||||
use_dp=True, dropout_rate=0.2, use_bn=True, after_bn=False,
|
||||
get_logits=False, **kwargs):
|
||||
"""初始化DNN
|
||||
get_logits=True, 返回logits
|
||||
"""
|
||||
super().__init__(**kwargs)
|
||||
self.hidden_unit = hidden_unit
|
||||
self.activation = activation
|
||||
self.after_bn = after_bn
|
||||
self.get_logits = get_logits
|
||||
self.use_dp = use_dp
|
||||
self.use_bn = use_bn
|
||||
|
||||
self.dnn_layers = [Dense(units, activation=None, use_bias=use_bias)
|
||||
for units in self.hidden_unit]
|
||||
self.activate_layer = Activation(activation)
|
||||
if self.get_logits:
|
||||
self.last_dnn_layer = Dense(1, activation=None, use_bias=False)
|
||||
if self.use_dp:
|
||||
self.dp_layers = [Dropout(dropout_rate) for _ in
|
||||
range(len(self.hidden_unit))]
|
||||
if self.use_bn:
|
||||
self.bn_layers = [BatchNormalization() for _ in
|
||||
range(len(self.hidden_unit))]
|
||||
|
||||
def call(self, x):
|
||||
for i in range(len(self.hidden_unit)):
|
||||
x = self.dnn_layers[i](x)
|
||||
if self.use_bn:
|
||||
if not self.after_bn:
|
||||
x = self.activate_layer(x)
|
||||
x = self.bn_layers[i](x)
|
||||
else:
|
||||
x = self.bn_layers[i](x)
|
||||
x = self.activate_layer(x)
|
||||
if self.use_dp:
|
||||
x = self.dp_layers[i](x)
|
||||
# 最后一层dnn的输出单独处理
|
||||
if self.get_logits:
|
||||
x = self.last_dnn_layer(x)
|
||||
return x
|
||||
|
||||
|
||||
class CosinSimilarity(Layer):
|
||||
def __init__(self, temperature=1, axis=-1, **kwargs):
|
||||
super(CosinSimilarity, self).__init__(**kwargs)
|
||||
self.temperature = temperature
|
||||
self.axis = axis
|
||||
self.type = type
|
||||
|
||||
def build(self, input_shape):
|
||||
return super().build(input_shape)
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
"""inputs 是一个列表"""
|
||||
query, candidate = inputs
|
||||
# 计算两个向量的二范数
|
||||
query_norm = tf.norm(query, axis=self.axis) # (B, 1)
|
||||
candidate_norm = tf.norm(candidate, axis=self.axis)
|
||||
# 计算相似度
|
||||
scores = tf.reduce_sum(tf.multiply(query, candidate), axis=-1)#(B,1)
|
||||
# 相似度除以二范数, 防止除零
|
||||
scores = tf.divide(scores, query_norm * candidate_norm + 1e-8)
|
||||
# 对score的范围限制到(-1, 1)之间
|
||||
scores = tf.clip_by_value(scores, -1, 1)
|
||||
# 乘以温度系数
|
||||
score = scores * self.temperature
|
||||
return score
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return (None, 1)
|
||||
|
||||
def get_config(self):
|
||||
config = {'temperature': self.temperature, 'axis':self.axis}
|
||||
base_config = super(CosinSimilarity, self).get_config()
|
||||
return dict(list(config.items() + base_config.items()))
|
||||
|
||||
|
||||
class PredictLayer(Layer):
|
||||
"""模型的任务分类
|
||||
# TODO 后续需要将其他任务的形式都考虑进来
|
||||
二分类
|
||||
多分类 sampled_softmax
|
||||
回归
|
||||
多任务
|
||||
"""
|
||||
def __init__(self, task='binary', use_bias=False, **kwargs):
|
||||
if task not in ["binary", "multiclass", "regression"]:
|
||||
raise ValueError("task must be binary,multiclass or regression")
|
||||
self.task = task
|
||||
self.use_bias = use_bias
|
||||
super(PredictLayer, self).__init__(**kwargs)
|
||||
|
||||
def build(self, input_shape):
|
||||
|
||||
if self.use_bias:
|
||||
self.global_bias = self.add_weight(
|
||||
shape=(1,), initializer=Zeros(), name="global_bias")
|
||||
|
||||
# Be sure to call this somewhere!
|
||||
super(PredictLayer, self).build(input_shape)
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
x = inputs
|
||||
if self.use_bias:
|
||||
x = tf.nn.bias_add(x, self.global_bias, data_format='NC')
|
||||
if self.task == "binary":
|
||||
x = tf.sigmoid(x)
|
||||
|
||||
output = tf.reshape(x, (-1, 1))
|
||||
|
||||
return output
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return (None, 1)
|
||||
|
||||
def get_config(self, ):
|
||||
config = {'task': self.task, 'use_bias': self.use_bias}
|
||||
base_config = super(PredictLayer, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
|
||||
# TODO Activation
|
||||
|
||||
|
||||
# TODO Normalization
|
||||
|
||||
355
codes/funrec/layers/interaction.py
Normal file
355
codes/funrec/layers/interaction.py
Normal file
@@ -0,0 +1,355 @@
|
||||
import itertools
|
||||
from re import L
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import Layer, Concatenate
|
||||
from tensorflow.keras.initializers import TruncatedNormal, glorot_normal
|
||||
|
||||
|
||||
class FM(Layer):
|
||||
"""显示特征交叉,直接按照优化后的公式实现即可
|
||||
注意:
|
||||
1. 传入进来的参数看起来是一个Embedding权重,没有像公式中出现的特征,那是因
|
||||
为,输入的id特征本质上都是onehot编码,取出对应的embedding就等价于特征乘以
|
||||
权重。所以后续的操作直接就是对特征进行操作
|
||||
2. 在实现过程中,对于公式中的平方的和与和的平方两部分,需要留意是在哪个维度
|
||||
上计算,这样就可以轻松实现FM特征交叉模块
|
||||
"""
|
||||
def __init__(self, **kwargs):
|
||||
super(FM, self).__init__(**kwargs)
|
||||
|
||||
def build(self, input_shape):
|
||||
if not isinstance(input_shape, list) or len(input_shape) < 2:
|
||||
raise ValueError('`FM` layer should be called \
|
||||
on a list of at least 2 inputs')
|
||||
super(FM, self).build(input_shape) # Be sure to call this somewhere!
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
"""
|
||||
inputs: 是一个列表,列表中每个元素的维度为:(None, 1, emb_dim), 列表长度
|
||||
为field_num
|
||||
"""
|
||||
concated_embeds_value = Concatenate(axis=1)(inputs) #(None,field_num,emb_dim)
|
||||
square_of_sum = tf.square(tf.reduce_sum(
|
||||
concated_embeds_value, axis=1, keepdims=True)) # (None, 1, emb_dim)
|
||||
sum_of_square = tf.reduce_sum(
|
||||
concated_embeds_value * concated_embeds_value,
|
||||
axis=1, keepdims=True) # (None, 1, emb_dim)
|
||||
cross_term = square_of_sum - sum_of_square
|
||||
cross_term = 0.5 * tf.reduce_sum(cross_term, axis=2, keepdims=False)#(None,1)
|
||||
return cross_term
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return (None, 1)
|
||||
|
||||
def get_config(self):
|
||||
return super().get_config()
|
||||
|
||||
|
||||
class InnerProduct(Layer):
|
||||
def __init__(self, use_mat_dot=False, units=128, **kwargs):
|
||||
super(InnerProduct, self).__init__(**kwargs)
|
||||
self.use_mat_dot = use_mat_dot
|
||||
self.units = units
|
||||
|
||||
def build(self, input_shape):
|
||||
if not isinstance(input_shape, list) or len(input_shape) < 2:
|
||||
raise ValueError('`InnerProduct` layer should be called \
|
||||
on a list of at least 2 inputs')
|
||||
|
||||
if self.use_mat_dot:
|
||||
self.field_size = len(input_shape)
|
||||
self.embedding_size = input_shape[0].as_list()[-1]
|
||||
# 未优化时的矩阵大小为:D x N x N
|
||||
# 优化后的内积权重大小为:D x N
|
||||
self.inner_w = self.add_weight(name='inner_w', shape=(self.units,
|
||||
self.field_size), initializer='glorot_normal')
|
||||
|
||||
super(InnerProduct, self).build(input_shape)
|
||||
|
||||
def call(self, inputs):
|
||||
"""inputs: 是一个长度为field_size的列表,其中每个元素的形状为:
|
||||
(None, 1, embedding_size)
|
||||
"""
|
||||
# 和原论文中一样使用可学习的权重矩阵与交叉特征做矩阵内积
|
||||
if self.use_mat_dot:
|
||||
concat_embed = Concatenate(axis=1)(inputs) # (None, feild_size, embedding_size)
|
||||
lp_list = []
|
||||
for i in range(self.units):
|
||||
# 相当于给每一个特征向量都乘以一个权重
|
||||
# self.inner_w[i] : (feild_size, ) 添加一个维度变成 (feild_size, 1)
|
||||
# delta = (None, feild_size, embedding_size)
|
||||
delta = tf.multiply(concat_embed, tf.expand_dims(self.inner_w[i], axis=1))
|
||||
# 在特征之间的维度上求和
|
||||
delta = tf.reduce_sum(delta, axis=1) # (None, embedding_size)
|
||||
# 最终在特征embedding维度上求二范数得到p
|
||||
lp_list.append(tf.reduce_sum(tf.square(delta), axis=-1, keepdims=True))
|
||||
lp = Concatenate(axis=1)(lp_list) # (None, units)
|
||||
return lp
|
||||
else:
|
||||
# 直接将特征两两做内积,最后展开
|
||||
row_list, col_list = [], []
|
||||
for i in range(len(inputs) - 1):
|
||||
for j in range(i + 1, len(inputs)):
|
||||
row_list.append(i)
|
||||
col_list.append(j)
|
||||
# pair_num = field_size * (field_size - 1) / 2
|
||||
p = tf.concat([inputs[idx] for idx in row_list], axis=1)
|
||||
q = tf.concat([inputs[idx] for idx in col_list], axis=1)
|
||||
lp = tf.reduce_sum(p * q, axis=-1, keepdims=False) # (None, pair_num)
|
||||
return lp
|
||||
|
||||
|
||||
class OuterProduct(Layer):
|
||||
def __init__(self, use_mat_dot=True, units=128, **kwargs):
|
||||
super(OuterProduct, self).__init__(**kwargs)
|
||||
self.use_mat_dot = use_mat_dot
|
||||
self.units = units
|
||||
|
||||
def build(self, input_shape):
|
||||
if not isinstance(input_shape, list) or len(input_shape) < 2:
|
||||
raise ValueError('`OuterProduct` layer should be called \
|
||||
on a list of at least 2 inputs')
|
||||
|
||||
self.field_size = len(input_shape)
|
||||
self.embedding_size = input_shape[0].as_list()[-1]
|
||||
# 优化之后的外积权重大小为:D x embed_dim x embed_dim,
|
||||
# 因为计算外积的时候在特征维度通过求和的方式进行了压缩
|
||||
self.outer_w = self.add_weight(name='outer_w', shape=(self.units,
|
||||
self.embedding_size, self.embedding_size), initializer='glorot_normal')
|
||||
|
||||
def call(self, inputs):
|
||||
"""inputs: 是一个长度为field_size的列表,其中每个元素的形状为:
|
||||
(None, 1, embedding_size)
|
||||
"""
|
||||
concat_embed = Concatenate(axis=1)(inputs) # (None, field_size, embedding_size)
|
||||
# 外积的优化是将embedding矩阵,在特征间的维度上通过求和进行压缩
|
||||
feat_sum = tf.reduce_sum(concat_embed, axis=1) # (None, embedding_size)
|
||||
# 为了方便计算外积,将维度进行扩展
|
||||
f1 = tf.expand_dims(feat_sum, axis=2) # (None, embedding_size, 1)
|
||||
f2 = tf.expand_dims(feat_sum, axis=1) # (None, 1, embedding_size)
|
||||
# 求外积 a * a^T
|
||||
product = tf.matmul(f1, f2) # (None, embedding_size, embedding_size)
|
||||
lp_list = []
|
||||
# 将product与外积权重矩阵对应元素相乘再相加
|
||||
for i in range(self.units):
|
||||
lpi = tf.multiply(product, self.outer_w[i]) # (None, embedding_size, embedding_size)
|
||||
# 将后面两个维度进行求和,需要注意的是,每使用一次reduce_sum就会减少一个维度
|
||||
lpi = tf.reduce_sum(lpi, axis=[1, 2]) # (None,)
|
||||
# 添加一个维度便于特征拼接
|
||||
lpi = tf.expand_dims(lpi, axis=1) # (None, 1)
|
||||
lp_list.append(lpi)
|
||||
# 将所有交叉特征拼接到一起
|
||||
lp = Concatenate(axis=1)(lp_list) # (None, self.units)
|
||||
return lp
|
||||
|
||||
|
||||
class SelfAttentionInteraction(Layer):
|
||||
def __init__(self, att_embedding_size=8, use_res=True, head_num=2,
|
||||
seed=1024, **kwargs):
|
||||
super(SelfAttentionInteraction, self).__init__(**kwargs)
|
||||
self.att_embedding_size = 8
|
||||
self.head_num = head_num
|
||||
self.seed = seed
|
||||
self.use_res = use_res
|
||||
|
||||
def build(self, input_shape):
|
||||
if not isinstance(input_shape, list) or len(input_shape) < 2:
|
||||
raise ValueError('`OuterProduct` layer should be called \
|
||||
on a list of at least 2 inputs')
|
||||
|
||||
embedding_size = input_shape[0].as_list()[-1]
|
||||
# 定义三个可学习的矩阵(W_Q, W_K, W_V)
|
||||
self.W_Q = self.add_weight(name="query", shape=[embedding_size,
|
||||
self.att_embedding_size * self.head_num], dtype=tf.float32,
|
||||
initializer=TruncatedNormal(self.seed))
|
||||
self.W_K = self.add_weight(name="key", shape=[embedding_size,
|
||||
self.att_embedding_size * self.head_num], dtype=tf.float32,
|
||||
initializer=TruncatedNormal(self.seed))
|
||||
self.W_V = self.add_weight(name="value", shape=[embedding_size,
|
||||
self.att_embedding_size * self.head_num], dtype=tf.float32,
|
||||
initializer=TruncatedNormal(self.seed))
|
||||
|
||||
# 残差映射权重矩阵
|
||||
if self.use_res:
|
||||
self.W_Res = self.add_weight(name="res", shape=[embedding_size,
|
||||
self.att_embedding_size * self.head_num], dtype=tf.float32,
|
||||
initializer=TruncatedNormal(self.seed))
|
||||
return super().build(input_shape)
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
"""inputs: 是一个长度为field_size的列表,其中每个元素的形状为:
|
||||
(None, 1, embedding_size)
|
||||
"""
|
||||
# 原始输入分别与三个权重矩阵相乘
|
||||
# inputs的最后一个维度与矩阵的第一个维度相乘
|
||||
inputs = Concatenate(axis=1)(inputs)
|
||||
# querys:(None, field_size, att_embedding_size*head_num)
|
||||
querys = tf.tensordot(inputs, self.W_Q, axes=(-1, 0))
|
||||
keys = tf.tensordot(inputs, self.W_K, axes=(-1, 0))
|
||||
values = tf.tensordot(inputs, self.W_V, axes=(-1, 0))
|
||||
|
||||
# 将每个注意力头分开,方便对单个注意力头的输出进行处理
|
||||
# stack默认是在第0个维度去堆叠
|
||||
# querys:(head_num, None, field_size, att_embedding_size)
|
||||
querys = tf.stack(tf.split(querys, self.head_num, axis=-1))
|
||||
keys = tf.stack(tf.split(keys, self.head_num, axis=-1))
|
||||
values = tf.stack(tf.split(values, self.head_num, axis=-1))
|
||||
|
||||
# 计算注意力权重
|
||||
# 先计算内积,transpose_b=True指的是在计算矩阵相乘时,将keys转置(key的最后
|
||||
# 两维换了位置)
|
||||
# 内积矩阵:(head_num, None, field_size, field_size)
|
||||
inner_product = tf.matmul(querys, keys, transpose_b=True)
|
||||
# att_scores: (head_num, None, field_size, 1)
|
||||
att_scores = tf.nn.softmax(inner_product, axis=-1)
|
||||
|
||||
# att_output: (head_num, None, field_size, att_embedding_size)
|
||||
att_output = tf.matmul(att_scores, values)
|
||||
# 将多头注意力分开用于拼接
|
||||
# tf.split默认在第0个维度切分
|
||||
# att_output: (1, None, field_size, att_embedding_size*head_num)
|
||||
att_output = tf.concat(tf.split(att_output, self.head_num), axis=-1)
|
||||
# att_output: (None, field_size, att_embedding_size*head_num)
|
||||
att_output = tf.squeeze(att_output, axis=0)
|
||||
|
||||
if self.use_res:
|
||||
att_output += tf.tensordot(inputs, self.W_Res, axes=(-1, 0))
|
||||
att_out = tf.nn.relu(att_output)
|
||||
return att_out
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return (None, len(input_shape), self.att_embedding_size * self.head_num)
|
||||
|
||||
def get_config(self):
|
||||
config = {'att_embedding_size': self.att_embedding_size,
|
||||
'head_num': self.head_num, 'use_res': self.use_res, 'seed': self.seed}
|
||||
base_config = super(SelfAttentionInteraction, self).get_config()
|
||||
base_config.update(config)
|
||||
return base_config
|
||||
|
||||
|
||||
class SENetLayer(Layer):
|
||||
def __init__(self, reduction_ratio=3, seed=1024, **kwargs):
|
||||
super(SENetLayer, self).__init__(**kwargs)
|
||||
self.reduction_ratio = reduction_ratio
|
||||
self.seed = seed
|
||||
|
||||
def build(self, input_shape):
|
||||
if not isinstance(input_shape, list) or len(input_shape) < 2:
|
||||
raise ValueError('`SENetLayer` layer should be called \
|
||||
on a list of at least 2 inputs')
|
||||
|
||||
self.field_size = len(input_shape)
|
||||
self.embedding_size = input_shape[0].as_list()[-1]
|
||||
reduction_size = max(1, int(self.field_size // self.reduction_ratio))
|
||||
|
||||
# 定义两个全连接层
|
||||
self.W_1 = self.add_weight(name="W_1", shape=(self.field_size,
|
||||
reduction_size), initializer=glorot_normal(self.seed))
|
||||
self.W_2 = self.add_weight(name="W_2", shape=(reduction_size,
|
||||
self.field_size), initializer=glorot_normal(self.seed))
|
||||
return super().build(input_shape)
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
"""inputs: 是一个长度为field_size的列表,其中每个元素的形状为:
|
||||
(None, 1, embedding_size)
|
||||
"""
|
||||
inputs = Concatenate(axis=1)(inputs) # (None, field_size, embedding_size)
|
||||
x = tf.reduce_mean(inputs, axis=-1) # (None, field_size)
|
||||
|
||||
# (None, field_size) * (field_size, reduction_size) =
|
||||
# (None, reduction_size)
|
||||
A_1 = tf.tensordot(x, self.W_1, axes=(-1, 0))
|
||||
A_1 = tf.nn.relu(A_1)
|
||||
# (None, reduction_size) * (reduction_size, field_size) =
|
||||
# (None, field_size)
|
||||
A_2 = tf.tensordot(A_1, self.W_2, axes=(-1, 0))
|
||||
A_2 = tf.nn.relu(A_2)
|
||||
A_2 = tf.expand_dims(A_2, axis=2) # (None, field_size, 1)
|
||||
|
||||
res = tf.multiply(inputs, A_2) #(None, field_size, embedding_size)
|
||||
# 切分成数组,方便后续特征交叉
|
||||
res = tf.split(res, self.field_size, axis=1)
|
||||
return res
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return input_shape
|
||||
|
||||
def get_config(self):
|
||||
config = {"reduction_ratio": self.reduction_ratio, "seed": self.seed}
|
||||
base_config = super(SENetLayer, self).get_config()
|
||||
base_config.update(config)
|
||||
return base_config
|
||||
|
||||
|
||||
class BilinearInteractionLayer(Layer):
|
||||
def __init__(self, bilinear_type="interaction", seed=1024, **kwargs):
|
||||
super(BilinearInteractionLayer, self).__init__(**kwargs)
|
||||
self.bilinear_type = bilinear_type
|
||||
self.seed = seed
|
||||
|
||||
def build(self, input_shape):
|
||||
if not isinstance(input_shape, list) or len(input_shape) < 2:
|
||||
raise ValueError('`OuterProduct` layer should be called \
|
||||
on a list of at least 2 inputs')
|
||||
|
||||
embedding_size = input_shape[0].as_list()[-1]
|
||||
field_size = len(input_shape)
|
||||
|
||||
# 所有交叉特征共享一个交叉矩阵
|
||||
if self.bilinear_type == 'all':
|
||||
self.W = self.add_weight(name='bilinear_weight',
|
||||
shape=(embedding_size, embedding_size),
|
||||
initializer=glorot_normal(self.seed))
|
||||
# 每个特征使用一个交叉矩阵
|
||||
elif self.bilinear_type == "each":
|
||||
self.W_list = [self.add_weight(name='bilinear_weight_'+str(i),
|
||||
shape=(embedding_size, embedding_size),
|
||||
initializer=glorot_normal(self.seed)) for i in range(field_size)]
|
||||
# 每组交叉特征使用一个交叉矩阵
|
||||
elif self.bilinear_type == 'interaction':
|
||||
self.W_list = [self.add_weight(name='bilinear_weight_'+str(i)+"_"+str(j),
|
||||
shape=(embedding_size, embedding_size),
|
||||
initializer=glorot_normal(self.seed))
|
||||
for i,j in itertools.combinations(range(field_size), 2)]
|
||||
else:
|
||||
raise NotImplementedError
|
||||
return super().build(input_shape)
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
"""inputs: 是一个长度为field_size的列表,其中每个元素的形状为:
|
||||
(None, 1, embedding_size)
|
||||
"""
|
||||
if self.bilinear_type == 'all':
|
||||
# 计算点积, 遍历所有的特征分别与交叉矩阵计算内积
|
||||
# inputs[i]: (None, 1, embedding_size)
|
||||
vdotw_list = [tf.tensordot(inputs[i], self.W, axes=(-1,0))
|
||||
for i in range(len(inputs))]
|
||||
# 计算哈达玛积,遍历两两特征组合,计算哈达玛积
|
||||
p = [tf.multiply(vdotw_list[i], inputs[j]) for i, j in
|
||||
itertools.combinations(range(len(inputs)), 2)]
|
||||
elif self.bilinear_type == 'each':
|
||||
# 每个特征都有一个交叉矩阵,self.W_list[i]
|
||||
vdotw_list = [tf.tensordot(inputs[i], self.W_list[i],
|
||||
axes=(-1,0)) for i in range(len(inputs))]
|
||||
p = [tf.multiply(vdotw_list[i], inputs[j]) for i, j in
|
||||
itertools.combinations(range(len(inputs)), 2)]
|
||||
elif self.bilinear_type == 'interaction':
|
||||
p = [tf.multiply(tf.tensordot(inputs[v[0]], w, axes=(-1, 0)), inputs[v[1]]) for v, w in
|
||||
zip(itertools.combinations(range(len(inputs)), 2), self.W_list)]
|
||||
else:
|
||||
raise NotImplementedError
|
||||
# (None, field_size * (field_size - 1) / 2, embedding_size)
|
||||
output = tf.concat(p, axis=1)
|
||||
return output
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
field_size = input_shape[1]
|
||||
embedding_size = input_shape[2]
|
||||
return (None, int(field_size * (field_size - 1) // 2), embedding_size)
|
||||
|
||||
def get_config(self):
|
||||
config = {"bilinear_type": self.bilinear_type, "seed": self.seed}
|
||||
base_config = super(BilinearInteractionLayer, self).get_config()
|
||||
base_config.update(config)
|
||||
return base_config
|
||||
7
codes/funrec/layers/sequence.py
Normal file
7
codes/funrec/layers/sequence.py
Normal file
@@ -0,0 +1,7 @@
|
||||
from tensorflow.keras.layers import Layer
|
||||
|
||||
# TODO
|
||||
class PoolingLayer(Layer):
|
||||
def __init__(self, trainable=True, name=None, dtype=None, dynamic=False, **kwargs):
|
||||
super().__init__(trainable, name, dtype, dynamic, **kwargs)
|
||||
pass
|
||||
17
codes/funrec/layers/utils.py
Normal file
17
codes/funrec/layers/utils.py
Normal file
@@ -0,0 +1,17 @@
|
||||
import tensorflow as tf
|
||||
|
||||
|
||||
class NoMask(tf.keras.layers.Layer):
|
||||
def __init__(self, **kwargs):
|
||||
super(NoMask, self).__init__(**kwargs)
|
||||
|
||||
def build(self, input_shape):
|
||||
# Be sure to call this somewhere!
|
||||
super(NoMask, self).build(input_shape)
|
||||
|
||||
def call(self, x, mask=None, **kwargs):
|
||||
return x
|
||||
|
||||
def compute_mask(self, inputs, mask):
|
||||
return None
|
||||
|
||||
1
codes/funrec/metrics.py
Normal file
1
codes/funrec/metrics.py
Normal file
@@ -0,0 +1 @@
|
||||
# TODO 将召回排序常用的指标汇总
|
||||
5
codes/funrec/models/__init__.py
Normal file
5
codes/funrec/models/__init__.py
Normal file
@@ -0,0 +1,5 @@
|
||||
from .matching.dssm import DSSM
|
||||
from .ranking.deepfm import DeepFM
|
||||
from .ranking.pnn import PNN
|
||||
from .ranking.autoint import AutoInt
|
||||
from .ranking.fibinet import FiBiNet
|
||||
1
codes/funrec/models/matching/__init__.py
Normal file
1
codes/funrec/models/matching/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .dssm import DSSM
|
||||
71
codes/funrec/models/matching/dssm.py
Normal file
71
codes/funrec/models/matching/dssm.py
Normal file
@@ -0,0 +1,71 @@
|
||||
from tensorflow.keras.models import Model
|
||||
from tensorflow.keras.layers import Flatten, Concatenate
|
||||
from features import FeatureEncoder
|
||||
from layers import DNN, CosinSimilarity, PredictLayer
|
||||
|
||||
|
||||
def process_feature(user_feature_columns, item_feature_columns, feature_encode):
|
||||
"""
|
||||
根据FeatureEncoder获取所有输入的Input层或者Embedding层,然后根据自己
|
||||
实际场景的业务数据,对不同的特征进行处理.
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_index_dict['user_id'], embedding_dim=4),
|
||||
SparseFeat('gender', feature_max_index_dict['gender'], embedding_dim=4),
|
||||
SparseFeat('occupation', feature_max_index_dict['occupation'], embedding_dim=4),
|
||||
SparseFeat('zip', feature_max_index_dict['zip'], embedding_dim=4),
|
||||
VarLenSparseFeat(SparseFeat('hist_movie_id', feature_max_idx['movie_id'], embedding_dim,
|
||||
embedding_name="movie_id"), SEQ_LEN, 'mean', 'hist_len'),
|
||||
]
|
||||
item_feature_columns = [SparseFeat('movie_id', feature_max_index_dict['movie_id'], embedding_dim=4)]
|
||||
"""
|
||||
group_embedding_dict = feature_encode.sparse_feature_dict
|
||||
|
||||
user_emb_name = [fc.embedding_name for fc in user_feature_columns]
|
||||
item_emb_name = [fc.embedding_name for fc in item_feature_columns]
|
||||
|
||||
user_dnn_input = [v for k, v in group_embedding_dict['default_group'].items()
|
||||
if k in user_emb_name]
|
||||
item_dnn_input = [v for k, v in group_embedding_dict['default_group'].items()
|
||||
if k in item_emb_name]
|
||||
|
||||
return user_dnn_input, item_dnn_input
|
||||
|
||||
|
||||
def DSSM(user_feature_columns, item_feature_columns, dnn_units=[64, 32],
|
||||
temp=10, task='binary'):
|
||||
# 构建所有特征的Input层和Embedding层
|
||||
feature_encode = FeatureEncoder(user_feature_columns + item_feature_columns)
|
||||
feature_input_layers_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
|
||||
# 特征处理
|
||||
user_dnn_input, item_dnn_input = process_feature(user_feature_columns,\
|
||||
item_feature_columns, feature_encode)
|
||||
|
||||
# 构建模型的核心层
|
||||
if len(user_dnn_input) >= 2:
|
||||
user_dnn_input = Concatenate(axis=1)(user_dnn_input)
|
||||
else:
|
||||
user_dnn_input = user_dnn_input[0]
|
||||
if len(item_dnn_input) >= 2:
|
||||
item_dnn_input = Concatenate(axis=1)(item_dnn_input)
|
||||
else:
|
||||
item_dnn_input = item_dnn_input[0]
|
||||
|
||||
user_dnn_input = Flatten()(user_dnn_input)
|
||||
item_dnn_input = Flatten()(item_dnn_input)
|
||||
|
||||
user_dnn_out = DNN(dnn_units)(user_dnn_input)
|
||||
item_dnn_out = DNN(dnn_units)(item_dnn_input)
|
||||
|
||||
# 计算相似度
|
||||
scores = CosinSimilarity(temp)([user_dnn_out, item_dnn_out]) # (B,1)
|
||||
|
||||
# 确定拟合目标
|
||||
output = PredictLayer()(scores)
|
||||
|
||||
# 根据输入输出构建模型
|
||||
model = Model(feature_input_layers_list, output)
|
||||
# model.summary()
|
||||
|
||||
return model
|
||||
|
||||
62
codes/funrec/models/ranking/autoint.py
Normal file
62
codes/funrec/models/ranking/autoint.py
Normal file
@@ -0,0 +1,62 @@
|
||||
from audioop import bias
|
||||
from itertools import chain
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.models import Model
|
||||
from tensorflow.keras.layers import Flatten, Concatenate, Dense, Reshape
|
||||
from features import FeatureEncoder
|
||||
from layers import DNN, SelfAttentionInteraction
|
||||
from layers.core import PredictLayer
|
||||
|
||||
|
||||
def process_feature(linear_feature_columns, dnn_feature_columns, feature_encode):
|
||||
"""
|
||||
根据FeatureEncoder获取所有输入的Input层或者Embedding层,然后根据自己
|
||||
实际场景的业务数据,对不同的特征进行处理.
|
||||
"""
|
||||
linear_input_sparse_dict = feature_encode.linear_sparse_feature_dict
|
||||
group_embedding_dict = feature_encode.sparse_feature_dict
|
||||
|
||||
linear_input_sparse_list = list(linear_input_sparse_dict['default_group'].values())
|
||||
linear_dense_dict = feature_encode.dense_feature_dict
|
||||
linear_dense_list = list(linear_dense_dict.values())
|
||||
|
||||
dnn_emb_name = [fc.embedding_name for fc in dnn_feature_columns]
|
||||
embedding_list = [v for k, v in group_embedding_dict['pnn'].items()
|
||||
if k in dnn_emb_name]
|
||||
|
||||
linear_sparse_inputs = Flatten()(Concatenate(axis=1)(linear_input_sparse_list))
|
||||
linear_dense_list.append(linear_sparse_inputs)
|
||||
linear_inputs = []
|
||||
if len(linear_dense_list) == 2:
|
||||
linear_inputs = Concatenate(axis=-1)(linear_dense_list)
|
||||
else:
|
||||
linear_inputs = linear_dense_list[0]
|
||||
|
||||
return linear_inputs, embedding_list
|
||||
|
||||
|
||||
def AutoInt(linear_feature_columns, dnn_feature_columns, hidden_units=(32, 16, 1),
|
||||
att_embedding_size=8, use_res=True, head_num=2, activation='relu',
|
||||
use_bias=True, dp_rate=0.2, use_bn=True, use_dp=True, task='binary'):
|
||||
|
||||
feature_columns = list(set(linear_feature_columns + dnn_feature_columns))
|
||||
feature_encode = FeatureEncoder(feature_columns,
|
||||
linear_sparse_feature=linear_feature_columns)
|
||||
feature_input_layers_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
|
||||
# 特征处理
|
||||
linear_inputs, embedding_list = \
|
||||
process_feature(linear_feature_columns, dnn_feature_columns, feature_encode)
|
||||
|
||||
interaction_inputs = SelfAttentionInteraction(att_embedding_size,
|
||||
use_res, head_num)(embedding_list)
|
||||
interaction_inputs = Flatten()(interaction_inputs)
|
||||
|
||||
dnn_inputs = Concatenate(axis=-1)([linear_inputs, interaction_inputs])
|
||||
|
||||
logits = DNN(hidden_units, activation, use_bias, use_dp, dp_rate, dp_rate,
|
||||
use_bn, get_logits=True)(dnn_inputs)
|
||||
|
||||
output = PredictLayer(task)(logits)
|
||||
model = Model(feature_input_layers_list, output)
|
||||
return model
|
||||
54
codes/funrec/models/ranking/deepfm.py
Normal file
54
codes/funrec/models/ranking/deepfm.py
Normal file
@@ -0,0 +1,54 @@
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.models import Model
|
||||
from tensorflow.keras.layers import Flatten, Concatenate, Dense
|
||||
from features import FeatureEncoder, get_linear_logits
|
||||
from layers import FM, DNN, PredictLayer
|
||||
|
||||
|
||||
def process_feature(linear_feature_columns, dnn_feature_columns, feature_encode):
|
||||
"""
|
||||
根据FeatureEncoder获取所有输入的Input层或者Embedding层,然后根据自己
|
||||
实际场景的业务数据,对不同的特征进行处理.
|
||||
"""
|
||||
linear_input_sparse_dict = feature_encode.linear_sparse_feature_dict
|
||||
group_embedding_dict = feature_encode.sparse_feature_dict
|
||||
|
||||
linear_input_sparse_list = list(linear_input_sparse_dict['default_group'].values())
|
||||
linear_dense_dict = feature_encode.dense_feature_dict
|
||||
linear_dense_list = list(linear_dense_dict.values())
|
||||
|
||||
dnn_emb_name = [fc.embedding_name for fc in dnn_feature_columns]
|
||||
dnn_input_list = [v for k, v in group_embedding_dict['fm'].items()
|
||||
if k in dnn_emb_name]
|
||||
|
||||
return linear_dense_list, linear_input_sparse_list, dnn_input_list
|
||||
|
||||
|
||||
def DeepFM(linear_feature_columns, dnn_feature_columns, hidden_units=(32, 16, 1),
|
||||
activation='relu', use_bias=True, dp_rate=0.2, use_bn=True, use_dp=True,
|
||||
task='binary'):
|
||||
# 构建所有特征的Input层和Embedding层
|
||||
# 因为有些特征可能在linear层和dnn层会重复了
|
||||
feature_columns = list(set(linear_feature_columns + dnn_feature_columns))
|
||||
feature_encode = FeatureEncoder(feature_columns,
|
||||
linear_sparse_feature=linear_feature_columns)
|
||||
feature_input_layers_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
|
||||
# 特征处理
|
||||
linear_dense_list, linear_input_sparse_list, dnn_input_list = \
|
||||
process_feature(linear_feature_columns, dnn_feature_columns, feature_encode)
|
||||
|
||||
fm_logits = FM()(dnn_input_list)
|
||||
linear_logits = get_linear_logits(linear_dense_list, linear_input_sparse_list)
|
||||
|
||||
dnn_inputs = Flatten()(Concatenate(axis=1)(dnn_input_list))
|
||||
dnn_logits = DNN(hidden_units, activation, use_bias, use_dp, dp_rate, dp_rate,
|
||||
use_bn, get_logits=True)(dnn_inputs)
|
||||
|
||||
logits = linear_logits + fm_logits + dnn_logits
|
||||
output = PredictLayer(task)(logits)
|
||||
model = Model(feature_input_layers_list, output)
|
||||
|
||||
return model
|
||||
|
||||
|
||||
67
codes/funrec/models/ranking/fibinet.py
Normal file
67
codes/funrec/models/ranking/fibinet.py
Normal file
@@ -0,0 +1,67 @@
|
||||
from audioop import bias
|
||||
from itertools import chain
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.models import Model
|
||||
from tensorflow.keras.layers import Flatten, Concatenate, Dense, Reshape
|
||||
from features import FeatureEncoder
|
||||
from layers import DNN, SENetLayer, BilinearInteractionLayer
|
||||
from layers.core import PredictLayer
|
||||
|
||||
|
||||
def process_feature(linear_feature_columns, dnn_feature_columns, feature_encode):
|
||||
"""
|
||||
根据FeatureEncoder获取所有输入的Input层或者Embedding层,然后根据自己
|
||||
实际场景的业务数据,对不同的特征进行处理.
|
||||
"""
|
||||
linear_input_sparse_dict = feature_encode.linear_sparse_feature_dict
|
||||
group_embedding_dict = feature_encode.sparse_feature_dict
|
||||
|
||||
linear_input_sparse_list = list(linear_input_sparse_dict['default_group'].values())
|
||||
linear_dense_dict = feature_encode.dense_feature_dict
|
||||
linear_dense_list = list(linear_dense_dict.values())
|
||||
|
||||
dnn_emb_name = [fc.embedding_name for fc in dnn_feature_columns]
|
||||
embedding_list = [v for k, v in group_embedding_dict['bilinear'].items()
|
||||
if k in dnn_emb_name]
|
||||
|
||||
linear_sparse_inputs = Flatten()(Concatenate(axis=1)(linear_input_sparse_list))
|
||||
linear_dense_list.append(linear_sparse_inputs)
|
||||
linear_inputs = []
|
||||
if len(linear_dense_list) == 2:
|
||||
linear_inputs = Concatenate(axis=-1)(linear_dense_list)
|
||||
else:
|
||||
linear_inputs = linear_dense_list[0]
|
||||
|
||||
return linear_inputs, embedding_list
|
||||
|
||||
|
||||
def FiBiNet(linear_feature_columns, dnn_feature_columns, hidden_units=(32, 16, 1),
|
||||
bilinear_type='interaction', activation='relu',
|
||||
use_bias=True, dp_rate=0.2, use_bn=True, use_dp=True, task='binary'):
|
||||
|
||||
feature_columns = list(set(linear_feature_columns + dnn_feature_columns))
|
||||
feature_encode = FeatureEncoder(feature_columns,
|
||||
linear_sparse_feature=linear_feature_columns)
|
||||
feature_input_layers_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
|
||||
# 特征处理
|
||||
linear_inputs, embedding_list = \
|
||||
process_feature(linear_feature_columns, dnn_feature_columns, feature_encode)
|
||||
|
||||
senet_out_embedding_list = SENetLayer()(embedding_list)
|
||||
|
||||
bilinear_out = BilinearInteractionLayer(bilinear_type)(embedding_list)
|
||||
bilinear_out_se = BilinearInteractionLayer(bilinear_type)(senet_out_embedding_list)
|
||||
|
||||
dnn_bilinear_inputs = Flatten()(bilinear_out)
|
||||
dnn_bilinear_se_inputs = Flatten()(bilinear_out_se)
|
||||
|
||||
dnn_inputs = Concatenate(axis=-1)([linear_inputs, dnn_bilinear_inputs, \
|
||||
dnn_bilinear_se_inputs])
|
||||
|
||||
logits = DNN(hidden_units, activation, use_bias, use_dp, dp_rate, dp_rate,
|
||||
use_bn, get_logits=True)(dnn_inputs)
|
||||
|
||||
output = PredictLayer(task)(logits)
|
||||
model = Model(feature_input_layers_list, output)
|
||||
return model
|
||||
84
codes/funrec/models/ranking/pnn.py
Normal file
84
codes/funrec/models/ranking/pnn.py
Normal file
@@ -0,0 +1,84 @@
|
||||
from audioop import bias
|
||||
from itertools import chain
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.models import Model
|
||||
from tensorflow.keras.layers import Flatten, Concatenate, Dense, Reshape
|
||||
from features import FeatureEncoder
|
||||
from layers import DNN, InnerProduct, OuterProduct
|
||||
from layers.core import PredictLayer
|
||||
|
||||
|
||||
def process_feature(linear_feature_columns, dnn_feature_columns, feature_encode):
|
||||
"""
|
||||
根据FeatureEncoder获取所有输入的Input层或者Embedding层,然后根据自己
|
||||
实际场景的业务数据,对不同的特征进行处理.
|
||||
"""
|
||||
linear_input_sparse_dict = feature_encode.linear_sparse_feature_dict
|
||||
group_embedding_dict = feature_encode.sparse_feature_dict
|
||||
|
||||
linear_input_sparse_list = list(linear_input_sparse_dict['default_group'].values())
|
||||
linear_dense_dict = feature_encode.dense_feature_dict
|
||||
linear_dense_list = list(linear_dense_dict.values())
|
||||
|
||||
dnn_emb_name = [fc.embedding_name for fc in dnn_feature_columns]
|
||||
embedding_list = [v for k, v in group_embedding_dict['pnn'].items()
|
||||
if k in dnn_emb_name]
|
||||
|
||||
linear_sparse_inputs = Flatten()(Concatenate(axis=1)(linear_input_sparse_list))
|
||||
linear_dense_list.append(linear_sparse_inputs)
|
||||
linear_inputs = []
|
||||
if len(linear_dense_list) == 2:
|
||||
linear_inputs = Concatenate(axis=-1)(linear_dense_list)
|
||||
else:
|
||||
linear_inputs = linear_dense_list[0]
|
||||
|
||||
return linear_inputs, embedding_list
|
||||
|
||||
|
||||
def PNN(linear_feature_columns, dnn_feature_columns, hidden_units=(32, 16, 1),
|
||||
use_inner=True, inner_units=512, outer_units=512, use_outter=True,
|
||||
use_mat_dot=False, activation='relu', use_bias=True, dp_rate=0.2, use_bn=True,
|
||||
use_dp=True, task='binary'):
|
||||
|
||||
feature_columns = list(set(linear_feature_columns + dnn_feature_columns))
|
||||
feature_encode = FeatureEncoder(feature_columns,
|
||||
linear_sparse_feature=linear_feature_columns)
|
||||
feature_input_layers_list = list(feature_encode.feature_input_layer_dict.values())
|
||||
|
||||
# 特征处理
|
||||
linear_inputs, embedding_list = \
|
||||
process_feature(linear_feature_columns, dnn_feature_columns, feature_encode)
|
||||
|
||||
# 这里本来应该对原始的embedding做矩阵内积的,但是考虑到参数量比较多,下面直接将embedding矩阵展开
|
||||
field_size = len(embedding_list)
|
||||
embedding_dim = embedding_list[0].shape[-1]
|
||||
embedding_matrix = Concatenate(axis=1)(embedding_list)
|
||||
# (None, field_size * embedding_size)
|
||||
dnn_linear_input = Reshape([field_size * embedding_dim])(embedding_matrix)
|
||||
|
||||
dnn_interaction_list = []
|
||||
if use_inner:
|
||||
dnn_inputs = InnerProduct(use_mat_dot, inner_units)(embedding_list)
|
||||
dnn_interaction_list.append(dnn_inputs)
|
||||
if use_outter:
|
||||
dnn_inputs = OuterProduct(use_mat_dot, outer_units)(embedding_list)
|
||||
dnn_interaction_list.append(dnn_inputs)
|
||||
|
||||
if len(dnn_interaction_list) == 2:
|
||||
dnn_interaction_input = Concatenate(axis=-1)(dnn_interaction_list)
|
||||
else:
|
||||
dnn_interaction_input = dnn_interaction_list[0]
|
||||
|
||||
if linear_inputs is not None:
|
||||
dnn_input_list = [linear_inputs, dnn_linear_input, dnn_interaction_input]
|
||||
else:
|
||||
dnn_input_list = [dnn_linear_input, dnn_interaction_input]
|
||||
|
||||
dnn_inputs = Flatten()(Concatenate(axis=-1)(dnn_input_list))
|
||||
|
||||
logits = DNN(hidden_units, activation, use_bias, use_dp, dp_rate, dp_rate,
|
||||
use_bn, get_logits=True)(dnn_inputs)
|
||||
|
||||
output = PredictLayer(task)(logits)
|
||||
model = Model(feature_input_layers_list, output)
|
||||
return model
|
||||
@@ -10,6 +10,9 @@ exposure_table_name_prefix = "exposure" # 用户曝光数据表的前缀
|
||||
loginfo_db_name = "loginfo" # log数据库
|
||||
loginfo_table_name_prefix = "log" # log数据表的前缀
|
||||
|
||||
contest_loginfo_db_name = "contest_loginfo"
|
||||
contest_loginfo_table_name_prefix = "contest_log"
|
||||
|
||||
# 默认配置
|
||||
mysql_username = "root"
|
||||
mysql_passwd = "123456"
|
||||
@@ -29,6 +32,8 @@ material_db_name = "NewsRecSys"
|
||||
feature_protrail_collection_name = "FeatureProtrail"
|
||||
redis_mongo_collection_name = "RedisProtrail"
|
||||
user_protrail_collection_name = "UserProtrail"
|
||||
contest_user_protrail_collection_name = "ContestUserProtrail"
|
||||
contest_feature_protrail_collection_name = "ContestFeatureProtrail"
|
||||
|
||||
# Redis
|
||||
redis_hostname = "127.0.0.1"
|
||||
|
||||
@@ -4,4 +4,9 @@ home_path = os.environ['HOME']
|
||||
proj_path = home_path + "/fun-rec/codes/news_recsys/news_rec_server/"
|
||||
|
||||
stop_words_path = proj_path + "conf/stop_words.txt"
|
||||
bad_case_news_log_path = proj_path + "logs/news_bad_cases.log"
|
||||
bad_case_news_log_path = proj_path + "logs/news_bad_cases.log"
|
||||
|
||||
root_data_path = "/home/recsys/news_data/5w_data/"
|
||||
log_data_path = root_data_path + "train_data_5w.csv"
|
||||
doc_info_path = root_data_path + "doc_info.txt"
|
||||
user_info_path = root_data_path + "user_info_data_5w.csv"
|
||||
@@ -0,0 +1,42 @@
|
||||
import sys
|
||||
sys.path.append("../../")
|
||||
import time
|
||||
from sqlalchemy import Column, String, Integer
|
||||
from sqlalchemy.ext.declarative import declarative_base
|
||||
|
||||
from dao.mysql_server import MysqlServer
|
||||
|
||||
# # 定义基类
|
||||
Base = declarative_base()
|
||||
|
||||
# 定义映射关系
|
||||
class ContestLogItem(Base):
|
||||
"""log日志数据抽象类
|
||||
"""
|
||||
# 声明是一个抽象类
|
||||
__abstract__ = True
|
||||
index = Column(Integer(), primary_key=True)
|
||||
user_id = Column(String(30))
|
||||
article_id = Column(String(100))
|
||||
net_status = Column(String(100))
|
||||
flush_nums = Column(String(100))
|
||||
expo_position = Column(String(100))
|
||||
click = Column(String(100))
|
||||
duration = Column(String(100))
|
||||
|
||||
def __init__(self):
|
||||
engine = MysqlServer().get_contest_loginfo_engine()
|
||||
Base.metadata.create_all(engine)
|
||||
|
||||
def __repr__(self):
|
||||
return "<ContestLogItem(user_id='%s', article_id='%s', net_status='%s', flush_nums='%s', \
|
||||
expo_position='%s', click='%s', duration='%s')>" % (
|
||||
self.user_id, self.article_id, self.net_status, self.flush_nums, self.expo_position, self.click, self.duration)
|
||||
|
||||
|
||||
# 通过元类实现一个新的类,因为sqlalchemy中一个类只能对应一个表
|
||||
def get_new_class(table_name):
|
||||
# 使用type创建一个新的类,类是type的实例,type称为是元类
|
||||
cls_name = 'ContestLogItem{}'.format(table_name)
|
||||
cls = type(cls_name, (ContestLogItem, ), {'__tablename__': table_name})
|
||||
return cls
|
||||
@@ -7,13 +7,18 @@ from conf.dao_config import sina_db_name, sina_collection_name_prefix
|
||||
from conf.dao_config import material_db_name, feature_protrail_collection_name
|
||||
from conf.dao_config import redis_mongo_collection_name
|
||||
from conf.dao_config import user_protrail_collection_name
|
||||
from conf.dao_config import contest_user_protrail_collection_name
|
||||
from conf.dao_config import contest_feature_protrail_collection_name
|
||||
|
||||
|
||||
class MongoServer(object):
|
||||
def __init__(self, _mongo_hostname=mongo_hostname, _mongo_port=mongo_port, _sina_db_name=sina_db_name,
|
||||
_sina_collection_name_prefix=sina_collection_name_prefix, _material_db_name=material_db_name,
|
||||
_feature_protrail_collection_name=feature_protrail_collection_name,
|
||||
_redis_mongo_collection_name=redis_mongo_collection_name,
|
||||
_user_protrail_collection_name=user_protrail_collection_name):
|
||||
_user_protrail_collection_name=user_protrail_collection_name,
|
||||
_contest_user_protrail_collection_name=contest_user_protrail_collection_name,
|
||||
_contest_feature_protrail_collection_name=contest_feature_protrail_collection_name):
|
||||
self._hostname = _mongo_hostname
|
||||
self._port = _mongo_port
|
||||
self._sina_db_name = _sina_db_name
|
||||
@@ -22,6 +27,8 @@ class MongoServer(object):
|
||||
self._feature_protrail_collection_name = _feature_protrail_collection_name
|
||||
self._redis_mongo_collection_name = _redis_mongo_collection_name
|
||||
self._user_protrail_collection_name = user_protrail_collection_name
|
||||
self._contest_user_protrail_collection_name = contest_user_protrail_collection_name
|
||||
self._contest_feature_protrail_collection_name = contest_feature_protrail_collection_name
|
||||
|
||||
self._mongo_client = self._mongodb()
|
||||
|
||||
@@ -52,3 +59,14 @@ class MongoServer(object):
|
||||
"""用户画像的数据集合
|
||||
"""
|
||||
return self._mongo_client[self._material_db_name][self._user_protrail_collection_name]
|
||||
|
||||
def get_contest_user_potrial_collection(self):
|
||||
"""获取竞赛数据中的用户画像集合
|
||||
"""
|
||||
return self._mongo_client[self._material_db_name][self._contest_user_protrail_collection_name]
|
||||
|
||||
def get_contest_feature_potrial_collection(self):
|
||||
"""获取竞赛数据中的文章画像集合
|
||||
"""
|
||||
return self._mongo_client[self._material_db_name][self._contest_feature_protrail_collection_name]
|
||||
|
||||
@@ -2,12 +2,13 @@ import sys
|
||||
sys.path.append("../")
|
||||
from sqlalchemy import create_engine
|
||||
from sqlalchemy.orm import sessionmaker
|
||||
from conf.dao_config import loginfo_db_name, user_info_db_name
|
||||
|
||||
from conf.dao_config import loginfo_db_name, user_info_db_name, contest_loginfo_db_name
|
||||
|
||||
|
||||
class MysqlServer(object):
|
||||
def __init__(self, username="root", passwd="123456", hostname="localhost", port="3306",
|
||||
user_info_db_name=user_info_db_name, loginfo_db_name=loginfo_db_name):
|
||||
def __init__(self, username="root", passwd="123456", hostname="localhost", port="3306", \
|
||||
user_info_db_name=user_info_db_name, loginfo_db_name=loginfo_db_name, \
|
||||
contest_loginfo_db_name=contest_loginfo_db_name):
|
||||
|
||||
self.username = username
|
||||
self.passwd = passwd
|
||||
@@ -15,6 +16,7 @@ class MysqlServer(object):
|
||||
self.port = port
|
||||
self.user_info_db_name = user_info_db_name
|
||||
self.loginfo_db_name = loginfo_db_name
|
||||
self.contest_loginfo_db_name = contest_loginfo_db_name
|
||||
|
||||
def session(self, db_name):
|
||||
"""链接数据库,绑定映射关系
|
||||
@@ -63,6 +65,12 @@ class MysqlServer(object):
|
||||
"""
|
||||
_, sess = self.session(self.user_info_db_name)
|
||||
return sess
|
||||
|
||||
def get_contest_loginfo_session(self):
|
||||
"""获取用户阅读的session
|
||||
"""
|
||||
_, sess = self.session(self.contest_loginfo_db_name)
|
||||
return sess
|
||||
|
||||
def get_register_user_engine(self):
|
||||
"""
|
||||
@@ -100,3 +108,8 @@ class MysqlServer(object):
|
||||
engine, _ = self.session(self.user_info_db_name)
|
||||
return engine
|
||||
|
||||
def get_contest_loginfo_engine(self):
|
||||
"""
|
||||
"""
|
||||
engine, _ = self.session(self.contest_loginfo_db_name)
|
||||
return engine
|
||||
@@ -0,0 +1,153 @@
|
||||
"""
|
||||
由于系统很难收集到大量用户的行为数据,为了后面的召回和排序可以正常进行下去
|
||||
这里将某个中文新闻推荐竞赛的数据集添加到数据库中用于后续的环节,这个脚本主
|
||||
要就是将竞赛数据集导入数据库
|
||||
"""
|
||||
import os
|
||||
import sys
|
||||
sys.path.append("../../")
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
from tqdm import tqdm
|
||||
import random
|
||||
import math
|
||||
|
||||
from dao.mongo_server import MongoServer
|
||||
from dao.mysql_server import MysqlServer
|
||||
from dao.entity.contest_logitem import ContestLogItem, get_new_class
|
||||
from conf.dao_config import contest_loginfo_table_name_prefix
|
||||
|
||||
"""
|
||||
'user_id': 用户id
|
||||
'article_id': 文章id
|
||||
'expo_time': 展现时间
|
||||
'net_status': 网络状态
|
||||
'flush_nums': 刷新次数
|
||||
'expo_position': 展示的位置
|
||||
'click': 是否点击
|
||||
'duration': 消费时长,单位是秒
|
||||
"""
|
||||
|
||||
|
||||
ROOT_PATH = '/home/recsys/news_data/5w_data/'
|
||||
|
||||
# 路径可能需要换一下
|
||||
trn_data_path = '/home/recsys/news_data/off_data/train_data.txt'
|
||||
tst_data_path = '/home/recsys/news_data//off_data/test_data.txt'
|
||||
user_info_data_path = '/home/recsys/news_data/off_data/user_info.txt'
|
||||
doc_info_data_path = '/home/recsys/news_data/off_data/doc_info.txt'
|
||||
|
||||
# 竞赛数据 采样
|
||||
def sample_train_data(trn_data_path, user_info_data_path, sample_num=100000, save_path=None, post_fix=None):
|
||||
trn_df = pd.read_csv(trn_data_path, names=['user_id', 'article_id', 'expo_time', \
|
||||
'net_status', 'flush_nums', 'expo_position', 'click', 'duration'], sep='\t')
|
||||
|
||||
# 'province':省 'city':市
|
||||
user_info_df = pd.read_csv(user_info_data_path, names=['user_id', 'device', 'os', 'province', 'city', 'age', 'gender'], sep='\t')
|
||||
|
||||
user_ids = set(trn_df['user_id'].unique())
|
||||
sample_user_ids = random.sample(user_ids, sample_num)
|
||||
sample_trn_df = trn_df[trn_df['user_id'].isin(sample_user_ids)]
|
||||
|
||||
sample_user_info_df = user_info_df[user_info_df['user_id'].isin(sample_user_ids)]
|
||||
|
||||
print("采样 {} 用户的行为日志的条数为: {} ".format(sample_num, sample_trn_df.shape[0]))
|
||||
|
||||
# 将上面采样的数据保存下来
|
||||
sample_trn_data_path = os.path.join(save_path, 'train_data_{}w.csv'.format(post_fix))
|
||||
sample_user_data_path = os.path.join(save_path, 'user_info_data_{}w.csv'.format(post_fix))
|
||||
|
||||
sample_trn_df.to_csv(sample_trn_data_path, header=True, sep='\t')
|
||||
sample_user_info_df.to_csv(sample_user_data_path, header=True, sep='\t')
|
||||
|
||||
return sample_trn_df, sample_user_info_df
|
||||
|
||||
|
||||
def load_user_info_data():
|
||||
"""导入用户画像数据
|
||||
原始的数据是存在NewsRecSys db中的 UserProtrail collection中
|
||||
现将竞赛数据的用户画像存到 NewsRecSys db中的 ContestUserProtrail collection中
|
||||
"""
|
||||
user_info_path = ROOT_PATH + 'user_info_data_5w.csv'
|
||||
columns = ['user_id', 'device', 'os', 'province', 'city', 'age','gender']
|
||||
user_info_df = pd.read_csv(user_info_path, usecols=columns, sep='\t')
|
||||
contest_user_protrail_collection = MongoServer().get_contest_user_potrial_collection()
|
||||
|
||||
user_num = user_info_df.shape[0]
|
||||
|
||||
for _, row in tqdm(user_info_df.iterrows()):
|
||||
user_info_dict = {}
|
||||
for col in columns:
|
||||
user_info_dict[col] = row[col]
|
||||
contest_user_protrail_collection.insert_one(user_info_dict)
|
||||
|
||||
print("load_user_info_data success, user nums: {}".format(user_num))
|
||||
|
||||
|
||||
def load_doc_info_data():
|
||||
"""导入文章画像数据
|
||||
原始的数据是存在NewsRecSys db中的 FeatureProtrail collection中
|
||||
现将竞赛数据的文章画像存到 NewsRecSys db中的 ContestFeatureProtrail collection中
|
||||
"""
|
||||
doc_info_path = ROOT_PATH + 'doc_info.txt'
|
||||
columns = ['article_id', 'title', 'ctime', 'img_num', 'cate','sub_cate', 'key_words']
|
||||
doc_info_df = pd.read_csv(doc_info_path, names=columns, sep='\t')
|
||||
print(doc_info_df.head())
|
||||
print(doc_info_df.shape)
|
||||
|
||||
feature_user_protrail_collection = MongoServer().get_contest_feature_potrial_collection()
|
||||
|
||||
doc_num = doc_info_df.shape[0]
|
||||
|
||||
for _, row in tqdm(doc_info_df.iterrows()):
|
||||
user_info_dict = {}
|
||||
for col in columns:
|
||||
user_info_dict[col] = row[col]
|
||||
try:
|
||||
feature_user_protrail_collection.insert_one(user_info_dict)
|
||||
except:
|
||||
# 有些异常数据,比如标题太长了,导致无法存入mongodb
|
||||
print(row)
|
||||
|
||||
print("load_doc_info_data success, doc nums: {}".format(doc_num))
|
||||
|
||||
|
||||
def load_user_behavior_data():
|
||||
"""导入用户行为数据
|
||||
原始的用户行为 存储在mysql中loginfo db中的 类似 log_2021_12_09 的表中
|
||||
现将竞赛数据的日志数据存储到mysql中loginfo db 中 类似 contest_log_2021_12_09 表中
|
||||
"""
|
||||
user_behavior_path = ROOT_PATH + 'train_data_5w.csv'
|
||||
columns = ['user_id', 'article_id', 'expo_time', 'net_status', 'flush_nums', 'expo_position', 'click', 'duration']
|
||||
user_behavior_df = pd.read_csv(user_behavior_path, usecols=columns, sep='\t')
|
||||
|
||||
# '%Y-%m-%d %H:%M:%S'
|
||||
user_behavior_df['expo_time_date_day'] = pd.to_datetime(user_behavior_df['expo_time'], unit='ms').dt.strftime('%Y_%m_%d')
|
||||
|
||||
sql_sess = MysqlServer().get_contest_loginfo_session()
|
||||
|
||||
for _, df in user_behavior_df.groupby('expo_time_date_day'):
|
||||
table_name = contest_loginfo_table_name_prefix + '_' + df['expo_time_date_day'].iloc[0]
|
||||
# 通过元类创建一个新的类
|
||||
# 因为SqlAlchemy中一个类只能对应一个表,但是现在的场景下的所有表的结构都是一样的,所以这里可以使用type来动态的构造表
|
||||
NewContestLogItem = get_new_class(table_name)
|
||||
print("当前分组的数据量为: {}".format(df.shape[0]))
|
||||
for _, row in tqdm(df.iterrows()):
|
||||
contest_user_log_item = NewContestLogItem()
|
||||
contest_user_log_item.user_id = row['user_id']
|
||||
contest_user_log_item.article_id = row['article_id']
|
||||
contest_user_log_item.net_status = row['net_status']
|
||||
contest_user_log_item.flush_nums = row['flush_nums']
|
||||
contest_user_log_item.expo_position = row['expo_position']
|
||||
contest_user_log_item.click = row['click']
|
||||
contest_user_log_item.duration = row['duration']
|
||||
|
||||
sql_sess.add(contest_user_log_item)
|
||||
sql_sess.commit()
|
||||
print('save {} success!'.format(table_name))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# load_user_info_data()
|
||||
# load_doc_info_data()
|
||||
load_user_behavior_data()
|
||||
@@ -22,7 +22,7 @@ from dao.redis_server import RedisServer
|
||||
10. url 新闻原始链接
|
||||
"""
|
||||
|
||||
class NewsProtraitServer:
|
||||
class NewsPortraitServer:
|
||||
def __init__(self):
|
||||
"""初始化相关参数
|
||||
"""
|
||||
@@ -128,7 +128,7 @@ class NewsProtraitServer:
|
||||
|
||||
if __name__ == "__main__":
|
||||
# TODO 需要放到 其他逻辑中,将物料这块的逻辑打通
|
||||
news_protrait = NewsProtraitServer()
|
||||
news_protrait = NewsPortraitServer()
|
||||
# news_protrait.update_new_items()
|
||||
news_protrait.update_redis_mongo_protrail_data()
|
||||
# news_protrait.update_dynamic_feature_protrail()
|
||||
|
||||
@@ -18,6 +18,6 @@ if __name__ == "__main__":
|
||||
# 查找当前集合中所有文档的数量
|
||||
cur_news_num = collection.count()
|
||||
|
||||
if (cur_news_num < news_num):
|
||||
if cur_news_num < news_num:
|
||||
print("the news nums of {}_{} collection is {} and less then {}.".\
|
||||
format(COLLECTION_NAME_PRFIX, time_str, cur_news_num, news_num))
|
||||
@@ -36,13 +36,13 @@ class SinaSpider(scrapy.Spider):
|
||||
def start_requests(self):
|
||||
"""返回一个Request迭代器
|
||||
"""
|
||||
# 遍历所有类型的论文
|
||||
# 遍历所有类型的新闻
|
||||
for cate_id in self.cate_dict.keys():
|
||||
for page in range(1, self.total_pages + 1):
|
||||
lid = cate_id
|
||||
# 这里就是一个随机数,具体含义不是很清楚
|
||||
r = random.random()
|
||||
# cb_kwargs 是用来往解析函数parse中传递参数的
|
||||
# cb_kwargs 是用来向解析函数parse中传递参数的
|
||||
yield Request(self.base_url.format(lid, page, r), callback=self.parse, cb_kwargs={"cate_id": lid})
|
||||
|
||||
def parse(self, response, cate_id):
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
from material_process.news_protrait import NewsProtraitServer
|
||||
from material_process.news_protrait import NewsPortraitServer
|
||||
from material_process.news_to_redis import NewsRedisServer
|
||||
|
||||
|
||||
@@ -6,13 +6,13 @@ def process_material():
|
||||
"""物料处理函数
|
||||
"""
|
||||
# 画像处理
|
||||
protrail_server = NewsProtraitServer()
|
||||
portrail_server = NewsPortraitServer()
|
||||
# 处理最新爬取新闻的画像,存入特征库
|
||||
protrail_server.update_new_items()
|
||||
portrail_server.update_new_items()
|
||||
# 更新新闻动态画像, 需要在redis数据库内容清空之前执行
|
||||
protrail_server.update_dynamic_feature_protrail()
|
||||
portrail_server.update_dynamic_feature_protrail()
|
||||
# 生成前端展示的新闻画像,并在mongodb中备份一份
|
||||
protrail_server.update_redis_mongo_protrail_data()
|
||||
portrail_server.update_redis_mongo_protrail_data()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
Binary file not shown.
Binary file not shown.
@@ -0,0 +1,53 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : create_ctr_data.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/2/7
|
||||
|
||||
import pickle
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
from sklearn.utils import shuffle
|
||||
|
||||
from model_tools.feature_columns import SparseFeat, DenseFeat
|
||||
|
||||
|
||||
def create_ctr_data(data_path, args, use_dict=True):
|
||||
with open(data_path + 'data.pkl', 'rb') as f:
|
||||
all_data, feature_info = pickle.load(f)
|
||||
f.close()
|
||||
|
||||
# 训练数据和测试数据
|
||||
all_data = shuffle(all_data)
|
||||
train_df = all_data[all_data['是否点击'] != -1]
|
||||
test_df = all_data[all_data['是否点击'] == -1]
|
||||
# 测试数据的标签
|
||||
test_labels = pd.read_pickle(data_path + 'test_label.pkl')
|
||||
test_labels = pd.merge(test_df[['index']], test_labels, how='left', on=['index'])
|
||||
|
||||
all_features = feature_info['dense_features'] + feature_info['sparse_features']
|
||||
if use_dict:
|
||||
train_inputs = {name: np.array(train_df[name].tolist()) for name in all_features}
|
||||
train_labels = train_df['是否点击'].values
|
||||
test_inputs = {name: np.array(test_df[name].tolist()) for name in all_features}
|
||||
test_labels = test_labels['是否点击'].values
|
||||
else:
|
||||
train_inputs = [np.array(train_df[name]) for name in all_features]
|
||||
train_labels = train_df['是否点击'].values
|
||||
test_inputs = [np.array(test_df[name]) for name in all_features]
|
||||
test_labels = test_labels['是否点击'].values
|
||||
|
||||
features_columns = [DenseFeat(name=feat,
|
||||
dimension=1,
|
||||
dtype='float32',)
|
||||
for feat in feature_info['dense_features']]
|
||||
|
||||
features_columns += [SparseFeat(name=feat,
|
||||
embed_name=feat,
|
||||
embed_dim=args.embed_dim,
|
||||
vocab_size=all_data[feat].max()+1,
|
||||
dtype='int32',)
|
||||
for feat in feature_info['sparse_features']]
|
||||
|
||||
return (train_inputs, train_labels), (test_inputs, test_labels), features_columns
|
||||
@@ -0,0 +1,163 @@
|
||||
#!/usrbin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : news_data_process.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/2/7
|
||||
|
||||
import os
|
||||
import gc
|
||||
import swifter
|
||||
import pickle
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
from tqdm.auto import tqdm
|
||||
from sklearn.preprocessing import LabelEncoder, StandardScaler
|
||||
from utils.data_compression import reduce_mem
|
||||
|
||||
|
||||
def get_statistical_features(all_data, past_day=7):
|
||||
# 统计新闻从发文到展示的日期差
|
||||
temp = all_data['展现日期'] - all_data['发文日期']
|
||||
all_data['从发文到展现的日期差'] = temp.dt.days
|
||||
all_data.loc[all_data['从发文到展现的日期差'] < 0, '从发文到展现的日期差'] = 0
|
||||
all_data.fillna(value={'从发文到展现的日期差': 0}, inplace=True)
|
||||
|
||||
statis_dense_columns = ['从发文到展现的日期差']
|
||||
|
||||
dates = all_data['展现日期'].unique()
|
||||
dates.sort()
|
||||
date_num = len(dates)
|
||||
date_map = dict(zip(dates, range(date_num)))
|
||||
all_data['展现日期_idx'] = all_data['展现日期'].map(date_map)
|
||||
|
||||
train_data = all_data[all_data['是否点击'] != -1]
|
||||
|
||||
# ===================================================================================
|
||||
for feat in tqdm([['user_id'], ['item_id'], ['一级分类'], ['二级分类'],
|
||||
['user_id', '一级分类'], ['user_id', '二级分类']]):
|
||||
res_arr = []
|
||||
name = f'过去{past_day}天_特征({"_".join(feat)})_展现总数'
|
||||
statis_dense_columns.append(name)
|
||||
|
||||
for day in range(0, date_num):
|
||||
train_data_temp = train_data[
|
||||
(train_data['展现日期_idx'] >= day-past_day) & (train_data['展现日期_idx'] < day)]
|
||||
train_data_temp = train_data_temp.groupby(feat)['item_id'].agg([
|
||||
(name, 'count')]).reset_index()
|
||||
train_data_temp['展现日期_idx'] = day
|
||||
res_arr.append(train_data_temp)
|
||||
stat_all_data = pd.concat(res_arr)
|
||||
all_data = all_data.merge(stat_all_data, how='left', on=feat + ['展现日期_idx'])
|
||||
|
||||
target = '是否点击'
|
||||
for feat in tqdm([['user_id'], ['item_id'], ['一级分类'], ['二级分类'],
|
||||
['user_id', '一级分类'], ['user_id', '二级分类']]):
|
||||
res_arr = []
|
||||
name_mean = f'过去{past_day}天_特征({"_".join(feat)})_点击率mean'
|
||||
name_sum = f'过去{past_day}天_特征({"_".join(feat)})_点击总数sum'
|
||||
|
||||
statis_dense_columns.append(name_mean)
|
||||
statis_dense_columns.append(name_sum)
|
||||
|
||||
for day in range(0, date_num):
|
||||
train_data_temp = train_data[
|
||||
(train_data['展现日期_idx'] >= day-past_day) & (train_data['展现日期_idx'] < day)]
|
||||
train_data_temp = train_data_temp.groupby(feat)[target].agg(
|
||||
[(name_mean, 'mean'), (name_sum, 'sum')]).reset_index()
|
||||
train_data_temp['展现日期_idx'] = day
|
||||
res_arr.append(train_data_temp)
|
||||
stat_all_data = pd.concat(res_arr)
|
||||
all_data = all_data.merge(stat_all_data, how='left', on=feat + ['展现日期_idx'])
|
||||
|
||||
target = '消费时长(秒)'
|
||||
for feat in tqdm([['user_id'], ['item_id'], ['一级分类'], ['二级分类'],
|
||||
['user_id', '一级分类'], ['user_id', '二级分类']]):
|
||||
res_arr = []
|
||||
name_mean = f'过去{past_day}天_特征({"_".join(feat)})_消费时长mean'
|
||||
name_std = f'过去{past_day}天_特征({"_".join(feat)})_消费时长std'
|
||||
name_sum = f'过去{past_day}天_特征({"_".join(feat)})_消费时长sum'
|
||||
statis_dense_columns.append(name_mean)
|
||||
statis_dense_columns.append(name_std)
|
||||
statis_dense_columns.append(name_sum)
|
||||
|
||||
for day in range(0, date_num):
|
||||
train_data_temp = train_data[
|
||||
(train_data['展现日期_idx'] >= day-past_day) & (train_data['展现日期_idx'] < day)]
|
||||
train_data_temp = train_data_temp.groupby(feat)[target].agg(
|
||||
[(name_mean, 'mean'), (name_std, 'std'), (name_sum, 'sum')]
|
||||
).reset_index()
|
||||
train_data_temp['展现日期_idx'] = day
|
||||
res_arr.append(train_data_temp)
|
||||
stat_all_data = pd.concat(res_arr)
|
||||
all_data = all_data.merge(stat_all_data, how='left', on=feat + ['展现日期_idx'])
|
||||
|
||||
return all_data, statis_dense_columns
|
||||
|
||||
|
||||
def main():
|
||||
raw_data_path = '../raw_data'
|
||||
new_data_path = '../new_data'
|
||||
os.makedirs(new_data_path, exist_ok=True)
|
||||
|
||||
train_data_path = os.path.join(raw_data_path, 'train_data.pkl')
|
||||
test_data_path = os.path.join(raw_data_path, 'test_data.pkl')
|
||||
|
||||
train_data = pd.read_pickle(train_data_path)
|
||||
test_data = pd.read_pickle(test_data_path)
|
||||
test_data['是否点击'] = -1
|
||||
all_data = pd.concat([train_data, test_data])
|
||||
|
||||
# 1. 合并用户特征
|
||||
user_path = os.path.join(new_data_path, 'user_info_5w.pkl')
|
||||
user_info = pd.read_pickle(user_path)
|
||||
all_data = all_data.merge(
|
||||
user_info[['user_id', '设备名称', '操作系统', '所在省', '所在市', '年龄', '性别']],
|
||||
how='left', on='user_id'
|
||||
)
|
||||
del user_info
|
||||
gc.collect()
|
||||
|
||||
# 2. 合并文档特征
|
||||
doc_path = os.path.join(new_data_path, 'doc_info.pkl')
|
||||
doc_info = pd.read_pickle(doc_path)
|
||||
all_data = all_data.merge(
|
||||
doc_info[['item_id', '一级分类', '二级分类', '关键词', '图片数量', '发文时间', '发文日期']],
|
||||
how='left', on='item_id'
|
||||
)
|
||||
del doc_info
|
||||
gc.collect()
|
||||
|
||||
# 3. 获取统计特征
|
||||
all_data, statis_dense_columns = get_statistical_features(all_data)
|
||||
|
||||
# 4. 连续特征处理
|
||||
base_dense_columns = ['刷新次数', '图片数量']
|
||||
dense_columns = base_dense_columns + statis_dense_columns
|
||||
|
||||
all_data.fillna(value={feat: 0 for feat in dense_columns}, inplace=True)
|
||||
# sc = StandardScaler()
|
||||
# all_data[dense_columns] = sc.fit_transform(all_data[dense_columns])
|
||||
for feat in dense_columns:
|
||||
all_data[feat] = np.log(1 + all_data[feat])
|
||||
|
||||
# 5. 离散特征处理
|
||||
sparse_columns = ['user_id', 'item_id', '网路环境', '设备名称', '操作系统', '展现位置',
|
||||
'所在省', '所在市', '年龄', '性别', '一级分类', '二级分类', '关键词']
|
||||
for feat in sparse_columns:
|
||||
lb = LabelEncoder()
|
||||
all_data[feat] = lb.fit_transform(all_data[feat].astype(str))
|
||||
|
||||
all_data = reduce_mem(all_data)
|
||||
feature_info = {'dense_features': dense_columns,
|
||||
'sparse_features': sparse_columns}
|
||||
file = [all_data, feature_info]
|
||||
file_save_path = os.path.join(new_data_path, 'data.pkl')
|
||||
with open(file_save_path, 'wb') as f:
|
||||
pickle.dump(file, f)
|
||||
f.close()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
@@ -0,0 +1,46 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : train&test_data_split.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/2/16
|
||||
|
||||
|
||||
import os
|
||||
import pandas as pd
|
||||
|
||||
|
||||
def main():
|
||||
raw_data_path = '../raw_data'
|
||||
new_data_path = '../new_data'
|
||||
|
||||
# 1. 数据读取
|
||||
all_data_path = os.path.join(raw_data_path, 'train_data_5w.csv')
|
||||
all_data = pd.read_csv(all_data_path, sep='\t', index_col=0) # .sample(n=100000)
|
||||
all_data.columns = ['user_id', 'item_id', '展现时间', '网路环境', '刷新次数', '展现位置', '是否点击', '消费时长(秒)']
|
||||
print(f'样本总数为:{all_data.shape[0]}')
|
||||
|
||||
# 2. 数据处理
|
||||
all_data.loc[all_data['消费时长(秒)'] < 0, '消费时长(秒)'] = 0
|
||||
all_data['展现时间'] = pd.to_datetime(
|
||||
all_data.loc[:, '展现时间'], utc=True, unit='ms').dt.tz_convert('Asia/Shanghai')
|
||||
all_data['展现日期'] = all_data['展现时间'].dt.date
|
||||
all_data['index'] = range(all_data.shape[0])
|
||||
|
||||
dates = all_data['展现日期'].unique()
|
||||
dates.sort()
|
||||
# 3. 训练、测试数据集划分
|
||||
train_data = all_data[all_data['展现日期'] != dates[-1]]
|
||||
test_data = all_data[all_data['展现日期'] == dates[-1]]
|
||||
test_label = test_data[['index', '是否点击']]
|
||||
|
||||
# 4. 测试集处理
|
||||
test_data = test_data.drop(columns=['消费时长(秒)', '展现位置', '是否点击'])
|
||||
|
||||
train_data.to_pickle(os.path.join(raw_data_path, 'train_data.pkl'))
|
||||
test_data.to_pickle(os.path.join(raw_data_path, 'test_data.pkl'))
|
||||
test_label.to_pickle(os.path.join(new_data_path, 'test_label.pkl'))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
@@ -0,0 +1,103 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : user&doc_data_process.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/2/9
|
||||
|
||||
import os
|
||||
import swifter
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
|
||||
def prob2val(feat_info):
|
||||
# 判断是否为空
|
||||
if feat_info == feat_info:
|
||||
prob_list = [values.split(':') for values in feat_info.split(',')]
|
||||
prob_list = sorted(prob_list, key=lambda x: float(x[1]))
|
||||
return prob_list[-1][0]
|
||||
else:
|
||||
return np.NaN
|
||||
|
||||
|
||||
def get_second_title(x):
|
||||
if x['二级分类'] == x['二级分类']:
|
||||
second_titles = x['二级分类'].split('/')
|
||||
for title in second_titles:
|
||||
# 跳过异常数据
|
||||
if title == 'A_0_24:0.447656,A_25_29:0.243809,A_30_39:0.076268,A_40+:0.232267':
|
||||
continue
|
||||
# 优先返回不等于一级分类的二级分类
|
||||
if title != x['一级分类']:
|
||||
return title
|
||||
|
||||
return x['一级分类']
|
||||
|
||||
|
||||
def get_key_word(feat_info):
|
||||
if feat_info == feat_info and isinstance(feat_info, str):
|
||||
key_word_list = [values.split(':') for values in feat_info.replace('^', '').split(',')]
|
||||
|
||||
new_list = []
|
||||
last_elem = ''
|
||||
for idx, values in enumerate(key_word_list):
|
||||
if len(values) == 1:
|
||||
last_elem = values[0] if last_elem == '' else ','.join([last_elem, values[0]])
|
||||
continue
|
||||
if len(values) > 2:
|
||||
# 将类似于‘你好,李焕英’这种关键词重新进行拼接
|
||||
# 这类关键词由于存在逗号,在获取key_word_list时被误分开了
|
||||
values[0] = ':'.join(values[:-1])
|
||||
|
||||
values[0] = values[0] if last_elem == '' else ','.join([last_elem, values[0]])
|
||||
new_list.append(values)
|
||||
last_elem = ''
|
||||
|
||||
return new_list[-1][0]
|
||||
else:
|
||||
return np.NaN
|
||||
|
||||
|
||||
def main():
|
||||
raw_data_path = '../raw_data'
|
||||
new_data_path = '../new_data'
|
||||
os.makedirs(new_data_path, exist_ok=True)
|
||||
|
||||
# 1. 处理用户文件
|
||||
user_path = os.path.join(raw_data_path, 'user_info_5w.csv')
|
||||
user_info = pd.read_csv(user_path, sep='\t', index_col=0)
|
||||
user_info.columns = ['user_id', '设备名称', '操作系统', '所在省', '所在市', '年龄', '性别']
|
||||
|
||||
user_info['年龄'] = [prob2val(age_info) for age_info in tqdm(user_info['年龄'])]
|
||||
user_info['性别'] = [prob2val(sex_info) for sex_info in tqdm(user_info['性别'])]
|
||||
|
||||
user_info.to_pickle(os.path.join(new_data_path, 'user_info_5w.pkl'))
|
||||
|
||||
# 2. 处理文档文件
|
||||
doc_path = os.path.join(raw_data_path, 'doc_info.txt')
|
||||
doc_info = pd.read_table(doc_path, sep='\t', low_memory=False, header=None)
|
||||
doc_info.columns = ['item_id', '标题', '发文时间', '图片数量', '一级分类', '二级分类', '关键词']
|
||||
|
||||
# 处理异常的发文时间数据
|
||||
condition_row = (doc_info['发文时间'].isnull()) | (doc_info['发文时间'] == 'Android')
|
||||
time_fill_value = doc_info.loc[~condition_row, '发文时间'].swifter.apply(lambda x: int(x[:10])).astype('int').min()
|
||||
doc_info.loc[condition_row, '发文时间'] = str(time_fill_value)
|
||||
|
||||
doc_info['发文时间'] = pd.to_datetime(
|
||||
doc_info.loc[:, '发文时间'], utc=True, unit='ms').dt.tz_convert('Asia/Shanghai')
|
||||
doc_info['发文日期'] = doc_info['发文时间'].dt.date
|
||||
|
||||
doc_info['图片数量'] = doc_info.loc[:, '图片数量'].swifter.apply(
|
||||
lambda x: 0 if (x in ['上海', '云南', '山东'] or x != x) else int(x))
|
||||
|
||||
doc_info['二级分类'] = doc_info.loc[:, ['一级分类', '二级分类']].swifter.apply(get_second_title, axis=1)
|
||||
doc_info['关键词'] = [get_key_word(words) for words in tqdm(doc_info['关键词'])]
|
||||
|
||||
doc_info.to_pickle(os.path.join(new_data_path, 'doc_info.pkl'))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
@@ -0,0 +1,13 @@
|
||||
原始数据集共包含3个,实验时存放在目录`rank/examples/dataset/raw_data/`下。
|
||||
|
||||
+ **user_info_5w.csv**
|
||||
+ 该文件共包含了5万条用户的个人数据;
|
||||
+ 特征分别包括了:['user_id', 'device', 'os', 'province', 'city', 'age', 'gender'];
|
||||
+ 各特征的含义为:['用户id', '设备名称', '操作系统', '所在省', '所在市', '年龄', '性别'];
|
||||
+ **doc_info.txt**
|
||||
+ 该文件包含了所有新闻的特征数据;
|
||||
+ 各特征的含义为:['文档id', '标题', '发文时间', '图片数量', '一级分类', '二级分类', '关键词'];
|
||||
|
||||
+ **train_data_5w.csv**
|
||||
+ 该文件为用户点击数据,包含了5万个用户在过去13天的点击数据;
|
||||
+ 各特征的含义为:['用户id', '文档id', '展现时间', '网路环境', '刷新次数', '展现位置', '是否点击', '消费时长(秒)'];
|
||||
@@ -0,0 +1,29 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : deepfm_news.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/1/27
|
||||
|
||||
import argparse
|
||||
|
||||
from run_train import run_deepfm
|
||||
from utils.set_parament import get_args
|
||||
from dataset.data_process.create_ctr_data import create_ctr_data
|
||||
|
||||
|
||||
parser = argparse.ArgumentParser(description='Model Parameter')
|
||||
parser.add_argument('--yaml_path',
|
||||
default='./set_para/deepfm_news.yaml',
|
||||
required=False)
|
||||
parser.add_argument('--data_path',
|
||||
default='./dataset/new_data/',
|
||||
required=False)
|
||||
parse_args = parser.parse_args()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = get_args(parse_args.yaml_path)
|
||||
train_data, test_data, feature_info = create_ctr_data(parse_args.data_path, args)
|
||||
|
||||
run_deepfm.run(train_data, test_data, feature_info, args)
|
||||
@@ -0,0 +1,29 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : deepfm_ppnet_news.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/2/8
|
||||
|
||||
import argparse
|
||||
|
||||
from run_train import run_deepfm_ppnet
|
||||
from utils.set_parament import get_args
|
||||
from dataset.data_process.create_ctr_data import create_ctr_data
|
||||
|
||||
|
||||
parser = argparse.ArgumentParser(description='Model Parameter')
|
||||
parser.add_argument('--yaml_path',
|
||||
default='./set_para/deepfm_ppnet_news.yaml',
|
||||
required=False)
|
||||
parser.add_argument('--data_path',
|
||||
default='./dataset/new_data/',
|
||||
required=False)
|
||||
parse_args = parser.parse_args()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = get_args(parse_args.yaml_path)
|
||||
train_data, test_data, feature_info = create_ctr_data(parse_args.data_path, args)
|
||||
|
||||
run_deepfm_ppnet.run(train_data, test_data, feature_info, args)
|
||||
@@ -0,0 +1,14 @@
|
||||
# data para
|
||||
seed: 48
|
||||
# model para
|
||||
embed_dim: 32
|
||||
drop_rate: 0.5
|
||||
use_bn: Ture
|
||||
hidden_units: [64, 128, 64]
|
||||
# compile para
|
||||
learning_rate: 0.001
|
||||
epochs: 1
|
||||
batch_size: 2048
|
||||
val_splite: 0.1
|
||||
patience: 5
|
||||
restore_best_weights: True
|
||||
@@ -0,0 +1,16 @@
|
||||
# data para
|
||||
seed: 48
|
||||
# model para
|
||||
embed_dim: 32
|
||||
drop_rate: 0.5
|
||||
ppnet_size: 256
|
||||
ppnet_features: ['user_id', '一级分类', '年龄']
|
||||
use_bn: Ture
|
||||
hidden_units: [64, 128, 64]
|
||||
# compile para
|
||||
learning_rate: 0.001
|
||||
epochs: 1
|
||||
batch_size: 2048
|
||||
val_splite: 0.1
|
||||
patience: 5
|
||||
restore_best_weights: True
|
||||
@@ -0,0 +1,6 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : __init__.py.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/1/27
|
||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
@@ -0,0 +1,24 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : activation.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/1/27
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.initializers import Zeros
|
||||
from tensorflow.keras.layers import Layer
|
||||
|
||||
unicode = str
|
||||
|
||||
|
||||
def activation_layer(activation):
|
||||
if isinstance(activation, (str, unicode)):
|
||||
act_layer = tf.keras.layers.Activation(activation)
|
||||
elif issubclass(activation, Layer):
|
||||
act_layer = activation()
|
||||
else:
|
||||
raise ValueError(
|
||||
"Invalid activation,found %s.You should use a str or a Activation Layer Class." % (activation))
|
||||
return act_layer
|
||||
|
||||
238
codes/news_recsys/news_rec_server/recprocess/rank/layers/core.py
Normal file
238
codes/news_recsys/news_rec_server/recprocess/rank/layers/core.py
Normal file
@@ -0,0 +1,238 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @File : core.py
|
||||
# @Author: xLyons
|
||||
# @IDE :PyCharm
|
||||
# @Time : 2022/1/27
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import Layer, Dense, Embedding, BatchNormalization, Dropout
|
||||
from tensorflow.keras.initializers import glorot_normal, Zeros, glorot_uniform
|
||||
from tensorflow.keras.regularizers import l2
|
||||
|
||||
from layers.activation import activation_layer
|
||||
|
||||
|
||||
class DNN(Layer):
|
||||
def __init__(self, hidden_units, activation='relu', l2_reg=.0, dropout_rate=.0, use_bn=False,
|
||||
output_activation=None, seed=48, **kwargs):
|
||||
self.hidden_units = hidden_units
|
||||
self.activation = activation
|
||||
self.l2_reg = l2_reg
|
||||
self.dropout_rate = dropout_rate
|
||||
self.use_bn = use_bn
|
||||
self.output_activation = output_activation
|
||||
self.seed = seed
|
||||
|
||||
super(DNN, self).__init__(**kwargs)
|
||||
|
||||
def build(self, input_shape):
|
||||
input_size = input_shape[-1]
|
||||
|
||||
hidden_units = [int(input_size)] + list(self.hidden_units)
|
||||
self.kernels = [self.add_weight(name='kernel' + str(i),
|
||||
shape=(
|
||||
hidden_units[i], hidden_units[i + 1]),
|
||||
initializer=glorot_uniform(
|
||||
seed=self.seed),
|
||||
regularizer=l2(self.l2_reg),
|
||||
trainable=True) for i in range(len(self.hidden_units))]
|
||||
self.bias = [self.add_weight(name='bias' + str(i),
|
||||
shape=(self.hidden_units[i],),
|
||||
initializer=Zeros(),
|
||||
trainable=True) for i in range(len(self.hidden_units))]
|
||||
if self.use_bn:
|
||||
self.bn_layers = [tf.keras.layers.BatchNormalization() for _ in range(len(self.hidden_units))]
|
||||
|
||||
self.dropout_layers = [tf.keras.layers.Dropout(self.dropout_rate, seed=self.seed + i) for i in
|
||||
range(len(self.hidden_units))]
|
||||
|
||||
self.activation_layers = [activation_layer(self.activation) for _ in range(len(self.hidden_units))]
|
||||
|
||||
if self.output_activation:
|
||||
self.activation_layers[-1] = activation_layer(self.output_activation)
|
||||
|
||||
super(DNN, self).build(input_shape)
|
||||
|
||||
def call(self, inputs, training=True, **kwargs):
|
||||
deep_input = inputs
|
||||
|
||||
for i in range(len(self.hidden_units)):
|
||||
fc = tf.nn.bias_add(tf.tensordot(
|
||||
deep_input, self.kernels[i], axes=(-1, 0)), self.bias[i])
|
||||
|
||||
if self.use_bn:
|
||||
fc = self.bn_layers[i](fc, training=training)
|
||||
try:
|
||||
fc = self.activation_layers[i](fc, training=training)
|
||||
except TypeError as e:
|
||||
print("make sure the activation function use training flag properly", e)
|
||||
fc = self.activation_layers[i](fc)
|
||||
|
||||
fc = self.dropout_layers[i](fc, training=training)
|
||||
deep_input = fc
|
||||
|
||||
return deep_input
|
||||
|
||||
|
||||
class Linear(Layer):
|
||||
def __init__(self, l2_reg=.0, use_bias=False, seed=48, **kwargs):
|
||||
self.l2_reg = l2_reg
|
||||
self.use_bias = use_bias
|
||||
self.seed = seed
|
||||
|
||||
super().__init__(**kwargs)
|
||||
|
||||
def build(self, input_shape):
|
||||
self.kernel = self.add_weight(
|
||||
name='linear_kernel',
|
||||
shape=(input_shape[-1], 1),
|
||||
initializer=glorot_normal(self.seed),
|
||||
regularizer=l2(self.l2_reg),
|
||||
trainable=True,
|
||||
)
|
||||
if self.use_bias:
|
||||
self.bias = self.add_weight(
|
||||
name='linear_bais',
|
||||
shape=(1, ),
|
||||
initializer=Zeros(),
|
||||
trainable=True
|
||||
)
|
||||
|
||||
super(Linear, self).build(input_shape)
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
linear_logits = tf.tensordot(inputs, self.kernel, axes=1)
|
||||
if self.use_bias:
|
||||
linear_logits += self.bias
|
||||
|
||||
return linear_logits
|
||||
|
||||
|
||||
class GateNN(Layer):
|
||||
def __init__(self, hidden_units, activation='relu', l2_reg=.0, dropout_rate=.0, use_bn=False,
|
||||
output_activation='sigmoid', seed=48, **kwargs):
|
||||
self.hidden_units = hidden_units
|
||||
self.activation = activation
|
||||
self.l2_reg = l2_reg
|
||||
self.dropout_rate = dropout_rate
|
||||
self.use_bn = use_bn
|
||||
self.output_activation = output_activation
|
||||
self.seed = seed
|
||||
|
||||
super(GateNN, self).__init__(**kwargs)
|
||||
|
||||
def build(self, input_shape):
|
||||
input_size = input_shape[-1]
|
||||
|
||||
hidden_units = [int(input_size)] + list(self.hidden_units)
|
||||
self.kernels = [self.add_weight(name='kernel' + str(i),
|
||||
shape=(
|
||||
hidden_units[i], hidden_units[i + 1]),
|
||||
initializer=glorot_uniform(
|
||||
seed=self.seed),
|
||||
regularizer=l2(self.l2_reg),
|
||||
trainable=True) for i in range(len(self.hidden_units))]
|
||||
self.bias = [self.add_weight(name='bias' + str(i),
|
||||
shape=(self.hidden_units[i],),
|
||||
initializer=Zeros(),
|
||||
trainable=True) for i in range(len(self.hidden_units))]
|
||||
|
||||
self.activation_layers = [activation_layer(self.activation) for _ in range(len(self.hidden_units))]
|
||||
|
||||
if self.output_activation:
|
||||
self.activation_layers[-1] = activation_layer(self.output_activation)
|
||||
|
||||
super(GateNN, self).build(input_shape)
|
||||
|
||||
def call(self, inputs, training=True, **kwargs):
|
||||
deep_input = inputs
|
||||
|
||||
for i in range(len(self.hidden_units)):
|
||||
fc = tf.nn.bias_add(tf.tensordot(
|
||||
deep_input, self.kernels[i], axes=(-1, 0)), self.bias[i])
|
||||
|
||||
try:
|
||||
fc = self.activation_layers[i](fc, training=training)
|
||||
except TypeError as e:
|
||||
print("make sure the activation function use training flag properly", e)
|
||||
fc = self.activation_layers[i](fc)
|
||||
|
||||
deep_input = fc
|
||||
|
||||
return deep_input
|
||||
|
||||
|
||||
class PPNet(Layer):
|
||||
def __init__(self, ppnet_size, hidden_units, activation='relu', l2_reg=.0, dropout_rate=.0, use_bn=False,
|
||||
output_activation=None, seed=48, **kwargs):
|
||||
self.ppnet_size = ppnet_size
|
||||
self.hidden_units = hidden_units
|
||||
self.activation = activation
|
||||
self.l2_reg = l2_reg
|
||||
self.dropout_rate = dropout_rate
|
||||
self.use_bn = use_bn
|
||||
self.output_activation = output_activation
|
||||
self.seed = seed
|
||||
|
||||
super(PPNet, self).__init__(**kwargs)
|
||||
|
||||
def build(self, input_shape):
|
||||
input_size = input_shape[0][-1]
|
||||
hidden_units = [int(input_size)] + list(self.hidden_units)
|
||||
|
||||
self.gate_nn_layers = [
|
||||
GateNN(hidden_units=[self.ppnet_size, hidden_units[i]],
|
||||
activation='relu',
|
||||
output_activation='sigmoid',
|
||||
l2_reg=self.l2_reg,
|
||||
seed=self.seed)
|
||||
for i in range(len(self.hidden_units))
|
||||
]
|
||||
self.kernels = [self.add_weight(name='kernel' + str(i),
|
||||
shape=(hidden_units[i], hidden_units[i + 1]),
|
||||
initializer=glorot_uniform(
|
||||
seed=self.seed),
|
||||
regularizer=l2(self.l2_reg),
|
||||
trainable=True) for i in range(len(self.hidden_units))]
|
||||
self.bias = [self.add_weight(name='bias' + str(i),
|
||||
shape=(self.hidden_units[i],),
|
||||
initializer=Zeros(),
|
||||
trainable=True) for i in range(len(self.hidden_units))]
|
||||
if self.use_bn:
|
||||
self.bn_layers = [tf.keras.layers.BatchNormalization() for _ in range(len(self.hidden_units))]
|
||||
|
||||
self.dropout_layers = [tf.keras.layers.Dropout(self.dropout_rate, seed=self.seed + i) for i in
|
||||
range(len(self.hidden_units))]
|
||||
|
||||
self.activation_layers = [activation_layer(self.activation) for _ in range(len(self.hidden_units))]
|
||||
|
||||
if self.output_activation:
|
||||
self.activation_layers[-1] = activation_layer(self.output_activation)
|
||||
|
||||
super(PPNet, self).build(input_shape)
|
||||
|
||||
def call(self, inputs, training=True, **kwargs):
|
||||
deep_input, ppnet_input = inputs
|
||||
|
||||
for i in range(len(self.hidden_units)):
|
||||
ppnet_scale = self.gate_nn_layers[i](ppnet_input)
|
||||
deep_input = deep_input * ppnet_scale * 2
|
||||
fc = tf.nn.bias_add(tf.tensordot(
|
||||
deep_input, self.kernels[i], axes=(-1, 0)), self.bias[i])
|
||||
|
||||
if self.use_bn:
|
||||
fc = self.bn_layers[i](fc, training=training)
|
||||
try:
|
||||
fc = self.activation_layers[i](fc, training=training)
|
||||
except TypeError as e:
|
||||
print("make sure the activation function use training flag properly", e)
|
||||
fc = self.activation_layers[i](fc)
|
||||
|
||||
fc = self.dropout_layers[i](fc, training=training)
|
||||
deep_input = fc
|
||||
|
||||
return deep_input
|
||||
|
||||
|
||||
|
||||
@@ -0,0 +1,41 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @File : embedding.py
|
||||
# @Author: xLyons
|
||||
# @IDE :PyCharm
|
||||
# @Time : 2021/8/27
|
||||
|
||||
from tensorflow.keras.layers import Embedding
|
||||
from tensorflow.keras.regularizers import l2
|
||||
|
||||
|
||||
def create_embed_dict(sparse_feature_columns, embed_l2_reg):
|
||||
sparse_embed_dict = {}
|
||||
for feat in sparse_feature_columns:
|
||||
feat_embed_name = feat.embed_name
|
||||
if feat_embed_name not in sparse_embed_dict.keys():
|
||||
embed_layer = Embedding(
|
||||
input_dim=feat.vocab_size,
|
||||
input_length=1,
|
||||
output_dim=feat.embed_dim,
|
||||
embeddings_initializer=feat.embed_init,
|
||||
embeddings_regularizer=l2(embed_l2_reg)
|
||||
)
|
||||
embed_layer.trainable = True
|
||||
sparse_embed_dict[feat_embed_name] = embed_layer
|
||||
|
||||
return sparse_embed_dict
|
||||
|
||||
|
||||
def embedding_lookup(sparse_embed_dict, feat_inputs, sparse_feature_columns, query_features=(), to_list=False):
|
||||
feat_embed_outputs = {}
|
||||
for feat in sparse_feature_columns:
|
||||
feat_name = feat.name
|
||||
if len(query_features) == 0 or feat_name in query_features:
|
||||
feat_input = feat_inputs[feat_name]
|
||||
feat_embed_outputs[feat_name] = sparse_embed_dict[feat.embed_name](feat_input)
|
||||
|
||||
if to_list:
|
||||
return list(feat_embed_outputs.values())
|
||||
|
||||
return feat_embed_outputs
|
||||
@@ -0,0 +1,32 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @file : interaction.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2021/9/15
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
from tensorflow.keras.layers import Layer
|
||||
|
||||
|
||||
class FMCross(Layer):
|
||||
def __init__(self, **kwargs):
|
||||
super(FMCross, self).__init__(**kwargs)
|
||||
|
||||
def build(self, input_shape):
|
||||
if len(input_shape) != 3:
|
||||
raise ValueError("Unexpected inputs dimensions % d,\
|
||||
expect to be 3 dimensions" % (len(input_shape)))
|
||||
|
||||
super(FMCross, self).build(input_shape) # Be sure to call this somewhere!
|
||||
|
||||
def call(self, inputs, **kwargs):
|
||||
square_of_sum = tf.square(tf.reduce_sum(inputs, axis=1, keepdims=True)) # None, 1, dim
|
||||
sum_of_square = tf.reduce_sum(inputs * inputs, axis=1, keepdims=True) # None, 1, dim
|
||||
|
||||
cross_term = square_of_sum - sum_of_square
|
||||
cross_term = 0.5 * tf.reduce_sum(cross_term, axis=2, keepdims=False) # None, 1
|
||||
|
||||
return cross_term
|
||||
|
||||
@@ -0,0 +1,6 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : __init__.py.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/1/27
|
||||
Binary file not shown.
Binary file not shown.
@@ -0,0 +1,102 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# @File : feature_columns.py
|
||||
# @Author: xLyons
|
||||
# @IDE :PyCharm
|
||||
# @Time : 2022/1/27
|
||||
|
||||
|
||||
import copy
|
||||
import tensorflow as tf
|
||||
|
||||
from collections import OrderedDict
|
||||
from tensorflow.keras.layers import Input, Flatten, Concatenate
|
||||
from tensorflow.keras.initializers import RandomNormal, Zeros
|
||||
from tensorflow.keras.layers.experimental.preprocessing import StringLookup
|
||||
|
||||
from layers.core import Linear
|
||||
from layers.embedding import create_embed_dict, embedding_lookup
|
||||
|
||||
|
||||
class SparseFeat(object):
|
||||
def __init__(self, name, embed_dim, vocab_size, dtype, embed_name=None, seed=48):
|
||||
self.name = name
|
||||
self.vocab_size = vocab_size
|
||||
self.embed_dim = embed_dim
|
||||
self.embed_init = RandomNormal(mean=0.0, stddev=0.01, seed=seed)
|
||||
self.dtype = dtype
|
||||
|
||||
self.embed_name = embed_name if embed_name else name
|
||||
|
||||
super(SparseFeat, self).__init__()
|
||||
|
||||
|
||||
class DenseFeat(object):
|
||||
def __init__(self, name, dimension, dtype=None):
|
||||
self.name = name
|
||||
self.dimension = dimension
|
||||
self.dtype = dtype
|
||||
|
||||
super(DenseFeat, self).__init__()
|
||||
|
||||
|
||||
def build_feature_inputs(feature_columns):
|
||||
feat_inputs = OrderedDict()
|
||||
for feat in feature_columns:
|
||||
if isinstance(feat, SparseFeat):
|
||||
sparse_inputs = Input(shape=(1, ),
|
||||
name=feat.name,
|
||||
dtype=feat.dtype)
|
||||
feat_inputs[feat.name] = sparse_inputs
|
||||
elif isinstance(feat, DenseFeat):
|
||||
dense_inputs = Input(shape=(feat.dimension, ),
|
||||
name=feat.name,
|
||||
dtype=feat.dtype)
|
||||
feat_inputs[feat.name] = dense_inputs
|
||||
else:
|
||||
raise TypeError("Invalid feature column type,got", type(feat))
|
||||
|
||||
return feat_inputs
|
||||
|
||||
|
||||
def build_feature_coding_model(all_data, sparse_features):
|
||||
feature_vocab_dict = dict()
|
||||
for feat in sparse_features:
|
||||
string_model = StringLookup(vocabulary=all_data[feat].unique(),
|
||||
mask_token=None)
|
||||
feature_vocab_dict[feat] = string_model
|
||||
|
||||
return feature_vocab_dict
|
||||
|
||||
|
||||
def get_dense_inputs(feat_inputs, feature_columns, concat_flag=True):
|
||||
dense_inputs = []
|
||||
for feat in feature_columns:
|
||||
if isinstance(feat, DenseFeat):
|
||||
dense_inputs.append(feat_inputs[feat.name])
|
||||
|
||||
if concat_flag:
|
||||
dense_inputs = tf.concat(dense_inputs, axis=-1)
|
||||
|
||||
return dense_inputs
|
||||
|
||||
|
||||
def get_linear_logit(feat_inputs, feature_columns, linear_l2_reg=.0, embed_l2_reg=1e-5, use_bias=True, seed=48,):
|
||||
linear_features = copy.deepcopy(feature_columns)
|
||||
for feat in linear_features:
|
||||
if isinstance(feat, SparseFeat):
|
||||
feat.embed_dim = 1
|
||||
feat.embed_init = Zeros()
|
||||
|
||||
sparse_feature_columns = list(
|
||||
filter(lambda x: isinstance(x, SparseFeat), linear_features)) if feature_columns else []
|
||||
sparse_embed_dict = create_embed_dict(sparse_feature_columns, embed_l2_reg)
|
||||
sparse_embed_list = embedding_lookup(sparse_embed_dict, feat_inputs, sparse_feature_columns, to_list=True)
|
||||
|
||||
dense_inputs = get_dense_inputs(feat_inputs, linear_features, concat_flag=True)
|
||||
sparse_embed_inputs = Flatten()(Concatenate(axis=-1)(sparse_embed_list))
|
||||
linear_inputs = tf.concat([dense_inputs, sparse_embed_inputs], axis=-1)
|
||||
|
||||
linear_logit = Linear(linear_l2_reg, use_bias, seed)(linear_inputs)
|
||||
|
||||
return linear_logit
|
||||
@@ -0,0 +1,6 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : __init__.py.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/1/27
|
||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
@@ -0,0 +1,63 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : deepfm.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/1/27
|
||||
|
||||
from tensorflow.keras.layers import Dense
|
||||
|
||||
from layers.core import DNN
|
||||
from layers.interaction import FMCross
|
||||
from model_tools.feature_columns import *
|
||||
|
||||
|
||||
def DeepFM(feature_columns,
|
||||
dnn_hidden_units,
|
||||
embed_l2_reg=1e-5,
|
||||
linear_l2_reg=1e-5,
|
||||
linear_use_bias=True,
|
||||
dnn_l2_reg=1e-5,
|
||||
dnn_drop_rate=.0,
|
||||
dnn_use_bn=False,
|
||||
dnn_activation='relu',
|
||||
seed=48):
|
||||
|
||||
feat_inputs = build_feature_inputs(feature_columns)
|
||||
inputs_list = list(feat_inputs.values())
|
||||
|
||||
sparse_feature_columns = list(
|
||||
filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
sparse_embed_dict = create_embed_dict(sparse_feature_columns, embed_l2_reg)
|
||||
sparse_embed_list = embedding_lookup(sparse_embed_dict, feat_inputs, sparse_feature_columns, to_list=True)
|
||||
|
||||
dense_inputs = get_dense_inputs(feat_inputs, feature_columns, concat_flag=True)
|
||||
|
||||
linear_logit = get_linear_logit(feat_inputs=feat_inputs,
|
||||
feature_columns=feature_columns,
|
||||
linear_l2_reg=linear_l2_reg,
|
||||
embed_l2_reg=embed_l2_reg,
|
||||
use_bias=linear_use_bias,
|
||||
seed=seed)
|
||||
|
||||
fm_inputs = Concatenate(axis=1)(sparse_embed_list)
|
||||
fm_logit = FMCross()(fm_inputs)
|
||||
|
||||
sparse_embed_inputs = Flatten()(Concatenate(axis=-1)(sparse_embed_list))
|
||||
dnn_inputs = tf.concat([dense_inputs, sparse_embed_inputs], axis=-1)
|
||||
dnn_logit = DNN(hidden_units=dnn_hidden_units,
|
||||
activation=dnn_activation,
|
||||
l2_reg=dnn_l2_reg,
|
||||
dropout_rate=dnn_drop_rate,
|
||||
use_bn=dnn_use_bn
|
||||
)(dnn_inputs)
|
||||
dnn_logit = Dense(units=1,
|
||||
use_bias=False,
|
||||
kernel_initializer=tf.keras.initializers.glorot_uniform(seed=seed)
|
||||
)(dnn_logit)
|
||||
|
||||
final_outputs = tf.nn.sigmoid(linear_logit + fm_logit + dnn_logit)
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=final_outputs)
|
||||
|
||||
return model
|
||||
@@ -0,0 +1,77 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : deepfm_ppnet.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/2/8
|
||||
|
||||
|
||||
from tensorflow.keras.layers import Dense
|
||||
|
||||
from layers.core import PPNet
|
||||
from layers.interaction import FMCross
|
||||
from model_tools.feature_columns import *
|
||||
|
||||
|
||||
def DeepFM_PPNet(
|
||||
feature_columns,
|
||||
ppnet_size,
|
||||
ppnet_features,
|
||||
dnn_hidden_units,
|
||||
embed_l2_reg=1e-5,
|
||||
linear_l2_reg=1e-5,
|
||||
linear_use_bias=True,
|
||||
dnn_l2_reg=1e-5,
|
||||
dnn_drop_rate=.0,
|
||||
dnn_use_bn=False,
|
||||
dnn_activation='relu',
|
||||
seed=48):
|
||||
|
||||
feat_inputs = build_feature_inputs(feature_columns)
|
||||
inputs_list = list(feat_inputs.values())
|
||||
|
||||
sparse_feature_columns = list(
|
||||
filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
sparse_embed_dict = create_embed_dict(sparse_feature_columns, embed_l2_reg)
|
||||
sparse_embed_list = embedding_lookup(sparse_embed_dict, feat_inputs, sparse_feature_columns, to_list=True)
|
||||
|
||||
dense_inputs = get_dense_inputs(feat_inputs, feature_columns, concat_flag=True)
|
||||
|
||||
linear_logit = get_linear_logit(feat_inputs=feat_inputs,
|
||||
feature_columns=feature_columns,
|
||||
linear_l2_reg=linear_l2_reg,
|
||||
embed_l2_reg=embed_l2_reg,
|
||||
use_bias=linear_use_bias,
|
||||
seed=seed)
|
||||
|
||||
fm_inputs = Concatenate(axis=1)(sparse_embed_list)
|
||||
fm_logit = FMCross()(fm_inputs)
|
||||
|
||||
sparse_embed_inputs = Flatten()(Concatenate(axis=-1)(sparse_embed_list))
|
||||
dnn_inputs = tf.concat([dense_inputs, sparse_embed_inputs], axis=-1)
|
||||
|
||||
ppnet_feature_columns = list(
|
||||
filter(lambda x: x.name in ppnet_features, feature_columns)) if feature_columns else []
|
||||
ppnet_embed_list = embedding_lookup(sparse_embed_dict, feat_inputs, ppnet_feature_columns, to_list=True)
|
||||
ppnet_inputs = Flatten()(Concatenate(axis=-1)(ppnet_embed_list))
|
||||
# stop gradient propagation
|
||||
ppnet_inputs = tf.stop_gradient(ppnet_inputs)
|
||||
|
||||
dnn_logit = PPNet(
|
||||
ppnet_size=ppnet_size,
|
||||
hidden_units=dnn_hidden_units,
|
||||
activation=dnn_activation,
|
||||
l2_reg=dnn_l2_reg,
|
||||
dropout_rate=dnn_drop_rate,
|
||||
use_bn=dnn_use_bn
|
||||
)([dnn_inputs, ppnet_inputs])
|
||||
dnn_logit = Dense(units=1,
|
||||
use_bias=False,
|
||||
kernel_initializer=tf.keras.initializers.glorot_uniform(seed=seed)
|
||||
)(dnn_logit)
|
||||
|
||||
final_outputs = tf.nn.sigmoid(linear_logit + fm_logit + dnn_logit)
|
||||
model = tf.keras.models.Model(inputs=inputs_list, outputs=final_outputs)
|
||||
|
||||
return model
|
||||
273
codes/news_recsys/news_rec_server/recprocess/rank/readme.md
Normal file
273
codes/news_recsys/news_rec_server/recprocess/rank/readme.md
Normal file
@@ -0,0 +1,273 @@
|
||||
# 1. 数据集介绍
|
||||
|
||||
原始数据集共包含3个,实验时存放在目录`rank/examples/dataset/raw_data/`下。
|
||||
|
||||
+ **user_info_5w.csv**
|
||||
+ 该文件共包含了5万条用户的个人数据;
|
||||
+ 特征分别包括了:['user_id', 'device', 'os', 'province', 'city', 'age', 'gender'];
|
||||
+ 各特征的含义为:['用户id', '设备名称', '操作系统', '所在省', '所在市', '年龄', '性别'];
|
||||
+ **doc_info.txt**
|
||||
+ 该文件包含了所有新闻的特征数据;
|
||||
+ 各特征的含义为:['文档id', '标题', '发文时间', '图片数量', '一级分类', '二级分类', '关键词'];
|
||||
|
||||
+ **train_data_5w.csv**
|
||||
+ 该文件为用户点击数据,包含了5万个用户在过去13天的点击数据;
|
||||
+ 各特征的含义为:['用户id', '文档id', '展现时间', '网路环境', '刷新次数', '展现位置', '是否点击', '消费时长(秒)'];
|
||||
|
||||
|
||||
|
||||
# 2. 数据处理
|
||||
|
||||
数据处理的文件存放在`rank/examples/dataset/data_process/`下。
|
||||
|
||||
## 2.1 训练集和测试集的划分
|
||||
|
||||
训练集和测试集的划分程序为:**train&test_data_split.py**
|
||||
|
||||
+ 训练集:将所有用户在前12天的点击行为划为训练集;
|
||||
+ 测试集:
|
||||
+ 将所有用户在第13天的点击行为化为测试集;
|
||||
+ 测试集丢弃特征:消费时长(秒),展现位置,是否点击;
|
||||
|
||||
+ 测试标签:
|
||||
+ 将测试集的真实标签单独进行存储;
|
||||
|
||||
其他特征处理:
|
||||
|
||||
+ 选中消费时长小于0的样本,并将其消费时长设置为0;
|
||||
+ 对所有样本的展现时间进行了格式处理,并新增了特征展现日期;
|
||||
+ 新增特征index,目的是为了后续对测试集进行评估;
|
||||
|
||||
## 2.2 特征处理
|
||||
|
||||
### 2.2.1 用户和文档特征
|
||||
|
||||
用户数据和文档数据的处理程序为:**user&doc_data_process.py**
|
||||
|
||||
**用户数据处理**
|
||||
|
||||
+ 性别特征:原始的用户性别数据为用户对应不同性别的概率,这里直接将概率最高的性别作为用户的实际性别;
|
||||
|
||||
+ 年龄数据:原始的用户年龄数据为用户对应不同年龄段的概率,这里将概率最高的年龄段作为用户所处的年龄段;
|
||||
|
||||
**文档数据处理**
|
||||
|
||||
+ 发文时间:对于部分发文时间异常或者为空的数据,使用已有文档中最早的发文时间进行填充;
|
||||
+ 发文日期:将文档的发文时间,提取出对应的发文日期(年-月-日);
|
||||
+ 图片数量:对部分异常的脏数据,使用 $0$ 进行填充处理;
|
||||
+ 二级分类:对于存在多个二级分类的文档,从其选取一个作为其二级分类。优先选择不等于一级分类的二级分类,对于二级分类为空的文档使用一级分类进行填充;
|
||||
+ 关键词:
|
||||
+ 每篇文档均存在多个关键词,每个关键词也会对应一个权重,这里选取权重最高的关键词作为文章的唯一关键词;
|
||||
+ 文档中不同的关键词及权重是采用逗号进行隔开的,但部分关键词本来就包含逗号(如==你好,李焕英==),故相关函数还对此进行了特殊处理;
|
||||
|
||||
### 2.2.2 统计特征
|
||||
|
||||
统计特征的生成的程序为:**news_data_process.py**
|
||||
|
||||
+ 从文档发文到展示的时间差:对于每一个样本,统计对应文档从发文到展示的日期差;
|
||||
+ 用户特征统计:
|
||||
|
||||
+ 统计每个用户过去几天,所展现的文档总数;
|
||||
+ 统计每个用户过去几天,在不同类别文档(一级分类)上的展现总数;
|
||||
+ 统计每个用户过去几天,在不同类别文档(二级分类)上的展现总数;
|
||||
+ 统计每个用户过去几天,整体的点击率;
|
||||
+ 统计每个用户过去几天,对不同类别文档(一级分类)上的点击率;
|
||||
+ 统计每个用户过去几天,对不同类别文档(二级分类)上的点击率;
|
||||
+ 统计每个用户过去几天,消费时长的总和;
|
||||
+ 统计每个用户过去几天,在不同类别文档(一级分类)上的总消费时长;
|
||||
+ 统计每个用户过去几天,在不同类别文档(二级分类)上的总消费时长;
|
||||
+ 统计每个用户过去几天,在不同类别文档(一级分类)上的平均消费时长;
|
||||
+ 统计每个用户过去几天,在不同类别文档(二级分类)上的平均消费时长;
|
||||
+ 统计每个用户过去几天,在不同类别文档(一级分类)上的消费时长的方差;
|
||||
+ 统计每个用户过去几天,在不同类别文档(二级分类)上的消费时长的方差;
|
||||
+ 文档特征统计:
|
||||
|
||||
+ 统计每篇文档在过去几天,被展示的总次数;
|
||||
+ 统计各类别(一级分类)文档在过去几天,被展示的总次数;
|
||||
+ 统计各类别(二级分类)文档在过去几天,被展示的总次数;
|
||||
+ 统计每篇文档在过去几天,平均的被点击率;
|
||||
+ 统计各类别(一级分类)文档在过去几天,平均被点击率;
|
||||
+ 统计各类别(二级分类)文档在过去几天,平均被点击率;
|
||||
+ 统计每篇文档在过去几天,总的被消费时长;
|
||||
+ 统计每篇文档在过去几天,平均的被消费时长;
|
||||
+ 统计每篇文档在过去几天,被消费时长的方差;
|
||||
+ 统计各类别(一级分类)文档在过去几天,总的被消费时长;
|
||||
+ 统计各类别(一级分类)文档在过去几天,平均的被消费时长;
|
||||
+ 统计各类别(一级分类)文档在过去几天,被消费时长的方差;
|
||||
+ 统计各类别(二级分类)文档在过去几天,总的被消费时长;
|
||||
+ 统计各类别(二级分类)文档在过去几天,平均的被消费时长;
|
||||
+ 统计各类别(二级分类)文档在过去几天,被消费时长的方差;
|
||||
|
||||
|
||||
### 2.2.3 特征归一化和编码
|
||||
|
||||
+ 连续型特征:
|
||||
+ 连续型特征包含的主要是统计特征,这里对于空值统一使用 $0$ 进行填充;
|
||||
+ 之后,对所有的连续型特征进行对数归一化, 即取 $log$ 对数;
|
||||
|
||||
+ 类别型特征:
|
||||
|
||||
+ 类别型特征这里主要是通过 $LabelEncoder$ 的方式进行编码,以便后续模型处理为相应的 $Embedding$;
|
||||
|
||||
|
||||
|
||||
# 3. 排序模型
|
||||
|
||||
排序模型的执行程序存放在`rank/examples/`下,分别为`deepfm_news.py`和`deepfm_ppnet_news.py`。
|
||||
|
||||
## 3.1 DeepFM
|
||||
|
||||
DeepFM是2017年由华为与哈工大提出的排序模型,,模型主要包含两部分:FM部分+Deep部分。
|
||||
|
||||
+ FM部分:对不同特征域的Embedding进行两两交叉,以加强模型在浅层网络中的特征组合能力。
|
||||
+ Deep部分:多层感知机网络模型。通过对特征各个维度进行充分的特征交叉组合,来学习到更多非线性以及组合特征的信息。
|
||||
|
||||
论文链接:[[DeepFM: A Factorization-Machine based Neural Network for CTR Prediction (arxiv.org)](https://arxiv.org/abs/1703.04247)
|
||||
|
||||
**实验结果**
|
||||
|
||||
1. 参数设置
|
||||
|
||||
```yaml
|
||||
# data para
|
||||
seed: 48
|
||||
# model para
|
||||
embed_dim: 32
|
||||
drop_rate: 0.5
|
||||
use_bn: Ture
|
||||
hidden_units: [64, 128, 64]
|
||||
# compile para
|
||||
learning_rate: 0.001
|
||||
epochs: 20
|
||||
batch_size: 2048
|
||||
val_splite: 0.1
|
||||
patience: 5
|
||||
restore_best_weights: True
|
||||
```
|
||||
|
||||
2. 运行结果
|
||||
|
||||
```bash
|
||||
Epoch 1/20
|
||||
2653/2653 [==============================] - 47s 17ms/step - loss: 0.3921 - auc: 0.7287 - val_loss: 0.3628 - val_auc: 0.7588
|
||||
Epoch 2/20
|
||||
2653/2653 [==============================] - 44s 17ms/step - loss: 0.3619 - auc: 0.7616 - val_loss: 0.3581 - val_auc: 0.7647
|
||||
Epoch 3/20
|
||||
2653/2653 [==============================] - 44s 17ms/step - loss: 0.3569 - auc: 0.7705 - val_loss: 0.3561 - val_auc: 0.7682
|
||||
Epoch 4/20
|
||||
2653/2653 [==============================] - 47s 18ms/step - loss: 0.3548 - auc: 0.7754 - val_loss: 0.3557 - val_auc: 0.7699
|
||||
Epoch 5/20
|
||||
2653/2653 [==============================] - 47s 18ms/step - loss: 0.3540 - auc: 0.7777 - val_loss: 0.3560 - val_auc: 0.7702
|
||||
Epoch 6/20
|
||||
2653/2653 [==============================] - 46s 18ms/step - loss: 0.3536 - auc: 0.7788 - val_loss: 0.3557 - val_auc: 0.7708
|
||||
Epoch 7/20
|
||||
2653/2653 [==============================] - 45s 17ms/step - loss: 0.3533 - auc: 0.7797 - val_loss: 0.3556 - val_auc: 0.7714
|
||||
Epoch 8/20
|
||||
2653/2653 [==============================] - 45s 17ms/step - loss: 0.3532 - auc: 0.7802 - val_loss: 0.3558 - val_auc: 0.7712
|
||||
Epoch 9/20
|
||||
2653/2653 [==============================] - 46s 17ms/step - loss: 0.3530 - auc: 0.7806 - val_loss: 0.3560 - val_auc: 0.7713
|
||||
Epoch 10/20
|
||||
2653/2653 [==============================] - 46s 17ms/step - loss: 0.3530 - auc: 0.7808 - val_loss: 0.3560 - val_auc: 0.7711
|
||||
Epoch 11/20
|
||||
2653/2653 [==============================] - 45s 17ms/step - loss: 0.3529 - auc: 0.7811 - val_loss: 0.3560 - val_auc: 0.7715
|
||||
Epoch 12/20
|
||||
2653/2653 [==============================] - 46s 17ms/step - loss: 0.3528 - auc: 0.7813 - val_loss: 0.3557 - val_auc: 0.7718
|
||||
251/251 [==============================] - 3s 11ms/step - loss: 0.3719 - auc: 0.7508
|
||||
test AUC: 0.750784
|
||||
```
|
||||
|
||||
## 3.2 DeepFM+PPNet
|
||||
|
||||
将DeepFM模型中,DNN 模块替换为PPNet模型:
|
||||
|
||||
+ 在语音识别领域中,2014 年和 2016 年提出的 LHUC 算法(learning hidden unit contributions)核心思想是做说话人自适应(speaker adaptation),其中一个关键突破是在 DNN 网络中,为每个说话人学习一个特定的隐式单位贡献(hidden unit contributions),来提升不同说话人的语音识别效果。
|
||||
+ 借鉴 LHUC 的思想,快手推荐团队在精排模型上展开了尝试。经过多次迭代优化,推荐团队设计出一种 gating 机制,可以增加 DNN 网络参数个性化并能够让模型快速收敛。快手把这种模型叫做 **PPNet(Parameter Personalized Net)**。
|
||||
|
||||
参考链接:[1.9万亿参数量,快手落地业界首个万亿参数推荐精排模型](https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&idx=4&mid=2650808254&scene=21&sn=6c295c8306b7339858f8ecfadfc9d698#wechat_redirect)
|
||||
|
||||
**实验结果:**
|
||||
|
||||
1. 参数设置
|
||||
|
||||
```yaml
|
||||
# data para
|
||||
seed: 48
|
||||
# model para
|
||||
embed_dim: 32
|
||||
drop_rate: 0.5
|
||||
ppnet_size: 256
|
||||
ppnet_features: ['user_id', '一级分类', '年龄']
|
||||
use_bn: Ture
|
||||
hidden_units: [64, 128, 64]
|
||||
# compile para
|
||||
learning_rate: 0.001
|
||||
epochs: 20
|
||||
batch_size: 2048
|
||||
val_splite: 0.1
|
||||
patience: 5
|
||||
restore_best_weights: True
|
||||
```
|
||||
|
||||
2. 运行结果
|
||||
|
||||
```bash
|
||||
Epoch 1/20
|
||||
2653/2653 [==============================] - 56s 20ms/step - loss: 0.3929 - auc: 0.7303 - val_loss: 0.3648 - val_auc: 0.7568
|
||||
Epoch 2/20
|
||||
2653/2653 [==============================] - 53s 20ms/step - loss: 0.3620 - auc: 0.7622 - val_loss: 0.3591 - val_auc: 0.7651
|
||||
Epoch 3/20
|
||||
2653/2653 [==============================] - 55s 21ms/step - loss: 0.3578 - auc: 0.7706 - val_loss: 0.3580 - val_auc: 0.7690
|
||||
Epoch 4/20
|
||||
2653/2653 [==============================] - 53s 20ms/step - loss: 0.3560 - auc: 0.7755 - val_loss: 0.3587 - val_auc: 0.7701
|
||||
Epoch 5/20
|
||||
2653/2653 [==============================] - 54s 20ms/step - loss: 0.3551 - auc: 0.7787 - val_loss: 0.3580 - val_auc: 0.7706
|
||||
Epoch 6/20
|
||||
2653/2653 [==============================] - 55s 21ms/step - loss: 0.3545 - auc: 0.7809 - val_loss: 0.3587 - val_auc: 0.7718
|
||||
Epoch 7/20
|
||||
2653/2653 [==============================] - 54s 20ms/step - loss: 0.3541 - auc: 0.7829 - val_loss: 0.3586 - val_auc: 0.7720
|
||||
Epoch 8/20
|
||||
2653/2653 [==============================] - 53s 20ms/step - loss: 0.3538 - auc: 0.7842 - val_loss: 0.3587 - val_auc: 0.7721
|
||||
251/251 [==============================] - 4s 13ms/step - loss: 0.3686 - auc: 0.7543
|
||||
test AUC: 0.754304
|
||||
```
|
||||
|
||||
|
||||
|
||||
# 4. 程序执行
|
||||
|
||||
```bash
|
||||
# 数据预处理
|
||||
1. user&doc_data_process.py
|
||||
2. train&test_data_split.py
|
||||
3. news_data_process.py
|
||||
|
||||
# 排序模型
|
||||
4. deepfm_news.py 或 deepfm_ppnet_news.py
|
||||
```
|
||||
|
||||
|
||||
|
||||
# Requirements
|
||||
|
||||
- Tensorflow2.5 (GPU)
|
||||
- Numpy
|
||||
- Pandas
|
||||
- Swifter
|
||||
- Sklearn
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Binary file not shown.
Binary file not shown.
@@ -0,0 +1,39 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : run_deepfm.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/1/27
|
||||
|
||||
|
||||
from tensorflow.keras.callbacks import EarlyStopping
|
||||
from tensorflow.keras.optimizers import Adam
|
||||
from tensorflow.keras.metrics import AUC
|
||||
|
||||
from models.deepfm import DeepFM
|
||||
|
||||
|
||||
def run(train_data, test_data, feature_columns, args):
|
||||
# 1. 建模
|
||||
model = DeepFM(feature_columns=feature_columns,
|
||||
dnn_hidden_units=args.hidden_units,
|
||||
dnn_drop_rate=args.drop_rate,
|
||||
dnn_use_bn=args.use_bn)
|
||||
# 2. 编译
|
||||
model.compile(optimizer=Adam(learning_rate=args.learning_rate),
|
||||
loss="binary_crossentropy",
|
||||
metrics=[AUC()])
|
||||
model.summary()
|
||||
# 3. 训练
|
||||
model.fit(train_data[0],
|
||||
train_data[1],
|
||||
batch_size=args.batch_size,
|
||||
epochs=args.epochs,
|
||||
callbacks=[EarlyStopping(monitor='val_loss',
|
||||
patience=args.patience,
|
||||
mode='min',
|
||||
restore_best_weights=args.restore_best_weights)],
|
||||
validation_split=args.val_splite,
|
||||
)
|
||||
# 4. 测试
|
||||
print('test AUC: %f' % model.evaluate(test_data[0], test_data[1], batch_size=args.batch_size)[1])
|
||||
@@ -0,0 +1,42 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : run_deepfm_ppnet.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/2/8
|
||||
|
||||
|
||||
from tensorflow.keras.callbacks import EarlyStopping
|
||||
from tensorflow.keras.optimizers import Adam
|
||||
from tensorflow.keras.metrics import AUC
|
||||
|
||||
from models.deepfm_ppnet import DeepFM_PPNet
|
||||
|
||||
|
||||
def run(train_data, test_data, feature_columns, args):
|
||||
# 1. 建模
|
||||
model = DeepFM_PPNet(
|
||||
feature_columns=feature_columns,
|
||||
ppnet_size=args.ppnet_size,
|
||||
ppnet_features=args.ppnet_features,
|
||||
dnn_hidden_units=args.hidden_units,
|
||||
dnn_drop_rate=args.drop_rate,
|
||||
dnn_use_bn=args.use_bn)
|
||||
# 2. 编译
|
||||
model.compile(optimizer=Adam(learning_rate=args.learning_rate),
|
||||
loss="binary_crossentropy",
|
||||
metrics=[AUC()])
|
||||
model.summary()
|
||||
# 3. 训练
|
||||
model.fit(train_data[0],
|
||||
train_data[1],
|
||||
batch_size=args.batch_size,
|
||||
epochs=args.epochs,
|
||||
callbacks=[EarlyStopping(monitor='val_loss',
|
||||
patience=args.patience,
|
||||
mode='min',
|
||||
restore_best_weights=args.restore_best_weights)],
|
||||
validation_split=args.val_splite,
|
||||
)
|
||||
# 4. 测试
|
||||
print('test AUC: %f' % model.evaluate(test_data[0], test_data[1], batch_size=args.batch_size)[1])
|
||||
Binary file not shown.
@@ -0,0 +1,44 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @File : data_compression.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/2/7
|
||||
|
||||
|
||||
import gc
|
||||
import numpy as np
|
||||
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
|
||||
def reduce_mem(df):
|
||||
start_mem = df.memory_usage().sum() / 1024 ** 2
|
||||
print(f'开始进行内存压缩...')
|
||||
for col in tqdm(df.columns):
|
||||
col_type = df[col].dtypes
|
||||
if col_type != object:
|
||||
c_min = df[col].min()
|
||||
c_max = df[col].max()
|
||||
if str(col_type)[:3] == 'int':
|
||||
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
|
||||
df[col] = df[col].astype(np.int8)
|
||||
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
|
||||
df[col] = df[col].astype(np.int16)
|
||||
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
|
||||
df[col] = df[col].astype(np.int32)
|
||||
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
|
||||
df[col] = df[col].astype(np.int64)
|
||||
elif str(col_type)[:5] == 'float':
|
||||
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
|
||||
df[col] = df[col].astype(np.float16)
|
||||
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
|
||||
df[col] = df[col].astype(np.float32)
|
||||
else:
|
||||
df[col] = df[col].astype(np.float64)
|
||||
|
||||
end_mem = df.memory_usage().sum() / 1024 ** 2
|
||||
print('{:.2f} Mb, {:.2f} Mb ({:.2f} %)'.format(start_mem, end_mem, 100 * (start_mem - end_mem) / start_mem))
|
||||
gc.collect()
|
||||
|
||||
return df
|
||||
@@ -0,0 +1,16 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @file : set_device.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/2/7
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
|
||||
def set_GPU():
|
||||
gpus = tf.config.experimental.list_physical_devices('GPU')
|
||||
print(gpus)
|
||||
|
||||
for gpu in gpus:
|
||||
tf.config.experimental.set_memory_growth(gpu, True)
|
||||
@@ -0,0 +1,20 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
# @file : set_parament.py
|
||||
# @Author: xLyons
|
||||
# @IDE : PyCharm
|
||||
# @Time : 2022/2/7
|
||||
|
||||
import yaml
|
||||
from collections import namedtuple
|
||||
|
||||
|
||||
def get_args(yaml_path):
|
||||
with open(yaml_path, 'r', encoding='utf-8') as f:
|
||||
para_dict = yaml.load(f.read(), Loader=yaml.FullLoader)
|
||||
|
||||
ps = namedtuple('parser', list(para_dict.keys()))
|
||||
args = ps(**para_dict)
|
||||
f.close()
|
||||
|
||||
return args
|
||||
@@ -0,0 +1,450 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "b06bec9d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import gc\n",
|
||||
"import os\n",
|
||||
"import math\n",
|
||||
"import pickle\n",
|
||||
"\n",
|
||||
"import numpy as np\n",
|
||||
"import pandas as pd\n",
|
||||
"from tqdm.auto import tqdm\n",
|
||||
"from operator import itemgetter\n",
|
||||
"\n",
|
||||
"from sklearn.utils import shuffle\n",
|
||||
"from collections import defaultdict\n",
|
||||
"from metric import PrintMetric\n",
|
||||
"\n",
|
||||
"import warnings\n",
|
||||
"warnings.filterwarnings(\"ignore\")\n",
|
||||
"\n",
|
||||
"raw_data_path = 'D:/news-rec/dataset/raw_data'\n",
|
||||
"new_data_path = 'D:/news-rec/dataset/recall_data'\n",
|
||||
"\n",
|
||||
"os.makedirs(new_data_path, exist_ok=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "4479018f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " user_id 设备名称 操作系统 所在省 所在市 \\\n0 1000372820 TAS-AN00 Android 广东 广州 \n10 1001440812 iPad IOS NaN NaN \n16 1001771644 V1901A Android 陕西 宝鸡 \n17 1001773994 STK-AL00 Android 广东 河源 \n142 1017050854 DUB-AL00 Android 湖北 武汉 \n\n 年龄 \\\n0 A_0_24:0.404616,A_25_29:0.059027,A_30_39:0.516... \n10 A_0_24:0.312738,A_25_29:0.261741,A_30_39:0.268... \n16 A_0_24:0.445645,A_25_29:0.330315,A_30_39:0.153... \n17 A_0_24:0.497841,A_25_29:0.245965,A_30_39:0.219... \n142 A_0_24:0.008895,A_25_29:0.067247,A_30_39:0.824... \n\n 性别 \n0 female:0.051339,male:0.948661 \n10 female:0.907997,male:0.092003 \n16 female:0.049787,male:0.950213 \n17 female:0.117317,male:0.882683 \n142 female:0.519291,male:0.480709 ",
|
||||
"text/html": "<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>user_id</th>\n <th>设备名称</th>\n <th>操作系统</th>\n <th>所在省</th>\n <th>所在市</th>\n <th>年龄</th>\n <th>性别</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>1000372820</td>\n <td>TAS-AN00</td>\n <td>Android</td>\n <td>广东</td>\n <td>广州</td>\n <td>A_0_24:0.404616,A_25_29:0.059027,A_30_39:0.516...</td>\n <td>female:0.051339,male:0.948661</td>\n </tr>\n <tr>\n <th>10</th>\n <td>1001440812</td>\n <td>iPad</td>\n <td>IOS</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>A_0_24:0.312738,A_25_29:0.261741,A_30_39:0.268...</td>\n <td>female:0.907997,male:0.092003</td>\n </tr>\n <tr>\n <th>16</th>\n <td>1001771644</td>\n <td>V1901A</td>\n <td>Android</td>\n <td>陕西</td>\n <td>宝鸡</td>\n <td>A_0_24:0.445645,A_25_29:0.330315,A_30_39:0.153...</td>\n <td>female:0.049787,male:0.950213</td>\n </tr>\n <tr>\n <th>17</th>\n <td>1001773994</td>\n <td>STK-AL00</td>\n <td>Android</td>\n <td>广东</td>\n <td>河源</td>\n <td>A_0_24:0.497841,A_25_29:0.245965,A_30_39:0.219...</td>\n <td>female:0.117317,male:0.882683</td>\n </tr>\n <tr>\n <th>142</th>\n <td>1017050854</td>\n <td>DUB-AL00</td>\n <td>Android</td>\n <td>湖北</td>\n <td>武汉</td>\n <td>A_0_24:0.008895,A_25_29:0.067247,A_30_39:0.824...</td>\n <td>female:0.519291,male:0.480709</td>\n </tr>\n </tbody>\n</table>\n</div>"
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"user_info = pd.read_csv(raw_data_path + '/user_info_5w.csv', sep='\\t', index_col=0)\n",
|
||||
"user_info.columns = [\"user_id\", \"设备名称\", \"操作系统\", \"所在省\", \"所在市\", \"年龄\",\"性别\"]\n",
|
||||
"\n",
|
||||
"user_info.head()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "22d466d5",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " item_id 标题 发文时间 图片数量 一级分类 \\\n0 361653323 疫情谣言粉碎机丨接种新冠疫苗后用麻药或致死?盘点最新疫情谣言,别被忽悠了 1624522285000 1 健康 \n1 426732705 实拍本田飞度:空间真大,8万出头工薪族可选,但内饰能忍? 1610808303000 9 汽车 \n2 430221183 搭载135kw电机比亚迪秦plus纯电动版外观更精致 1612581556000 2 汽车 \n3 441756326 【提车作业】不顾他人眼光帕萨特phev俘获30老男人浪子心 1618825835000 23 汽车 \n4 443485341 魏延有反骨之心都能重用,赵云忠心为什么却不被重用? 1619484501000 4 历史 \n\n 二级分类 关键词 \n0 健康/疾病防护治疗及西医用药 医生:14.760494,吸烟:16.474872,板蓝根:15.597788,板蓝根^^熏... \n1 汽车/买车 155n:8.979802,polo:7.951116,中控台:5.954278,中网:7.... \n2 汽车/买车 etc:12.055207,代表:8.878175,内饰:5.342025,刀片:9.453... \n3 汽车/买车 丰田凯美瑞:12.772149,充电器:8.394001,品牌:8.436843,城市:7.... \n4 历史/中国史 三国:8.979797,五虎将:13.072728,人才:7.532783,保镖:6.811... ",
|
||||
"text/html": "<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>item_id</th>\n <th>标题</th>\n <th>发文时间</th>\n <th>图片数量</th>\n <th>一级分类</th>\n <th>二级分类</th>\n <th>关键词</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>361653323</td>\n <td>疫情谣言粉碎机丨接种新冠疫苗后用麻药或致死?盘点最新疫情谣言,别被忽悠了</td>\n <td>1624522285000</td>\n <td>1</td>\n <td>健康</td>\n <td>健康/疾病防护治疗及西医用药</td>\n <td>医生:14.760494,吸烟:16.474872,板蓝根:15.597788,板蓝根^^熏...</td>\n </tr>\n <tr>\n <th>1</th>\n <td>426732705</td>\n <td>实拍本田飞度:空间真大,8万出头工薪族可选,但内饰能忍?</td>\n <td>1610808303000</td>\n <td>9</td>\n <td>汽车</td>\n <td>汽车/买车</td>\n <td>155n:8.979802,polo:7.951116,中控台:5.954278,中网:7....</td>\n </tr>\n <tr>\n <th>2</th>\n <td>430221183</td>\n <td>搭载135kw电机比亚迪秦plus纯电动版外观更精致</td>\n <td>1612581556000</td>\n <td>2</td>\n <td>汽车</td>\n <td>汽车/买车</td>\n <td>etc:12.055207,代表:8.878175,内饰:5.342025,刀片:9.453...</td>\n </tr>\n <tr>\n <th>3</th>\n <td>441756326</td>\n <td>【提车作业】不顾他人眼光帕萨特phev俘获30老男人浪子心</td>\n <td>1618825835000</td>\n <td>23</td>\n <td>汽车</td>\n <td>汽车/买车</td>\n <td>丰田凯美瑞:12.772149,充电器:8.394001,品牌:8.436843,城市:7....</td>\n </tr>\n <tr>\n <th>4</th>\n <td>443485341</td>\n <td>魏延有反骨之心都能重用,赵云忠心为什么却不被重用?</td>\n <td>1619484501000</td>\n <td>4</td>\n <td>历史</td>\n <td>历史/中国史</td>\n <td>三国:8.979797,五虎将:13.072728,人才:7.532783,保镖:6.811...</td>\n </tr>\n </tbody>\n</table>\n</div>"
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"doc_info = pd.read_table(raw_data_path + '/doc_info.txt', sep='\\t')\n",
|
||||
"doc_info.columns = [\"item_id\", \"标题\", \"发文时间\", \"图片数量\", \"一级分类\", \"二级分类\", \"关键词\"]\n",
|
||||
"\n",
|
||||
"item2cate = dict(zip(doc_info['item_id'], doc_info['一级分类']))\n",
|
||||
"doc_info.head()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "7cf3ff94",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " user_id item_id 展现时间 网路环境 刷新次数 展现位置 是否点击 消费时长(秒)\n0 1000014754 463510256 1624843756147 5 0 16 0 0\n1 1000014754 463852707 1624843756147 5 0 13 1 80\n2 1000014754 464757134 1625052999841 5 0 13 1 1050\n3 1000014754 464617167 1625052999841 5 0 16 1 286\n4 1000014754 465426190 1625382421168 5 0 5 0 0",
|
||||
"text/html": "<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>user_id</th>\n <th>item_id</th>\n <th>展现时间</th>\n <th>网路环境</th>\n <th>刷新次数</th>\n <th>展现位置</th>\n <th>是否点击</th>\n <th>消费时长(秒)</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>1000014754</td>\n <td>463510256</td>\n <td>1624843756147</td>\n <td>5</td>\n <td>0</td>\n <td>16</td>\n <td>0</td>\n <td>0</td>\n </tr>\n <tr>\n <th>1</th>\n <td>1000014754</td>\n <td>463852707</td>\n <td>1624843756147</td>\n <td>5</td>\n <td>0</td>\n <td>13</td>\n <td>1</td>\n <td>80</td>\n </tr>\n <tr>\n <th>2</th>\n <td>1000014754</td>\n <td>464757134</td>\n <td>1625052999841</td>\n <td>5</td>\n <td>0</td>\n <td>13</td>\n <td>1</td>\n <td>1050</td>\n </tr>\n <tr>\n <th>3</th>\n <td>1000014754</td>\n <td>464617167</td>\n <td>1625052999841</td>\n <td>5</td>\n <td>0</td>\n <td>16</td>\n <td>1</td>\n <td>286</td>\n </tr>\n <tr>\n <th>4</th>\n <td>1000014754</td>\n <td>465426190</td>\n <td>1625382421168</td>\n <td>5</td>\n <td>0</td>\n <td>5</td>\n <td>0</td>\n <td>0</td>\n </tr>\n </tbody>\n</table>\n</div>"
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"all_data = pd.read_csv(raw_data_path + '/train_data_5w.csv', sep='\\t', index_col=0)\n",
|
||||
"all_data.columns = [\"user_id\", \"item_id\", \"展现时间\", \"网路环境\", \"刷新次数\", \"展现位置\", \"是否点击\", \"消费时长(秒)\"]\n",
|
||||
"\n",
|
||||
"all_data.head()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " user_id item_id 展现时间 网路环境 刷新次数 展现位置 是否点击 消费时长(秒) \\\n0 1000014754 463510256 2021-06-28 01:29:16 5 0 16 0 0 \n1 1000014754 463852707 2021-06-28 01:29:16 5 0 13 1 80 \n2 1000014754 464757134 2021-06-30 11:36:39 5 0 13 1 1050 \n3 1000014754 464617167 2021-06-30 11:36:39 5 0 16 1 286 \n4 1000014754 465426190 2021-07-04 07:07:01 5 0 5 0 0 \n\n 展现时间_日期 \n0 28 \n1 28 \n2 30 \n3 30 \n4 4 ",
|
||||
"text/html": "<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>user_id</th>\n <th>item_id</th>\n <th>展现时间</th>\n <th>网路环境</th>\n <th>刷新次数</th>\n <th>展现位置</th>\n <th>是否点击</th>\n <th>消费时长(秒)</th>\n <th>展现时间_日期</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>1000014754</td>\n <td>463510256</td>\n <td>2021-06-28 01:29:16</td>\n <td>5</td>\n <td>0</td>\n <td>16</td>\n <td>0</td>\n <td>0</td>\n <td>28</td>\n </tr>\n <tr>\n <th>1</th>\n <td>1000014754</td>\n <td>463852707</td>\n <td>2021-06-28 01:29:16</td>\n <td>5</td>\n <td>0</td>\n <td>13</td>\n <td>1</td>\n <td>80</td>\n <td>28</td>\n </tr>\n <tr>\n <th>2</th>\n <td>1000014754</td>\n <td>464757134</td>\n <td>2021-06-30 11:36:39</td>\n <td>5</td>\n <td>0</td>\n <td>13</td>\n <td>1</td>\n <td>1050</td>\n <td>30</td>\n </tr>\n <tr>\n <th>3</th>\n <td>1000014754</td>\n <td>464617167</td>\n <td>2021-06-30 11:36:39</td>\n <td>5</td>\n <td>0</td>\n <td>16</td>\n <td>1</td>\n <td>286</td>\n <td>30</td>\n </tr>\n <tr>\n <th>4</th>\n <td>1000014754</td>\n <td>465426190</td>\n <td>2021-07-04 07:07:01</td>\n <td>5</td>\n <td>0</td>\n <td>5</td>\n <td>0</td>\n <td>0</td>\n <td>4</td>\n </tr>\n </tbody>\n</table>\n</div>"
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"all_data['展现时间'] = all_data['展现时间'].astype('str')\n",
|
||||
"all_data['展现时间'] = all_data['展现时间'].apply(lambda x: int(x[:10]))\n",
|
||||
"\n",
|
||||
"all_data['展现时间'] = pd.to_datetime(all_data['展现时间'], unit='s', errors='coerce')\n",
|
||||
"all_data['展现时间_日期'] = all_data['展现时间'].dt.day\n",
|
||||
"\n",
|
||||
"all_data.head()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "73c9843e",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": "179"
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"mode = 'debug'\n",
|
||||
"\n",
|
||||
"if mode == 'debug':\n",
|
||||
" all_data = shuffle(all_data)\n",
|
||||
" all_data.reset_index(drop=True)\n",
|
||||
"\n",
|
||||
" train_data = all_data[(all_data['展现时间_日期'] >= 5) & (all_data['展现时间_日期'] < 6)]\n",
|
||||
" test_data = all_data.loc[all_data['展现时间_日期'] == 6, :]\n",
|
||||
"else:\n",
|
||||
" train_data = all_data[(all_data['展现时间_日期'] >= 1) & (all_data['展现时间_日期'] < 6)]\n",
|
||||
" test_data = all_data.loc[all_data['展现时间_日期'] == 6, :]\n",
|
||||
"\n",
|
||||
"# 训练集按照时间排序\n",
|
||||
"train_data.sort_values('展现时间', inplace=True)\n",
|
||||
"\n",
|
||||
"del all_data, doc_info, user_info\n",
|
||||
"gc.collect()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"15655\n",
|
||||
"33664\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(train_data['user_id'].nunique())\n",
|
||||
"print(train_data['item_id'].nunique())"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class ItemCF(object):\n",
|
||||
" def __init__(self, his_data, item2cate):\n",
|
||||
" self.user_set = set()\n",
|
||||
" self.his_data = his_data\n",
|
||||
" self.item2cate = item2cate\n",
|
||||
"\n",
|
||||
" self.item_sim_matrix = dict()\n",
|
||||
" self.item_interacted_num = defaultdict(int)\n",
|
||||
"\n",
|
||||
" def calculate_similarity_matrix(self):\n",
|
||||
" # his_data已经按照时间排序....\n",
|
||||
" user2items = self.his_data.groupby('user_id')['item_id'].apply(list).reset_index()\n",
|
||||
" # print(f'计算ItemCF第一阶段...')\n",
|
||||
" pbar = tqdm(total=user2items.shape[0])\n",
|
||||
" for idx, row in user2items.iterrows():\n",
|
||||
" self.user_set.add(row['user_id'])\n",
|
||||
" for idx1, item_1 in enumerate(row['item_id']):\n",
|
||||
" self.item_interacted_num[item_1] += 1\n",
|
||||
" self.item_sim_matrix.setdefault(item_1, {})\n",
|
||||
" for idx2, item_2 in enumerate(row['item_id']):\n",
|
||||
" if item_1 == item_2:\n",
|
||||
" continue\n",
|
||||
" self.item_sim_matrix[item_1].setdefault(item_2, 0)\n",
|
||||
" # 新闻阅读可能具有连续性,后续阅读的新闻与前面阅读的新闻相似度更高\n",
|
||||
" related_score = 1 if idx1 > idx2 else 0.8\n",
|
||||
" # 如果二者类别相同,新闻之间的相似度更高\n",
|
||||
" related_score *= 1 if item2cate.get(item_1, None) == item2cate.get(item_2, None) else 0.5\n",
|
||||
"\n",
|
||||
" # 活跃用户在计算物品之间相似度时,贡献小于非活跃用户\n",
|
||||
" self.item_sim_matrix[item_1][item_2] += related_score / math.log(1 + len(row['item_id']))\n",
|
||||
" pbar.update(1)\n",
|
||||
" pbar.close()\n",
|
||||
"\n",
|
||||
" # 理论上,物品之间共现的用户越多,相似度越高\n",
|
||||
" # 但是,热门物品与很多物品之间的相似度都很高\n",
|
||||
" # print(f'计算ItemCF第二阶段...')\n",
|
||||
" for item_1, related_items in tqdm(self.item_sim_matrix.items()):\n",
|
||||
" for item_2, weight in related_items.items():\n",
|
||||
" # 打压热门物品\n",
|
||||
" self.item_sim_matrix[item_1][item_2] = \\\n",
|
||||
" weight / math.sqrt(self.item_interacted_num[item_1] * self.item_interacted_num[item_2])\n",
|
||||
"\n",
|
||||
" def __call__(self, users, _n=50, _topk=20):\n",
|
||||
" print(f'开始ItemCF召回: Recall@{topk}-Near@{_n}')\n",
|
||||
" user2items = self.his_data.groupby('user_id')['item_id'].apply(list)\n",
|
||||
" popular_items = [val[0] for val in sorted(\n",
|
||||
" self.item_interacted_num.items(), key=lambda x: x[1], reverse=True)[:_topk]]\n",
|
||||
"\n",
|
||||
" user_rec = {}\n",
|
||||
" for user_id in tqdm(users):\n",
|
||||
" # 新用户,直接推荐热门物品\n",
|
||||
" if user_id not in self.user_set:\n",
|
||||
" user_rec[user_id] = popular_items\n",
|
||||
" else:\n",
|
||||
" rank = defaultdict(int)\n",
|
||||
" his_items = user2items.loc[user_id]\n",
|
||||
" # 遍历用户历史交互物品\n",
|
||||
" for his_item in his_items:\n",
|
||||
" # 选取与his_item相似度最高的_n个物品\n",
|
||||
" for candidate_item, item_smi_score in sorted(self.item_sim_matrix[his_item].items(),\n",
|
||||
" key=itemgetter(1), reverse=True)[:_n]:\n",
|
||||
" # 如果推荐的物品已经被购买过了,是否纳入推荐(可跳过)\n",
|
||||
" # if candidate_item in his_items:\n",
|
||||
" # continue\n",
|
||||
" rank[candidate_item] += item_smi_score\n",
|
||||
" rec_items = [item[0] for item in sorted(rank.items(), key=itemgetter(1), reverse=True)[:_topk]]\n",
|
||||
" # 如果推荐的物品不够,用热门物品进行填充\n",
|
||||
" rec_items += popular_items[:topk-len(rec_items)]\n",
|
||||
" user_rec[user_id] = rec_items\n",
|
||||
"\n",
|
||||
" return user_rec"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"icf_cls_path = os.path.join(new_data_path, 'item_cf')\n",
|
||||
"os.makedirs(icf_cls_path, exist_ok=True)"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " 0%| | 0/15655 [00:00<?, ?it/s]",
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"version_major": 2,
|
||||
"version_minor": 0,
|
||||
"model_id": "d5c3c1e99e764b40a4dac12d60bc4b77"
|
||||
}
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " 0%| | 0/33664 [00:00<?, ?it/s]",
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"version_major": 2,
|
||||
"version_minor": 0,
|
||||
"model_id": "9011a3e044c948f9850a19db02e464bf"
|
||||
}
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"demo_icf_path = os.path.join(icf_cls_path, mode+'_ifc.pkl')\n",
|
||||
"if os.path.exists(demo_icf_path):\n",
|
||||
" with open(demo_icf_path, 'rb') as file:\n",
|
||||
" demo_icf = pickle.loads(file.read())\n",
|
||||
" file.close()\n",
|
||||
"else:\n",
|
||||
" demo_icf = ItemCF(train_data, item2cate)\n",
|
||||
" demo_icf.calculate_similarity_matrix()\n",
|
||||
" demo_icf_pkl = pickle.dumps(demo_icf)\n",
|
||||
"\n",
|
||||
" output_icf = open(demo_icf_path, 'wb')\n",
|
||||
" output_icf.write(demo_icf_pkl)\n",
|
||||
" output_icf.close()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"开始ItemCF召回: Recall@100-Near@50\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " 0%| | 0/13792 [00:00<?, ?it/s]",
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"version_major": 2,
|
||||
"version_minor": 0,
|
||||
"model_id": "afe3cbc4db0f423c9a62c7bede9befa2"
|
||||
}
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"n, topk = 50, 100\n",
|
||||
"\n",
|
||||
"# 召回\n",
|
||||
"test_users = test_data['user_id'].unique()\n",
|
||||
"icf_rec_result = demo_icf(test_users, n, topk)\n",
|
||||
"\n",
|
||||
"test_user_group = test_data.groupby('user_id')['item_id'].agg(list).reset_index()\n",
|
||||
"test_pred = [icf_rec_result[user_id] for user_id in test_user_group['user_id']]\n",
|
||||
"test_true = test_user_group['item_id'].to_list()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"MAP@100: 0.016906571748779006\n",
|
||||
"Recall@100: 0.15798311228206416\n",
|
||||
"Precision@100: 0.027745069605568447\n",
|
||||
"F1@100: 0.03914852311427278\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"PrintMetric(test_true, test_pred, topk)"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"outputs": [],
|
||||
"source": [],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.8.12"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
2063
codes/news_recsys/news_rec_server/recprocess/recall/i2i_pop.ipynb
Normal file
2063
codes/news_recsys/news_rec_server/recprocess/recall/i2i_pop.ipynb
Normal file
File diff suppressed because one or more lines are too long
@@ -0,0 +1,101 @@
|
||||
import os
|
||||
import sys
|
||||
sys.path.append("../../")
|
||||
from conf.proj_path import log_data_path, user_info_path, doc_info_path
|
||||
import pandas as pd
|
||||
|
||||
|
||||
class RegionRecall(object):
|
||||
def __init__(self, log_data_path, user_info_path, doc_info_path):
|
||||
super().__init__()
|
||||
self.log_data_path = log_data_path
|
||||
self.user_info_path = user_info_path
|
||||
self.doc_info_path = doc_info_path
|
||||
self.read_and_process_data()
|
||||
|
||||
def read_and_process_data(self):
|
||||
"""读取并处理数据
|
||||
"""
|
||||
log_columns = ['user_id', 'article_id', 'expo_time', 'net_status', 'flush_nums', 'expo_position', 'click', 'duration']
|
||||
user_columns = ['user_id', 'device', 'os', 'province', 'city', 'age','gender']
|
||||
doc_columns = ['article_id', 'title', 'ctime', 'img_num', 'cate','sub_cate', 'key_words']
|
||||
self.train_log_df = pd.read_csv(self.log_data_path, usecols=log_columns, sep='\t')
|
||||
self.doc_info_df = pd.read_csv(self.doc_info_path, names=doc_columns, sep='\t')
|
||||
self.user_info_df = pd.read_csv(self.user_info_path, usecols=user_columns, sep='\t')
|
||||
# 删除重复数据
|
||||
self.train_log_df = self.train_log_df.drop_duplicates(keep='last')
|
||||
self.doc_info_df = self.doc_info_df.drop_duplicates(keep='last')
|
||||
self.user_info_df = self.user_info_df.drop_duplicates(keep='last')
|
||||
# 转换成天的日期,可以用来筛选数据
|
||||
self.train_log_df['expo_time_day'] = pd.to_datetime(self.train_log_df['expo_time'], unit='ms').dt.strftime('%Y_%m_%d')
|
||||
print("read_and_process_data success...")
|
||||
|
||||
def get_article_stat_data(self, train_df, doc_info_df):
|
||||
"""统计所有文章的点击和曝光次数,以及点击率(点击次数 / 曝光次数)
|
||||
"""
|
||||
# 日志数据去重, 保留最后一条记录
|
||||
train_df = train_df.drop_duplicates(keep='last')
|
||||
# 统计曝光
|
||||
expo_num_s = train_df.groupby('article_id')['user_id'].count()
|
||||
expo_num_df = pd.DataFrame({'article_id': expo_num_s.index, 'expo_num': expo_num_s.values})
|
||||
# 统计点击
|
||||
click_num_s = train_df.groupby('article_id')['click'].sum()
|
||||
click_num_df = pd.DataFrame({'article_id': click_num_s.index, 'click_num': click_num_s.values})
|
||||
article_df = pd.merge(expo_num_df, click_num_df, how='left', on='article_id')
|
||||
# 拼接文章信息
|
||||
article_df = pd.merge(article_df, doc_info_df[['article_id', 'ctime', 'cate']], how='left', on='article_id')
|
||||
article_df['click_rate'] = article_df['click_num'] / article_df['expo_num']
|
||||
return article_df
|
||||
|
||||
def get_province_articles(self, df, topK, cur_time):
|
||||
"""筛选和过滤规则, 里面的超参都可以根据业务数据的具体分布进行修改
|
||||
"""
|
||||
df['ctime_date'] = pd.to_datetime(df['ctime'], unit='ms')
|
||||
# 时间差
|
||||
df['delta_time'] = pd.to_datetime([cur_time] * df.shape[0]) - df['ctime_date']
|
||||
# 保留最近三天的新闻,保证新闻的时效性
|
||||
df = df[df['delta_time'].dt.days >= 3].reset_index(drop=True)
|
||||
# expo_num 过滤
|
||||
df = df[df['expo_num'] >= 1000].reset_index(drop=True)
|
||||
# 点击率
|
||||
df = df[df['click_rate'] >= 0.1].reset_index(drop=True)
|
||||
# 按照点击率倒排
|
||||
df = df.sort_values('click_rate', ascending=False).reset_index(drop=True)
|
||||
# 数据格式:article_id:cate:click_rate
|
||||
df['article_id_and_click_rate'] = df.apply(lambda x: str(\
|
||||
x['article_id']) + ':' + str(x['cate']) + ':' + str(round(x['click_rate'], 5)), axis=1)
|
||||
article_list = df['article_id_and_click_rate'].values[:topK]
|
||||
return article_list
|
||||
|
||||
def province_recall(self, N, cur_time):
|
||||
article_df = self.get_article_stat_data(self.train_log_df, self.doc_info_df)
|
||||
region_articles_df = pd.merge(self.train_log_df, self.user_info_df, how='left', on='user_id')
|
||||
region_articles_df = region_articles_df[['user_id', 'article_id', 'province', 'city']]
|
||||
region_articles_df = pd.merge(region_articles_df, article_df, how='left', on='article_id')
|
||||
# 去除时间为空, 以及一些异常数据
|
||||
region_articles_df['ctime'] = region_articles_df['ctime'].astype(str)
|
||||
region_articles_df = region_articles_df[region_articles_df['ctime'].str.isnumeric()]
|
||||
# 分组
|
||||
province_df_dict = {}
|
||||
for name, df in region_articles_df.groupby('province'):
|
||||
if df.shape[0] < 5000:
|
||||
continue
|
||||
# 分完组之后可以取出重复数据
|
||||
df = df[['article_id', 'expo_num', 'click_num', 'click_rate', 'ctime', 'cate']].\
|
||||
drop_duplicates(subset='article_id').reset_index(drop=True)
|
||||
province_df_dict[name] = df
|
||||
# 给每个省份筛选一部分优质物料
|
||||
province_results_dict = {}
|
||||
for province, df in province_df_dict.items():
|
||||
province_results_dict[province] = self.get_province_articles(df, N, cur_time)
|
||||
print("province_recall success...")
|
||||
return province_results_dict
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
root_path = '/data1/ryluo/5w_data/'
|
||||
region_recall = RegionRecall(log_data_path, user_info_path, doc_info_path)
|
||||
province_results_dict = region_recall.province_recall(N=300, cur_time='2021-07-03')
|
||||
# 这里的召回内容还没有落盘
|
||||
print(province_results_dict)
|
||||
# TODO 召回结果落盘逻辑
|
||||
@@ -0,0 +1,413 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "b06bec9d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import gc\n",
|
||||
"import os\n",
|
||||
"import math\n",
|
||||
"import pickle\n",
|
||||
"\n",
|
||||
"import numpy as np\n",
|
||||
"import pandas as pd\n",
|
||||
"from tqdm.auto import tqdm\n",
|
||||
"from operator import itemgetter\n",
|
||||
"\n",
|
||||
"from sklearn.utils import shuffle\n",
|
||||
"from collections import defaultdict\n",
|
||||
"\n",
|
||||
"from metric import PrintMetric\n",
|
||||
"\n",
|
||||
"import warnings\n",
|
||||
"warnings.filterwarnings(\"ignore\")\n",
|
||||
"\n",
|
||||
"raw_data_path = 'D:/news-rec/dataset/raw_data'\n",
|
||||
"new_data_path = 'D:/news-rec/dataset/recall_data'\n",
|
||||
"\n",
|
||||
"os.makedirs(new_data_path, exist_ok=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "4479018f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " user_id 设备名称 操作系统 所在省 所在市 \\\n0 1000372820 TAS-AN00 Android 广东 广州 \n10 1001440812 iPad IOS NaN NaN \n16 1001771644 V1901A Android 陕西 宝鸡 \n17 1001773994 STK-AL00 Android 广东 河源 \n142 1017050854 DUB-AL00 Android 湖北 武汉 \n\n 年龄 \\\n0 A_0_24:0.404616,A_25_29:0.059027,A_30_39:0.516... \n10 A_0_24:0.312738,A_25_29:0.261741,A_30_39:0.268... \n16 A_0_24:0.445645,A_25_29:0.330315,A_30_39:0.153... \n17 A_0_24:0.497841,A_25_29:0.245965,A_30_39:0.219... \n142 A_0_24:0.008895,A_25_29:0.067247,A_30_39:0.824... \n\n 性别 \n0 female:0.051339,male:0.948661 \n10 female:0.907997,male:0.092003 \n16 female:0.049787,male:0.950213 \n17 female:0.117317,male:0.882683 \n142 female:0.519291,male:0.480709 ",
|
||||
"text/html": "<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>user_id</th>\n <th>设备名称</th>\n <th>操作系统</th>\n <th>所在省</th>\n <th>所在市</th>\n <th>年龄</th>\n <th>性别</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>1000372820</td>\n <td>TAS-AN00</td>\n <td>Android</td>\n <td>广东</td>\n <td>广州</td>\n <td>A_0_24:0.404616,A_25_29:0.059027,A_30_39:0.516...</td>\n <td>female:0.051339,male:0.948661</td>\n </tr>\n <tr>\n <th>10</th>\n <td>1001440812</td>\n <td>iPad</td>\n <td>IOS</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>A_0_24:0.312738,A_25_29:0.261741,A_30_39:0.268...</td>\n <td>female:0.907997,male:0.092003</td>\n </tr>\n <tr>\n <th>16</th>\n <td>1001771644</td>\n <td>V1901A</td>\n <td>Android</td>\n <td>陕西</td>\n <td>宝鸡</td>\n <td>A_0_24:0.445645,A_25_29:0.330315,A_30_39:0.153...</td>\n <td>female:0.049787,male:0.950213</td>\n </tr>\n <tr>\n <th>17</th>\n <td>1001773994</td>\n <td>STK-AL00</td>\n <td>Android</td>\n <td>广东</td>\n <td>河源</td>\n <td>A_0_24:0.497841,A_25_29:0.245965,A_30_39:0.219...</td>\n <td>female:0.117317,male:0.882683</td>\n </tr>\n <tr>\n <th>142</th>\n <td>1017050854</td>\n <td>DUB-AL00</td>\n <td>Android</td>\n <td>湖北</td>\n <td>武汉</td>\n <td>A_0_24:0.008895,A_25_29:0.067247,A_30_39:0.824...</td>\n <td>female:0.519291,male:0.480709</td>\n </tr>\n </tbody>\n</table>\n</div>"
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"user_info = pd.read_csv(raw_data_path + '/user_info_5w.csv', sep='\\t', index_col=0)\n",
|
||||
"user_info.columns = [\"user_id\", \"设备名称\", \"操作系统\", \"所在省\", \"所在市\", \"年龄\",\"性别\"]\n",
|
||||
"\n",
|
||||
"user_info.head()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "22d466d5",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " item_id 标题 发文时间 图片数量 一级分类 \\\n0 361653323 疫情谣言粉碎机丨接种新冠疫苗后用麻药或致死?盘点最新疫情谣言,别被忽悠了 1624522285000 1 健康 \n1 426732705 实拍本田飞度:空间真大,8万出头工薪族可选,但内饰能忍? 1610808303000 9 汽车 \n2 430221183 搭载135kw电机比亚迪秦plus纯电动版外观更精致 1612581556000 2 汽车 \n3 441756326 【提车作业】不顾他人眼光帕萨特phev俘获30老男人浪子心 1618825835000 23 汽车 \n4 443485341 魏延有反骨之心都能重用,赵云忠心为什么却不被重用? 1619484501000 4 历史 \n\n 二级分类 关键词 \n0 健康/疾病防护治疗及西医用药 医生:14.760494,吸烟:16.474872,板蓝根:15.597788,板蓝根^^熏... \n1 汽车/买车 155n:8.979802,polo:7.951116,中控台:5.954278,中网:7.... \n2 汽车/买车 etc:12.055207,代表:8.878175,内饰:5.342025,刀片:9.453... \n3 汽车/买车 丰田凯美瑞:12.772149,充电器:8.394001,品牌:8.436843,城市:7.... \n4 历史/中国史 三国:8.979797,五虎将:13.072728,人才:7.532783,保镖:6.811... ",
|
||||
"text/html": "<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>item_id</th>\n <th>标题</th>\n <th>发文时间</th>\n <th>图片数量</th>\n <th>一级分类</th>\n <th>二级分类</th>\n <th>关键词</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>361653323</td>\n <td>疫情谣言粉碎机丨接种新冠疫苗后用麻药或致死?盘点最新疫情谣言,别被忽悠了</td>\n <td>1624522285000</td>\n <td>1</td>\n <td>健康</td>\n <td>健康/疾病防护治疗及西医用药</td>\n <td>医生:14.760494,吸烟:16.474872,板蓝根:15.597788,板蓝根^^熏...</td>\n </tr>\n <tr>\n <th>1</th>\n <td>426732705</td>\n <td>实拍本田飞度:空间真大,8万出头工薪族可选,但内饰能忍?</td>\n <td>1610808303000</td>\n <td>9</td>\n <td>汽车</td>\n <td>汽车/买车</td>\n <td>155n:8.979802,polo:7.951116,中控台:5.954278,中网:7....</td>\n </tr>\n <tr>\n <th>2</th>\n <td>430221183</td>\n <td>搭载135kw电机比亚迪秦plus纯电动版外观更精致</td>\n <td>1612581556000</td>\n <td>2</td>\n <td>汽车</td>\n <td>汽车/买车</td>\n <td>etc:12.055207,代表:8.878175,内饰:5.342025,刀片:9.453...</td>\n </tr>\n <tr>\n <th>3</th>\n <td>441756326</td>\n <td>【提车作业】不顾他人眼光帕萨特phev俘获30老男人浪子心</td>\n <td>1618825835000</td>\n <td>23</td>\n <td>汽车</td>\n <td>汽车/买车</td>\n <td>丰田凯美瑞:12.772149,充电器:8.394001,品牌:8.436843,城市:7....</td>\n </tr>\n <tr>\n <th>4</th>\n <td>443485341</td>\n <td>魏延有反骨之心都能重用,赵云忠心为什么却不被重用?</td>\n <td>1619484501000</td>\n <td>4</td>\n <td>历史</td>\n <td>历史/中国史</td>\n <td>三国:8.979797,五虎将:13.072728,人才:7.532783,保镖:6.811...</td>\n </tr>\n </tbody>\n</table>\n</div>"
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"doc_info = pd.read_table(raw_data_path + '/doc_info.txt', sep='\\t')\n",
|
||||
"doc_info.columns = [\"item_id\", \"标题\", \"发文时间\", \"图片数量\", \"一级分类\", \"二级分类\", \"关键词\"]\n",
|
||||
"\n",
|
||||
"doc_info.head()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "7cf3ff94",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " user_id item_id 展现时间 网路环境 刷新次数 展现位置 是否点击 消费时长(秒)\n0 1000014754 463510256 1624843756147 5 0 16 0 0\n1 1000014754 463852707 1624843756147 5 0 13 1 80\n2 1000014754 464757134 1625052999841 5 0 13 1 1050\n3 1000014754 464617167 1625052999841 5 0 16 1 286\n4 1000014754 465426190 1625382421168 5 0 5 0 0",
|
||||
"text/html": "<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>user_id</th>\n <th>item_id</th>\n <th>展现时间</th>\n <th>网路环境</th>\n <th>刷新次数</th>\n <th>展现位置</th>\n <th>是否点击</th>\n <th>消费时长(秒)</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>1000014754</td>\n <td>463510256</td>\n <td>1624843756147</td>\n <td>5</td>\n <td>0</td>\n <td>16</td>\n <td>0</td>\n <td>0</td>\n </tr>\n <tr>\n <th>1</th>\n <td>1000014754</td>\n <td>463852707</td>\n <td>1624843756147</td>\n <td>5</td>\n <td>0</td>\n <td>13</td>\n <td>1</td>\n <td>80</td>\n </tr>\n <tr>\n <th>2</th>\n <td>1000014754</td>\n <td>464757134</td>\n <td>1625052999841</td>\n <td>5</td>\n <td>0</td>\n <td>13</td>\n <td>1</td>\n <td>1050</td>\n </tr>\n <tr>\n <th>3</th>\n <td>1000014754</td>\n <td>464617167</td>\n <td>1625052999841</td>\n <td>5</td>\n <td>0</td>\n <td>16</td>\n <td>1</td>\n <td>286</td>\n </tr>\n <tr>\n <th>4</th>\n <td>1000014754</td>\n <td>465426190</td>\n <td>1625382421168</td>\n <td>5</td>\n <td>0</td>\n <td>5</td>\n <td>0</td>\n <td>0</td>\n </tr>\n </tbody>\n</table>\n</div>"
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"all_data = pd.read_csv(raw_data_path + '/train_data_5w.csv', sep='\\t', index_col=0)\n",
|
||||
"all_data.columns = [\"user_id\", \"item_id\", \"展现时间\", \"网路环境\", \"刷新次数\", \"展现位置\", \"是否点击\", \"消费时长(秒)\"]\n",
|
||||
"\n",
|
||||
"all_data.head()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " user_id item_id 展现时间 网路环境 刷新次数 展现位置 是否点击 消费时长(秒) \\\n0 1000014754 463510256 2021-06-28 01:29:16 5 0 16 0 0 \n1 1000014754 463852707 2021-06-28 01:29:16 5 0 13 1 80 \n2 1000014754 464757134 2021-06-30 11:36:39 5 0 13 1 1050 \n3 1000014754 464617167 2021-06-30 11:36:39 5 0 16 1 286 \n4 1000014754 465426190 2021-07-04 07:07:01 5 0 5 0 0 \n\n 展现时间_日期 \n0 28 \n1 28 \n2 30 \n3 30 \n4 4 ",
|
||||
"text/html": "<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>user_id</th>\n <th>item_id</th>\n <th>展现时间</th>\n <th>网路环境</th>\n <th>刷新次数</th>\n <th>展现位置</th>\n <th>是否点击</th>\n <th>消费时长(秒)</th>\n <th>展现时间_日期</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>1000014754</td>\n <td>463510256</td>\n <td>2021-06-28 01:29:16</td>\n <td>5</td>\n <td>0</td>\n <td>16</td>\n <td>0</td>\n <td>0</td>\n <td>28</td>\n </tr>\n <tr>\n <th>1</th>\n <td>1000014754</td>\n <td>463852707</td>\n <td>2021-06-28 01:29:16</td>\n <td>5</td>\n <td>0</td>\n <td>13</td>\n <td>1</td>\n <td>80</td>\n <td>28</td>\n </tr>\n <tr>\n <th>2</th>\n <td>1000014754</td>\n <td>464757134</td>\n <td>2021-06-30 11:36:39</td>\n <td>5</td>\n <td>0</td>\n <td>13</td>\n <td>1</td>\n <td>1050</td>\n <td>30</td>\n </tr>\n <tr>\n <th>3</th>\n <td>1000014754</td>\n <td>464617167</td>\n <td>2021-06-30 11:36:39</td>\n <td>5</td>\n <td>0</td>\n <td>16</td>\n <td>1</td>\n <td>286</td>\n <td>30</td>\n </tr>\n <tr>\n <th>4</th>\n <td>1000014754</td>\n <td>465426190</td>\n <td>2021-07-04 07:07:01</td>\n <td>5</td>\n <td>0</td>\n <td>5</td>\n <td>0</td>\n <td>0</td>\n <td>4</td>\n </tr>\n </tbody>\n</table>\n</div>"
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"all_data['展现时间'] = all_data['展现时间'].astype('str')\n",
|
||||
"all_data['展现时间'] = all_data['展现时间'].apply(lambda x: int(x[:10]))\n",
|
||||
"\n",
|
||||
"all_data['展现时间'] = pd.to_datetime(all_data['展现时间'], unit='s', errors='coerce')\n",
|
||||
"all_data['展现时间_日期'] = all_data['展现时间'].dt.day\n",
|
||||
"\n",
|
||||
"all_data.head()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "73c9843e",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": "75"
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"mode = 'debug'\n",
|
||||
"\n",
|
||||
"if mode == 'debug':\n",
|
||||
" all_data = shuffle(all_data)\n",
|
||||
" all_data.reset_index(drop=True)\n",
|
||||
"\n",
|
||||
" train_data = all_data[(all_data['展现时间_日期'] >= 5) & (all_data['展现时间_日期'] < 6)]\n",
|
||||
" test_data = all_data.loc[all_data['展现时间_日期'] == 6, :]\n",
|
||||
"else:\n",
|
||||
" train_data = all_data[(all_data['展现时间_日期'] >= 1) & (all_data['展现时间_日期'] < 6)]\n",
|
||||
" test_data = all_data.loc[all_data['展现时间_日期'] == 6, :]\n",
|
||||
"\n",
|
||||
"del all_data, doc_info, user_info\n",
|
||||
"gc.collect()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"15655\n",
|
||||
"33664\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(train_data['user_id'].nunique())\n",
|
||||
"print(train_data['item_id'].nunique())"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "345cc0d2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class UserCF(object):\n",
|
||||
" def __init__(self, his_data):\n",
|
||||
" self.user_set = set()\n",
|
||||
" self.item_set = set()\n",
|
||||
"\n",
|
||||
" self.his_data = his_data\n",
|
||||
" self.user_sim_matrix = dict()\n",
|
||||
" self.user_interacted_num = defaultdict(int)\n",
|
||||
" self.item_interacted_num = defaultdict(int) # 热门推荐时会用到\n",
|
||||
"\n",
|
||||
" def calculate_similarity_matrix(self):\n",
|
||||
" item2users = self.his_data.groupby('item_id')['user_id'].apply(list).reset_index()\n",
|
||||
"\n",
|
||||
" # print(f'计算ItemCF第一阶段...')\n",
|
||||
" pbar = tqdm(total=item2users.shape[0])\n",
|
||||
" for idx, row in item2users.iterrows():\n",
|
||||
" self.item_set.add(row['item_id'])\n",
|
||||
" self.user_set.update(row['user_id'])\n",
|
||||
" self.item_interacted_num[row['item_id']] += len(row['user_id'])\n",
|
||||
" for idx1, user_1 in enumerate(row['user_id']):\n",
|
||||
" self.user_interacted_num[user_1] += 1\n",
|
||||
" self.user_sim_matrix.setdefault(user_1, {})\n",
|
||||
" for idx2, user_2 in enumerate(row['user_id']):\n",
|
||||
" if user_1 == user_2:\n",
|
||||
" continue\n",
|
||||
" self.user_sim_matrix[user_1].setdefault(user_2, 0)\n",
|
||||
" # 热门物品用在计算用户之间相似度时,贡献小于非热门物品\n",
|
||||
" self.user_sim_matrix[user_1][user_2] += 1 / math.log(1 + len(row['user_id']))\n",
|
||||
" pbar.update(1)\n",
|
||||
" pbar.close()\n",
|
||||
"\n",
|
||||
" # 理论上,用户之间共现的物品越多,相似度越高\n",
|
||||
" # 但是,活跃用户与很多用户之间的相似度都很高\n",
|
||||
" print(f'计算UserCF第二阶段...')\n",
|
||||
" for user_1, related_users in tqdm(self.user_sim_matrix.items()):\n",
|
||||
" for user_2, weight in related_users.items():\n",
|
||||
" # 打压活跃用户\n",
|
||||
" self.user_sim_matrix[user_1][user_2] =\\\n",
|
||||
" weight / math.sqrt(self.user_interacted_num[user_1] * self.user_interacted_num[user_2])\n",
|
||||
"\n",
|
||||
" def __call__(self, users, _n=50, _topk=20):\n",
|
||||
" print(f'开始ItemCF召回: Recall@{topk}-Near@{_n}')\n",
|
||||
" user2items = self.his_data.groupby('user_id')['item_id'].apply(list)\n",
|
||||
" popular_items = [val[0] for val in sorted(\n",
|
||||
" self.item_interacted_num.items(), key=lambda x: x[1], reverse=True)[:_topk]]\n",
|
||||
"\n",
|
||||
" user_rec = {}\n",
|
||||
" for user_id in tqdm(users):\n",
|
||||
" # 新用户,直接推荐热门物品\n",
|
||||
" if user_id not in self.user_set:\n",
|
||||
" user_rec[user_id] = popular_items\n",
|
||||
" else:\n",
|
||||
" rank = defaultdict(int)\n",
|
||||
" for relate_user, user_smi_score in sorted(self.user_sim_matrix[user_id].items(),\n",
|
||||
" key=itemgetter(1), reverse=True)[:_n]:\n",
|
||||
" for candidate_item in user2items.loc[relate_user]:\n",
|
||||
" # if candidate_item in user2items.loc[user_id]:\n",
|
||||
" # continue\n",
|
||||
" rank[candidate_item] += user_smi_score\n",
|
||||
" rec_items = [item[0] for item in sorted(rank.items(), key=itemgetter(1), reverse=True)[:_topk]]\n",
|
||||
" # 如果推荐的物品不够,用热门物品进行填充\n",
|
||||
" rec_items += popular_items[:topk-len(rec_items)]\n",
|
||||
" user_rec[user_id] = rec_items\n",
|
||||
"\n",
|
||||
" return user_rec"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"ucf_cls_path = os.path.join(new_data_path, 'user_cf')\n",
|
||||
"os.makedirs(ucf_cls_path, exist_ok=True)"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"demo_ucf_path = os.path.join(ucf_cls_path, mode+'_ufc.pkl')\n",
|
||||
"\n",
|
||||
"if os.path.exists(demo_ucf_path):\n",
|
||||
" with open(demo_ucf_path, 'rb') as file:\n",
|
||||
" demo_ucf = pickle.loads(file.read())\n",
|
||||
" file.close()\n",
|
||||
"else:\n",
|
||||
" demo_ucf = UserCF(train_data)\n",
|
||||
" demo_ucf.calculate_similarity_matrix()\n",
|
||||
" demo_ucf_pkl = pickle.dumps(demo_ucf)\n",
|
||||
"\n",
|
||||
" output_ucf = open(demo_ucf_path, 'wb')\n",
|
||||
" output_ucf.write(demo_ucf_pkl)\n",
|
||||
" output_ucf.close()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"开始ItemCF召回: Recall@100-Near@50\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": " 0%| | 0/13792 [00:00<?, ?it/s]",
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"version_major": 2,
|
||||
"version_minor": 0,
|
||||
"model_id": "e7e74728073f45ba9d21802109555731"
|
||||
}
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"n, topk = 50, 100\n",
|
||||
"\n",
|
||||
"# 召回\n",
|
||||
"test_users = test_data['user_id'].unique()\n",
|
||||
"icf_rec_result = demo_ucf(test_users, n, topk)\n",
|
||||
"\n",
|
||||
"test_user_group = test_data.groupby('user_id')['item_id'].agg(list).reset_index()\n",
|
||||
"test_pred = [icf_rec_result[user_id] for user_id in test_user_group['user_id']]\n",
|
||||
"test_true = test_user_group['item_id'].to_list()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"MAP@100: 0.012998163356723474\n",
|
||||
"Recall@100: 0.14660816973054847\n",
|
||||
"Precision@100: 0.02628625290023202\n",
|
||||
"F1@100: 0.036618405618781665\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"PrintMetric(test_true, test_pred, topk)"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"outputs": [],
|
||||
"source": [],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
}
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.8.12"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -69,7 +69,7 @@
|
||||
|
||||
- [X] **推荐页及热门页内容显示** —— 根据不同用户个性化显示不同新闻内容
|
||||
|
||||
- 推荐页和热门页之间的切换(首次切换时会刷新,正在修复这个bug)
|
||||
- 推荐页和热门页之间的切换
|
||||
|
||||
- 点进新闻详情页后阅读次数会实时增加
|
||||
|
||||
@@ -140,7 +140,10 @@
|
||||
```
|
||||
|
||||
---
|
||||
#### cookie.js
|
||||
|
||||
|
||||
|
||||
### cookie.js
|
||||
|
||||
定义cookie的相关操作
|
||||
|
||||
@@ -185,7 +188,7 @@ function clearCookie(name) {
|
||||
```
|
||||
|
||||
|
||||
#### APP.vue
|
||||
### APP.vue
|
||||
|
||||
定义了组件的缓存
|
||||
|
||||
@@ -201,7 +204,11 @@ function clearCookie(name) {
|
||||
```
|
||||
|
||||
|
||||
#### signIn.vue/signUp.vue
|
||||
|
||||
|
||||
|
||||
|
||||
### signIn.vue/signUp.vue
|
||||
|
||||
登录注册时将信息存入store
|
||||
|
||||
@@ -222,7 +229,10 @@ if(this.checked){
|
||||
}
|
||||
```
|
||||
|
||||
#### recLists.vue/hotLists.vue
|
||||
|
||||
|
||||
|
||||
### recLists.vue/hotLists.vue
|
||||
|
||||
获取后端接口数据
|
||||
|
||||
@@ -268,7 +278,10 @@ beforeRouteLeave(to, from, next) {
|
||||
```
|
||||
|
||||
|
||||
#### router.js
|
||||
|
||||
|
||||
|
||||
### router.js
|
||||
|
||||
定义路由相关配置,控制页面跳转
|
||||
|
||||
@@ -329,7 +342,10 @@ routerObj.beforeEach((to, from, next) => {
|
||||
```
|
||||
|
||||
|
||||
#### store.js
|
||||
|
||||
|
||||
|
||||
### store.js
|
||||
|
||||
管理用户的各种状态
|
||||
|
||||
@@ -393,6 +409,8 @@ export default new Vuex.Store({
|
||||
})
|
||||
```
|
||||
|
||||
|
||||
|
||||
**state:**
|
||||
|
||||
在store中存储状态,在组件中通过 `this.$store.state.type` 调用
|
||||
@@ -410,6 +428,7 @@ state: {
|
||||
},
|
||||
```
|
||||
|
||||
|
||||
**mutations:**
|
||||
|
||||
更改 store 中的状态,在组件中通过 `this.$store.commit('numChange')`调用
|
||||
@@ -469,7 +488,7 @@ mutations: {
|
||||
|
||||
|
||||
|
||||
#### NewsInfo.vue
|
||||
### NewsInfo.vue
|
||||
|
||||
发送action请求
|
||||
|
||||
@@ -508,7 +527,9 @@ sendInfo() {
|
||||
},
|
||||
```
|
||||
|
||||
#### Myself.vue
|
||||
|
||||
|
||||
### Myself.vue
|
||||
|
||||
退出登录时删除该用户相关信息
|
||||
|
||||
|
||||
0
docs/.nojekyll
Normal file
0
docs/.nojekyll
Normal file
232
docs/README.md
Normal file
232
docs/README.md
Normal file
@@ -0,0 +1,232 @@
|
||||
# FunRec
|
||||
<p align="left">
|
||||
<img src='https://img.shields.io/badge/python-3.8+-blue'>
|
||||
<img src='https://img.shields.io/badge/Tensorflow-2.2+-blue'>
|
||||
<img src='https://img.shields.io/badge/NumPy-1.22.3-brightgreen'>
|
||||
<img src='https://img.shields.io/badge/pandas-1.4.1-brightgreen'>
|
||||
<img src='https://img.shields.io/badge/sklearn-1.0.2-brightgreen'>
|
||||
</p>
|
||||
|
||||
本教程主要是针对具有机器学习基础并想找推荐算法岗位的同学。教程内容由推荐系统概述、推荐算法基础、推荐系统实战和推荐系统面经四个部分组成。本教程对于入门推荐算法的同学来说,可以从推荐算法的基础到实战再到面试,形成一个闭环。每个部分的详细内容如下:
|
||||
|
||||
- **推荐系统概述。** 这部分内容会从推荐系统的意义及应用,到架构及相关的技术栈做一个概述性的总结,目的是为了让初学者更加了解推荐系统。
|
||||
- **推荐系统算法基础。** 这部分会介绍推荐系统中对于算法工程师来说基础并且重要的相关算法,如经典的召回、排序算法。随着项目的迭代,后续还会不断的总结其他的关键算法和技术,如重排、冷启动等。
|
||||
- **推荐系统实战。** 这部分内容包含推荐系统竞赛实战和新闻推荐系统的实践。其中推荐系统竞赛实战是结合阿里天池上的新闻推荐入门赛做的相关内容。新闻推荐系统实践是实现一个具有前后端交互及整个推荐链路的项目,该项目是一个新闻推荐系统的demo没有实际的商业化价值。
|
||||
- **推荐系统算法面经。** 这里会将推荐算法工程师面试过程中常考的一些基础知识、热门技术等面经进行整理,方便同学在有了一定推荐算法基础之后去面试,因为对于初学者来说只有在公司实习学到的东西才是最有价值的。
|
||||
|
||||
项目在Datawhale的组队学习过程中不断的迭代和优化,通过大家的反馈来修正或者补充相关的内容,如果对项目内容设计有更好的意见欢迎给我们反馈。为了方便学习和交流,建了一个fun-rec微信交流群,由于微信群的二维码只有7天内有效,所以直接加下面这个微信,备注:**Fun-Rec**,会被拉到Fun-Rec交流群。由于现在已经有了好几个微信群,为了更方便沉淀内容,我们创建了一个Fun-Rec学习小组知识星球,由于我们的内容面向的人群主要是学生,所以知识星球永久免费,感兴趣的可以加入星球讨论(加入星球的同学先看置定的必读帖)。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20220408193745249.png" alt="image-20220408193745249" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
## 内容导航
|
||||
### 推荐系统概述
|
||||
- [推荐系统的意义](/推荐系统概述/推荐系统的意义)
|
||||
- 推荐系统的应用【未完成】
|
||||
- 推荐系统的架构【未完成】
|
||||
- 推荐系统技术栈【未完成】
|
||||
|
||||
### 推荐系统算法基础
|
||||
#### 经典召回模型
|
||||
- **基于协同过滤的召回**
|
||||
- UserCF【已完成,待优化】
|
||||
- ItemCF【已完成,待优化】
|
||||
- Swing(Graph-based)【未完成】
|
||||
- 矩阵分解系列(ALS,SVD++)【已完成,待优化】
|
||||
- **基于向量的召回**
|
||||
- FM召回【未完成】
|
||||
- word2vec召回
|
||||
- word2vec原理【未完成】
|
||||
- Airbnb召回【未完成】
|
||||
- YoutubeDNN召回【完成一半,待优化】
|
||||
- 双塔召回
|
||||
- 经典双塔【未完成】
|
||||
- Youtube双塔【未完成】
|
||||
- MOBIUS【未完成】
|
||||
- 图召回
|
||||
- EGES【完成一半,待优化】
|
||||
- PinSAGE【未完成】
|
||||
- 序列召回
|
||||
- [MIND](/推荐算法基础/经典召回模型/基于序列的召回/MIND模型)
|
||||
- [SDM](/推荐算法基础/经典召回模型/基于序列的召回/SDM模型)
|
||||
- **树模型召回**
|
||||
- TDM【未完成】
|
||||
|
||||
#### 经典排序模型
|
||||
- **[GBDT+LR](/推荐算法基础/经典排序模型/GBDT+LR)**
|
||||
- **特征交叉**
|
||||
- [FM](/推荐算法基础/经典排序模型/特征交叉/FM)
|
||||
- [PNN](/推荐算法基础/经典排序模型/特征交叉/PNN)
|
||||
- [DCN](/推荐算法基础/经典排序模型/特征交叉/DCN)
|
||||
- AutoInt【完成一半,待优化】
|
||||
- FiBiNET【完成一半,待优化】
|
||||
- **WideNDeep系列**
|
||||
- **[Wide&Deep](/推荐算法基础/经典排序模型/Wide&Deep系列/Wide&Deep)**
|
||||
- **改进Deep侧**
|
||||
- [NFM](/推荐算法基础/经典排序模型/Wide&Deep系列/NFM)
|
||||
- [AFM](/推荐算法基础/经典排序模型/Wide&Deep系列/AFM)
|
||||
- **改进Wide侧**
|
||||
- [DeepFM](/推荐算法基础/经典排序模型/Wide&Deep系列/DeepFM)
|
||||
- xDeepFM【未完成】
|
||||
- **序列模型**
|
||||
- [DIN](/推荐算法基础/经典排序模型/序列模型/DIN)
|
||||
- [DIEN](/推荐算法基础/经典排序模型/序列模型/DIEN)
|
||||
- DISN【未完成】
|
||||
- BST【未完成】
|
||||
- **多任务学习**
|
||||
- SharedBottom【已完成,待优化】
|
||||
- ESSM【已完成,待优化】
|
||||
- MMOE【已完成,待优化】
|
||||
- PLE【已完成,待优化】
|
||||
|
||||
### 推荐系统实战
|
||||
|
||||
#### 竞赛实践(天池入门赛-新闻推荐)
|
||||
- **视频**
|
||||
- [赛题理解](https://www.bilibili.com/video/BV1do4y1d7FP?p=1)
|
||||
- [多路召回](https://www.bilibili.com/video/BV1do4y1d7FP?p=4)
|
||||
- [特征工程](https://www.bilibili.com/video/BV1do4y1d7FP?p=2)
|
||||
- [上分技巧](https://www.bilibili.com/video/BV1do4y1d7FP?p=3)
|
||||
- **文档**
|
||||
- [赛题理解&Baseline](/推荐系统实战/竞赛实践/markdown/赛题理解+Baseline)
|
||||
- [数据分析](/推荐系统实战/竞赛实践/markdown/数据分析)
|
||||
- [多路召回](/推荐系统实战/竞赛实践/markdown/多路召回)
|
||||
- [特征工程](/推荐系统实战/竞赛实践/markdown/特征工程)
|
||||
- [排序模型&模型融合](/推荐系统实战/竞赛实践/markdown/排序模型+模型融合)
|
||||
|
||||
#### 新闻推荐系统实践
|
||||
- 新闻推荐系统流程的构建视频讲解【已完成】
|
||||
- 离线物料系统的构建
|
||||
- Mysql基础【已完成】
|
||||
- MongoDB基础【已完成】
|
||||
- Redis基础【已完成】
|
||||
- Scrapy基础及新闻爬取实战【已完成】
|
||||
- 自动化构建用户及物料画像【已完成】
|
||||
- 前后端基础及交互
|
||||
- 前端基础及Vue实战【已完成】
|
||||
- flask简介及基础【已完成】
|
||||
- 前后端交互【已完成】
|
||||
- 推荐流程的构建【已完成】
|
||||
- 召回
|
||||
- 规则类召回
|
||||
- 热度召回【完成一半,待优化】
|
||||
- 地域召回【完成一半,待优化】
|
||||
- 模型类召回
|
||||
- YoutubeDNN召回【已完成,待优化】
|
||||
- DSSM召回【已完成,待优化】
|
||||
- DeepFM排序模型【已完成,待优化】
|
||||
- 规则与重排【完成一半,待优化】
|
||||
- 任务监控与调度【完成一半,待优化】
|
||||
|
||||
### 推荐系统算法面经
|
||||
- [ML与DL基础](/推荐算法面经/ML与DL基础)
|
||||
- [推荐模型相关](/推荐算法面经/推荐模型相关)
|
||||
- [热门技术相关](/推荐算法面经/热门技术相关)
|
||||
- [业务场景相关](/推荐算法面经/业务场景相关)
|
||||
- [HR及其他](/推荐算法面经/HR及其他)
|
||||
|
||||
|
||||
## 致谢
|
||||
<table align="center" style="width:80%;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>成员</th>
|
||||
<th>个人简介及贡献</th>
|
||||
<th>个人主页</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">罗如意</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,西安电子科技大学硕士,项目负责人, 核心贡献者</td>
|
||||
<td><a href="https://github.com/ruyiluo">Github</a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">吴忠强</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,东北大学硕士,CSDN博客专家,核心贡献者</td>
|
||||
<td><a href="https://blog.csdn.net/wuzhongqiang">CSDN</a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">何世福</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,算法工程师,课程设计及内容审核</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">徐何军</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,算法工程师,内容审核</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">李万业</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,同济大学硕士,新闻推荐入门赛贡献部分内容</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">陈琰钰</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,清华大学硕士,新闻推荐入门赛贡献部分内容</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">陈锴</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,中山大学本科,推荐算法基础贡献部分内容</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">梁家晖</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,公众号:可能好玩,基础推荐算法贡献部分内容</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">王贺</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,算法工程师,新闻推荐入门赛赛题设计者</td>
|
||||
<td><a href="https://www.zhihu.com/people/wang-he-13-93">鱼遇雨欲语与余</a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">宁彦吉</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,算法工程师,深度推荐模型章节贡献部分内容</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">田雨</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,武汉大学硕士,深度推荐模型章节贡献部分内容</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">赖敏材</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale成员,上海科技大学硕士,深度模型及面经贡献部分内容</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">汪志鸿</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale意向成员,东北大学硕士,新闻推荐系统实践贡献部分内容</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">王辰玥</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale意向成员,中国地质大学,新闻推荐系统实践前端负责人</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">唐鑫</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale意向成员,西安电子科技大学硕士,机器学习基础贡献部分内容</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">宋禹成</span></td>
|
||||
<td><span style="font-weight:normal;font-style:normal;text-decoration:none">Datawhale意向成员,东北大学硕士,新闻推荐系统贡献部分内容</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
<font color='red'>感谢Datawhale成员刘雯静、吕豪杰及意向成员张汉隆、吴丹飞、王云川、肖桐、管柯琴、陈雨龙和宋禹成等人在开源项目组队学习中担任助教时的辛苦付出!</font>
|
||||
|
||||
## 关注我们
|
||||
<div align=center>
|
||||
<p>扫描下方二维码关注公众号:Datawhale</p>
|
||||
<img src="https://raw.githubusercontent.com/datawhalechina/pumpkin-book/master/res/qrcode.jpeg" width = "180" height = "180">
|
||||
</div>
|
||||
|
||||
## LICENSE
|
||||
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="知识共享许可协议" style="border-width:0" src="https://img.shields.io/badge/license-CC%20BY--NC--SA%204.0-lightgrey" /></a>
|
||||
本作品采用<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/">知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议</a>进行许可。
|
||||
94
docs/_sidebar.md
Normal file
94
docs/_sidebar.md
Normal file
@@ -0,0 +1,94 @@
|
||||
<!-- docs/_sidebar.md -->
|
||||
|
||||
* [Fun-Rec项目介绍](/)
|
||||
* [推荐系统概述]()
|
||||
* [推荐系统的意义](/推荐系统概述/推荐系统的意义)
|
||||
* [推荐系统的应用](/推荐系统概述/推荐系统的应用)
|
||||
* [推荐系统架构](/推荐系统概述/推荐系统架构)
|
||||
* [推荐系统技术栈](/推荐系统概述/推荐系统技术栈)
|
||||
* [推荐系统算法基础]()
|
||||
* [经典召回模型](/推荐算法基础/经典召回模型/)
|
||||
* [基于协同过滤的召回](/推荐算法基础/经典召回模型/基于统计的召回/)
|
||||
* [UserCF]()
|
||||
* [ItemCF]()
|
||||
* [Swing(Graph-based)]()
|
||||
* [矩阵分解系列(ALS,SVD++)]()
|
||||
* [基于向量的召回](/推荐算法基础/经典召回模型/基于向量的召回/)
|
||||
* [FM召回]()
|
||||
* [item2vec召回]()
|
||||
* [word2vec原理]()
|
||||
* [Airbnb召回]()
|
||||
* [YoutubeDNN召回]()
|
||||
* [双塔召回]()
|
||||
* [经典双塔]()
|
||||
* [Youtube双塔]()
|
||||
* [MOBIUS]()
|
||||
* [基于图的召回]()
|
||||
* [EGES]()
|
||||
* [PinSAGE]()
|
||||
* [基于序列的召回]()
|
||||
* [MIND](/推荐算法基础/经典召回模型/基于序列的召回/MIND模型)
|
||||
* [SDM](/推荐算法基础/经典召回模型/基于序列的召回/SDM模型)
|
||||
* [基于树模型的召回]()
|
||||
* [TDM]()
|
||||
* [经典排序模型]()
|
||||
* [GBDT+LR](/推荐算法基础/经典排序模型/GBDT+LR)
|
||||
* [特征交叉](/推荐算法基础/经典排序模型/特征交叉/readme)
|
||||
* [FM](/推荐算法基础/经典排序模型/特征交叉/FM)
|
||||
* [PNN](/推荐算法基础/经典排序模型/特征交叉/PNN)
|
||||
* [DCN](/推荐算法基础/经典排序模型/特征交叉/DCN)
|
||||
* [AutoInt]()
|
||||
* [FiBiNet]()
|
||||
* [Wide&Deep系列]()
|
||||
* [Wide&Deep](/推荐算法基础/经典排序模型/Wide&Deep系列/Wide&Deep)
|
||||
* [改进Deep侧]()
|
||||
* [NFM](/推荐算法基础/经典排序模型/Wide&Deep系列/NFM)
|
||||
* [AFM](/推荐算法基础/经典排序模型/Wide&Deep系列/AFM)
|
||||
* [改进Wide侧]()
|
||||
* [DeepFM](/推荐算法基础/经典排序模型/Wide&Deep系列/DeepFM)
|
||||
* [xDeepFM]()
|
||||
* [序列模型]()
|
||||
* [DIN](/推荐算法基础/经典排序模型/序列模型/DIN)
|
||||
* [DIEN](/推荐算法基础/经典排序模型/序列模型/DIEN)
|
||||
* [DISN]()
|
||||
* [BST]()
|
||||
* [多任务学习]()
|
||||
* [SharedBottom]()
|
||||
* [ESSM]()
|
||||
* [MMOE]()
|
||||
* [PLE]()
|
||||
* [推荐系统实战]()
|
||||
* [竞赛实践(天池入门赛-新闻推荐)]()
|
||||
* [赛题理解&Baseline](/推荐系统实战/竞赛实践/markdown/赛题理解+Baseline)
|
||||
* [数据分析](/推荐系统实战/竞赛实践/markdown/数据分析)
|
||||
* [多路召回](/推荐系统实战/竞赛实践/markdown/多路召回)
|
||||
* [特征工程](/推荐系统实战/竞赛实践/markdown/特征工程)
|
||||
* [排序模型&模型融合](/推荐系统实战/竞赛实践/markdown/排序模型&模型融合)
|
||||
* [新闻推荐系统的实践]()
|
||||
* [离线物料系统的构建]()
|
||||
* [Mysql基础]()
|
||||
* [MongoDB基础]()
|
||||
* [Redis基础]()
|
||||
* [Scrapy基础及新闻爬取实战]()
|
||||
* [自动化构建用户及物料画像]()
|
||||
* [前后端基础及交互]()
|
||||
* [前端基础及Vue实战]()
|
||||
* [flask简介及基础]()
|
||||
* [前后端交互]()
|
||||
* [推荐流程的构建]()
|
||||
* [召回]()
|
||||
- [规则类召回]()
|
||||
- [热度召回]()
|
||||
- [地域召回]()
|
||||
- [模型类召回]()
|
||||
- [YoutubeDNN]()
|
||||
- [双塔召回]()
|
||||
* [DeepFM排序]()
|
||||
* [规则与重排]()
|
||||
* [任务调度与监控]()
|
||||
* [推荐系统算法面经]()
|
||||
* [ML与DL基础](/推荐算法面经/ML与DL基础)
|
||||
* [推荐模型相关](/推荐算法面经/推荐模型相关)
|
||||
* [热门技术相关](/推荐算法面经/热门技术相关)
|
||||
* [业务场景相关](/推荐算法面经/业务场景相关)
|
||||
* [HR及其他](/推荐算法面经/HR及其他)
|
||||
33
docs/index.html
Normal file
33
docs/index.html
Normal file
@@ -0,0 +1,33 @@
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<title>Document</title>
|
||||
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" />
|
||||
<meta name="description" content="Description">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0">
|
||||
<link rel="stylesheet" href="//cdn.jsdelivr.net/npm/docsify@4/lib/themes/vue.css">
|
||||
</head>
|
||||
<body>
|
||||
<div id="app"></div>
|
||||
<script>
|
||||
window.$docsify = {
|
||||
name: '',
|
||||
repo: '',
|
||||
loadSidebar: true,
|
||||
subMaxLevel: 4
|
||||
}
|
||||
</script>
|
||||
|
||||
<!-- CDN files for docsify-katex -->
|
||||
<script src="//cdn.jsdelivr.net/npm/docsify-katex@latest/dist/docsify-katex.js"></script>
|
||||
<!-- or <script src="//cdn.jsdelivr.net/gh/upupming/docsify-katex@latest/dist/docsify-katex.js"></script> -->
|
||||
<link rel="stylesheet" href="//cdn.jsdelivr.net/npm/katex@latest/dist/katex.min.css"/>
|
||||
|
||||
<script src="//cdn.jsdelivr.net/npm/docsify-copy-code"></script>
|
||||
<script src="//cdn.jsdelivr.net/npm/prismjs@1/components/prism-python.min.js"></script>
|
||||
|
||||
<!-- Docsify v4 -->
|
||||
<script src="//cdn.jsdelivr.net/npm/docsify@4"></script>
|
||||
</body>
|
||||
</html>
|
||||
1
docs/推荐算法基础/经典召回模型/基于协同过滤的召回/readme.md
Normal file
1
docs/推荐算法基础/经典召回模型/基于协同过滤的召回/readme.md
Normal file
@@ -0,0 +1 @@
|
||||
# README
|
||||
1
docs/推荐算法基础/经典召回模型/基于向量的召回/readme.md
Normal file
1
docs/推荐算法基础/经典召回模型/基于向量的召回/readme.md
Normal file
@@ -0,0 +1 @@
|
||||
# README
|
||||
1
docs/推荐算法基础/经典召回模型/基于图的召回/readme.md
Normal file
1
docs/推荐算法基础/经典召回模型/基于图的召回/readme.md
Normal file
@@ -0,0 +1 @@
|
||||
# README
|
||||
415
docs/推荐算法基础/经典召回模型/基于序列的召回/MIND模型.md
Normal file
415
docs/推荐算法基础/经典召回模型/基于序列的召回/MIND模型.md
Normal file
@@ -0,0 +1,415 @@
|
||||
## 1. 写在前面
|
||||
MIND模型(Multi-Interest Network with Dynamic Routing), 是阿里团队2019年在CIKM上发的一篇paper,该模型依然是用在召回阶段的一个模型,解决的痛点是之前在召回阶段的模型,比如双塔,YouTubeDNN召回模型等,在模拟用户兴趣的时候,总是基于用户的历史点击,最后通过pooling的方式得到一个兴趣向量,用该向量来表示用户的兴趣,但是该篇论文的作者认为,**用一个向量来表示用户的广泛兴趣未免有点太过于单一**,这是作者基于天猫的实际场景出发的发现,每个用户每天与数百种产品互动, 而互动的产品往往来自于很多个类别,这就说明用户的兴趣极其广泛,**用一个向量是无法表示这样广泛的兴趣的**,于是乎,就自然而然的引出一个问题,**有没有可能用多个向量来表示用户的多种兴趣呢?**
|
||||
|
||||
这篇paper的核心是胶囊网络,**该网络采用了动态路由算法能非常自然的将历史商品聚成多个集合,每个集合的历史行为进一步推断对应特定兴趣的用户表示向量。这样,对于一个特定的用户,MND输出了多个表示向量,它们代表了用户的不同兴趣。当用户再有新的交互时,通过胶囊网络,还能实时的改变用户的兴趣表示向量,做到在召回阶段的实时个性化**。那么,胶囊网络究竟是怎么做到的呢? 胶囊网络又是什么原理呢?
|
||||
|
||||
**主要内容**:
|
||||
* 背景与动机
|
||||
* 胶囊网络与动态路由机制
|
||||
* MIND模型的网络结构与细节剖析
|
||||
* MIND模型之简易代码复现
|
||||
* 总结
|
||||
|
||||
## 2. 背景与动机
|
||||
本章是基于天猫APP的背景来探索十亿级别的用户个性化推荐。天猫的推荐的流程主要分为召回阶段和排序阶段。召回阶段负责检索数千个与用户兴趣相关的候选物品,之后,排序阶段预测用户与这些候选物品交互的精确概率。这篇文章做的是召回阶段的工作,来对满足用户兴趣的物品的有效检索。
|
||||
|
||||
作者这次的出发点是基于场景出发,在天猫的推荐场景中,作者发现**用户的兴趣存在多样性**。平均上,10亿用户访问天猫,每个用户每天与数百种产品互动。交互后的物品往往属于不同的类别,说明用户兴趣的多样性。 一张图片会更加简洁直观:
|
||||
|
||||

|
||||
因此如果能在**召回阶段建立用户多兴趣模型来模拟用户的这种广泛兴趣**,那么作者认为是非常有必要的,因为召回阶段的任务就是根据用户兴趣检索候选商品嘛。
|
||||
|
||||
那么,如何能基于用户的历史交互来学习用户的兴趣表示呢? 以往的解决方案如下:
|
||||
* 协同过滤的召回方法(itemcf和usercf)是通过历史交互过的物品或隐藏因子直接表示用户兴趣, 但会遇到**稀疏或计算问题**
|
||||
* 基于深度学习的方法用低维的embedding向量表示用户,比如YoutubeDNN召回模型,双塔模型等,都是把用户的基本信息,或者用户交互过的历史商品信息等,过一个全连接层,最后编码成一个向量,用这个向量来表示用户兴趣,但作者认为,**这是多兴趣表示的瓶颈**,因为需要压缩所有与用户多兴趣相关的信息到一个表示向量,所有用户多兴趣的信息进行了混合,导致这种多兴趣并无法体现,所以往往召回回来的商品并不是很准确,除非向量维度很大,但是大维度又会带来高计算。
|
||||
* DIN模型在Embedding的基础上加入了Attention机制,来选择的捕捉用户兴趣的多样性,但采用Attention机制,**对于每个目标物品,都需要重新计算用户表示**,这在召回阶段是行不通的(海量),所以DIN一般是用于排序。
|
||||
|
||||
所以,作者想在召回阶段去建模用户的多兴趣,但以往的方法都不好使,为了解决这个问题,就提出了动态路由的多兴趣网络MIND。为了推断出用户的多兴趣表示,提出了一个多兴趣提取层,该层使用动态路由机制自动的能将用户的历史行为聚类,然后每个类簇中产生一个表示向量,这个向量能代表用户某种特定的兴趣,而多个类簇的多个向量合起来,就能表示用户广泛的兴趣了。
|
||||
|
||||
这就是MIND的提出动机以及初步思路了,这里面的核心是Multi-interest extractor layer, 而这里面重点是动态路由与胶囊网络,所以接下来先补充这方面的相关知识。
|
||||
|
||||
## 3. 胶囊网络与动态路由机制
|
||||
### 3.1 胶囊网络初识
|
||||
Hinton大佬在2011年的时候,就首次提出了"胶囊"的概念, "胶囊"可以看成是一组聚合起来输出整个向量的小神经元组合,这个向量的每个维度(每个小神经元),代表着某个实体的某个特征。
|
||||
|
||||
胶囊网络其实可以和神经网络对比着看可能更好理解,我们知道神经网络的每一层的神经元输出的是单个的标量值,接收的输入,也是多个标量值,所以这是一种value to value的形式,而胶囊网络每一层的胶囊输出的是一个向量值,接收的输入也是多个向量,所以它是vector to vector形式的。来个图对比下就清楚了:
|
||||
|
||||
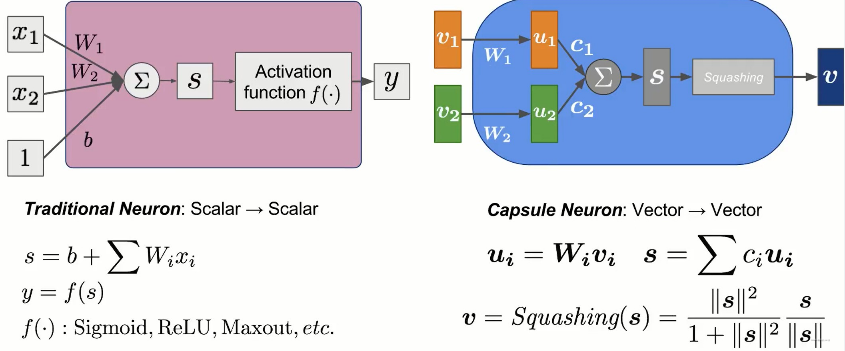
|
||||
左边的图是普通神经元的计算示意,而右边是一个胶囊内部的计算示意图。 神经元这里不过多解释,这里主要是剖析右边的这个胶囊计算原理。从上图可以看出, 输入是两个向量$v_1,v_2$,首先经过了一个线性映射,得到了两个新向量$u_1,u_2$,然后呢,经过了一个向量的加权汇总,这里的$c_1$,$c_2$可以先理解成权重,具体计算后面会解释。 得到汇总后的向量$s$,接下来进行了Squash操作,整体的计算公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
&u^{1}=W^{1} v^{1} \quad u^{2}=W^{2} v^{2} \\
|
||||
&s=c_{1} u^{1}+c_{2} u^{2} \\
|
||||
&v=\operatorname{Squash}(s) =\frac{\|s\|^{2}}{1+\|s\|^{2}} \frac{s}{\|s\|}
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的Squash操作可以简单看下,主要包括两部分,右边的那部分其实就是向量归一化操作,把norm弄成1,而左边那部分算是一个非线性操作,如果$s$的norm很大,那么这个整体就接近1, 而如果这个norm很小,那么整体就会接近0, 和sigmoid很像有没有?
|
||||
|
||||
这样就完成了一个胶囊的计算,但有两点需要注意:
|
||||
1. 这里的$W^i$参数是可学习的,和神经网络一样, 通过BP算法更新
|
||||
2. 这里的$c_i$参数不是BP算法学习出来的,而是采用动态路由机制现场算出来的,这个非常类似于pooling层,我们知道pooling层的参数也不是学习的,而是根据前面的输入现场取最大或者平均计算得到的。
|
||||
|
||||
所以这里的问题,就是怎么通过动态路由机制得到$c_i$,下面是动态路由机制的过程。
|
||||
|
||||
### 3.2 动态路由机制原理
|
||||
我们先来一个胶囊结构:
|
||||
|
||||
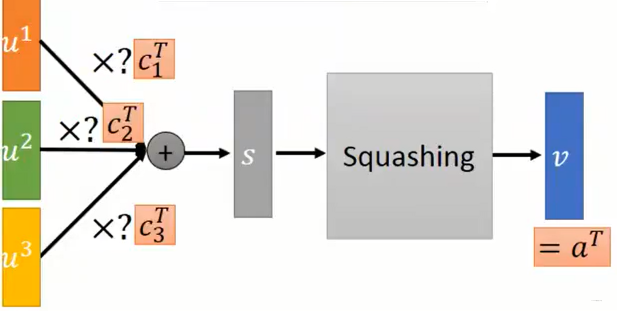
|
||||
这个$c_i$是通过动态路由机制计算得到,那么动态路由机制究竟是啥子意思? 其实就是通过迭代的方式去计算,没有啥神秘的,迭代计算的流程如下图:
|
||||
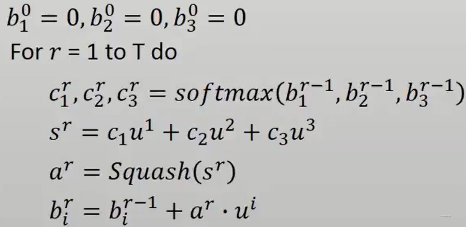
|
||||
首先我们先初始化$b_i$,与每一个输入胶囊$u_i$进行对应,这哥们有个名字叫做"routing logit", 表示的是输出的这个胶囊与输入胶囊的相关性,和注意力机制里面的score值非常像。由于一开始不知道这个哪个胶囊与输出的胶囊有关系,所以默认相关性分数都一样,然后进入迭代。
|
||||
|
||||
在每一次迭代中,首先把分数转成权重,然后加权求和得到$s$,这个很类似于注意力机制的步骤,得到$s$之后,通过归一化操作,得到$a$,接下来要通过$a$和输入胶囊的相关性以及上一轮的$b_i$来更新$b_i$。最后那个公式有必要说一下在干嘛:
|
||||
>如果当前的$a$与某一个输入胶囊$u_i$非常相关,即内积结果很大的话,那么相应的下一轮的该输入胶囊对应的$b_i$就会变大, 那么, 在计算下一轮的$a$的时候,与上一轮$a$相关的$u_i$就会占主导,相当于下一轮的$a$与上一轮中和他相关的那些$u_i$之间的路径权重会大一些,这样从空间点的角度观察,就相当于$a$点朝与它相关的那些$u$点更近了一点。
|
||||
|
||||
通过若干次迭代之后,得到最后的输出胶囊向量$a$会慢慢的走到与它更相关的那些$u$附近,而远离那些与它不相干的$u$。所以上面的这个迭代过程有点像**排除异常输入胶囊的感觉**。
|
||||
|
||||
|
||||
|
||||
而从另一个角度来考虑,这个过程其实像是聚类的过程,因为胶囊的输出向量$v$经过若干次迭代之后,会最终停留到与其非常相关的那些输入胶囊里面,而这些输入胶囊,其实就可以看成是某个类别了,因为既然都共同的和输出胶囊$v$比较相关,那么彼此之间的相关性也比较大,于是乎,经过这样一个动态路由机制之后,就不自觉的,把输入胶囊实现了聚类。把和与其他输入胶囊不同的那些胶囊给排除了出去。
|
||||
|
||||
所以,这个动态路由机制的计算设计的还是比较巧妙的, 下面是上述过程的展开计算过程, 这个和RNN的计算有点类似:
|
||||
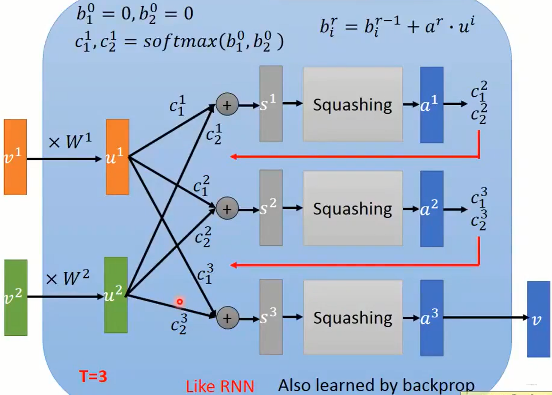
|
||||
这样就完成了一个胶囊内部的计算过程了。
|
||||
|
||||
Ok, 有了上面的这些铺垫,再来看MIND就会比较简单了。下面正式对MIND模型的网络架构剖析。
|
||||
|
||||
## 4. MIND模型的网络结构与细节剖析
|
||||
### 4.1 网络整体结构
|
||||
MIND网络的架构如下:
|
||||

|
||||
初步先分析这个网络结构的运作: 首先接收的输入有三类特征,用户base属性,历史行为属性以及商品的属性,用户的历史行为序列属性过了一个多兴趣提取层得到了多个兴趣胶囊,接下来和用户base属性拼接过DNN,得到了交互之后的用户兴趣。然后在训练阶段,用户兴趣和当前商品向量过一个label-aware attention,然后求softmax损失。 在服务阶段,得到用户的向量之后,就可以直接进行近邻检索,找候选商品了。 这就是宏观过程,但是,多兴趣提取层以及这个label-aware attention是在做什么事情呢? 如果单独看这个图,感觉得到多个兴趣胶囊之后,直接把这些兴趣胶囊以及用户的base属性拼接过全连接,那最终不就成了一个用户向量,此时label-aware attention的意义不就没了? 所以这个图初步感觉画的有问题,和论文里面描述的不符。所以下面先以论文为主,正式开始描述具体细节。
|
||||
|
||||
### 4.2 任务目标
|
||||
召回任务的目标是对于每一个用户$u \in \mathcal{U}$从十亿规模的物品池$\mathcal{I}$检索出包含与用户兴趣相关的上千个物品集。
|
||||
#### 4.2.1 模型的输入
|
||||
对于模型,每个样本的输入可以表示为一个三元组:$\left(\mathcal{I}_{u}, \mathcal{P}_{u}, \mathcal{F}_{i}\right)$,其中$\mathcal{I}_{u}$代表与用户$u$交互过的物品集,即用户的历史行为;$\mathcal{P}_{u}$表示用户的属性,例如性别、年龄等;$\mathcal{F}_{i}$定义为目标物品$i$的一些特征,例如物品id和种类id等。
|
||||
#### 4.2.2 任务描述
|
||||
MIND的核心任务是学习一个从原生特征映射到**用户表示**的函数,用户表示定义为:
|
||||
$$
|
||||
\mathrm{V}_{u}=f_{u s e r}\left(\mathcal{I}_{u}, \mathcal{P}_{u}\right)
|
||||
$$
|
||||
其中,$\mathbf{V}_{u}=\left(\overrightarrow{\boldsymbol{v}}_{u}^{1}, \ldots, \overrightarrow{\boldsymbol{v}}_{u}^{K}\right) \in \mathbb{R}^{d \times k}$是用户$u$的表示向量,$d$是embedding的维度,$K$表示向量的个数,即兴趣的数量。如果$K=1$,那么MIND模型就退化成YouTubeDNN的向量表示方式了。
|
||||
|
||||
目标物品$i$的embedding函数为:
|
||||
$$
|
||||
\overrightarrow{\mathbf{e}}_{i}=f_{\text {item }}\left(\mathcal{F}_{i}\right)
|
||||
$$
|
||||
其中,$\overrightarrow{\mathbf{e}}_{i} \in \mathbb{R}^{d \times 1}, \quad f_{i t e m}(\cdot)$表示一个embedding&pooling层。
|
||||
#### 4.2.3 最终结果
|
||||
根据评分函数检索(根据**目标物品与用户表示向量的内积的最大值作为相似度依据**,DIN的Attention部分也是以这种方式来衡量两者的相似度),得到top N个候选项:
|
||||
|
||||
$$
|
||||
f_{\text {score }}\left(\mathbf{V}_{u}, \overrightarrow{\mathbf{e}}_{i}\right)=\max _{1 \leq k \leq K} \overrightarrow{\mathbf{e}}_{i}^{\mathrm{T}} \overrightarrow{\mathbf{V}}_{u}^{\mathrm{k}}
|
||||
$$
|
||||
|
||||
### 4.3 Embedding & Pooling层
|
||||
Embedding层的输入由三部分组成,用户属性$\mathcal{P}_{u}$、用户行为$\mathcal{I}_{u}$和目标物品标签$\mathcal{F}_{i}$。每一部分都由多个id特征组成,则是一个高维的稀疏数据,因此需要Embedding技术将其映射为低维密集向量。具体来说,
|
||||
|
||||
* 对于$\mathcal{P}_{u}$的id特征(年龄、性别等)是将其Embedding的向量进行Concat,组成用户属性Embedding$\overrightarrow{\mathbf{p}}_{u}$;
|
||||
* 目标物品$\mathcal{F}_{i}$通常包含其他分类特征id(品牌id、店铺id等) ,这些特征有利于物品的冷启动问题,需要将所有的分类特征的Embedding向量进行平均池化,得到一个目标物品向量$\overrightarrow{\mathbf{e}}_{i}$;
|
||||
* 对于用户行为$\mathcal{I}_{u}$,由物品的Embedding向量组成用户行为Embedding列表$E_{u}=\overrightarrow{\mathbf{e}}_{j}, j \in \mathcal{I}_{u}$, 当然这里不仅只有物品embedding哈,也可能有类别,品牌等其他的embedding信息。
|
||||
|
||||
### 4.4 Multi-Interest Extractor Layer(核心)
|
||||
作者认为,单一的向量不足以表达用户的多兴趣。所以作者采用**多个表示向量**来分别表示用户不同的兴趣。通过这个方式,在召回阶段,用户的多兴趣可以分别考虑,对于兴趣的每一个方面,能够更精确的进行物品检索。
|
||||
|
||||
为了学习多兴趣表示,作者利用胶囊网络表示学习的动态路由将用户的历史行为分组到多个簇中。来自一个簇的物品应该密切相关,并共同代表用户兴趣的一个特定方面。
|
||||
|
||||
由于多兴趣提取器层的设计灵感来自于胶囊网络表示学习的动态路由,所以这里作者回顾了动态路由机制。当然,如果之前对胶囊网络或动态路由不了解,这里读起来就会有点艰难,但由于我上面进行了铺垫,这里就直接拿过原文并解释即可。
|
||||
#### 4.4.1 动态路由
|
||||
动态路由是胶囊网络中的迭代学习算法,用于学习低水平胶囊和高水平胶囊之间的路由对数(logit)$b_{ij}$,来得到高水平胶囊的表示。
|
||||
|
||||
我们假设胶囊网络有两层,即低水平胶囊$\vec{c}_{i}^{l} \in \mathbb{R}^{N_{l} \times 1}, i \in\{1, \ldots, m\}$和高水平胶囊$\vec{c}_{j}^{h} \in \mathbb{R}^{N_{h} \times 1}, j \in\{1, \ldots, n\}$,其中$m,n$表示胶囊的个数, $N_l,N_h$表示胶囊的维度。 路由对数$b_{ij}$计算公式如下:
|
||||
$$
|
||||
b_{i j}=\left(\vec{c}_{j}^{h}\right)^{T} \mathrm{~S}_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
其中$\mathbf{S}_{i j} \in \mathbb{R}^{N_{h} \times N_{l}}$表示待学习的双线性映射矩阵【在胶囊网络的原文中称为转换矩阵】
|
||||
|
||||
通过计算路由对数,将高阶胶囊$j$的候选向量计算为所有低阶胶囊的加权和:
|
||||
$$
|
||||
\vec{z}_{j}^{h}=\sum_{i=1}^{m} w_{i j} S_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
其中$w_{ij}$定义为连接低阶胶囊$i$和高阶胶囊$j$的权重【称为耦合系数】,而且其通过对路由对数执行softmax来计算:
|
||||
$$
|
||||
w_{i j}=\frac{\exp b_{i j}}{\sum_{k=1}^{m} \exp b_{i k}}
|
||||
$$
|
||||
最后,应用一个非线性的“压缩”函数来获得一个高阶胶囊的向量【胶囊网络向量的模表示由胶囊所代表的实体存在的概率】
|
||||
$$
|
||||
\vec{c}_{j}^{h}=\operatorname{squash}\left(\vec{z}_{j}^{h}\right)=\frac{\left\|\vec{z}_{j}^{h}\right\|^{2}}{1+\left\|\vec{z}_{j}^{h}\right\|^{2}} \frac{\vec{z}_{j}^{h}}{\left\|\vec{z}_{j}^{h}\right\|}
|
||||
$$
|
||||
路由过程重复进行3次达到收敛。当路由结束,高阶胶囊值$\vec{c}_{j}^{h}$固定,作为下一层的输入。
|
||||
|
||||
Ok,下面我们开始解释,其实上面说的这些就是胶囊网络的计算过程,只不过和之前所用的符号不一样了。这里拿个图:
|
||||
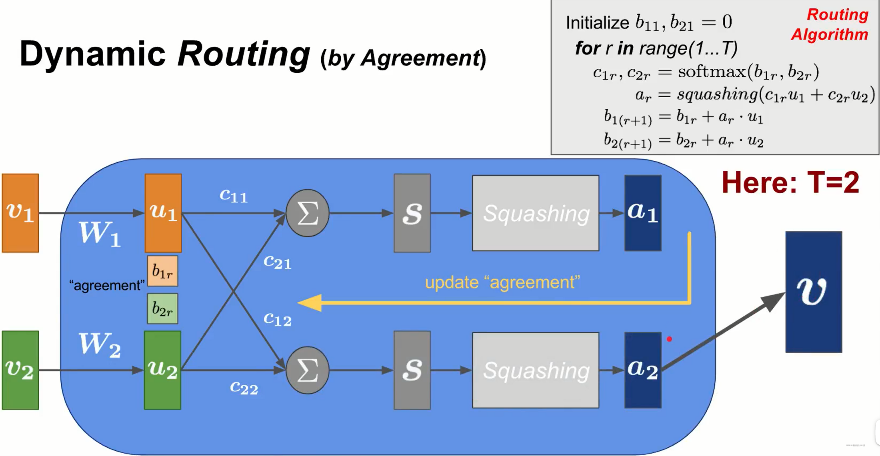
|
||||
首先,论文里面也是个两层的胶囊网络,低水平层->高水平层。 低水平层有$m$个胶囊,每个胶囊向量维度是$N_l$,用$\vec{c}_{i}^l$表示的,高水平层有$n$个胶囊,每个胶囊$N_h$维,用$\vec{c}_{j}^h$表示。
|
||||
|
||||
单独拿出每个$\vec{c}_{j}^h$,其计算过程如上图所示。首先,先随机初始化路由对数$b_{ij}=0$,然后开始迭代,对于每次迭代:
|
||||
$$
|
||||
w_{i j}=\frac{\exp b_{i j}}{\sum_{k=1}^{m} \exp b_{i k}} \\
|
||||
\vec{z}_{j}^{h}=\sum_{i=1}^{m} w_{i j} S_{i j} \vec{c}_{i}^{l} \\ \vec{c}_{j}^{h}=\operatorname{squash}\left(\vec{z}_{j}^{h}\right)=\frac{\left\|\vec{z}_{j}^{h}\right\|^{2}}{1+\left\|\vec{z}_{j}^{h}\right\|^{2}} \frac{\vec{z}_{j}^{h}}{\left\|\vec{z}_{j}^{h}\right\|} \\ b_{i j}=\left(\vec{c}_{j}^{h}\right)^{T} \mathrm{~S}_{i j} \vec{c}_{i}^{l}
|
||||
$$
|
||||
只不过这里的符合和上图中的不太一样,这里的$w_{ij}$对应的是每个输入胶囊的权重$c_{ij}$, 这里的$\vec{c}_{j}^h$对应上图中的$a$, 这里的$\vec{z}_{j}^h$对应的是输入胶囊的加权组合。这里的$\vec{c}_{i}^l$对应上图中的$v_i$,这里的$S_{ij}$对应的是上图的权重$W_{ij}$,只不过这个可以换成矩阵运算。 和上图中不同的是路由对数$b_{ij}$更新那里,没有了上一层的路由对数值,但感觉这样会有问题。
|
||||
|
||||
所以,这样解释完之后就会发现,其实上面的一顿操作就是说的传统的动态路由机制。
|
||||
|
||||
#### 4.4.2 B2I动态路由
|
||||
作者设计的多兴趣提取层就是就是受到了上述胶囊网络的启发。
|
||||
|
||||
如果把用户的行为序列看成是行为胶囊, 把用户的多兴趣看成兴趣胶囊,那么多兴趣提取层就是利用动态路由机制学习行为胶囊`->`兴趣胶囊的映射关系。但是原始路由算法无法直接应用于处理用户行为数据。因此,提出了**行为(Behavior)到兴趣(Interest)(B2I)动态路由**来自适应地将用户的行为聚合到兴趣表示向量中,它与原始路由算法有三个不同之处:
|
||||
|
||||
1. **共享双向映射矩阵**。在初始动态路由中,使用固定的或者说共享的双线性映射矩阵$S$而不是单独的双线性映射矩阵, 在原始的动态路由中,对于每个输出胶囊$\vec{c}_{j}^h$,都会有对应的$S_{ij}$,而这里是每个输出胶囊,都共用一个$S$矩阵。 原因有两个:
|
||||
1. 一方面,用户行为是可变长度的,从几十个到几百个不等,因此使用共享的双线性映射矩阵是有利于泛化。
|
||||
2. 另一方面,希望兴趣胶囊在同一个向量空间中,但不同的双线性映射矩阵将兴趣胶囊映射到不同的向量空间中。因为映射矩阵的作用就是对用户的行为胶囊进行线性映射嘛, 由于用户的行为序列都是商品,所以希望经过映射之后,到统一的商品向量空间中去。路由对数计算如下:
|
||||
$$
|
||||
b_{i j}=\overrightarrow{\boldsymbol{u}}_{j}^{T} \mathrm{S\overrightarrow{e}}_{i}, \quad i \in \mathcal{I}_{u}, j \in\{1, \ldots, K\}
|
||||
$$
|
||||
其中,$\overrightarrow{\boldsymbol{e}}_{i} \in \mathbb{R}^{d}$是历史物品$i$的embedding,$\vec{u}_{j} \in \mathbb{R}^{d}$表示兴趣胶囊$j$的向量。$S \in \mathbb{R}^{d \times d}$是每一对行为胶囊(低价)到兴趣胶囊(高阶)之间 的共享映射矩阵。
|
||||
|
||||
|
||||
2. **随机初始化路由对数**。由于利用共享双向映射矩阵$S$,如果再初始化路由对数为0将导致相同的初始的兴趣胶囊。随后的迭代将陷入到一个不同兴趣胶囊在所有的时间保持相同的情景。因为每个输出胶囊的运算都一样了嘛(除非迭代的次数不同,但这样也会导致兴趣胶囊都很类似),为了减轻这种现象,作者通过高斯分布进行随机采样来初始化路由对数$b_{ij}$,让初始兴趣胶囊与其他每一个不同,其实就是希望在计算每个输出胶囊的时候,通过随机化的方式,希望这几个聚类中心离得远一点,这样才能表示出广泛的用户兴趣(我们已经了解这个机制就仿佛是聚类,而计算过程就是寻找聚类中心)。
|
||||
3. **动态的兴趣数量**,兴趣数量就是聚类中心的个数,由于不同用户的历史行为序列不同,那么相应的,其兴趣胶囊有可能也不一样多,所以这里使用了一种启发式方式自适应调整聚类中心的数量,即$K$值。
|
||||
$$
|
||||
K_{u}^{\prime}=\max \left(1, \min \left(K, \log _{2}\left(\left|\mathcal{I}_{u}\right|\right)\right)\right)
|
||||
$$
|
||||
这种调整兴趣胶囊数量的策略可以为兴趣较小的用户节省一些资源,包括计算和内存资源。这个公式不用多解释,与行为序列长度成正比。
|
||||
|
||||
最终的B2I动态路由算法如下:
|
||||

|
||||
应该很好理解了吧。
|
||||
|
||||
### 4.5 Label-aware Attention Layer
|
||||
通过多兴趣提取器层,从用户的行为embedding中生成多个兴趣胶囊。不同的兴趣胶囊代表用户兴趣的不同方面,相应的兴趣胶囊用于评估用户对特定类别的偏好。所以,在训练的期间,最后需要设置一个Label-aware的注意力层,对于当前的商品,根据相关性选择最相关的兴趣胶囊。这里其实就是一个普通的注意力机制,和DIN里面的那个注意力层基本上是一模一样,计算公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\overrightarrow{\boldsymbol{v}}_{u} &=\operatorname{Attention}\left(\overrightarrow{\boldsymbol{e}}_{i}, \mathrm{~V}_{u}, \mathrm{~V}_{u}\right) \\
|
||||
&=\mathrm{V}_{u} \operatorname{softmax}\left(\operatorname{pow}\left(\mathrm{V}_{u}^{\mathrm{T}} \overrightarrow{\boldsymbol{e}}_{i}, p\right)\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
首先这里的$\overrightarrow{\boldsymbol{e}}_{i}$表示当前的商品向量,$V_u$表示用户的多兴趣向量组合,里面有$K$个向量,表示用户的$K$的兴趣。用户的各个兴趣向量与目标商品做内积,然后softmax转成权重,然后反乘到多个兴趣向量进行加权求和。 但是这里需要注意的一个小点,就是这里做内积求完相似性之后,先做了一个指数操作,**这个操作其实能放大或缩小相似程度**,至于放大或者缩小的程度,由$p$控制。 比如某个兴趣向量与当前商品非常相似,那么再进行指数操作之后,如果$p$也很大,那么显然这个兴趣向量就占了主导作用。$p$是一个可调节的参数来调整注意力分布。当$p$接近0,每一个兴趣胶囊都得到相同的关注。当$p$大于1时,随着$p$的增加,具有较大值的点积将获得越来越多的权重。考虑极限情况,当$p$趋近于无穷大时,注意机制就变成了一种硬注意,选关注最大的值而忽略其他值。在实验中,发现使用硬注意导致更快的收敛。
|
||||
>理解:$p$小意味着所有的相似程度都缩小了, 使得之间的差距会变小,所以相当于每个胶囊都会受到关注,而越大的话,使得各个相似性差距拉大,相似程度越大的会更大,就类似于贫富差距, 最终使得只关注于比较大的胶囊。
|
||||
|
||||
### 4.6 训练与服务
|
||||
得到用户向量$\overrightarrow{\boldsymbol{v}}_{u}$和标签物品embedding$\vec{e}_{i}$后,计算用户$u$与标签物品$i$交互的概率:
|
||||
$$
|
||||
\operatorname{Pr}(i \mid u)=\operatorname{Pr}\left(\vec{e}_{i} \mid \vec{v}_{u}\right)=\frac{\exp \left(\vec{v}_{u}^{\mathrm{T} \rightarrow}\right)}{\sum_{j \in I} \exp \left(\vec{v}_{u}^{\mathrm{T}} \vec{e}_{j}\right)}
|
||||
$$
|
||||
目标函数是:
|
||||
$$
|
||||
L=\sum_{(u, i) \in \mathcal{D}} \log \operatorname{Pr}(i \mid u)
|
||||
$$
|
||||
其中$\mathcal{D}$是训练数据包含用户物品交互的集合。因为物品的数量可伸缩到数十亿,所以不能直接算。因此。使用采样的softmax技术,并且选择Adam优化来训练MIND。
|
||||
|
||||
训练结束后,抛开label-aware注意力层,MIND网络得到一个用户表示映射函数$f_{user}$。在服务期间,用户的历史序列与自身属性喂入到$f_{user}$,每个用户得到多兴趣向量。然后这个表示向量通过一个近似邻近方法来检索top N物品。
|
||||
|
||||
这就是整个MIND模型的细节了。
|
||||
|
||||
## 5. MIND模型之简易代码复现
|
||||
下面参考Deepctr,用简易的代码实现下MIND,并在新闻推荐的数据集上进行召回任务。
|
||||
|
||||
### 5.1 整个代码架构
|
||||
|
||||
整个MIND模型算是参考deepmatch修改的一个简易版本:
|
||||
|
||||
```python
|
||||
def MIND(user_feature_columns, item_feature_columns, num_sampled=5, k_max=2, p=1.0, dynamic_k=False, user_dnn_hidden_units=(64, 32),
|
||||
dnn_activation='relu', dnn_use_bn=False, l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, output_activation='linear', seed=1024):
|
||||
"""
|
||||
:param k_max: 用户兴趣胶囊的最大个数
|
||||
"""
|
||||
# 目前这里只支持item_feature_columns为1的情况,即只能转入item_id
|
||||
if len(item_feature_columns) > 1:
|
||||
raise ValueError("Now MIND only support 1 item feature like item_id")
|
||||
|
||||
# 获取item相关的配置参数
|
||||
item_feature_column = item_feature_columns[0]
|
||||
item_feature_name = item_feature_column.name
|
||||
item_vocabulary_size = item_feature_column.vocabulary_size
|
||||
item_embedding_dim = item_feature_column.embedding_dim
|
||||
|
||||
behavior_feature_list = [item_feature_name]
|
||||
|
||||
# 为用户特征创建Input层
|
||||
user_input_layer_dict = build_input_layers(user_feature_columns)
|
||||
item_input_layer_dict = build_input_layers(item_feature_columns)
|
||||
# 将Input层转化成列表的形式作为model的输入
|
||||
user_input_layers = list(user_input_layer_dict.values())
|
||||
item_input_layers = list(item_input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse特征和dense特征,方便单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
varlen_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
|
||||
# 由于这个变长序列里面只有历史点击文章,没有类别啥的,所以这里直接可以用varlen_feature_columns
|
||||
# deepctr这里单独把点击文章这个放到了history_feature_columns
|
||||
seq_max_len = varlen_feature_columns[0].maxlen
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(user_feature_columns+item_feature_columns)
|
||||
|
||||
# 获取当前的行为特征(doc)的embedding,这里面可能又多个类别特征,所以需要pooling下
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, item_input_layer_dict, embedding_layer_dict) # 长度为1
|
||||
# 获取行为序列(doc_id序列, hist_doc_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
keys_embed_list = embedding_lookup([varlen_feature_columns[0].name], user_input_layer_dict, embedding_layer_dict) # 长度为1
|
||||
|
||||
# 用户离散特征的输入层与embedding层拼接
|
||||
dnn_input_emb_list = embedding_lookup([col.name for col in sparse_feature_columns], user_input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 获取dense
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
if fc.name != 'hist_len': # 连续特征不要这个
|
||||
dnn_dense_input.append(user_input_layer_dict[fc.name])
|
||||
|
||||
# 把keys_emb_list和query_emb_listpooling操作, 这是因为可能每个商品不仅有id,还可能用类别,品牌等多个embedding向量,这种需要pooling成一个
|
||||
history_emb = PoolingLayer()(NoMask()(keys_embed_list)) # (None, 50, 8)
|
||||
target_emb = PoolingLayer()(NoMask()(query_embed_list)) # (None, 1, 8)
|
||||
|
||||
hist_len = user_input_layer_dict['hist_len']
|
||||
# 胶囊网络
|
||||
# (None, 2, 8) 得到了两个兴趣胶囊
|
||||
high_capsule = CapsuleLayer(input_units=item_embedding_dim, out_units=item_embedding_dim,
|
||||
max_len=seq_max_len, k_max=k_max)((history_emb, hist_len))
|
||||
|
||||
|
||||
# 把用户的其他特征拼接到胶囊网络上来
|
||||
if len(dnn_input_emb_list) > 0 or len(dnn_dense_input) > 0:
|
||||
user_other_feature = combined_dnn_input(dnn_input_emb_list, dnn_dense_input)
|
||||
# (None, 2, 32) 这里会发现其他的用户特征是每个胶囊复制了一份,然后拼接起来
|
||||
other_feature_tile = tf.keras.layers.Lambda(tile_user_otherfeat, arguments={'k_max': k_max})(user_other_feature)
|
||||
user_deep_input = Concatenate()([NoMask()(other_feature_tile), high_capsule]) # (None, 2, 40)
|
||||
else:
|
||||
user_deep_input = high_capsule
|
||||
|
||||
# 接下来过一个DNN层,获取最终的用户表示向量 如果是三维输入, 那么最后一个维度与w相乘,所以这里如果不自己写,可以用Dense层的列表也可以
|
||||
user_embeddings = DNN(user_dnn_hidden_units, dnn_activation, l2_reg_dnn,
|
||||
dnn_dropout, dnn_use_bn, output_activation=output_activation, seed=seed,
|
||||
name="user_embedding")(user_deep_input) # (None, 2, 8)
|
||||
|
||||
# 接下来,过Label-aware layer
|
||||
if dynamic_k:
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb, hist_len))
|
||||
else:
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb))
|
||||
|
||||
# 接下来
|
||||
item_embedding_matrix = embedding_layer_dict[item_feature_name] # 获取doc_id的embedding层
|
||||
item_index = EmbeddingIndex(list(range(item_vocabulary_size)))(item_input_layer_dict[item_feature_name]) # 所有doc_id的索引
|
||||
item_embedding_weight = NoMask()(item_embedding_matrix(item_index)) # 拿到所有item的embedding
|
||||
pooling_item_embedding_weight = PoolingLayer()([item_embedding_weight]) # 这里依然是当可能不止item_id,或许还有brand_id, cat_id等,需要池化
|
||||
|
||||
# 这里传入的是整个doc_id的embedding, user_embedding, 以及用户点击的doc_id,然后去进行负采样计算损失操作
|
||||
output = SampledSoftmaxLayer(num_sampled)([pooling_item_embedding_weight, user_embedding_final, item_input_layer_dict[item_feature_name]])
|
||||
|
||||
model = Model(inputs=user_input_layers+item_input_layers, outputs=output)
|
||||
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", user_embeddings)
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
|
||||
return model
|
||||
```
|
||||
简单说下流程, 函数式API搭建模型的方式,首先我们需要传入封装好的用户特征描述以及item特征描述,比如:
|
||||
|
||||
```python
|
||||
# 建立模型
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
|
||||
VarLenSparseFeat(SparseFeat('hist_doc_ids', feature_max_idx['article_id'], embedding_dim,
|
||||
embedding_name="click_doc_id"), his_seq_maxlen, 'mean', 'hist_len'),
|
||||
DenseFeat('hist_len', 1),
|
||||
SparseFeat('u_city', feature_max_idx['city'], embedding_dim),
|
||||
SparseFeat('u_age', feature_max_idx['age'], embedding_dim),
|
||||
SparseFeat('u_gender', feature_max_idx['gender'], embedding_dim),
|
||||
]
|
||||
doc_feature_columns = [
|
||||
SparseFeat('click_doc_id', feature_max_idx['article_id'], embedding_dim)
|
||||
# 这里后面也可以把文章的类别画像特征加入
|
||||
]
|
||||
```
|
||||
首先, 函数会对传入的这种特征建立模型的Input层,主要是`build_input_layers`函数。建立完了之后,获取到Input层列表,这个是为了最终定义模型用的,keras要求定义模型的时候是列表的形式。
|
||||
|
||||
接下来是选出sparse特征和Dense特征来,这个也是常规操作了,因为不同的特征后面处理方式不一样,对于sparse特征,后面要接embedding层,Dense特征的话,直接可以拼接起来。这就是筛选特征的3行代码。
|
||||
|
||||
接下来,是为所有的离散特征建立embedding层,通过函数`build_embedding_layers`。建立完了之后,把item相关的embedding层与对应的Input层接起来,作为query_embed_list, 而用户历史行为序列的embedding层与Input层接起来作为keys_embed_list,这两个有单独的用户。而Input层与embedding层拼接是通过`embedding_lookup`函数完成的。 这样完成了之后,就能通过Input层-embedding层拿到item的系列embedding,以及历史序列里面item系列embedding,之所以这里是系列embedding,是有可能不止item_id这一个特征,还可能有品牌id, 类别id等好几个,所以接下来把系列embedding通过pooling操作,得到最终表示item的向量。 就是这两行代码:
|
||||
|
||||
```python
|
||||
# 把keys_emb_list和query_emb_listpooling操作, 这是因为可能每个商品不仅有id,还可能用类别,品牌等多个embedding向量,这种需要pooling成一个
|
||||
history_emb = PoolingLayer()(NoMask()(keys_embed_list)) # (None, 50, 8)
|
||||
target_emb = PoolingLayer()(NoMask()(query_embed_list)) # (None, 1, 8)
|
||||
```
|
||||
而像其他的输入类别特征, 依然是Input层与embedding层拼起来,留着后面用,这个存到了dnn_input_emb_list中。 而dense特征, 不需要embedding层,直接通过Input层获取到,然后存到列表里面,留着后面用。
|
||||
|
||||
上面得到的history_emb,就是用户的历史行为序列,这个东西接下来要过兴趣提取层,去学习用户的多兴趣,当然这里还需要传入行为序列的真实长度。因为每个用户行为序列不一样长,通过mask让其等长了,但是真实在胶囊网络计算的时候,这些填充的序列是要被mask掉的。所以必须要知道真实长度。
|
||||
|
||||
```python
|
||||
# 胶囊网络
|
||||
# (None, 2, 8) 得到了两个兴趣胶囊
|
||||
high_capsule = CapsuleLayer(input_units=item_embedding_dim, out_units=item_embedding_dim,max_len=seq_max_len, k_max=k_max)((history_emb, hist_len))
|
||||
```
|
||||
通过这步操作,就得到了两个兴趣胶囊。 至于具体细节,下一节看。 然后把用户的其他特征拼接上来,这里有必要看下代码究竟是怎么拼接的:
|
||||
|
||||
```python
|
||||
# 把用户的其他特征拼接到胶囊网络上来
|
||||
if len(dnn_input_emb_list) > 0 or len(dnn_dense_input) > 0:
|
||||
user_other_feature = combined_dnn_input(dnn_input_emb_list, dnn_dense_input)
|
||||
# (None, 2, 32) 这里会发现其他的用户特征是每个胶囊复制了一份,然后拼接起来
|
||||
other_feature_tile = tf.keras.layers.Lambda(tile_user_otherfeat, arguments={'k_max': k_max})(user_other_feature)
|
||||
user_deep_input = Concatenate()([NoMask()(other_feature_tile), high_capsule]) # (None, 2, 40)
|
||||
else:
|
||||
user_deep_input = high_capsule
|
||||
```
|
||||
这里会发现,使用了一个Lambda层,这个东西的作用呢,其实是将用户的其他特征在胶囊个数的维度上复制了一份,再拼接,这就相当于在每个胶囊的后面都拼接上了用户的基础特征。这样得到的维度就成了(None, 2, 40),2是胶囊个数, 40是兴趣胶囊的维度+其他基础特征维度总和。这样拼完了之后,接下来过全连接层
|
||||
|
||||
```python
|
||||
# 接下来过一个DNN层,获取最终的用户表示向量 如果是三维输入, 那么最后一个维度与w相乘,所以这里如果不自己写,可以用Dense层的列表也可以
|
||||
user_embeddings = DNN(user_dnn_hidden_units, dnn_activation, l2_reg_dnn,
|
||||
dnn_dropout, dnn_use_bn, output_activation=output_activation, seed=seed,
|
||||
name="user_embedding")(user_deep_input) # (None, 2, 8)
|
||||
```
|
||||
最终得到的是(None, 2, 8)的向量,这样就解决了之前的那个疑问, 最终得到的兴趣向量个数并不是1个,而是多个兴趣向量了,因为上面用户特征拼接,是每个胶囊后面都拼接一份同样的特征。另外,就是原来DNN这里的输入还可以是3维的,这样进行运算的话,是最后一个维度与W进行运算,相当于只在第3个维度上进行了降维操作后者非线性操作,这样得到的兴趣个数是不变的。
|
||||
|
||||
这样,有了两个兴趣的输出之后,接下来,就是过LabelAwareAttention层了,对这两个兴趣向量与当前item的相关性加注意力权重,最后变成1个用户的最终向量。
|
||||
|
||||
```python
|
||||
user_embedding_final = LabelAwareAttention(k_max=k_max, pow_p=p,)((user_embeddings, target_emb))
|
||||
```
|
||||
这样,就得到了用户的最终表示向量,当然这个操作仅是训练的时候,服务的时候是拿的上面DNN的输出,即多个兴趣,这里注意一下。
|
||||
|
||||
拿到了最终的用户向量,如何计算损失呢? 这里用了负采样层进行操作。关于这个层具体的原理,后面我们可能会出一篇文章总结。
|
||||
|
||||
接下来有几行代码也需要注意:
|
||||
|
||||
```python
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", user_embeddings)
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
```
|
||||
这几行代码是为了模型训练完,我们给定输入之后,拿embedding用的,设置好了之后,通过:
|
||||
|
||||
```python
|
||||
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
|
||||
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
|
||||
|
||||
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
|
||||
# user_embs = user_embs[:, i, :] # i in [0,k_max) if MIND
|
||||
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
|
||||
```
|
||||
这样就能拿到用户和item的embedding, 接下来近邻检索完成召回过程。 注意,MIND的话,这里是拿到的多个兴趣向量的。
|
||||
|
||||
## 6. 小总
|
||||
今天这篇文章整理的MIND,这是一个多兴趣的召回模型,核心是兴趣提取层,该层通过动态路由机制能够自动的对用户的历史行为序列进行聚类,得到多个兴趣向量,这样能在召回阶段捕获到用户的广泛兴趣,从而召回更好的候选商品。
|
||||
|
||||
|
||||
**参考**:
|
||||
* Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
|
||||
* [ AI上推荐 之 MIND(动态路由与胶囊网络的奇光异彩)](https://blog.csdn.net/wuzhongqiang/article/details/123696462?spm=1001.2014.3001.5501)
|
||||
* [Dynamic Routing Between Capsule ](https://arxiv.org/pdf/1710.09829.pdf)
|
||||
* [CIKM2019|MIND---召回阶段的多兴趣模型](https://zhuanlan.zhihu.com/p/262638999)
|
||||
* [B站胶囊网络课程](https://www.bilibili.com/video/BV1eW411Q7CE?p=2)
|
||||
* [胶囊网络识别交通标志](https://blog.csdn.net/shebao3333/article/details/79008688)
|
||||
|
||||
|
||||
404
docs/推荐算法基础/经典召回模型/基于序列的召回/SDM模型.md
Normal file
404
docs/推荐算法基础/经典召回模型/基于序列的召回/SDM模型.md
Normal file
@@ -0,0 +1,404 @@
|
||||
## 1. 写在前面
|
||||
SDM模型(Sequential Deep Matching Model),是阿里团队在2019年CIKM上的一篇paper。和MIND模型一样,是一种序列召回模型,研究的依然是如何通过用户的历史行为序列去学习到用户的丰富兴趣。 对于MIND,我们已经知道是基于胶囊网络的动态路由机制,设计了一个动态兴趣提取层,把用户的行为序列通过路由机制聚类,然后映射成了多个兴趣胶囊,以此来获取到用户的广泛兴趣。而SDM模型,是先把用户的历史序列根据交互的时间分成了短期和长期两类,然后从**短期会话**和**长期行为**中分别采取**相应的措施(短期的RNN+多头注意力, 长期的Att Net)** 去学习到用户的短期兴趣和长期行为偏好,并**巧妙的设计了一个门控网络==有选择==的将长短期兴趣进行融合**,以此得到用户的最终兴趣向量。 这篇paper中的一些亮点,比如长期偏好的行为表示,多头注意力机制学习多兴趣,长短期兴趣的融合机制等,又给了一些看待问题的新角度,同时,给出了我们一种利用历史行为序列去捕捉用户动态偏好的新思路。
|
||||
|
||||
这篇paper依然是从引言开始, 介绍SDM模型提出的动机以及目前方法存在的不足(why), 接下来就是SDM的网络模型架构(what), 这里面的关键是如何从短期会话和长期行为两个方面学习到用户的短期长期偏好(how),最后,依然是简易代码实现。
|
||||
|
||||
大纲如下:
|
||||
* 背景与动机
|
||||
* SDM的网络结构与细节
|
||||
* SDM模型代码复现
|
||||
|
||||
## 2. 背景与动机
|
||||
这里要介绍该模型提出的动机,即why要有这样的一个模型?
|
||||
|
||||
一个好的推荐系统应该是能精确的捕捉用户兴趣偏好以及能对他们当前需求进行快速响应的,往往工业上的推荐系统,为了能快速响应, 一般会把整个推荐流程分成召回和排序两个阶段,先通过召回,从海量商品中得到一个小的候选集,然后再给到排序模型做精确的筛选操作。 这也是目前推荐系统的一个范式了。在这个过程中,召回模块所检索到的候选对象的质量在整个系统中起着至关重要的作用。
|
||||
|
||||
淘宝目前的召回模型是一些基于协同过滤的模型, 这些模型是通过用户与商品的历史交互建模,从而得到用户的物品的表示向量,但这个过程是**静态的**,而用户的行为或者兴趣是时刻变化的, 对于协同过滤的模型来说,并不能很好的捕捉到用户整个行为序列的动态变化。
|
||||
|
||||
那我们知道了学习用户历史行为序列很重要, 那么假设序列很长呢?这时候直接用模型学习长序列之间的演进可能不是很好,因为很长的序列里面可能用户的兴趣发生过很大的转变,很多商品压根就没有啥关系,这样硬学,反而会导致越学越乱,就别提这个演进了。所以这里是以会话为单位,对长序列进行切分。作者这里的依据就是用户在同一个Session下,其需求往往是很明确的, 这时候,交互的商品也往往都非常类似。 但是Session与Session之间,可能需求改变,那么商品类型可能骤变。 所以以Session为单位来学习商品之间的序列信息,感觉要比整个长序列学习来的靠谱。
|
||||
|
||||
作者首先是先把长序列分成了多个会话, 然后**把最近的一次会话,和之前的会话分别视为了用户短期行为和长期行为分别进行了建模,并采用不同的措施学习用户的短期兴趣和长期兴趣,然后通过一个门控机制融合得到用户最终的表示向量**。这就是SDM在做的事情,
|
||||
|
||||
|
||||
长短期行为序列联合建模,其实是在给我们提供一种新的学习用户兴趣的新思路, 那么究竟是怎么做的呢?以及为啥这么做呢?
|
||||
* 对于短期用户行为, 首先作者使用了LSTM来学习序列关系, 而接下来是用一个Multi-head attention机制,学习用户的多兴趣。
|
||||
|
||||
先分析分析作者为啥用多头注意力机制,作者这里依然是基于实际的场景出发,作者发现,**用户的兴趣点在一个会话里面其实也是多重的**。这个可能之前的很多模型也是没考虑到的,但在商品购买的场景中,这确实也是个事实, 顾客在买一个商品的时候,往往会进行多方比较, 考虑品牌,颜色,商店等各种因素。作者认为用普通的注意力机制是无法反映广泛的兴趣了,所以用多头注意力网络。
|
||||
|
||||
多头注意力机制从某个角度去看,也有类似聚类的功效,首先它接收了用户的行为序列,然后从多个角度学习到每个商品与其他商品的相关性,然后根据与其他商品的相关性加权融合,这样,相似的item向量大概率就融合到了一块组成一个向量,所谓用户的多兴趣,可能是因为这些行为商品之间,可以从多个空间或者角度去get彼此之间的相关性,这里面有着用户多兴趣的表达信息。
|
||||
|
||||
* 用户的长期行为也会影响当前的决策,作者在这里举了一个NBA粉丝的例子,说如果一个是某个NBA球星的粉丝,那么他可能在之前会买很多有关这个球星的商品,如果现在这个时刻想买鞋的时候,大概率会考虑和球星相关的。所以作者说**长期偏好和短期行为都非常关键**。但是长期偏好或者行为往往是复杂广泛的,就像刚才这个例子里面,可能长期行为里面,买的与这个球星相关商品只占一小部分,而就只有这一小部分对当前决策有用。
|
||||
这个也是之前的模型利用长期偏好方面存在的问题,那么如何选择出长期偏好里面对于当前决策有用的那部分呢? 作者这里设计了一个门控的方式融合短期和长期,这个想法还是很巧妙的,后面介绍这个东西的时候说下我的想法。
|
||||
|
||||
所以下面总结动机以及本篇论文的亮点:
|
||||
* 动机: 召回模型需要捕获用户的动态兴趣变化,这个过程中利用好用户的长期行为和短期偏好非常关键,而以往的模型有下面几点不足:
|
||||
* 协同过滤模型: 基于用户的交互进行静态建模,无法感知用户的兴趣变化过程,易召回同质性的商品
|
||||
* 早期的一些序列推荐模型: 要么是对整个长序列直接建模,但这样太暴力,没法很好的学习商品之间的序列信息,有些是把长序列分成会话,但忽视了一个会话中用户的多重兴趣
|
||||
* 有些方法在考虑用户的长期行为方面,只是简单的拼接或者加权求和,而实际上用户长期行为中只有很少一小部分对当前的预测有用,这样暴力融合反而会适得其反,起不到效果。另外还有一些多任务或者对抗方法, 在工业场景中不适用等。
|
||||
* 这些我只是通过我的理解简单总结,详细内容看原论文相关工作部分。
|
||||
* 亮点:
|
||||
* SDM模型, 考虑了用户的短期行为和长期兴趣,以会话的形式进行分割,并对这两方面分别建模
|
||||
* 短期会话由于对当前决策影响比较大,那么我们就学习的全面一点, 首先RNN学习序列关系,其次通过多头注意力机制捕捉多兴趣,然后通过一个Attention Net加权得到短期兴趣表示
|
||||
* 长期会话通过Attention Net融合,然后过DNN,得到用户的长期表示
|
||||
* 我们设计了一个门控机制,类似于LSTM的那种门控,能巧妙的融合这两种兴趣,得到用户最终的表示向量
|
||||
|
||||
这就是动机与背景总结啦。 那么接下来,SDM究竟是如何学习短期和长期表示,又是如何融合的? 为什么要这么玩?
|
||||
|
||||
## 3. SDM的网络结构与细节剖析
|
||||
### 3.1 问题定义
|
||||
这里本来直接看模型结构,但感觉还是先过一下问题定义吧,毕竟这次涉及到了会话,还有几个小规则。
|
||||
|
||||
$\mathcal{U}$表示用户集合,$\mathcal{I}$表示item集合,模型考虑在时间$t$,是否用户$u$会对$i$产生交互。 对于$u$, 我们能够得到它的历史行为序列,那么先说一下如何进行会话的划分, 这里有三个规则:
|
||||
1. 相同会话ID的商品(后台能获取)算是一个会话
|
||||
2. 相邻的商品,时间间隔小于10分钟(业务自己调整)算一个会话
|
||||
3. 同一个会话中的商品不能超过50个,多出来的放入下一个会话
|
||||
|
||||
这样划分开会话之后, 对于用户$u$的短期行为定义是离目前最近的这次会话, 用$\mathcal{S}^{u}=\left[i_{1}^{u}, \ldots, i_{t}^{u}, \ldots, i_{m}^{u}\right]$表示,$m$是序列长度。 而长期的用户行为是过去一周内的会话,但不包括短期的这次会话, 这个用$\mathcal{L}^{u}$表示。网络推荐架构如下:
|
||||
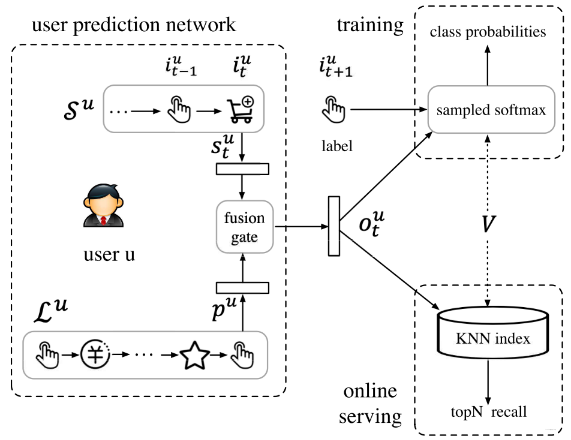
|
||||
这个感觉并不用过多解释。看过召回的应该都能懂, 接收了用户的短期行为和长期行为,然后分别通过两个盲盒得到表示向量,再通过门控融合就得到了最终的用户表示。
|
||||
|
||||
下面要开那三个盲盒操作,即短期行为学习,长期行为学习以及门控融合机制。但在这之前,得先说一个东西,就是输入层这里, 要带物品的side infomation,比如物品的item ID, 物品的品牌ID,商铺ID, 类别ID等等, 那你说,为啥要单独说呢? 之前的模型不也有, 但是这里在利用方式上有些不一样需要注意。
|
||||
|
||||
### 3.2 Input Embedding with side Information
|
||||
在淘宝的推荐场景中,作者发现, 顾客与物品产生交互行为的时候,不仅考虑特定的商品本身,还考虑产品, 商铺,价格等,这个显然。所以,这里对于一个商品来说,不仅要用到Item ID,还用了更多的side info信息,包括`leat category, fist level category, brand,shop`。
|
||||
|
||||
所以,假设用户的短期行为是$\mathcal{S}^{u}=\left[i_{1}^{u}, \ldots, i_{t}^{u}, \ldots, i_{m}^{u}\right]$, 这里面的每个商品$i_t^u$其实有5个属性表示了,每个属性本质是ID,但转成embedding之后,就得到了5个embedding, 所以这里就涉及到了融合问题。 这里用$\boldsymbol{e}_{{i}^u_t} \in \mathbb{R}^{d \times 1}$来表示每个$i_t^u$,但这里不是embedding的pooling操作,而是Concat
|
||||
$$
|
||||
\boldsymbol{e}_{i_{t}^{u}}=\operatorname{concat}\left(\left\{\boldsymbol{e}_{i}^{f} \mid f \in \mathcal{F}\right\}\right)
|
||||
$$
|
||||
其中,$\boldsymbol{e}_{i}^{f}=\boldsymbol{W}^{f} \boldsymbol{x}_{i}^{f} \in \mathbb{R}^{d_{f} \times 1}$, 这个公式看着负责,其实就是每个side info的id过embedding layer得到各自的embedding。这里embedding的维度是$d_f$, 等拼接起来之后,就是$d$维了。这个点要注意。
|
||||
|
||||
另外就是用户的base表示向量了,这个很简单, 就是用户的基础画像,得到embedding,直接也是Concat,这个常规操作不解释:
|
||||
$$
|
||||
\boldsymbol{e}_{u}=\operatorname{concat}\left(\left\{\boldsymbol{e}_{u}^{p} \mid p \in \mathcal{P}\right\}\right)
|
||||
$$
|
||||
$e_u^p$是特征$p$的embedding。
|
||||
|
||||
Ok,输入这里说完了之后,就直接开盲盒, 不按照论文里面的顺序来了。想看更多细节的就去看原论文吧,感觉那里面说的有些啰嗦。不如直接上图解释来的明显:
|
||||
|
||||
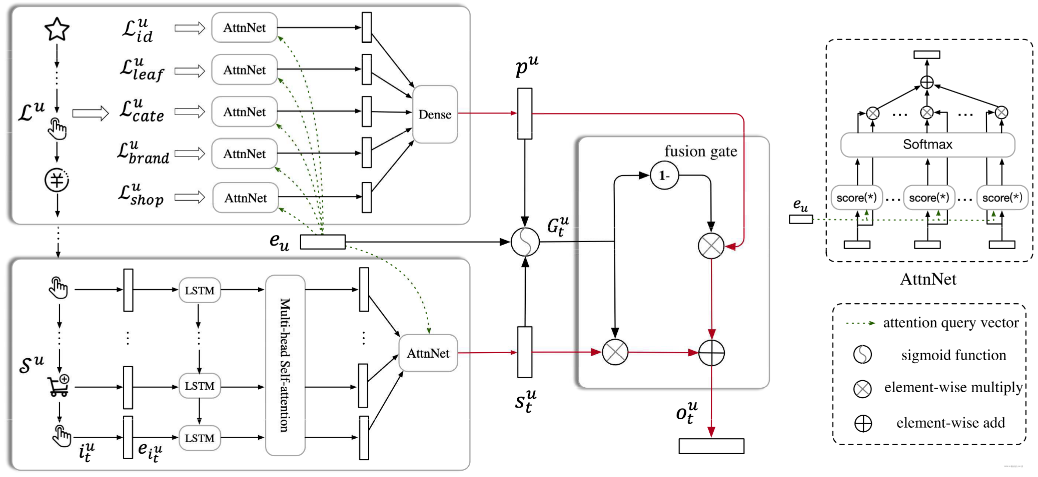
|
||||
这里正好三个框把盒子框住了,下面剖析出每个来就行啦。
|
||||
### 3.3 短期用户行为建模
|
||||
这里短期用户行为是下面的那个框, 接收的输入,首先是用户最近的那次会话,里面各个商品加入了side info信息之后,有了最终的embedding表示$\left[\boldsymbol{e}_{i_{1}^{u}}, \ldots, \boldsymbol{e}_{i_{t}^{u}}\right]$。
|
||||
|
||||
这个东西,首先要过LSTM,学习序列信息,这个感觉不用多说,直接上公式:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\boldsymbol{i} \boldsymbol{n}_{t}^{u} &=\sigma\left(\boldsymbol{W}_{i n}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{i n}^{2} \boldsymbol{h}_{t-1}^{u}+b_{i n}\right) \\
|
||||
f_{t}^{u} &=\sigma\left(\boldsymbol{W}_{f}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{f}^{2} \boldsymbol{h}_{t-1}^{u}+b_{f}\right) \\
|
||||
\boldsymbol{o}_{t}^{u} &=\sigma\left(\boldsymbol{W}_{o}^{1} \boldsymbol{e}_{i}^{u}+\boldsymbol{W}_{o}^{2} \boldsymbol{h}_{t-1}^{u}+b_{o}\right) \\
|
||||
\boldsymbol{c}_{t}^{u} &=\boldsymbol{f}_{t} \boldsymbol{c}_{t-1}^{u}+\boldsymbol{i} \boldsymbol{n}_{t}^{u} \tanh \left(\boldsymbol{W}_{c}^{1} \boldsymbol{e}_{i_{t}^{u}}+\boldsymbol{W}_{c}^{2} \boldsymbol{h}_{t-1}^{u}+b_{c}\right) \\
|
||||
\boldsymbol{h}_{t}^{u} &=\boldsymbol{o}_{t}^{u} \tanh \left(\boldsymbol{c}_{t}^{u}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里采用的是多输入多输出, 即每个时间步都会有一个隐藏状态$h_t^u$输出出来,那么经过LSTM之后,原始的序列就有了序列相关信息,得到了$\left[\boldsymbol{h}_{1}^{u}, \ldots, \boldsymbol{h}_{t}^{u}\right]$, 把这个记为$\boldsymbol{X}^{u}$。这里的$\boldsymbol{h}_{t}^{u} \in \mathbb{R}^{d \times 1}$表示时间$t$的序列偏好表示。
|
||||
|
||||
接下来, 这个东西要过Multi-head self-attention层,这个东西的原理我这里就不多讲了,这个东西可以学习到$h_i^u$系列之间的相关性,这个操作从某种角度看,也很像聚类, 因为我们这里是先用多头矩阵把$h_i^u$系列映射到多个空间,然后从各个空间中互求相关性
|
||||
$$
|
||||
\text { head }{ }_{i}^{u}=\operatorname{Attention}\left(\boldsymbol{W}_{i}^{Q} \boldsymbol{X}^{u}, \boldsymbol{W}_{i}^{K} \boldsymbol{X}^{u}, \boldsymbol{W}_{i}^{V} \boldsymbol{X}^{u}\right)
|
||||
$$
|
||||
得到权重后,对原始的向量加权融合。 让$Q_{i}^{u}=W_{i}^{Q} X^{u}$, $K_{i}^{u}=W_{i}^{K} \boldsymbol{X}^{u}$,$V_{i}^{u}=W_{i}^{V} X^{u}$, 背后计算是:
|
||||
$$
|
||||
\begin{aligned}
|
||||
&f\left(Q_{i}^{u}, K_{i}^{u}\right)=Q_{i}^{u T} K_{i}^{u} \\
|
||||
&A_{i}^{u}=\operatorname{softmax}\left(f\left(Q_{i}^{u}, K_{i}^{u}\right)\right)
|
||||
\end{aligned} \\ \operatorname{head}_{i}^{u}=V_{i}^{u} A_{i}^{u T}
|
||||
$$
|
||||
|
||||
这里如果有多头注意力基础的话非常好理解啊,不多解释,可以看我[这篇文章](https://blog.csdn.net/wuzhongqiang/article/details/104414239?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164872966516781683952272%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164872966516781683952272&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-104414239.nonecase&utm_term=Attention+is+all&spm=1018.2226.3001.4450)补一下。
|
||||
|
||||
这是一个头的计算, 接下来每个头都这么算,假设有$h$个头,这里会通过上面的映射矩阵$W$系列,先把原始的$h_i^u$向量映射到$d_{k}=\frac{1}{h} d$维度,然后计算$head_i^u$也是$d_k$维,这样$h$个head进行拼接,正好是$d$维, 接下来过一个全连接或者线性映射得到MultiHead的输出。
|
||||
$$
|
||||
\hat{X}^{u}=\text { MultiHead }\left(X^{u}\right)=W^{O} \text { concat }\left(\text { head }_{1}^{u}, \ldots, \text { head }_{h}^{u}\right)
|
||||
$$
|
||||
|
||||
这样就相当于更相似的$h_i^u$融合到了一块,而这个更相似又是从多个角度得到的,于是乎, 作者认为,这样就能学习到用户的多兴趣。
|
||||
|
||||
得到这个东西之后,接下来再过一个User Attention, 因为作者发现,对于相似历史行为的不同用户,其兴趣偏好也不太一样。
|
||||
所以加入这个用户Attention层,想挖掘更细粒度的用户个性化信息。 当然,这个就是普通的embedding层了, 用户的base向量$e_u$作为query,与$\hat{X}^{u}$的每个向量做Attention,然后加权求和得最终向量:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\alpha_{k} &=\frac{\exp \left(\hat{\boldsymbol{h}}_{k}^{u T} \boldsymbol{e}_{u}\right)}{\sum_{k=1}^{t} \exp \left(\hat{\boldsymbol{h}}_{k}^{u T} \boldsymbol{e}_{u}\right)} \\
|
||||
\boldsymbol{s}_{t}^{u} &=\sum_{k=1}^{t} \alpha_{k} \hat{\boldsymbol{h}}_{k}^{u}
|
||||
\end{aligned}
|
||||
$$
|
||||
其中$s_{t}^{u} \in \mathbb{R}^{d \times 1}$,这样短期行为兴趣就修成了正果。
|
||||
|
||||
### 3.4 用户长期行为建模
|
||||
从长期的视角来看,用户在不同的维度上可能积累了广泛的兴趣,用户可能经常访问一组类似的商店,并反复购买属于同一类别的商品。 所以长期行为$\mathcal{L}^{u}$来自于不同的特征尺度。
|
||||
$$
|
||||
\mathcal{L}^{u}=\left\{\mathcal{L}_{f}^{u} \mid f \in \mathcal{F}\right\}
|
||||
$$
|
||||
这里面包含了各种side特征。这里就和短期行为那里不太一样了,长期行为这里,是从特征的维度进行聚合,也就是把用户的历史长序列分成了多个特征,比如用户历史点击过的商品,历史逛过的店铺,历史看过的商品的类别,品牌等,分成了多个特征子集,然后这每个特征子集里面有对应的id,比如商品有商品id, 店铺有店铺id等,对于每个子集,过user Attention layer,和用户的base向量求Attention, 相当于看看用户喜欢逛啥样的商店, 喜欢啥样的品牌,啥样的商品类别等等,得到每个子集最终的表示向量。每个子集的计算过程如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\alpha_{k} &=\frac{\exp \left(\boldsymbol{g}_{k}^{u T} \boldsymbol{e}_{u}\right)}{\sum_{k=1}^{\left|\mathcal{L}_{f}^{u}\right|} \exp \left(\boldsymbol{g}_{k}^{u T} \boldsymbol{e}_{u}\right)} \\
|
||||
z_{f}^{u} &=\sum_{k=1}^{\left|\mathcal{L}_{f}^{u}\right|} \alpha_{k} \boldsymbol{g}_{k}^{u}
|
||||
\end{aligned}
|
||||
$$
|
||||
每个子集都会得到一个加权的向量,把这个东西拼起来,然后过DNN。
|
||||
$$
|
||||
\begin{aligned}
|
||||
&z^{u}=\operatorname{concat}\left(\left\{z_{f}^{u} \mid f \in \mathcal{F}\right\}\right) \\
|
||||
&\boldsymbol{p}^{u}=\tanh \left(\boldsymbol{W}^{p} z^{u}+b\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的$\boldsymbol{p}^{u} \in \mathbb{R}^{d \times 1}$, 这样就得到了用户的长期兴趣表示。
|
||||
### 3.5 短长期兴趣融合
|
||||
长短期兴趣融合这里,作者发现之前模型往往喜欢直接拼接起来,或者加和,注意力加权等,但作者认为这样不能很好的将两类兴趣融合起来,因为长期序列里面,其实只有很少的一部分行为和当前有关。那么这样的话,直接无脑融合是有问题的。所以这里作者用了一种较为巧妙的方式,即门控机制:
|
||||
$$
|
||||
G_{t}^{u}=\operatorname{sigmoid}\left(\boldsymbol{W}^{1} \boldsymbol{e}_{u}+\boldsymbol{W}^{2} s_{t}^{u}+\boldsymbol{W}^{3} \boldsymbol{p}^{u}+b\right) \\
|
||||
o_{t}^{u}=\left(1-G_{t}^{u}\right) \odot p^{u}+G_{t}^{u} \odot s_{t}^{u}
|
||||
$$
|
||||
这个和LSTM的这种门控机制很像,首先门控接收的输入有用户画像$e_u$,用户短期兴趣$s_t^u$, 用户长期兴趣$p^u$,经过sigmoid函数得到了$G_{t}^{u} \in \mathbb{R}^{d \times 1}$,用来决定在$t$时刻短期和长期兴趣的贡献程度。然后根据这个贡献程度对短期和长期偏好加权进行融合。
|
||||
|
||||
为啥这东西就有用了呢? 实验中证明了这个东西有用,但这里给出我的理解哈,我们知道最终得到的短期或者长期兴趣都是$d$维的向量, 每一个维度可能代表着不同的兴趣偏好,比如第一维度代表品牌,第二个维度代表类别,第三个维度代表价格,第四个维度代表商店等等,当然假设哈,真实的向量不可解释。
|
||||
|
||||
那么如果我们是直接相加或者是加权相加,其实都意味着长短期兴趣这每个维度都有很高的保留, 但其实上,万一长期兴趣和短期兴趣维度冲突了呢? 比如短期兴趣里面可能用户喜欢这个品牌,长期用户里面用户喜欢那个品牌,那么听谁的? 你可能说短期兴趣这个占更大权重呗,那么普通加权可是所有向量都加的相同的权重,品牌这个维度听短期兴趣的,其他维度比如价格,商店也都听短期兴趣的?本身存在不合理性。那么反而直接相加或者加权效果会不好。
|
||||
|
||||
而门控机制的巧妙就在于,我会给每个维度都学习到一个权重,而这个权重非0即1(近似哈), 那么接下来融合的时候,我通过这个门控机制,取长期和短期兴趣向量每个维度上的其中一个。比如在品牌方面听谁的,类别方面听谁的,价格方面听谁的,只会听短期和长期兴趣的其中一个的。这样就不会有冲突发生,而至于具体听谁的,交给网络自己学习。这样就使得用户长期兴趣和短期兴趣融合的时候,每个维度上的信息保留变得**有选择**。使得兴趣的融合方式更加的灵活。
|
||||
|
||||
==这其实又给我们提供了一种两个向量融合的一种新思路,并不一定非得加权或者拼接或者相加了,还可以通过门控机制让网络自己学==
|
||||
|
||||
|
||||
## 4. SDM模型的简易复现
|
||||
下面参考DeepMatch,用简易的代码实现下SDM,并在新闻推荐的数据集上进行召回任务。
|
||||
|
||||
首先,下面分析SDM的整体架构,从代码层面看运行流程, 然后就这里面几个关键的细节进行说明。
|
||||
|
||||
### 4.1 模型的输入
|
||||
对于SDM模型,由于它是将用户的行为序列分成了会话的形式,所以在构造SDM模型输入方面和前面的MIND以及YouTubeDNN有很大的不同了,所以这里需要先重点强调下输入。
|
||||
|
||||
在为SDM产生数据集的时候, 需要传入短期会话的长度以及长期会话的长度, 这样, 对于一个行为序列,构造数据集的时候要按照两个长度分成短期行为和长期行为两种,并且每一种都需要指明真实的序列长度。另外,由于这里用到了文章的side info信息,所以我这里在之前列的基础上加入了文章的两个类别特征分别是cat_1和cat_2,作为文章的side info。 这个产生数据集的代码如下:
|
||||
|
||||
```python
|
||||
"""构造sdm数据集"""
|
||||
def get_data_set(click_data, seq_short_len=5, seq_prefer_len=50):
|
||||
"""
|
||||
:param: seq_short_len: 短期会话的长度
|
||||
:param: seq_prefer_len: 会话的最长长度
|
||||
"""
|
||||
click_data.sort_values("expo_time", inplace=True)
|
||||
|
||||
train_set, test_set = [], []
|
||||
for user_id, hist_click in tqdm(click_data.groupby('user_id')):
|
||||
pos_list = hist_click['article_id'].tolist()
|
||||
cat1_list = hist_click['cat_1'].tolist()
|
||||
cat2_list = hist_click['cat_2'].tolist()
|
||||
|
||||
# 滑动窗口切分数据
|
||||
for i in range(1, len(pos_list)):
|
||||
hist = pos_list[:i]
|
||||
cat1_hist = cat1_list[:i]
|
||||
cat2_hist = cat2_list[:i]
|
||||
# 序列长度只够短期的
|
||||
if i <= seq_short_len and i != len(pos_list) - 1:
|
||||
train_set.append((
|
||||
# 用户id, 用户短期历史行为序列, 用户长期历史行为序列, 当前行为文章, label,
|
||||
user_id, hist[::-1], [0]*seq_prefer_len, pos_list[i], 1,
|
||||
# 用户短期历史序列长度, 用户长期历史序列长度,
|
||||
len(hist[::-1]), 0,
|
||||
# 用户短期历史序列对应类别1, 用户长期历史行为序列对应类别1
|
||||
cat1_hist[::-1], [0]*seq_prefer_len,
|
||||
# 历史短期历史序列对应类别2, 用户长期历史行为序列对应类别2
|
||||
cat2_hist[::-1], [0]*seq_prefer_len
|
||||
))
|
||||
# 序列长度够长期的
|
||||
elif i != len(pos_list) - 1:
|
||||
train_set.append((
|
||||
# 用户id, 用户短期历史行为序列,用户长期历史行为序列, 当前行为文章, label
|
||||
user_id, hist[::-1][:seq_short_len], hist[::-1][seq_short_len:], pos_list[i], 1,
|
||||
# 用户短期行为序列长度,用户长期行为序列长度,
|
||||
seq_short_len, len(hist[::-1])-seq_short_len,
|
||||
# 用户短期历史行为序列对应类别1, 用户长期历史行为序列对应类别1
|
||||
cat1_hist[::-1][:seq_short_len], cat1_hist[::-1][seq_short_len:],
|
||||
# 用户短期历史行为序列对应类别2, 用户长期历史行为序列对应类别2
|
||||
cat2_hist[::-1][:seq_short_len], cat2_hist[::-1][seq_short_len:]
|
||||
))
|
||||
# 测试集保留最长的那一条
|
||||
elif i <= seq_short_len and i == len(pos_list) - 1:
|
||||
test_set.append((
|
||||
user_id, hist[::-1], [0]*seq_prefer_len, pos_list[i], 1,
|
||||
len(hist[::-1]), 0,
|
||||
cat1_hist[::-1], [0]*seq_perfer_len,
|
||||
cat2_hist[::-1], [0]*seq_prefer_len
|
||||
))
|
||||
else:
|
||||
test_set.append((
|
||||
user_id, hist[::-1][:seq_short_len], hist[::-1][seq_short_len:], pos_list[i], 1,
|
||||
seq_short_len, len(hist[::-1])-seq_short_len,
|
||||
cat1_hist[::-1][:seq_short_len], cat1_hist[::-1][seq_short_len:],
|
||||
cat2_list[::-1][:seq_short_len], cat2_hist[::-1][seq_short_len:]
|
||||
))
|
||||
|
||||
random.shuffle(train_set)
|
||||
random.shuffle(test_set)
|
||||
|
||||
return train_set, test_set
|
||||
```
|
||||
思路和之前的是一样的,无非就是根据会话的长短,把之前的一个长行为序列划分成了短期和长期两个,然后加入两个新的side info特征。
|
||||
|
||||
### 4.2 模型的代码架构
|
||||
整个SDM模型算是参考deepmatch修改的一个简易版本:
|
||||
|
||||
```python
|
||||
def SDM(user_feature_columns, item_feature_columns, history_feature_list, num_sampled=5, units=32, rnn_layers=2,
|
||||
dropout_rate=0.2, rnn_num_res=1, num_head=4, l2_reg_embedding=1e-6, dnn_activation='tanh', seed=1024):
|
||||
"""
|
||||
:param rnn_num_res: rnn的残差层个数
|
||||
:param history_feature_list: short和long sequence field
|
||||
"""
|
||||
# item_feature目前只支持doc_id, 再加别的就不行了,其实这里可以改造下
|
||||
if (len(item_feature_columns)) > 1:
|
||||
raise ValueError("SDM only support 1 item feature like doc_id")
|
||||
|
||||
# 获取item_feature的一些属性
|
||||
item_feature_column = item_feature_columns[0]
|
||||
item_feature_name = item_feature_column.name
|
||||
item_vocabulary_size = item_feature_column.vocabulary_size
|
||||
|
||||
# 为用户特征创建Input层
|
||||
user_input_layer_dict = build_input_layers(user_feature_columns)
|
||||
item_input_layer_dict = build_input_layers(item_feature_columns)
|
||||
|
||||
# 将Input层转化成列表的形式作为model的输入
|
||||
user_input_layers = list(user_input_layer_dict.values())
|
||||
item_input_layers = list(item_input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse特征和dense特征,方便单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
if len(dense_feature_columns) != 0:
|
||||
raise ValueError("SDM dont support dense feature") # 目前不支持Dense feature
|
||||
varlen_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), user_feature_columns)) if user_feature_columns else []
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(user_feature_columns+item_feature_columns)
|
||||
|
||||
# 拿到短期会话和长期会话列 之前的命名规则在这里起作用
|
||||
sparse_varlen_feature_columns = []
|
||||
prefer_history_columns = []
|
||||
short_history_columns = []
|
||||
|
||||
prefer_fc_names = list(map(lambda x: "prefer_" + x, history_feature_list))
|
||||
short_fc_names = list(map(lambda x: "short_" + x, history_feature_list))
|
||||
|
||||
for fc in varlen_feature_columns:
|
||||
if fc.name in prefer_fc_names:
|
||||
prefer_history_columns.append(fc)
|
||||
elif fc.name in short_fc_names:
|
||||
short_history_columns.append(fc)
|
||||
else:
|
||||
sparse_varlen_feature_columns.append(fc)
|
||||
|
||||
# 获取用户的长期行为序列列表 L^u
|
||||
# [<tf.Tensor 'emb_prefer_doc_id_2/Identity:0' shape=(None, 50, 32) dtype=float32>, <tf.Tensor 'emb_prefer_cat1_2/Identity:0' shape=(None, 50, 32) dtype=float32>, <tf.Tensor 'emb_prefer_cat2_2/Identity:0' shape=(None, 50, 32) dtype=float32>]
|
||||
prefer_emb_list = embedding_lookup(prefer_fc_names, user_input_layer_dict, embedding_layer_dict)
|
||||
# 获取用户的短期序列列表 S^u
|
||||
# [<tf.Tensor 'emb_short_doc_id_2/Identity:0' shape=(None, 5, 32) dtype=float32>, <tf.Tensor 'emb_short_cat1_2/Identity:0' shape=(None, 5, 32) dtype=float32>, <tf.Tensor 'emb_short_cat2_2/Identity:0' shape=(None, 5, 32) dtype=float32>]
|
||||
short_emb_list = embedding_lookup(short_fc_names, user_input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 用户离散特征的输入层与embedding层拼接 e^u
|
||||
user_emb_list = embedding_lookup([col.name for col in sparse_feature_columns], user_input_layer_dict, embedding_layer_dict)
|
||||
user_emb = concat_func(user_emb_list)
|
||||
user_emb_output = Dense(units, activation=dnn_activation, name='user_emb_output')(user_emb) # (None, 1, 32)
|
||||
|
||||
# 长期序列行为编码
|
||||
# 过AttentionSequencePoolingLayer --> Concat --> DNN
|
||||
prefer_sess_length = user_input_layer_dict['prefer_sess_length']
|
||||
prefer_att_outputs = []
|
||||
# 遍历长期行为序列
|
||||
for i, prefer_emb in enumerate(prefer_emb_list):
|
||||
prefer_attention_output = AttentionSequencePoolingLayer(dropout_rate=0)([user_emb_output, prefer_emb, prefer_sess_length])
|
||||
prefer_att_outputs.append(prefer_attention_output)
|
||||
prefer_att_concat = concat_func(prefer_att_outputs) # (None, 1, 64) <== Concat(item_embedding,cat1_embedding,cat2_embedding)
|
||||
prefer_output = Dense(units, activation=dnn_activation, name='prefer_output')(prefer_att_concat)
|
||||
# print(prefer_output.shape) # (None, 1, 32)
|
||||
|
||||
# 短期行为序列编码
|
||||
short_sess_length = user_input_layer_dict['short_sess_length']
|
||||
short_emb_concat = concat_func(short_emb_list) # (None, 5, 64) 这里注意下, 对于短期序列,描述item的side info信息进行了拼接
|
||||
short_emb_input = Dense(units, activation=dnn_activation, name='short_emb_input')(short_emb_concat) # (None, 5, 32)
|
||||
# 过rnn 这里的return_sequence=True, 每个时间步都需要输出h
|
||||
short_rnn_output = DynamicMultiRNN(num_units=units, return_sequence=True, num_layers=rnn_layers,
|
||||
num_residual_layers=rnn_num_res, # 这里竟然能用到残差
|
||||
dropout_rate=dropout_rate)([short_emb_input, short_sess_length])
|
||||
# print(short_rnn_output) # (None, 5, 32)
|
||||
# 过MultiHeadAttention # (None, 5, 32)
|
||||
short_att_output = MultiHeadAttention(num_units=units, head_num=num_head, dropout_rate=dropout_rate)([short_rnn_output, short_sess_length]) # (None, 5, 64)
|
||||
# user_attention # (None, 1, 32)
|
||||
short_output = UserAttention(num_units=units, activation=dnn_activation, use_res=True, dropout_rate=dropout_rate)([user_emb_output, short_att_output, short_sess_length])
|
||||
|
||||
# 门控融合
|
||||
gated_input = concat_func([prefer_output, short_output, user_emb_output])
|
||||
gate = Dense(units, activation='sigmoid')(gated_input) # (None, 1, 32)
|
||||
|
||||
# temp = tf.multiply(gate, short_output) + tf.multiply(1-gate, prefer_output) 感觉这俩一样?
|
||||
gated_output = Lambda(lambda x: tf.multiply(x[0], x[1]) + tf.multiply(1-x[0], x[2]))([gate, short_output, prefer_output]) # [None, 1,32]
|
||||
gated_output_reshape = Lambda(lambda x: tf.squeeze(x, 1))(gated_output) # (None, 32) 这个维度必须要和docembedding层的维度一样,否则后面没法sortmax_loss
|
||||
|
||||
# 接下来
|
||||
item_embedding_matrix = embedding_layer_dict[item_feature_name] # 获取doc_id的embedding层
|
||||
item_index = EmbeddingIndex(list(range(item_vocabulary_size)))(item_input_layer_dict[item_feature_name]) # 所有doc_id的索引
|
||||
item_embedding_weight = NoMask()(item_embedding_matrix(item_index)) # 拿到所有item的embedding
|
||||
pooling_item_embedding_weight = PoolingLayer()([item_embedding_weight]) # 这里依然是当可能不止item_id,或许还有brand_id, cat_id等,需要池化
|
||||
|
||||
# 这里传入的是整个doc_id的embedding, user_embedding, 以及用户点击的doc_id,然后去进行负采样计算损失操作
|
||||
output = SampledSoftmaxLayer(num_sampled)([pooling_item_embedding_weight, gated_output_reshape, item_input_layer_dict[item_feature_name]])
|
||||
|
||||
model = Model(inputs=user_input_layers+item_input_layers, outputs=output)
|
||||
|
||||
# 下面是等模型训练完了之后,获取用户和item的embedding
|
||||
model.__setattr__("user_input", user_input_layers)
|
||||
model.__setattr__("user_embedding", gated_output_reshape) # 用户embedding是取得门控融合的用户向量
|
||||
model.__setattr__("item_input", item_input_layers)
|
||||
# item_embedding取得pooling_item_embedding_weight, 这个会发现是负采样操作训练的那个embedding矩阵
|
||||
model.__setattr__("item_embedding", get_item_embedding(pooling_item_embedding_weight, item_input_layer_dict[item_feature_name]))
|
||||
return model
|
||||
```
|
||||
函数式API搭建模型的方式,首先我们需要传入封装好的用户特征描述以及item特征描述,比如:
|
||||
|
||||
```python
|
||||
# 建立模型
|
||||
user_feature_columns = [
|
||||
SparseFeat('user_id', feature_max_idx['user_id'], 16),
|
||||
SparseFeat('gender', feature_max_idx['gender'], 16),
|
||||
SparseFeat('age', feature_max_idx['age'], 16),
|
||||
SparseFeat('city', feature_max_idx['city'], 16),
|
||||
|
||||
VarLenSparseFeat(SparseFeat('short_doc_id', feature_max_idx['article_id'], embedding_dim, embedding_name="doc_id"), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_doc_id', feature_max_idx['article_id'], embedding_dim, embedding_name='doc_id'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('short_cat1', feature_max_idx['cat_1'], embedding_dim, embedding_name='cat_1'), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_cat1', feature_max_idx['cat_1'], embedding_dim, embedding_name='cat_1'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('short_cat2', feature_max_idx['cat_2'], embedding_dim, embedding_name='cat_2'), SEQ_LEN_short, 'mean', 'short_sess_length'),
|
||||
VarLenSparseFeat(SparseFeat('prefer_cat2', feature_max_idx['cat_2'], embedding_dim, embedding_name='cat_2'), SEQ_LEN_prefer, 'mean', 'prefer_sess_length'),
|
||||
]
|
||||
|
||||
item_feature_columns = [SparseFeat('doc_id', feature_max_idx['article_id'], embedding_dim)]
|
||||
```
|
||||
这里需要注意的一个点是短期和长期序列的名字,必须严格的`short_, prefer_`进行标识,因为在模型搭建的时候就是靠着这个去找到短期和长期序列特征的。
|
||||
|
||||
逻辑其实也比较清晰,首先是建立Input层,然后是embedding层, 接下来,根据命名选择出用户的base特征列, 短期行为序列和长期行为序列。长期序列的话是过`AttentionPoolingLayer`层进行编码,这里本质上注意力然后融合,但这里注意的一个点就是for循环,也就是长期序列行为里面的特征列,比如商品,cat_1, cat_2是for循环的形式求融合向量,再拼接起来过DNN,和论文图保持一致。
|
||||
|
||||
短期序列编码部分,是`item_embedding,cat_1embedding, cat_2embedding`拼接起来,过`DynamicMultiRNN`层学习序列信息, 过`MultiHeadAttention`学习多兴趣,最后过`UserAttentionLayer`进行向量融合。 接下来,长期兴趣向量和短期兴趣向量以及用户base向量,过门控融合机制,得到最终的`user_embedding`。
|
||||
|
||||
而后面的那块是为了模型训练完之后,拿用户embedding和item embedding用的, 这个在MIND那篇文章里作了解释。
|
||||
|
||||
## 5. 小总
|
||||
今天整理的是SDM,这也是一个标准的序列推荐召回模型,主要还是研究用户的序列,不过这篇paper里面一个有意思的点就是把用户的行为训练以会话的形式进行切分,然后再根据时间,分成了短期会话和长期会话,然后分别采用不同的策略去学习用户的短期兴趣和长期兴趣。
|
||||
* 对于短期会话,可能和当前预测相关性较大,所以首先用RNN来学习序列信息,然后采用多头注意力机制得到用户的多兴趣, 隐隐约约感觉多头注意力机制还真有种能聚类的功效,接下来就是和用户的base向量进行注意力融合得到短期兴趣
|
||||
* 长期会话序列中,每个side info信息进行分开,然后分别进行注意力编码融合得到
|
||||
|
||||
为了使得长期会话中对当前预测有用的部分得以体现,在融合短期兴趣和长期兴趣的时候,采用了门控的方式,而不是普通的拼接或者加和等操作,使得兴趣保留信息变得**有选择**。
|
||||
|
||||
这其实就是这篇paper的故事了,借鉴的地方首先是多头注意力机制也能学习到用户的多兴趣, 这样对于多兴趣,就有了胶囊网络与多头注意力机制两种思路。 而对于两个向量融合,这里又给我们提供了一种门控融合机制。
|
||||
|
||||
|
||||
**参考**:
|
||||
|
||||
* SDM原论文
|
||||
* [AI上推荐 之 SDM模型(建模用户长短期兴趣的Match模型)](https://blog.csdn.net/wuzhongqiang/article/details/123856954?spm=1001.2014.3001.5501)
|
||||
* [一文读懂Attention机制](https://zhuanlan.zhihu.com/p/129316415)
|
||||
* [【推荐系统经典论文(十)】阿里SDM模型](https://zhuanlan.zhihu.com/p/137775247?from_voters_page=true)
|
||||
* [SDM-深度序列召回模型](https://zhuanlan.zhihu.com/p/395673080)
|
||||
* [推荐广告中的序列建模](https://blog.csdn.net/qq_41010971/article/details/123762312?spm=1001.2014.3001.5501)
|
||||
1
docs/推荐算法基础/经典召回模型/基于序列的召回/readme.md
Normal file
1
docs/推荐算法基础/经典召回模型/基于序列的召回/readme.md
Normal file
@@ -0,0 +1 @@
|
||||
# README
|
||||
1
docs/推荐算法基础/经典召回模型/基于树模型的召回/readme.md
Normal file
1
docs/推荐算法基础/经典召回模型/基于树模型的召回/readme.md
Normal file
@@ -0,0 +1 @@
|
||||
# README
|
||||
352
docs/推荐算法基础/经典排序模型/GBDT+LR.md
Normal file
352
docs/推荐算法基础/经典排序模型/GBDT+LR.md
Normal file
@@ -0,0 +1,352 @@
|
||||
### GBDT+LR简介
|
||||
|
||||
前面介绍的协同过滤和矩阵分解存在的劣势就是仅利用了用户与物品相互行为信息进行推荐, 忽视了用户自身特征, 物品自身特征以及上下文信息等,导致生成的结果往往会比较片面。 而这次介绍的这个模型是2014年由Facebook提出的GBDT+LR模型, 该模型利用GBDT自动进行特征筛选和组合, 进而生成新的离散特征向量, 再把该特征向量当做LR模型的输入, 来产生最后的预测结果, 该模型能够综合利用用户、物品和上下文等多种不同的特征, 生成较为全面的推荐结果, 在CTR点击率预估场景下使用较为广泛。
|
||||
|
||||
下面首先会介绍逻辑回归和GBDT模型各自的原理及优缺点, 然后介绍GBDT+LR模型的工作原理和细节。
|
||||
|
||||
### 逻辑回归模型
|
||||
|
||||
逻辑回归模型非常重要, 在推荐领域里面, 相比于传统的协同过滤, 逻辑回归模型能够综合利用用户、物品、上下文等多种不同的特征生成较为“全面”的推荐结果, 关于逻辑回归的更多细节, 可以参考下面给出的链接,这里只介绍比较重要的一些细节和在推荐中的应用。
|
||||
|
||||
逻辑回归是在线性回归的基础上加了一个 Sigmoid 函数(非线形)映射,使得逻辑回归成为了一个优秀的分类算法, 学习逻辑回归模型, 首先应该记住一句话:**逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的。**
|
||||
|
||||
相比于协同过滤和矩阵分解利用用户的物品“相似度”进行推荐, 逻辑回归模型将问题看成了一个分类问题, 通过预测正样本的概率对物品进行排序。这里的正样本可以是用户“点击”了某个商品或者“观看”了某个视频, 均是推荐系统希望用户产生的“正反馈”行为, 因此**逻辑回归模型将推荐问题转化成了一个点击率预估问题**。而点击率预测就是一个典型的二分类, 正好适合逻辑回归进行处理, 那么逻辑回归是如何做推荐的呢? 过程如下:
|
||||
1. 将用户年龄、性别、物品属性、物品描述、当前时间、当前地点等特征转成数值型向量
|
||||
2. 确定逻辑回归的优化目标,比如把点击率预测转换成二分类问题, 这样就可以得到分类问题常用的损失作为目标, 训练模型
|
||||
3. 在预测的时候, 将特征向量输入模型产生预测, 得到用户“点击”物品的概率
|
||||
4. 利用点击概率对候选物品排序, 得到推荐列表
|
||||
|
||||
推断过程可以用下图来表示:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200909215410263.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:55%;" />
|
||||
</div>
|
||||
|
||||
这里的关键就是每个特征的权重参数$w$, 我们一般是使用梯度下降的方式, 首先会先随机初始化参数$w$, 然后将特征向量(也就是我们上面数值化出来的特征)输入到模型, 就会通过计算得到模型的预测概率, 然后通过对目标函数求导得到每个$w$的梯度, 然后进行更新$w$
|
||||
|
||||
这里的目标函数长下面这样:
|
||||
|
||||
$$
|
||||
J(w)=-\frac{1}{m}\left(\sum_{i=1}^{m}\left(y^{i} \log f_{w}\left(x^{i}\right)+\left(1-y^{i}\right) \log \left(1-f_{w}\left(x^{i}\right)\right)\right)\right.
|
||||
$$
|
||||
求导之后的方式长这样:
|
||||
$$
|
||||
w_{j} \leftarrow w_{j}-\gamma \frac{1}{m} \sum_{i=1}^{m}\left(f_{w}\left(x^{i}\right)-y^{i}\right) x_{j}^{i}
|
||||
$$
|
||||
这样通过若干次迭代, 就可以得到最终的$w$了, 关于这些公式的推导,可以参考下面给出的文章链接, 下面我们分析一下逻辑回归模型的优缺点。
|
||||
|
||||
**优点:**
|
||||
1. LR模型形式简单,可解释性好,从特征的权重可以看到不同的特征对最后结果的影响。
|
||||
2. 训练时便于并行化,在预测时只需要对特征进行线性加权,所以**性能比较好**,往往适合处理**海量id类特征**,用id类特征有一个很重要的好处,就是**防止信息损失**(相对于范化的 CTR 特征),对于头部资源会有更细致的描述
|
||||
3. 资源占用小,尤其是内存。在实际的工程应用中只需要存储权重比较大的特征及特征对应的权重。
|
||||
4. 方便输出结果调整。逻辑回归可以很方便的得到最后的分类结果,因为输出的是每个样本的概率分数,我们可以很容易的对这些概率分数进行cutoff,也就是划分阈值(大于某个阈值的是一类,小于某个阈值的是一类)
|
||||
|
||||
**当然, 逻辑回归模型也有一定的局限性**
|
||||
1. 表达能力不强, 无法进行特征交叉, 特征筛选等一系列“高级“操作(这些工作都得人工来干, 这样就需要一定的经验, 否则会走一些弯路), 因此可能造成信息的损失
|
||||
2. 准确率并不是很高。因为这毕竟是一个线性模型加了个sigmoid, 形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布
|
||||
3. 处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据, 如果想处理非线性, 首先对连续特征的处理需要先进行**离散化**(离散化的目的是为了引入非线性),如上文所说,人工分桶的方式会引入多种问题。
|
||||
4. LR 需要进行**人工特征组合**,这就需要开发者有非常丰富的领域经验,才能不走弯路。这样的模型迁移起来比较困难,换一个领域又需要重新进行大量的特征工程。
|
||||
|
||||
所以如何**自动发现有效的特征、特征组合,弥补人工经验不足,缩短LR特征实验周期**,是亟需解决的问题, 而GBDT模型, 正好可以**自动发现特征并进行有效组合**
|
||||
|
||||
### GBDT模型
|
||||
|
||||
GBDT全称梯度提升决策树,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩。原因大概有几个,一是效果确实挺不错。二是即可以用于分类也可以用于回归。三是可以筛选特征, 所以这个模型依然是一个非常重要的模型。
|
||||
|
||||
GBDT是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的误差来达到将数据分类或者回归的算法, 其训练过程如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200908202508786.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" style="zoom:65%;" />
|
||||
</div>
|
||||
gbdt通过多轮迭代, 每轮迭代会产生一个弱分类器, 每个分类器在上一轮分类器的残差基础上进行训练。 gbdt对弱分类器的要求一般是足够简单, 并且低方差高偏差。 因为训练的过程是通过降低偏差来不断提高最终分类器的精度。 由于上述高偏差和简单的要求,每个分类回归树的深度不会很深。最终的总分类器是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。
|
||||
|
||||
关于GBDT的详细细节,依然是可以参考下面给出的链接。这里想分析一下GBDT如何来进行二分类的,因为我们要明确一点就是**gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的**, 而这里的残差指的就是当前模型的负梯度值, 这个就要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的, 而**gbdt 无论用于分类还是回归一直都是使用的CART 回归树**, 那么既然是回归树, 是如何进行二分类问题的呢?
|
||||
|
||||
GBDT 来解决二分类问题和解决回归问题的本质是一样的,都是通过不断构建决策树的方式,使预测结果一步步的接近目标值, 但是二分类问题和回归问题的损失函数是不同的, 关于GBDT在回归问题上的树的生成过程, 损失函数和迭代原理可以参考给出的链接, 回归问题中一般使用的是平方损失, 而二分类问题中, GBDT和逻辑回归一样, 使用的下面这个:
|
||||
|
||||
$$
|
||||
L=\arg \min \left[\sum_{i}^{n}-\left(y_{i} \log \left(p_{i}\right)+\left(1-y_{i}\right) \log \left(1-p_{i}\right)\right)\right]
|
||||
$$
|
||||
其中, $y_i$是第$i$个样本的观测值, 取值要么是0要么是1, 而$p_i$是第$i$个样本的预测值, 取值是0-1之间的概率,由于我们知道GBDT拟合的残差是当前模型的负梯度, 那么我们就需要求出这个模型的导数, 即$\frac{dL}{dp_i}$, 对于某个特定的样本, 求导的话就可以只考虑它本身, 去掉加和号, 那么就变成了$\frac{dl}{dp_i}$, 其中$l$如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
l &=-y_{i} \log \left(p_{i}\right)-\left(1-y_{i}\right) \log \left(1-p_{i}\right) \\
|
||||
&=-y_{i} \log \left(p_{i}\right)-\log \left(1-p_{i}\right)+y_{i} \log \left(1-p_{i}\right) \\
|
||||
&=-y_{i}\left(\log \left(\frac{p_{i}}{1-p_{i}}\right)\right)-\log \left(1-p_{i}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
如果对逻辑回归非常熟悉的话, $\left(\log \left(\frac{p_{i}}{1-p_{i}}\right)\right)$一定不会陌生吧, 这就是对几率比取了个对数, 并且在逻辑回归里面这个式子会等于$\theta X$, 所以才推出了$p_i=\frac{1}{1+e^-{\theta X}}$的那个形式。 这里令$\eta_i=\frac{p_i}{1-p_i}$, 即$p_i=\frac{\eta_i}{1+\eta_i}$, 则上面这个式子变成了:
|
||||
|
||||
$$
|
||||
\begin{aligned}
|
||||
l &=-y_{i} \log \left(\eta_{i}\right)-\log \left(1-\frac{e^{\log \left(\eta_{i}\right)}}{1+e^{\log \left(\eta_{i}\right)}}\right) \\
|
||||
&=-y_{i} \log \left(\eta_{i}\right)-\log \left(\frac{1}{1+e^{\log \left(\eta_{i}\right)}}\right) \\
|
||||
&=-y_{i} \log \left(\eta_{i}\right)+\log \left(1+e^{\log \left(\eta_{i}\right)}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这时候,我们对$log(\eta_i)$求导, 得
|
||||
$$
|
||||
\frac{d l}{d \log (\eta_i)}=-y_{i}+\frac{e^{\log \left(\eta_{i}\right)}}{1+e^{\log \left(\eta_{i}\right)}}=-y_i+p_i
|
||||
$$
|
||||
这样, 我们就得到了某个训练样本在当前模型的梯度值了, 那么残差就是$y_i-p_i$。GBDT二分类的这个思想,其实和逻辑回归的思想一样,**逻辑回归是用一个线性模型去拟合$P(y=1|x)$这个事件的对数几率$log\frac{p}{1-p}=\theta^Tx$**, GBDT二分类也是如此, 用一系列的梯度提升树去拟合这个对数几率, 其分类模型可以表达为:
|
||||
$$
|
||||
P(Y=1 \mid x)=\frac{1}{1+e^{-F_{M}(x)}}
|
||||
$$
|
||||
|
||||
下面我们具体来看GBDT的生成过程, 构建分类GBDT的步骤有两个:
|
||||
1. 初始化GBDT
|
||||
和回归问题一样, 分类 GBDT 的初始状态也只有一个叶子节点,该节点为所有样本的初始预测值,如下:
|
||||
$$
|
||||
F_{0}(x)=\arg \min _{\gamma} \sum_{i=1}^{n} L(y, \gamma)
|
||||
$$
|
||||
上式里面, $F$代表GBDT模型, $F_0$是模型的初识状态, 该式子的意思是找到一个$\gamma$,使所有样本的 Loss 最小,在这里及下文中,$\gamma$都表示节点的输出,即叶子节点, 且它是一个 $log(\eta_i)$ 形式的值(回归值),在初始状态,$\gamma =F_0$。
|
||||
|
||||
下面看例子(该例子来自下面的第二个链接), 假设我们有下面3条样本:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910095539432.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
我们希望构建 GBDT 分类树,它能通过「喜欢爆米花」、「年龄」和「颜色偏好」这 3 个特征来预测某一个样本是否喜欢看电影。我们把数据代入上面的公式中求Loss:
|
||||
$$
|
||||
\operatorname{Loss}=L(1, \gamma)+L(1, \gamma)+L(0, \gamma)
|
||||
$$
|
||||
为了令其最小, 我们求导, 且让导数为0, 则:
|
||||
$$
|
||||
\operatorname{Loss}=p-1 + p-1+p=0
|
||||
$$
|
||||
于是, 就得到了初始值$p=\frac{2}{3}=0.67, \gamma=log(\frac{p}{1-p})=0.69$, 模型的初识状态$F_0(x)=0.69$
|
||||
|
||||
2. 循环生成决策树
|
||||
这里回忆一下回归树的生成步骤, 其实有4小步, 第一就是计算负梯度值得到残差, 第二步是用回归树拟合残差, 第三步是计算叶子节点的输出值, 第四步是更新模型。 下面我们一一来看:
|
||||
|
||||
1. 计算负梯度得到残差
|
||||
$$
|
||||
r_{i m}=-\left[\frac{\partial L\left(y_{i}, F\left(x_{i}\right)\right)}{\partial F\left(x_{i}\right)}\right]_{F(x)=F_{m-1}(x)}
|
||||
$$
|
||||
此处使用$m-1$棵树的模型, 计算每个样本的残差$r_{im}$, 就是上面的$y_i-pi$, 于是例子中, 每个样本的残差:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910101154282.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
2. 使用回归树来拟合$r_{im}$, 这里的$i$表示样本哈,回归树的建立过程可以参考下面的链接文章,简单的说就是遍历每个特征, 每个特征下遍历每个取值, 计算分裂后两组数据的平方损失, 找到最小的那个划分节点。 假如我们产生的第2棵决策树如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910101558282.png#pic_center" alt="在这里插入图片描述" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
3. 对于每个叶子节点$j$, 计算最佳残差拟合值
|
||||
$$
|
||||
\gamma_{j m}=\arg \min _{\gamma} \sum_{x \in R_{i j}} L\left(y_{i}, F_{m-1}\left(x_{i}\right)+\gamma\right)
|
||||
$$
|
||||
意思是, 在刚构建的树$m$中, 找到每个节点$j$的输出$\gamma_{jm}$, 能使得该节点的loss最小。 那么我们看一下这个$\gamma$的求解方式, 这里非常的巧妙。 首先, 我们把损失函数写出来, 对于左边的第一个样本, 有
|
||||
$$
|
||||
L\left(y_{1}, F_{m-1}\left(x_{1}\right)+\gamma\right)=-y_{1}\left(F_{m-1}\left(x_{1}\right)+\gamma\right)+\log \left(1+e^{F_{m-1}\left(x_{1}\right)+\gamma}\right)
|
||||
$$
|
||||
这个式子就是上面推导的$l$, 因为我们要用回归树做分类, 所以这里把分类的预测概率转换成了对数几率回归的形式, 即$log(\eta_i)$, 这个就是模型的回归输出值。而如果求这个损失的最小值, 我们要求导, 解出令损失最小的$\gamma$。 但是上面这个式子求导会很麻烦, 所以这里介绍了一个技巧就是**使用二阶泰勒公式来近似表示该式, 再求导**, 还记得伟大的泰勒吗?
|
||||
$$
|
||||
f(x+\Delta x) \approx f(x)+\Delta x f^{\prime}(x)+\frac{1}{2} \Delta x^{2} f^{\prime \prime}(x)+O(\Delta x)
|
||||
$$
|
||||
这里就相当于把$L(y_1, F_{m-1}(x_1))$当做常量$f(x)$, $\gamma$作为变量$\Delta x$, 将$f(x)$二阶展开:
|
||||
$$
|
||||
L\left(y_{1}, F_{m-1}\left(x_{1}\right)+\gamma\right) \approx L\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)+L^{\prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right) \gamma+\frac{1}{2} L^{\prime \prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right) \gamma^{2}
|
||||
$$
|
||||
这时候再求导就简单了
|
||||
$$
|
||||
\frac{d L}{d \gamma}=L^{\prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)+L^{\prime \prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right) \gamma
|
||||
$$
|
||||
Loss最小的时候, 上面的式子等于0, 就可以得到$\gamma$:
|
||||
$$
|
||||
\gamma_{11}=\frac{-L^{\prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)}{L^{\prime \prime}\left(y_{1}, F_{m-1}\left(x_{1}\right)\right)}
|
||||
$$
|
||||
**因为分子就是残差(上述已经求到了), 分母可以通过对残差求导,得到原损失函数的二阶导:**
|
||||
$$
|
||||
\begin{aligned}
|
||||
L^{\prime \prime}\left(y_{1}, F(x)\right) &=\frac{d L^{\prime}}{d \log (\eta_1)} \\
|
||||
&=\frac{d}{d \log (\eta_1)}\left[-y_{i}+\frac{e^{\log (\eta_1)}}{1+e^{\log (\eta_1)}}\right] \\
|
||||
&=\frac{d}{d \log (\eta_1)}\left[e^{\log (\eta_1)}\left(1+e^{\log (\eta_1)}\right)^{-1}\right] \\
|
||||
&=e^{\log (\eta_1)}\left(1+e^{\log (\eta_1)}\right)^{-1}-e^{2 \log (\eta_1)}\left(1+e^{\log (\eta_1)}\right)^{-2} \\
|
||||
&=\frac{e^{\log (\eta_1)}}{\left(1+e^{\log (\eta_1)}\right)^{2}} \\
|
||||
&=\frac{\eta_1}{(1+\eta_1)}\frac{1}{(1+\eta_1)} \\
|
||||
&=p_1(1-p_1)
|
||||
\end{aligned}
|
||||
$$
|
||||
这时候, 就可以算出该节点的输出:
|
||||
$$
|
||||
\gamma_{11}=\frac{r_{11}}{p_{10}\left(1-p_{10}\right)}=\frac{0.33}{0.67 \times 0.33}=1.49
|
||||
$$
|
||||
这里的下面$\gamma_{jm}$表示第$m$棵树的第$j$个叶子节点。 接下来是右边节点的输出, 包含样本2和样本3, 同样使用二阶泰勒公式展开:
|
||||
$$
|
||||
\begin{array}{l}
|
||||
L\left(y_{2}, F_{m-1}\left(x_{2}\right)+\gamma\right)+L\left(y_{3}, F_{m-1}\left(x_{3}\right)+\gamma\right) \\
|
||||
\approx L\left(y_{2}, F_{m-1}\left(x_{2}\right)\right)+L^{\prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right) \gamma+\frac{1}{2} L^{\prime \prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right) \gamma^{2} \\
|
||||
+L\left(y_{3}, F_{m-1}\left(x_{3}\right)\right)+L^{\prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right) \gamma+\frac{1}{2} L^{\prime \prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right) \gamma^{2}
|
||||
\end{array}
|
||||
$$
|
||||
求导, 令其结果为0,就会得到, 第1棵树的第2个叶子节点的输出:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\gamma_{21} &=\frac{-L^{\prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right)-L^{\prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right)}{L^{\prime \prime}\left(y_{2}, F_{m-1}\left(x_{2}\right)\right)+L^{\prime \prime}\left(y_{3}, F_{m-1}\left(x_{3}\right)\right)} \\
|
||||
&=\frac{r_{21}+r_{31}}{p_{20}\left(1-p_{20}\right)+p_{30}\left(1-p_{30}\right)} \\
|
||||
&=\frac{0.33-0.67}{0.67 \times 0.33+0.67 \times 0.33} \\
|
||||
&=-0.77
|
||||
\end{aligned}
|
||||
$$
|
||||
可以看出, 对于任意叶子节点, 我们可以直接计算其输出值:
|
||||
$$
|
||||
\gamma_{j m}=\frac{\sum_{i=1}^{R_{i j}} r_{i m}}{\sum_{i=1}^{R_{i j}} p_{i, m-1}\left(1-p_{i, m-1}\right)}
|
||||
$$
|
||||
|
||||
4. 更新模型$F_m(x)$
|
||||
$$
|
||||
F_{m}(x)=F_{m-1}(x)+\nu \sum_{j=1}^{J_{m}} \gamma_{m}
|
||||
$$
|
||||
|
||||
这样, 通过多次循环迭代, 就可以得到一个比较强的学习器$F_m(x)$
|
||||
|
||||
<br>
|
||||
|
||||
**下面分析一下GBDT的优缺点:**
|
||||
|
||||
我们可以把树的生成过程理解成**自动进行多维度的特征组合**的过程,从根结点到叶子节点上的整个路径(多个特征值判断),才能最终决定一棵树的预测值, 另外,对于**连续型特征**的处理,GBDT 可以拆分出一个临界阈值,比如大于 0.027 走左子树,小于等于 0.027(或者 default 值)走右子树,这样很好的规避了人工离散化的问题。这样就非常轻松的解决了逻辑回归那里**自动发现特征并进行有效组合**的问题, 这也是GBDT的优势所在。
|
||||
|
||||
但是GBDT也会有一些局限性, 对于**海量的 id 类特征**,GBDT 由于树的深度和棵树限制(防止过拟合),不能有效的存储;另外海量特征在也会存在性能瓶颈,当 GBDT 的 one hot 特征大于 10 万维时,就必须做分布式的训练才能保证不爆内存。所以 GBDT 通常配合少量的反馈 CTR 特征来表达,这样虽然具有一定的范化能力,但是同时会有**信息损失**,对于头部资源不能有效的表达。
|
||||
|
||||
所以, 我们发现其实**GBDT和LR的优缺点可以进行互补**。
|
||||
|
||||
### GBDT+LR模型
|
||||
2014年, Facebook提出了一种利用GBDT自动进行特征筛选和组合, 进而生成新的离散特征向量, 再把该特征向量当做LR模型的输入, 来产生最后的预测结果, 这就是著名的GBDT+LR模型了。GBDT+LR 使用最广泛的场景是CTR点击率预估,即预测当给用户推送的广告会不会被用户点击。
|
||||
|
||||
有了上面的铺垫, 这个模型解释起来就比较容易了, 模型的总体结构长下面这样:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20200910161923481.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" alt="在这里插入图片描述" style="zoom:67%;" />
|
||||
</div>
|
||||
**训练时**,GBDT 建树的过程相当于自动进行的特征组合和离散化,然后从根结点到叶子节点的这条路径就可以看成是不同特征进行的特征组合,用叶子节点可以唯一的表示这条路径,并作为一个离散特征传入 LR 进行**二次训练**。
|
||||
|
||||
比如上图中, 有两棵树,x为一条输入样本,遍历两棵树后,x样本分别落到两颗树的叶子节点上,每个叶子节点对应LR一维特征,那么通过遍历树,就得到了该样本对应的所有LR特征。构造的新特征向量是取值0/1的。 比如左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第二个节点,编码[0,1,0],落在右树第二个节点则编码[0,1],所以整体的编码为[0,1,0,0,1],这类编码作为特征,输入到线性分类模型(LR or FM)中进行分类。
|
||||
|
||||
**预测时**,会先走 GBDT 的每棵树,得到某个叶子节点对应的一个离散特征(即一组特征组合),然后把该特征以 one-hot 形式传入 LR 进行线性加权预测。
|
||||
|
||||
这个方案应该比较简单了, 下面有几个关键的点我们需要了解:
|
||||
1. **通过GBDT进行特征组合之后得到的离散向量是和训练数据的原特征一块作为逻辑回归的输入, 而不仅仅全是这种离散特征**
|
||||
2. 建树的时候用ensemble建树的原因就是一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些。GBDT每棵树都在学习前面棵树尚存的不足,迭代多少次就会生成多少棵树。
|
||||
3. RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
|
||||
4. 在CRT预估中, GBDT一般会建立两类树(非ID特征建一类, ID类特征建一类), AD,ID类特征在CTR预估中是非常重要的特征,直接将AD,ID作为feature进行建树不可行,故考虑为每个AD,ID建GBDT树。
|
||||
1. 非ID类树:不以细粒度的ID建树,此类树作为base,即便曝光少的广告、广告主,仍可以通过此类树得到有区分性的特征、特征组合
|
||||
2. ID类树:以细粒度 的ID建一类树,用于发现曝光充分的ID对应有区分性的特征、特征组合
|
||||
|
||||
### 编程实践
|
||||
|
||||
下面我们通过kaggle上的一个ctr预测的比赛来看一下GBDT+LR模型部分的编程实践, [数据来源](https://github.com/zhongqiangwu960812/AI-RecommenderSystem/tree/master/GBDT%2BLR/data)
|
||||
|
||||
我们回顾一下上面的模型架构, 首先是要训练GBDT模型, GBDT的实现一般可以使用xgboost, 或者lightgbm。训练完了GBDT模型之后, 我们需要预测出每个样本落在了哪棵树上的哪个节点上, 然后通过one-hot就会得到一些新的离散特征, 这和原来的特征进行合并组成新的数据集, 然后作为逻辑回归的输入,最后通过逻辑回归模型得到结果。
|
||||
|
||||
根据上面的步骤, 我们看看代码如何实现:
|
||||
|
||||
假设我们已经有了处理好的数据x_train, y_train。
|
||||
|
||||
1. **训练GBDT模型**
|
||||
|
||||
GBDT模型的搭建我们可以通过XGBOOST, lightgbm等进行构建。比如:
|
||||
|
||||
```python
|
||||
gbm = lgb.LGBMRegressor(objective='binary',
|
||||
subsample= 0.8,
|
||||
min_child_weight= 0.5,
|
||||
colsample_bytree= 0.7,
|
||||
num_leaves=100,
|
||||
max_depth = 12,
|
||||
learning_rate=0.05,
|
||||
n_estimators=10,
|
||||
)
|
||||
|
||||
gbm.fit(x_train, y_train,
|
||||
eval_set = [(x_train, y_train), (x_val, y_val)],
|
||||
eval_names = ['train', 'val'],
|
||||
eval_metric = 'binary_logloss',
|
||||
# early_stopping_rounds = 100,
|
||||
)
|
||||
```
|
||||
|
||||
2. **特征转换并构建新的数据集**
|
||||
|
||||
通过上面我们建立好了一个gbdt模型, 我们接下来要用它来预测出样本会落在每棵树的哪个叶子节点上, 为后面的离散特征构建做准备, 由于不是用gbdt预测结果而是预测训练数据在每棵树上的具体位置, 就需要用到下面的语句:
|
||||
|
||||
```python
|
||||
model = gbm.booster_ # 获取到建立的树
|
||||
|
||||
# 每个样本落在每个树的位置 , 下面两个是矩阵 (样本个数, 树的棵树) , 每一个数字代表某个样本落在了某个数的哪个叶子节点
|
||||
gbdt_feats_train = model.predict(train, pred_leaf = True)
|
||||
gbdt_feats_test = model.predict(test, pred_leaf = True)
|
||||
|
||||
# 把上面的矩阵转成新的样本-特征的形式, 与原有的数据集合并
|
||||
gbdt_feats_name = ['gbdt_leaf_' + str(i) for i in range(gbdt_feats_train.shape[1])]
|
||||
df_train_gbdt_feats = pd.DataFrame(gbdt_feats_train, columns = gbdt_feats_name)
|
||||
df_test_gbdt_feats = pd.DataFrame(gbdt_feats_test, columns = gbdt_feats_name)
|
||||
|
||||
# 构造新数据集
|
||||
train = pd.concat([train, df_train_gbdt_feats], axis = 1)
|
||||
test = pd.concat([test, df_test_gbdt_feats], axis = 1)
|
||||
train_len = train.shape[0]
|
||||
data = pd.concat([train, test])
|
||||
```
|
||||
|
||||
3. **离散特征的独热编码,并划分数据集**
|
||||
|
||||
```python
|
||||
# 新数据的新特征进行读入编码
|
||||
for col in gbdt_feats_name:
|
||||
onehot_feats = pd.get_dummies(data[col], prefix = col)
|
||||
data.drop([col], axis = 1, inplace = True)
|
||||
data = pd.concat([data, onehot_feats], axis = 1)
|
||||
|
||||
# 划分数据集
|
||||
train = data[: train_len]
|
||||
test = data[train_len:]
|
||||
|
||||
x_train, x_val, y_train, y_val = train_test_split(train, target, test_size = 0.3, random_state = 2018)
|
||||
```
|
||||
|
||||
4. **训练逻辑回归模型作最后的预测**
|
||||
|
||||
```python
|
||||
# 训练逻辑回归模型
|
||||
lr = LogisticRegression()
|
||||
lr.fit(x_train, y_train)
|
||||
tr_logloss = log_loss(y_train, lr.predict_proba(x_train)[:, 1])
|
||||
print('tr-logloss: ', tr_logloss)
|
||||
val_logloss = log_loss(y_val, lr.predict_proba(x_val)[:, 1])
|
||||
print('val-logloss: ', val_logloss)
|
||||
|
||||
# 预测
|
||||
y_pred = lr.predict_proba(test)[:, 1]
|
||||
```
|
||||
|
||||
上面我们就完成了GBDT+LR模型的基本训练步骤, 具体详细的代码可以参考链接。
|
||||
|
||||
### 思考
|
||||
1. **为什么使用集成的决策树? 为什么使用GBDT构建决策树而不是随机森林?**
|
||||
2. **面对高维稀疏类特征的时候(比如ID类特征), 逻辑回归一般要比GBDT这种非线性模型好, 为什么?**
|
||||
|
||||
|
||||
**参考资料**
|
||||
|
||||
* 王喆 - 《深度学习推荐系统》
|
||||
* [决策树之 GBDT 算法 - 分类部分](https://www.jianshu.com/p/f5e5db6b29f2)
|
||||
* [深入理解GBDT二分类算法](https://zhuanlan.zhihu.com/p/89549390?utm_source=zhihu)
|
||||
* [逻辑回归、优化算法和正则化的幕后细节补充](https://blog.csdn.net/wuzhongqiang/article/details/108456051)
|
||||
* [梯度提升树GBDT的理论学习与细节补充](https://blog.csdn.net/wuzhongqiang/article/details/108471107)
|
||||
* [推荐系统遇上深度学习(十)--GBDT+LR融合方案实战](https://zhuanlan.zhihu.com/p/37522339)
|
||||
* [CTR预估中GBDT与LR融合方案](https://blog.csdn.net/lilyth_lilyth/article/details/48032119)
|
||||
* [GBDT+LR算法解析及Python实现](https://www.cnblogs.com/wkang/p/9657032.html)
|
||||
* [常见计算广告点击率预估算法总结](https://zhuanlan.zhihu.com/p/29053940)
|
||||
* [GBDT--分类篇](https://blog.csdn.net/On_theway10/article/details/83576715?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.channel_param)
|
||||
|
||||
**论文**
|
||||
|
||||
* [http://quinonero.net/Publications/predicting-clicks-facebook.pdf 原论文](http://quinonero.net/Publications/predicting-clicks-facebook.pdf)
|
||||
* [Predicting Clicks: Estimating the Click-Through Rate for New Ads](https://www.microsoft.com/en-us/research/publication/predicting-clicks-estimating-the-click-through-rate-for-new-ads/)\
|
||||
* [Greedy Fun tion Approximation : A Gradient Boosting](https://www.semanticscholar.org/paper/Greedy-Fun-tion-Approximation-%3A-A-Gradient-Boosting-Friedman/0d97ee4888506beb30a3f3b6552d88a9b0ca11f0?p2df)
|
||||
|
||||
127
docs/推荐算法基础/经典排序模型/Wide&Deep系列/AFM.md
Normal file
127
docs/推荐算法基础/经典排序模型/Wide&Deep系列/AFM.md
Normal file
@@ -0,0 +1,127 @@
|
||||
# AFM
|
||||
## AFM提出的动机
|
||||
|
||||
AFM的全称是Attentional Factorization Machines, 从模型的名称上来看是在FM的基础上加上了注意力机制,FM是通过特征隐向量的内积来对交叉特征进行建模,从公式中可以看出所有的交叉特征都具有相同的权重也就是1,没有考虑到不同的交叉特征的重要性程度:
|
||||
$$
|
||||
y_{fm} = w_0+\sum_{i=1}^nw_ix_i+\sum_{i=1}^{n}\sum_{i+1}^n\lt v_i,v_j\gt x_ix_j
|
||||
$$
|
||||
如何让不同的交叉特征具有不同的重要性就是AFM核心的贡献,在谈论AFM交叉特征注意力之前,对于FM交叉特征部分的改进还有FFM,其是考虑到了对于不同的其他特征,某个指定特征的隐向量应该是不同的(相比于FM对于所有的特征只有一个隐向量,FFM对于一个特征有多个不同的隐向量)。
|
||||
|
||||
## AFM模型原理
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210131092744905.png" alt="image-20210131092744905" style="zoom: 50%;" />
|
||||
</div>
|
||||
上图表示的就是AFM交叉特征部分的模型结构(非交叉部分与FM是一样的,图中并没有给出)。AFM最核心的两个点分别是Pair-wise Interaction Layer和Attention-based Pooling。前者将输入的非零特征的隐向量两两计算element-wise product(哈达玛积,两个向量对应元素相乘,得到的还是一个向量),假如输入的特征中的非零向量的数量为m,那么经过Pair-wise Interaction Layer之后输出的就是$\frac{m(m-1)}{2}$个向量,再将前面得到的交叉特征向量组输入到Attention-based Pooling,该pooling层会先计算出每个特征组合的自适应权重(通过Attention Net进行计算),通过加权求和的方式将向量组压缩成一个向量,由于最终需要输出的是一个数值,所以还需要将前一步得到的向量通过另外一个向量将其映射成一个值,得到最终的基于注意力加权的二阶交叉特征的输出。(对于这部分如果不是很清楚,可以先看下面对两个核心层的介绍)
|
||||
|
||||
### Pair-wise Interaction Layer
|
||||
|
||||
FM二阶交叉项:所有非零特征对应的隐向量两两点积再求和,输出的是一个数值
|
||||
$$
|
||||
\sum_{i=1}^{n}\sum_{i+1}^n\lt v_i,v_j\gt x_ix_j
|
||||
$$
|
||||
AFM二阶交叉项(无attention):所有非零特征对应的隐向量两两对应元素乘积,然后再向量求和,输出的还是一个向量。
|
||||
$$
|
||||
\sum_{i=1}^{n}\sum_{i+1}^n (v_i \odot v_j) x_ix_j
|
||||
$$
|
||||
上述写法是为了更好的与FM进行对比,下面将公式变形方便与原论文中保持一致。首先是特征的隐向量。从上图中可以看出,作者对数值特征也对应了一个隐向量,不同的数值乘以对应的隐向量就可以得到不同的隐向量,相对于onehot编码的特征乘以1还是其本身(并没有什么变化),其实就是为了将公式进行统一。虽然论文中给出了对数值特征定义隐向量,但是在作者的代码中并没有发现有对数值特征进行embedding的过程([原论文代码链接](https://github.com/hexiangnan/attentional_factorization_machine/blob/master/code/AFM.py))具体原因不详。
|
||||
|
||||
按照论文的意思,特征的embedding可以表示为:$\varepsilon = {v_ix_i}$,经过Pair-wise Interaction Layer输出可得:
|
||||
$$
|
||||
f_{PI}(\varepsilon)=\{(v_i \odot v_j) x_ix_j\}_{i,j \in R_x}
|
||||
$$
|
||||
$R_x$表示的是有效特征集合。此时的$f_{PI}(\varepsilon)$表示的是一个向量集合,所以需要先将这些向量集合聚合成一个向量,然后在转换成一个数值:
|
||||
$$
|
||||
\hat{y} = p^T \sum_{(i,j)\in R_x}(v_i \odot v_j) x_ix_j + b
|
||||
$$
|
||||
上式中的求和部分就是将向量集合聚合成一个维度与隐向量维度相同的向量,通过向量$p$再将其转换成一个数值,b表示的是偏置。
|
||||
|
||||
从开始介绍Pair-wise Interaction Layer到现在解决的一个问题是,如何将使用哈达玛积得到的交叉特征转换成一个最终输出需要的数值,到目前为止交叉特征之间的注意力权重还没有出现。在没有详细介绍注意力之前先感性的认识一下如果现在已经有了每个交叉特征的注意力权重,那么交叉特征的输出可以表示为:
|
||||
$$
|
||||
\hat{y} = p^T \sum_{(i,j)\in R_x}\alpha_{ij}(v_i \odot v_j) x_ix_j + b
|
||||
$$
|
||||
就是在交叉特征得到的新向量前面乘以一个注意力权重$\alpha_{ij}$, 那么这个注意力权重如何计算得到呢?
|
||||
|
||||
### Attention-based Pooling
|
||||
|
||||
对于神经网络注意力相关的基础知识大家可以去看一下邱锡鹏老师的《神经网络与深度学习》第8章注意力机制与外部记忆。这里简单的叙述一下使用MLP实现注意力机制的计算。假设现在有n个交叉特征(假如维度是k),将nxk的数据输入到一个kx1的全连接网络中,输出的张量维度为nx1,使用softmax函数将nx1的向量的每个维度进行归一化,得到一个新的nx1的向量,这个向量所有维度加起来的和为1,每个维度上的值就可以表示原nxk数据每一行(即1xk的数据)的权重。用公式表示为:
|
||||
$$
|
||||
\alpha_{ij}' = h^T ReLU(W(v_i \odot v_j)x_ix_j + b)
|
||||
$$
|
||||
使用softmax归一化可得:
|
||||
$$
|
||||
\alpha_{ij} = \frac{exp(\alpha_{ij}')}{\sum_{(i,j)\in R_x}exp(\alpha_{ij}')}
|
||||
$$
|
||||
这样就得到了AFM二阶交叉部分的注意力权重,如果将AFM的一阶项写在一起,AFM模型用公式表示为:
|
||||
$$
|
||||
\hat{y}_{afm}(x) = w_0+\sum_{i=1}^nw_ix_i+p^T \sum_{(i,j)\in R_x}\alpha_{ij}(v_i \odot v_j) x_ix_j + b
|
||||
$$
|
||||
### AFM模型训练
|
||||
|
||||
AFM从最终的模型公式可以看出与FM的模型公式是非常相似的,所以也可以和FM一样应用于不同的任务,例如分类、回归及排序(不同的任务的损失函数是不一样的),AFM也有对防止过拟合进行处理:
|
||||
|
||||
1. 在Pair-wise Interaction Layer层的输出结果上使用dropout防止过拟合,因为并不是所有的特征组合对预测结果都有用,所以随机的去除一些交叉特征,让剩下的特征去自适应的学习可以更好的防止过拟合。
|
||||
2. 对Attention-based Pooling层中的权重矩阵$W$使用L2正则,作者没有在这一层使用dropout的原因是发现同时在特征交叉层和注意力层加dropout会使得模型训练不稳定,并且性能还会下降。
|
||||
|
||||
加上正则参数之后的回归任务的损失函数表示为:
|
||||
$$
|
||||
L = \sum_{x\in T} (\hat{y}_{afm}(x) - y(x))^2 + \lambda ||W||^2
|
||||
$$
|
||||
## AFM代码实现
|
||||
|
||||
1. linear part: 这部分是有关于线性计算,也就是FM的前半部分$w1x1+w2x2...wnxn+b$的计算。对于这一块的计算,我们用了一个get_linear_logits函数实现,后面再说,总之通过这个函数,我们就可以实现上面这个公式的计算过程,得到linear的输出
|
||||
2. dnn part: 这部分是后面交叉特征的那部分计算,这一部分需要使用注意力机制来将所有类别特征的embedding计算注意力权重,然后通过加权求和的方式将所有交叉之后的特征池化成一个向量,最终通过一个映射矩阵$p$将向量转化成一个logits值
|
||||
3. 最终将linear部分与dnn部分相加之后,通过sigmoid激活得到最终的输出
|
||||
|
||||
```python
|
||||
def AFM(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# embedding层用户构建FM交叉部分和DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 将输入到dnn中的sparse特征筛选出来
|
||||
att_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
att_logits = get_attention_logits(sparse_input_dict, att_sparse_feature_columns, embedding_layers) # B x (n(n-1)/2)
|
||||
|
||||
# 将linear,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, att_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layers)
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210307200304199.png" alt="image-20210307200304199" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片AFM.png" alt="image-20210307200304199" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
1. AFM与NFM优缺点对比。
|
||||
|
||||
|
||||
**参考资料**
|
||||
[原论文](https://www.ijcai.org/Proceedings/2017/0435.pdf)
|
||||
[deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
156
docs/推荐算法基础/经典排序模型/Wide&Deep系列/DeepFM.md
Normal file
156
docs/推荐算法基础/经典排序模型/Wide&Deep系列/DeepFM.md
Normal file
@@ -0,0 +1,156 @@
|
||||
# DeepFM
|
||||
## 动机
|
||||
对于CTR问题,被证明的最有效的提升任务表现的策略是特征组合(Feature Interaction), 在CTR问题的探究历史上来看就是如何更好地学习特征组合,进而更加精确地描述数据的特点。可以说这是基础推荐模型到深度学习推荐模型遵循的一个主要的思想。而组合特征大牛们研究过组合二阶特征,三阶甚至更高阶,但是面临一个问题就是随着阶数的提升,复杂度就成几何倍的升高。这样即使模型的表现更好了,但是推荐系统在实时性的要求也不能满足了。所以很多模型的出现都是为了解决另外一个更加深入的问题:如何更高效的学习特征组合?
|
||||
|
||||
为了解决上述问题,出现了FM和FFM来优化LR的特征组合较差这一个问题。并且在这个时候科学家们已经发现了DNN在特征组合方面的优势,所以又出现了FNN和PNN等使用深度网络的模型。但是DNN也存在局限性。
|
||||
|
||||
- **DNN局限**
|
||||
当我们使用DNN网络解决推荐问题的时候存在网络参数过于庞大的问题,这是因为在进行特征处理的时候我们需要使用one-hot编码来处理离散特征,这会导致输入的维度猛增。这里借用AI大会的一张图片:
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-15.png" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
这样庞大的参数量也是不实际的。为了解决DNN参数量过大的局限性,可以采用非常经典的Field思想,将OneHot特征转换为Dense Vector
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-40.png" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
此时通过增加全连接层就可以实现高阶的特征组合,如下图所示:
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-59.png" style="zoom:67%;" />
|
||||
</div>
|
||||
但是仍然缺少低阶的特征组合,于是增加FM来表示低阶的特征组合。
|
||||
|
||||
- **FNN和PNN**
|
||||
结合FM和DNN其实有两种方式,可以并行结合也可以串行结合。这两种方式各有几种代表模型。在DeepFM之前有FNN,虽然在影响力上可能并不如DeepFM,但是了解FNN的思想对我们理解DeepFM的特点和优点是很有帮助的。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-12-19.png" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
FNN是使用预训练好的FM模块,得到隐向量,然后把隐向量作为DNN的输入,但是经过实验进一步发现,在Embedding layer和hidden layer1之间增加一个product层(如上图所示)可以提高模型的表现,所以提出了PNN,使用product layer替换FM预训练层。
|
||||
|
||||
- **Wide&Deep**
|
||||
FNN和PNN模型仍然有一个比较明显的尚未解决的缺点:对于低阶组合特征学习到的比较少,这一点主要是由于FM和DNN的串行方式导致的,也就是虽然FM学到了低阶特征组合,但是DNN的全连接结构导致低阶特征并不能在DNN的输出端较好的表现。看来我们已经找到问题了,将串行方式改进为并行方式能比较好的解决这个问题。于是Google提出了Wide&Deep模型(将前几章),但是如果深入探究Wide&Deep的构成方式,虽然将整个模型的结构调整为了并行结构,在实际的使用中Wide Module中的部分需要较为精巧的特征工程,换句话说人工处理对于模型的效果具有比较大的影响(这一点可以在Wide&Deep模型部分得到验证)。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
|
||||
</div>
|
||||
如上图所示,该模型仍然存在问题:**在output Units阶段直接将低阶和高阶特征进行组合,很容易让模型最终偏向学习到低阶或者高阶的特征,而不能做到很好的结合。**
|
||||
|
||||
综上所示,DeepFM模型横空出世。
|
||||
|
||||
## 模型的结构与原理
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225180556628.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
前面的Field和Embedding处理是和前面的方法是相同的,如上图中的绿色部分;DeepFM将Wide部分替换为了FM layer如上图中的蓝色部分
|
||||
|
||||
这幅图其实有很多的点需要注意,很多人都一眼略过了,这里我个人认为在DeepFM模型中有三点需要注意:
|
||||
|
||||
- **Deep模型部分**
|
||||
- **FM模型部分**
|
||||
- **Sparse Feature中黄色和灰色节点代表什么意思**
|
||||
|
||||
### FM
|
||||
详细内容参考FM模型部分的内容,下图是FM的一个结构图,从图中大致可以看出FM Layer是由一阶特征和二阶特征Concatenate到一起在经过一个Sigmoid得到logits(结合FM的公式一起看),所以在实现的时候需要单独考虑linear部分和FM交叉特征部分。
|
||||
$$
|
||||
\hat{y}_{FM}(x) = w_0+\sum_{i=1}^N w_ix_i + \sum_{i=1}^N \sum_{j=i+1}^N v_i^T v_j x_ix_j
|
||||
$$
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225181340313.png" alt="image-20210225181340313" style="zoom: 67%;" />
|
||||
</div>
|
||||
### Deep
|
||||
Deep架构图
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225181010107.png" alt="image-20210225181010107" style="zoom:50%;" />
|
||||
</div>
|
||||
Deep Module是为了学习高阶的特征组合,在上图中使用用全连接的方式将Dense Embedding输入到Hidden Layer,这里面Dense Embeddings就是为了解决DNN中的参数爆炸问题,这也是推荐模型中常用的处理方法。
|
||||
|
||||
Embedding层的输出是将所有id类特征对应的embedding向量concat到到一起输入到DNN中。其中$v_i$表示第i个field的embedding,m是field的数量。
|
||||
$$
|
||||
z_1=[v_1, v_2, ..., v_m]
|
||||
$$
|
||||
上一层的输出作为下一层的输入,我们得到:
|
||||
$$
|
||||
z_L=\sigma(W_{L-1} z_{L-1}+b_{L-1})
|
||||
$$
|
||||
其中$\sigma$表示激活函数,$z, W, b $分别表示该层的输入、权重和偏置。
|
||||
|
||||
最后进入DNN部分输出使用sigmod激活函数进行激活:
|
||||
$$
|
||||
y_{DNN}=\sigma(W^{L}a^L+b^L)
|
||||
$$
|
||||
|
||||
|
||||
## 代码实现
|
||||
DeepFM在模型的结构图中显示,模型大致由两部分组成,一部分是FM,还有一部分就是DNN, 而FM又由一阶特征部分与二阶特征交叉部分组成,所以可以将整个模型拆成三部分,分别是一阶特征处理linear部分,二阶特征交叉FM以及DNN的高阶特征交叉。在下面的代码中也能够清晰的看到这个结构。此外每一部分可能由是由不同的特征组成,所以在构建模型的时候需要分别对这三部分输入的特征进行选择。
|
||||
|
||||
- linear_logits: 这部分是有关于线性计算,也就是FM的前半部分$w1x1+w2x2...wnxn+b$的计算。对于这一块的计算,我们用了一个get_linear_logits函数实现,后面再说,总之通过这个函数,我们就可以实现上面这个公式的计算过程,得到linear的输出, 这部分特征由数值特征和类别特征的onehot编码组成的一维向量组成,实际应用中根据自己的业务放置不同的一阶特征(这里的dense特征并不是必须的,有可能会将数值特征进行分桶,然后在当做类别特征来处理)
|
||||
- fm_logits: 这一块主要是针对离散的特征,首先过embedding,然后使用FM特征交叉的方式,两两特征进行交叉,得到新的特征向量,最后计算交叉特征的logits
|
||||
- dnn_logits: 这一块主要是针对离散的特征,首先过embedding,然后将得到的embedding拼接成一个向量(具体的可以看代码,也可以看一下下面的模型结构图),通过dnn学习类别特征之间的隐式特征交叉并输出logits值
|
||||
|
||||
```python
|
||||
def DeepFM(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# embedding层用户构建FM交叉部分和DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 将输入到dnn中的所有sparse特征筛选出来
|
||||
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
fm_logits = get_fm_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # 只考虑二阶项
|
||||
|
||||
# 将所有的Embedding都拼起来,一起输入到dnn中
|
||||
dnn_logits = get_dnn_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
|
||||
|
||||
# 将linear,FM,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, fm_logits, dnn_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layers)
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210228161135777.png" alt="image-20210228161135777" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片DeepFM.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
1. 如果对于FM采用随机梯度下降SGD训练模型参数,请写出模型各个参数的梯度和FM参数训练的复杂度
|
||||
2. 对于下图所示,根据你的理解Sparse Feature中的不同颜色节点分别表示什么意思
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225180556628.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
|
||||
**参考资料**
|
||||
- [论文原文](https://arxiv.org/pdf/1703.04247.pdf)
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
- [FM](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommendationSystemFundamentals/04%20FM.md)
|
||||
- [推荐系统遇上深度学习(三)--DeepFM模型理论和实践](https://www.jianshu.com/p/6f1c2643d31b)
|
||||
- [FM算法公式推导](https://blog.csdn.net/qq_32486393/article/details/103498519)
|
||||
146
docs/推荐算法基础/经典排序模型/Wide&Deep系列/NFM.md
Normal file
146
docs/推荐算法基础/经典排序模型/Wide&Deep系列/NFM.md
Normal file
@@ -0,0 +1,146 @@
|
||||
# NFM
|
||||
## 动机
|
||||
|
||||
NFM(Neural Factorization Machines)是2017年由新加坡国立大学的何向南教授等人在SIGIR会议上提出的一个模型,传统的FM模型仅局限于线性表达和二阶交互, 无法胜任生活中各种具有复杂结构和规律性的真实数据, 针对FM的这点不足, 作者提出了一种将FM融合进DNN的策略,通过引进了一个特征交叉池化层的结构,使得FM与DNN进行了完美衔接,这样就组合了FM的建模低阶特征交互能力和DNN学习高阶特征交互和非线性的能力,形成了深度学习时代的神经FM模型(NFM)。
|
||||
|
||||
那么NFM具体是怎么做的呢? 首先看一下NFM的公式:
|
||||
$$
|
||||
\hat{y}_{N F M}(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+f(\mathbf{x})
|
||||
$$
|
||||
我们对比FM, 就会发现变化的是第三项,前两项还是原来的, 因为我们说FM的一个问题,就是只能到二阶交叉, 且是线性模型, 这是他本身的一个局限性, 而如果想突破这个局限性, 就需要从他的公式本身下点功夫, 于是乎,作者在这里改进的思路就是**用一个表达能力更强的函数来替代原FM中二阶隐向量内积的部分**。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" style="zoom:70%;" />
|
||||
</div>
|
||||
而这个表达能力更强的函数呢, 我们很容易就可以想到神经网络来充当,因为神经网络理论上可以拟合任何复杂能力的函数, 所以作者真的就把这个$f(x)$换成了一个神经网络,当然不是一个简单的DNN, 而是依然底层考虑了交叉,然后高层使用的DNN网络, 这个也就是我们最终的NFM网络了:
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" style="zoom:80%;" />
|
||||
</div>
|
||||
这个结构,如果前面看过了PNN的伙伴会发现,这个结构和PNN非常像,只不过那里是一个product_layer, 而这里换成了Bi-Interaction Pooling了, 这个也是NFM的核心结构了。这里注意, 这个结构中,忽略了一阶部分,只可视化出来了$f(x)$, 我们还是下面从底层一点点的对这个网络进行剖析。
|
||||
|
||||
## 模型结构与原理
|
||||
### Input 和Embedding层
|
||||
输入层的特征, 文章指定了稀疏离散特征居多, 这种特征我们也知道一般是先one-hot, 然后会通过embedding,处理成稠密低维的。 所以这两层还是和之前一样,假设$\mathbf{v}_{\mathbf{i}} \in \mathbb{R}^{k}$为第$i$个特征的embedding向量, 那么$\mathcal{V}_{x}=\left\{x_{1} \mathbf{v}_{1}, \ldots, x_{n} \mathbf{v}_{n}\right\}$表示的下一层的输入特征。这里带上了$x_i$是因为很多$x_i$转成了One-hot之后,出现很多为0的, 这里的$\{x_iv_i\}$是$x_i$不等于0的那些特征向量。
|
||||
|
||||
### Bi-Interaction Pooling layer
|
||||
在Embedding层和神经网络之间加入了特征交叉池化层是本网络的核心创新了,正是因为这个结构,实现了FM与DNN的无缝连接, 组成了一个大的网络,且能够正常的反向传播。假设$\mathcal{V}_{x}$是所有特征embedding的集合, 那么在特征交叉池化层的操作:
|
||||
$$
|
||||
f_{B I}\left(\mathcal{V}_{x}\right)=\sum_{i=1}^{n} \sum_{j=i+1}^{n} x_{i} \mathbf{v}_{i} \odot x_{j} \mathbf{v}_{j}
|
||||
$$
|
||||
|
||||
$\odot$表示两个向量的元素积操作,即两个向量对应维度相乘得到的元素积向量(可不是点乘呀),其中第$k$维的操作:
|
||||
$$
|
||||
\left(v_{i} \odot v_{j}\right)_{k}=\boldsymbol{v}_{i k} \boldsymbol{v}_{j k}
|
||||
$$
|
||||
|
||||
这便定义了在embedding空间特征的二阶交互,这个不仔细看会和感觉FM的最后一项很像,但是不一样,一定要注意这个地方不是两个隐向量的内积,而是元素积,也就是这一个交叉完了之后k个维度不求和,最后会得到一个$k$维向量,而FM那里内积的话最后得到一个数, 在进行两两Embedding元素积之后,对交叉特征向量取和, 得到该层的输出向量, 很显然, 输出是一个$k$维的向量。
|
||||
|
||||
注意, 之前的FM到这里其实就完事了, 上面就是输出了,而这里很大的一点改进就是加入特征池化层之后, 把二阶交互的信息合并, 且上面接了一个DNN网络, 这样就能够增强FM的表达能力了, 因为FM只能到二阶, 而这里的DNN可以进行多阶且非线性,只要FM把二阶的学习好了, DNN这块学习来会更加容易, 作者在论文中也说明了这一点,且通过后面的实验证实了这个观点。
|
||||
|
||||
如果不加DNN, NFM就退化成了FM,所以改进的关键就在于加了一个这样的层,组合了一下二阶交叉的信息,然后又给了DNN进行高阶交叉的学习,成了一种“加强版”的FM。
|
||||
|
||||
Bi-Interaction层不需要额外的模型学习参数,更重要的是它在一个线性的时间内完成计算,和FM一致的,即时间复杂度为$O\left(k N_{x}\right)$,$N_x$为embedding向量的数量。参考FM,可以将上式转化为:
|
||||
$$
|
||||
f_{B I}\left(\mathcal{V}_{x}\right)=\frac{1}{2}\left[\left(\sum_{i=1}^{n} x_{i} \mathbf{v}_{i}\right)^{2}-\sum_{i=1}^{n}\left(x_{i} \mathbf{v}_{i}\right)^{2}\right]
|
||||
$$
|
||||
后面代码复现NFM就是用的这个公式直接计算,比较简便且清晰。
|
||||
|
||||
### 隐藏层
|
||||
这一层就是全连接的神经网络, DNN在进行特征的高层非线性交互上有着天然的学习优势,公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\mathbf{z}_{1}=&\sigma_{1}\left(\mathbf{W}_{1} f_{B I}
|
||||
\left(\mathcal{V}_{x}\right)+\mathbf{b}_{1}\right) \\
|
||||
\mathbf{z}_{2}=& \sigma_{2}\left(\mathbf{W}_{2} \mathbf{z}_{1}+\mathbf{b}_{2}\right) \\
|
||||
\ldots \ldots \\
|
||||
\mathbf{z}_{L}=& \sigma_{L}\left(\mathbf{W}_{L} \mathbf{z}_{L-1}+\mathbf{b}_{L}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的$\sigma_i$是第$i$层的激活函数,可不要理解成sigmoid激活函数。
|
||||
|
||||
### 预测层
|
||||
这个就是最后一层的结果直接过一个隐藏层,但注意由于这里是回归问题,没有加sigmoid激活:
|
||||
$$
|
||||
f(\mathbf{x})=\mathbf{h}^{T} \mathbf{z}_{L}
|
||||
$$
|
||||
|
||||
所以, NFM模型的前向传播过程总结如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\hat{y}_{N F M}(\mathbf{x}) &=w_{0}+\sum_{i=1}^{n} w_{i} x_{i} \\
|
||||
&+\mathbf{h}^{T} \sigma_{L}\left(\mathbf{W}_{L}\left(\ldots \sigma_{1}\left(\mathbf{W}_{1} f_{B I}\left(\mathcal{V}_{x}\right)+\mathbf{b}_{1}\right) \ldots\right)+\mathbf{b}_{L}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这就是NFM模型的全貌, NFM相比较于其他模型的核心创新点是特征交叉池化层,基于它,实现了FM和DNN的无缝连接,使得DNN可以在底层就学习到包含更多信息的组合特征,这时候,就会减少DNN的很多负担,只需要很少的隐藏层就可以学习到高阶特征信息。NFM相比之前的DNN, 模型结构更浅,更简单,但是性能更好,训练和调参更容易。集合FM二阶交叉线性和DNN高阶交叉非线性的优势,非常适合处理稀疏数据的场景任务。在对NFM的真实训练过程中,也会用到像Dropout和BatchNormalization这样的技术来缓解过拟合和在过大的改变数据分布。
|
||||
|
||||
下面通过代码看下NFM的具体实现过程, 学习一些细节。
|
||||
|
||||
## 代码实现
|
||||
下面我们看下NFM的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
|
||||
|
||||
这里主要说一下NFM模型的总体运行逻辑, 这样可以让大家从宏观的层面去把握模型的设计过程, 该模型所使用的数据集是criteo数据集,具体介绍参考后面的GitHub。 数据集的特征会分为dense特征(连续)和sparse特征(离散), 所以模型的输入层接收这两种输入。但是我们这里把输入分成了linear input和dnn input两种情况,而每种情况都有可能包含上面这两种输入。因为我们后面的模型逻辑会分这两部分走,这里有个细节要注意,就是光看上面那个NFM模型的话,是没有看到它线性特征处理的那部分的,也就是FM的前半部分公式那里图里面是没有的。但是这里我们要加上。
|
||||
$$
|
||||
\hat{y}_{N F M}(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+f(\mathbf{x})
|
||||
$$
|
||||
所以模型的逻辑我们分成了两大部分,这里我分别给大家解释下每一块做了什么事情:
|
||||
|
||||
1. linear part: 这部分是有关于线性计算,也就是FM的前半部分$w1x1+w2x2...wnxn+b$的计算。对于这一块的计算,我们用了一个get_linear_logits函数实现,后面再说,总之通过这个函数,我们就可以实现上面这个公式的计算过程,得到linear的输出
|
||||
2. dnn part: 这部分是后面交叉特征的那部分计算,FM的最后那部分公式f(x)。 这一块主要是针对离散的特征,首先过embedding, 然后过特征交叉池化层,这个计算我们用了get_bi_interaction_pooling_output函数实现, 得到输出之后又过了DNN网络,最后得到dnn的输出
|
||||
|
||||
模型的最后输出结果,就是把这两个部分的输出结果加和(当然也可以加权),再过一个sigmoid得到。所以NFM的模型定义就出来了:
|
||||
|
||||
```python
|
||||
def NFM(linear_feature_columns, dnn_feature_columns):
|
||||
"""
|
||||
搭建NFM模型,上面已经把所有组块都写好了,这里拼起来就好
|
||||
:param linear_feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是linear数据的特征封装版
|
||||
:param dnn_feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是DNN数据的特征封装版
|
||||
"""
|
||||
# 构建输入层,即所有特征对应的Input()层, 这里使用字典的形式返回, 方便后续构建模型
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns+dnn_feature_columns)
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 线性部分的计算 w1x1 + w2x2 + ..wnxn + b部分,dense特征和sparse两部分的计算结果组成,具体看上面细节
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_feature_columns)
|
||||
|
||||
# DNN部分的计算
|
||||
# 首先,在这里构建DNN部分的embedding层,之所以写在这里,是为了灵活的迁移到其他网络上,这里用字典的形式返回
|
||||
# embedding层用于构建FM交叉部分以及DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 过特征交叉池化层
|
||||
pooling_output = get_bi_interaction_pooling_output(sparse_input_dict, dnn_feature_columns, embedding_layers)
|
||||
|
||||
# 加个BatchNormalization
|
||||
pooling_output = BatchNormalization()(pooling_output)
|
||||
|
||||
# dnn部分的计算
|
||||
dnn_logits = get_dnn_logits(pooling_output)
|
||||
|
||||
# 线性部分和dnn部分的结果相加,最后再过个sigmoid
|
||||
output_logits = Add()([linear_logits, dnn_logits])
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(inputs=input_layers, outputs=output_layers)
|
||||
|
||||
return model
|
||||
```
|
||||
|
||||
有了上面的解释,这个模型的宏观层面相信就很容易理解了。关于这每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片NFM_aaaa.png" alt="NFM_aaaa" style="zoom: 50%;" />
|
||||
</div>
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片nfm.png" alt="NFM_aaaa" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考题
|
||||
1. NFM中的特征交叉与FM中的特征交叉有何异同,分别从原理和代码实现上进行对比分析
|
||||
|
||||
**参考资料**
|
||||
- [论文原文](https://arxiv.org/pdf/1708.05027.pdf)
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
- [AI上推荐 之 FNN、DeepFM与NFM(FM在深度学习中的身影重现)](https://blog.csdn.net/wuzhongqiang/article/details/109532267?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161442951716780255224635%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=161442951716780255224635&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v1~rank_blog_v1-1-109532267.pc_v1_rank_blog_v1&utm_term=NFM)
|
||||
118
docs/推荐算法基础/经典排序模型/Wide&Deep系列/Wide&Deep.md
Normal file
118
docs/推荐算法基础/经典排序模型/Wide&Deep系列/Wide&Deep.md
Normal file
@@ -0,0 +1,118 @@
|
||||
# Wide & Deep
|
||||
## 动机
|
||||
|
||||
在CTR预估任务中利用手工构造的交叉组合特征来使线性模型具有“记忆性”,使模型记住共现频率较高的特征组合,往往也能达到一个不错的baseline,且可解释性强。但这种方式有着较为明显的缺点:
|
||||
|
||||
1. 特征工程需要耗费太多精力。
|
||||
2. 模型是强行记住这些组合特征的,对于未曾出现过的特征组合,权重系数为0,无法进行泛化。
|
||||
|
||||
为了加强模型的泛化能力,研究者引入了DNN结构,将高维稀疏特征编码为低维稠密的Embedding vector,这种基于Embedding的方式能够有效提高模型的泛化能力。但是,基于Embedding的方式可能因为数据长尾分布,导致长尾的一些特征值无法被充分学习,其对应的Embedding vector是不准确的,这便会造成模型泛化过度。
|
||||
|
||||
Wide&Deep模型就是围绕记忆性和泛化性进行讨论的,模型能够从历史数据中学习到高频共现的特征组合的能力,称为是模型的Memorization。能够利用特征之间的传递性去探索历史数据中从未出现过的特征组合,称为是模型的Generalization。Wide&Deep兼顾Memorization与Generalization并在Google Play store的场景中成功落地。
|
||||
|
||||
## 模型结构及原理
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
|
||||
</div>
|
||||
|
||||
其实wide&deep模型本身的结构是非常简单的,对于有点机器学习基础和深度学习基础的人来说都非常的容易看懂,但是如何根据自己的场景去选择那些特征放在Wide部分,哪些特征放在Deep部分就需要理解这篇论文提出者当时对于设计该模型不同结构时的意图了,所以这也是用好这个模型的一个前提。
|
||||
|
||||
**如何理解Wide部分有利于增强模型的“记忆能力”,Deep部分有利于增强模型的“泛化能力”?**
|
||||
|
||||
- wide部分是一个广义的线性模型,输入的特征主要有两部分组成,一部分是原始的部分特征,另一部分是原始特征的交叉特征(cross-product transformation),对于交互特征可以定义为:
|
||||
$$
|
||||
\phi_{k}(x)=\prod_{i=1}^d x_i^{c_{ki}}, c_{ki}\in \{0,1\}
|
||||
$$
|
||||
$c_{ki}$是一个布尔变量,当第i个特征属于第k个特征组合时,$c_{ki}$的值为1,否则为0,$x_i$是第i个特征的值,大体意思就是两个特征都同时为1这个新的特征才能为1,否则就是0,说白了就是一个特征组合。用原论文的例子举例:
|
||||
|
||||
> AND(user_installed_app=QQ, impression_app=WeChat),当特征user_installed_app=QQ,和特征impression_app=WeChat取值都为1的时候,组合特征AND(user_installed_app=QQ, impression_app=WeChat)的取值才为1,否则为0。
|
||||
|
||||
对于wide部分训练时候使用的优化器是带$L_1$正则的FTRL算法(Follow-the-regularized-leader),而L1 FTLR是非常注重模型稀疏性质的,也就是说W&D模型采用L1 FTRL是想让Wide部分变得更加的稀疏,即Wide部分的大部分参数都为0,这就大大压缩了模型权重及特征向量的维度。**Wide部分模型训练完之后留下来的特征都是非常重要的,那么模型的“记忆能力”就可以理解为发现"直接的",“暴力的”,“显然的”关联规则的能力。**例如Google W&D期望wide部分发现这样的规则:**用户安装了应用A,此时曝光应用B,用户安装应用B的概率大。**
|
||||
|
||||
- Deep部分是一个DNN模型,输入的特征主要分为两大类,一类是数值特征(可直接输入DNN),一类是类别特征(需要经过Embedding之后才能输入到DNN中),Deep部分的数学形式如下:
|
||||
$$
|
||||
a^{(l+1)} = f(W^{l}a^{(l)} + b^{l})
|
||||
$$
|
||||
**我们知道DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。**对于Deep部分的DNN模型作者使用了深度学习常用的优化器AdaGrad,这也是为了使得模型可以得到更精确的解。
|
||||
|
||||
**Wide部分与Deep部分的结合**
|
||||
|
||||
W&D模型是将两部分输出的结果结合起来联合训练,将deep和wide部分的输出重新使用一个逻辑回归模型做最终的预测,输出概率值。联合训练的数学形式如下:需要注意的是,因为Wide侧的数据是高维稀疏的,所以作者使用了FTRL算法优化,而Deep侧使用的是 Adagrad。
|
||||
$$
|
||||
P(Y=1|x)=\delta(w_{wide}^T[x,\phi(x)] + w_{deep}^T a^{(lf)} + b)
|
||||
$$
|
||||
|
||||
## 代码实现
|
||||
|
||||
Wide侧记住的是历史数据中那些**常见、高频**的模式,是推荐系统中的“**红海**”。实际上,Wide侧没有发现新的模式,只是学习到这些模式之间的权重,做一些模式的筛选。正因为Wide侧不能发现新模式,因此我们需要**根据人工经验、业务背景,将我们认为有价值的、显而易见的特征及特征组合,喂入Wide侧**
|
||||
|
||||
Deep侧就是DNN,通过embedding的方式将categorical/id特征映射成稠密向量,让DNN学习到这些特征之间的**深层交叉**,以增强扩展能力。
|
||||
|
||||
模型的实现与模型结构类似由deep和wide两部分组成,这两部分结构所需要的特征在上面已经说过了,针对当前数据集实现,我们在wide部分加入了所有可能的一阶特征,包括数值特征和类别特征的onehot都加进去了,其实也可以加入一些与wide&deep原论文中类似交叉特征。只要能够发现高频、常见模式的特征都可以放在wide侧,对于Deep部分,在本数据中放入了数值特征和类别特征的embedding特征,实际应用也需要根据需求进行选择。
|
||||
|
||||
```python
|
||||
# Wide&Deep 模型的wide部分及Deep部分的特征选择,应该根据实际的业务场景去确定哪些特征应该放在Wide部分,哪些特征应该放在Deep部分
|
||||
def WideNDeep(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# Wide&Deep模型论文中Wide部分使用的特征比较简单,并且得到的特征非常的稀疏,所以使用了FTRL优化Wide部分(这里没有实现FTRL)
|
||||
# 但是是根据他们业务进行选择的,我们这里将所有可能用到的特征都输入到Wide部分,具体的细节可以根据需求进行修改
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
# 在Wide&Deep模型中,deep部分的输入是将dense特征和embedding特征拼在一起输入到dnn中
|
||||
dnn_logits = get_dnn_logits(dense_input_dict, sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
|
||||
|
||||
# 将linear,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, dnn_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layer = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210228160557072.png" alt="image-20210228160557072" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片Wide&Deep.png" alt="image-20210228160557072" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
1. 在你的应用场景中,哪些特征适合放在Wide侧,哪些特征适合放在Deep侧,为什么呢?
|
||||
2. 为什么Wide部分要用L1 FTRL训练?
|
||||
3. 为什么Deep部分不特别考虑稀疏性的问题?
|
||||
|
||||
思考题可以参考[见微知著,你真的搞懂Google的Wide&Deep模型了吗?](https://zhuanlan.zhihu.com/p/142958834)
|
||||
|
||||
|
||||
**参考资料**
|
||||
- [论文原文](https://arxiv.org/pdf/1606.07792.pdf)
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
- [看Google如何实现Wide & Deep模型(1)](https://zhuanlan.zhihu.com/p/47293765)
|
||||
- [推荐系统系列(六):Wide&Deep理论与实践](https://zhuanlan.zhihu.com/p/92279796?utm_source=wechat_session&utm_medium=social&utm_oi=753565305866829824&utm_campaign=shareopn)
|
||||
- [见微知著,你真的搞懂Google的Wide&Deep模型了吗?](https://zhuanlan.zhihu.com/p/142958834)
|
||||
- [用NumPy手工打造 Wide & Deep](https://zhuanlan.zhihu.com/p/53110408)
|
||||
- [tensorflow官网的WideDeepModel](https://www.tensorflow.org/api_docs/python/tf/keras/experimental/WideDeepModel)
|
||||
- [详解 Wide & Deep 结构背后的动机](https://zhuanlan.zhihu.com/p/53361519)
|
||||
|
||||
|
||||
1
docs/推荐算法基础/经典排序模型/Wide&Deep系列/readme.md
Normal file
1
docs/推荐算法基础/经典排序模型/Wide&Deep系列/readme.md
Normal file
@@ -0,0 +1 @@
|
||||
# README
|
||||
1
docs/推荐算法基础/经典排序模型/多任务学习/readme.md
Normal file
1
docs/推荐算法基础/经典排序模型/多任务学习/readme.md
Normal file
@@ -0,0 +1 @@
|
||||
# README
|
||||
177
docs/推荐算法基础/经典排序模型/序列模型/DIEN.md
Normal file
177
docs/推荐算法基础/经典排序模型/序列模型/DIEN.md
Normal file
@@ -0,0 +1,177 @@
|
||||
# DIEN
|
||||
## DIEN提出的动机
|
||||
在推荐场景,用户无需输入搜索关键词来表达意图,这种情况下捕捉用户兴趣并考虑兴趣的动态变化将是提升模型效果的关键。以Wide&Deep为代表的深度模型更多的是考虑不同field特征之间的相互作用,未关注用户兴趣。
|
||||
|
||||
DIN模型考虑了用户兴趣,并且强调用户兴趣是多样的,该模型使用注意力机制来捕捉和**target item**的相关的兴趣,这样以来用户的兴趣就会随着目标商品自适应的改变。但是大多该类模型包括DIN在内,直接将用户的行为当做用户的兴趣(因为DIN模型只是在行为序列上做了简单的特征处理),但是用户潜在兴趣一般很难直接通过用户的行为直接表示,大多模型都没有挖掘用户行为背后真实的兴趣,捕捉用户兴趣的动态变化对用户兴趣的表示非常重要。DIEN相比于之前的模型,即对用户的兴趣进行建模,又对建模出来的用户兴趣继续建模得到用户的兴趣变化过程。
|
||||
|
||||
## DIEN模型原理
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218155901144.png" alt="image-20210218155901144" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
模型的输入可以分成两大部分,一部分是用户的行为序列(这部分会通过兴趣提取层及兴趣演化层转换成与用户当前兴趣相关的embedding),另一部分就是除了用户行为以外的其他所有特征,如Target id, Coontext Feature, UserProfile Feature,这些特征都转化成embedding的类型然后concat在一起(形成一个大的embedding)作为非行为相关的特征(这里可能也会存在一些非id类特征,应该可以直接进行concat)。最后DNN输入的部分由行为序列embedding和非行为特征embedding(多个特征concat到一起之后形成的一个大的向量)组成,将两者concat之后输入到DNN中。
|
||||
|
||||
所以DIEN模型的重点就是如何将用户的行为序列转换成与用户兴趣相关的向量,在DIN中是直接通过与target item计算序列中每个元素的注意力分数,然后加权求和得到最终的兴趣表示向量。在DIEN中使用了两层结构来建模用户兴趣相关的向量。
|
||||
|
||||
### Interest Exterator Layer
|
||||
|
||||
兴趣抽取层的输入原本是一个id序列(按照点击时间的先后顺序形成的一个序列),通过Embedding层将其转化成一个embedding序列。然后使用GRU模块对兴趣进行抽取,GRU的输入是embedding层之后得到的embedding序列。对于GRU模块不是很了解的可以看一下[动手学深度学习中GRU相关的内容](https://zh.d2l.ai/chapter_recurrent-neural-networks/gru.html)
|
||||
|
||||
作者并没有直接完全使用原始的GRU来提取用户的兴趣,而是引入了一个辅助函数来指导用户兴趣的提取。作者认为如果直接使用GRU提取用户的兴趣,只能得到用户行为之间的依赖关系,不能有效的表示用户的兴趣。因为是用户的兴趣导致了用户的点击,用户的最后一次点击与用户点击之前的兴趣相关性就很强,但是直接使用行为序列训练GRU的话,只有用户最后一次点击的物品(也就是label,在这里可以认为是Target Ad), 那么最多就是能够捕捉到用户最后一次点击时的兴趣,而最后一次的兴趣又和前面点击过的物品在兴趣上是相关的,而前面点击的物品中并没有target item进行监督。**所以作者提出的辅助损失就是为了让行为序列中的每一个时刻都有一个target item进行监督训练,也就是使用下一个行为来监督兴趣状态的学习**
|
||||
|
||||
**辅助损失**
|
||||
首先需要明确的就是辅助损失是计算哪两个量的损失。计算的是用户每个时刻的兴趣表示(GRU每个时刻输出的隐藏状态形成的序列)与用户当前时刻实际点击的物品表示(输入的embedding序列)之间的损失,相当于是行为序列中的第t+1个物品与用户第t时刻的兴趣表示之间的损失**(为什么这里用户第t时刻的兴趣与第t+1时刻的真实点击做损失呢?我的理解是,只有知道了用户第t+1真实点击的商品,才能更好的确定用户第t时刻的兴趣)。**
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218163742638.png" alt="image-20210218163742638" style="zoom:50%;" />
|
||||
</div>
|
||||
|
||||
当然,如果只计算用户点击物品与其点击前一次的兴趣之间的损失,只能认为是正样本之间的损失,那么用户第t时刻的兴趣其实还有很多其他的未点击的商品,这些未点击的商品就是负样本,负样本一般通过从用户点击序列中采样得到,这样一来辅助损失中就包含了用户某个时刻下的兴趣及与该时刻兴趣相关的正负物品。所以最终的损失函数表示如下。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218162447125.png" alt="image-20210218162447125" style="zoom: 25%;" />
|
||||
</div>
|
||||
其中$h_t^i$表示的是用户$i$第$t$时刻的隐藏状态,可以表示用户第$t$时刻的兴趣向量,$e_b^i,\hat{e_b^i}$分别表示的是正负样本,$e_b^i[t+1]$表示的是用户$i$第$t+1$时刻点击的物品向量。
|
||||
|
||||
辅助损失会加到最终的目标损失(ctr损失)中一起进行优化,并且通过$\alpha$参数来平衡点击率和兴趣的关系
|
||||
$$
|
||||
L = L_{target} + \alpha L_{aux}
|
||||
$$
|
||||
|
||||
**引入辅助函数的函数有:**
|
||||
|
||||
- 辅助loss可以帮助GRU的隐状态更好地表示用户兴趣。
|
||||
|
||||
- RNN在长序列建模场景下梯度传播可能并不能很好的影响到序列开始部分,如果在序列的每个部分都引入一个辅助的监督信号,则可一定程度降低优化难度。
|
||||
|
||||
- 辅助loss可以给embedding层的学习带来更多语义信息,学习到item对应的更好的embedding。
|
||||
|
||||
### Interest Evolving Layer
|
||||
将用户的行为序列通过GRU+辅助损失建模之后,对用户行为序列中的兴趣进行了提取并表达成了向量的形式(GRU每个时刻输出的隐藏状态)。而用户的兴趣会因为外部环境或内部认知随着时间变化,特点如下:
|
||||
|
||||
- **兴趣是多样化的,可能发生漂移**。兴趣漂移对行为的影响是用户可能在一段时间内对各种书籍感兴趣,而在另一段时间却需要衣服
|
||||
|
||||
- 虽然兴趣可能会相互影响,但是**每一种兴趣都有自己的发展过程**,例如书和衣服的发展过程几乎是独立的。**而我们只关注与target item相关的演进过程。**
|
||||
|
||||
由于用户的兴趣是多样的,但是用户的每一种兴趣都有自己的发展过程,即使兴趣发生漂移我们可以只考虑用户与target item(广告或者商品)相关的兴趣演化过程,这样就不用考虑用户多样化的兴趣的问题了,而如何只获取与target item相关的信息,作者使用了与DIN模型中提取与target item相同的方法,来计算用户历史兴趣与target item之间的相似度,即这里也使用了DIN中介绍的局部激活单元(就是下图中的Attention模块)。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218180755462.png" alt="image-20210218180755462" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
当得到了用户历史兴趣序列及兴趣序列与target item之间的相关性(注意力分数)之后,就需要再次对注意力序列进行建模得到用户注意力的演化过程,进一步表示用户最终的兴趣向量。此时的序列数据等同于有了一个序列及序列中每个向量的注意力权重,下面就是考虑如何使用这个注意力权重来一起优化序列建模的结果了。作者提出了三种注意力结合的GRU模型快:
|
||||
|
||||
1. **AIGRU:** 将注意力分数直接与输入的序列进行相乘,也就是权重越大的向量对应的值也越大, 其中$i_t^{'}, h_t, a_t$分别表示用户$i$在兴趣演化过程使用的GRU的第t时刻的输入,$h_t$表示的是兴趣抽取层第t时刻的输出,$a_t$表示的是$h_t$的注意力分数,这种方式的弊端是即使是零输入也会改变GRU的隐藏状态,所以相对较少的兴趣值也会影响兴趣的学习进化(根据GRU门的更新公式就可以知道,下一个隐藏状态的计算会用到上一个隐藏状态的信息,所以即使当前输入为0,最终隐藏状态也不会直接等于0,所以即使兴趣较少,也会影响到最终兴趣的演化)。
|
||||
$$
|
||||
i_t^{'} = h_t * a_t
|
||||
$$
|
||||
|
||||
2. **AGRU:** 将注意力分数直接作为GRU模块中,更新门的值,则重置门对应的值表示为$1-a_t$, 所以最终隐藏状态的更新公式表示为:其中$\hat{h_t^{'}}$表示的是候选隐藏状态。但是这种方式的弊端是弱化了兴趣之间的相关性,因为最终兴趣的更新前后是没关系的,只取决于输入的注意力分数
|
||||
$$
|
||||
h_t^{'} = (1-a_t)h_{t-1}^{'} + a_t * \tilde{h_t^{'}}
|
||||
$$
|
||||
|
||||
3. **AUGRU:** 将注意力分数作为更新门的权重,这样既兼顾了注意力分数很低时的状态更新值,也利用了兴趣之间的相关性,最终的表达式如下:
|
||||
$$
|
||||
\begin{align}
|
||||
& \tilde{u_t^{'}} = a_t * u_t \\
|
||||
& h_t^{'} = (1-\tilde{u_t^{'}})h_{t-1}^{'} + \tilde{u_t^{'}} * \tilde{h_t^{'}}
|
||||
\end{align}
|
||||
$$
|
||||
|
||||
**建模兴趣演化过程的好处:**
|
||||
- 追踪用户的interest可以使我们学习final interest的表达时包含更多的历史信息
|
||||
- 可以根据interest的变化趋势更好地进行CTR预测
|
||||
|
||||
## 代码实现
|
||||
下面我们看下DIN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
|
||||
|
||||
这里主要和大家说一下DIN模型的总体运行逻辑,这样可以让大家从宏观的层面去把握模型的编写过程。该模型所使用的数据集是movielens数据集, 具体介绍可以参考后面的GitHub。 因为上面反复强调了DIN的应用场景,需要基于用户的历史行为数据, 所以在这个数据集中会有用户过去对电影评分的一系列行为。这在之前的数据集中往往是看不到的。 大家可以导入数据之后自行查看这种行为特征(hist_behavior)。另外还有一点需要说明的是这种历史行为是序列性质的特征, 并且**不同的用户这种历史行为特征长度会不一样**, 但是我们的神经网络是要求序列等长的,所以这种情况我们一般会按照最长的序列进行padding的操作(不够长的填0), 而到具体层上进行运算的时候,会用mask掩码的方式标记出这些填充的位置,好保证计算的准确性。 在我们给出的代码中,大家会在AttentionPoolingLayer层的前向传播中看到这种操作。下面开始说编写逻辑:
|
||||
|
||||
首先, DIN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型),也就是指的上面的历史行为数据。而不同的类型特征也就决定了后面处理的方式会不同:
|
||||
|
||||
* Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
|
||||
* Sparse型特征,为离散型特征建立Input层接收输入,然后需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进DNN, 但是这里面要注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。
|
||||
* VarlenSparse型特征:这个一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入AttentionPoolingLayer去对这些历史行为特征加权合并,最后得到输出。
|
||||
|
||||
通过上面的三种处理, 就得到了处理好的连续特征,离散特征和变长离散特征, 接下来把这三种特征拼接,进DNN网络,得到最后的输出结果即可。所以有了这个解释, 就可以放DIN模型的代码全貌了,大家可以感受下我上面解释的:
|
||||
|
||||
```python
|
||||
def DIEN(feature_columns, behavior_feature_list, behavior_seq_feature_list, neg_seq_feature_list, use_neg_sample=False, alpha=1.0):
|
||||
# 构建输入层
|
||||
input_layer_dict = build_input_layers(feature_columns)
|
||||
|
||||
# 将Input层转化为列表的形式作为model的输入
|
||||
input_layers = list(input_layer_dict.values()) # 各个输入层
|
||||
user_behavior_length = input_layer_dict["hist_len"]
|
||||
|
||||
# 筛选出特征中的sparse_fea, dense_fea, varlen_fea
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if feature_columns else []
|
||||
varlen_sparse_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 获取dense
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
dnn_dense_input.append(input_layer_dict[fc.name])
|
||||
|
||||
# 将所有的dense特征拼接
|
||||
dnn_dense_input = concat_input_list(dnn_dense_input)
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
|
||||
|
||||
# 因为这里最终需要将embedding拼接后直接输入到全连接层(Dense)中, 所以需要Flatten
|
||||
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
|
||||
# 将所有sparse特征的embedding进行拼接
|
||||
dnn_sparse_input = concat_input_list(dnn_sparse_embed_input)
|
||||
|
||||
# 获取当前的行为特征(movie)的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 获取行为序列(movie_id序列, hist_movie_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 把q,k的embedding拼在一块
|
||||
query_emb, keys_emb = concat_input_list(query_embed_list), concat_input_list(keys_embed_list)
|
||||
|
||||
# 采样的负行为
|
||||
neg_uiseq_embed_list = embedding_lookup(neg_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
neg_concat_behavior = concat_input_list(neg_uiseq_embed_list)
|
||||
|
||||
# 兴趣进化层的计算过程
|
||||
dnn_seq_input, aux_loss = interest_evolution(keys_emb, query_emb, user_behavior_length, neg_concat_behavior, gru_type="AUGRU")
|
||||
|
||||
# 后面的全连接层
|
||||
deep_input_embed = Concatenate()([dnn_dense_input, dnn_sparse_input, dnn_seq_input])
|
||||
|
||||
# 获取最终dnn的logits
|
||||
dnn_logits = get_dnn_logits(deep_input_embed, activation='prelu')
|
||||
model = Model(input_layers, dnn_logits)
|
||||
|
||||
# 加兴趣提取层的损失 这个比例可调
|
||||
if use_neg_sample:
|
||||
model.add_loss(alpha * aux_loss)
|
||||
|
||||
# 所有变量需要初始化
|
||||
tf.compat.v1.keras.backend.get_session().run(tf.compat.v1.global_variables_initializer())
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中(看不清的话可以自己用代码生成之后使用其他的软件打开看)。
|
||||
|
||||
> 下面这个图失效了
|
||||
<div align=center>
|
||||
<img src="C:\Users\ryl\Desktop\DW_Rec\组队学习内容\代码\imgs\DIEN.png" alt="image-20210218180755462" style="zoom:70%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
1. 对于知乎上大佬们对DIEN的探讨,你有什么看法呢?[也评Deep Interest Evolution Network](https://zhuanlan.zhihu.com/p/54838663)
|
||||
|
||||
|
||||
**参考资料**
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
- [原论文](https://arxiv.org/pdf/1809.03672.pdf)
|
||||
- [论文阅读-阿里DIEN深度兴趣进化网络之总体解读](https://mp.weixin.qq.com/s/IlVZCVtDco3hWuvnsUmekg)
|
||||
- [也评Deep Interest Evolution Network](https://zhuanlan.zhihu.com/p/54838663)
|
||||
|
||||
177
docs/推荐算法基础/经典排序模型/序列模型/DIN.md
Normal file
177
docs/推荐算法基础/经典排序模型/序列模型/DIN.md
Normal file
@@ -0,0 +1,177 @@
|
||||
# DIN
|
||||
## 动机
|
||||
Deep Interest Network(DIIN)是2018年阿里巴巴提出来的模型, 该模型基于业务的观察,从实际应用的角度进行改进,相比于之前很多“学术风”的深度模型, 该模型更加具有业务气息。该模型的应用场景是阿里巴巴的电商广告推荐业务, 这样的场景下一般**会有大量的用户历史行为信息**, 这个其实是很关键的,因为DIN模型的创新点或者解决的问题就是使用了注意力机制来对用户的兴趣动态模拟, 而这个模拟过程存在的前提就是用户之前有大量的历史行为了,这样我们在预测某个商品广告用户是否点击的时候,就可以参考他之前购买过或者查看过的商品,这样就能猜测出用户的大致兴趣来,这样我们的推荐才能做的更加到位,所以这个模型的使用场景是**非常注重用户的历史行为特征(历史购买过的商品或者类别信息)**,也希望通过这一点,能够和前面的一些深度学习模型对比一下。
|
||||
|
||||
在个性化的电商广告推荐业务场景中,也正式由于用户留下了大量的历史交互行为,才更加看出了之前的深度学习模型(作者统称Embeding&MLP模型)的不足之处。如果学习了前面的各种深度学习模型,就会发现Embeding&MLP模型对于这种推荐任务一般有着差不多的固定处理套路,就是大量稀疏特征先经过embedding层, 转成低维稠密的,然后进行拼接,最后喂入到多层神经网络中去。
|
||||
|
||||
这些模型在这种个性化广告点击预测任务中存在的问题就是**无法表达用户广泛的兴趣**,因为这些模型在得到各个特征的embedding之后,就蛮力拼接了,然后就各种交叉等。这时候根本没有考虑之前用户历史行为商品具体是什么,究竟用户历史行为中的哪个会对当前的点击预测带来积极的作用。 而实际上,对于用户点不点击当前的商品广告,很大程度上是依赖于他的历史行为的,王喆老师举了个例子
|
||||
|
||||
>假设广告中的商品是键盘, 如果用户历史点击的商品中有化妆品, 包包,衣服, 洗面奶等商品, 那么大概率上该用户可能是对键盘不感兴趣的, 而如果用户历史行为中的商品有鼠标, 电脑,iPad,手机等, 那么大概率该用户对键盘是感兴趣的, 而如果用户历史商品中有鼠标, 化妆品, T-shirt和洗面奶, 鼠标这个商品embedding对预测“键盘”广告的点击率的重要程度应该大于后面的那三个。
|
||||
|
||||
这里也就是说如果是之前的那些深度学习模型,是没法很好的去表达出用户这广泛多样的兴趣的,如果想表达的准确些, 那么就得加大隐向量的维度,让每个特征的信息更加丰富, 那这样带来的问题就是计算量上去了,毕竟真实情景尤其是电商广告推荐的场景,特征维度的规模是非常大的。 并且根据上面的例子, 也**并不是用户所有的历史行为特征都会对某个商品广告点击预测起到作用**。所以对于当前某个商品广告的点击预测任务,没必要考虑之前所有的用户历史行为。
|
||||
|
||||
这样, DIN的动机就出来了,在业务的角度,我们应该自适应的去捕捉用户的兴趣变化,这样才能较为准确的实施广告推荐;而放到模型的角度, 我们应该**考虑到用户的历史行为商品与当前商品广告的一个关联性**,如果用户历史商品中很多与当前商品关联,那么说明该商品可能符合用户的品味,就把该广告推荐给他。而一谈到关联性的话, 我们就容易想到“注意力”的思想了, 所以为了更好的从用户的历史行为中学习到与当前商品广告的关联性,学习到用户的兴趣变化, 作者把注意力引入到了模型,设计了一个"local activation unit"结构,利用候选商品和历史问题商品之间的相关性计算出权重,这个就代表了对于当前商品广告的预测,用户历史行为的各个商品的重要程度大小, 而加入了注意力权重的深度学习网络,就是这次的主角DIN, 下面具体来看下该模型。
|
||||
|
||||
## DIN模型结构及原理
|
||||
在具体分析DIN模型之前, 我们还得先介绍两块小内容,一个是DIN模型的数据集和特征表示, 一个是上面提到的之前深度学习模型的基线模型, 有了这两个, 再看DIN模型,就感觉是水到渠成了。
|
||||
|
||||
### 特征表示
|
||||
工业上的CTR预测数据集一般都是`multi-group categorial form`的形式,就是类别型特征最为常见,这种数据集一般长这样:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210118190044920.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" style="zoom: 67%;" />
|
||||
</div>
|
||||
|
||||
这里的亮点就是框出来的那个特征,这个包含着丰富的用户兴趣信息。
|
||||
|
||||
对于特征编码,作者这里举了个例子:`[weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book]`, 这种情况我们知道一般是通过one-hot的形式对其编码, 转成系数的二值特征的形式。但是这里我们会发现一个`visted_cate_ids`, 也就是用户的历史商品列表, 对于某个用户来讲,这个值是个多值型的特征, 而且还要知道这个特征的长度不一样长,也就是用户购买的历史商品个数不一样多,这个显然。这个特征的话,我们一般是用到multi-hot编码,也就是可能不止1个1了,有哪个商品,对应位置就是1, 所以经过编码后的数据长下面这个样子:
|
||||
<div align=center>
|
||||
<img src="https://img-blog.csdnimg.cn/20210118185933510.png" style="zoom:67%;" />
|
||||
</div>
|
||||
这个就是喂入模型的数据格式了,这里还要注意一点 就是上面的特征里面没有任何的交互组合,也就是没有做特征交叉。这个交互信息交给后面的神经网络去学习。
|
||||
|
||||
### 基线模型
|
||||
|
||||
这里的base 模型,就是上面提到过的Embedding&MLP的形式, 这个之所以要介绍,就是因为DIN网络的基准也是他,只不过在这个的基础上添加了一个新结构(注意力网络)来学习当前候选广告与用户历史行为特征的相关性,从而动态捕捉用户的兴趣。
|
||||
|
||||
基准模型的结构相对比较简单,我们前面也一直用这个基准, 分为三大模块:Embedding layer,Pooling & Concat layer和MLP, 结构如下:
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片3.png" style="zoom:80%;" />
|
||||
</div>
|
||||
|
||||
前面的大部分深度模型结构也是遵循着这个范式套路, 简介一下各个模块。
|
||||
|
||||
1. **Embedding layer**:这个层的作用是把高维稀疏的输入转成低维稠密向量, 每个离散特征下面都会对应着一个embedding词典, 维度是$D\times K$, 这里的$D$表示的是隐向量的维度, 而$K$表示的是当前离散特征的唯一取值个数, 这里为了好理解,这里举个例子说明,就比如上面的weekday特征:
|
||||
|
||||
> 假设某个用户的weekday特征就是周五,化成one-hot编码的时候,就是[0,0,0,0,1,0,0]表示,这里如果再假设隐向量维度是D, 那么这个特征对应的embedding词典是一个$D\times7$的一个矩阵(每一列代表一个embedding,7列正好7个embedding向量,对应周一到周日),那么该用户这个one-hot向量经过embedding层之后会得到一个$D\times1$的向量,也就是周五对应的那个embedding,怎么算的,其实就是$embedding矩阵* [0,0,0,0,1,0,0]^T$ 。其实也就是直接把embedding矩阵中one-hot向量为1的那个位置的embedding向量拿出来。 这样就得到了稀疏特征的稠密向量了。其他离散特征也是同理,只不过上面那个multi-hot编码的那个,会得到一个embedding向量的列表,因为他开始的那个multi-hot向量不止有一个是1,这样乘以embedding矩阵,就会得到一个列表了。通过这个层,上面的输入特征都可以拿到相应的稠密embedding向量了。
|
||||
|
||||
2. **pooling layer and Concat layer**: pooling层的作用是将用户的历史行为embedding这个最终变成一个定长的向量,因为每个用户历史购买的商品数是不一样的, 也就是每个用户multi-hot中1的个数不一致,这样经过embedding层,得到的用户历史行为embedding的个数不一样多,也就是上面的embedding列表$t_i$不一样长, 那么这样的话,每个用户的历史行为特征拼起来就不一样长了。 而后面如果加全连接网络的话,我们知道,他需要定长的特征输入。 所以往往用一个pooling layer先把用户历史行为embedding变成固定长度(统一长度),所以有了这个公式:
|
||||
$$
|
||||
e_i=pooling(e_{i1}, e_{i2}, ...e_{ik})
|
||||
$$
|
||||
这里的$e_{ij}$是用户历史行为的那些embedding。$e_i$就变成了定长的向量, 这里的$i$表示第$i$个历史特征组(是历史行为,比如历史的商品id,历史的商品类别id等), 这里的$k$表示对应历史特种组里面用户购买过的商品数量,也就是历史embedding的数量,看上面图里面的user behaviors系列,就是那个过程了。 Concat layer层的作用就是拼接了,就是把这所有的特征embedding向量,如果再有连续特征的话也算上,从特征维度拼接整合,作为MLP的输入。
|
||||
|
||||
3. **MLP**:这个就是普通的全连接,用了学习特征之间的各种交互。
|
||||
|
||||
4. **Loss**: 由于这里是点击率预测任务, 二分类的问题,所以这里的损失函数用的负的log对数似然:
|
||||
$$
|
||||
L=-\frac{1}{N} \sum_{(\boldsymbol{x}, y) \in \mathcal{S}}(y \log p(\boldsymbol{x})+(1-y) \log (1-p(\boldsymbol{x})))
|
||||
$$
|
||||
|
||||
这就是base 模型的全貌, 这里应该能看出这种模型的问题, 通过上面的图也能看出来, 用户的历史行为特征和当前的候选广告特征在全都拼起来给神经网络之前,是一点交互的过程都没有, 而拼起来之后给神经网络,虽然是有了交互了,但是原来的一些信息,比如,每个历史商品的信息会丢失了一部分,因为这个与当前候选广告商品交互的是池化后的历史特征embedding, 这个embedding是综合了所有的历史商品信息, 这个通过我们前面的分析,对于预测当前广告点击率,并不是所有历史商品都有用,综合所有的商品信息反而会增加一些噪声性的信息,可以联想上面举得那个键盘鼠标的例子,如果加上了各种洗面奶,衣服啥的反而会起到反作用。其次就是这样综合起来,已经没法再看出到底用户历史行为中的哪个商品与当前商品比较相关,也就是丢失了历史行为中各个商品对当前预测的重要性程度。最后一点就是如果所有用户浏览过的历史行为商品,最后都通过embedding和pooling转换成了固定长度的embedding,这样会限制模型学习用户的多样化兴趣。
|
||||
|
||||
那么改进这个问题的思路有哪些呢? 第一个就是加大embedding的维度,增加之前各个商品的表达能力,这样即使综合起来,embedding的表达能力也会加强, 能够蕴涵用户的兴趣信息,但是这个在大规模的真实推荐场景计算量超级大,不可取。 另外一个思路就是**在当前候选广告和用户的历史行为之间引入注意力的机制**,这样在预测当前广告是否点击的时候,让模型更关注于与当前广告相关的那些用户历史产品,也就是说**与当前商品更加相关的历史行为更能促进用户的点击行为**。 作者这里又举了之前的一个例子:
|
||||
> 想象一下,当一个年轻母亲访问电子商务网站时,她发现展示的新手袋很可爱,就点击它。让我们来分析一下点击行为的驱动力。<br><br>展示的广告通过软搜索这位年轻母亲的历史行为,发现她最近曾浏览过类似的商品,如大手提袋和皮包,从而击中了她的相关兴趣
|
||||
|
||||
第二个思路就是DIN的改进之处了。DIN通过给定一个候选广告,然后去注意与该广告相关的局部兴趣的表示来模拟此过程。 DIN不会通过使用同一向量来表达所有用户的不同兴趣,而是通过考虑历史行为的相关性来自适应地计算用户兴趣的表示向量(对于给的广告)。 该表示向量随不同广告而变化。下面看一下DIN模型。
|
||||
|
||||
### DIN模型架构
|
||||
|
||||
上面分析完了base模型的不足和改进思路之后,DIN模型的结构就呼之欲出了,首先,它依然是采用了基模型的结构,只不过是在这个的基础上加了一个注意力机制来学习用户兴趣与当前候选广告间的关联程度, 用论文里面的话是,引入了一个新的`local activation unit`, 这个东西用在了用户历史行为特征上面, **能够根据用户历史行为特征和当前广告的相关性给用户历史行为特征embedding进行加权**。我们先看一下它的结构,然后看一下这个加权公式。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片4.png" style="zoom: 80%;" />
|
||||
</div>
|
||||
|
||||
这里改进的地方已经框出来了,这里会发现相比于base model, 这里加了一个local activation unit, 这里面是一个前馈神经网络,输入是用户历史行为商品和当前的候选商品, 输出是它俩之间的相关性, 这个相关性相当于每个历史商品的权重,把这个权重与原来的历史行为embedding相乘求和就得到了用户的兴趣表示$\boldsymbol{v}_{U}(A)$, 这个东西的计算公式如下:
|
||||
$$
|
||||
\boldsymbol{v}_{U}(A)=f\left(\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\right)=\sum_{j=1}^{H} a\left(\boldsymbol{e}_{j}, \boldsymbol{v}_{A}\right) \boldsymbol{e}_{j}=\sum_{j=1}^{H} \boldsymbol{w}_{j} \boldsymbol{e}_{j}
|
||||
$$
|
||||
这里的$\{\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\}$是用户$U$的历史行为特征embedding, $v_{A}$表示的是候选广告$A$的embedding向量, $a(e_j, v_A)=w_j$表示的权重或者历史行为商品与当前广告$A$的相关性程度。$a(\cdot)$表示的上面那个前馈神经网络,也就是那个所谓的注意力机制, 当然,看图里的话,输入除了历史行为向量和候选广告向量外,还加了一个它俩的外积操作,作者说这里是有利于模型相关性建模的显性知识。
|
||||
|
||||
这里有一点需要特别注意,就是这里的权重加和不是1, 准确的说这里不是权重, 而是直接算的相关性的那种分数作为了权重,也就是平时的那种scores(softmax之前的那个值),这个是为了保留用户的兴趣强度。
|
||||
|
||||
## DIN实现
|
||||
|
||||
下面我们看下DIN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
|
||||
|
||||
这里主要和大家说一下DIN模型的总体运行逻辑,这样可以让大家从宏观的层面去把握模型的编写过程。该模型所使用的数据集是movielens数据集, 具体介绍可以参考后面的GitHub。 因为上面反复强调了DIN的应用场景,需要基于用户的历史行为数据, 所以在这个数据集中会有用户过去对电影评分的一系列行为。这在之前的数据集中往往是看不到的。 大家可以导入数据之后自行查看这种行为特征(hist_behavior)。另外还有一点需要说明的是这种历史行为是序列性质的特征, 并且**不同的用户这种历史行为特征长度会不一样**, 但是我们的神经网络是要求序列等长的,所以这种情况我们一般会按照最长的序列进行padding的操作(不够长的填0), 而到具体层上进行运算的时候,会用mask掩码的方式标记出这些填充的位置,好保证计算的准确性。 在我们给出的代码中,大家会在AttentionPoolingLayer层的前向传播中看到这种操作。下面开始说编写逻辑:
|
||||
|
||||
首先, DIN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型),也就是指的上面的历史行为数据。而不同的类型特征也就决定了后面处理的方式会不同:
|
||||
|
||||
* Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
|
||||
* Sparse型特征,为离散型特征建立Input层接收输入,然后需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进DNN, 但是这里面要注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。
|
||||
* VarlenSparse型特征:这个一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入AttentionPoolingLayer去对这些历史行为特征加权合并,最后得到输出。
|
||||
|
||||
通过上面的三种处理, 就得到了处理好的连续特征,离散特征和变长离散特征, 接下来把这三种特征拼接,进DNN网络,得到最后的输出结果即可。所以有了这个解释, 就可以放DIN模型的代码全貌了,大家可以感受下我上面解释的:
|
||||
|
||||
```python
|
||||
# DIN网络搭建
|
||||
def DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list):
|
||||
"""
|
||||
这里搭建DIN网络,有了上面的各个模块,这里直接拼起来
|
||||
:param feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是数据的特征封装版
|
||||
:param behavior_feature_list: A list. 用户的候选行为列表
|
||||
:param behavior_seq_feature_list: A list. 用户的历史行为列表
|
||||
"""
|
||||
# 构建Input层并将Input层转成列表作为模型的输入
|
||||
input_layer_dict = build_input_layers(feature_columns)
|
||||
input_layers = list(input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse和Dense特征, 后面要单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns))
|
||||
|
||||
# 获取Dense Input
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
dnn_dense_input.append(input_layer_dict[fc.name])
|
||||
|
||||
# 将所有的dense特征拼接
|
||||
dnn_dense_input = concat_input_list(dnn_dense_input) # (None, dense_fea_nums)
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
|
||||
|
||||
# 离散的这些特特征embedding之后,然后拼接,然后直接作为全连接层Dense的输入,所以需要进行Flatten
|
||||
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
# 将所有的sparse特征embedding特征拼接
|
||||
dnn_sparse_input = concat_input_list(dnn_sparse_embed_input) # (None, sparse_fea_nums*embed_dim)
|
||||
|
||||
# 获取当前行为特征的embedding, 这里有可能有多个行为产生了行为列表,所以需要列表将其放在一起
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 获取历史行为的embedding, 这里有可能有多个行为产生了行为列表,所以需要列表将其放在一起
|
||||
keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 使用注意力机制将历史行为的序列池化,得到用户的兴趣
|
||||
dnn_seq_input_list = []
|
||||
for i in range(len(keys_embed_list)):
|
||||
seq_embed = AttentionPoolingLayer()([query_embed_list[i], keys_embed_list[i]]) # (None, embed_dim)
|
||||
dnn_seq_input_list.append(seq_embed)
|
||||
|
||||
# 将多个行为序列的embedding进行拼接
|
||||
dnn_seq_input = concat_input_list(dnn_seq_input_list) # (None, hist_len*embed_dim)
|
||||
|
||||
# 将dense特征,sparse特征, 即通过注意力机制加权的序列特征拼接起来
|
||||
dnn_input = Concatenate(axis=1)([dnn_dense_input, dnn_sparse_input, dnn_seq_input]) # (None, dense_fea_num+sparse_fea_nums*embed_dim+hist_len*embed_dim)
|
||||
|
||||
# 获取最终的DNN的预测值
|
||||
dnn_logits = get_dnn_logits(dnn_input, activation='prelu')
|
||||
|
||||
model = Model(inputs=input_layers, outputs=dnn_logits)
|
||||
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片DIN_aaaa.png" alt="DIN_aaaa" style="zoom: 70%;" />
|
||||
</div>
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片din.png" alt="DIN_aaaa" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
DIN模型在工业上的应用还是比较广泛的, 大家可以自由去通过查资料看一下具体实践当中这个模型是怎么用的? 有什么问题?比如行为序列的制作是否合理, 如果时间间隔比较长的话应不应该分一下段? 再比如注意力机制那里能不能改成别的计算注意力的方式会好点?(我们也知道注意力机制的方式可不仅DNN这一种), 再比如注意力权重那里该不该加softmax? 这些其实都是可以值的思考探索的一些问题,根据实际的业务场景,大家也可以总结一些更加有意思的工业上应用该模型的技巧和tricks,欢迎一块讨论和分享。
|
||||
|
||||
**参考资料**
|
||||
* [DIN原论文](https://arxiv.org/pdf/1706.06978.pdf)
|
||||
* [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
* [AI上推荐 之 AFM与DIN模型(当推荐系统遇上了注意力机制)](https://blog.csdn.net/wuzhongqiang/article/details/109532346)
|
||||
* 王喆 - 《深度学习推荐系统》
|
||||
1
docs/推荐算法基础/经典排序模型/序列模型/readme.md
Normal file
1
docs/推荐算法基础/经典排序模型/序列模型/readme.md
Normal file
@@ -0,0 +1 @@
|
||||
# README
|
||||
155
docs/推荐算法基础/经典排序模型/特征交叉/DCN.md
Normal file
155
docs/推荐算法基础/经典排序模型/特征交叉/DCN.md
Normal file
@@ -0,0 +1,155 @@
|
||||
# DCN
|
||||
## 动机
|
||||
Wide&Deep模型的提出不仅综合了“记忆能力”和“泛化能力”, 而且开启了不同网络结构融合的新思路。 所以后面就有各式各样的模型改进Wide部分或者Deep部分, 而Deep&Cross模型(DCN)就是其中比较典型的一个,这是2017年斯坦福大学和谷歌的研究人员在ADKDD会议上提出的, 该模型针对W&D的wide部分进行了改进, 因为Wide部分有一个不足就是需要人工进行特征的组合筛选, 过程繁琐且需要经验, 而2阶的FM模型在线性的时间复杂度中自动进行特征交互,但是这些特征交互的表现能力并不够,并且随着阶数的上升,模型复杂度会大幅度提高。于是乎,作者用一个Cross Network替换掉了Wide部分,来自动进行特征之间的交叉,并且网络的时间和空间复杂度都是线性的。 通过与Deep部分相结合,构成了深度交叉网络(Deep & Cross Network),简称DCN。
|
||||
|
||||
## 模型结构及原理
|
||||
|
||||
这个模型的结构是这个样子的:
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片dcn.png" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
这个模型的结构也是比较简洁的, 从下到上依次为:Embedding和Stacking层, Cross网络层与Deep网络层并列, 以及最后的输出层。下面也是一一为大家剖析。
|
||||
|
||||
### Embedding和Stacking 层
|
||||
|
||||
Embedding层我们已经非常的熟悉了吧, 这里的作用依然是把稀疏离散的类别型特征变成低维密集型。
|
||||
$$
|
||||
\mathbf{x}_{\text {embed, } i}=W_{\text {embed, } i} \mathbf{x}_{i}
|
||||
$$
|
||||
其中对于某一类稀疏分类特征(如id),$X_{embed, i}$是第个$i$分类值(id序号)的embedding向量。$W_{embed,i}$是embedding矩阵, $n_e\times n_v$维度, $n_e$是embedding维度, $n_v$是该类特征的唯一取值个数。$x_i$属于该特征的二元稀疏向量(one-hot)编码的。 【实质上就是在训练得到的Embedding参数矩阵中找到属于当前样本对应的Embedding向量】。其实绝大多数基于深度学习的推荐模型都需要Embedding操作,参数学习是通过神经网络进行训练。
|
||||
|
||||
最后,该层需要将所有的密集型特征与通过embedding转换后的特征进行联合(Stacking):
|
||||
$$
|
||||
\mathbf{x}_{0}=\left[\mathbf{x}_{\text {embed, } 1}^{T}, \ldots, \mathbf{x}_{\text {embed, }, k}^{T}, \mathbf{x}_{\text {dense }}^{T}\right]
|
||||
$$
|
||||
一共$k$个类别特征, dense是数值型特征, 两者在特征维度拼在一块。 上面的这两个操作如果是看了前面的模型的话,应该非常容易理解了。
|
||||
|
||||
### Cross Network
|
||||
|
||||
这个就是本模型最大的亮点了【Cross网络】, 这个思路感觉非常Nice。设计该网络的目的是增加特征之间的交互力度。交叉网络由多个交叉层组成, 假设第$l$层的输出向量$x_l$, 那么对于第$l+1$层的输出向量$x_{l+1}$表示为:
|
||||
|
||||
$$
|
||||
\mathbf{x}_{l+1}=\mathbf{x}_{0} \mathbf{x}_{l}^{T} \mathbf{w}_{l}+\mathbf{b}_{l}+\mathbf{x}_{l}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l}
|
||||
$$
|
||||
可以看到, 交叉层的二阶部分非常类似PNN提到的外积操作, 在此基础上增加了外积操作的权重向量$w_l$, 以及原输入向量$x_l$和偏置向量$b_l$。 交叉层的可视化如下:
|
||||
|
||||
<div align=center> <img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片cross.png" style="zoom:67%;" />
|
||||
</div>
|
||||
|
||||
可以看到, 每一层增加了一个$n$维的权重向量$w_l$(n表示输入向量维度), 并且在每一层均保留了输入向量, 因此输入和输出之间的变化不会特别明显。关于这一层, 原论文里面有个具体的证明推导Cross Network为啥有效, 不过比较复杂,这里我拿一个式子简单的解释下上面这个公式的伟大之处:
|
||||
|
||||
> **我们根据上面这个公式, 尝试的写前面几层看看:**
|
||||
>
|
||||
> $l=0:\mathbf{x}_{1} =\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}$
|
||||
>
|
||||
> $l=1:\mathbf{x}_{2} =\mathbf{x}_{0} \mathbf{x}_{1}^{T} \mathbf{w}_{1}+ \mathbf{b}_{1}+\mathbf{x}_{1}=\mathbf{x}_{0} [\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}]^{T}\mathbf{w}_{1}+\mathbf{b}_{1}+\mathbf{x}_{1}$
|
||||
>
|
||||
> $l=2:\mathbf{x}_{3} =\mathbf{x}_{0} \mathbf{x}_{2}^{T} \mathbf{w}_{2}+ \mathbf{b}_{2}+\mathbf{x}_{2}=\mathbf{x}_{0} [\mathbf{x}_{0} [\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}]^{T}\mathbf{w}_{1}+\mathbf{b}_{1}+\mathbf{x}_{1}]^{T}\mathbf{w}_{2}+\mathbf{b}_{2}+\mathbf{x}_{2}$
|
||||
|
||||
我们暂且写到第3层的计算, 我们会发现什么结论呢? 给大家总结一下:
|
||||
|
||||
1. $\mathrm{x}_1$中包含了所有的$\mathrm{x}_0$的1,2阶特征的交互, $\mathrm{x}_2$包含了所有的$\mathrm{x}_1, \mathrm{x}_0$的1、2、3阶特征的交互,$\mathrm{x}_3$中包含了所有的$\mathrm{x}_2$, $\mathrm{x}_1$与$\mathrm{x}_0$的交互,$\mathrm{x}_0$的1、2、3、4阶特征交互。 因此, 交叉网络层的叉乘阶数是有限的。 **第$l$层特征对应的最高的叉乘阶数$l+1$**
|
||||
|
||||
2. Cross网络的参数是共享的, 每一层的这个权重特征之间共享, 这个可以使得模型泛化到看不见的特征交互作用, 并且对噪声更具有鲁棒性。 例如两个稀疏的特征$x_i,x_j$, 它们在数据中几乎不发生交互, 那么学习$x_i,x_j$的权重对于预测没有任何的意义。
|
||||
|
||||
3. 计算交叉网络的参数数量。 假设交叉层的数量是$L_c$, 特征$x$的维度是$n$, 那么总共的参数是:
|
||||
|
||||
$$
|
||||
n\times L_c \times 2
|
||||
$$
|
||||
这个就是每一层会有$w$和$b$。且$w$维度和$x$的维度是一致的。
|
||||
|
||||
4. 交叉网络的时间和空间复杂度是线性的。这是因为, 每一层都只有$w$和$b$, 没有激活函数的存在,相对于深度学习网络, 交叉网络的复杂性可以忽略不计。
|
||||
|
||||
5. Cross网络是FM的泛化形式, 在FM模型中, 特征$x_i$的权重$v_i$, 那么交叉项$x_i,x_j$的权重为$<x_i,x_j>$。在DCN中, $x_i$的权重为${W_K^{(i)}}_{k=1}^l$, 交叉项$x_i,x_j$的权重是参数${W_K^{(i)}}_{k=1}^l$和${W_K^{(j)}}_{k=1}^l$的乘积,这个看上面那个例子展开感受下。因此两个模型都各自学习了独立于其他特征的一些参数,并且交叉项的权重是相应参数的某种组合。FM只局限于2阶的特征交叉(一般),而DCN可以构建更高阶的特征交互, 阶数由网络深度决定,并且交叉网络的参数只依据输入的维度线性增长。
|
||||
|
||||
6. 还有一点我们也要了解,对于每一层的计算中, 都会跟着$\mathrm{x}_0$, 这个是咱们的原始输入, 之所以会乘以一个这个,是为了保证后面不管怎么交叉,都不能偏离我们的原始输入太远,别最后交叉交叉都跑偏了。
|
||||
|
||||
7. $\mathbf{x}_{l+1}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l}$, 这个东西其实有点跳远连接的意思,也就是和ResNet也有点相似,无形之中还能有效的缓解梯度消失现象。
|
||||
|
||||
好了, 关于本模型的交叉网络的细节就介绍到这里了。这应该也是本模型的精华之处了,后面就简单了。
|
||||
|
||||
### Deep Network
|
||||
|
||||
这个就和上面的D&W的全连接层原理一样。这里不再过多的赘述。
|
||||
$$
|
||||
\mathbf{h}_{l+1}=f\left(W_{l} \mathbf{h}_{l}+\mathbf{b}_{l}\right)
|
||||
$$
|
||||
具体的可以参考W&D模型。
|
||||
|
||||
### 组合输出层
|
||||
|
||||
这个层负责将两个网络的输出进行拼接, 并且通过简单的Logistics回归完成最后的预测:
|
||||
$$
|
||||
p=\sigma\left(\left[\mathbf{x}_{L_{1}}^{T}, \mathbf{h}_{L_{2}}^{T}\right] \mathbf{w}_{\text {logits }}\right)
|
||||
$$
|
||||
其中$\mathbf{x}_{L_{1}}^{T}$和$\mathbf{h}_{L_{2}}^{T}$分别表示交叉网络和深度网络的输出。
|
||||
最后二分类的损失函数依然是交叉熵损失:
|
||||
$$
|
||||
\text { loss }=-\frac{1}{N} \sum_{i=1}^{N} y_{i} \log \left(p_{i}\right)+\left(1-y_{i}\right) \log \left(1-p_{i}\right)+\lambda \sum_{l}\left\|\mathbf{w}_{i}\right\|^{2}
|
||||
$$
|
||||
|
||||
Cross&Deep模型的原理就是这些了,其核心部分就是Cross Network, 这个可以进行特征的自动交叉, 避免了更多基于业务理解的人工特征组合。 该模型相比于W&D,Cross部分表达能力更强, 使得模型具备了更强的非线性学习能力。
|
||||
|
||||
## 代码实现
|
||||
|
||||
下面我们看下DCN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。
|
||||
|
||||
从上面的结构图我们也可以看出, DCN的模型搭建,其实主要分为几大模块, 首先就是建立输入层,用到的函数式`build_input_layers`,有了输入层之后, 我们接下来是embedding层的搭建,用到的函数是`build_embedding_layers`, 这个层的作用是接收离散特征,变成低维稠密。 接下来就是把连续特征和embedding之后的离散特征进行拼接,分别进入wide端和deep端。 wide端就是交叉网络,而deep端是DNN网络, 这里分别是`CrossNet()`和`get_dnn_output()`, 接下来就是把这两块的输出拼接得到最后的输出了。所以整体代码如下:
|
||||
|
||||
```python
|
||||
def DCN(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns)) if linear_feature_columns else []
|
||||
|
||||
sparse_kd_embed = concat_embedding_list(sparse_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed)
|
||||
|
||||
dnn_input = Concatenate(axis=1)([concat_dense_inputs, concat_sparse_kd_embed])
|
||||
|
||||
dnn_output = get_dnn_output(dnn_input)
|
||||
|
||||
cross_output = CrossNet()(dnn_input)
|
||||
|
||||
# stack layer
|
||||
stack_output = Concatenate(axis=1)([dnn_output, cross_output])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layer = Dense(1, activation='sigmoid')(stack_output)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
这个模型的实现过程和DeepFM比较类似,这里不画草图了,如果想看的可以去参考DeepFM草图及代码之间的对应关系。
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
<div align=center> <img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片DCN.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
</div>
|
||||
|
||||
## 思考
|
||||
|
||||
1. 请计算Cross Network的复杂度,需要的变量请自己定义。
|
||||
2. 在实现矩阵计算$x_0*x_l^Tw$的过程中,有人说要先算前两个,有人说要先算后两个,请问那种方式更好?为什么?
|
||||
|
||||
**参考资料**
|
||||
* 《深度学习推荐系统》 --- 王喆
|
||||
* [Deep&Cross模型原论文](https://arxiv.org/abs/1708.05123)
|
||||
* [AI上推荐 之 Wide&Deep与Deep&Cross模型(记忆与泛化并存的华丽转身)]()
|
||||
* [Wide&Deep模型的进阶---Cross&Deep模型](https://mp.weixin.qq.com/s/DkoaMaXhlgQv1NhZHF-7og)
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user