推荐系统实践(新闻推荐)
数据下载
链接:https://pan.baidu.com/s/15ReHXSM6VlQP-usia0DgYw 提取码:135r
基本信息
- 学习周期:15天
- 学习形式:理论学习+练习
- 人群定位:有一定的数据分析基础,了解推荐系统基本算法,了解机器学习算法流程
- 先修内容:Python编程语言;编程实践(Pandas);编程实践(Numpy);推荐系统基础。
- 难度系数:中
学习目标
熟悉推荐系统竞赛的基本流程
- 掌握数据分析方法
- 了解多路召回策略
- 了解冷启动策略
- 了解排序特征的构造方法
- 了解常见的排序模型
- 了解模型融合
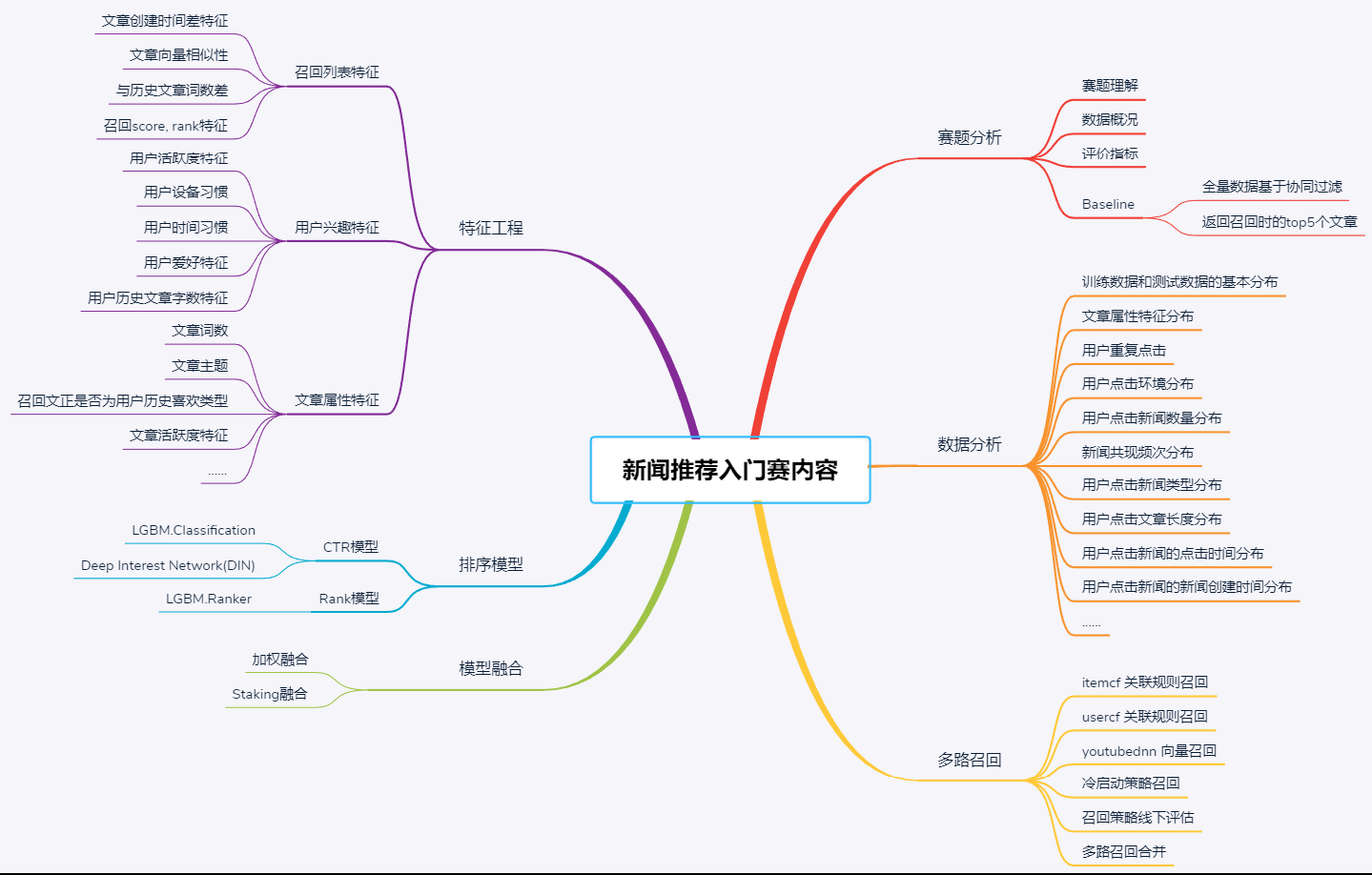
新闻推荐入门赛学习内容汇总:
任务安排
Task00:熟悉规则(1天)
- 组队、修改群昵称
- 熟悉打开规则
Task01:赛题理解+Baseline(3天)
- 理解赛题数据和目标,理解评分指标,了解赛题的解题思路
- 完成赛题报名和数据下载,跑通Baseline并成功提交结果
Task02:数据分析(2天)
- 了解数据中不同文件所包含的信息,不同数据文件之间的关系
- 分析点击数据中用户的点击环境、点击偏好,点击的文章属性等分布
- 分析点击数据中文章的基本属性,文章的热门程度,文章的共现情况等
- 分析文章属性文件中(embedding文件和属性特征文件),文章的基本信息
Task03:多路召回(3天)
- 熟悉常见的召回策略,如:itemcf, usercf以及深度模型召回等
- 了解当前场景下的冷启动问题,及常见解决策略,了解如何将多路召回的结果进行合并
- 完成多种策略的召回,冷启动及多路召回合并
- 完成召回策略的调参和召回效果的评估
Task04:特征工程(3天)
- 了解排序数据标签的构建,训练数据的负采样,排序特征的常用构造思路
- 完成用户召回文章与历史文章相关性的特征构造
- 完成用户历史兴趣的相关特征的提取,文章本身属性特征的提取
Task05:排序模型+模型融合(3天)
- 了解基本的排序模型,模型的训练和测试,常用的模型融合策略
- 完成LGB分类模型,LGB排序模型,及深度模型中的DIN模型的训练、验证及调参
- 完成加权融合与Staking融合两种融合策略
关于Datawhale
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale 以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。 本次数据挖掘路径学习,专题知识将在天池分享,详情可关注Datawhale(二维码在上面)
其他组队学习
有关组队学习的开源内容
- team-learning:主要展示Datawhale的组队学习计划。
- team-learning-program:主要存储Datawhale组队学习中“编程、数据结构与算法”方向的资料。
- team-learning-data-mining:主要存储Datawhale组队学习中“数据挖掘/机器学习”方向的资料。
- team-learning-nlp:主要存储Datawhale组队学习中“自然语言处理”方向的资料。
- team-learning-cv:主要存储Datawhale组队学习中“计算机视觉”方向的资料。
- team-learning-rs:主要存储Datawhale组队学习中“推荐系统”方向的资料。
- team-learning-rl:主要存储Datawhale组队学习中“强化学习”方向的资料。