diff --git a/docs/README.md b/docs/README.md
index d23e8eb5..edd38f90 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -45,7 +45,7 @@
- MOBIUS
- **图召回**
- [EGES](ch02/ch2.1/ch2.1.3/EGES)
- - PinSAGE
+ - [PinSAGE](ch02/ch2.1/ch2.1.3/PinSage)
- **序列召回**
- [MIND](ch02/ch2.1/ch2.1.4/MIND)
- [SDM](ch02/ch2.1/ch2.1.4/SDM)
@@ -76,7 +76,7 @@
- **多任务学习**
- SharedBottom
- ESSM
- - MMOE
+ - [MMOE](ch02/ch2.2/ch2.2.5/MMOE)
- PLE
### 推荐系统实战
diff --git a/docs/_sidebar.md b/docs/_sidebar.md
index 4aa1a2a7..ce94aeb1 100644
--- a/docs/_sidebar.md
+++ b/docs/_sidebar.md
@@ -25,7 +25,7 @@
- MOBIUS
- 2.1.3 基于图的召回
- [EGES](ch02/ch2.1/ch2.1.3/EGES)
- - PinSAGE
+ - [PinSAGE](ch02/ch2.1/ch2.1.3/PinSage)
- 2.1.4 基于序列的召回
- [MIND](ch02/ch2.1/ch2.1.4/MIND)
- [SDM](ch02/ch2.1/ch2.1.4/SDM)
@@ -53,7 +53,7 @@
- 2.2.5 多任务学习
- SharedBottom
- ESSM
- - MMOE
+ - [MMOE](ch02/ch2.2/ch2.2.5/MMOE)
- PLE
- 第三章 推荐系统实战
- 3.1 天池入门赛-新闻推荐
diff --git a/docs/ch02/ch2.2/ch2.2.5/MMOE.md b/docs/ch02/ch2.2/ch2.2.5/MMOE.md
index 5c8a81de..48f57a9a 100644
--- a/docs/ch02/ch2.2/ch2.2.5/MMOE.md
+++ b/docs/ch02/ch2.2/ch2.2.5/MMOE.md
@@ -1,21 +1,16 @@
-## 1. 写在前面
+## 写在前面
MMOE是2018年谷歌提出的,全称是Multi-gate Mixture-of-Experts, 对于多个优化任务,引入了多个专家进行不同的决策和组合,最终完成多目标的预测。解决的是硬共享里面如果多个任务相似性不是很强,底层的embedding学习反而相互影响,最终都学不好的痛点。
本篇文章首先是先了解下Hard-parameter sharing以及存在的问题,然后引出MMOE,对理论部分进行整理,最后是参考deepctr简单复现。
-**主要内容**:
-* 背景与动机
-* MMOE模型的理论
-* MMOE模型代码复现
-* 小总
-
-## 2. 背景与动机
+## 背景与动机
推荐系统中,即使同一个场景,常常也不只有一个业务目标。 在Youtube的视频推荐中,推荐排序任务不仅需要考虑到用户点击率,完播率,也需要考虑到一些满意度指标,例如,对视频是否喜欢,用户观看后对视频的评分;在淘宝的信息流商品推荐中,需要考虑到点击率,也需要考虑转化率;而在一些内容场景中,需要考虑到点击和互动、关注、停留时长等指标。
模型中,如果采用一个网络同时完成多个任务,就可以把这样的网络模型称为多任务模型, 这种模型能在不同任务之间学习共性以及差异性,能够提高建模的质量以及效率。 常见的多任务模型的设计范式大致可以分为三大类:
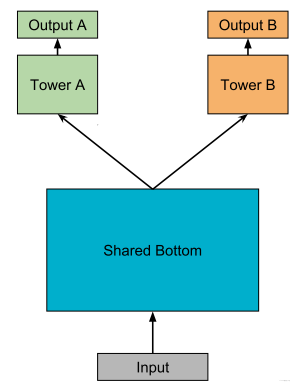
* hard parameter sharing 方法: 这是非常经典的一种方式,底层是共享的隐藏层,学习各个任务的共同模式,上层用一些特定的全连接层学习特定任务模式。
-
- 
+
+

+
+

+