diff --git a/docs/推荐算法基础/经典排序模型/序列模型/DIEN.md b/docs/推荐算法基础/经典排序模型/序列模型/DIEN.md
index 808e8593..37a21e71 100644
--- a/docs/推荐算法基础/经典排序模型/序列模型/DIEN.md
+++ b/docs/推荐算法基础/经典排序模型/序列模型/DIEN.md
@@ -5,8 +5,9 @@
DIN模型考虑了用户兴趣,并且强调用户兴趣是多样的,该模型使用注意力机制来捕捉和**target item**的相关的兴趣,这样以来用户的兴趣就会随着目标商品自适应的改变。但是大多该类模型包括DIN在内,直接将用户的行为当做用户的兴趣(因为DIN模型只是在行为序列上做了简单的特征处理),但是用户潜在兴趣一般很难直接通过用户的行为直接表示,大多模型都没有挖掘用户行为背后真实的兴趣,捕捉用户兴趣的动态变化对用户兴趣的表示非常重要。DIEN相比于之前的模型,即对用户的兴趣进行建模,又对建模出来的用户兴趣继续建模得到用户的兴趣变化过程。
## DIEN模型原理
-
+
+
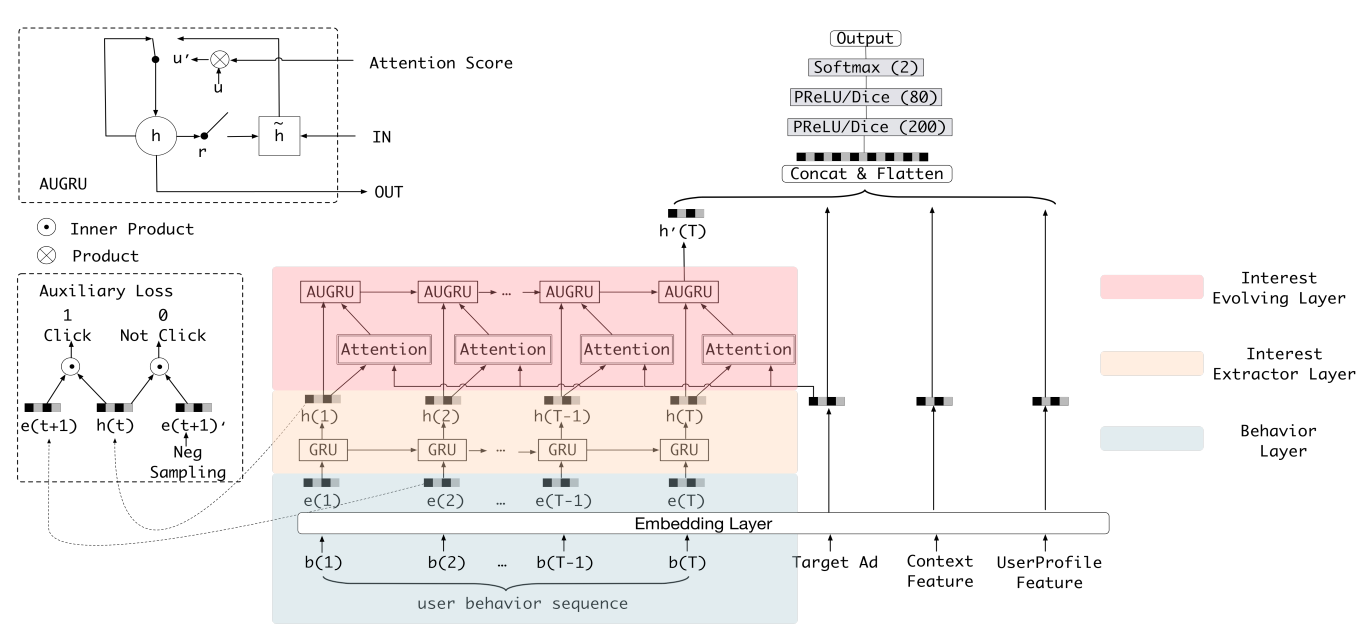
模型的输入可以分成两大部分,一部分是用户的行为序列(这部分会通过兴趣提取层及兴趣演化层转换成与用户当前兴趣相关的embedding),另一部分就是除了用户行为以外的其他所有特征,如Target id, Coontext Feature, UserProfile Feature,这些特征都转化成embedding的类型然后concat在一起(形成一个大的embedding)作为非行为相关的特征(这里可能也会存在一些非id类特征,应该可以直接进行concat)。最后DNN输入的部分由行为序列embedding和非行为特征embedding(多个特征concat到一起之后形成的一个大的向量)组成,将两者concat之后输入到DNN中。
@@ -19,15 +20,17 @@ DIN模型考虑了用户兴趣,并且强调用户兴趣是多样的,该模
作者并没有直接完全使用原始的GRU来提取用户的兴趣,而是引入了一个辅助函数来指导用户兴趣的提取。作者认为如果直接使用GRU提取用户的兴趣,只能得到用户行为之间的依赖关系,不能有效的表示用户的兴趣。因为是用户的兴趣导致了用户的点击,用户的最后一次点击与用户点击之前的兴趣相关性就很强,但是直接使用行为序列训练GRU的话,只有用户最后一次点击的物品(也就是label,在这里可以认为是Target Ad), 那么最多就是能够捕捉到用户最后一次点击时的兴趣,而最后一次的兴趣又和前面点击过的物品在兴趣上是相关的,而前面点击的物品中并没有target item进行监督。**所以作者提出的辅助损失就是为了让行为序列中的每一个时刻都有一个target item进行监督训练,也就是使用下一个行为来监督兴趣状态的学习**
**辅助损失**
-
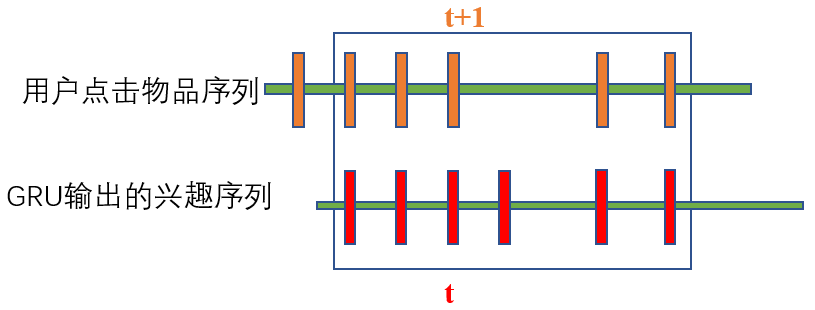
首先需要明确的就是辅助损失是计算哪两个量的损失。计算的是用户每个时刻的兴趣表示(GRU每个时刻输出的隐藏状态形成的序列)与用户当前时刻实际点击的物品表示(输入的embedding序列)之间的损失,相当于是行为序列中的第t+1个物品与用户第t时刻的兴趣表示之间的损失**(为什么这里用户第t时刻的兴趣与第t+1时刻的真实点击做损失呢?我的理解是,只有知道了用户第t+1真实点击的商品,才能更好的确定用户第t时刻的兴趣)。**
+
+
当然,如果只计算用户点击物品与其点击前一次的兴趣之间的损失,只能认为是正样本之间的损失,那么用户第t时刻的兴趣其实还有很多其他的未点击的商品,这些未点击的商品就是负样本,负样本一般通过从用户点击序列中采样得到,这样一来辅助损失中就包含了用户某个时刻下的兴趣及与该时刻兴趣相关的正负物品。所以最终的损失函数表示如下。
+
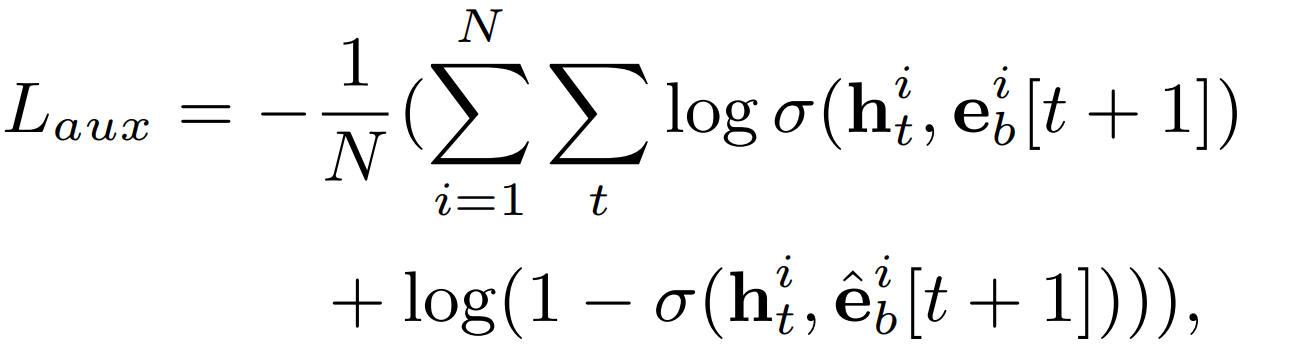
-
+
其中$h_t^i$表示的是用户$i$第$t$时刻的隐藏状态,可以表示用户第$t$时刻的兴趣向量,$e_b^i,\hat{e_b^i}$分别表示的是正负样本,$e_b^i[t+1]$表示的是用户$i$第$t+1$时刻点击的物品向量。
辅助损失会加到最终的目标损失(ctr损失)中一起进行优化,并且通过$\alpha$参数来平衡点击率和兴趣的关系
@@ -52,7 +55,9 @@ $$
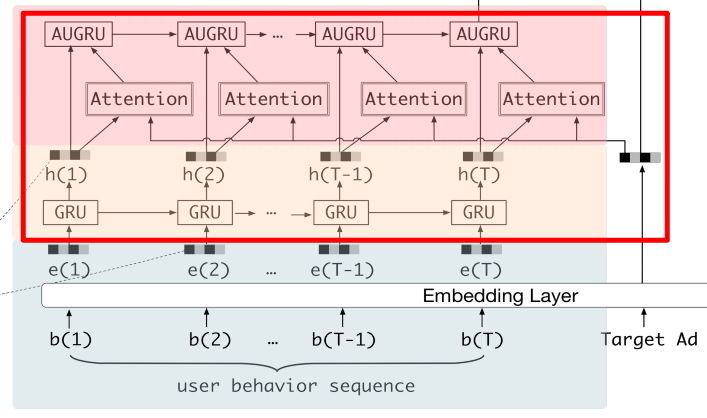
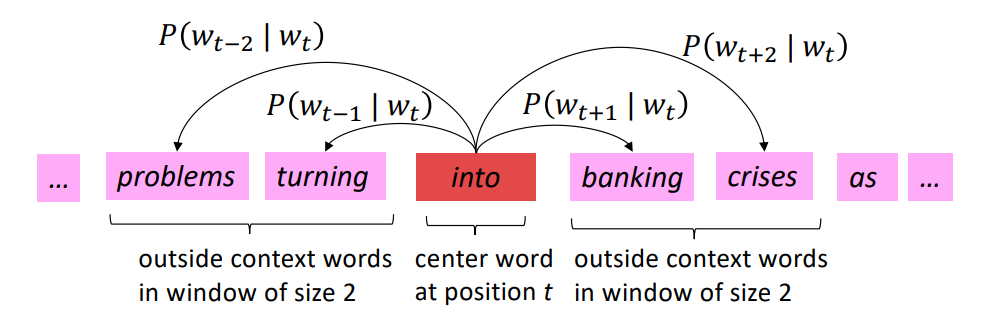
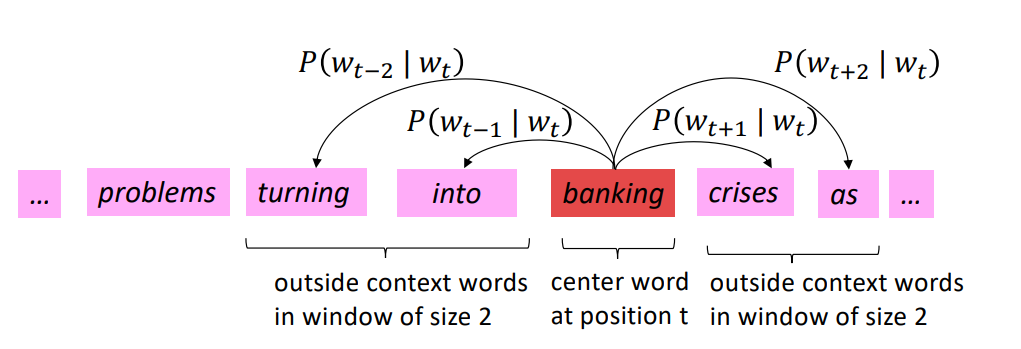
由于用户的兴趣是多样的,但是用户的每一种兴趣都有自己的发展过程,即使兴趣发生漂移我们可以只考虑用户与target item(广告或者商品)相关的兴趣演化过程,这样就不用考虑用户多样化的兴趣的问题了,而如何只获取与target item相关的信息,作者使用了与DIN模型中提取与target item相同的方法,来计算用户历史兴趣与target item之间的相似度,即这里也使用了DIN中介绍的局部激活单元(就是下图中的Attention模块)。
+
+
当得到了用户历史兴趣序列及兴趣序列与target item之间的相关性(注意力分数)之后,就需要再次对注意力序列进行建模得到用户注意力的演化过程,进一步表示用户最终的兴趣向量。此时的序列数据等同于有了一个序列及序列中每个向量的注意力权重,下面就是考虑如何使用这个注意力权重来一起优化序列建模的结果了。作者提出了三种注意力结合的GRU模型快:
@@ -155,10 +160,12 @@ def DIEN(feature_columns, behavior_feature_list, behavior_seq_feature_list, neg_
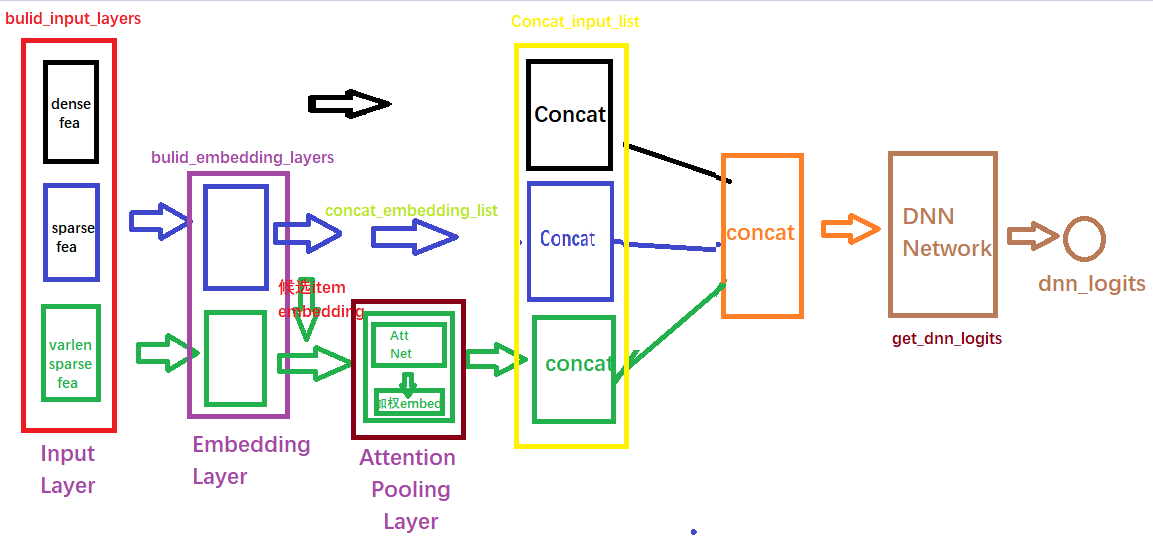
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中(看不清的话可以自己用代码生成之后使用其他的软件打开看)。
-
+> 下面这个图失效了
+
+

+
-
+
-
+
-
+