更新深度模型内容
131
DeepRecommendationModel/AFM.md
Normal file
@@ -0,0 +1,131 @@
|
||||
# AFM
|
||||
|
||||
## 1. AFM提出的动机
|
||||
|
||||
AFM的全称是Attentional Factorization Machines, 从模型的名称上来看是在FM的基础上加上了注意力机制,FM是通过特征隐向量的内积来对交叉特征进行建模,从公式中可以看出所有的交叉特征都具有相同的权重也就是1,没有考虑到不同的交叉特征的重要性程度:
|
||||
$$
|
||||
y_{fm} = w_0+\sum_{i=1}^nw_ix_i+\sum_{i=1}^{n}\sum_{i+1}^n\lt v_i,v_j\gt x_ix_j
|
||||
$$
|
||||
如何让不同的交叉特征具有不同的重要性就是AFM核心的贡献,在谈论AFM交叉特征注意力之前,对于FM交叉特征部分的改进还有FFM,其是考虑到了对于不同的其他特征,某个指定特征的隐向量应该是不同的(相比于FM对于所有的特征只有一个隐向量,FFM对于一个特征有多个不同的隐向量)。
|
||||
|
||||
## 2. AFM模型原理
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210131092744905.png" alt="image-20210131092744905" style="zoom: 50%;" />
|
||||
|
||||
上图表示的就是AFM交叉特征部分的模型结构(非交叉部分与FM是一样的,图中并没有给出)。AFM最核心的两个点分别是Pair-wise Interaction Layer和Attention-based Pooling。前者将输入的非零特征的隐向量两两计算element-wise product(哈达玛积,两个向量对应元素相乘,得到的还是一个向量),假如输入的特征中的非零向量的数量为m,那么经过Pair-wise Interaction Layer之后输出的就是$\frac{m(m-1)}{2}$个向量,再将前面得到的交叉特征向量组输入到Attention-based Pooling,该pooling层会先计算出每个特征组合的自适应权重(通过Attention Net进行计算),通过加权求和的方式将向量组压缩成一个向量,由于最终需要输出的是一个数值,所以还需要将前一步得到的向量通过另外一个向量将其映射成一个值,得到最终的基于注意力加权的二阶交叉特征的输出。(对于这部分如果不是很清楚,可以先看下面对两个核心层的介绍)
|
||||
|
||||
### 2.1 Pair-wise Interaction Layer
|
||||
|
||||
FM二阶交叉项:所有非零特征对应的隐向量两两点积再求和,输出的是一个数值
|
||||
$$
|
||||
\sum_{i=1}^{n}\sum_{i+1}^n\lt v_i,v_j\gt x_ix_j
|
||||
$$
|
||||
AFM二阶交叉项(无attention):所有非零特征对应的隐向量两两对应元素乘积,然后再向量求和,输出的还是一个向量。
|
||||
$$
|
||||
\sum_{i=1}^{n}\sum_{i+1}^n (v_i \odot v_j) x_ix_j
|
||||
$$
|
||||
上述写法是为了更好的与FM进行对比,下面将公式变形方便与原论文中保持一致。首先是特征的隐向量。从上图中可以看出,作者对数值特征也对应了一个隐向量,不同的数值乘以对应的隐向量就可以得到不同的隐向量,相对于onehot编码的特征乘以1还是其本身(并没有什么变化),其实就是为了将公式进行统一。虽然论文中给出了对数值特征定义隐向量,但是在作者的代码中并没有发现有对数值特征进行embedding的过程([原论文代码链接](https://github.com/hexiangnan/attentional_factorization_machine/blob/master/code/AFM.py))具体原因不详。
|
||||
|
||||
按照论文的意思,特征的embedding可以表示为:$\varepsilon = {v_ix_i}$,经过Pair-wise Interaction Layer输出可得:
|
||||
$$
|
||||
f_{PI}(\varepsilon)=\{(v_i \odot v_j) x_ix_j\}_{i,j \in R_x}
|
||||
$$
|
||||
$R_x$表示的是有效特征集合。此时的$f_{PI}(\varepsilon)$表示的是一个向量集合,所以需要先将这些向量集合聚合成一个向量,然后在转换成一个数值:
|
||||
$$
|
||||
\hat{y} = p^T \sum_{(i,j)\in R_x}(v_i \odot v_j) x_ix_j + b
|
||||
$$
|
||||
上式中的求和部分就是将向量集合聚合成一个维度与隐向量维度相同的向量,通过向量$p$再将其转换成一个数值,b表示的是偏置。
|
||||
|
||||
从开始介绍Pair-wise Interaction Layer到现在解决的一个问题是,如何将使用哈达玛积得到的交叉特征转换成一个最终输出需要的数值,到目前为止交叉特征之间的注意力权重还没有出现。在没有详细介绍注意力之前先感性的认识一下如果现在已经有了每个交叉特征的注意力权重,那么交叉特征的输出可以表示为:
|
||||
$$
|
||||
\hat{y} = p^T \sum_{(i,j)\in R_x}\alpha_{ij}(v_i \odot v_j) x_ix_j + b
|
||||
$$
|
||||
就是在交叉特征得到的新向量前面乘以一个注意力权重$\alpha_{ij}$, 那么这个注意力权重如何计算得到呢?
|
||||
|
||||
### 2.2 Attention-based Pooling
|
||||
|
||||
对于神经网络注意力相关的基础知识大家可以去看一下邱锡鹏老师的《神经网络与深度学习》第8章注意力机制与外部记忆。这里简单的叙述一下使用MLP实现注意力机制的计算。假设现在有n个交叉特征(假如维度是k),将nxk的数据输入到一个kx1的全连接网络中,输出的张量维度为nx1,使用softmax函数将nx1的向量的每个维度进行归一化,得到一个新的nx1的向量,这个向量所有维度加起来的和为1,每个维度上的值就可以表示原nxk数据每一行(即1xk的数据)的权重。用公式表示为:
|
||||
$$
|
||||
\alpha_{ij}' = h^T ReLU(W(v_i \odot v_j)x_ix_j + b)
|
||||
$$
|
||||
使用softmax归一化可得:
|
||||
$$
|
||||
\alpha_{ij} = \frac{exp(\alpha_{ij}')}{\sum_{(i,j)\in R_x}exp(\alpha_{ij}')}
|
||||
$$
|
||||
这样就得到了AFM二阶交叉部分的注意力权重,如果将AFM的一阶项写在一起,AFM模型用公式表示为:
|
||||
$$
|
||||
\hat{y}_{afm}(x) = w_0+\sum_{i=1}^nw_ix_i+p^T \sum_{(i,j)\in R_x}\alpha_{ij}(v_i \odot v_j) x_ix_j + b
|
||||
$$
|
||||
### 2.3 AFM模型训练
|
||||
|
||||
AFM从最终的模型公式可以看出与FM的模型公式是非常相似的,所以也可以和FM一样应用于不同的任务,例如分类、回归及排序(不同的任务的损失函数是不一样的),AFM也有对防止过拟合进行处理:
|
||||
|
||||
1. 在Pair-wise Interaction Layer层的输出结果上使用dropout防止过拟合,因为并不是所有的特征组合对预测结果都有用,所以随机的去除一些交叉特征,让剩下的特征去自适应的学习可以更好的防止过拟合。
|
||||
2. 对Attention-based Pooling层中的权重矩阵$W$使用L2正则,作者没有在这一层使用dropout的原因是发现同时在特征交叉层和注意力层加dropout会使得模型训练不稳定,并且性能还会下降。
|
||||
|
||||
加上正则参数之后的回归任务的损失函数表示为:
|
||||
$$
|
||||
L = \sum_{x\in T} (\hat{y}_{afm}(x) - y(x))^2 + \lambda ||x||^2
|
||||
$$
|
||||
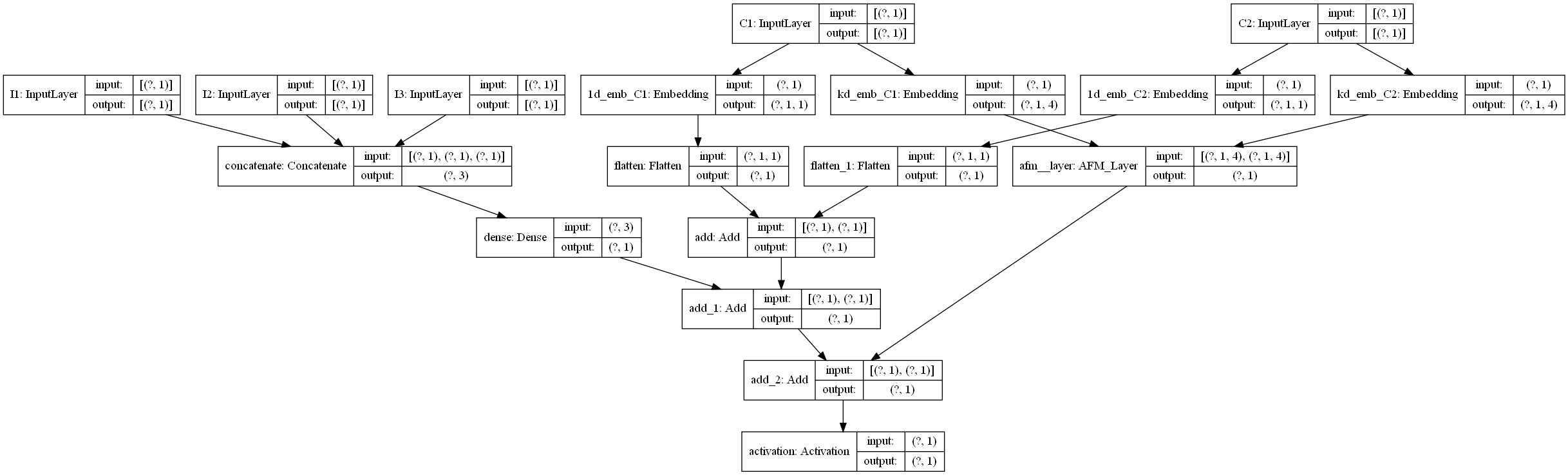
## 3. AFM代码实现
|
||||
|
||||
1. linear part: 这部分是有关于线性计算,也就是FM的前半部分$w1x1+w2x2...wnxn+b$的计算。对于这一块的计算,我们用了一个get_linear_logits函数实现,后面再说,总之通过这个函数,我们就可以实现上面这个公式的计算过程,得到linear的输出
|
||||
2. dnn part: 这部分是后面交叉特征的那部分计算,这一部分需要使用注意力机制来将所有类别特征的embedding计算注意力权重,然后通过加权求和的方式将所有交叉之后的特征池化成一个向量,最终通过一个映射矩阵$p$将向量转化成一个logits值
|
||||
3. 最终将linear部分与dnn部分相加之后,通过sigmoid激活得到最终的输出
|
||||
|
||||
```python
|
||||
def AFM(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# embedding层用户构建FM交叉部分和DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 将输入到dnn中的sparse特征筛选出来
|
||||
att_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
att_logits = get_attention_logits(sparse_input_dict, att_sparse_feature_columns, embedding_layers) # B x (n(n-1)/2)
|
||||
|
||||
# 将linear,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, att_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layers)
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210307200304199.png" alt="image-20210307200304199" style="zoom:67%;" />
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
|
||||
|
||||
## 4. 思考
|
||||
|
||||
1. AFM与NFM优缺点对比。
|
||||
|
||||
|
||||
|
||||
## 5. 参考资料
|
||||
|
||||
[原论文](https://www.ijcai.org/Proceedings/2017/0435.pdf)
|
||||
|
||||
[deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
|
||||
|
||||
|
||||
158
DeepRecommendationModel/DCN.md
Normal file
@@ -0,0 +1,158 @@
|
||||
# DCN
|
||||
|
||||
## 1. 动机
|
||||
|
||||
Wide&Deep模型的提出不仅综合了“记忆能力”和“泛化能力”, 而且开启了不同网络结构融合的新思路。 所以后面就有各式各样的模型改进Wide部分或者Deep部分, 而Deep&Cross模型(DCN)就是其中比较典型的一个,这是2017年斯坦福大学和谷歌的研究人员在ADKDD会议上提出的, 该模型针对W&D的wide部分进行了改进, 因为Wide部分有一个不足就是需要人工进行特征的组合筛选, 过程繁琐且需要经验, 而2阶的FM模型在线性的时间复杂度中自动进行特征交互,但是这些特征交互的表现能力并不够,并且随着阶数的上升,模型复杂度会大幅度提高。于是乎,作者用一个Cross Network替换掉了Wide部分,来自动进行特征之间的交叉,并且网络的时间和空间复杂度都是线性的。 通过与Deep部分相结合,构成了深度交叉网络(Deep & Cross Network),简称DCN。
|
||||
|
||||
## 2. 模型结构及原理
|
||||
|
||||
这个模型的结构是这个样子的:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片dcn.png" style="zoom:67%;" />
|
||||
|
||||
这个模型的结构也是比较简洁的, 从上到下依次为:Embedding和Stacking层, Cross网络层与Deep网络层并列, 以及最后的输出层。下面也是一一为大家剖析。
|
||||
|
||||
### 2.1 Embedding和Stacking 层
|
||||
|
||||
Embedding层我们已经非常的熟悉了吧, 这里的作用依然是把稀疏离散的类别型特征变成低维密集型。
|
||||
$$
|
||||
\mathbf{x}_{\text {embed, } i}=W_{\text {embed, } i} \mathbf{x}_{i}
|
||||
$$
|
||||
其中对于某一类稀疏分类特征(如id),$X_{embed, i}$是第个$i$分类值(id序号)的embedding向量。$W_{embed,i}$是embedding矩阵, $n_e\times n_v$维度, $n_e$是embedding维度, $n_v$是该类特征的唯一取值个数。$x_i$属于该特征的二元稀疏向量(one-hot)编码的。 【实质上就是在训练得到的Embedding参数矩阵中找到属于当前样本对应的Embedding向量】。其实绝大多数基于深度学习的推荐模型都需要Embedding操作,参数学习是通过神经网络进行训练。
|
||||
|
||||
最后,该层需要将所有的密集型特征与通过embedding转换后的特征进行联合(Stacking):
|
||||
$$
|
||||
\mathbf{x}_{0}=\left[\mathbf{x}_{\text {embed, } 1}^{T}, \ldots, \mathbf{x}_{\text {embed, }, k}^{T}, \mathbf{x}_{\text {dense }}^{T}\right]
|
||||
$$
|
||||
一共$k$个类别特征, dense是数值型特征, 两者在特征维度拼在一块。 上面的这两个操作如果是看了前面的模型的话,应该非常容易理解了。
|
||||
|
||||
### 2.2 Cross Network
|
||||
|
||||
这个就是本模型最大的亮点了---Cross网络, 这个思路感觉非常Nice。设计该网络的目的是增加特征之间的交互力度。交叉网络由多个交叉层组成, 假设$l$层的输出向量$x_l$, 那么对于第$l+1$层的输出向量$x_{l+1}$表示为:
|
||||
|
||||
$$
|
||||
\mathbf{x}_{l+1}=\mathbf{x}_{0} \mathbf{x}_{l}^{T} \mathbf{w}_{l}+\mathbf{b}_{l}+\mathbf{x}_{l}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l}
|
||||
$$
|
||||
可以看到, 交叉层的操作的二阶部分非常类似PNN提到的外积操作, 在此基础上增加了外积操作的权重向量$w_l$, 以及原输入向量$x_l$和偏置向量$b_l$。 交叉层的可视化如下:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片cross.png" style="zoom:67%;" />
|
||||
|
||||
可以看到, 每一层增加了一个$n$维的权重向量$w_l$(n表示输入向量维度), 并且在每一层均保留了输入向量, 因此输入和输出之间的变化不会特别明显。关于这一层, 原论文里面有个具体的证明推导Cross Network为啥有效, 不过比较复杂,这里我拿一个式子简单的解释下上面这个公式的伟大之处:
|
||||
|
||||
> 我们根据上面这个公式, 尝试的写前面几层看看:<br>
|
||||
>
|
||||
> $l$ =0: $\mathbf{x}_{1} =\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}$
|
||||
>
|
||||
> $l=1:\mathbf{x}_{2} =\mathbf{x}_{0} \mathbf{x}_{1}^{T} \mathbf{w}_{1}+ \mathbf{b}_{1}+\mathbf{x}_{1}=\mathbf{x}_{0} [\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}]^{T}\mathbf{w}_{1}+\mathbf{b}_{1}+\mathbf{x}_{1}$
|
||||
>
|
||||
> $l=2:\mathbf{x}_{3} =\mathbf{x}_{0} \mathbf{x}_{2}^{T} \mathbf{w}_{2}+ \mathbf{b}_{2}+\mathbf{x}_{2}=\mathbf{x}_{0} [\mathbf{x}_{0} [\mathbf{x}_{0} \mathbf{x}_{0}^{T} \mathbf{w}_{0}+ \mathbf{b}_{0}+\mathbf{x}_{0}]^{T}\mathbf{w}_{1}+\mathbf{b}_{1}+\mathbf{x}_{1}]^{T}\mathbf{w}_{2}+\mathbf{b}_{2}+\mathbf{x}_{2}$
|
||||
|
||||
我们暂且写到第3层的计算, 我们会发现什么结论呢? 给大家总结一下:
|
||||
|
||||
1. $\mathrm{x}_1$中包含了所有的$\mathrm{x}_0$的1,2阶特征的交互, $\mathrm{x}_2$包含了所有的$\mathrm{x}_1, \mathrm{x}_0$的1, 2, 3阶特征的交互,$\mathrm{x}_3$中包含了所有的$\mathrm{x}_2$, $\mathrm{x}_1$与$\mathrm{x}_0$的交互,$\mathrm{x}_0$的1,2,3,4阶特征交互。 因此, 交叉网络层的叉乘阶数是有限的。 **第$l$层特征对应的最高的叉乘阶数$l+1$**
|
||||
|
||||
2. Cross网络的参数是共享的, 每一层的这个权重特征之间共享, 这个可以使得模型泛化到看不见的特征交互作用, 并且对噪声更具有鲁棒性。 例如两个稀疏的特征$x_i,x_j$, 它们在数据中几乎不发生交互, 那么学习$x_i,x_j$的权重对于预测没有任何的意义。
|
||||
|
||||
3. 计算交叉网络的参数数量。 假设交叉层的数量是$L_c$, 特征$x$的维度是$n$, 那么总共的参数是:
|
||||
|
||||
$$
|
||||
n\times L_c \times 2
|
||||
$$
|
||||
这个就是每一层会有$w$和$b$。且$w$维度和$x$的维度是一致的。
|
||||
|
||||
4. 交叉网络的时间和空间复杂度是线性的。这是因为, 每一层都只有$w$和$b$, 没有激活函数的存在,相对于深度学习网络, 交叉网络的复杂性可以忽略不计。
|
||||
|
||||
5. Cross网络是FM的泛化形式, 在FM模型中, 特征$x_i$的权重$v_i$, 那么交叉项$x_i,x_j$的权重为$<x_i,x_j>$。在DCN中, $x_i$的权重为${W_K^{(i)}}_{k=1}^l$, 交叉项$x_i,x_j$的权重是参数${W_K^{(i)}}_{k=1}^l$和${W_K^{(j)}}_{k=1}^l$的乘积,这个看上面那个例子展开感受下。因此两个模型都各自学习了独立于其他特征的一些参数,并且交叉项的权重是相应参数的某种组合。FM只局限于2阶的特征交叉(一般),而DCN可以构建更高阶的特征交互, 阶数由网络深度决定,并且交叉网络的参数只依据输入的维度线性增长。
|
||||
|
||||
6. 还有一点我们也要了解,对于每一层的计算中, 都会跟着$\mathrm{x}_0$, 这个是咱们的原始输入, 之所以会乘以一个这个,是为了保证后面不管怎么交叉,都不能偏离我们的原始输入太远,别最后交叉交叉都跑偏了。
|
||||
|
||||
7. $\mathbf{x}_{l+1}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l}$, 这个东西其实有点跳远连接的意思,也就是和ResNet也有点相似,无形之中还能有效的缓解梯度消失现象。
|
||||
|
||||
好了, 关于本模型的交叉网络的细节就介绍到这里了。这应该也是本模型的精华之处了,后面就简单了。
|
||||
|
||||
### 2.3 Deep Network
|
||||
|
||||
这个就和上面的D&W的全连接层原理一样。这里不再过多的赘述。
|
||||
$$
|
||||
\mathbf{h}_{l+1}=f\left(W_{l} \mathbf{h}_{l}+\mathbf{b}_{l}\right)
|
||||
$$
|
||||
具体的可以参考W&D模型。
|
||||
|
||||
### 2.4组合输出层
|
||||
|
||||
这个层负责将两个网络的输出进行拼接, 并且通过简单的Logistics回归完成最后的预测:
|
||||
$$
|
||||
p=\sigma\left(\left[\mathbf{x}_{L_{1}}^{T}, \mathbf{h}_{L_{2}}^{T}\right] \mathbf{w}_{\text {logits }}\right)
|
||||
$$
|
||||
其中$\mathbf{x}_{L_{1}}^{T}$$\mathbf{h}_{L_{2}}^{T}$表示交叉网络和深度网络的输出。
|
||||
最后二分类的损失函数依然是交叉熵损失:
|
||||
$$
|
||||
\text { loss }=-\frac{1}{N} \sum_{i=1}^{N} y_{i} \log \left(p_{i}\right)+\left(1-y_{i}\right) \log \left(1-p_{i}\right)+\lambda \sum_{l}\left\|\mathbf{w}_{i}\right\|^{2}
|
||||
$$
|
||||
|
||||
Cross&Deep模型的原理就是这些了,其核心部分就是Cross Network, 这个可以进行特征的自动交叉, 避免了更多基于业务理解的人工特征组合。 该模型相比于W&D,Cross部分表达能力更强, 使得模型具备了更强的非线性学习能力。
|
||||
|
||||
## 3. 代码实现
|
||||
|
||||
下面我们看下DCN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
|
||||
|
||||
从上面的结构图我们也可以看出, DCN的模型搭建,其实主要分为几大模块, 首先就是建立输入层,用到的函数式`build_input_layers`,有了输入层之后, 我们接下来是embedding层的搭建,用到的函数是`build_embedding_layers`, 这个层的作用是接收离散特征,变成低维稠密。 接下来就是把连续特征和embedding之后的离散特征进行拼接,分别进入wide端和deep端。 wide端就是交叉网络,而deep端是DNN网络, 这里分别是`CrossNet()`和`get_dnn_output()`, 接下来就是把这两块的输出拼接得到最后的输出了。所以整体代码如下:
|
||||
|
||||
```python
|
||||
def DCN(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns)) if linear_feature_columns else []
|
||||
|
||||
sparse_kd_embed = concat_embedding_list(sparse_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed)
|
||||
|
||||
dnn_input = Concatenate(axis=1)([concat_dense_inputs, concat_sparse_kd_embed])
|
||||
|
||||
dnn_output = get_dnn_output(dnn_input)
|
||||
|
||||
cross_output = CrossNet()(dnn_input)
|
||||
|
||||
# stack layer
|
||||
stack_output = Concatenate(axis=1)([dnn_output, cross_output])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layer = Dense(1, activation='sigmoid')(stack_output)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
这个模型的实现过程和DeepFM比较类似,这里不画草图了,如果想看的可以去参考DeepFM草图及代码之间的对应关系。
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||

|
||||
|
||||
## 4. 思考
|
||||
|
||||
1. 请计算Cross Network的复杂度,需要的变量请自己定义。
|
||||
2. 在实现矩阵计算$x_0*x_l^Tw$的过程中,有人说要先算前两个,有人说要先算后两个,请问那种方式更好?为什么?
|
||||
|
||||
|
||||
|
||||
## 5. 参考资料
|
||||
|
||||
* 《深度学习推荐系统》 --- 王喆
|
||||
* [Deep&Cross模型原论文](https://arxiv.org/abs/1708.05123)
|
||||
* [AI上推荐 之 Wide&Deep与Deep&Cross模型(记忆与泛化并存的华丽转身)]()
|
||||
|
||||
* [Wide&Deep模型的进阶---Cross&Deep模型](https://mp.weixin.qq.com/s/DkoaMaXhlgQv1NhZHF-7og)
|
||||
|
||||
195
DeepRecommendationModel/DIEN.md
Normal file
@@ -0,0 +1,195 @@
|
||||
# DIEN
|
||||
|
||||
## 1. DIEN提出的动机
|
||||
|
||||
在推荐场景,用户无需输入搜索关键词来表达意图,这种情况下捕捉用户兴趣并考虑兴趣的动态变化将是提升模型效果的关键。以Wide&Deep为代表的深度模型更多的是考虑不同field特征之间的相互作用,未关注用户兴趣。
|
||||
|
||||
DIN模型考虑了用户兴趣,并且强调用户兴趣是多样的,该模型使用注意力机制来捕捉和**target item**的相关的兴趣,这样以来用户的兴趣就会随着目标商品自适应的改变。但是大多该类模型包括DIN在内,直接将用户的行为当做用户的兴趣(因为DIN模型只是在行为序列上做了简单的特征处理),但是用户潜在兴趣一般很难直接通过用户的行为直接表示,大多模型都没有挖掘用户行为背后真实的兴趣,捕捉用户兴趣的动态变化对用户兴趣的表示非常重要。DIEN相比于之前的模型,即对用户的兴趣进行建模,又对建模出来的用户兴趣继续建模得到用户的兴趣变化过程。
|
||||
|
||||
## 2. DIEN模型原理
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218155901144.png" alt="image-20210218155901144" style="zoom:50%;" />
|
||||
|
||||
模型的输入可以分成两大部分,一部分是用户的行为序列(这部分会通过兴趣提取层及兴趣演化层转换成与用户当前兴趣相关的embedding),另一部分就是除了用户行为以外的其他所有特征,如Target id, Coontext Feature, UserProfile Feature,这些特征都转化成embedding的类型然后concat在一起(形成一个大的embedding)作为非行为相关的特征(这里可能也会存在一些非id类特征,应该可以直接进行concat)。最后DNN输入的部分由行为序列embedding和非行为特征embedding(多个特征concat到一起之后形成的一个大的向量)组成,将两者concat之后输入到DNN中。
|
||||
|
||||
所以DIEN模型的重点就是如何将用户的行为序列转换成与用户兴趣相关的向量,在DIN中是直接通过与target item计算序列中每个元素的注意力分数,然后加权求和得到最终的兴趣表示向量。在DIEN中使用了两层结构来建模用户兴趣相关的向量。
|
||||
|
||||
### 2.1 Interest Exterator Layer
|
||||
|
||||
兴趣抽取层的输入原本是一个id序列(按照点击时间的先后顺序形成的一个序列),通过Embedding层将其转化成一个embedding序列。然后使用GRU模块对兴趣进行抽取,GRU的输入是embedding层之后得到的embedding序列。对于GRU模块不是很了解的可以看一下[动手学深度学习中GRU相关的内容](https://zh.d2l.ai/chapter_recurrent-neural-networks/gru.html)
|
||||
|
||||
作者并没有直接完全使用原始的GRU来提取用户的兴趣,而是引入了一个辅助函数来指导用户兴趣的提取。作者认为如果直接使用GRU提取用户的兴趣,只能得到用户行为之间的依赖关系,不能有效的表示用户的兴趣。因为是用户的兴趣导致了用户的点击,用户的最后一次点击与用户点击之前的兴趣相关性就很强,但是直接使用行为序列训练GRU的话,只有用户最后一次点击的物品(也就是label,在这里可以认为是Target Ad), 那么最多就是能够捕捉到用户最后一次点击时的兴趣,而最后一次的兴趣又和前面点击过的物品在兴趣上是相关的,而前面点击的物品中并没有target item进行监督。**所以作者提出的辅助损失就是为了让行为序列中的每一个时刻都有一个target item进行监督训练,也就是使用下一个行为来监督兴趣状态的学习**
|
||||
|
||||
|
||||
|
||||
**辅助损失**
|
||||
|
||||
首先需要明确的就是辅助损失是计算哪两个量的损失。计算的是用户每个时刻的兴趣表示(GRU每个时刻输出的隐藏状态形成的序列)与用户当前时刻实际点击的物品表示(输入的embedding序列)之间的损失,相当于是行为序列中的第t+1个物品与用户第t时刻的兴趣表示之间的损失**(为什么这里用户第t时刻的兴趣与第t+1时刻的真实点击做损失呢?我的理解是,只有知道了用户第t+1真实点击的商品,才能更好的确定用户第t时刻的兴趣)。**
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218163742638.png" alt="image-20210218163742638" style="zoom:50%;" />
|
||||
|
||||
当然,如果只计算用户点击物品与其点击前一次的兴趣之间的损失,只能认为是正样本之间的损失,那么用户第t时刻的兴趣其实还有很多其他的未点击的商品,这些未点击的商品就是负样本,负样本一般通过从用户点击序列中采样得到,这样一来辅助损失中就包含了用户某个时刻下的兴趣及与该时刻兴趣相关的正负物品。所以最终的损失函数表示如下。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218162447125.png" alt="image-20210218162447125" style="zoom: 25%;" />
|
||||
|
||||
其中$h_t^i$表示的是用户$i$第$t$时刻的隐藏状态,可以表示用户第$t$时刻的兴趣向量,$e_b^i,\hat{e_b^i}$分别表示的是正负样本,$e_b^i[t+1]$表示的是用户$i$第$t+1$时刻点击的物品向量。
|
||||
|
||||
辅助损失会加到最终的目标损失(ctr损失)中一起进行优化,并且通过$\alpha$参数来平衡点击率和兴趣的关系
|
||||
$$
|
||||
L = L_{target} + \alpha L_{aux}
|
||||
$$
|
||||
|
||||
**引入辅助函数的函数有:**
|
||||
|
||||
- 辅助loss可以帮助GRU的隐状态更好地表示用户兴趣。
|
||||
|
||||
- RNN在长序列建模场景下梯度传播可能并不能很好的影响到序列开始部分,如果在序列的每个部分都引入一个辅助的监督信号,则可一定程度降低优化难度。
|
||||
|
||||
- 辅助loss可以给embedding层的学习带来更多语义信息,学习到item对应的更好的embedding。
|
||||
|
||||
|
||||
|
||||
### 2.2 Interest Evolving Layer
|
||||
|
||||
将用户的行为序列通过GRU+辅助损失建模之后,对用户行为序列中的兴趣进行了提取并表达成了向量的形式(GRU每个时刻输出的隐藏状态)。而用户的兴趣会因为外部环境或内部认知随着时间变化,特点如下:
|
||||
|
||||
- **兴趣是多样化的,可能发生漂移**。兴趣漂移对行为的影响是用户可能在一段时间内对各种书籍感兴趣,而在另一段时间却需要衣服
|
||||
|
||||
- 虽然兴趣可能会相互影响,但是**每一种兴趣都有自己的发展过程**,例如书和衣服的发展过程几乎是独立的。**而我们只关注与target item相关的演进过程。**
|
||||
|
||||
|
||||
|
||||
由于用户的兴趣是多样的,但是用户的每一种兴趣都有自己的发展过程,即使兴趣发生漂移我们可以只考虑用户与target item(广告或者商品)相关的兴趣演化过程,这样就不用考虑用户多样化的兴趣的问题了,而如何只获取与target item相关的信息,作者使用了与DIN模型中提取与target item相同的方法,来计算用户历史兴趣与target item之间的相似度,即这里也使用了DIN中介绍的局部激活单元(就是下图中的Attention模块)。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210218180755462.png" alt="image-20210218180755462" style="zoom:70%;" />
|
||||
|
||||
|
||||
|
||||
当得到了用户历史兴趣序列及兴趣序列与target item之间的相关性(注意力分数)之后,就需要再次对注意力序列进行建模得到用户注意力的演化过程,进一步表示用户最终的兴趣向量。此时的序列数据等同于有了一个序列及序列中每个向量的注意力权重,下面就是考虑如何使用这个注意力权重来一起优化序列建模的结果了。作者提出了三种注意力结合的GRU模型快:
|
||||
|
||||
1. **AIGRU:** 将注意力分数直接与输入的序列进行相乘,也就是权重越大的向量对应的值也越大, 其中$i_t^{'}, h_t, a_t$分别表示用户$i$在兴趣演化过程使用的GRU的第t时刻的输入,$h_t$表示的是兴趣抽取层第t时刻的输出,$a_t$表示的是$h_t$的注意力分数,这种方式的弊端是即使是零输入也会改变GRU的隐藏状态,所以相对较少的兴趣值也会影响兴趣的学习进化(根据GRU门的更新公式就可以知道,下一个隐藏状态的计算会用到上一个隐藏状态的信息,所以即使当前输入为0,最终隐藏状态也不会直接等于0,所以即使兴趣较少,也会影响到最终兴趣的演化)。
|
||||
$$
|
||||
i_t^{'} = h_t * a_t
|
||||
$$
|
||||
|
||||
2. **AGRU:** 将注意力分数直接作为GRU模块中,更新门的值,则重置门对应的值表示为$1-a_t$, 所以最终隐藏状态的更新公式表示为:其中$\hat{h_t^{'}}$表示的是候选隐藏状态。但是这种方式的弊端是弱化了兴趣之间的相关性,因为最终兴趣的更新前后是没关系的,只取决于输入的注意力分数
|
||||
$$
|
||||
h_t^{'} = (1-a_t)h_{t-1}^{'} + a_t * \tilde{h_t^{'}}
|
||||
$$
|
||||
|
||||
3. **AUGRU:** 将注意力分数作为更新门的权重,这样既兼顾了注意力分数很低时的状态更新值,也利用了兴趣之间的相关性,最终的表达式如下:
|
||||
$$
|
||||
\begin{align}
|
||||
& \tilde{u_t^{'}} = a_t * u_t \\
|
||||
& h_t^{'} = (1-\tilde{u_t^{'}})h_{t-1}^{'} + \tilde{u_t^{'}} * \tilde{h_t^{'}}
|
||||
\end{align}
|
||||
$$
|
||||
|
||||
**建模兴趣演化过程的好处:**
|
||||
|
||||
- 追踪用户的interest可以使我们学习final interest的表达时包含更多的历史信息
|
||||
|
||||
- 可以根据interest的变化趋势更好地进行CTR预测
|
||||
|
||||
|
||||
|
||||
## 3. 代码实现
|
||||
|
||||
下面我们看下DIN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
|
||||
|
||||
这里主要和大家说一下DIN模型的总体运行逻辑,这样可以让大家从宏观的层面去把握模型的编写过程。该模型所使用的数据集是movielens数据集, 具体介绍可以参考后面的GitHub。 因为上面反复强调了DIN的应用场景,需要基于用户的历史行为数据, 所以在这个数据集中会有用户过去对电影评分的一系列行为。这在之前的数据集中往往是看不到的。 大家可以导入数据之后自行查看这种行为特征(hist_behavior)。另外还有一点需要说明的是这种历史行为是序列性质的特征, 并且**不同的用户这种历史行为特征长度会不一样**, 但是我们的神经网络是要求序列等长的,所以这种情况我们一般会按照最长的序列进行padding的操作(不够长的填0), 而到具体层上进行运算的时候,会用mask掩码的方式标记出这些填充的位置,好保证计算的准确性。 在我们给出的代码中,大家会在AttentionPoolingLayer层的前向传播中看到这种操作。下面开始说编写逻辑:
|
||||
|
||||
首先, DIN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型),也就是指的上面的历史行为数据。而不同的类型特征也就决定了后面处理的方式会不同:
|
||||
|
||||
* Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
|
||||
* Sparse型特征,为离散型特征建立Input层接收输入,然后需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进DNN, 但是这里面要注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。
|
||||
* VarlenSparse型特征:这个一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入AttentionPoolingLayer去对这些历史行为特征加权合并,最后得到输出。
|
||||
|
||||
通过上面的三种处理, 就得到了处理好的连续特征,离散特征和变长离散特征, 接下来把这三种特征拼接,进DNN网络,得到最后的输出结果即可。所以有了这个解释, 就可以放DIN模型的代码全貌了,大家可以感受下我上面解释的:
|
||||
|
||||
```python
|
||||
def DIEN(feature_columns, behavior_feature_list, behavior_seq_feature_list, neg_seq_feature_list, use_neg_sample=False, alpha=1.0):
|
||||
# 构建输入层
|
||||
input_layer_dict = build_input_layers(feature_columns)
|
||||
|
||||
# 将Input层转化为列表的形式作为model的输入
|
||||
input_layers = list(input_layer_dict.values()) # 各个输入层
|
||||
user_behavior_length = input_layer_dict["hist_len"]
|
||||
|
||||
# 筛选出特征中的sparse_fea, dense_fea, varlen_fea
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if feature_columns else []
|
||||
varlen_sparse_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 获取dense
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
dnn_dense_input.append(input_layer_dict[fc.name])
|
||||
|
||||
# 将所有的dense特征拼接
|
||||
dnn_dense_input = concat_input_list(dnn_dense_input)
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
|
||||
|
||||
# 因为这里最终需要将embedding拼接后直接输入到全连接层(Dense)中, 所以需要Flatten
|
||||
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
|
||||
# 将所有sparse特征的embedding进行拼接
|
||||
dnn_sparse_input = concat_input_list(dnn_sparse_embed_input)
|
||||
|
||||
# 获取当前的行为特征(movie)的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 获取行为序列(movie_id序列, hist_movie_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 把q,k的embedding拼在一块
|
||||
query_emb, keys_emb = concat_input_list(query_embed_list), concat_input_list(keys_embed_list)
|
||||
|
||||
# 采样的负行为
|
||||
neg_uiseq_embed_list = embedding_lookup(neg_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
neg_concat_behavior = concat_input_list(neg_uiseq_embed_list)
|
||||
|
||||
# 兴趣进化层的计算过程
|
||||
dnn_seq_input, aux_loss = interest_evolution(keys_emb, query_emb, user_behavior_length, neg_concat_behavior, gru_type="AUGRU")
|
||||
|
||||
# 后面的全连接层
|
||||
deep_input_embed = Concatenate()([dnn_dense_input, dnn_sparse_input, dnn_seq_input])
|
||||
|
||||
# 获取最终dnn的logits
|
||||
dnn_logits = get_dnn_logits(deep_input_embed, activation='prelu')
|
||||
model = Model(input_layers, dnn_logits)
|
||||
|
||||
# 加兴趣提取层的损失 这个比例可调
|
||||
if use_neg_sample:
|
||||
model.add_loss(alpha * aux_loss)
|
||||
|
||||
# 所有变量需要初始化
|
||||
tf.compat.v1.keras.backend.get_session().run(tf.compat.v1.global_variables_initializer())
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中(看不清的话可以自己用代码生成之后使用其他的软件打开看)。
|
||||
|
||||

|
||||
|
||||
## 4. 思考
|
||||
|
||||
1. 对于知乎上大佬们对DIEN的探讨,你有什么看法呢?[也评Deep Interest Evolution Network](https://zhuanlan.zhihu.com/p/54838663)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 5. 参考资料
|
||||
|
||||
[deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
|
||||
[原论文](Deep Interest Evolution Network for Click-Through Rate Prediction )
|
||||
|
||||
[[论文阅读]阿里DIEN深度兴趣进化网络之总体解读](https://mp.weixin.qq.com/s/IlVZCVtDco3hWuvnsUmekg)
|
||||
|
||||
[也评Deep Interest Evolution Network](https://zhuanlan.zhihu.com/p/54838663)
|
||||
|
||||
179
DeepRecommendationModel/DIN.md
Normal file
@@ -0,0 +1,179 @@
|
||||
# DIN
|
||||
|
||||
## 1. 动机
|
||||
|
||||
Deep Interest Network(DIIN)是2018年阿里巴巴提出来的模型, 该模型基于业务的观察,从实际应用的角度进行改进,相比于之前很多“学术风”的深度模型, 该模型更加具有业务气息。该模型的应用场景是阿里巴巴的电商广告推荐业务, 这样的场景下一般**会有大量的用户历史行为信息**, 这个其实是很关键的,因为DIN模型的创新点或者解决的问题就是使用了注意力机制来对用户的兴趣动态模拟, 而这个模拟过程存在的前提就是用户之前有大量的历史行为了,这样我们在预测某个商品广告用户是否点击的时候,就可以参考他之前购买过或者查看过的商品,这样就能猜测出用户的大致兴趣来,这样我们的推荐才能做的更加到位,所以这个模型的使用场景是**非常注重用户的历史行为特征(历史购买过的商品或者类别信息)**,也希望通过这一点,能够和前面的一些深度学习模型对比一下。
|
||||
|
||||
在个性化的电商广告推荐业务场景中,也正式由于用户留下了大量的历史交互行为,才更加看出了之前的深度学习模型(作者统称Embeding&MLP模型)的不足之处。如果学习了前面的各种深度学习模型,就会发现Embeding&MLP模型对于这种推荐任务一般有着差不多的固定处理套路,就是大量稀疏特征先经过embedding层, 转成低维稠密的,然后进行拼接,最后喂入到多层神经网络中去。
|
||||
|
||||
这些模型在这种个性化广告点击预测任务中存在的问题就是**无法表达用户广泛的兴趣**,因为这些模型在得到各个特征的embedding之后,就蛮力拼接了,然后就各种交叉等。这时候根本没有考虑之前用户历史行为商品具体是什么,究竟用户历史行为中的哪个会对当前的点击预测带来积极的作用。 而实际上,对于用户点不点击当前的商品广告,很大程度上是依赖于他的历史行为的,王喆老师举了个例子
|
||||
|
||||
>假设广告中的商品是键盘, 如果用户历史点击的商品中有化妆品, 包包,衣服, 洗面奶等商品, 那么大概率上该用户可能是对键盘不感兴趣的, 而如果用户历史行为中的商品有鼠标, 电脑,iPad,手机等, 那么大概率该用户对键盘是感兴趣的, 而如果用户历史商品中有鼠标, 化妆品, T-shirt和洗面奶, 鼠标这个商品embedding对预测“键盘”广告的点击率的重要程度应该大于后面的那三个。
|
||||
|
||||
这里也就是说如果是之前的那些深度学习模型,是没法很好的去表达出用户这广泛多样的兴趣的,如果想表达的准确些, 那么就得加大隐向量的维度,让每个特征的信息更加丰富, 那这样带来的问题就是计算量上去了,毕竟真实情景尤其是电商广告推荐的场景,特征维度的规模是非常大的。 并且根据上面的例子, 也**并不是用户所有的历史行为特征都会对某个商品广告点击预测起到作用**。所以对于当前某个商品广告的点击预测任务,没必要考虑之前所有的用户历史行为。
|
||||
|
||||
这样, DIN的动机就出来了,在业务的角度,我们应该自适应的去捕捉用户的兴趣变化,这样才能较为准确的实施广告推荐;而放到模型的角度, 我们应该**考虑到用户的历史行为商品与当前商品广告的一个关联性**,如果用户历史商品中很多与当前商品关联,那么说明该商品可能符合用户的品味,就把该广告推荐给他。而一谈到关联性的话, 我们就容易想到“注意力”的思想了, 所以为了更好的从用户的历史行为中学习到与当前商品广告的关联性,学习到用户的兴趣变化, 作者把注意力引入到了模型,设计了一个"local activation unit"结构,利用候选商品和历史问题商品之间的相关性计算出权重,这个就代表了对于当前商品广告的预测,用户历史行为的各个商品的重要程度大小, 而加入了注意力权重的深度学习网络,就是这次的主角DIN, 下面具体来看下该模型。
|
||||
|
||||
## 2. DIN模型结构及原理
|
||||
|
||||
在具体分析DIN模型之前, 我们还得先介绍两块小内容,一个是DIN模型的数据集和特征表示, 一个是上面提到的之前深度学习模型的基线模型, 有了这两个, 再看DIN模型,就感觉是水到渠成了。
|
||||
|
||||
### 2.1 特征表示
|
||||
|
||||
工业上的CTR预测数据集一般都是`multi-group categorial form`的形式,就是类别型特征最为常见,这种数据集一般长这样:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" style="zoom: 67%;" />
|
||||
|
||||
这里的亮点就是框出来的那个特征,这个包含着丰富的用户兴趣信息。
|
||||
|
||||
对于特征编码,作者这里举了个例子:`[weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book]`, 这种情况我们知道一般是通过one-hot的形式对其编码, 转成系数的二值特征的形式。但是这里我们会发现一个`visted_cate_ids`, 也就是用户的历史商品列表, 对于某个用户来讲,这个值是个多值型的特征, 而且还要知道这个特征的长度不一样长,也就是用户购买的历史商品个数不一样多,这个显然。这个特征的话,我们一般是用到multi-hot编码,也就是可能不止1个1了,有哪个商品,对应位置就是1, 所以经过编码后的数据长下面这个样子:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" style="zoom:67%;" />
|
||||
|
||||
这个就是喂入模型的数据格式了,这里还要注意一点 就是上面的特征里面没有任何的交互组合,也就是没有做特征交叉。这个交互信息交给后面的神经网络去学习。
|
||||
|
||||
### 2.2 基线模型
|
||||
|
||||
这里的base 模型,就是上面提到过的Embedding&MLP的形式, 这个之所以要介绍,就是因为DIN网络的基准也是他,只不过在这个的基础上添加了一个新结构(注意力网络)来学习当前候选广告与用户历史行为特征的相关性,从而动态捕捉用户的兴趣。
|
||||
|
||||
基准模型的结构相对比较简单,我们前面也一直用这个基准, 分为三大模块:Embedding layer,Pooling & Concat layer和MLP, 结构如下:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片3.png" style="zoom:67%;" />
|
||||
|
||||
|
||||
前面的大部分深度模型结构也是遵循着这个范式套路, 简介一下各个模块。
|
||||
|
||||
1. **Embedding layer**:这个层的作用是把高维稀疏的输入转成低维稠密向量, 每个离散特征下面都会对应着一个embedding词典, 维度是$D\times K$, 这里的$D$表示的是隐向量的维度, 而$K$表示的是当前离散特征的唯一取值个数, 这里为了好理解,这里举个例子说明,就比如上面的weekday特征:
|
||||
|
||||
> 假设某个用户的weekday特征就是周五,化成one-hot编码的时候,就是[0,0,0,0,1,0,0]表示,这里如果再假设隐向量维度是D, 那么这个特征对应的embedding词典是一个$D\times7$的一个矩阵(每一列代表一个embedding,7列正好7个embedding向量,对应周一到周日),那么该用户这个one-hot向量经过embedding层之后会得到一个$D\times1$的向量,也就是周五对应的那个embedding,怎么算的,其实就是$embedding矩阵* [0,0,0,0,1,0,0]^T$ 。其实也就是直接把embedding矩阵中one-hot向量为1的那个位置的embedding向量拿出来。 这样就得到了稀疏特征的稠密向量了。
|
||||
|
||||
其他离散特征也是同理,只不过上面那个multi-hot编码的那个,会得到一个embedding向量的列表,因为他开始的那个multi-hot向量不止有一个是1,这样乘以embedding矩阵,就会得到一个列表了。通过这个层,上面的输入特征都可以拿到相应的稠密embedding向量了。
|
||||
|
||||
2. **pooling layer and Concat layer**: pooling层的作用是将用户的历史行为embedding这个最终变成一个定长的向量,因为每个用户历史购买的商品数是不一样的, 也就是每个用户multi-hot中1的个数不一致,这样经过embedding层,得到的用户历史行为embedding的个数不一样多,也就是上面的embedding列表$t_i$不一样长, 那么这样的话,每个用户的历史行为特征拼起来就不一样长了。 而后面如果加全连接网络的话,我们知道,他需要定长的特征输入。 所以往往用一个pooling layer先把用户历史行为embedding变成固定长度(统一长度),所以有了这个公式:
|
||||
$$
|
||||
e_i=pooling(e_{i1}, e_{i2}, ...e_{ik})
|
||||
$$
|
||||
这里的$e_{ij}$是用户历史行为的那些embedding。$e_i$就变成了定长的向量, 这里的$i$表示第$i$个历史特征组(是历史行为,比如历史的商品id,历史的商品类别id等), 这里的$k$表示对应历史特种组里面用户购买过的商品数量,也就是历史embedding的数量,看上面图里面的user behaviors系列,就是那个过程了。 Concat layer层的作用就是拼接了,就是把这所有的特征embedding向量,如果再有连续特征的话也算上,从特征维度拼接整合,作为MLP的输入。
|
||||
|
||||
3. **MLP**:这个就是普通的全连接,用了学习特征之间的各种交互。
|
||||
|
||||
4. **Loss**: 由于这里是点击率预测任务, 二分类的问题,所以这里的损失函数用的负的log对数似然:
|
||||
$$
|
||||
L=-\frac{1}{N} \sum_{(\boldsymbol{x}, y) \in \mathcal{S}}(y \log p(\boldsymbol{x})+(1-y) \log (1-p(\boldsymbol{x})))
|
||||
$$
|
||||
|
||||
这就是base 模型的全貌, 这里应该能看出这种模型的问题, 通过上面的图也能看出来, 用户的历史行为特征和当前的候选广告特征在全都拼起来给神经网络之前,是一点交互的过程都没有, 而拼起来之后给神经网络,虽然是有了交互了,但是原来的一些信息,比如,每个历史商品的信息会丢失了一部分,因为这个与当前候选广告商品交互的是池化后的历史特征embedding, 这个embedding是综合了所有的历史商品信息, 这个通过我们前面的分析,对于预测当前广告点击率,并不是所有历史商品都有用,综合所有的商品信息反而会增加一些噪声性的信息,可以联想上面举得那个键盘鼠标的例子,如果加上了各种洗面奶,衣服啥的反而会起到反作用。其次就是这样综合起来,已经没法再看出到底用户历史行为中的哪个商品与当前商品比较相关,也就是丢失了历史行为中各个商品对当前预测的重要性程度。最后一点就是如果所有用户浏览过的历史行为商品,最后都通过embedding和pooling转换成了固定长度的embedding,这样会限制模型学习用户的多样化兴趣。
|
||||
|
||||
那么改进这个问题的思路有哪些呢? 第一个就是加大embedding的维度,增加之前各个商品的表达能力,这样即使综合起来,embedding的表达能力也会加强, 能够蕴涵用户的兴趣信息,但是这个在大规模的真实推荐场景计算量超级大,不可取。 另外一个思路就是**在当前候选广告和用户的历史行为之间引入注意力的机制**,这样在预测当前广告是否点击的时候,让模型更关注于与当前广告相关的那些用户历史产品,也就是说**与当前商品更加相关的历史行为更能促进用户的点击行为**。 作者这里又举了之前的一个例子:
|
||||
> 想象一下,当一个年轻母亲访问电子商务网站时,她发现展示的新手袋很可爱,就点击它。让我们来分析一下点击行为的驱动力。<br><br>展示的广告通过软搜索这位年轻母亲的历史行为,发现她最近曾浏览过类似的商品,如大手提袋和皮包,从而击中了她的相关兴趣
|
||||
|
||||
|
||||
第二个思路就是DIN的改进之处了。DIN通过给定一个候选广告,然后去注意与该广告相关的局部兴趣的表示来模拟此过程。 DIN不会通过使用同一向量来表达所有用户的不同兴趣,而是通过考虑历史行为的相关性来自适应地计算用户兴趣的表示向量(对于给的广告)。 该表示向量随不同广告而变化。下面看一下DIN模型。
|
||||
|
||||
### 2.3 DIN模型架构
|
||||
|
||||
上面分析完了base模型的不足和改进思路之后,DIN模型的结构就呼之欲出了,首先,它依然是采用了基模型的结构,只不过是在这个的基础上加了一个注意力机制来学习用户兴趣与当前候选广告间的关联程度, 用论文里面的话是,引入了一个新的`local activation unit`, 这个东西用在了用户历史行为特征上面, **能够根据用户历史行为特征和当前广告的相关性给用户历史行为特征embedding进行加权**。我们先看一下它的结构,然后看一下这个加权公式。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片4.png" style="zoom: 67%;" />
|
||||
|
||||
这里改进的地方已经框出来了,这里会发现相比于base model, 这里加了一个local activation unit, 这里面是一个前馈神经网络,输入是用户历史行为商品和当前的候选商品, 输出是它俩之间的相关性, 这个相关性相当于每个历史商品的权重,把这个权重与原来的历史行为embedding相乘求和就得到了用户的兴趣表示$\boldsymbol{v}_{U}(A)$, 这个东西的计算公式如下:
|
||||
$$
|
||||
\boldsymbol{v}_{U}(A)=f\left(\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\right)=\sum_{j=1}^{H} a\left(\boldsymbol{e}_{j}, \boldsymbol{v}_{A}\right) \boldsymbol{e}_{j}=\sum_{j=1}^{H} \boldsymbol{w}_{j} \boldsymbol{e}_{j}
|
||||
$$
|
||||
这里的$\{\boldsymbol{v}_{A}, \boldsymbol{e}_{1}, \boldsymbol{e}_{2}, \ldots, \boldsymbol{e}_{H}\}$是用户$U$的历史行为特征embedding, $v_{A}$表示的是候选广告$A$的embedding向量, $a(e_j, v_A)=w_j$表示的权重或者历史行为商品与当前广告$A$的相关性程度。$a(\cdot)$表示的上面那个前馈神经网络,也就是那个所谓的注意力机制, 当然,看图里的话,输入除了历史行为向量和候选广告向量外,还加了一个它俩的外积操作,作者说这里是有利于模型相关性建模的显性知识。
|
||||
|
||||
这里有一点需要特别注意,就是这里的权重加和不是1, 准确的说这里不是权重, 而是直接算的相关性的那种分数作为了权重,也就是平时的那种scores(softmax之前的那个值),这个是为了保留用户的兴趣强度。
|
||||
|
||||
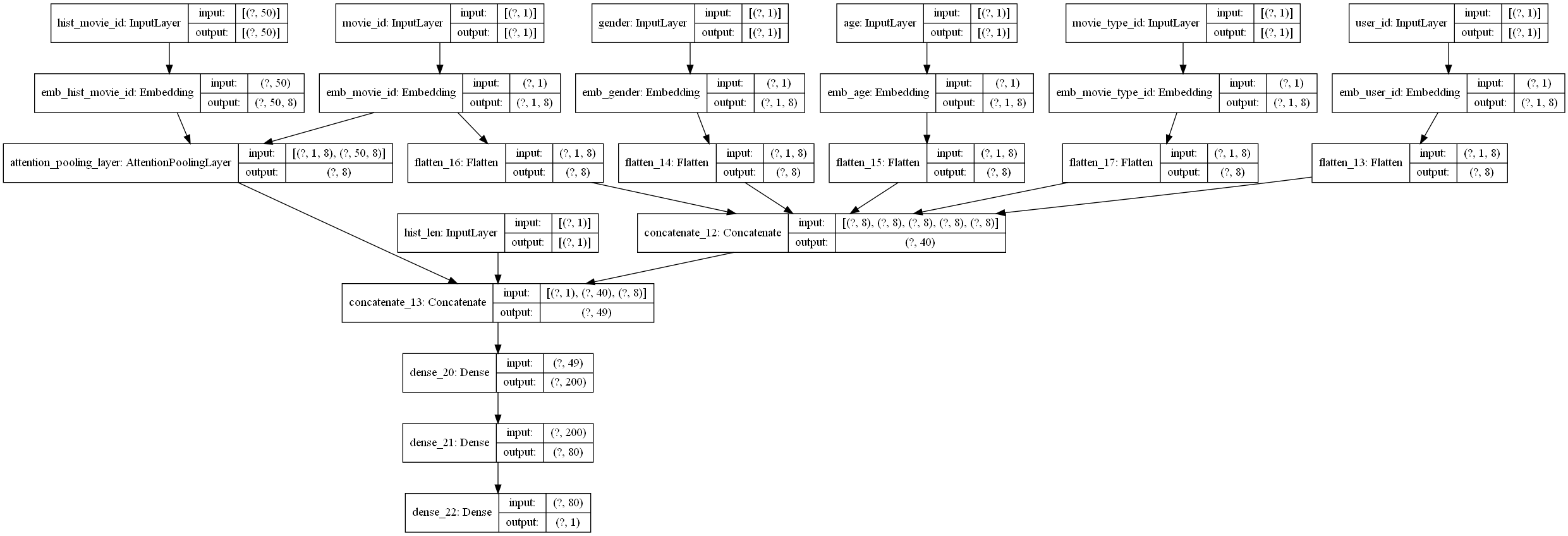
## 3. DIN实现
|
||||
|
||||
下面我们看下DIN的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
|
||||
|
||||
这里主要和大家说一下DIN模型的总体运行逻辑,这样可以让大家从宏观的层面去把握模型的编写过程。该模型所使用的数据集是movielens数据集, 具体介绍可以参考后面的GitHub。 因为上面反复强调了DIN的应用场景,需要基于用户的历史行为数据, 所以在这个数据集中会有用户过去对电影评分的一系列行为。这在之前的数据集中往往是看不到的。 大家可以导入数据之后自行查看这种行为特征(hist_behavior)。另外还有一点需要说明的是这种历史行为是序列性质的特征, 并且**不同的用户这种历史行为特征长度会不一样**, 但是我们的神经网络是要求序列等长的,所以这种情况我们一般会按照最长的序列进行padding的操作(不够长的填0), 而到具体层上进行运算的时候,会用mask掩码的方式标记出这些填充的位置,好保证计算的准确性。 在我们给出的代码中,大家会在AttentionPoolingLayer层的前向传播中看到这种操作。下面开始说编写逻辑:
|
||||
|
||||
首先, DIN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型),也就是指的上面的历史行为数据。而不同的类型特征也就决定了后面处理的方式会不同:
|
||||
|
||||
* Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
|
||||
* Sparse型特征,为离散型特征建立Input层接收输入,然后需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进DNN, 但是这里面要注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。
|
||||
* VarlenSparse型特征:这个一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入AttentionPoolingLayer去对这些历史行为特征加权合并,最后得到输出。
|
||||
|
||||
通过上面的三种处理, 就得到了处理好的连续特征,离散特征和变长离散特征, 接下来把这三种特征拼接,进DNN网络,得到最后的输出结果即可。所以有了这个解释, 就可以放DIN模型的代码全貌了,大家可以感受下我上面解释的:
|
||||
|
||||
```python
|
||||
# DIN网络搭建
|
||||
def DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list):
|
||||
"""
|
||||
这里搭建DIN网络,有了上面的各个模块,这里直接拼起来
|
||||
:param feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是数据的特征封装版
|
||||
:param behavior_feature_list: A list. 用户的候选行为列表
|
||||
:param behavior_seq_feature_list: A list. 用户的历史行为列表
|
||||
"""
|
||||
# 构建Input层并将Input层转成列表作为模型的输入
|
||||
input_layer_dict = build_input_layers(feature_columns)
|
||||
input_layers = list(input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse和Dense特征, 后面要单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns))
|
||||
|
||||
# 获取Dense Input
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
dnn_dense_input.append(input_layer_dict[fc.name])
|
||||
|
||||
# 将所有的dense特征拼接
|
||||
dnn_dense_input = concat_input_list(dnn_dense_input) # (None, dense_fea_nums)
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
|
||||
|
||||
# 离散的这些特特征embedding之后,然后拼接,然后直接作为全连接层Dense的输入,所以需要进行Flatten
|
||||
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
# 将所有的sparse特征embedding特征拼接
|
||||
dnn_sparse_input = concat_input_list(dnn_sparse_embed_input) # (None, sparse_fea_nums*embed_dim)
|
||||
|
||||
# 获取当前行为特征的embedding, 这里有可能有多个行为产生了行为列表,所以需要列表将其放在一起
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 获取历史行为的embedding, 这里有可能有多个行为产生了行为列表,所以需要列表将其放在一起
|
||||
keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 使用注意力机制将历史行为的序列池化,得到用户的兴趣
|
||||
dnn_seq_input_list = []
|
||||
for i in range(len(keys_embed_list)):
|
||||
seq_embed = AttentionPoolingLayer()([query_embed_list[i], keys_embed_list[i]]) # (None, embed_dim)
|
||||
dnn_seq_input_list.append(seq_embed)
|
||||
|
||||
# 将多个行为序列的embedding进行拼接
|
||||
dnn_seq_input = concat_input_list(dnn_seq_input_list) # (None, hist_len*embed_dim)
|
||||
|
||||
# 将dense特征,sparse特征, 即通过注意力机制加权的序列特征拼接起来
|
||||
dnn_input = Concatenate(axis=1)([dnn_dense_input, dnn_sparse_input, dnn_seq_input]) # (None, dense_fea_num+sparse_fea_nums*embed_dim+hist_len*embed_dim)
|
||||
|
||||
# 获取最终的DNN的预测值
|
||||
dnn_logits = get_dnn_logits(dnn_input, activation='prelu')
|
||||
|
||||
model = Model(inputs=input_layers, outputs=dnn_logits)
|
||||
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片DIN_aaaa.png" alt="DIN_aaaa" style="zoom: 50%;" />
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
|
||||
|
||||
## 4. 思考
|
||||
|
||||
DIN模型在工业上的应用还是比较广泛的, 大家可以自由去通过查资料看一下具体实践当中这个模型是怎么用的? 有什么问题?比如行为序列的制作是否合理, 如果时间间隔比较长的话应不应该分一下段? 再比如注意力机制那里能不能改成别的计算注意力的方式会好点?(我们也知道注意力机制的方式可不仅DNN这一种), 再比如注意力权重那里该不该加softmax? 这些其实都是可以值的思考探索的一些问题,根据实际的业务场景,大家也可以总结一些更加有意思的工业上应用该模型的技巧和tricks,欢迎一块讨论和分享。
|
||||
|
||||
|
||||
|
||||
## 5. 参考资料
|
||||
|
||||
* [DIN原论文](https://arxiv.org/pdf/1706.06978.pdf)
|
||||
* [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
* [AI上推荐 之 AFM与DIN模型(当推荐系统遇上了注意力机制)](https://blog.csdn.net/wuzhongqiang/article/details/109532346)
|
||||
* 王喆 - 《深度学习推荐系统》
|
||||
151
DeepRecommendationModel/DeepCrossing.md
Normal file
@@ -0,0 +1,151 @@
|
||||
# DeepCrossing
|
||||
|
||||
## 1. 动机
|
||||
|
||||
这个模型就是一个真正的把深度学习架构应用于推荐系统中的模型了, 2016年由微软提出, 完整的解决了特征工程、稀疏向量稠密化, 多层神经网络进行优化目标拟合等一系列深度学习再推荐系统的应用问题。 这个模型涉及到的技术比较基础,在传统神经网络的基础上加入了embedding,残差连接等思想,且结构比较简单,对初学者复现和学习都比较友好。
|
||||
|
||||
DeepCrossing模型应用场景是微软搜索引擎Bing中的搜索广告推荐, 用户在输入搜索词之后, 搜索引擎除了返回相关结果, 还返回与搜索词相关的广告,Deep Crossing的优化目标就是预测对于某一广告, 用户是否会点击,依然是点击率预测的一个问题。
|
||||
|
||||
这种场景下,我们的输入一般会有类别型特征,比如广告id,和数值型特征,比如广告预算,两种情况。 对于类别型特征,我们需要进行one-hot编码处理,而数值型特征 一般需要进行归一化处理,这样算是把数据进行了一个简单清洗。 DeepCrossing模型就是利用这些特征向量进行CRT预估,那么它的结构长啥样, 又是怎么做CTR预估的呢? 这又是DeepCrossing的核心内容。
|
||||
|
||||
## 2. 模型结构及原理
|
||||
|
||||
为了完成端到端的训练, DeepCrossing模型要在内部网络结构中解决如下问题:
|
||||
|
||||
1. 离散类特征编码后过于稀疏, 不利于直接输入神经网络训练, 需要解决稀疏特征向量稠密化的问题
|
||||
2. 如何解决特征自动交叉组合的问题
|
||||
3. 如何在输出层中达成问题设定的优化目标
|
||||
|
||||
DeepCrossing分别设置了不同神经网络层解决上述问题。模型结构如下
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2020100916594542.png" alt="image-20210217173154706" style="zoom:67%;" />
|
||||
|
||||
下面分别介绍一下各层的作用:
|
||||
|
||||
### 2.1 Embedding Layer
|
||||
|
||||
将稀疏的类别型特征转成稠密的Embedding向量,Embedding的维度会远小于原始的稀疏特征向量。 Embedding是NLP里面常用的一种技术,这里的Feature #1表示的类别特征(one-hot编码后的稀疏特征向量), Feature #2是数值型特征,不用embedding, 直接到了Stacking Layer。 关于Embedding Layer的实现, 往往一个全连接层即可,Tensorflow中有实现好的层可以直接用。 和NLP里面的embedding技术异曲同工, 比如Word2Vec, 语言模型等。
|
||||
|
||||
### 2.2 Stacking Layer
|
||||
|
||||
这个层是把不同的Embedding特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量,该层通常也称为连接层, 具体的实现如下,先将所有的数值特征拼接起来,然后将所有的Embedding拼接起来,最后将数值特征和Embedding特征拼接起来作为DNN的输入,这里TF是通过Concatnate层进行拼接。
|
||||
|
||||
```python
|
||||
#将所有的dense特征拼接到一起
|
||||
dense_dnn_list = list(dense_input_dict.values())
|
||||
dense_dnn_inputs = Concatenate(axis=1)(dense_dnn_list) # B x n (n表示数值特征的数量)
|
||||
|
||||
# 因为需要将其与dense特征拼接到一起所以需要Flatten,不进行Flatten的Embedding层输出的维度为:Bx1xdim
|
||||
sparse_dnn_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
sparse_dnn_inputs = Concatenate(axis=1)(sparse_dnn_list) # B x m*dim (n表示类别特征的数量,dim表示embedding的维度)
|
||||
|
||||
# 将dense特征和Sparse特征拼接到一起
|
||||
dnn_inputs = Concatenate(axis=1)([dense_dnn_inputs, sparse_dnn_inputs]) # B x (n + m*dim)
|
||||
```
|
||||
|
||||
### 2.3 Multiple Residual Units Layer
|
||||
|
||||
该层的主要结构是MLP, 但DeepCrossing采用了残差网络进行的连接。通过多层残差网络对特征向量各个维度充分的交叉组合, 使得模型能够抓取更多的非线性特征和组合特征信息, 增加模型的表达能力。残差网络结构如下图所示:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片20201009193957977.png" alt="image-20210217174914659" style="zoom:67%;" />
|
||||
|
||||
Deep Crossing模型使用稍微修改过的残差单元,它不使用卷积内核,改为了两层神经网络。我们可以看到,残差单元是通过两层ReLU变换再将原输入特征相加回来实现的。具体代码实现如下:
|
||||
|
||||
```python
|
||||
# DNN残差块的定义
|
||||
class ResidualBlock(Layer):
|
||||
def __init__(self, units): # units表示的是DNN隐藏层神经元数量
|
||||
super(ResidualBlock, self).__init__()
|
||||
self.units = units
|
||||
|
||||
def build(self, input_shape):
|
||||
out_dim = input_shape[-1]
|
||||
self.dnn1 = Dense(self.units, activation='relu')
|
||||
self.dnn2 = Dense(out_dim, activation='relu') # 保证输入的维度和输出的维度一致才能进行残差连接
|
||||
def call(self, inputs):
|
||||
x = inputs
|
||||
x = self.dnn1(x)
|
||||
x = self.dnn2(x)
|
||||
x = Activation('relu')(x + inputs) # 残差操作
|
||||
return x
|
||||
```
|
||||
|
||||
### 2.4 Scoring Layer
|
||||
|
||||
这个作为输出层,为了拟合优化目标存在。 对于CTR预估二分类问题, Scoring往往采用逻辑回归,模型通过叠加多个残差块加深网络的深度,最后将结果转换成一个概率值输出。
|
||||
|
||||
```python
|
||||
# block_nums表示DNN残差块的数量
|
||||
def get_dnn_logits(dnn_inputs, block_nums=3):
|
||||
dnn_out = dnn_inputs
|
||||
for i in range(block_nums):
|
||||
dnn_out = ResidualBlock(64)(dnn_out)
|
||||
|
||||
# 将dnn的输出转化成logits
|
||||
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
|
||||
|
||||
return dnn_logits
|
||||
```
|
||||
|
||||
## 3. 总结
|
||||
|
||||
这就是DeepCrossing的结构了,比较清晰和简单,没有引入特殊的模型结构,只是常规的Embedding+多层神经网络。但这个网络模型的出现,有革命意义。DeepCrossing模型中没有任何人工特征工程的参与,只需要简单的特征处理,原始特征经Embedding Layer输入神经网络层,自主交叉和学习。 相比于FM,FFM只具备二阶特征交叉能力的模型,DeepCrossing可以通过调整神经网络的深度进行特征之间的“深度交叉”,这也是Deep Crossing名称的由来。
|
||||
|
||||
如果是用于点击率预估模型的损失函数就是对数损失函数:
|
||||
|
||||
$$
|
||||
logloss=-\frac 1N\sum_1^N(y_ilog(p_i)+(1-y_i)log(1-p_i)
|
||||
$$
|
||||
其中$$y_i$$表示真实的标签(点击或未点击),$$p_i$$表示Scoring Layer输出的结果。但是在实际应用中,根据不同的需求可以灵活替换为其他目标函数。
|
||||
|
||||
## 4. 代码实现
|
||||
|
||||
从模型的代码结构上来看,DeepCrossing的模型输入主要由数值特征和类别特征组成,并将经过Embedding之后的类别特征及类别特征拼接在一起,详细的拼接代码如Staking Layer所示,下面是构建模型的核心代码,详细代码参考github。
|
||||
|
||||
```python
|
||||
def DeepCrossing(dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
#将所有的dense特征拼接到一起
|
||||
dense_dnn_list = list(dense_input_dict.values())
|
||||
dense_dnn_inputs = Concatenate(axis=1)(dense_dnn_list) # B x n (n表示数值特征的数量)
|
||||
|
||||
# 因为需要将其与dense特征拼接到一起所以需要Flatten,不进行Flatten的Embedding层输出的维度为:Bx1xdim
|
||||
sparse_dnn_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
sparse_dnn_inputs = Concatenate(axis=1)(sparse_dnn_list) # B x m*dim (n表示类别特征的数量,dim表示embedding的维度)
|
||||
|
||||
# 将dense特征和Sparse特征拼接到一起
|
||||
dnn_inputs = Concatenate(axis=1)([dense_dnn_inputs, sparse_dnn_inputs]) # B x (n + m*dim)
|
||||
|
||||
# 输入到dnn中,需要提前定义需要几个残差块
|
||||
output_layer = get_dnn_logits(dnn_inputs, block_nums=3)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210304222328047.png" alt="image-20210304222328047" style="zoom:67%;" />
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||

|
||||
|
||||
## 5. 参考资料
|
||||
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
- [论文原文](https://www.kdd.org/kdd2016/papers/files/adf0975-shanA.pdf)
|
||||
|
||||
- [AI上推荐 之 AutoRec与Deep Crossing模型(改变神经网络的复杂程度)](https://blog.csdn.net/wuzhongqiang/article/details/108948440)
|
||||
|
||||
163
DeepRecommendationModel/DeepFM.md
Normal file
@@ -0,0 +1,163 @@
|
||||
# DeepFM
|
||||
|
||||
## 1. 动机
|
||||
|
||||
对于CTR问题,被证明的最有效的提升任务表现的策略是特征组合(Feature Interaction), 在CTR问题的探究历史上来看就是如何更好地学习特征组合,进而更加精确地描述数据的特点。可以说这是基础推荐模型到深度学习推荐模型遵循的一个主要的思想。而组合特征大牛们研究过组合二阶特征,三阶甚至更高阶,但是面临一个问题就是随着阶数的提升,复杂度就成几何倍的升高。这样即使模型的表现更好了,但是推荐系统在实时性的要求也不能满足了。所以很多模型的出现都是为了解决另外一个更加深入的问题:如何更高效的学习特征组合?
|
||||
|
||||
为了解决上述问题,出现了FM和FFM来优化LR的特征组合较差这一个问题。并且在这个时候科学家们已经发现了DNN在特征组合方面的优势,所以又出现了FNN和PNN等使用深度网络的模型。但是DNN也存在局限性。
|
||||
|
||||
- ==DNN局限==
|
||||
当我们使用DNN网络解决推荐问题的时候存在网络参数过于庞大的问题,这是因为在进行特征处理的时候我们需要使用one-hot编码来处理离散特征,这会导致输入的维度猛增。这里借用AI大会的一张图片:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-15.png" style="zoom: 50%;" />
|
||||
|
||||
这样庞大的参数量也是不实际的。为了解决DNN参数量过大的局限性,可以采用非常经典的Field思想,将OneHot特征转换为Dense Vector
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-40.png" style="zoom: 50%;" />
|
||||
|
||||
此时通过增加全连接层就可以实现高阶的特征组合,如下图所示:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-11-59.png" style="zoom:67%;" />
|
||||
|
||||
但是仍然缺少低阶的特征组合,于是增加FM来表示低阶的特征组合。
|
||||
|
||||
- ==FNN和PNN==
|
||||
|
||||
结合FM和DNN其实有两种方式,可以并行结合也可以串行结合。这两种方式各有几种代表模型。在DeepFM之前有FNN,虽然在影响力上可能并不如DeepFM,但是了解FNN的思想对我们理解DeepFM的特点和优点是很有帮助的。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2021-02-22-10-12-19.png" style="zoom:50%;" />
|
||||
|
||||
FNN是使用预训练好的FM模块,得到隐向量,然后把隐向量作为DNN的输入,但是经过实验进一步发现,在Embedding layer和hidden layer1之间增加一个product层(如上图所示)可以提高模型的表现,所以提出了PNN,使用product layer替换FM预训练层。
|
||||
|
||||
- ==Wide&Deep==
|
||||
|
||||
FNN和PNN模型仍然有一个比较明显的尚未解决的缺点:对于低阶组合特征学习到的比较少,这一点主要是由于FM和DNN的串行方式导致的,也就是虽然FM学到了低阶特征组合,但是DNN的全连接结构导致低阶特征并不能在DNN的输出端较好的表现。看来我们已经找到问题了,将串行方式改进为并行方式能比较好的解决这个问题。于是Google提出了Wide&Deep模型(将前几章),但是如果深入探究Wide&Deep的构成方式,虽然将整个模型的结构调整为了并行结构,在实际的使用中Wide Module中的部分需要较为精巧的特征工程,换句话说人工处理对于模型的效果具有比较大的影响(这一点可以在Wide&Deep模型部分得到验证)。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
|
||||
|
||||
如上图所示,该模型仍然存在问题:**在output Units阶段直接将低阶和高阶特征进行组合,很容易让模型最终偏向学习到低阶或者高阶的特征,而不能做到很好的结合。**
|
||||
|
||||
综上所示,DeepFM模型横空出世。
|
||||
|
||||
## 2. 模型的结构与原理
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225180556628.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
|
||||
前面的Field和Embedding处理是和前面的方法是相同的,如上图中的绿色部分;DeepFM将Wide部分替换为了FM layer如上图中的蓝色部分
|
||||
|
||||
这幅图其实有很多的点需要注意,很多人都一眼略过了,这里我个人认为在DeepFM模型中有三点需要注意:
|
||||
|
||||
- **Deep模型部分**
|
||||
- **FM模型部分**
|
||||
- **Sparse Feature中黄色和灰色节点代表什么意思**
|
||||
|
||||
### 2.1 FM
|
||||
|
||||
详细内容参考FM模型部分的内容,下图是FM的一个结构图,从图中大致可以看出FM Layer是由一阶特征和二阶特征Concatenate到一起在经过一个Sigmoid得到logits(结合FM的公式一起看),所以在实现的时候需要单独考虑linear部分和FM交叉特征部分。
|
||||
$$
|
||||
\hat{y}_{FM}(x) = w_0+\sum_{i=1}^N w_ix_i + \sum_{i=1}^N \sum_{j=i+1}^N v_i^T v_j x_ix_j
|
||||
$$
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225181340313.png" alt="image-20210225181340313" style="zoom: 67%;" />
|
||||
|
||||
### 2.2 Deep
|
||||
|
||||
Deep架构图
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225181010107.png" alt="image-20210225181010107" style="zoom:50%;" />
|
||||
|
||||
Deep Module是为了学习高阶的特征组合,在上图中使用用全连接的方式将Dense Embedding输入到Hidden Layer,这里面Dense Embeddings就是为了解决DNN中的参数爆炸问题,这也是推荐模型中常用的处理方法。
|
||||
|
||||
Embedding层的输出是将所有id类特征对应的embedding向量concat到到一起输入到DNN中。其中$v_i$表示第i个field的embedding,m是field的数量。
|
||||
$$
|
||||
z_1=[v_1, v_2, ..., v_m]
|
||||
$$
|
||||
上一层的输出作为下一层的输入,我们得到:
|
||||
$$
|
||||
z_L=\sigma(W_{L-1} z_{L-1}+b_{L-1})
|
||||
$$
|
||||
其中$\sigma$表示激活函数,$z, W, b $分别表示该层的输入、权重和偏置。
|
||||
|
||||
最后进入DNN部分输出使用sigmod激活函数进行激活:
|
||||
$$
|
||||
y_{DNN}=\sigma(W^{L}a^L+b^L)
|
||||
$$
|
||||
|
||||
|
||||
## 3. 代码实现
|
||||
|
||||
DeepFM在模型的结构图中显示,模型大致由两部分组成,一部分是FM,还有一部分就是DNN, 而FM又由一阶特征部分与二阶特征交叉部分组成,所以可以将整个模型拆成三部分,分别是一阶特征处理linear部分,二阶特征交叉FM以及DNN的高阶特征交叉。在下面的代码中也能够清晰的看到这个结构。此外每一部分可能由是由不同的特征组成,所以在构建模型的时候需要分别对这三部分输入的特征进行选择。
|
||||
|
||||
- linear_logits: 这部分是有关于线性计算,也就是FM的前半部分$w1x1+w2x2...wnxn+b$的计算。对于这一块的计算,我们用了一个get_linear_logits函数实现,后面再说,总之通过这个函数,我们就可以实现上面这个公式的计算过程,得到linear的输出, 这部分特征由数值特征和类别特征的onehot编码组成的一维向量组成,实际应用中根据自己的业务放置不同的一阶特征(这里的dense特征并不是必须的,有可能会将数值特征进行分桶,然后在当做类别特征来处理)
|
||||
|
||||
- fm_logits: 这一块主要是针对离散的特征,首先过embedding,然后使用FM特征交叉的方式,两两特征进行交叉,得到新的特征向量,最后计算交叉特征的logits
|
||||
|
||||
- dnn_logits: 这一块主要是针对离散的特征,首先过embedding,然后将得到的embedding拼接成一个向量(具体的可以看代码,也可以看一下下面的模型结构图),通过dnn学习类别特征之间的隐式特征交叉并输出logits值
|
||||
|
||||
```python
|
||||
def DeepFM(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# embedding层用户构建FM交叉部分和DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 将输入到dnn中的所有sparse特征筛选出来
|
||||
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
fm_logits = get_fm_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # 只考虑二阶项
|
||||
|
||||
# 将所有的Embedding都拼起来,一起输入到dnn中
|
||||
dnn_logits = get_dnn_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
|
||||
|
||||
# 将linear,FM,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, fm_logits, dnn_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layers)
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210228161135777.png" alt="image-20210228161135777" />
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
## 4. 思考
|
||||
|
||||
1. 如果对于FM采用随机梯度下降SGD训练模型参数,请写出模型各个参数的梯度和FM参数训练的复杂度
|
||||
|
||||
2. 对于下图所示,根据你的理解Sparse Feature中的不同颜色节点分别表示什么意思
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210225180556628.png" alt="image-20210225180556628" style="zoom:50%;" />
|
||||
|
||||
|
||||
|
||||
## 5. 参考资料
|
||||
|
||||
- [论文原文](https://arxiv.org/pdf/1703.04247.pdf)
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
|
||||
- [FM](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommendationSystemFundamentals/04%20FM.md)
|
||||
- [推荐系统遇上深度学习(三)--DeepFM模型理论和实践](https://www.jianshu.com/p/6f1c2643d31b)
|
||||
|
||||
- [深度推荐模型之DeepFM](https://zhuanlan.zhihu.com/p/57873613)
|
||||
[详解 Wide & Deep 结构背后的动机](https://zhuanlan.zhihu.com/p/53361519)
|
||||
[FM算法公式推导](https://blog.csdn.net/qq_32486393/article/details/103498519)
|
||||
160
DeepRecommendationModel/NFM.md
Normal file
@@ -0,0 +1,160 @@
|
||||
# NFM
|
||||
|
||||
## 1. 动机
|
||||
|
||||
NFM(Neural Factorization Machines)是2017年由新加坡国立大学的何向南教授等人在SIGIR会议上提出的一个模型,传统的FM模型仅局限于线性表达和二阶交互, 无法胜任生活中各种具有复杂结构和规律性的真实数据, 针对FM的这点不足, 作者提出了一种将FM融合进DNN的策略,通过引进了一个特征交叉池化层的结构,使得FM与DNN进行了完美衔接,这样就组合了FM的建模低阶特征交互能力和DNN学习高阶特征交互和非线性的能力,形成了深度学习时代的神经FM模型(NFM)。
|
||||
|
||||
那么NFM具体是怎么做的呢? 首先看一下NFM的公式:
|
||||
$$
|
||||
\hat{y}_{N F M}(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+f(\mathbf{x})
|
||||
$$
|
||||
我们对比FM, 就会发现变化的是第三项,前两项还是原来的, 因为我们说FM的一个问题,就是只能到二阶交叉, 且是线性模型, 这是他本身的一个局限性, 而如果想突破这个局限性, 就需要从他的公式本身下点功夫, 于是乎,作者在这里改进的思路就是**用一个表达能力更强的函数来替代原FM中二阶隐向量内积的部分**。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片1.png" style="zoom:70%;" />
|
||||
|
||||
而这个表达能力更强的函数呢, 我们很容易就可以想到神经网络来充当,因为神经网络理论上可以拟合任何复杂能力的函数, 所以作者真的就把这个$f(x)$换成了一个神经网络,当然不是一个简单的DNN, 而是依然底层考虑了交叉,然后高层使用的DNN网络, 这个也就是我们最终的NFM网络了:
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片2.png" style="zoom:80%;" />
|
||||
|
||||
这个结构,如果前面看过了PNN的伙伴会发现,这个结构和PNN非常像,只不过那里是一个product_layer, 而这里换成了Bi-Interaction Pooling了, 这个也是NFM的核心结构了。这里注意, 这个结构中,忽略了一阶部分,只可视化出来了$f(x)$, 我们还是下面从底层一点点的对这个网络进行剖析。
|
||||
|
||||
## 2. 模型结构与原理
|
||||
|
||||
### 2.1 Input 和Embedding层
|
||||
|
||||
输入层的特征, 文章指定了稀疏离散特征居多, 这种特征我们也知道一般是先one-hot, 然后会通过embedding,处理成稠密低维的。 所以这两层还是和之前一样,假设$\mathbf{v}_{\mathbf{i}} \in \mathbb{R}^{k}$为第$i$个特征的embedding向量, 那么$\mathcal{V}_{x}=\left\{x_{1} \mathbf{v}_{1}, \ldots, x_{n} \mathbf{v}_{n}\right\}$表示的下一层的输入特征。这里带上了$x_i$是因为很多$x_i$转成了One-hot之后,出现很多为0的, 这里的$\{x_iv_i\}$是$x_i$不等于0的那些特征向量。
|
||||
|
||||
### 2.2 Bi-Interaction Pooling layer
|
||||
|
||||
在Embedding层和神经网络之间加入了特征交叉池化层是本网络的核心创新了,正是因为这个结构,实现了FM与DNN的无缝连接, 组成了一个大的网络,且能够正常的反向传播。假设$\mathcal{V}_{x}$是所有特征embedding的集合, 那么在特征交叉池化层的操作:
|
||||
|
||||
$$
|
||||
f_{B I}\left(\mathcal{V}_{x}\right)=\sum_{i=1}^{n} \sum_{j=i+1}^{n} x_{i} \mathbf{v}_{i} \odot x_{j} \mathbf{v}_{j}
|
||||
$$
|
||||
|
||||
$\odot$表示两个向量的元素积操作,即两个向量对应维度相乘得到的元素积向量(可不是点乘呀),其中第$k$维的操作:
|
||||
$$
|
||||
\left(v_{i} \odot v_{j}\right)_{k}=\boldsymbol{v}_{i k} \boldsymbol{v}_{j k}
|
||||
$$
|
||||
|
||||
这便定义了在embedding空间特征的二阶交互,这个不仔细看会和感觉FM的最后一项很像,但是不一样,一定要注意这个地方不是两个隐向量的内积,而是元素积,也就是这一个交叉完了之后k个维度不求和,最后会得到一个$k$维向量,而FM那里内积的话最后得到一个数, 在进行两两Embedding元素积之后,对交叉特征向量取和, 得到该层的输出向量, 很显然, 输出是一个$k$维的向量。
|
||||
|
||||
注意, 之前的FM到这里其实就完事了, 上面就是输出了,而这里很大的一点改进就是加入特征池化层之后, 把二阶交互的信息合并, 且上面接了一个DNN网络, 这样就能够增强FM的表达能力了, 因为FM只能到二阶, 而这里的DNN可以进行多阶且非线性,只要FM把二阶的学习好了, DNN这块学习来会更加容易, 作者在论文中也说明了这一点,且通过后面的实验证实了这个观点。
|
||||
|
||||
如果不加DNN, NFM就退化成了FM,所以改进的关键就在于加了一个这样的层,组合了一下二阶交叉的信息,然后又给了DNN进行高阶交叉的学习,成了一种“加强版”的FM。
|
||||
|
||||
Bi-Interaction层不需要额外的模型学习参数,更重要的是它在一个线性的时间内完成计算,和FM一致的,即时间复杂度为$O\left(k N_{x}\right)$,$N_x$为embedding向量的数量。参考FM,可以将上式转化为:
|
||||
$$
|
||||
f_{B I}\left(\mathcal{V}_{x}\right)=\frac{1}{2}\left[\left(\sum_{i=1}^{n} x_{i} \mathbf{v}_{i}\right)^{2}-\sum_{i=1}^{n}\left(x_{i} \mathbf{v}_{i}\right)^{2}\right]
|
||||
$$
|
||||
后面代码复现NFM就是用的这个公式直接计算,比较简便且清晰。
|
||||
|
||||
### 2.3 隐藏层
|
||||
|
||||
这一层就是全连接的神经网络, DNN在进行特征的高层非线性交互上有着天然的学习优势,公式如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\mathbf{z}_{1}=&\sigma_{1}\left(\mathbf{W}_{1} f_{B I}
|
||||
\left(\mathcal{V}_{x}\right)+\mathbf{b}_{1}\right) \\
|
||||
\mathbf{z}_{2}=& \sigma_{2}\left(\mathbf{W}_{2} \mathbf{z}_{1}+\mathbf{b}_{2}\right) \\
|
||||
\ldots \ldots \\
|
||||
\mathbf{z}_{L}=& \sigma_{L}\left(\mathbf{W}_{L} \mathbf{z}_{L-1}+\mathbf{b}_{L}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这里的$\sigma_i$是第$i$层的激活函数,可不要理解成sigmoid激活函数。
|
||||
|
||||
### 2.4 预测层
|
||||
|
||||
这个就是最后一层的结果直接过一个隐藏层,但注意由于这里是回归问题,没有加sigmoid激活:
|
||||
$$
|
||||
f(\mathbf{x})=\mathbf{h}^{T} \mathbf{z}_{L}
|
||||
$$
|
||||
|
||||
所以, NFM模型的前向传播过程总结如下:
|
||||
$$
|
||||
\begin{aligned}
|
||||
\hat{y}_{N F M}(\mathbf{x}) &=w_{0}+\sum_{i=1}^{n} w_{i} x_{i} \\
|
||||
&+\mathbf{h}^{T} \sigma_{L}\left(\mathbf{W}_{L}\left(\ldots \sigma_{1}\left(\mathbf{W}_{1} f_{B I}\left(\mathcal{V}_{x}\right)+\mathbf{b}_{1}\right) \ldots\right)+\mathbf{b}_{L}\right)
|
||||
\end{aligned}
|
||||
$$
|
||||
这就是NFM模型的全貌, NFM相比较于其他模型的核心创新点是特征交叉池化层,基于它,实现了FM和DNN的无缝连接,使得DNN可以在底层就学习到包含更多信息的组合特征,这时候,就会减少DNN的很多负担,只需要很少的隐藏层就可以学习到高阶特征信息。NFM相比之前的DNN, 模型结构更浅,更简单,但是性能更好,训练和调参更容易。集合FM二阶交叉线性和DNN高阶交叉非线性的优势,非常适合处理稀疏数据的场景任务。在对NFM的真实训练过程中,也会用到像Dropout和BatchNormalization这样的技术来缓解过拟合和在过大的改变数据分布。
|
||||
|
||||
下面通过代码看下NFM的具体实现过程, 学习一些细节。
|
||||
|
||||
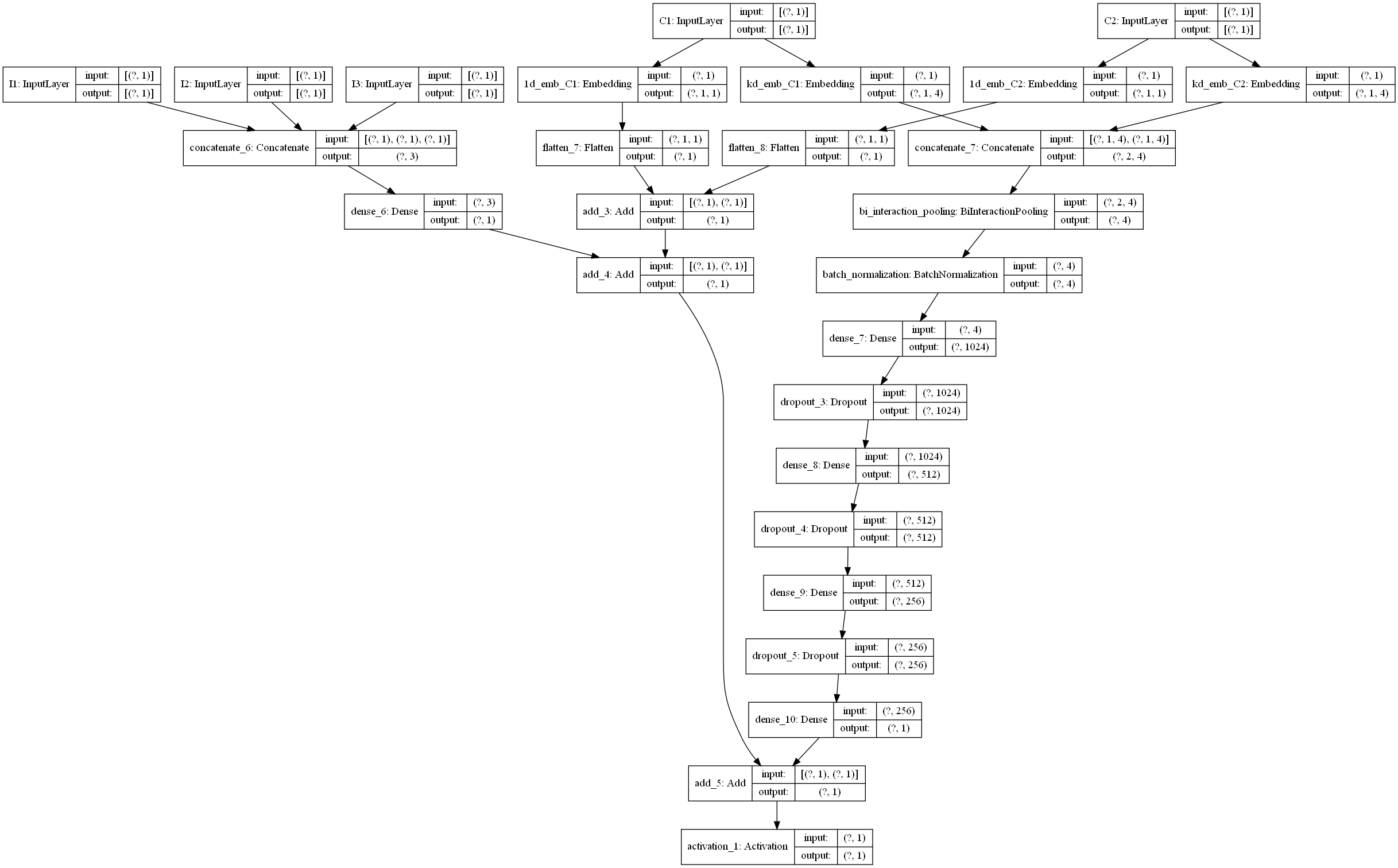
## 3. 代码实现
|
||||
|
||||
下面我们看下NFM的代码复现,这里主要是给大家说一下这个模型的设计逻辑,参考了deepctr的函数API的编程风格, 具体的代码以及示例大家可以去参考后面的GitHub,里面已经给出了详细的注释, 这里主要分析模型的逻辑这块。关于函数API的编程式风格,我们还给出了一份文档, 大家可以先看这个,再看后面的代码部分,会更加舒服些。下面开始:
|
||||
|
||||
这里主要说一下NFM模型的总体运行逻辑, 这样可以让大家从宏观的层面去把握模型的设计过程, 该模型所使用的数据集是criteo数据集,具体介绍参考后面的GitHub。 数据集的特征会分为dense特征(连续)和sparse特征(离散), 所以模型的输入层接收这两种输入。但是我们这里把输入分成了linear input和dnn input两种情况,而每种情况都有可能包含上面这两种输入。因为我们后面的模型逻辑会分这两部分走,这里有个细节要注意,就是光看上面那个NFM模型的话,是没有看到它线性特征处理的那部分的,也就是FM的前半部分公式那里图里面是没有的。但是这里我们要加上。
|
||||
$$
|
||||
\hat{y}_{N F M}(\mathbf{x})=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+f(\mathbf{x})
|
||||
$$
|
||||
所以模型的逻辑我们分成了两大部分,这里我分别给大家解释下每一块做了什么事情:
|
||||
|
||||
1. linear part: 这部分是有关于线性计算,也就是FM的前半部分$w1x1+w2x2...wnxn+b$的计算。对于这一块的计算,我们用了一个get_linear_logits函数实现,后面再说,总之通过这个函数,我们就可以实现上面这个公式的计算过程,得到linear的输出
|
||||
2. dnn part: 这部分是后面交叉特征的那部分计算,FM的最后那部分公式f(x)。 这一块主要是针对离散的特征,首先过embedding, 然后过特征交叉池化层,这个计算我们用了get_bi_interaction_pooling_output函数实现, 得到输出之后又过了DNN网络,最后得到dnn的输出
|
||||
|
||||
模型的最后输出结果,就是把这两个部分的输出结果加和(当然也可以加权),再过一个sigmoid得到。所以NFM的模型定义就出来了:
|
||||
|
||||
```python
|
||||
def NFM(linear_feature_columns, dnn_feature_columns):
|
||||
"""
|
||||
搭建NFM模型,上面已经把所有组块都写好了,这里拼起来就好
|
||||
:param linear_feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是linear数据的特征封装版
|
||||
:param dnn_feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是DNN数据的特征封装版
|
||||
"""
|
||||
# 构建输入层,即所有特征对应的Input()层, 这里使用字典的形式返回, 方便后续构建模型
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns+dnn_feature_columns)
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 线性部分的计算 w1x1 + w2x2 + ..wnxn + b部分,dense特征和sparse两部分的计算结果组成,具体看上面细节
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_feature_columns)
|
||||
|
||||
# DNN部分的计算
|
||||
# 首先,在这里构建DNN部分的embedding层,之所以写在这里,是为了灵活的迁移到其他网络上,这里用字典的形式返回
|
||||
# embedding层用于构建FM交叉部分以及DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 过特征交叉池化层
|
||||
pooling_output = get_bi_interaction_pooling_output(sparse_input_dict, dnn_feature_columns, embedding_layers)
|
||||
|
||||
# 加个BatchNormalization
|
||||
pooling_output = BatchNormalization()(pooling_output)
|
||||
|
||||
# dnn部分的计算
|
||||
dnn_logits = get_dnn_logits(pooling_output)
|
||||
|
||||
# 线性部分和dnn部分的结果相加,最后再过个sigmoid
|
||||
output_logits = Add()([linear_logits, dnn_logits])
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(inputs=input_layers, outputs=output_layers)
|
||||
|
||||
return model
|
||||
```
|
||||
|
||||
有了上面的解释,这个模型的宏观层面相信就很容易理解了。关于这每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片NFM_aaaa.png" alt="NFM_aaaa" style="zoom: 50%;" />
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
|
||||
|
||||
## 4. 思考题
|
||||
|
||||
1. NFM中的特征交叉与FM中的特征交叉有何异同,分别从原理和代码实现上进行对比分析
|
||||
|
||||
|
||||
|
||||
## 5. 参考资料
|
||||
|
||||
- [论文原文](https://arxiv.org/pdf/1708.05027.pdf)
|
||||
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
|
||||
- [AI上推荐 之 FNN、DeepFM与NFM(FM在深度学习中的身影重现)](https://blog.csdn.net/wuzhongqiang/article/details/109532267?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161442951716780255224635%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=161442951716780255224635&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v1~rank_blog_v1-1-109532267.pc_v1_rank_blog_v1&utm_term=NFM)
|
||||
|
||||
- 王喆 - 《深度学习推荐系统》
|
||||
117
DeepRecommendationModel/NeuralCF.md
Normal file
@@ -0,0 +1,117 @@
|
||||
# NeuralCF
|
||||
|
||||
## 1.动机
|
||||
|
||||
在前面的组队学习中,我们学习了最经典的推荐算法,协同过滤。在前深度学习的时代,协同过滤曾经大放异彩,但随着技术的发展,协同过滤相比深度学习模型的弊端就日益显现出来了,因为它是通过直接利用非常稀疏的共现矩阵进行预测的,所以模型的泛化能力非常弱,遇到历史行为非常少的用户,就没法产生准确的推荐结果了。虽然,我们可以通过矩阵分解算法增强它的泛化能力,但因为矩阵分解是利用非常简单的内积方式来处理用户向量和物品向量的交叉问题的,所以,它的拟合能力也比较弱。这该怎么办呢?不是说深度学习模型的拟合能力都很强吗?我们能不能利用深度学习来改进协同过滤算法呢?当然是可以的。2017 年,新加坡国立的研究者就使用深度学习网络来改进了传统的协同过滤算法,取名 NeuralCF(神经网络协同过滤)。NeuralCF 大大提高了协同过滤算法的泛化能力和拟合能力,让这个经典的推荐算法又重新在深度学习时代焕发生机。这章节,我们就一起来学习并实现 NeuralCF!
|
||||
|
||||
## 2.模型结构及原理
|
||||
|
||||
<img src="https://static001.geekbang.org/resource/image/5f/2c/5ff301f11e686eedbacd69dee184312c.jpg" alt="image-20210210101954221" style="zoom: 33%;" />
|
||||
|
||||
Neural collaborative filtering framework
|
||||
|
||||
为了允许神经网络对协同过滤进行一个完整的处理,我们采用上图展示的多层感知机去模拟一个用户项目交互$y_{ui}$,它的一层的输出作为下一层的输入。底部输入层包括两个特征向量$v^U_u$和$v^I_i$ ,分别用来描述用户$u$和项目$i$。 他们可以进行定制,用以支持广泛的用户和项目的建模,例如上下文感知,基于内容,和基于邻居的构建方式。由于本章工作的重点是纯的协同过滤模型设置,我们仅使用一个用户和一个项目作为输入特征,它使用$one-hot$编码将它们转化为二值化稀疏向量。注意到,我们对输入使用这样的通用特征表示,可以很容易地使用的内容特征来表示用户和项目,以调整解决冷启动问题。
|
||||
|
||||
输入层上面是嵌入层$(Embedding Layer)$;它是一个全连接层,用来将输入层的稀疏特征向量映射为一个稠密向量$(dense vector)$。所获得的用户(项目)的嵌入(就是一个稠密向量)可以被看作是在潜在因素模型的上下文中用于描述用户(项目)的潜在向量。然后我们将用户嵌入和项目嵌入送入多层神经网络中,我们将它称为神经网络协同过滤层,它将潜在向量映射为预测分数。NCF层的每一层都可以被定制,用以发现用户-项目交互的某些潜在结构。最后一个隐藏层 $X$ 的维度尺寸决定了模型的能力。最终输出层是预测分数$\hat{y}_{ui}$,通过最小化预测值$\hat{y}_{ui}$和其目标值$y_{ui}$之间逐点损失进行训练。
|
||||
|
||||
论文中主要运用均方误差$(squared loss)$进行回归:
|
||||
$$
|
||||
L_{sqr}=\sum_{(u,i)\in y\cup y^-}w_{ui}(y_{ui}-\hat{y}_{ui})^2
|
||||
$$
|
||||
其中$ y$表示交互矩阵$Y$中观察到的条目(如对电影有明确的评分,评级), $y^-$表示负样本($negative instances$,可以将未观察的样本全体视为负样本,或者采取抽样的方式标记为负样本); $w_{ui}$是一个超参数,用来表示训练样本$(u,i)$的权重。虽然均方误差可以通过假设观测服从高斯分布来作出解释,但是它不适合处理隐性数据$(implicit data)$。这是因为对于隐含数据来说,目标值 $y_{ui}$是二进制值$1$或$0$,表示$u$是否与$i$进行了互动。在下文中提出了逐点学习NCF的概率学方法,特别注重隐性数据的二进制属性。
|
||||
|
||||
考虑到隐性反馈的一类性质,我们可以将$y_{ui}$的值作为一个标签------$1$表示项目$i$和用户$u$相关,$0$表达不相关。这样一来预测分数$\hat{y}_{ui}$就代表了项目$i$和用户$u$相关的可能性大小。为了赋予NCF这样的概率解释,我们需要将网络输出限制到$[0,1]$的范围内,通过使用概率函数(逻辑函数$sigmoid$或者$probit$函数)作为激活函数作用在输出层$\phi_{out}$,我们可以很容易地实现数据压缩。经过以上设置后,我们这样定义似然函数:
|
||||
$$
|
||||
p(y,y^-|P,Q,\Theta_f)=\prod_{(u,i)\in{y}}\hat{y}_{ui}\prod_{(u,j)\in{y^-}}(1-\hat{y}_{uj})
|
||||
$$
|
||||
对似然函数取负对数,我们得到(负对数可以用来表示$Loss$函数,而且还能消除小数乘法的下溢出问题):
|
||||
$$
|
||||
L=-\sum_{(u,i)\in{y}}log\hat{y}_{ui}-\sum_{(u,j)\in{y^-}}log(1-\hat{y}_{uj})=-\sum_{(u,i)\in{y}\cup{y}^-}y_{ui}log \hat{y}_{ui}+(1-y_{ui})log(1-\hat{y}_{ui})
|
||||
$$
|
||||
这是NCF需要去最小化的目标函数,并且可以通过使用随机梯度下降$(SGD)$来进行训练优化。这个函数和交叉熵损失函数$(binary cross-entropy loss,又被成为log loss)$是一样的。通过在NCF上使用这样一个概率处理$(probabilistic treatment)$,我们把隐性反馈的推荐问题当做一个二分类问题来解决。对于负样本 $y^-$ ,我们在每次迭代均匀地从未观察到的相互作用中采样(作为负样本)并且对照可观察到交互的数量,控制采样比率。
|
||||
|
||||
我们现在来证明MF是如何被解释为我们的NCF框架的一个特例。由于MF是推荐领域最流行的模型,并已在众多文献中被广泛的研究,复现它能证明NCF可以模拟大部分的分解模型。由于输入层是用户(项目)ID中的一个$one-hot encoding$编码,所获得的嵌入向量可以被看作是用户(项目)的潜在向量。我们用$P^Tv^U_u$表示用户的潜在向量$p_u$,$Q^Tv^I_i$表示项目的潜在向量$q_i$ ,我们定义第一层神经CF层的映射函数为:
|
||||
$$
|
||||
\phi(p_u,q_i)=p_u\odot q_i
|
||||
$$
|
||||
其中$\odot$表示向量的逐元素乘积。然后,我们将向量映射到输出层:
|
||||
$$
|
||||
\hat{y}_{ui}=a_{out}(h^T(p_u\odot q_i))
|
||||
$$
|
||||
其中$a_{out}$和$h$分别表示输出层的激活函数和连接权。直观地讲,如果我们将$a_{out}$看做一个恒等函数, $h$权重全为1,显然这就是我们的MF模型。在NCF的框架下,MF可以很容易地被泛化和推广。例如,如果我们允许从没有一致性约束(uniform constraint)的数据中学习$h$,则会形成MF的变体,它允许潜在维度的不同重要性(For example, if we allow h to be learnt from data without the uniform constraint, it will result in a variant of MF that allows varying importance of latent dimensions)。如果我们用一个非线性函数$a_{out}$将进一步推广MF到非线性集合,使得模型比线性MF模型更具有表现力。在NCF下实现一个更一般化的MF,它使用Sigmoid函数$\sigma(x)=1/1(1+e^{-x})$作为激活函数,通过$log loss$学习 $h$。称为GMF(Generalized Matrix Factorization,广义矩阵分解)。
|
||||
|
||||
<img src="https://img-blog.csdnimg.cn/20201019200457212.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3d1emhvbmdxaWFuZw==,size_1,color_FFFFFF,t_70#pic_center" style="zoom: 67%;" />
|
||||
|
||||
GMF,它应用了一个线性内核来模拟潜在的特征交互;MLP,使用非线性内核从数据中学习交互函数。接下来的问题是:我们如何能够在NCF框架下融合GMF和MLP,使他们能够相互强化,以更好地对复杂的用户-项目交互建模?一个直接的解决方法是让GMF和MLP共享相同的嵌入层(Embedding Layer),然后再结合它们分别对相互作用的函数输出。这种方式和著名的神经网络张量(NTN,Neural Tensor Network)有点相似。然而,共享GMF和MLP的嵌入层可能会限制融合模型的性能。例如,它意味着,GMF和MLP必须使用的大小相同的嵌入;对于数据集,两个模型的最佳嵌入尺寸差异很大,使得这种解决方案可能无法获得最佳的组合。为了使得融合模型具有更大的灵活性,我们允许GMF和MLP学习独立的嵌入,并结合两种模型通过连接他们最后的隐层输出。
|
||||
|
||||
|
||||
## 3.代码实现
|
||||
|
||||
从模型的结构上来看,NeuralCF的模型其实是在矩阵分解上进行了加强,用MLP代替了inner product,下面是构建模型的核心代码,详细代码参考github。
|
||||
|
||||
```python
|
||||
def NCF(dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
_, sparse_input_dict = build_input_layers(dnn_feature_columns) # 没有dense特征
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(sparse_input_dict.values())
|
||||
|
||||
# 创建两份embedding向量, 由于Embedding层的name不能相同,所以这里加入一个prefix参数
|
||||
GML_embedding_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False, prefix='GML')
|
||||
MLP_embedding_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False, prefix='MLP')
|
||||
|
||||
# 构建GML的输出
|
||||
GML_user_emb = Flatten()(GML_embedding_dict['user_id'](sparse_input_dict['user_id'])) # B x embed_dim
|
||||
GML_item_emb = Flatten()(GML_embedding_dict['movie_id'](sparse_input_dict['movie_id'])) # B x embed_dim
|
||||
GML_out = tf.multiply(GML_user_emb, GML_item_emb) # 按元素相乘
|
||||
|
||||
# 构建MLP的输出
|
||||
MLP_user_emb = Flatten()(MLP_embedding_dict['user_id'](sparse_input_dict['user_id'])) # B x embed_dim
|
||||
MLP_item_emb = Flatten()(MLP_embedding_dict['movie_id'](sparse_input_dict['movie_id'])) # B x embed_dim
|
||||
MLP_dnn_input = Concatenate(axis=1)([MLP_user_emb, MLP_item_emb]) # 两个向量concat
|
||||
MLP_dnn_out = get_dnn_out(MLP_dnn_input, (32, 16))
|
||||
|
||||
# 将dense特征和Sparse特征拼接到一起
|
||||
concat_out = Concatenate(axis=1)([GML_out, MLP_dnn_out])
|
||||
|
||||
# 输入到dnn中,需要提前定义需要几个残差块
|
||||
# output_layer = Dense(1, 'sigmoid')(concat_out)
|
||||
output_layer = Dense(1)(concat_out)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。
|
||||
|
||||

|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
## 4.思考
|
||||
|
||||
如何用双塔结构实现NeuralCF?
|
||||
|
||||
|
||||
|
||||
## 5.参考资料
|
||||
|
||||
[deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
|
||||
[论文原文](https://arxiv.org/pdf/1708.05031.pdf)
|
||||
|
||||
[AI上推荐 之 NeuralCF与PNN模型(改变特征交叉方式)](https://blog.csdn.net/wuzhongqiang/article/details/108985457)
|
||||
|
||||
[论文笔记:Neural Collaborative Filtering(NCF)](https://blog.csdn.net/qq_44015059/article/details/107441512)
|
||||
|
||||
[datawhale组队学习之协同过滤](http://datawhale.club/t/topic/41)
|
||||
|
||||
[datawhale组队学习之矩阵分解](http://datawhale.club/t/topic/42)
|
||||
|
||||
[谷歌双塔模型](https://zhuanlan.zhihu.com/p/137538147)
|
||||
252
DeepRecommendationModel/PNN.md
Normal file
@@ -0,0 +1,252 @@
|
||||
# PNN
|
||||
|
||||
## 1. 动机
|
||||
|
||||
在特征交叉的相关模型中FM, FFM都证明了特征交叉的重要性,FNN将神经网络的高阶隐式交叉加到了FM的二阶特征交叉上,一定程度上说明了DNN做特征交叉的有效性。但是对于DNN这种“add”操作的特征交叉并不能充分挖掘类别特征的交叉效果。PNN虽然也用了DNN来对特征进行交叉组合,但是并不是直接将低阶特征放入DNN中,而是设计了Product层先对低阶特征进行充分的交叉组合之后再送入到DNN中去。
|
||||
|
||||
PNN模型其实是对IPNN和OPNN的总称,两者分别对应的是不同的Product实现方法,前者采用的是inner product,后者采用的是outer product。在PNN的算法方面,比较重要的部分就是Product Layer的简化实现方法,需要在数学和代码上都能够比较深入的理解。
|
||||
|
||||
## 2. 模型的结构及原理
|
||||
|
||||
> 在学习PNN模型之前,应当对于DNN结构具有一定的了解,同时已经学习过了前面的章节。
|
||||
|
||||
PNN模型的整体架构如下图所示:
|
||||
|
||||
<img src="C:\Users\ryl\AppData\Roaming\Typora\typora-user-images\image-20210308142624189.png" alt="image-20210308142624189" style="zoom: 50%;" />
|
||||
|
||||
一共分为五层,其中除了Product Layer别的layer都是比较常规的处理方法,均可以从前面的章节进一步了解。模型中最重要的部分就是通过Product层对embedding特征进行交叉组合,也就是上图中红框所显示的部分。
|
||||
|
||||
Product层主要有线性部分和非线性部分组成,分别用$l_z$和$l_p$来表示,
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210308143101261.png" alt="image-20210308143101261" style="zoom: 50%;" />
|
||||
|
||||
1. 线性模块,一阶特征(未经过显示特征交叉处理),对应论文中的$l_z=(l_z^1,l_z^2, ..., l_z^{D_1})$
|
||||
2. 非线性模块,高阶特征(经过显示特征交叉处理),对应论文中的$l_p=(l_p^1,l_p^2, ..., l_p^{D_1})$
|
||||
|
||||
==线性部分==
|
||||
|
||||
先来解释一下$l_z$是如何计算得到的,在介绍计算$l_z$之前先介绍一下矩阵内积计算, 如下公式所示,用一句话来描述就是两个矩阵对应元素相称,然后将相乘之后的所有元素相加
|
||||
$$
|
||||
A \odot{B} = \sum_{i,j}A_{i,j}B_{i,j}
|
||||
$$
|
||||
$l_z^n$的计算就是矩阵内积,而$l_z$是有$D_1$个$l_z^n$组成,所以需要$D1$个矩阵求得,但是在代码实现的时候不一定是定义$D_1$个矩阵,可以将这些矩阵Flatten,具体的细节可以参考给出的代码。
|
||||
$$
|
||||
l_z=(l_z^1,l_z^2, ..., l_z^{D_1})\\
|
||||
l_z^n = W_z^n \odot{z} \\
|
||||
z = (z_1, z_2, ..., z_N)
|
||||
$$
|
||||
总之这一波操作就是将所有的embedding向量中的所有元素都乘以一个矩阵的对应元素,最后相加即可,这一部分比较简单(N表示的是特征的数量,M表示的是所有特征转化为embedding之后维度,也就是N*emb_dim)
|
||||
$$
|
||||
l_z^n = W_z^n \odot{z} = \sum_{i=1}^N \sum_{j=1}^M (W_z^n)_{i,j}z_{i,j}
|
||||
$$
|
||||
|
||||
### 2.1 Product Layer
|
||||
|
||||
==非线性部分==
|
||||
|
||||
上面介绍了线性部分$l_p$的计算,非线性部分的计算相比线性部分要复杂很多,先从整体上看$l_p$的计算
|
||||
$$
|
||||
l_p=(l_p^1,l_p^2, ..., l_p^{D_1}) \\
|
||||
l_p^n = W_p^n \odot{p} \\
|
||||
p = \{p_{i,j}\}, i=1,2,...,N,j=1,2,...,N
|
||||
$$
|
||||
从上述公式中可以发现,$l_p^n$和$l_z^n$类似需要$D_1$个$W_p^n$矩阵计算内积得到,重点就是如何求这个$p$,这里作者提出了两种方式,一种是使用内积计算,另一种是使用外积计算。
|
||||
|
||||
#### 2.1.1 IPNN
|
||||
|
||||
使用内积实现特征交叉就和FM是类似的(两两向量计算内积),下面将向量内积操作表示如下表达式
|
||||
$$
|
||||
g(f_i,f_j) = <f_i, f_j>
|
||||
$$
|
||||
将内积的表达式带入$l_p^n$的计算表达式中有:
|
||||
$$
|
||||
\begin{align}
|
||||
|
||||
l_p^n &= W_p^n \odot{p} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j}p_{i,j} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j}<f_i, f_j>
|
||||
|
||||
\end{align}
|
||||
$$
|
||||
上面就提到了这里使用的内积是计算两两特征之间的内积,然而向量a和向量b的内积与向量b和向量a的内积是相同的,其实是没必要计算的,看一下下面FM的计算公式:
|
||||
$$
|
||||
\hat{y}(X) = \omega_{0}+\sum_{i=1}^{n}{\omega_{i}x_{i}}+\sum_{i=1}^{n}{\sum_{j=i+1}^{n} <v_{i},v_{j}>x_{i}x_{j}}
|
||||
$$
|
||||
也就是说计算的内积矩阵$p$是对称的,那么与其对应元素做矩阵内积的矩阵$W_p^n$也是对称的,对于可学习的权重来说如果是对称的是不是可以只使用其中的一半就行了呢,所以基于这个思考,对Inner Product的权重定义及内积计算进行优化,首先将权重矩阵分解$W_p^n=\theta^n \theta^{nT}$,此时$\theta^n \in R^N$(参数从原来的$N^2$变成了$N$),将分解后的$W_p^n$带入$l_p^n$的计算公式有:
|
||||
$$
|
||||
\begin{align}
|
||||
|
||||
l_p^n &= W_p^n \odot{p} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j}p_{i,j} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N \theta^n \theta^n <f_i, f_j> \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N <\theta^n f_i, \theta^n f_j> \\
|
||||
&= <\sum_{i=1}^N \theta^n f_i, \sum_{j=1}^N \theta^n f_j> \\
|
||||
&= ||\sum_{i=1}^N \theta^n f_i||^2
|
||||
\end{align}
|
||||
$$
|
||||
所以优化后的$l_p$的计算公式为:
|
||||
$$
|
||||
l_p = (||\sum_{i=1}^N \theta^1 f_i||^2, ||\sum_{i=1}^N \theta^2 f_i||^2, ..., ||\sum_{i=1}^N \theta^{D_1} f_i||^2)
|
||||
$$
|
||||
这里为了好理解不做过多的解释,其实这里对于矩阵分解省略了一些细节,感兴趣的可以去看原文,最后模型实现的时候就是基于上面的这个公式计算的(给出的代码也是基于优化之后的实现)。
|
||||
|
||||
#### 2.1.2 OPNN
|
||||
|
||||
使用外积实现相比于使用内积实现,唯一的区别就是使用向量的外积来计算矩阵$p$,首先定义向量的外积计算
|
||||
$$
|
||||
g(i,j) = f_i f_j^T
|
||||
$$
|
||||
从外积公式可以发现两个向量的外积得到的是一个矩阵,与上面介绍的内积计算不太相同,内积得到的是一个数值。内积实现的Product层是将计算得到的内积矩阵,乘以一个与其大小一样的权重矩阵,然后求和,按照这个思路的话,通过外积得到的$p$计算$W_p^n \odot{p}$相当于之前的内积值乘以权重矩阵对应位置的值求和就变成了,外积矩阵乘以权重矩阵中对应位置的子矩阵然后将整个相乘得到的大矩阵对应元素相加,用公式表示如下:
|
||||
$$
|
||||
\begin{align}
|
||||
|
||||
l_p^n &= W_p^n \odot{p} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j}p_{i,j} \\
|
||||
&= \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j} f_i f_j^T
|
||||
|
||||
\end{align}
|
||||
$$
|
||||
需要注意的是此时的$(W_p^n)_{i,j}$表示的是一个矩阵,而不是一个值,此时计算$l_p$的复杂度是$O(D_1*N^2*M^2)$, 其中$N^2$表示的是特征的组合数量,$M^2$表示的是计算外积的复杂度。这样的复杂度肯定是无法接受的,所以为了优化复杂度,PNN的作者重新定义了$p$的计算方式:
|
||||
$$
|
||||
p=\sum_{i=1}^N \sum_{j=1}^N f_i f_j^T = f_{\sum}(f_\sum)^T\\
|
||||
f_\sum = \sum_{i=1}^N f_i
|
||||
$$
|
||||
需要注意,这里新定义的外积计算与传统的外积计算时不等价的,这里是为了优化计算效率重新定义的计算方式,从公式中可以看出,相当于先将原来的embedding向量在特征维度上先求和,变成一个向量之后再计算外积。加入原embedding向量表示为$E \in R^{N\times M}$,其中$N$表示特征的数量,M表示的是所有特征的总维度,即$N*emb\_dim$, 在特征维度上进行求和就是将$E \in R^{N\times M}$矩阵压缩成了$E \in R^M$, 然后两个$M$维的向量计算外积得到最终所有特征的外积交叉结果$p\in R^{M\times M}$,最终的$l_p^n$可以表示为:
|
||||
$$
|
||||
l_p^n = W_p^n \odot{p} = \sum_{i=1}^N \sum_{j=1}^N (W_p^n)_{i,j}p_{i,j} \\
|
||||
$$
|
||||
最终的计算方式和$l_z$的计算方式看起来差不多,但是需要注意外积优化后的$W_p^n$的维度是$R^{M \times M}$的,$M$表示的是特征矩阵的维度,即$N*emb\_dim$。
|
||||
|
||||
> 虽然叠加概念的引入可以降低计算开销,但是中间的精度损失也是很大的,性能与精度之间的tradeoff
|
||||
|
||||
|
||||
|
||||
## 3. 代码实现
|
||||
|
||||
代码实现的整体逻辑比较简单,就是对类别特征进行embedding编码,然后通过embedding特征计算$l_z,l_p$, 接着将$l_z, l_p$的输出concat到一起输入到DNN中得到最终的预测结果
|
||||
|
||||
```python
|
||||
def PNN(dnn_feature_columns, inner=True, outer=True):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
_, sparse_input_dict = build_input_layers(dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(sparse_input_dict.values())
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
sparse_embed_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=False)
|
||||
|
||||
dnn_inputs = ProductLayer(units=32, use_inner=True, use_outer=True)(sparse_embed_list)
|
||||
|
||||
# 输入到dnn中,需要提前定义需要几个残差块
|
||||
output_layer = get_dnn_logits(dnn_inputs)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
PNN的难点就是Product层的实现,下面是Product 层实现的代码,代码中是使用优化之后$l_p$的计算方式编写的, 代码中有详细的注释,但是要完全理解代码还需要去理解上述说过的优化思路。
|
||||
|
||||
```python
|
||||
class ProductLayer(Layer):
|
||||
def __init__(self, units, use_inner=True, use_outer=False):
|
||||
super(ProductLayer, self).__init__()
|
||||
self.use_inner = use_inner
|
||||
self.use_outer = use_outer
|
||||
self.units = units # 指的是原文中D1的大小
|
||||
|
||||
def build(self, input_shape):
|
||||
# 需要注意input_shape也是一个列表,并且里面的每一个元素都是TensorShape类型,
|
||||
# 需要将其转换成list然后才能参与数值计算,不然类型容易错
|
||||
# input_shape[0] : feat_nums x embed_dims
|
||||
self.feat_nums = len(input_shape)
|
||||
self.embed_dims = input_shape[0].as_list()[-1]
|
||||
flatten_dims = self.feat_nums * self.embed_dims
|
||||
|
||||
# Linear signals weight, 这部分是用于产生Z的权重,因为这里需要计算的是两个元素对应元素乘积然后再相加
|
||||
# 等价于先把矩阵拉成一维,然后相乘再相加
|
||||
self.linear_w = self.add_weight(name='linear_w', shape=(flatten_dims, self.units), initializer='glorot_normal')
|
||||
|
||||
# inner product weight
|
||||
if self.use_inner:
|
||||
# 优化之后的内积权重是未优化时的一个分解矩阵,未优化时的矩阵大小为:D x N x N
|
||||
# 优化后的内积权重大小为:D x N
|
||||
self.inner_w = self.add_weight(name='inner_w', shape=(self.units, self.feat_nums), initializer='glorot_normal')
|
||||
|
||||
if self.use_outer:
|
||||
# 优化之后的外积权重大小为:D x embed_dim x embed_dim, 因为计算外积的时候在特征维度通过求和的方式进行了压缩
|
||||
self.outer_w = self.add_weight(name='outer_w', shape=(self.units, self.embed_dims, self.embed_dims), initializer='glorot_normal')
|
||||
|
||||
|
||||
def call(self, inputs):
|
||||
# inputs是一个列表
|
||||
# 先将所有的embedding拼接起来计算线性信号部分的输出
|
||||
concat_embed = Concatenate(axis=1)(inputs) # B x feat_nums x embed_dims
|
||||
# 将两个矩阵都拉成二维的,然后通过矩阵相乘得到最终的结果
|
||||
concat_embed_ = tf.reshape(concat_embed, shape=[-1, self.feat_nums * self.embed_dims])
|
||||
lz = tf.matmul(concat_embed_, self.linear_w) # B x units
|
||||
|
||||
# inner
|
||||
lp_list = []
|
||||
if self.use_inner:
|
||||
for i in range(self.units):
|
||||
# 相当于给每一个特征向量都乘以一个权重
|
||||
# self.inner_w[i] : (embed_dims, ) 添加一个维度变成 (embed_dims, 1)
|
||||
delta = tf.multiply(concat_embed, tf.expand_dims(self.inner_w[i], axis=1)) # B x feat_nums x embed_dims
|
||||
# 在特征之间的维度上求和
|
||||
delta = tf.reduce_sum(delta, axis=1) # B x embed_dims
|
||||
# 最终在特征embedding维度上求二范数得到p
|
||||
lp_list.append(tf.reduce_sum(tf.square(delta), axis=1, keepdims=True)) # B x 1
|
||||
|
||||
# outer
|
||||
if self.use_outer:
|
||||
# 外积的优化是将embedding矩阵,在特征间的维度上通过求和进行压缩
|
||||
feat_sum = tf.reduce_sum(concat_embed, axis=1) # B x embed_dims
|
||||
|
||||
# 为了方便计算外积,将维度进行扩展
|
||||
f1 = tf.expand_dims(feat_sum, axis=2) # B x embed_dims x 1
|
||||
f2 = tf.expand_dims(feat_sum, axis=1) # B x 1 x embed_dims
|
||||
|
||||
# 求外积, a * a^T
|
||||
product = tf.matmul(f1, f2) # B x embed_dims x embed_dims
|
||||
|
||||
# 将product与外积权重矩阵对应元素相乘再相加
|
||||
for i in range(self.units):
|
||||
lpi = tf.multiply(product, self.outer_w[i]) # B x embed_dims x embed_dims
|
||||
# 将后面两个维度进行求和,需要注意的是,每使用一次reduce_sum就会减少一个维度
|
||||
lpi = tf.reduce_sum(lpi, axis=[1, 2]) # B
|
||||
# 添加一个维度便于特征拼接
|
||||
lpi = tf.expand_dims(lpi, axis=1) # B x 1
|
||||
lp_list.append(lpi)
|
||||
|
||||
# 将所有交叉特征拼接到一起
|
||||
lp = Concatenate(axis=1)(lp_list)
|
||||
|
||||
# 将lz和lp拼接到一起
|
||||
product_out = Concatenate(axis=1)([lz, lp])
|
||||
|
||||
return product_out
|
||||
```
|
||||
|
||||
因为这个模型的整体实现框架比较简单,就不画实现的草图了,直接看模型搭建的函数即可,对于PNN重点需要理解Product的两种类型及不同的优化方式。
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
|
||||
|
||||
## 4. 思考题
|
||||
|
||||
1. 降低复杂度的具体策略与具体的product函数选择有关,IPNN其实通过矩阵分解,“跳过”了显式的product层,而OPNN则是直接在product层入手进行优化。看原文去理解优化的动机及细节。
|
||||
|
||||
|
||||
|
||||
## 5. 参考文献
|
||||
|
||||
[PNN原文论文](https://arxiv.org/pdf/1611.00144.pdf)
|
||||
|
||||
[推荐系统系列(四):PNN理论与实践](https://zhuanlan.zhihu.com/p/89850560)
|
||||
|
||||
[deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
126
DeepRecommendationModel/Wide&Deep.md
Normal file
@@ -0,0 +1,126 @@
|
||||
# Wide & Deep
|
||||
|
||||
## 1. 动机
|
||||
|
||||
在CTR预估任务中利用手工构造的交叉组合特征来使线性模型具有“记忆性”,使模型记住共现频率较高的特征组合,往往也能达到一个不错的baseline,且可解释性强。但这种方式有着较为明显的缺点:
|
||||
|
||||
1. 特征工程需要耗费太多精力。
|
||||
2. 模型是强行记住这些组合特征的,对于未曾出现过的特征组合,权重系数为0,无法进行泛化。
|
||||
|
||||
为了加强模型的泛化能力,研究者引入了DNN结构,将高维稀疏特征编码为低维稠密的Embedding vector,这种基于Embedding的方式能够有效提高模型的泛化能力。但是,基于Embedding的方式可能因为数据长尾分布,导致长尾的一些特征值无法被充分学习,其对应的Embedding vector是不准确的,这便会造成模型泛化过度。
|
||||
|
||||
Wide&Deep模型就是围绕记忆性和泛化性进行讨论的,模型能够从历史数据中学习到高频共现的特征组合的能力,称为是模型的Memorization。能够利用特征之间的传递性去探索历史数据中从未出现过的特征组合,称为是模型的Generalization。Wide&Deep兼顾Memorization与Generalization并在Google Play store的场景中成功落地。
|
||||
|
||||
## 2. 模型结构及原理
|
||||
|
||||
<div align=center>
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
|
||||
</div>
|
||||
|
||||
其实wide&deep模型本身的结构是非常简单的,对于有点机器学习基础和深度学习基础的人来说都非常的容易看懂,但是如何根据自己的场景去选择那些特征放在Wide部分,哪些特征放在Deep部分就需要理解这篇论文提出者当时对于设计该模型不同结构时的意图了,所以这也是用好这个模型的一个前提。
|
||||
|
||||
**如何理解Wide部分有利于增强模型的“记忆能力”,Deep部分有利于增强模型的“泛化能力”?**
|
||||
|
||||
- wide部分是一个广义的线性模型,输入的特征主要有两部分组成,一部分是原始的部分特征,另一部分是原始特征的交叉特征(cross-product transformation),对于交互特征可以定义为:
|
||||
$$
|
||||
\phi_{k}(x)=\prod_{i=1}^d x_i^{c_{ki}}, c_{ki}\in \{0,1\}
|
||||
$$
|
||||
$c_{ki}$是一个布尔变量,当第i个特征属于第k个特征组合时,$c_{ki}$的值为1,否则为0,$x_i$是第i个特征的值,大体意思就是两个特征都同时为1这个新的特征才能为1,否则就是0,说白了就是一个特征组合。用原论文的例子举例:
|
||||
|
||||
> AND(user_installed_app=QQ, impression_app=WeChat),当特征user_installed_app=QQ,和特征impression_app=WeChat取值都为1的时候,组合特征AND(user_installed_app=QQ, impression_app=WeChat)的取值才为1,否则为0。
|
||||
|
||||
对于wide部分训练时候使用的优化器是带$L_1$正则的FTRL算法(Follow-the-regularized-leader),而L1 FTLR是非常注重模型稀疏性质的,也就是说W&D模型采用L1 FTRL是想让Wide部分变得更加的稀疏,即Wide部分的大部分参数都为0,这就大大压缩了模型权重及特征向量的维度。**Wide部分模型训练完之后留下来的特征都是非常重要的,那么模型的“记忆能力”就可以理解为发现"直接的",“暴力的”,“显然的”关联规则的能力。**例如Google W&D期望wide部分发现这样的规则:**用户安装了应用A,此时曝光应用B,用户安装应用B的概率大。**
|
||||
|
||||
- Deep部分是一个DNN模型,输入的特征主要分为两大类,一类是数值特征(可直接输入DNN),一类是类别特征(需要经过Embedding之后才能输入到DNN中),Deep部分的数学形式如下:
|
||||
$$
|
||||
a^{(l+1)} = f(W^{l}a^{(l)} + b^{l})
|
||||
$$
|
||||
**我们知道DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。**对于Deep部分的DNN模型作者使用了深度学习常用的优化器AdaGrad,这也是为了使得模型可以得到更精确的解。
|
||||
|
||||
|
||||
|
||||
**Wide部分与Deep部分的结合**
|
||||
|
||||
W&D模型是将两部分输出的结果结合起来联合训练,将deep和wide部分的输出重新使用一个逻辑回归模型做最终的预测,输出概率值。联合训练的数学形式如下:需要注意的是,因为Wide侧的数据是高维稀疏的,所以作者使用了FTRL算法优化,而Deep侧使用的是 Adagrad。
|
||||
$$
|
||||
P(Y=1|x)=\delta(w_{wide}^T[x,\phi(x)] + w_{deep}^T a^{(lf)} + b)
|
||||
$$
|
||||
|
||||
|
||||
## 3. 代码实现
|
||||
|
||||
Wide侧记住的是历史数据中那些**常见、高频**的模式,是推荐系统中的“**红海**”。实际上,Wide侧没有发现新的模式,只是学习到这些模式之间的权重,做一些模式的筛选。正因为Wide侧不能发现新模式,因此我们需要**根据人工经验、业务背景,将我们认为有价值的、显而易见的特征及特征组合,喂入Wide侧**
|
||||
|
||||
Deep侧就是DNN,通过embedding的方式将categorical/id特征映射成稠密向量,让DNN学习到这些特征之间的**深层交叉**,以增强扩展能力。
|
||||
|
||||
模型的实现与模型结构类似由deep和wide两部分组成,这两部分结构所需要的特征在上面已经说过了,针对当前数据集实现,我们在wide部分加入了所有可能的一阶特征,包括数值特征和类别特征的onehot都加进去了,其实也可以加入一些与wide&deep原论文中类似交叉特征。只要能够发现高频、常见模式的特征都可以放在wide侧,对于Deep部分,在本数据中放入了数值特征和类别特征的embedding特征,实际应用也需要根据需求进行选择。
|
||||
|
||||
```python
|
||||
# Wide&Deep 模型的wide部分及Deep部分的特征选择,应该根据实际的业务场景去确定哪些特征应该放在Wide部分,哪些特征应该放在Deep部分
|
||||
def WideNDeep(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# Wide&Deep模型论文中Wide部分使用的特征比较简单,并且得到的特征非常的稀疏,所以使用了FTRL优化Wide部分(这里没有实现FTRL)
|
||||
# 但是是根据他们业务进行选择的,我们这里将所有可能用到的特征都输入到Wide部分,具体的细节可以根据需求进行修改
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
# 在Wide&Deep模型中,deep部分的输入是将dense特征和embedding特征拼在一起输入到dnn中
|
||||
dnn_logits = get_dnn_logits(dense_input_dict, sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
|
||||
|
||||
# 将linear,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, dnn_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layer = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
```
|
||||
|
||||
关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播。(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210228160557072.png" alt="image-20210228160557072" style="zoom:67%;" />
|
||||
|
||||
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。
|
||||
|
||||
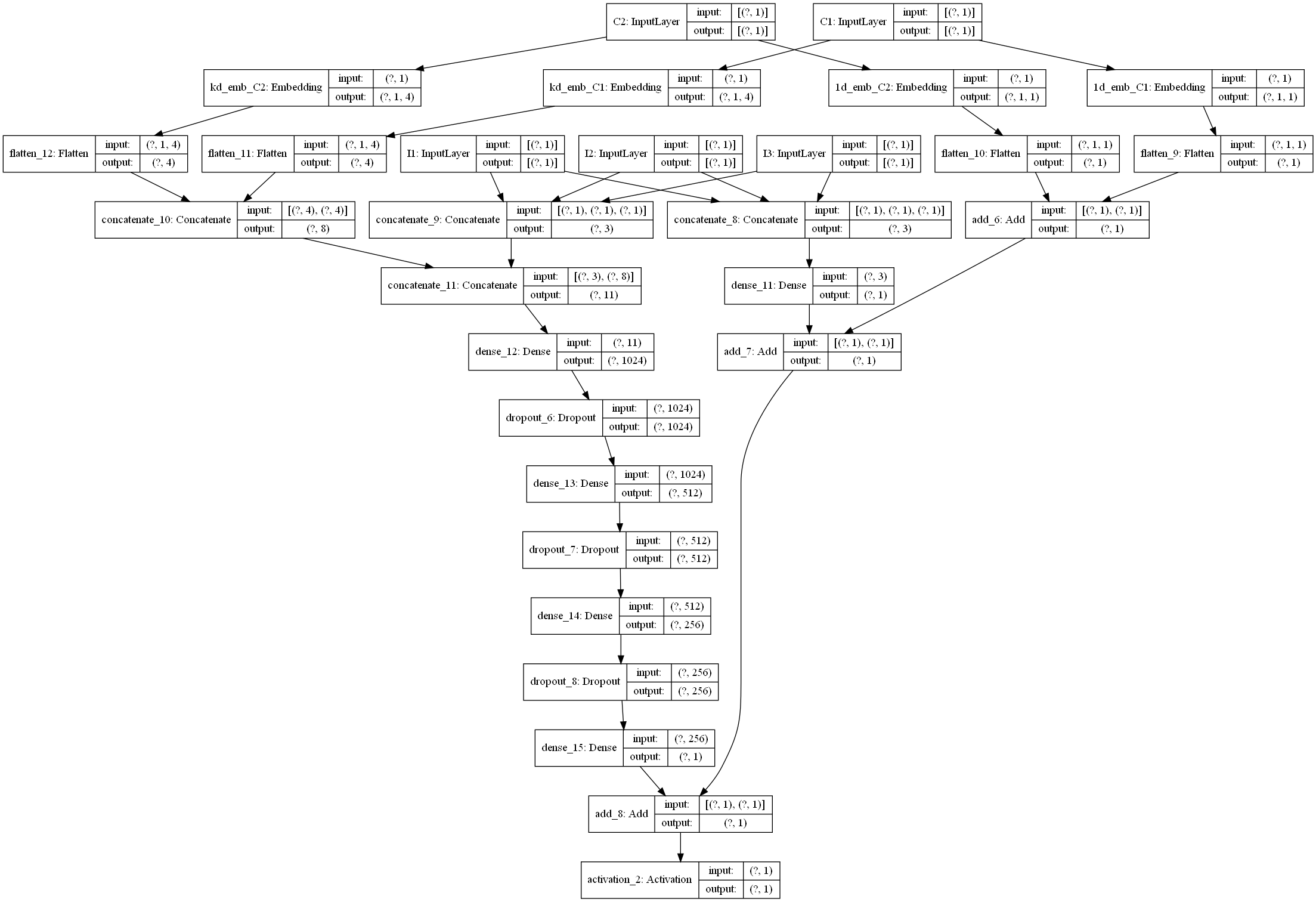
|
||||
|
||||
## 4. 思考
|
||||
|
||||
1. 在你的应用场景中,哪些特征适合放在Wide侧,哪些特征适合放在Deep侧,为什么呢?
|
||||
2. 为什么Wide部分要用L1 FTRL训练?
|
||||
3. 为什么Deep部分不特别考虑稀疏性的问题?
|
||||
|
||||
思考题可以参考[见微知著,你真的搞懂Google的Wide&Deep模型了吗?](https://zhuanlan.zhihu.com/p/142958834)
|
||||
|
||||
|
||||
|
||||
## 5. 参考资料
|
||||
|
||||
- [论文原文](https://arxiv.org/pdf/1606.07792.pdf)
|
||||
- [deepctr](https://github.com/shenweichen/DeepCTR)
|
||||
|
||||
- [看Google如何实现Wide & Deep模型(1)](https://zhuanlan.zhihu.com/p/47293765)
|
||||
|
||||
- [推荐系统系列(六):Wide&Deep理论与实践](https://zhuanlan.zhihu.com/p/92279796?utm_source=wechat_session&utm_medium=social&utm_oi=753565305866829824&utm_campaign=shareopn)
|
||||
|
||||
- [见微知著,你真的搞懂Google的Wide&Deep模型了吗?](https://zhuanlan.zhihu.com/p/142958834)
|
||||
|
||||
- [用NumPy手工打造 Wide & Deep](https://zhuanlan.zhihu.com/p/53110408)
|
||||
|
||||
- [tensorflow官网的WideDeepModel](https://www.tensorflow.org/api_docs/python/tf/keras/experimental/WideDeepModel)
|
||||
|
||||
|
||||
@@ -1,4 +1,57 @@
|
||||
## 简介
|
||||
### 组队学习计划
|
||||
|
||||
项目介绍由负责人来写吧。
|
||||
### 基本信息
|
||||
|
||||
- 贡献人员:罗如意、吴忠强、田雨,宁彦吉, 何世福、徐何军、赖敏材、刘纪川
|
||||
- 学习周期:15天
|
||||
- 学习形式:理论+实践;完成学习打卡
|
||||
- 人群定位:了解机器学习基础, 了解推荐系统基础(参加过以往的推荐系统组队学习),了解TF2 keras的基本用法
|
||||
- 难度系数:中等
|
||||
|
||||
|
||||
|
||||
#### 学习目标
|
||||
|
||||
熟悉经典深度学习模型的原理及代码实现(考虑到内容太多,这里选择了部分模型进行组队学习)。
|
||||
|
||||
|
||||
|
||||
#### 环境配置
|
||||
|
||||
Tensorflow2.x
|
||||
|
||||
> 所有代码在colab上以默认配置跑没有问题。如果自己电脑可以装tf2.x,也可以在自己的电脑上完成代码实战
|
||||
|
||||
|
||||
|
||||
#### 学习计划
|
||||
|
||||
##### Task00:熟悉规则(1天)
|
||||
|
||||
- 组队、修改群昵称
|
||||
- 熟悉打卡规则
|
||||
|
||||
##### Task01: DeepCrossing(2天)
|
||||
|
||||
- 完成模型理论学习及代码实现
|
||||
- 完成思考题
|
||||
|
||||
##### Task02: Wide&Deep(2天)
|
||||
|
||||
- 完成模型理论学习及代码实现
|
||||
- 完成思考题
|
||||
|
||||
##### Task03: DeepFM(3天)
|
||||
|
||||
- 完成模型理论学习及代码实现
|
||||
- 完成思考题
|
||||
|
||||
##### Task04: NFM(3天)
|
||||
|
||||
- 完成模型理论学习及代码实现
|
||||
- 完成思考题
|
||||
|
||||
##### Task05: DIN(3天)
|
||||
|
||||
- 完成模型理论学习及代码实现
|
||||
- 完成思考题
|
||||
|
||||
3
DeepRecommendationModel/代码/.vscode/settings.json
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
{
|
||||
"python.pythonPath": "D:\\ProgramData\\Anaconda3\\envs\\tf2.1\\python.exe"
|
||||
}
|
||||
236
DeepRecommendationModel/代码/AFM.py
Normal file
@@ -0,0 +1,236 @@
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
import warnings, random, math, os
|
||||
from collections import namedtuple, OrderedDict
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import *
|
||||
from tensorflow.keras.models import *
|
||||
import tensorflow.keras.backend as K
|
||||
from tensorflow.python.keras.initializers import Zeros, glorot_normal
|
||||
from tensorflow.python.keras.regularizers import l2
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.preprocessing import OneHotEncoder, MinMaxScaler, StandardScaler, LabelEncoder
|
||||
|
||||
from utils import DenseFeat, SparseFeat, VarLenSparseFeat
|
||||
import itertools
|
||||
|
||||
# 简单处理特征,包括填充缺失值,数值处理,类别编码
|
||||
def data_process(data_df, dense_features, sparse_features):
|
||||
data_df[dense_features] = data_df[dense_features].fillna(0.0)
|
||||
for f in dense_features:
|
||||
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
|
||||
|
||||
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
|
||||
for f in sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
data_df[f] = lbe.fit_transform(data_df[f])
|
||||
|
||||
return data_df[dense_features + sparse_features]
|
||||
|
||||
|
||||
def build_input_layers(feature_columns):
|
||||
# 构建Input层字典,并以dense和sparse两类字典的形式返回
|
||||
dense_input_dict, sparse_input_dict = {}, {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
|
||||
elif isinstance(fc, DenseFeat):
|
||||
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
|
||||
|
||||
return dense_input_dict, sparse_input_dict
|
||||
|
||||
|
||||
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
|
||||
# 定义一个embedding层对应的字典
|
||||
embedding_layers_dict = dict()
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
|
||||
if is_linear:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, 1, name='1d_emb_' + fc.name)
|
||||
else:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name='kd_emb_' + fc.name)
|
||||
|
||||
return embedding_layers_dict
|
||||
|
||||
|
||||
def get_linear_logits(dense_input_dict, sparse_input_dict, sparse_feature_columns):
|
||||
# 将所有的dense特征的Input层,然后经过一个全连接层得到dense特征的logits
|
||||
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
|
||||
dense_logits_output = Dense(1)(concat_dense_inputs)
|
||||
|
||||
# 获取linear部分sparse特征的embedding层,这里使用embedding的原因是:
|
||||
# 对于linear部分直接将特征进行onehot然后通过一个全连接层,当维度特别大的时候,计算比较慢
|
||||
# 使用embedding层的好处就是可以通过查表的方式获取到哪些非零的元素对应的权重,然后在将这些权重相加,效率比较高
|
||||
linear_embedding_layers = build_embedding_layers(sparse_feature_columns, sparse_input_dict, is_linear=True)
|
||||
|
||||
# 将一维的embedding拼接,注意这里需要使用一个Flatten层,使维度对应
|
||||
sparse_1d_embed = []
|
||||
for fc in sparse_feature_columns:
|
||||
feat_input = sparse_input_dict[fc.name]
|
||||
embed = Flatten()(linear_embedding_layers[fc.name](feat_input))
|
||||
sparse_1d_embed.append(embed)
|
||||
|
||||
# embedding中查询得到的权重就是对应onehot向量中一个位置的权重,所以后面不用再接一个全连接了,本身一维的embedding就相当于全连接
|
||||
# 只不过是这里的输入特征只有0和1,所以直接向非零元素对应的权重相加就等同于进行了全连接操作(非零元素部分乘的是1)
|
||||
sparse_logits_output = Add()(sparse_1d_embed)
|
||||
|
||||
# 最终将dense特征和sparse特征对应的logits相加,得到最终linear的logits
|
||||
linear_part = Add()([dense_logits_output, sparse_logits_output])
|
||||
return linear_part
|
||||
|
||||
|
||||
class AFM_Layer(Layer):
|
||||
def __init__(self, att_dims=8):
|
||||
super(AFM_Layer, self).__init__()
|
||||
self.att_dims = att_dims
|
||||
|
||||
def build(self, input_shape):
|
||||
embed_dims = input_shape[0][-1]
|
||||
|
||||
self.att_W = self.add_weight(name='W',
|
||||
shape=(embed_dims, self.att_dims),
|
||||
initializer='glorot_normal',
|
||||
regularizer='l2',
|
||||
trainable=True)
|
||||
|
||||
self.att_b = self.add_weight(name='b',
|
||||
shape=(self.att_dims, ),
|
||||
initializer='zeros',
|
||||
trainable=True)
|
||||
|
||||
self.project_h = self.add_weight(name='h',
|
||||
shape=(self.att_dims, 1),
|
||||
initializer='glorot_normal',
|
||||
regularizer='l2',
|
||||
trainable=True)
|
||||
|
||||
self.project_p = self.add_weight(name='p',
|
||||
shape=(embed_dims, 1),
|
||||
initializer='glorot_normal',
|
||||
regularizer='l2',
|
||||
trainable=True)
|
||||
|
||||
|
||||
def call(self, inputs):
|
||||
# inputs: 是一个列表,长度为n,列表中的每个元素是一个Bx1xk的向量
|
||||
rows = []
|
||||
cols = []
|
||||
|
||||
# 将inputs中的所有向量进行两两组合
|
||||
for r, c in itertools.combinations(inputs, 2): # r / c => B x 1 x k
|
||||
rows.append(r)
|
||||
cols.append(c)
|
||||
|
||||
# 将列表转换成tensor
|
||||
p = tf.concat(rows, axis=1) # B x (n(n-1)/2) x k
|
||||
q = tf.concat(cols, axis=1) # B x (n(n-1)/2) x k
|
||||
|
||||
# 计算两两向量之间对应元素的乘积
|
||||
element_wise_product = p * q # B x (n(n-1)/2) x k
|
||||
|
||||
# 计算attention值, 根据公式进行计算
|
||||
att_temp = tf.nn.relu(tf.matmul(element_wise_product, self.att_W) + self.att_b) # B x (n(n-1)/2) x att_dims
|
||||
att_temp = tf.matmul(att_temp, self.project_h) # B x (n(n-1)/2) x 1
|
||||
att_temp = tf.nn.softmax(att_temp, axis=2) # B x (n(n-1)/2) x 1
|
||||
|
||||
att_out = tf.reduce_sum(att_temp * element_wise_product, axis=1) # B x k
|
||||
att_logits = tf.matmul(att_out, self.project_p) # B x 1
|
||||
|
||||
return att_logits
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return (None, 1) # 返回的是logits值
|
||||
|
||||
|
||||
def get_attention_logits(sparse_input_dict, sparse_feature_columns, dnn_embedding_layers):
|
||||
# 只考虑sparse的二阶交叉,将所有的embedding拼接到一起
|
||||
# 这里在实际运行的时候,其实只会将那些非零元素对应的embedding拼接到一起
|
||||
# 并且将非零元素对应的embedding拼接到一起本质上相当于已经乘了x, 因为x中的值是1(公式中的x)
|
||||
sparse_kd_embed = []
|
||||
for fc in sparse_feature_columns:
|
||||
feat_input = sparse_input_dict[fc.name]
|
||||
_embed = dnn_embedding_layers[fc.name](feat_input) # B x 1 x k
|
||||
sparse_kd_embed.append(_embed)
|
||||
|
||||
# 输入AFM_Layer中的是一个列表,方便计算两两向量之间的对应元素的乘积
|
||||
att_logits = AFM_Layer()(sparse_kd_embed)
|
||||
|
||||
return att_logits
|
||||
|
||||
|
||||
def AFM(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# embedding层用户构建FM交叉部分和DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 将输入到dnn中的sparse特征筛选出来
|
||||
att_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
att_logits = get_attention_logits(sparse_input_dict, att_sparse_feature_columns, embedding_layers) # B x (n(n-1)/2)
|
||||
|
||||
# 将linear,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, att_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layers)
|
||||
return model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 读取数据
|
||||
data = pd.read_csv('./data/criteo_sample.txt')
|
||||
|
||||
# 划分dense和sparse特征
|
||||
columns = data.columns.values
|
||||
dense_features = [feat for feat in columns if 'I' in feat]
|
||||
sparse_features = [feat for feat in columns if 'C' in feat]
|
||||
|
||||
# 简单的数据预处理
|
||||
train_data = data_process(data, dense_features, sparse_features)
|
||||
train_data['label'] = data['label']
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for feat in sparse_features] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for feat in sparse_features] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建AFM模型
|
||||
history = AFM(linear_feature_columns, dnn_feature_columns)
|
||||
history.summary()
|
||||
history.compile(optimizer="adam",
|
||||
loss="binary_crossentropy",
|
||||
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
|
||||
|
||||
# 将输入数据转化成字典的形式输入
|
||||
train_model_input = {name: data[name] for name in dense_features + sparse_features}
|
||||
# 模型训练
|
||||
history.fit(train_model_input, train_data['label'].values,
|
||||
batch_size=64, epochs=5, validation_split=0.2, )
|
||||
192
DeepRecommendationModel/代码/DCN.py
Normal file
@@ -0,0 +1,192 @@
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore")
|
||||
import itertools
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from collections import namedtuple
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import *
|
||||
from tensorflow.keras.models import *
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
|
||||
|
||||
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
|
||||
|
||||
# 简单处理特征,包括填充缺失值,数值处理,类别编码
|
||||
def data_process(data_df, dense_features, sparse_features):
|
||||
data_df[dense_features] = data_df[dense_features].fillna(0.0)
|
||||
for f in dense_features:
|
||||
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
|
||||
|
||||
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
|
||||
for f in sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
data_df[f] = lbe.fit_transform(data_df[f])
|
||||
|
||||
return data_df[dense_features + sparse_features]
|
||||
|
||||
|
||||
def build_input_layers(feature_columns):
|
||||
# 构建Input层字典,并以dense和sparse两类字典的形式返回
|
||||
dense_input_dict, sparse_input_dict = {}, {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
|
||||
elif isinstance(fc, DenseFeat):
|
||||
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
|
||||
|
||||
return dense_input_dict, sparse_input_dict
|
||||
|
||||
|
||||
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
|
||||
# 定义一个embedding层对应的字典
|
||||
embedding_layers_dict = dict()
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
|
||||
if is_linear:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, 1, name='1d_emb_' + fc.name)
|
||||
else:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name='kd_emb_' + fc.name)
|
||||
|
||||
return embedding_layers_dict
|
||||
|
||||
|
||||
# 将所有的sparse特征embedding拼接
|
||||
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
|
||||
# 将sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
|
||||
|
||||
embedding_list = []
|
||||
for fc in sparse_feature_columns:
|
||||
_input = input_layer_dict[fc.name] # 获取输入层
|
||||
_embed = embedding_layer_dict[fc.name] # B x 1 x dim 获取对应的embedding层
|
||||
embed = _embed(_input) # B x dim 将input层输入到embedding层中
|
||||
|
||||
# 是否需要flatten, 如果embedding列表最终是直接输入到Dense层中,需要进行Flatten,否则不需要
|
||||
if flatten:
|
||||
embed = Flatten()(embed)
|
||||
|
||||
embedding_list.append(embed)
|
||||
|
||||
return embedding_list
|
||||
|
||||
|
||||
def get_dnn_output(dnn_input):
|
||||
|
||||
# dnn层,这里的Dropout参数,Dense中的参数都可以自己设定
|
||||
fc_layer = Dropout(0.5)(Dense(1024, activation='relu')(dnn_input))
|
||||
fc_layer = Dropout(0.3)(Dense(512, activation='relu')(fc_layer))
|
||||
dnn_out = Dropout(0.1)(Dense(256, activation='relu')(fc_layer))
|
||||
|
||||
return dnn_out
|
||||
|
||||
|
||||
class CrossNet(Layer):
|
||||
def __init__(self, layer_nums=3):
|
||||
super(CrossNet, self).__init__()
|
||||
self.layer_nums = layer_nums
|
||||
|
||||
def build(self, input_shape):
|
||||
# 计算w的维度,w的维度与输入数据的最后一个维度相同
|
||||
self.dim = int(input_shape[-1])
|
||||
|
||||
# 注意,在DCN中W不是一个矩阵而是一个向量,这里根据残差的层数定义一个权重列表
|
||||
self.W = [self.add_weight(name='W_' + str(i), shape=(self.dim,)) for i in range(self.layer_nums)]
|
||||
self.b = [self.add_weight(name='b_' + str(i),shape=(self.dim,), initializer='zeros') for i in range(self.layer_nums)]
|
||||
|
||||
def call(self, inputs):
|
||||
|
||||
# 进行特征交叉时的x_0一直没有变,变的是x_l和每一层的权重
|
||||
x_0 = inputs # B x dims
|
||||
x_l = x_0
|
||||
for i in range(self.layer_nums):
|
||||
# 将x_l的第一个维度与w[i]的第0个维度计算点积
|
||||
xl_w = tf.tensordot(x_l, self.W[i], axes=(1, 0)) # B,
|
||||
xl_w = tf.expand_dims(xl_w, axis=-1) # 在最后一个维度上添加一个维度 # B x 1
|
||||
cross = tf.multiply(x_0, xl_w) # B x dims
|
||||
x_l = cross + self.b[i] + x_l
|
||||
|
||||
return x_l
|
||||
|
||||
|
||||
def DCN(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns)) if linear_feature_columns else []
|
||||
|
||||
sparse_kd_embed = concat_embedding_list(sparse_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed)
|
||||
|
||||
dnn_input = Concatenate(axis=1)([concat_dense_inputs, concat_sparse_kd_embed])
|
||||
|
||||
dnn_output = get_dnn_output(dnn_input)
|
||||
|
||||
cross_output = CrossNet()(dnn_input)
|
||||
|
||||
# stack layer
|
||||
stack_output = Concatenate(axis=1)([dnn_output, cross_output])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layer = Dense(1, activation='sigmoid')(stack_output)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 读取数据
|
||||
data = pd.read_csv('./data/criteo_sample.txt')
|
||||
|
||||
# 划分dense和sparse特征
|
||||
columns = data.columns.values
|
||||
dense_features = [feat for feat in columns if 'I' in feat]
|
||||
sparse_features = [feat for feat in columns if 'C' in feat]
|
||||
|
||||
# 简单的数据预处理
|
||||
train_data = data_process(data, dense_features, sparse_features)
|
||||
train_data['label'] = data['label']
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建DCN模型
|
||||
history = DCN(linear_feature_columns, dnn_feature_columns)
|
||||
history.summary()
|
||||
history.compile(optimizer="adam",
|
||||
loss="binary_crossentropy",
|
||||
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
|
||||
|
||||
# 将输入数据转化成字典的形式输入
|
||||
train_model_input = {name: data[name] for name in dense_features + sparse_features}
|
||||
# 模型训练
|
||||
history.fit(train_model_input, train_data['label'].values,
|
||||
batch_size=32, epochs=5, validation_split=0.2, )
|
||||
|
||||
|
||||
447
DeepRecommendationModel/代码/DIEN.py
Normal file
@@ -0,0 +1,447 @@
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore")
|
||||
import itertools
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from collections import namedtuple
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import *
|
||||
from tensorflow.keras.models import *
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
|
||||
from random import sample
|
||||
|
||||
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
|
||||
|
||||
from contrib.rnn_v2 import dynamic_rnn
|
||||
from contrib.utils import QAAttGRUCell, VecAttGRUCell
|
||||
|
||||
tf.compat.v1.disable_eager_execution() # 这句要加上
|
||||
|
||||
|
||||
# 构建输入层
|
||||
# 将输入的数据转换成字典的形式,定义输入层的时候让输入层的name和字典中特征的key一致,就可以使得输入的数据和对应的Input层对应
|
||||
def build_input_layers(feature_columns):
|
||||
input_layer_dict = {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
input_layer_dict[fc.name] = Input(shape=(1,), name=fc.name)
|
||||
elif isinstance(fc, DenseFeat):
|
||||
input_layer_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
|
||||
elif isinstance(fc, VarLenSparseFeat):
|
||||
input_layer_dict[fc.name] = Input(shape=(fc.maxlen, ), name=fc.name)
|
||||
|
||||
return input_layer_dict
|
||||
|
||||
|
||||
# 构建embedding层
|
||||
def build_embedding_layers(feature_columns, input_layer_dict):
|
||||
embedding_layer_dict = {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
embedding_layer_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name='emb_' + fc.name)
|
||||
elif isinstance(fc, VarLenSparseFeat):
|
||||
embedding_layer_dict[fc.name] = Embedding(fc.vocabulary_size + 1, fc.embedding_dim, name='emb_' + fc.name, mask_zero=True)
|
||||
|
||||
return embedding_layer_dict
|
||||
|
||||
def embedding_lookup(feature_columns, input_layer_dict, embedding_layer_dict):
|
||||
embedding_list = []
|
||||
|
||||
for fc in feature_columns:
|
||||
_input = input_layer_dict[fc]
|
||||
_embed = embedding_layer_dict[fc]
|
||||
embed = _embed(_input)
|
||||
embedding_list.append(embed)
|
||||
|
||||
return embedding_list
|
||||
|
||||
# 输入层拼接成列表
|
||||
def concat_input_list(input_list):
|
||||
feature_nums = len(input_list)
|
||||
if feature_nums > 1:
|
||||
return Concatenate(axis=1)(input_list)
|
||||
elif feature_nums == 1:
|
||||
return input_list[0]
|
||||
else:
|
||||
return None
|
||||
|
||||
# 将所有的sparse特征embedding拼接
|
||||
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
|
||||
embedding_list = []
|
||||
for fc in feature_columns:
|
||||
_input = input_layer_dict[fc.name] # 获取输入层
|
||||
_embed = embedding_layer_dict[fc.name] # B x 1 x dim 获取对应的embedding层
|
||||
embed = _embed(_input) # B x dim 将input层输入到embedding层中
|
||||
|
||||
# 是否需要flatten, 如果embedding列表最终是直接输入到Dense层中,需要进行Flatten,否则不需要
|
||||
if flatten:
|
||||
embed = Flatten()(embed)
|
||||
|
||||
embedding_list.append(embed)
|
||||
|
||||
return embedding_list
|
||||
|
||||
|
||||
"""Attention NetWork"""
|
||||
class LocalActivationUnit(Layer):
|
||||
|
||||
def __init__(self, hidden_units=(256, 128, 64), activation='prelu'):
|
||||
super(LocalActivationUnit, self).__init__()
|
||||
self.hidden_units = hidden_units
|
||||
self.linear = Dense(1)
|
||||
self.dnn = [Dense(unit, activation=PReLU() if activation == 'prelu' else Dice()) for unit in hidden_units]
|
||||
|
||||
def call(self, inputs):
|
||||
# query: B x 1 x emb_dim keys: B x len x emb_dim
|
||||
query, keys = inputs
|
||||
|
||||
# 获取序列长度
|
||||
keys_len, keys_dim = keys.get_shape()[1], keys.get_shape()[2]
|
||||
|
||||
queries = tf.tile(query, multiples=[1, keys_len, 1]) # (None, len * emb_dim)
|
||||
queries = tf.reshape(queries, shape=[-1, keys_len, keys_dim])
|
||||
|
||||
# 将特征进行拼接
|
||||
att_input = tf.concat([queries, keys, queries - keys, queries * keys], axis=-1) # B x len x 4*emb_dim
|
||||
|
||||
# 将原始向量与外积结果拼接后输入到一个dnn中
|
||||
att_out = att_input
|
||||
for fc in self.dnn:
|
||||
att_out = fc(att_out) # B x len x att_out
|
||||
|
||||
att_out = self.linear(att_out) # B x len x 1
|
||||
att_out = tf.squeeze(att_out, -1) # B x len
|
||||
|
||||
return att_out
|
||||
|
||||
|
||||
class AttentionPoolingLayer(Layer):
|
||||
def __init__(self, user_behavior_length, att_hidden_units=(256, 128, 64), return_score=False):
|
||||
super(AttentionPoolingLayer, self).__init__()
|
||||
self.att_hidden_units = att_hidden_units
|
||||
self.local_att = LocalActivationUnit(self.att_hidden_units)
|
||||
self.user_behavior_length = user_behavior_length
|
||||
self.return_score = return_score
|
||||
|
||||
def call(self, inputs):
|
||||
# keys: B x len x emb_dim, queries: B x 1 x emb_dim
|
||||
queries, keys = inputs
|
||||
|
||||
# 获取行为序列embedding的mask矩阵,将Embedding矩阵中的非零元素设置成True,
|
||||
key_masks = tf.sequence_mask(self.user_behavior_length, keys.shape[1]) # (None, 1, max_len) 这里注意user_behavior_length是(None,1)
|
||||
key_masks = key_masks[:, 0, :] # 所以上面会多出个1维度来, 这里去掉才行,(None, max_len)
|
||||
|
||||
# 获取行为序列中每个商品对应的注意力权重
|
||||
attention_score = self.local_att([queries, keys]) # (None, max_len)
|
||||
|
||||
# 创建一个padding的tensor, 目的是为了标记出行为序列embedding中无效的位置
|
||||
paddings = tf.zeros_like(attention_score) # B x len
|
||||
|
||||
# outputs 表示的是padding之后的attention_score
|
||||
outputs = tf.where(key_masks, attention_score, paddings) # B x len
|
||||
|
||||
# 将注意力分数与序列对应位置加权求和,这一步可以在
|
||||
outputs = tf.expand_dims(outputs, axis=1) # B x 1 x len
|
||||
|
||||
if not self.return_score:
|
||||
# keys : B x len x emb_dim
|
||||
outputs = tf.matmul(outputs, keys) # B x 1 x dim
|
||||
outputs = tf.squeeze(outputs, axis=1)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
"""兴趣进化网络"""
|
||||
class DynamicGRU(Layer):
|
||||
def __init__(self, num_units=None, gru_type='GRU', return_sequence=True):
|
||||
super(DynamicGRU, self).__init__()
|
||||
self.num_units = num_units
|
||||
self.return_sequence = return_sequence
|
||||
self.gru_type = gru_type
|
||||
self.return_sequence = return_sequence
|
||||
|
||||
def build(self, input_shape):
|
||||
# 创建一个可训练的权重变量
|
||||
input_seq_shape = input_shape[0]
|
||||
if self.num_units is None:
|
||||
self.num_units = input_seq_shape.as_list()[-1] # 如果GRU的隐藏单元个数不指定,就取embedding维度
|
||||
if self.gru_type == 'AGRU':
|
||||
self.gru_cell = QAAttGRUCell(self.num_units)
|
||||
elif self.gru_type == 'AUGRU':
|
||||
self.gru_cell = VecAttGRUCell(self.num_units)
|
||||
else:
|
||||
self.gru_cell = tf.compat.v1.nn.rnn_cell.GRUCell(self.num_units)
|
||||
|
||||
super(DynamicGRU, self).build(input_shape)
|
||||
|
||||
def call(self, input_list):
|
||||
"""
|
||||
:param concated_embeds_value: None * field_size * embedding_size
|
||||
:return: None*1
|
||||
"""
|
||||
# 兴趣抽取层的运算
|
||||
if self.gru_type == "GRU" or self.gru_type == "AIGRU":
|
||||
rnn_input, sequence_length = input_list
|
||||
att_score = None
|
||||
else: # 这个是兴趣进化层,这个中间会有个注意力机制
|
||||
rnn_input, sequence_length, att_score = input_list
|
||||
|
||||
rnn_output, hidden_state = dynamic_rnn(self.gru_cell, inputs=rnn_input, att_scores=att_score,
|
||||
sequence_length=tf.squeeze(sequence_length),
|
||||
dtype = tf.float32)
|
||||
|
||||
if not self.return_sequence: # 只返回最后一个时间步的结果
|
||||
return hidden_state
|
||||
else: # 返回所有时间步的结果
|
||||
return rnn_output
|
||||
|
||||
|
||||
class DNN(Layer):
|
||||
"""
|
||||
FC network
|
||||
"""
|
||||
def __init__(self, hidden_units, activation='relu', dropout=0.):
|
||||
"""
|
||||
:param hidden_units: A list. the number of the hidden layer neural units
|
||||
:param activation: A string. Activation function of dnn.
|
||||
:param dropout: A scalar. Dropout rate
|
||||
"""
|
||||
super(DNN, self).__init__()
|
||||
self.dnn_net = [Dense(units=unit, activation=activation) for unit in hidden_units]
|
||||
self.dropout = Dropout(dropout)
|
||||
|
||||
def call(self, inputs):
|
||||
x = inputs
|
||||
for dnn in self.dnn_net:
|
||||
x = dnn(x)
|
||||
x = self.dropout(x)
|
||||
|
||||
outputs = Dense(1, activation='sigmoid')(x)
|
||||
return outputs
|
||||
|
||||
|
||||
def auxiliary_loss(h_states, click_seq, noclick_seq, mask):
|
||||
"""
|
||||
计算auxiliary_loss
|
||||
:param h_states: 兴趣提取层的隐藏状态的输出h_states (None, T-1, embed_dim)
|
||||
:param click_seq: 下一个时刻用户点击的embedding向量 (None, T-1, embed_dim)
|
||||
:param noclick_seq:下一个时刻用户未点击的embedding向量 (None, T-1, embed_dim)
|
||||
:param mask: 用户历史行为序列的长度, 注意这里是原seq_length-1,因为最后一个时间步的输出就没法计算了 (None, 1)
|
||||
|
||||
:return: 根据论文的公式,计算出损失,返回回来
|
||||
"""
|
||||
hist_len, _ = click_seq.get_shape().as_list()[1:] # (T-1, embed_dim) 元组解包的操作, hist_len=T-1
|
||||
mask = tf.sequence_mask(mask, hist_len) # 这是遮盖的操作 (None, 1, T-1) 每一行是bool类型的值, 为FALSE的为填充
|
||||
mask = mask[:, 0, :] # (None, T-1)
|
||||
|
||||
mask = tf.cast(mask, tf.float32)
|
||||
|
||||
click_input = tf.concat([h_states, click_seq], -1) # (None, T-1, 2*embed_dim)
|
||||
noclick_input = tf.concat([h_states, noclick_seq], -1) # (None, T-1, 2*embed_dim)
|
||||
|
||||
auxiliary_nn = DNN([100, 50], activation='sigmoid')
|
||||
click_prop = auxiliary_nn(click_input)[:, :, 0] # (None, T-1)
|
||||
noclick_prop = auxiliary_nn(noclick_input)[:, :, 0] # (None, T-1)
|
||||
|
||||
click_loss = -tf.reshape(tf.compat.v1.log(click_prop), [-1, tf.shape(click_seq)[1]]) * mask
|
||||
noclick_loss = -tf.reshape(tf.compat.v1.log(1.0-noclick_prop), [-1, tf.shape(noclick_seq)[1]]) * mask
|
||||
|
||||
aux_loss = tf.reduce_mean(click_loss + noclick_loss)
|
||||
|
||||
return aux_loss
|
||||
|
||||
|
||||
def interest_evolution(concat_behavior, query_input_item, user_behavior_length, neg_concat_behavior, gru_type="GRU", use_neg=True):
|
||||
|
||||
aux_loss = None
|
||||
use_aux_loss = None
|
||||
embedding_size = None
|
||||
|
||||
# 兴趣提取层
|
||||
rnn_outputs = DynamicGRU(embedding_size, return_sequence=True)([concat_behavior, user_behavior_length]) # (None, max_len, embed_dim)
|
||||
# "AUGRU"并且采用负采样序列方式,这时候要先计算auxiliary_loss
|
||||
if gru_type == "AUGRU" and use_neg:
|
||||
aux_loss = auxiliary_loss(rnn_outputs[:, :-1, :],
|
||||
concat_behavior[:, 1:, :],
|
||||
neg_concat_behavior[:, 1:, :],
|
||||
tf.subtract(user_behavior_length, 1))
|
||||
|
||||
# 兴趣演化层用的GRU, 这时候先得到输出, 然后把Attention的结果直接加权上去
|
||||
if gru_type == "GRU":
|
||||
rnn_outputs2 = DynamicGRU(embedding_size, return_sequence=True)([rnn_outputs, user_behavior_length]) # (None, max_len, embed_dim)
|
||||
hist = AttentionPoolingLayer(user_behavior_length, return_score=False)([query_input_item, rnn_outputs2])
|
||||
else:
|
||||
scores = AttentionPoolingLayer(user_behavior_length, return_score=True)([query_input_item, rnn_outputs])
|
||||
# 兴趣演化层如果是AIGRU, 把Attention的结果先乘到输入上去,然后再过GRU
|
||||
if gru_type == "AIGRU":
|
||||
hist = multiply([rnn_outputs, Permute[2, 1](scores)])
|
||||
final_state2 = DynamicGRU(embedding_size, gru_type="GRU", return_sequence=False)([hist, user_behavior_length])
|
||||
else: # 兴趣演化层是AUGRU或者AGRU, 这时候, 需要用相应的cell去进行计算了
|
||||
final_state2 = DynamicGRU(embedding_size, gru_type=gru_type, return_sequence=False)([rnn_outputs, user_behavior_length, Permute([2, 1])(scores)])
|
||||
hist = final_state2
|
||||
return hist, aux_loss
|
||||
|
||||
|
||||
"""DNN Network"""
|
||||
class Dice(Layer):
|
||||
def __init__(self):
|
||||
super(Dice, self).__init__()
|
||||
self.bn = BatchNormalization(center=False, scale=False)
|
||||
|
||||
def build(self, input_shape):
|
||||
self.alpha = self.add_weight(shape=(input_shape[-1],), dtype=tf.float32, name='alpha')
|
||||
|
||||
def call(self, x):
|
||||
x_normed = self.bn(x)
|
||||
x_p = tf.sigmoid(x_normed)
|
||||
|
||||
return self.alpha * (1.0-x_p) * x + x_p * x
|
||||
|
||||
def get_dnn_logits(dnn_input, hidden_units=(200, 80), activation='prelu'):
|
||||
dnns = [Dense(unit, activation=PReLU() if activation == 'prelu' else Dice()) for unit in hidden_units]
|
||||
|
||||
dnn_out = dnn_input
|
||||
for dnn in dnns:
|
||||
dnn_out = dnn(dnn_out)
|
||||
|
||||
# 获取logits
|
||||
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
|
||||
|
||||
return dnn_logits
|
||||
|
||||
|
||||
"""DIEN NetWork"""
|
||||
def DIEN(feature_columns, behavior_feature_list, behavior_seq_feature_list, neg_seq_feature_list, use_neg_sample=False, alpha=1.0):
|
||||
# 构建输入层
|
||||
input_layer_dict = build_input_layers(feature_columns)
|
||||
|
||||
# 将Input层转化为列表的形式作为model的输入
|
||||
input_layers = list(input_layer_dict.values()) # 各个输入层
|
||||
user_behavior_length = input_layer_dict["hist_len"]
|
||||
|
||||
# 筛选出特征中的sparse_fea, dense_fea, varlen_fea
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if feature_columns else []
|
||||
varlen_sparse_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 获取dense
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
dnn_dense_input.append(input_layer_dict[fc.name])
|
||||
|
||||
# 将所有的dense特征拼接
|
||||
dnn_dense_input = concat_input_list(dnn_dense_input)
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
|
||||
|
||||
# 因为这里最终需要将embedding拼接后直接输入到全连接层(Dense)中, 所以需要Flatten
|
||||
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
|
||||
# 将所有sparse特征的embedding进行拼接
|
||||
dnn_sparse_input = concat_input_list(dnn_sparse_embed_input)
|
||||
|
||||
# 获取当前的行为特征(movie)的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 获取行为序列(movie_id序列, hist_movie_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
# 把q,k的embedding拼在一块
|
||||
query_emb, keys_emb = concat_input_list(query_embed_list), concat_input_list(keys_embed_list)
|
||||
|
||||
# 采样的负行为
|
||||
neg_uiseq_embed_list = embedding_lookup(neg_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
neg_concat_behavior = concat_input_list(neg_uiseq_embed_list)
|
||||
|
||||
# 兴趣进化层的计算过程
|
||||
dnn_seq_input, aux_loss = interest_evolution(keys_emb, query_emb, user_behavior_length, neg_concat_behavior, gru_type="AUGRU")
|
||||
|
||||
# 后面的全连接层
|
||||
deep_input_embed = Concatenate()([dnn_dense_input, dnn_sparse_input, dnn_seq_input])
|
||||
|
||||
# 获取最终dnn的logits
|
||||
dnn_logits = get_dnn_logits(deep_input_embed, activation='prelu')
|
||||
model = Model(input_layers, dnn_logits)
|
||||
|
||||
# 加兴趣提取层的损失 这个比例可调
|
||||
if use_neg_sample:
|
||||
model.add_loss(alpha * aux_loss)
|
||||
|
||||
# 所有变量需要初始化
|
||||
tf.compat.v1.keras.backend.get_session().run(tf.compat.v1.global_variables_initializer())
|
||||
return model
|
||||
|
||||
|
||||
def get_neg_click(data_df, neg_num=10):
|
||||
movies_np = data_df['hist_movie_id'].values
|
||||
|
||||
movie_list = []
|
||||
for movies in movies_np:
|
||||
movie_list.extend([x for x in movies.split(',') if x != '0'])
|
||||
|
||||
movies_set = set(movie_list)
|
||||
|
||||
neg_movies_list = []
|
||||
for movies in movies_np:
|
||||
hist_movies = set([x for x in movies.split(',') if x != '0'])
|
||||
neg_movies_set = movies_set - hist_movies # 集合求差集
|
||||
neg_movies = sample(neg_movies_set, neg_num) # 返回的是一个列表
|
||||
neg_movies_list.append(','.join(neg_movies))
|
||||
|
||||
return pd.Series(neg_movies_list)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
"""读取数据"""
|
||||
samples_data = pd.read_csv("data/movie_sample.txt", sep="\t", header = None)
|
||||
samples_data.columns = ["user_id", "gender", "age", "hist_movie_id", "hist_len", "movie_id", "movie_type_id", "label"]
|
||||
|
||||
"""数据集"""
|
||||
X = samples_data[["user_id", "gender", "age", "hist_movie_id", "hist_len", "movie_id", "movie_type_id"]]
|
||||
y = samples_data["label"]
|
||||
|
||||
# 负采样,负采样的时候序列的长度和设置的行为序列长度一样长
|
||||
# 不用担心会多计算损失,其实在计算损失的时候使用mask,无效的值不会参与计算
|
||||
X['neg_hist_movie_id'] = get_neg_click(X, neg_num=50)
|
||||
|
||||
"""构建DIEN模型的输入格式"""
|
||||
# 这里和DIN相比, 会多出负采样的一列历史行为
|
||||
X_train = {"user_id": np.array(X["user_id"]), \
|
||||
"gender": np.array(X["gender"]), \
|
||||
"age": np.array(X["age"]), \
|
||||
"hist_movie_id": np.array([[int(i) for i in l.split(',')] for l in X["hist_movie_id"]]), \
|
||||
"neg_hist_movie_id": np.array([[int(i) for i in l.split(',')] for l in X["neg_hist_movie_id"]]), \
|
||||
"hist_len": np.array(X["hist_len"]), \
|
||||
"movie_id": np.array(X["movie_id"]), \
|
||||
"movie_type_id": np.array(X["movie_type_id"])}
|
||||
|
||||
y_train = np.array(y)
|
||||
|
||||
"""特征封装"""
|
||||
feature_columns = [SparseFeat('user_id', max(samples_data["user_id"])+1, embedding_dim=8),
|
||||
SparseFeat('gender', max(samples_data["gender"])+1, embedding_dim=8),
|
||||
SparseFeat('age', max(samples_data["age"])+1, embedding_dim=8),
|
||||
SparseFeat('movie_id', max(samples_data["movie_id"])+1, embedding_dim=8),
|
||||
SparseFeat('movie_type_id', max(samples_data["movie_type_id"])+1, embedding_dim=8),
|
||||
DenseFeat('hist_len', 1)]
|
||||
|
||||
feature_columns += [VarLenSparseFeat('hist_movie_id', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=50)]
|
||||
feature_columns += [VarLenSparseFeat('neg_hist_movie_id', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=50)]
|
||||
|
||||
# 行为特征列表,表示的是基础特征
|
||||
behavior_feature_list = ['movie_id']
|
||||
# 行为序列特征
|
||||
behavior_seq_feature_list = ['hist_movie_id']
|
||||
# 负采样序列特征
|
||||
neg_seq_feature_list = ['neg_hist_movie_id']
|
||||
|
||||
"""构建DIN模型"""
|
||||
history = DIEN(feature_columns, behavior_feature_list, behavior_seq_feature_list, neg_seq_feature_list, use_neg_sample=True)
|
||||
|
||||
history.compile('adam', 'binary_crossentropy')
|
||||
|
||||
history.fit(X_train, y_train, batch_size=64, epochs=5, validation_split=0.2, )
|
||||
270
DeepRecommendationModel/代码/DIN.py
Normal file
@@ -0,0 +1,270 @@
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore")
|
||||
import itertools
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from collections import namedtuple
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import *
|
||||
from tensorflow.keras.models import *
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
|
||||
|
||||
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
|
||||
|
||||
# 构建输入层
|
||||
# 将输入的数据转换成字典的形式,定义输入层的时候让输入层的name和字典中特征的key一致,就可以使得输入的数据和对应的Input层对应
|
||||
def build_input_layers(feature_columns):
|
||||
input_layer_dict = {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
input_layer_dict[fc.name] = Input(shape=(1,), name=fc.name)
|
||||
elif isinstance(fc, DenseFeat):
|
||||
input_layer_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
|
||||
elif isinstance(fc, VarLenSparseFeat):
|
||||
input_layer_dict[fc.name] = Input(shape=(fc.maxlen, ), name=fc.name)
|
||||
|
||||
return input_layer_dict
|
||||
|
||||
# 构建embedding层
|
||||
def build_embedding_layers(feature_columns, input_layer_dict):
|
||||
embedding_layer_dict = {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
embedding_layer_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name='emb_' + fc.name)
|
||||
elif isinstance(fc, VarLenSparseFeat):
|
||||
embedding_layer_dict[fc.name] = Embedding(fc.vocabulary_size + 1, fc.embedding_dim, name='emb_' + fc.name, mask_zero=True)
|
||||
|
||||
return embedding_layer_dict
|
||||
|
||||
|
||||
def embedding_lookup(feature_columns, input_layer_dict, embedding_layer_dict):
|
||||
embedding_list = []
|
||||
|
||||
for fc in feature_columns:
|
||||
_input = input_layer_dict[fc]
|
||||
_embed = embedding_layer_dict[fc]
|
||||
embed = _embed(_input)
|
||||
embedding_list.append(embed)
|
||||
|
||||
return embedding_list
|
||||
|
||||
|
||||
class Dice(Layer):
|
||||
def __init__(self):
|
||||
super(Dice, self).__init__()
|
||||
self.bn = BatchNormalization(center=False, scale=False)
|
||||
|
||||
def build(self, input_shape):
|
||||
self.alpha = self.add_weight(shape=(input_shape[-1],), dtype=tf.float32, name='alpha')
|
||||
|
||||
def call(self, x):
|
||||
x_normed = self.bn(x)
|
||||
x_p = tf.sigmoid(x_normed)
|
||||
|
||||
return self.alpha * (1.0-x_p) * x + x_p * x
|
||||
|
||||
|
||||
class LocalActivationUnit(Layer):
|
||||
|
||||
def __init__(self, hidden_units=(256, 128, 64), activation='prelu'):
|
||||
super(LocalActivationUnit, self).__init__()
|
||||
self.hidden_units = hidden_units
|
||||
self.linear = Dense(1)
|
||||
self.dnn = [Dense(unit, activation=PReLU() if activation == 'prelu' else Dice()) for unit in hidden_units]
|
||||
|
||||
def call(self, inputs):
|
||||
# query: B x 1 x emb_dim keys: B x len x emb_dim
|
||||
query, keys = inputs
|
||||
|
||||
# 获取序列长度
|
||||
keys_len = keys.get_shape()[1]
|
||||
|
||||
queries = tf.tile(query, multiples=[1, keys_len, 1]) # (None, len, emb_dim)
|
||||
|
||||
# 将特征进行拼接
|
||||
att_input = tf.concat([queries, keys, queries - keys, queries * keys], axis=-1) # B x len x 4*emb_dim
|
||||
|
||||
# 将原始向量与外积结果拼接后输入到一个dnn中
|
||||
att_out = att_input
|
||||
for fc in self.dnn:
|
||||
att_out = fc(att_out) # B x len x att_out
|
||||
|
||||
att_out = self.linear(att_out) # B x len x 1
|
||||
att_out = tf.squeeze(att_out, -1) # B x len
|
||||
|
||||
return att_out
|
||||
|
||||
|
||||
class AttentionPoolingLayer(Layer):
|
||||
def __init__(self, att_hidden_units=(256, 128, 64)):
|
||||
super(AttentionPoolingLayer, self).__init__()
|
||||
self.att_hidden_units = att_hidden_units
|
||||
self.local_att = LocalActivationUnit(self.att_hidden_units)
|
||||
|
||||
def call(self, inputs):
|
||||
# keys: B x len x emb_dim, queries: B x 1 x emb_dim
|
||||
queries, keys = inputs
|
||||
|
||||
# 获取行为序列embedding的mask矩阵,将Embedding矩阵中的非零元素设置成True,
|
||||
key_masks = tf.not_equal(keys[:,:,0], 0) # B x len
|
||||
# key_masks = keys._keras_mask # tf的有些版本不能使用这个属性,2.1是可以的,2.4好像不行
|
||||
|
||||
# 获取行为序列中每个商品对应的注意力权重
|
||||
attention_score = self.local_att([queries, keys]) # B x len
|
||||
|
||||
# 去除最后一个维度,方便后续理解与计算
|
||||
# outputs = attention_score
|
||||
# 创建一个padding的tensor, 目的是为了标记出行为序列embedding中无效的位置
|
||||
paddings = tf.zeros_like(attention_score) # B x len
|
||||
|
||||
# outputs 表示的是padding之后的attention_score
|
||||
outputs = tf.where(key_masks, attention_score, paddings) # B x len
|
||||
|
||||
# 将注意力分数与序列对应位置加权求和,这一步可以在
|
||||
outputs = tf.expand_dims(outputs, axis=1) # B x 1 x len
|
||||
|
||||
# keys : B x len x emb_dim
|
||||
outputs = tf.matmul(outputs, keys) # B x 1 x dim
|
||||
outputs = tf.squeeze(outputs, axis=1)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
def get_dnn_logits(dnn_input, hidden_units=(200, 80), activation='prelu'):
|
||||
dnns = [Dense(unit, activation=PReLU() if activation == 'prelu' else Dice()) for unit in hidden_units]
|
||||
|
||||
dnn_out = dnn_input
|
||||
for dnn in dnns:
|
||||
dnn_out = dnn(dnn_out)
|
||||
|
||||
# 获取logits
|
||||
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
|
||||
|
||||
return dnn_logits
|
||||
|
||||
# 输入层拼接成列表
|
||||
def concat_input_list(input_list):
|
||||
feature_nums = len(input_list)
|
||||
if feature_nums > 1:
|
||||
return Concatenate(axis=1)(input_list)
|
||||
elif feature_nums == 1:
|
||||
return input_list[0]
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
# 将所有的sparse特征embedding拼接
|
||||
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
|
||||
embedding_list = []
|
||||
for fc in feature_columns:
|
||||
_input = input_layer_dict[fc.name] # 获取输入层
|
||||
_embed = embedding_layer_dict[fc.name] # B x 1 x dim 获取对应的embedding层
|
||||
embed = _embed(_input) # B x dim 将input层输入到embedding层中
|
||||
|
||||
# 是否需要flatten, 如果embedding列表最终是直接输入到Dense层中,需要进行Flatten,否则不需要
|
||||
if flatten:
|
||||
embed = Flatten()(embed)
|
||||
|
||||
embedding_list.append(embed)
|
||||
|
||||
return embedding_list
|
||||
|
||||
|
||||
def DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list):
|
||||
# 构建Input层
|
||||
input_layer_dict = build_input_layers(feature_columns)
|
||||
|
||||
# 将Input层转化成列表的形式作为model的输入
|
||||
input_layers = list(input_layer_dict.values())
|
||||
|
||||
# 筛选出特征中的sparse特征和dense特征,方便单独处理
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
|
||||
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns))
|
||||
|
||||
# 获取dense
|
||||
dnn_dense_input = []
|
||||
for fc in dense_feature_columns:
|
||||
dnn_dense_input.append(input_layer_dict[fc.name])
|
||||
|
||||
# 将所有的dense特征拼接
|
||||
dnn_dense_input = concat_input_list(dnn_dense_input)
|
||||
|
||||
# 构建embedding字典
|
||||
embedding_layer_dict = build_embedding_layers(feature_columns, input_layer_dict)
|
||||
|
||||
# 因为这里最终需要将embedding拼接后直接输入到全连接层(Dense)中, 所以需要Flatten
|
||||
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
# 将所有sparse特征的embedding进行拼接
|
||||
dnn_sparse_input = concat_input_list(dnn_sparse_embed_input)
|
||||
|
||||
# 获取当前的行为特征(movie)的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
query_embed_list = embedding_lookup(behavior_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 获取行为序列(movie_id序列, hist_movie_id) 对应的embedding,这里有可能有多个行为产生了行为序列,所以需要使用列表将其放在一起
|
||||
keys_embed_list = embedding_lookup(behavior_seq_feature_list, input_layer_dict, embedding_layer_dict)
|
||||
|
||||
# 使用注意力机制将历史movie_id序列进行池化
|
||||
dnn_seq_input_list = []
|
||||
for i in range(len(keys_embed_list)):
|
||||
seq_emb = AttentionPoolingLayer()([query_embed_list[i], keys_embed_list[i]])
|
||||
dnn_seq_input_list.append(seq_emb)
|
||||
|
||||
# 将多个行为序列attention poolint 之后的embedding进行拼接
|
||||
dnn_seq_input = concat_input_list(dnn_seq_input_list)
|
||||
|
||||
# 将dense特征,sparse特征,及通过注意力加权的序列特征拼接
|
||||
dnn_input = Concatenate(axis=1)([dnn_dense_input, dnn_sparse_input, dnn_seq_input])
|
||||
|
||||
# 获取最终dnn的logits
|
||||
dnn_logits = get_dnn_logits(dnn_input, activation='prelu')
|
||||
|
||||
model = Model(input_layers, dnn_logits)
|
||||
return model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 读取数据
|
||||
samples_data = pd.read_csv("./data/movie_sample.txt", sep="\t", header = None)
|
||||
samples_data.columns = ["user_id", "gender", "age", "hist_movie_id", "hist_len", "movie_id", "movie_type_id", "label"]
|
||||
|
||||
# samples_data = shuffle(samples_data)
|
||||
|
||||
X = samples_data[["user_id", "gender", "age", "hist_movie_id", "hist_len", "movie_id", "movie_type_id"]]
|
||||
y = samples_data["label"]
|
||||
|
||||
X_train = {"user_id": np.array(X["user_id"]), \
|
||||
"gender": np.array(X["gender"]), \
|
||||
"age": np.array(X["age"]), \
|
||||
"hist_movie_id": np.array([[int(i) for i in l.split(',')] for l in X["hist_movie_id"]]), \
|
||||
"hist_len": np.array(X["hist_len"]), \
|
||||
"movie_id": np.array(X["movie_id"]), \
|
||||
"movie_type_id": np.array(X["movie_type_id"])}
|
||||
|
||||
y_train = np.array(y)
|
||||
|
||||
feature_columns = [SparseFeat('user_id', max(samples_data["user_id"])+1, embedding_dim=8),
|
||||
SparseFeat('gender', max(samples_data["gender"])+1, embedding_dim=8),
|
||||
SparseFeat('age', max(samples_data["age"])+1, embedding_dim=8),
|
||||
SparseFeat('movie_id', max(samples_data["movie_id"])+1, embedding_dim=8),
|
||||
SparseFeat('movie_type_id', max(samples_data["movie_type_id"])+1, embedding_dim=8),
|
||||
DenseFeat('hist_len', 1)]
|
||||
|
||||
feature_columns += [VarLenSparseFeat('hist_movie_id', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=50)]
|
||||
|
||||
# 行为特征列表,表示的是基础特征
|
||||
behavior_feature_list = ['movie_id']
|
||||
# 行为序列特征
|
||||
behavior_seq_feature_list = ['hist_movie_id']
|
||||
|
||||
history = DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list)
|
||||
|
||||
history.compile('adam', 'binary_crossentropy')
|
||||
|
||||
history.fit(X_train, y_train, batch_size=64, epochs=5, validation_split=0.2, )
|
||||
183
DeepRecommendationModel/代码/DeepCrossing.py
Normal file
@@ -0,0 +1,183 @@
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore")
|
||||
import itertools
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from collections import namedtuple
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow import keras
|
||||
from tensorflow.keras.layers import *
|
||||
from tensorflow.keras.models import *
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
|
||||
|
||||
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
|
||||
|
||||
|
||||
def data_process(data_df, dense_features, sparse_features):
|
||||
"""
|
||||
简单处理特征,包括填充缺失值,数值处理,类别编码
|
||||
param data_df: DataFrame格式的数据
|
||||
param dense_features: 数值特征名称列表
|
||||
param sparse_features: 类别特征名称列表
|
||||
"""
|
||||
data_df[dense_features] = data_df[dense_features].fillna(0.0)
|
||||
for f in dense_features:
|
||||
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
|
||||
|
||||
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
|
||||
for f in sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
data_df[f] = lbe.fit_transform(data_df[f])
|
||||
|
||||
return data_df[dense_features + sparse_features]
|
||||
|
||||
|
||||
def build_input_layers(feature_columns):
|
||||
"""
|
||||
构建输入层
|
||||
param feature_columns: 数据集中的所有特征对应的特征标记之
|
||||
"""
|
||||
# 构建Input层字典,并以dense和sparse两类字典的形式返回
|
||||
dense_input_dict, sparse_input_dict = {}, {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
|
||||
elif isinstance(fc, DenseFeat):
|
||||
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
|
||||
|
||||
return dense_input_dict, sparse_input_dict
|
||||
|
||||
|
||||
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
|
||||
# 定义一个embedding层对应的字典
|
||||
embedding_layers_dict = dict()
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
|
||||
if is_linear:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size + 1, 1, name='1d_emb_' + fc.name)
|
||||
else:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size + 1, fc.embedding_dim, name='kd_emb_' + fc.name)
|
||||
|
||||
return embedding_layers_dict
|
||||
|
||||
|
||||
# 将所有的sparse特征embedding拼接
|
||||
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
|
||||
# 将sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
|
||||
|
||||
embedding_list = []
|
||||
for fc in sparse_feature_columns:
|
||||
_input = input_layer_dict[fc.name] # 获取输入层
|
||||
_embed = embedding_layer_dict[fc.name] # B x 1 x dim 获取对应的embedding层
|
||||
embed = _embed(_input) # B x dim 将input层输入到embedding层中
|
||||
|
||||
# 是否需要flatten, 如果embedding列表最终是直接输入到Dense层中,需要进行Flatten,否则不需要
|
||||
if flatten:
|
||||
embed = Flatten()(embed)
|
||||
|
||||
embedding_list.append(embed)
|
||||
|
||||
return embedding_list
|
||||
|
||||
|
||||
# DNN残差块的定义
|
||||
class ResidualBlock(Layer):
|
||||
def __init__(self, units): # units表示的是DNN隐藏层神经元数量
|
||||
super(ResidualBlock, self).__init__()
|
||||
self.units = units
|
||||
|
||||
def build(self, input_shape):
|
||||
out_dim = input_shape[-1]
|
||||
self.dnn1 = Dense(self.units, activation='relu')
|
||||
self.dnn2 = Dense(out_dim, activation='relu') # 保证输入的维度和输出的维度一致才能进行残差连接
|
||||
def call(self, inputs):
|
||||
x = inputs
|
||||
x = self.dnn1(x)
|
||||
x = self.dnn2(x)
|
||||
x = Activation('relu')(x + inputs) # 残差操作
|
||||
return x
|
||||
|
||||
|
||||
# block_nums表示DNN残差块的数量
|
||||
def get_dnn_logits(dnn_inputs, block_nums=3):
|
||||
dnn_out = dnn_inputs
|
||||
for i in range(block_nums):
|
||||
dnn_out = ResidualBlock(64)(dnn_out)
|
||||
|
||||
# 将dnn的输出转化成logits
|
||||
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
|
||||
|
||||
return dnn_logits
|
||||
|
||||
|
||||
def DeepCrossing(dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(dnn_feature_columns)
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
#将所有的dense特征拼接到一起
|
||||
dense_dnn_list = list(dense_input_dict.values())
|
||||
dense_dnn_inputs = Concatenate(axis=1)(dense_dnn_list) # B x n (n表示数值特征的数量)
|
||||
|
||||
# 因为需要将其与dense特征拼接到一起所以需要Flatten,不进行Flatten的Embedding层输出的维度为:Bx1xdim
|
||||
sparse_dnn_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
|
||||
|
||||
sparse_dnn_inputs = Concatenate(axis=1)(sparse_dnn_list) # B x m*dim (n表示类别特征的数量,dim表示embedding的维度)
|
||||
|
||||
# 将dense特征和Sparse特征拼接到一起
|
||||
dnn_inputs = Concatenate(axis=1)([dense_dnn_inputs, sparse_dnn_inputs]) # B x (n + m*dim)
|
||||
|
||||
# 输入到dnn中,需要提前定义需要几个残差块
|
||||
output_layer = get_dnn_logits(dnn_inputs, block_nums=3)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 读取数据
|
||||
data = pd.read_csv('./data/criteo_sample.txt')
|
||||
|
||||
# 划分dense和sparse特征
|
||||
columns = data.columns.values
|
||||
dense_features = [feat for feat in columns if 'I' in feat]
|
||||
sparse_features = [feat for feat in columns if 'C' in feat]
|
||||
|
||||
# 简单的数据预处理
|
||||
train_data = data_process(data, dense_features, sparse_features)
|
||||
train_data['label'] = data['label']
|
||||
|
||||
# 将特征做标记
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for feat in sparse_features] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建DeepCrossing模型
|
||||
history = DeepCrossing(dnn_feature_columns)
|
||||
|
||||
history.summary()
|
||||
history.compile(optimizer="adam",
|
||||
loss="binary_crossentropy",
|
||||
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
|
||||
|
||||
# 将输入数据转化成字典的形式输入
|
||||
train_model_input = {name: data[name] for name in dense_features + sparse_features}
|
||||
# 模型训练
|
||||
history.fit(train_model_input, train_data['label'].values,
|
||||
batch_size=64, epochs=5, validation_split=0.2, )
|
||||
220
DeepRecommendationModel/代码/DeepFM.py
Normal file
@@ -0,0 +1,220 @@
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore")
|
||||
import itertools
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from collections import namedtuple
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import *
|
||||
from tensorflow.keras.models import *
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
|
||||
|
||||
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
|
||||
|
||||
|
||||
# 简单处理特征,包括填充缺失值,数值处理,类别编码
|
||||
def data_process(data_df, dense_features, sparse_features):
|
||||
data_df[dense_features] = data_df[dense_features].fillna(0.0)
|
||||
for f in dense_features:
|
||||
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
|
||||
|
||||
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
|
||||
for f in sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
data_df[f] = lbe.fit_transform(data_df[f])
|
||||
|
||||
return data_df[dense_features + sparse_features]
|
||||
|
||||
|
||||
def build_input_layers(feature_columns):
|
||||
# 构建Input层字典,并以dense和sparse两类字典的形式返回
|
||||
dense_input_dict, sparse_input_dict = {}, {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
|
||||
elif isinstance(fc, DenseFeat):
|
||||
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
|
||||
|
||||
return dense_input_dict, sparse_input_dict
|
||||
|
||||
|
||||
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
|
||||
# 定义一个embedding层对应的字典
|
||||
embedding_layers_dict = dict()
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
|
||||
if is_linear:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, 1, name='1d_emb_' + fc.name)
|
||||
else:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name='kd_emb_' + fc.name)
|
||||
|
||||
return embedding_layers_dict
|
||||
|
||||
|
||||
def get_linear_logits(dense_input_dict, sparse_input_dict, sparse_feature_columns):
|
||||
# 将所有的dense特征的Input层,然后经过一个全连接层得到dense特征的logits
|
||||
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
|
||||
dense_logits_output = Dense(1)(concat_dense_inputs)
|
||||
|
||||
# 获取linear部分sparse特征的embedding层,这里使用embedding的原因是:
|
||||
# 对于linear部分直接将特征进行onehot然后通过一个全连接层,当维度特别大的时候,计算比较慢
|
||||
# 使用embedding层的好处就是可以通过查表的方式获取到哪些非零的元素对应的权重,然后在将这些权重相加,效率比较高
|
||||
linear_embedding_layers = build_embedding_layers(sparse_feature_columns, sparse_input_dict, is_linear=True)
|
||||
|
||||
# 将一维的embedding拼接,注意这里需要使用一个Flatten层,使维度对应
|
||||
sparse_1d_embed = []
|
||||
for fc in sparse_feature_columns:
|
||||
feat_input = sparse_input_dict[fc.name]
|
||||
embed = Flatten()(linear_embedding_layers[fc.name](feat_input)) # B x 1
|
||||
sparse_1d_embed.append(embed)
|
||||
|
||||
# embedding中查询得到的权重就是对应onehot向量中一个位置的权重,所以后面不用再接一个全连接了,本身一维的embedding就相当于全连接
|
||||
# 只不过是这里的输入特征只有0和1,所以直接向非零元素对应的权重相加就等同于进行了全连接操作(非零元素部分乘的是1)
|
||||
sparse_logits_output = Add()(sparse_1d_embed)
|
||||
|
||||
# 最终将dense特征和sparse特征对应的logits相加,得到最终linear的logits
|
||||
linear_logits = Add()([dense_logits_output, sparse_logits_output])
|
||||
return linear_logits
|
||||
|
||||
|
||||
class FM_Layer(Layer):
|
||||
def __init__(self):
|
||||
super(FM_Layer, self).__init__()
|
||||
|
||||
def call(self, inputs):
|
||||
# 优化后的公式为: 0.5 * 求和(和的平方-平方的和) =>> B x 1
|
||||
concated_embeds_value = inputs # B x n x k
|
||||
|
||||
square_of_sum = tf.square(tf.reduce_sum(concated_embeds_value, axis=1, keepdims=True)) # B x 1 x k
|
||||
sum_of_square = tf.reduce_sum(concated_embeds_value * concated_embeds_value, axis=1, keepdims=True) # B x1 xk
|
||||
cross_term = square_of_sum - sum_of_square # B x 1 x k
|
||||
cross_term = 0.5 * tf.reduce_sum(cross_term, axis=2, keepdims=False) # B x 1
|
||||
|
||||
return cross_term
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return (None, 1)
|
||||
|
||||
|
||||
def get_fm_logits(sparse_input_dict, sparse_feature_columns, dnn_embedding_layers):
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), sparse_feature_columns))
|
||||
|
||||
# 只考虑sparse的二阶交叉,将所有的embedding拼接到一起进行FM计算
|
||||
# 因为类别型数据输入的只有0和1所以不需要考虑将隐向量与x相乘,直接对隐向量进行操作即可
|
||||
sparse_kd_embed = []
|
||||
for fc in sparse_feature_columns:
|
||||
feat_input = sparse_input_dict[fc.name]
|
||||
_embed = dnn_embedding_layers[fc.name](feat_input) # B x 1 x k
|
||||
sparse_kd_embed.append(_embed)
|
||||
|
||||
# 将所有sparse的embedding拼接起来,得到 (n, k)的矩阵,其中n为特征数,k为embedding大小
|
||||
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed) # B x n x k
|
||||
fm_cross_out = FM_Layer()(concat_sparse_kd_embed)
|
||||
|
||||
return fm_cross_out
|
||||
|
||||
|
||||
def get_dnn_logits(sparse_input_dict, sparse_feature_columns, dnn_embedding_layers):
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), sparse_feature_columns))
|
||||
|
||||
# 将所有非零的sparse特征对应的embedding拼接到一起
|
||||
sparse_kd_embed = []
|
||||
for fc in sparse_feature_columns:
|
||||
feat_input = sparse_input_dict[fc.name]
|
||||
_embed = dnn_embedding_layers[fc.name](feat_input) # B x 1 x k
|
||||
_embed = Flatten()(_embed) # B x k
|
||||
sparse_kd_embed.append(_embed)
|
||||
|
||||
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed) # B x nk
|
||||
|
||||
# dnn层,这里的Dropout参数,Dense中的参数都可以自己设定,以及Dense的层数都可以自行设定
|
||||
mlp_out = Dropout(0.5)(Dense(256, activation='relu')(concat_sparse_kd_embed))
|
||||
mlp_out = Dropout(0.3)(Dense(256, activation='relu')(mlp_out))
|
||||
mlp_out = Dropout(0.1)(Dense(256, activation='relu')(mlp_out))
|
||||
|
||||
dnn_out = Dense(1)(mlp_out)
|
||||
|
||||
return dnn_out
|
||||
|
||||
def DeepFM(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# embedding层用户构建FM交叉部分和DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 将输入到dnn中的所有sparse特征筛选出来
|
||||
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
fm_logits = get_fm_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # 只考虑二阶项
|
||||
|
||||
# 将所有的Embedding都拼起来,一起输入到dnn中
|
||||
dnn_logits = get_dnn_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
|
||||
|
||||
# 将linear,FM,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, fm_logits, dnn_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layers)
|
||||
return model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 读取数据
|
||||
data = pd.read_csv('./data/criteo_sample.txt')
|
||||
|
||||
# 划分dense和sparse特征
|
||||
columns = data.columns.values
|
||||
dense_features = [feat for feat in columns if 'I' in feat]
|
||||
sparse_features = [feat for feat in columns if 'C' in feat]
|
||||
|
||||
# 简单的数据预处理
|
||||
train_data = data_process(data, dense_features, sparse_features)
|
||||
train_data['label'] = data['label']
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建DeepFM模型
|
||||
history = DeepFM(linear_feature_columns, dnn_feature_columns)
|
||||
history.summary()
|
||||
history.compile(optimizer="adam",
|
||||
loss="binary_crossentropy",
|
||||
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
|
||||
|
||||
# 将输入数据转化成字典的形式输入
|
||||
train_model_input = {name: data[name] for name in dense_features + sparse_features}
|
||||
# 模型训练
|
||||
history.fit(train_model_input, train_data['label'].values,
|
||||
batch_size=64, epochs=5, validation_split=0.2, )
|
||||
121
DeepRecommendationModel/代码/NCF.py
Normal file
@@ -0,0 +1,121 @@
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore")
|
||||
import itertools
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from collections import namedtuple
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import *
|
||||
from tensorflow.keras.models import *
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
|
||||
|
||||
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
|
||||
|
||||
|
||||
def build_input_layers(feature_columns):
|
||||
# 构建Input层字典,并以dense和sparse两类字典的形式返回
|
||||
dense_input_dict, sparse_input_dict = {}, {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
|
||||
elif isinstance(fc, DenseFeat):
|
||||
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
|
||||
|
||||
return dense_input_dict, sparse_input_dict
|
||||
|
||||
|
||||
def build_embedding_layers(feature_columns, input_layers_dict, is_linear, prefix=''):
|
||||
# 定义一个embedding层对应的字典
|
||||
embedding_layers_dict = dict()
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
|
||||
if is_linear:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size + 1, 1, name=prefix + '1d_emb_' + fc.name)
|
||||
else:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size + 1, fc.embedding_dim, name=prefix + 'kd_emb_' + fc.name)
|
||||
|
||||
return embedding_layers_dict
|
||||
|
||||
|
||||
def get_dnn_out(dnn_inputs, units=(32, 16)):
|
||||
|
||||
dnn_out = dnn_inputs
|
||||
for out_dim in units:
|
||||
dnn_out = Dense(out_dim)(dnn_out)
|
||||
|
||||
return dnn_out
|
||||
|
||||
|
||||
def NCF(dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
_, sparse_input_dict = build_input_layers(dnn_feature_columns) # 没有dense特征
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(sparse_input_dict.values())
|
||||
|
||||
# 创建两份embedding向量, 由于Embedding层的name不能相同,所以这里加入一个prefix参数
|
||||
GML_embedding_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False, prefix='GML')
|
||||
MLP_embedding_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False, prefix='MLP')
|
||||
|
||||
# 构建GML的输出
|
||||
GML_user_emb = Flatten()(GML_embedding_dict['user_id'](sparse_input_dict['user_id'])) # B x embed_dim
|
||||
GML_item_emb = Flatten()(GML_embedding_dict['movie_id'](sparse_input_dict['movie_id'])) # B x embed_dim
|
||||
GML_out = tf.multiply(GML_user_emb, GML_item_emb) # 按元素相乘
|
||||
|
||||
# 构建MLP的输出
|
||||
MLP_user_emb = Flatten()(MLP_embedding_dict['user_id'](sparse_input_dict['user_id'])) # B x embed_dim
|
||||
MLP_item_emb = Flatten()(MLP_embedding_dict['movie_id'](sparse_input_dict['movie_id'])) # B x embed_dim
|
||||
MLP_dnn_input = Concatenate(axis=1)([MLP_user_emb, MLP_item_emb]) # 两个向量concat
|
||||
MLP_dnn_out = get_dnn_out(MLP_dnn_input, (32, 16))
|
||||
|
||||
# 将dense特征和Sparse特征拼接到一起
|
||||
concat_out = Concatenate(axis=1)([GML_out, MLP_dnn_out])
|
||||
|
||||
# 输入到dnn中,需要提前定义需要几个残差块
|
||||
# output_layer = Dense(1, 'sigmoid')(concat_out)
|
||||
output_layer = Dense(1)(concat_out)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 读取数据,NCF使用的特征只有user_id和item_id
|
||||
rnames = ['user_id','movie_id','rating','timestamp']
|
||||
data = pd.read_csv('./data/ml-1m/ratings.dat', sep='::', engine='python', names=rnames)
|
||||
|
||||
lbe = LabelEncoder()
|
||||
data['user_id'] = lbe.fit_transform(data['user_id'])
|
||||
data['movie_id'] = lbe.fit_transform(data['movie_id'])
|
||||
|
||||
train_data = data[['user_id', 'movie_id']]
|
||||
train_data['label'] = data['rating']
|
||||
|
||||
dnn_feature_columns = [SparseFeat('user_id', train_data['user_id'].nunique(), 8),
|
||||
SparseFeat('movie_id', train_data['movie_id'].nunique(), 8)]
|
||||
|
||||
# 构建FM模型
|
||||
history = NCF(dnn_feature_columns)
|
||||
history.summary()
|
||||
# 因为数据目前只有用户点击的数据,没有用户未点击的movie,所以这里不能用于做ctr预估
|
||||
# 如果需要做ctr预估需要给用户点击和未点击的movie打标签,这里就先预测用户评分
|
||||
history.compile(optimizer="adam", loss="mse", metrics=['mae'])
|
||||
|
||||
# 将输入数据转化成字典的形式输入
|
||||
# 将数据转换成字典的形式,用于Input()层对应
|
||||
train_model_input = {name: train_data[name] for name in ['user_id', 'movie_id', 'label']}
|
||||
|
||||
# 模型训练
|
||||
history.fit(train_model_input, train_data['label'].values,
|
||||
batch_size=32, epochs=2, validation_split=0.2, )
|
||||
208
DeepRecommendationModel/代码/NFM.py
Normal file
@@ -0,0 +1,208 @@
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore")
|
||||
import itertools
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from collections import namedtuple
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import *
|
||||
from tensorflow.keras.models import *
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
|
||||
|
||||
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
|
||||
|
||||
|
||||
# 简单处理特征,包括填充缺失值,数值处理,类别编码
|
||||
def data_process(data_df, dense_features, sparse_features):
|
||||
data_df[dense_features] = data_df[dense_features].fillna(0.0)
|
||||
for f in dense_features:
|
||||
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
|
||||
|
||||
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
|
||||
for f in sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
data_df[f] = lbe.fit_transform(data_df[f])
|
||||
|
||||
return data_df[dense_features + sparse_features]
|
||||
|
||||
|
||||
def build_input_layers(feature_columns):
|
||||
# 构建Input层字典,并以dense和sparse两类字典的形式返回
|
||||
dense_input_dict, sparse_input_dict = {}, {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
|
||||
elif isinstance(fc, DenseFeat):
|
||||
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
|
||||
|
||||
return dense_input_dict, sparse_input_dict
|
||||
|
||||
|
||||
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
|
||||
# 定义一个embedding层对应的字典
|
||||
embedding_layers_dict = dict()
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
|
||||
if is_linear:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, 1, name='1d_emb_' + fc.name)
|
||||
else:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name='kd_emb_' + fc.name)
|
||||
|
||||
return embedding_layers_dict
|
||||
|
||||
|
||||
def get_linear_logits(dense_input_dict, sparse_input_dict, sparse_feature_columns):
|
||||
# 将所有的dense特征的Input层,然后经过一个全连接层得到dense特征的logits
|
||||
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
|
||||
dense_logits_output = Dense(1)(concat_dense_inputs)
|
||||
|
||||
# 获取linear部分sparse特征的embedding层,这里使用embedding的原因是:
|
||||
# 对于linear部分直接将特征进行onehot然后通过一个全连接层,当维度特别大的时候,计算比较慢
|
||||
# 使用embedding层的好处就是可以通过查表的方式获取到哪些非零的元素对应的权重,然后在将这些权重相加,效率比较高
|
||||
linear_embedding_layers = build_embedding_layers(sparse_feature_columns, sparse_input_dict, is_linear=True)
|
||||
|
||||
# 将一维的embedding拼接,注意这里需要使用一个Flatten层,使维度对应
|
||||
sparse_1d_embed = []
|
||||
for fc in sparse_feature_columns:
|
||||
feat_input = sparse_input_dict[fc.name]
|
||||
embed = Flatten()(linear_embedding_layers[fc.name](feat_input))
|
||||
sparse_1d_embed.append(embed)
|
||||
|
||||
# embedding中查询得到的权重就是对应onehot向量中一个位置的权重,所以后面不用再接一个全连接了,本身一维的embedding就相当于全连接
|
||||
# 只不过是这里的输入特征只有0和1,所以直接向非零元素对应的权重相加就等同于进行了全连接操作(非零元素部分乘的是1)
|
||||
sparse_logits_output = Add()(sparse_1d_embed)
|
||||
|
||||
# 最终将dense特征和sparse特征对应的logits相加,得到最终linear的logits
|
||||
linear_part = Add()([dense_logits_output, sparse_logits_output])
|
||||
return linear_part
|
||||
|
||||
|
||||
class BiInteractionPooling(Layer):
|
||||
def __init__(self):
|
||||
super(BiInteractionPooling, self).__init__()
|
||||
|
||||
def call(self, inputs):
|
||||
# 优化后的公式为: 0.5 * (和的平方-平方的和) =>> B x k
|
||||
concated_embeds_value = inputs # B x n x k
|
||||
|
||||
square_of_sum = tf.square(tf.reduce_sum(concated_embeds_value, axis=1, keepdims=False)) # B x k
|
||||
sum_of_square = tf.reduce_sum(concated_embeds_value * concated_embeds_value, axis=1, keepdims=False) # B x k
|
||||
cross_term = 0.5 * (square_of_sum - sum_of_square) # B x k
|
||||
|
||||
return cross_term
|
||||
|
||||
def compute_output_shape(self, input_shape):
|
||||
return (None, input_shape[2])
|
||||
|
||||
|
||||
def get_bi_interaction_pooling_output(sparse_input_dict, sparse_feature_columns, dnn_embedding_layers):
|
||||
# 只考虑sparse的二阶交叉,将所有的embedding拼接到一起
|
||||
# 这里在实际运行的时候,其实只会将那些非零元素对应的embedding拼接到一起
|
||||
# 并且将非零元素对应的embedding拼接到一起本质上相当于已经乘了x, 因为x中的值是1(公式中的x)
|
||||
sparse_kd_embed = []
|
||||
for fc in sparse_feature_columns:
|
||||
feat_input = sparse_input_dict[fc.name]
|
||||
_embed = dnn_embedding_layers[fc.name](feat_input) # B x 1 x k
|
||||
sparse_kd_embed.append(_embed)
|
||||
|
||||
# 将所有sparse的embedding拼接起来,得到 (n, k)的矩阵,其中n为特征数,k为embedding大小
|
||||
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed) # B x n x k
|
||||
|
||||
pooling_out = BiInteractionPooling()(concat_sparse_kd_embed)
|
||||
|
||||
return pooling_out
|
||||
|
||||
|
||||
def get_dnn_logits(pooling_out):
|
||||
# dnn层,这里的Dropout参数,Dense中的参数都可以自己设定, 论文中还说使用了BN, 但是个人觉得BN和dropout同时使用
|
||||
# 可能会出现一些问题,感兴趣的可以尝试一些,这里就先不加上了
|
||||
dnn_out = Dropout(0.5)(Dense(1024, activation='relu')(pooling_out))
|
||||
dnn_out = Dropout(0.3)(Dense(512, activation='relu')(dnn_out))
|
||||
dnn_out = Dropout(0.1)(Dense(256, activation='relu')(dnn_out))
|
||||
|
||||
dnn_logits = Dense(1)(dnn_out)
|
||||
|
||||
return dnn_logits
|
||||
|
||||
def NFM(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
# embedding层用户构建FM交叉部分和DNN的输入部分
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
# 将输入到dnn中的sparse特征筛选出来
|
||||
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
pooling_output = get_bi_interaction_pooling_output(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # B x (n(n-1)/2)
|
||||
|
||||
# 论文中说到在池化之后加上了BN操作
|
||||
pooling_output = BatchNormalization()(pooling_output)
|
||||
|
||||
dnn_logits = get_dnn_logits(pooling_output)
|
||||
|
||||
# 将linear,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, dnn_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layers = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layers)
|
||||
return model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 读取数据
|
||||
data = pd.read_csv('./data/criteo_sample.txt')
|
||||
|
||||
# 划分dense和sparse特征
|
||||
columns = data.columns.values
|
||||
dense_features = [feat for feat in columns if 'I' in feat]
|
||||
sparse_features = [feat for feat in columns if 'C' in feat]
|
||||
|
||||
# 简单的数据预处理
|
||||
train_data = data_process(data, dense_features, sparse_features)
|
||||
train_data['label'] = data['label']
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建NFM模型
|
||||
history = NFM(linear_feature_columns, dnn_feature_columns)
|
||||
history.summary()
|
||||
history.compile(optimizer="adam",
|
||||
loss="binary_crossentropy",
|
||||
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
|
||||
|
||||
# 将输入数据转化成字典的形式输入
|
||||
train_model_input = {name: data[name] for name in dense_features + sparse_features}
|
||||
# 模型训练
|
||||
history.fit(train_model_input, train_data['label'].values,
|
||||
batch_size=64, epochs=5, validation_split=0.2, )
|
||||
227
DeepRecommendationModel/代码/PNN.py
Normal file
@@ -0,0 +1,227 @@
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore")
|
||||
import itertools
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from collections import namedtuple
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import *
|
||||
from tensorflow.keras.models import *
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
|
||||
|
||||
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
|
||||
|
||||
|
||||
# 简单处理特征,包括填充缺失值,数值处理,类别编码
|
||||
def data_process(data_df, dense_features, sparse_features):
|
||||
data_df[dense_features] = data_df[dense_features].fillna(0.0)
|
||||
for f in dense_features:
|
||||
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
|
||||
|
||||
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
|
||||
for f in sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
data_df[f] = lbe.fit_transform(data_df[f])
|
||||
|
||||
return data_df[dense_features + sparse_features]
|
||||
|
||||
|
||||
def build_input_layers(feature_columns):
|
||||
# 构建Input层字典,并以dense和sparse两类字典的形式返回
|
||||
dense_input_dict, sparse_input_dict = {}, {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
|
||||
elif isinstance(fc, DenseFeat):
|
||||
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
|
||||
|
||||
return dense_input_dict, sparse_input_dict
|
||||
|
||||
|
||||
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
|
||||
# 定义一个embedding层对应的字典
|
||||
embedding_layers_dict = dict()
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
|
||||
if is_linear:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size + 1, 1, name='1d_emb_' + fc.name)
|
||||
else:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size + 1, fc.embedding_dim, name='kd_emb_' + fc.name)
|
||||
|
||||
return embedding_layers_dict
|
||||
|
||||
|
||||
# 将所有的sparse特征embedding拼接
|
||||
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
|
||||
# 将sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
|
||||
|
||||
embedding_list = []
|
||||
for fc in sparse_feature_columns:
|
||||
_input = input_layer_dict[fc.name] # 获取输入层
|
||||
_embed = embedding_layer_dict[fc.name] # B x 1 x dim 获取对应的embedding层
|
||||
embed = _embed(_input) # B x dim 将input层输入到embedding层中
|
||||
|
||||
# 是否需要flatten, 如果embedding列表最终是直接输入到Dense层中,需要进行Flatten,否则不需要
|
||||
if flatten:
|
||||
embed = Flatten()(embed)
|
||||
|
||||
embedding_list.append(embed)
|
||||
|
||||
return embedding_list
|
||||
|
||||
|
||||
def get_dnn_logits(dnn_inputs, units=(64, 32)):
|
||||
|
||||
dnn_out = dnn_inputs
|
||||
for out_dim in units:
|
||||
dnn_out = Dense(out_dim, activation='relu')(dnn_out)
|
||||
|
||||
# 将dnn的输出转化成logits
|
||||
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
|
||||
|
||||
return dnn_logits
|
||||
|
||||
|
||||
class ProductLayer(Layer):
|
||||
def __init__(self, units, use_inner=True, use_outer=False):
|
||||
super(ProductLayer, self).__init__()
|
||||
self.use_inner = use_inner
|
||||
self.use_outer = use_outer
|
||||
self.units = units # 指的是原文中D1的大小
|
||||
|
||||
def build(self, input_shape):
|
||||
# 需要注意input_shape也是一个列表,并且里面的每一个元素都是TensorShape类型,
|
||||
# 需要将其转换成list然后才能参与数值计算,不然类型容易错
|
||||
# input_shape[0] : feat_nums x embed_dims
|
||||
self.feat_nums = len(input_shape)
|
||||
self.embed_dims = input_shape[0].as_list()[-1]
|
||||
flatten_dims = self.feat_nums * self.embed_dims
|
||||
|
||||
# Linear signals weight, 这部分是用于产生Z的权重,因为这里需要计算的是两个元素对应元素乘积然后再相加
|
||||
# 等价于先把矩阵拉成一维,然后相乘再相加
|
||||
self.linear_w = self.add_weight(name='linear_w', shape=(flatten_dims, self.units), initializer='glorot_normal')
|
||||
|
||||
# inner product weight
|
||||
if self.use_inner:
|
||||
# 优化之后的内积权重是未优化时的一个分解矩阵,未优化时的矩阵大小为:D x N x N
|
||||
# 优化后的内积权重大小为:D x N
|
||||
self.inner_w = self.add_weight(name='inner_w', shape=(self.units, self.feat_nums), initializer='glorot_normal')
|
||||
|
||||
if self.use_outer:
|
||||
# 优化之后的外积权重大小为:D x embed_dim x embed_dim, 因为计算外积的时候在特征维度通过求和的方式进行了压缩
|
||||
self.outer_w = self.add_weight(name='outer_w', shape=(self.units, self.embed_dims, self.embed_dims), initializer='glorot_normal')
|
||||
|
||||
|
||||
def call(self, inputs):
|
||||
# inputs是一个列表
|
||||
# 先将所有的embedding拼接起来计算线性信号部分的输出
|
||||
concat_embed = Concatenate(axis=1)(inputs) # B x feat_nums x embed_dims
|
||||
# 将两个矩阵都拉成二维的,然后通过矩阵相乘得到最终的结果
|
||||
concat_embed_ = tf.reshape(concat_embed, shape=[-1, self.feat_nums * self.embed_dims])
|
||||
lz = tf.matmul(concat_embed_, self.linear_w) # B x units
|
||||
|
||||
# inner
|
||||
lp_list = []
|
||||
if self.use_inner:
|
||||
for i in range(self.units):
|
||||
# 相当于给每一个特征向量都乘以一个权重
|
||||
# self.inner_w[i] : (embed_dims, ) 添加一个维度变成 (embed_dims, 1)
|
||||
delta = tf.multiply(concat_embed, tf.expand_dims(self.inner_w[i], axis=1)) # B x feat_nums x embed_dims
|
||||
# 在特征之间的维度上求和
|
||||
delta = tf.reduce_sum(delta, axis=1) # B x embed_dims
|
||||
# 最终在特征embedding维度上求二范数得到p
|
||||
lp_list.append(tf.reduce_sum(tf.square(delta), axis=1, keepdims=True)) # B x 1
|
||||
|
||||
# outer
|
||||
if self.use_outer:
|
||||
# 外积的优化是将embedding矩阵,在特征间的维度上通过求和进行压缩
|
||||
feat_sum = tf.reduce_sum(concat_embed, axis=1) # B x embed_dims
|
||||
|
||||
# 为了方便计算外积,将维度进行扩展
|
||||
f1 = tf.expand_dims(feat_sum, axis=2) # B x embed_dims x 1
|
||||
f2 = tf.expand_dims(feat_sum, axis=1) # B x 1 x embed_dims
|
||||
|
||||
# 求外积, a * a^T
|
||||
product = tf.matmul(f1, f2) # B x embed_dims x embed_dims
|
||||
|
||||
# 将product与外积权重矩阵对应元素相乘再相加
|
||||
for i in range(self.units):
|
||||
lpi = tf.multiply(product, self.outer_w[i]) # B x embed_dims x embed_dims
|
||||
# 将后面两个维度进行求和,需要注意的是,每使用一次reduce_sum就会减少一个维度
|
||||
lpi = tf.reduce_sum(lpi, axis=[1, 2]) # B
|
||||
# 添加一个维度便于特征拼接
|
||||
lpi = tf.expand_dims(lpi, axis=1) # B x 1
|
||||
lp_list.append(lpi)
|
||||
|
||||
# 将所有交叉特征拼接到一起
|
||||
lp = Concatenate(axis=1)(lp_list)
|
||||
|
||||
# 将lz和lp拼接到一起
|
||||
product_out = Concatenate(axis=1)([lz, lp])
|
||||
|
||||
return product_out
|
||||
|
||||
|
||||
def PNN(dnn_feature_columns, inner=True, outer=True):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
_, sparse_input_dict = build_input_layers(dnn_feature_columns)
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(sparse_input_dict.values())
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
sparse_embed_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=False)
|
||||
|
||||
dnn_inputs = ProductLayer(units=32, use_inner=True, use_outer=True)(sparse_embed_list)
|
||||
|
||||
# 输入到dnn中,需要提前定义需要几个残差块
|
||||
output_layer = get_dnn_logits(dnn_inputs)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
|
||||
|
||||
# 实现PNN的时候一定要明确是实现优化前的还是优化后的,因为网上有的参考代码是优化前的,有的是优化后的,容易搞混了
|
||||
if __name__ == "__main__":
|
||||
# 读取数据
|
||||
data = pd.read_csv('./data/criteo_sample.txt')
|
||||
|
||||
# 划分dense和sparse特征
|
||||
columns = data.columns.values
|
||||
dense_features = [feat for feat in columns if 'I' in feat]
|
||||
sparse_features = [feat for feat in columns if 'C' in feat]
|
||||
|
||||
# 简单的数据预处理
|
||||
train_data = data_process(data, dense_features, sparse_features)
|
||||
train_data['label'] = data['label']
|
||||
|
||||
# 只传入类别特征, 如果想要传入dense特征,也可以传入直接进行拼接
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)]
|
||||
|
||||
# 构建FM模型
|
||||
history = PNN(dnn_feature_columns)
|
||||
history.summary()
|
||||
history.compile(optimizer="adam",
|
||||
loss="binary_crossentropy",
|
||||
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
|
||||
|
||||
# 将输入数据转化成字典的形式输入
|
||||
train_model_input = {name: data[name] for name in dense_features + sparse_features}
|
||||
# 模型训练
|
||||
history.fit(train_model_input, train_data['label'].values,
|
||||
batch_size=64, epochs=5, validation_split=0.2, )
|
||||
261
DeepRecommendationModel/代码/PlotModels.py
Normal file
@@ -0,0 +1,261 @@
|
||||
from collections import namedtuple
|
||||
from tensorflow import keras
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from sklearn.preprocessing import LabelEncoder
|
||||
|
||||
from DeepCrossing import DeepCrossing
|
||||
from DeepFM import DeepFM
|
||||
from NFM import NFM
|
||||
from WideNDeep import WideNDeep
|
||||
from DIN import DIN
|
||||
from NCF import NCF
|
||||
from AFM import AFM
|
||||
from DCN import DCN
|
||||
from PNN import PNN
|
||||
from DIEN import DIEN
|
||||
|
||||
from utils import DenseFeat, SparseFeat, VarLenSparseFeat
|
||||
|
||||
# 简单处理特征,包括填充缺失值,数值处理,类别编码
|
||||
def data_process(data_df, dense_features, sparse_features):
|
||||
data_df[dense_features] = data_df[dense_features].fillna(0.0)
|
||||
for f in dense_features:
|
||||
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
|
||||
|
||||
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
|
||||
for f in sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
data_df[f] = lbe.fit_transform(data_df[f])
|
||||
|
||||
return data_df[dense_features + sparse_features]
|
||||
|
||||
|
||||
# 读取criteo数据
|
||||
def read_criteo_data():
|
||||
# 读取数据
|
||||
data = pd.read_csv('./data/criteo_sample.txt')
|
||||
|
||||
# 划分dense和sparse特征
|
||||
columns = data.columns.values
|
||||
dense_features = [feat for feat in columns if 'I' in feat]
|
||||
sparse_features = [feat for feat in columns if 'C' in feat]
|
||||
|
||||
return data, dense_features, sparse_features
|
||||
|
||||
|
||||
def plot_deepcrossing():
|
||||
data, dense_features, sparse_features = read_criteo_data()
|
||||
dense_features = dense_features[:3]
|
||||
sparse_features = sparse_features[:3]
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for feat in sparse_features] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建DeepCrossing模型
|
||||
history = DeepCrossing(dnn_feature_columns)
|
||||
keras.utils.plot_model(history, to_file="./imgs/DeepCrossing.png", show_shapes=True)
|
||||
|
||||
|
||||
def plot_deepfm():
|
||||
# 读取数据
|
||||
data, dense_features, sparse_features = read_criteo_data()
|
||||
dense_features = dense_features[:3]
|
||||
sparse_features = sparse_features[:2]
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for feat in sparse_features] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for feat in sparse_features] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建DeepFM模型
|
||||
history = DeepFM(linear_feature_columns, dnn_feature_columns)
|
||||
keras.utils.plot_model(history, to_file="./imgs/DeepFM.png", show_shapes=True)
|
||||
|
||||
|
||||
def plot_nfm():
|
||||
# 读取数据
|
||||
data, dense_features, sparse_features = read_criteo_data()
|
||||
dense_features = dense_features[:3]
|
||||
sparse_features = sparse_features[:2]
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建NFM模型
|
||||
history = NFM(linear_feature_columns, dnn_feature_columns)
|
||||
keras.utils.plot_model(history, to_file="./imgs/NFM.png", show_shapes=True)
|
||||
|
||||
|
||||
def plot_widendeep():
|
||||
# 读取数据
|
||||
data, dense_features, sparse_features = read_criteo_data()
|
||||
dense_features = dense_features[:3]
|
||||
sparse_features = sparse_features[:2]
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建WideNDeep模型
|
||||
history = WideNDeep(linear_feature_columns, dnn_feature_columns)
|
||||
keras.utils.plot_model(history, to_file="./imgs/Wide&Deep.png", show_shapes=True)
|
||||
|
||||
|
||||
def plot_din():
|
||||
# 读取数据
|
||||
samples_data = pd.read_csv("./data/movie_sample.txt", sep="\t", header = None)
|
||||
samples_data.columns = ["user_id", "gender", "age", "hist_movie_id", "hist_len", "movie_id", "movie_type_id", "label"]
|
||||
|
||||
feature_columns = [SparseFeat('user_id', max(samples_data["user_id"])+1, embedding_dim=8),
|
||||
SparseFeat('gender', max(samples_data["gender"])+1, embedding_dim=8),
|
||||
SparseFeat('age', max(samples_data["age"])+1, embedding_dim=8),
|
||||
SparseFeat('movie_id', max(samples_data["movie_id"])+1, embedding_dim=8),
|
||||
SparseFeat('movie_type_id', max(samples_data["movie_type_id"])+1, embedding_dim=8),
|
||||
DenseFeat('hist_len', 1)]
|
||||
|
||||
feature_columns += [VarLenSparseFeat('hist_movie_id', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=50)]
|
||||
|
||||
# 行为特征列表,表示的是基础特征
|
||||
behavior_feature_list = ['movie_id']
|
||||
# 行为序列特征
|
||||
behavior_seq_feature_list = ['hist_movie_id']
|
||||
|
||||
history = DIN(feature_columns, behavior_feature_list, behavior_seq_feature_list)
|
||||
keras.utils.plot_model(history, to_file="./imgs/DIN.png", show_shapes=True)
|
||||
|
||||
|
||||
def plot_pnn():
|
||||
data, dense_features, sparse_features = read_criteo_data()
|
||||
dense_features = dense_features[:3]
|
||||
sparse_features = sparse_features[:3]
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for feat in sparse_features] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建DeepCrossing模型
|
||||
history = PNN(dnn_feature_columns)
|
||||
keras.utils.plot_model(history, to_file="./imgs/PNN.png", show_shapes=True)
|
||||
|
||||
|
||||
def plot_ncf():
|
||||
# 读取数据,NCF使用的特征只有user_id和item_id
|
||||
rnames = ['user_id','movie_id','rating','timestamp']
|
||||
data = pd.read_csv('./data/ml-1m/ratings.dat', sep='::', engine='python', names=rnames)
|
||||
|
||||
lbe = LabelEncoder()
|
||||
data['user_id'] = lbe.fit_transform(data['user_id'])
|
||||
data['movie_id'] = lbe.fit_transform(data['movie_id'])
|
||||
|
||||
dnn_feature_columns = [SparseFeat('user_id', data['user_id'].nunique(), 8),
|
||||
SparseFeat('movie_id', data['movie_id'].nunique(), 8)]
|
||||
|
||||
# 构建FM模型
|
||||
history = NCF(dnn_feature_columns)
|
||||
keras.utils.plot_model(history, to_file="./imgs/NCF.png", show_shapes=True)
|
||||
|
||||
|
||||
def plot_dcn():
|
||||
# 读取数据
|
||||
data, dense_features, sparse_features = read_criteo_data()
|
||||
dense_features = dense_features[:3]
|
||||
sparse_features = sparse_features[:2]
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建AFM模型
|
||||
history = DCN(linear_feature_columns, dnn_feature_columns)
|
||||
keras.utils.plot_model(history, to_file="./imgs/DCN.png", show_shapes=True)
|
||||
|
||||
|
||||
def plot_afm():
|
||||
# 读取数据
|
||||
data, dense_features, sparse_features = read_criteo_data()
|
||||
dense_features = dense_features[:3]
|
||||
sparse_features = sparse_features[:2]
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建AFM模型
|
||||
history = AFM(linear_feature_columns, dnn_feature_columns)
|
||||
keras.utils.plot_model(history, to_file="./imgs/AFM.png", show_shapes=True)
|
||||
|
||||
|
||||
def plot_dien():
|
||||
"""读取数据"""
|
||||
samples_data = pd.read_csv("data/movie_sample.txt", sep="\t", header = None)
|
||||
samples_data.columns = ["user_id", "gender", "age", "hist_movie_id", "hist_len", "movie_id", "movie_type_id", "label"]
|
||||
|
||||
"""数据集"""
|
||||
X = samples_data[["user_id", "gender", "age", "hist_movie_id", "hist_len", "movie_id", "movie_type_id"]]
|
||||
y = samples_data["label"]
|
||||
|
||||
"""特征封装"""
|
||||
feature_columns = [SparseFeat('user_id', max(samples_data["user_id"])+1, embedding_dim=8),
|
||||
SparseFeat('gender', max(samples_data["gender"])+1, embedding_dim=8),
|
||||
SparseFeat('age', max(samples_data["age"])+1, embedding_dim=8),
|
||||
SparseFeat('movie_id', max(samples_data["movie_id"])+1, embedding_dim=8),
|
||||
SparseFeat('movie_type_id', max(samples_data["movie_type_id"])+1, embedding_dim=8),
|
||||
DenseFeat('hist_len', 1)]
|
||||
|
||||
feature_columns += [VarLenSparseFeat('hist_movie_id', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=50)]
|
||||
feature_columns += [VarLenSparseFeat('neg_hist_movie_id', vocabulary_size=max(samples_data["movie_id"])+1, embedding_dim=8, maxlen=50)]
|
||||
|
||||
# 行为特征列表,表示的是基础特征
|
||||
behavior_feature_list = ['movie_id']
|
||||
# 行为序列特征
|
||||
behavior_seq_feature_list = ['hist_movie_id']
|
||||
# 负采样序列特征
|
||||
neg_seq_feature_list = ['neg_hist_movie_id']
|
||||
|
||||
"""构建DIN模型"""
|
||||
history = DIEN(feature_columns, behavior_feature_list, behavior_seq_feature_list, neg_seq_feature_list, use_neg_sample=True)
|
||||
|
||||
keras.utils.plot_model(history, to_file="./imgs/DIEN.png", show_shapes=True)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
# plot_deepcrossing()
|
||||
# plot_deepfm()
|
||||
# plot_nfm()
|
||||
# plot_widendeep()
|
||||
# plot_din()
|
||||
# plot_ncf()
|
||||
# plot_afm()
|
||||
# plot_dcn()
|
||||
# plot_pnn()
|
||||
plot_dien()
|
||||
|
||||
194
DeepRecommendationModel/代码/WideNDeep.py
Normal file
@@ -0,0 +1,194 @@
|
||||
import warnings
|
||||
warnings.filterwarnings("ignore")
|
||||
import itertools
|
||||
import pandas as pd
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from collections import namedtuple
|
||||
|
||||
import tensorflow as tf
|
||||
from tensorflow.keras.layers import *
|
||||
from tensorflow.keras.models import *
|
||||
|
||||
from sklearn.model_selection import train_test_split
|
||||
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
|
||||
|
||||
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
|
||||
|
||||
# 简单处理特征,包括填充缺失值,数值处理,类别编码
|
||||
def data_process(data_df, dense_features, sparse_features):
|
||||
data_df[dense_features] = data_df[dense_features].fillna(0.0)
|
||||
for f in dense_features:
|
||||
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
|
||||
|
||||
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
|
||||
for f in sparse_features:
|
||||
lbe = LabelEncoder()
|
||||
data_df[f] = lbe.fit_transform(data_df[f])
|
||||
|
||||
return data_df[dense_features + sparse_features]
|
||||
|
||||
|
||||
def build_input_layers(feature_columns):
|
||||
# 构建Input层字典,并以dense和sparse两类字典的形式返回
|
||||
dense_input_dict, sparse_input_dict = {}, {}
|
||||
|
||||
for fc in feature_columns:
|
||||
if isinstance(fc, SparseFeat):
|
||||
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
|
||||
elif isinstance(fc, DenseFeat):
|
||||
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
|
||||
|
||||
return dense_input_dict, sparse_input_dict
|
||||
|
||||
|
||||
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
|
||||
# 定义一个embedding层对应的字典
|
||||
embedding_layers_dict = dict()
|
||||
|
||||
# 将特征中的sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
|
||||
|
||||
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
|
||||
if is_linear:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, 1, name='1d_emb_' + fc.name)
|
||||
else:
|
||||
for fc in sparse_feature_columns:
|
||||
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name='kd_emb_' + fc.name)
|
||||
|
||||
return embedding_layers_dict
|
||||
|
||||
|
||||
def get_linear_logits(dense_input_dict, sparse_input_dict, sparse_feature_columns):
|
||||
# 将所有的dense特征的Input层,然后经过一个全连接层得到dense特征的logits
|
||||
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
|
||||
dense_logits_output = Dense(1)(concat_dense_inputs)
|
||||
|
||||
# 获取linear部分sparse特征的embedding层,这里使用embedding的原因是:
|
||||
# 对于linear部分直接将特征进行onehot然后通过一个全连接层,当维度特别大的时候,计算比较慢
|
||||
# 使用embedding层的好处就是可以通过查表的方式获取到哪些非零的元素对应的权重,然后在将这些权重相加,效率比较高
|
||||
linear_embedding_layers = build_embedding_layers(sparse_feature_columns, sparse_input_dict, is_linear=True)
|
||||
|
||||
# 将一维的embedding拼接,注意这里需要使用一个Flatten层,使维度对应
|
||||
sparse_1d_embed = []
|
||||
for fc in sparse_feature_columns:
|
||||
feat_input = sparse_input_dict[fc.name]
|
||||
embed = Flatten()(linear_embedding_layers[fc.name](feat_input)) # B x 1
|
||||
sparse_1d_embed.append(embed)
|
||||
|
||||
# embedding中查询得到的权重就是对应onehot向量中一个位置的权重,所以后面不用再接一个全连接了,本身一维的embedding就相当于全连接
|
||||
# 只不过是这里的输入特征只有0和1,所以直接向非零元素对应的权重相加就等同于进行了全连接操作(非零元素部分乘的是1)
|
||||
sparse_logits_output = Add()(sparse_1d_embed)
|
||||
|
||||
# 最终将dense特征和sparse特征对应的logits相加,得到最终linear的logits
|
||||
linear_logits = Add()([dense_logits_output, sparse_logits_output])
|
||||
return linear_logits
|
||||
|
||||
|
||||
# 将所有的sparse特征embedding拼接
|
||||
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
|
||||
# 将sparse特征筛选出来
|
||||
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
|
||||
|
||||
embedding_list = []
|
||||
for fc in sparse_feature_columns:
|
||||
_input = input_layer_dict[fc.name] # 获取输入层
|
||||
_embed = embedding_layer_dict[fc.name] # B x 1 x dim 获取对应的embedding层
|
||||
embed = _embed(_input) # B x dim 将input层输入到embedding层中
|
||||
|
||||
# 是否需要flatten, 如果embedding列表最终是直接输入到Dense层中,需要进行Flatten,否则不需要
|
||||
if flatten:
|
||||
embed = Flatten()(embed)
|
||||
|
||||
embedding_list.append(embed)
|
||||
|
||||
return embedding_list
|
||||
|
||||
|
||||
def get_dnn_logits(dense_input_dict, sparse_input_dict, sparse_feature_columns, dnn_embedding_layers):
|
||||
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values())) # B x n1 (n表示的是dense特征的维度)
|
||||
|
||||
sparse_kd_embed = concat_embedding_list(sparse_feature_columns, sparse_input_dict, dnn_embedding_layers, flatten=True)
|
||||
|
||||
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed) # B x n2k (n2表示的是Sparse特征的维度)
|
||||
|
||||
dnn_input = Concatenate(axis=1)([concat_dense_inputs, concat_sparse_kd_embed]) # B x (n2k + n1)
|
||||
|
||||
# dnn层,这里的Dropout参数,Dense中的参数及Dense的层数都可以自己设定
|
||||
dnn_out = Dropout(0.5)(Dense(1024, activation='relu')(dnn_input))
|
||||
dnn_out = Dropout(0.3)(Dense(512, activation='relu')(dnn_out))
|
||||
dnn_out = Dropout(0.1)(Dense(256, activation='relu')(dnn_out))
|
||||
|
||||
dnn_logits = Dense(1)(dnn_out)
|
||||
|
||||
return dnn_logits
|
||||
|
||||
# Wide&Deep 模型的wide部分及Deep部分的特征选择,应该根据实际的业务场景去确定哪些特征应该放在Wide部分,哪些特征应该放在Deep部分
|
||||
def WideNDeep(linear_feature_columns, dnn_feature_columns):
|
||||
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
|
||||
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
|
||||
|
||||
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
|
||||
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
|
||||
|
||||
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
|
||||
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
|
||||
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
|
||||
|
||||
# Wide&Deep模型论文中Wide部分使用的特征比较简单,并且得到的特征非常的稀疏,所以使用了FTRL优化Wide部分(这里没有实现FTRL)
|
||||
# 但是是根据他们业务进行选择的,我们这里将所有可能用到的特征都输入到Wide部分,具体的细节可以根据需求进行修改
|
||||
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
|
||||
|
||||
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
|
||||
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
|
||||
|
||||
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
|
||||
|
||||
# 在Wide&Deep模型中,deep部分的输入是将dense特征和embedding特征拼在一起输入到dnn中
|
||||
dnn_logits = get_dnn_logits(dense_input_dict, sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
|
||||
|
||||
# 将linear,dnn的logits相加作为最终的logits
|
||||
output_logits = Add()([linear_logits, dnn_logits])
|
||||
|
||||
# 这里的激活函数使用sigmoid
|
||||
output_layer = Activation("sigmoid")(output_logits)
|
||||
|
||||
model = Model(input_layers, output_layer)
|
||||
return model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 读取数据
|
||||
data = pd.read_csv('./data/criteo_sample.txt')
|
||||
|
||||
# 划分dense和sparse特征
|
||||
columns = data.columns.values
|
||||
dense_features = [feat for feat in columns if 'I' in feat]
|
||||
sparse_features = [feat for feat in columns if 'C' in feat]
|
||||
|
||||
# 简单的数据预处理
|
||||
train_data = data_process(data, dense_features, sparse_features)
|
||||
train_data['label'] = data['label']
|
||||
|
||||
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
|
||||
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
|
||||
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
|
||||
for feat in dense_features]
|
||||
|
||||
# 构建WideNDeep模型
|
||||
history = WideNDeep(linear_feature_columns, dnn_feature_columns)
|
||||
history.summary()
|
||||
history.compile(optimizer="adam",
|
||||
loss="binary_crossentropy",
|
||||
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
|
||||
|
||||
# 将输入数据转化成字典的形式输入
|
||||
train_model_input = {name: data[name] for name in dense_features + sparse_features}
|
||||
# 模型训练
|
||||
history.fit(train_model_input, train_data['label'].values,
|
||||
batch_size=64, epochs=5, validation_split=0.2, )
|
||||
BIN
DeepRecommendationModel/代码/__pycache__/AFM.cpython-36.pyc
Normal file
BIN
DeepRecommendationModel/代码/__pycache__/DCN.cpython-36.pyc
Normal file
BIN
DeepRecommendationModel/代码/__pycache__/DIEN.cpython-36.pyc
Normal file
BIN
DeepRecommendationModel/代码/__pycache__/DIN.cpython-36.pyc
Normal file
BIN
DeepRecommendationModel/代码/__pycache__/DeepFM.cpython-36.pyc
Normal file
BIN
DeepRecommendationModel/代码/__pycache__/NCF.cpython-36.pyc
Normal file
BIN
DeepRecommendationModel/代码/__pycache__/NFM.cpython-36.pyc
Normal file
BIN
DeepRecommendationModel/代码/__pycache__/PNN.cpython-36.pyc
Normal file
BIN
DeepRecommendationModel/代码/__pycache__/WideNDeep.cpython-36.pyc
Normal file
BIN
DeepRecommendationModel/代码/__pycache__/utils.cpython-36.pyc
Normal file
0
DeepRecommendationModel/代码/contrib/__init__.py
Normal file
1153
DeepRecommendationModel/代码/contrib/rnn.py
Normal file
1452
DeepRecommendationModel/代码/contrib/rnn_v2.py
Normal file
378
DeepRecommendationModel/代码/contrib/utils.py
Normal file
@@ -0,0 +1,378 @@
|
||||
from tensorflow.python.ops import array_ops
|
||||
from tensorflow.python.ops import init_ops
|
||||
from tensorflow.python.ops import math_ops
|
||||
from tensorflow.python.ops import nn_ops
|
||||
from tensorflow.python.ops import variable_scope as vs
|
||||
from tensorflow.python.ops.rnn_cell import *
|
||||
from tensorflow.python.util import nest
|
||||
|
||||
_BIAS_VARIABLE_NAME = "bias"
|
||||
|
||||
_WEIGHTS_VARIABLE_NAME = "kernel"
|
||||
|
||||
|
||||
class _Linear_(object):
|
||||
"""Linear map: sum_i(args[i] * W[i]), where W[i] is a variable.
|
||||
|
||||
|
||||
|
||||
Args:
|
||||
|
||||
args: a 2D Tensor or a list of 2D, batch x n, Tensors.
|
||||
|
||||
output_size: int, second dimension of weight variable.
|
||||
|
||||
dtype: data type for variables.
|
||||
|
||||
build_bias: boolean, whether to build a bias variable.
|
||||
|
||||
bias_initializer: starting value to initialize the bias
|
||||
|
||||
(default is all zeros).
|
||||
|
||||
kernel_initializer: starting value to initialize the weight.
|
||||
|
||||
|
||||
|
||||
Raises:
|
||||
|
||||
ValueError: if inputs_shape is wrong.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
|
||||
args,
|
||||
|
||||
output_size,
|
||||
|
||||
build_bias,
|
||||
|
||||
bias_initializer=None,
|
||||
|
||||
kernel_initializer=None):
|
||||
|
||||
self._build_bias = build_bias
|
||||
|
||||
if args is None or (nest.is_sequence(args) and not args):
|
||||
raise ValueError("`args` must be specified")
|
||||
|
||||
if not nest.is_sequence(args):
|
||||
|
||||
args = [args]
|
||||
|
||||
self._is_sequence = False
|
||||
|
||||
else:
|
||||
|
||||
self._is_sequence = True
|
||||
|
||||
# Calculate the total size of arguments on dimension 1.
|
||||
|
||||
total_arg_size = 0
|
||||
|
||||
shapes = [a.get_shape() for a in args]
|
||||
|
||||
for shape in shapes:
|
||||
|
||||
if shape.ndims != 2:
|
||||
raise ValueError(
|
||||
"linear is expecting 2D arguments: %s" % shapes)
|
||||
|
||||
if shape[1] is None:
|
||||
|
||||
raise ValueError("linear expects shape[1] to be provided for shape %s, "
|
||||
|
||||
"but saw %s" % (shape, shape[1]))
|
||||
|
||||
else:
|
||||
|
||||
total_arg_size += int(shape[1])#.value
|
||||
|
||||
dtype = [a.dtype for a in args][0]
|
||||
|
||||
scope = vs.get_variable_scope()
|
||||
|
||||
with vs.variable_scope(scope) as outer_scope:
|
||||
|
||||
self._weights = vs.get_variable(
|
||||
|
||||
_WEIGHTS_VARIABLE_NAME, [total_arg_size, output_size],
|
||||
|
||||
dtype=dtype,
|
||||
|
||||
initializer=kernel_initializer)
|
||||
|
||||
if build_bias:
|
||||
|
||||
with vs.variable_scope(outer_scope) as inner_scope:
|
||||
|
||||
inner_scope.set_partitioner(None)
|
||||
|
||||
if bias_initializer is None:
|
||||
bias_initializer = init_ops.constant_initializer(
|
||||
0.0, dtype=dtype)
|
||||
|
||||
self._biases = vs.get_variable(
|
||||
|
||||
_BIAS_VARIABLE_NAME, [output_size],
|
||||
|
||||
dtype=dtype,
|
||||
|
||||
initializer=bias_initializer)
|
||||
|
||||
def __call__(self, args):
|
||||
|
||||
if not self._is_sequence:
|
||||
args = [args]
|
||||
|
||||
if len(args) == 1:
|
||||
|
||||
res = math_ops.matmul(args[0], self._weights)
|
||||
|
||||
else:
|
||||
|
||||
res = math_ops.matmul(array_ops.concat(args, 1), self._weights)
|
||||
|
||||
if self._build_bias:
|
||||
res = nn_ops.bias_add(res, self._biases)
|
||||
|
||||
return res
|
||||
|
||||
|
||||
try:
|
||||
from tensorflow.python.ops.rnn_cell_impl import _Linear
|
||||
except:
|
||||
_Linear = _Linear_
|
||||
|
||||
|
||||
class QAAttGRUCell(RNNCell):
|
||||
"""Gated Recurrent Unit cell (cf. http://arxiv.org/abs/1406.1078).
|
||||
|
||||
Args:
|
||||
|
||||
num_units: int, The number of units in the GRU cell.
|
||||
|
||||
activation: Nonlinearity to use. Default: `tanh`.
|
||||
|
||||
reuse: (optional) Python boolean describing whether to reuse variables
|
||||
|
||||
in an existing scope. If not `True`, and the existing scope already has
|
||||
|
||||
the given variables, an error is raised.
|
||||
|
||||
kernel_initializer: (optional) The initializer to use for the weight and
|
||||
|
||||
projection matrices.
|
||||
|
||||
bias_initializer: (optional) The initializer to use for the bias.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
|
||||
num_units,
|
||||
|
||||
activation=None,
|
||||
|
||||
reuse=None,
|
||||
|
||||
kernel_initializer=None,
|
||||
|
||||
bias_initializer=None):
|
||||
|
||||
super(QAAttGRUCell, self).__init__(_reuse=reuse)
|
||||
|
||||
self._num_units = num_units
|
||||
|
||||
self._activation = activation or math_ops.tanh
|
||||
|
||||
self._kernel_initializer = kernel_initializer
|
||||
|
||||
self._bias_initializer = bias_initializer
|
||||
|
||||
self._gate_linear = None
|
||||
|
||||
self._candidate_linear = None
|
||||
|
||||
@property
|
||||
def state_size(self):
|
||||
|
||||
return self._num_units
|
||||
|
||||
@property
|
||||
def output_size(self):
|
||||
|
||||
return self._num_units
|
||||
|
||||
def __call__(self, inputs, state, att_score):
|
||||
|
||||
return self.call(inputs, state, att_score)
|
||||
|
||||
def call(self, inputs, state, att_score=None):
|
||||
"""Gated recurrent unit (GRU) with nunits cells."""
|
||||
|
||||
if self._gate_linear is None:
|
||||
|
||||
bias_ones = self._bias_initializer
|
||||
|
||||
if self._bias_initializer is None:
|
||||
bias_ones = init_ops.constant_initializer(
|
||||
1.0, dtype=inputs.dtype)
|
||||
|
||||
with vs.variable_scope("gates"): # Reset gate and update gate.
|
||||
|
||||
self._gate_linear = _Linear(
|
||||
|
||||
[inputs, state],
|
||||
|
||||
2 * self._num_units,
|
||||
|
||||
True,
|
||||
|
||||
bias_initializer=bias_ones,
|
||||
|
||||
kernel_initializer=self._kernel_initializer)
|
||||
|
||||
value = math_ops.sigmoid(self._gate_linear([inputs, state]))
|
||||
|
||||
r, u = array_ops.split(value=value, num_or_size_splits=2, axis=1)
|
||||
|
||||
r_state = r * state
|
||||
|
||||
if self._candidate_linear is None:
|
||||
with vs.variable_scope("candidate"):
|
||||
self._candidate_linear = _Linear(
|
||||
|
||||
[inputs, r_state],
|
||||
|
||||
self._num_units,
|
||||
|
||||
True,
|
||||
|
||||
bias_initializer=self._bias_initializer,
|
||||
|
||||
kernel_initializer=self._kernel_initializer)
|
||||
|
||||
c = self._activation(self._candidate_linear([inputs, r_state]))
|
||||
|
||||
new_h = (1. - att_score) * state + att_score * c
|
||||
|
||||
return new_h, new_h
|
||||
|
||||
|
||||
class VecAttGRUCell(RNNCell):
|
||||
"""Gated Recurrent Unit cell (cf. http://arxiv.org/abs/1406.1078).
|
||||
|
||||
Args:
|
||||
|
||||
num_units: int, The number of units in the GRU cell.
|
||||
|
||||
activation: Nonlinearity to use. Default: `tanh`.
|
||||
|
||||
reuse: (optional) Python boolean describing whether to reuse variables
|
||||
|
||||
in an existing scope. If not `True`, and the existing scope already has
|
||||
|
||||
the given variables, an error is raised.
|
||||
|
||||
kernel_initializer: (optional) The initializer to use for the weight and
|
||||
|
||||
projection matrices.
|
||||
|
||||
bias_initializer: (optional) The initializer to use for the bias.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
|
||||
num_units,
|
||||
|
||||
activation=None,
|
||||
|
||||
reuse=None,
|
||||
|
||||
kernel_initializer=None,
|
||||
|
||||
bias_initializer=None):
|
||||
|
||||
super(VecAttGRUCell, self).__init__(_reuse=reuse)
|
||||
|
||||
self._num_units = num_units
|
||||
|
||||
self._activation = activation or math_ops.tanh
|
||||
|
||||
self._kernel_initializer = kernel_initializer
|
||||
|
||||
self._bias_initializer = bias_initializer
|
||||
|
||||
self._gate_linear = None
|
||||
|
||||
self._candidate_linear = None
|
||||
|
||||
@property
|
||||
def state_size(self):
|
||||
|
||||
return self._num_units
|
||||
|
||||
@property
|
||||
def output_size(self):
|
||||
|
||||
return self._num_units
|
||||
|
||||
def __call__(self, inputs, state, att_score):
|
||||
|
||||
return self.call(inputs, state, att_score)
|
||||
|
||||
def call(self, inputs, state, att_score=None):
|
||||
"""Gated recurrent unit (GRU) with nunits cells."""
|
||||
|
||||
if self._gate_linear is None:
|
||||
|
||||
bias_ones = self._bias_initializer
|
||||
|
||||
if self._bias_initializer is None:
|
||||
bias_ones = init_ops.constant_initializer(
|
||||
1.0, dtype=inputs.dtype)
|
||||
|
||||
with vs.variable_scope("gates"): # Reset gate and update gate.
|
||||
|
||||
self._gate_linear = _Linear(
|
||||
|
||||
[inputs, state],
|
||||
|
||||
2 * self._num_units,
|
||||
|
||||
True,
|
||||
|
||||
bias_initializer=bias_ones,
|
||||
|
||||
kernel_initializer=self._kernel_initializer)
|
||||
|
||||
value = math_ops.sigmoid(self._gate_linear([inputs, state]))
|
||||
|
||||
r, u = array_ops.split(value=value, num_or_size_splits=2, axis=1)
|
||||
|
||||
r_state = r * state
|
||||
|
||||
if self._candidate_linear is None:
|
||||
with vs.variable_scope("candidate"):
|
||||
self._candidate_linear = _Linear(
|
||||
|
||||
[inputs, r_state],
|
||||
|
||||
self._num_units,
|
||||
|
||||
True,
|
||||
|
||||
bias_initializer=self._bias_initializer,
|
||||
|
||||
kernel_initializer=self._kernel_initializer)
|
||||
|
||||
c = self._activation(self._candidate_linear([inputs, r_state]))
|
||||
|
||||
u = (1.0 - att_score) * u
|
||||
|
||||
new_h = u * state + (1 - u) * c
|
||||
|
||||
return new_h, new_h
|
||||
101
DeepRecommendationModel/代码/data/avazu_sample.txt
Normal file
@@ -0,0 +1,101 @@
|
||||
id,click,hour,C1,banner_pos,site_id,site_domain,site_category,app_id,app_domain,app_category,device_id,device_ip,device_model,device_type,device_conn_type,C14,C15,C16,C17,C18,C19,C20,C21
|
||||
1000009418151094273,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,ddd2926e,44956a24,1,2,15706,320,50,1722,0,35,-1,79
|
||||
10000169349117863715,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,96809ac8,711ee120,1,0,15704,320,50,1722,0,35,100084,79
|
||||
10000371904215119486,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,b3cf8def,8a4875bd,1,0,15704,320,50,1722,0,35,100084,79
|
||||
10000640724480838376,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,e8275b8f,6332421a,1,0,15706,320,50,1722,0,35,100084,79
|
||||
10000679056417042096,0,14102100,1005,1,fe8cc448,9166c161,0569f928,ecad2386,7801e8d9,07d7df22,a99f214a,9644d0bf,779d90c2,1,0,18993,320,50,2161,0,35,-1,157
|
||||
10000720757801103869,0,14102100,1005,0,d6137915,bb1ef334,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,05241af0,8a4875bd,1,0,16920,320,50,1899,0,431,100077,117
|
||||
10000724729988544911,0,14102100,1005,0,8fda644b,25d4cfcd,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,b264c159,be6db1d7,1,0,20362,320,50,2333,0,39,-1,157
|
||||
10000918755742328737,0,14102100,1005,1,e151e245,7e091613,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,e6f67278,be74e6fe,1,0,20632,320,50,2374,3,39,-1,23
|
||||
10000949271186029916,1,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,37e8da74,5db079b5,1,2,15707,320,50,1722,0,35,-1,79
|
||||
10001264480619467364,0,14102100,1002,0,84c7ba46,c4e18dd6,50e219e0,ecad2386,7801e8d9,07d7df22,c357dbff,f1ac7184,373ecbe6,0,0,21689,320,50,2496,3,167,100191,23
|
||||
10001868339616595934,0,14102100,1005,1,e151e245,7e091613,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,5d877109,8f5c9827,1,0,17747,320,50,1974,2,39,100019,33
|
||||
10001966791793526909,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,6f407810,1f0bc64f,1,0,15701,320,50,1722,0,35,-1,79
|
||||
10002028568167339219,0,14102100,1005,0,9e8cf15d,0d3cb7be,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,58811cdf,8326c04b,1,2,20596,320,50,2161,0,35,100148,157
|
||||
10002044883120869786,0,14102100,1005,0,d6137915,bb1ef334,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,72aab6df,04258293,1,0,19771,320,50,2227,0,687,100077,48
|
||||
10002518649031436658,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,98fed791,d9b5648e,0f2161f8,a99f214a,6dec2796,aad45b01,1,0,20984,320,50,2371,0,551,-1,46
|
||||
10003539039235338011,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,a4f47b2e,8a4875bd,1,0,15699,320,50,1722,0,35,100084,79
|
||||
10003585669470236873,0,14102100,1005,0,d9750ee7,98572c79,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,9b1fe278,128f4ba1,1,0,17914,320,50,2043,2,39,-1,32
|
||||
10004105575081229495,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,c26c53cf,be87996b,1,2,15708,320,50,1722,0,35,100084,79
|
||||
10004181428767727519,0,14102100,1005,1,0c2fe9d6,27e3c518,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,b7a69808,158e4944,1,0,6558,320,50,571,2,39,-1,32
|
||||
10004482643316086592,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,66a5f0f3,d9b5648e,cef3e649,a99f214a,fa60af6b,b4b19c97,1,0,21234,320,50,2434,3,163,100088,61
|
||||
10004510652136496837,0,14102100,1005,0,543a539e,c7ca3108,3e814130,ecad2386,7801e8d9,07d7df22,a99f214a,8a308c73,3223bcfe,1,0,20352,320,50,2333,0,39,-1,157
|
||||
10004574413841529209,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,1b6530bc,1aa0e912,1,0,15706,320,50,1722,0,35,-1,79
|
||||
10004670021948955159,0,14102100,1005,0,543a539e,c7ca3108,3e814130,ecad2386,7801e8d9,07d7df22,a99f214a,a2d12b33,607e78f2,1,0,20366,320,50,2333,0,39,-1,157
|
||||
10004765361151096125,1,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,c6563308,7fdd04d2,1,0,15701,320,50,1722,0,35,-1,79
|
||||
10005249248600843539,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,e99d0c2e,d25693ce,1,0,15706,320,50,1722,0,35,100083,79
|
||||
10005334911727438633,0,14102100,1010,1,85f751fd,c4e18dd6,50e219e0,ffc6ffd0,7801e8d9,0f2161f8,fb23c543,69890c7f,9fef9da8,4,0,21665,320,50,2493,3,35,-1,117
|
||||
10005541670676403131,0,14102100,1005,1,e151e245,7e091613,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,c62f7206,69f9dd0e,1,0,20984,320,50,2371,0,551,100217,46
|
||||
10005609489911213467,1,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,54c5d545,2347f47a,0f2161f8,9af87478,2a2bfc89,ecf10acf,1,0,21611,320,50,2480,3,297,100111,61
|
||||
10005649443863261125,0,14102100,1005,0,543a539e,c7ca3108,3e814130,ecad2386,7801e8d9,07d7df22,a99f214a,50d86760,d787e91b,1,0,20366,320,50,2333,0,39,-1,157
|
||||
10005951398749600249,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,431b3174,f39b265e,1,0,15706,320,50,1722,0,35,-1,79
|
||||
10006192453619779489,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,685d1c4c,2347f47a,8ded1f7a,6a943594,8a014cbb,81b42528,1,3,15708,320,50,1722,0,35,-1,79
|
||||
10006415976094813740,0,14102100,1005,0,f84e52b6,d7e2f29b,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,a8649089,e9b8d8d7,1,0,16838,320,50,1882,3,35,-1,13
|
||||
10006490708516192015,1,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,a4459495,517bef98,1,0,15708,320,50,1722,0,35,100083,79
|
||||
10006557235872316145,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,ac77b71a,d787e91b,1,0,15699,320,50,1722,0,35,-1,79
|
||||
10006629065800243858,0,14102100,1005,0,543a539e,c7ca3108,3e814130,ecad2386,7801e8d9,07d7df22,a99f214a,6769bdb2,d787e91b,1,0,20362,320,50,2333,0,39,-1,157
|
||||
10006777279679619273,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,d2bb6502,2347f47a,8ded1f7a,4b2309e9,22c2dcf4,d6e0e6ff,1,3,18987,320,50,2158,3,291,100193,61
|
||||
10006789981076459409,0,14102100,1005,0,030440fe,08ba7db9,76b2941d,ecad2386,7801e8d9,07d7df22,a99f214a,692824c7,293291c1,1,0,20596,320,50,2161,0,35,-1,157
|
||||
10006958186789044052,1,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,0acbeaa3,45a51db4,f95efa07,a99f214a,ce6e6bbd,2cd8ff6d,1,0,18993,320,50,2161,0,35,100034,157
|
||||
10007163879183388340,0,14102100,1005,0,030440fe,08ba7db9,76b2941d,ecad2386,7801e8d9,07d7df22,a99f214a,5035aded,3db9fde9,1,0,18993,320,50,2161,0,35,-1,157
|
||||
10007164336863914220,1,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,b2b14786,36d749e5,1,0,15706,320,50,1722,0,35,-1,79
|
||||
10007197383452514432,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,07f39509,49ea3580,1,0,15704,320,50,1722,0,35,100084,79
|
||||
10007446479189647526,0,14102100,1005,0,6ec06dbd,d262cf1e,f66779e6,ecad2386,7801e8d9,07d7df22,a99f214a,3aea6370,6360f9ec,1,0,19870,320,50,2271,0,687,100075,48
|
||||
10007768440836622373,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,e2a1ca37,2347f47a,8ded1f7a,432cd280,45919d0d,1ccc7835,1,0,15708,320,50,1722,0,35,-1,79
|
||||
10007830732992705885,0,14102100,1010,1,85f751fd,c4e18dd6,50e219e0,a607e6a7,7801e8d9,0f2161f8,890abcbb,9f02f646,e8c7729d,4,0,21665,320,50,2493,3,35,-1,117
|
||||
10007847530896919634,1,14102100,1002,0,84c7ba46,c4e18dd6,50e219e0,ecad2386,7801e8d9,07d7df22,767a174e,3e805b2a,cf19f7f7,0,0,21661,320,50,2446,3,171,100228,156
|
||||
10007908698866493310,0,14102100,1005,1,0eb72673,d2f72222,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,834f84b2,76dc4769,1,0,16208,320,50,1800,3,167,100075,23
|
||||
10007944429976961145,1,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,07875ea4,aaffed8f,1,0,15701,320,50,1722,0,35,-1,79
|
||||
10009147085943364421,0,14102100,1005,1,e151e245,7e091613,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,905d2fbc,1b13b020,1,0,17037,320,50,1934,2,39,-1,16
|
||||
10009190848778773294,0,14102100,1005,1,5ee41ff2,17d996e6,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,fc7f99ee,70359270,1,0,16920,320,50,1899,0,431,-1,117
|
||||
10009635774586344851,0,14102100,1005,0,543a539e,c7ca3108,3e814130,ecad2386,7801e8d9,07d7df22,a99f214a,37018b2d,24f6b932,1,0,20352,320,50,2333,0,39,-1,157
|
||||
10009699694430474960,1,14102100,1005,0,4dd0a958,79cf0c8d,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,f6a5ae09,88fe1d5d,1,0,20366,320,50,2333,0,39,-1,157
|
||||
10009807995169380879,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,396df801,2347f47a,0f2161f8,a99f214a,554d9f5f,36a30aeb,1,0,15705,320,50,1722,0,35,100084,79
|
||||
10009910814812262951,1,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,a079ef6b,2347f47a,75d80bbe,a99f214a,f8c8df20,be87996b,1,2,18993,320,50,2161,0,35,100131,157
|
||||
10010452321736390000,1,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,cede6db1,a0f5f879,1,0,15701,320,50,1722,0,35,100084,79
|
||||
10010485868773711631,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,1cb5985e,1ccc7835,1,0,15701,320,50,1722,0,35,100084,79
|
||||
10010504760200486071,0,14102100,1005,1,5ee41ff2,17d996e6,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,d012a1cb,ecb851b2,1,0,16615,320,50,1863,3,39,100188,23
|
||||
10010730108771379386,0,14102100,1005,1,e151e245,7e091613,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,08dd2eb8,cdf6ea96,1,0,20634,320,50,2374,3,39,-1,23
|
||||
10010804179216291475,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,9a5911ad,1ccc7835,1,0,15704,320,50,1722,0,35,-1,79
|
||||
1001082718558099372,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,1779deee,2347f47a,f95efa07,a99f214a,5a96d22e,9e3836ff,1,0,18993,320,50,2161,0,35,-1,157
|
||||
10010924186026106882,0,14102100,1005,0,030440fe,08ba7db9,76b2941d,ecad2386,7801e8d9,07d7df22,a99f214a,8f6c30bb,744ae245,1,0,18993,320,50,2161,0,35,-1,157
|
||||
10010966574628106108,1,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,0acbeaa3,45a51db4,f95efa07,a99f214a,061893d4,68b900d9,1,0,20596,320,50,2161,0,35,100034,157
|
||||
10011085150831357375,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,07875ea4,d787e91b,1,0,15699,320,50,1722,0,35,-1,79
|
||||
10011205200760015892,0,14102100,1005,0,6256f5b4,28f93029,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,04a1662e,521f95fe,1,0,17212,320,50,1887,3,39,100202,23
|
||||
1001139595064240144,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,c9758700,76dc4769,1,0,15705,320,50,1722,0,35,-1,79
|
||||
10011406079394798455,0,14102100,1005,0,543a539e,c7ca3108,3e814130,ecad2386,7801e8d9,07d7df22,a99f214a,9ae68bb9,24f6b932,1,0,20362,320,50,2333,0,39,-1,157
|
||||
1001156047808171144,1,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,2801fd97,575d0d2a,1,0,15708,320,50,1722,0,35,100084,79
|
||||
10011561503992804801,0,14102100,1005,1,e151e245,7e091613,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,931519c4,e9b8d8d7,1,0,17747,320,50,1974,2,39,100021,33
|
||||
10011650513707909570,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,febd1138,82e27996,0f2161f8,a99f214a,1ce4451d,99e427c9,1,0,21611,320,50,2480,3,297,100111,61
|
||||
10011658782619041235,1,14102100,1005,0,0aab7161,660aeadc,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,0086332e,1f0bc64f,1,0,15699,320,50,1722,0,35,-1,79
|
||||
10011677979251422697,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,82310cab,f39b265e,1,0,15707,320,50,1722,0,35,-1,79
|
||||
1001179289293608710,0,14102100,1005,1,e023ba3e,75f9ddc3,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,f7c9ee04,56f254f5,1,0,17914,320,50,2043,2,39,-1,32
|
||||
10012212068904346443,0,14102100,1005,0,543a539e,c7ca3108,3e814130,ecad2386,7801e8d9,07d7df22,a99f214a,6769bdb2,d787e91b,1,0,20352,320,50,2333,0,39,-1,157
|
||||
10012222478217629851,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,3738b922,d787e91b,1,0,15705,320,50,1722,0,35,100084,79
|
||||
10012820175855462623,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,8acb1161,1f0bc64f,1,0,15707,320,50,1722,0,35,-1,79
|
||||
10013076841337920650,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,ed326aa2,4ceb2e0b,1,0,15702,320,50,1722,0,35,-1,79
|
||||
10013222055782902774,0,14102100,1005,0,5b08c53b,7687a86e,3e814130,ecad2386,7801e8d9,07d7df22,a99f214a,09b19f16,7eef184d,1,0,17654,300,250,1994,2,39,-1,33
|
||||
10013330254346467994,0,14102100,1005,0,f5476ff8,00e1b9c0,3e814130,ecad2386,7801e8d9,07d7df22,a99f214a,da162469,8b1aa260,1,0,18993,320,50,2161,0,35,-1,157
|
||||
10013378798301872145,1,14102100,1005,1,e151e245,7e091613,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,40fb49ca,be74e6fe,1,0,20362,320,50,2333,0,39,-1,157
|
||||
10013493678511778479,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,39947756,2347f47a,cef3e649,a2cbb1e0,d784a354,9f8d0424,1,2,18993,320,50,2161,0,35,-1,157
|
||||
10013552540914034684,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,e2fcccd2,5c5a694b,0f2161f8,a99f214a,c21a1e56,89416188,1,0,4687,320,50,423,2,39,100148,32
|
||||
10013750748974177308,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,8eb51743,a0f5f879,1,0,15703,320,50,1722,0,35,100083,79
|
||||
1001378691598807810,0,14102100,1002,0,85f751fd,c4e18dd6,50e219e0,a37bf1e4,7801e8d9,07d7df22,1ab3feec,c45c8256,8debacdb,0,0,21691,320,50,2495,2,167,-1,23
|
||||
10013840276980995258,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,e2fcccd2,5c5a694b,0f2161f8,a99f214a,07533d06,76dc4769,1,0,4687,320,50,423,2,39,100148,32
|
||||
10013846047025246486,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,2e93a860,f39b265e,1,0,15702,320,50,1722,0,35,100083,79
|
||||
10014026899633599058,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,9cdc12cc,711ee120,1,0,15699,320,50,1722,0,35,100084,79
|
||||
10014063680973162331,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,665810f3,78d9bd10,1,0,15699,320,50,1722,0,35,100083,79
|
||||
10014190212266331300,1,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,9c13b419,2347f47a,f95efa07,a99f214a,ed9450c2,1f0bc64f,1,0,20633,320,50,2374,3,39,-1,23
|
||||
10014285064795240866,1,14102100,1002,0,84c7ba46,c4e18dd6,50e219e0,ecad2386,7801e8d9,07d7df22,c357dbff,06f76b24,373ecbe6,0,0,21682,320,50,2496,3,167,100191,23
|
||||
10014385711019128754,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,12c3d700,ef726eae,1,0,15704,320,50,1722,0,35,-1,79
|
||||
10014630626523032142,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,0345a137,3bd9e8e7,1,0,15702,320,50,1722,0,35,100083,79
|
||||
10014764617325763141,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,4e873691,c6263d8a,1,0,15703,320,50,1722,0,35,-1,79
|
||||
10014885175555340290,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,27f3fa06,d25693ce,1,0,15705,320,50,1722,0,35,100083,79
|
||||
10014887683839786798,1,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,e2fcccd2,5c5a694b,0f2161f8,a99f214a,fac78767,84ebbcd4,1,0,4687,320,50,423,2,39,100148,32
|
||||
10015140740686523448,0,14102100,1005,0,85f751fd,c4e18dd6,50e219e0,c51f82bc,d9b5648e,0f2161f8,a99f214a,2d227840,9b5ce758,1,0,21611,320,50,2480,3,297,100111,61
|
||||
10015211672544614902,0,14102100,1005,1,e151e245,7e091613,f028772b,ecad2386,7801e8d9,07d7df22,a99f214a,42606fe6,cb0fb677,1,0,17037,320,50,1934,2,39,-1,16
|
||||
10015376300289320595,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,03108db9,a0f5f879,1,0,15701,320,50,1722,0,35,100084,79
|
||||
10015405794859644629,1,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,0b697be1,1f0bc64f,1,0,15701,320,50,1722,0,35,100084,79
|
||||
10015629448289660116,1,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,58db4f0c,6332421a,1,0,15708,320,50,1722,0,35,-1,79
|
||||
100156980486870304,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,02b9b0fc,1aa0e912,1,0,15706,320,50,1722,0,35,-1,79
|
||||
10015745448500295401,0,14102100,1005,0,1fbe01fe,f3845767,28905ebd,ecad2386,7801e8d9,07d7df22,a99f214a,6b9769f2,4c8aeb60,1,0,15701,320,50,1722,0,35,-1,79
|
||||
201
DeepRecommendationModel/代码/data/criteo_sample.txt
Normal file
@@ -0,0 +1,201 @@
|
||||
label,I1,I2,I3,I4,I5,I6,I7,I8,I9,I10,I11,I12,I13,C1,C2,C3,C4,C5,C6,C7,C8,C9,C10,C11,C12,C13,C14,C15,C16,C17,C18,C19,C20,C21,C22,C23,C24,C25,C26
|
||||
0,,3,260.0,,17668.0,,,33.0,,,,0.0,,05db9164,08d6d899,9143c832,f56b7dd5,25c83c98,7e0ccccf,df5c2d18,0b153874,a73ee510,8f48ce11,a7b606c4,ae1bb660,eae197fd,b28479f6,bfef54b3,bad5ee18,e5ba7672,87c6f83c,,,0429f84b,,3a171ecb,c0d61a5c,,
|
||||
0,,-1,19.0,35.0,30251.0,247.0,1.0,35.0,160.0,,1.0,,35.0,68fd1e64,04e09220,95e13fd4,a1e6a194,25c83c98,fe6b92e5,f819e175,062b5529,a73ee510,ab9456b4,6153cf57,8882c6cd,769a1844,b28479f6,69f825dd,23056e4f,d4bb7bd8,6fc84bfb,,,5155d8a3,,be7c41b4,ded4aac9,,
|
||||
0,0.0,0,2.0,12.0,2013.0,164.0,6.0,35.0,523.0,0.0,3.0,,18.0,05db9164,38a947a1,3f55fb72,5de245c7,30903e74,7e0ccccf,b72ec13d,1f89b562,a73ee510,acce978c,3547565f,a5b0521a,12880350,b28479f6,c12fc269,95a8919c,e5ba7672,675c9258,,,2e01979f,,bcdee96c,6d5d1302,,
|
||||
0,,13,1.0,4.0,16836.0,200.0,5.0,4.0,29.0,,2.0,,4.0,05db9164,8084ee93,02cf9876,c18be181,25c83c98,,e14874c9,0b153874,7cc72ec2,2462946f,636405ac,8fe001f4,31b42deb,07d13a8f,422c8577,36103458,e5ba7672,52e44668,,,e587c466,,32c7478e,3b183c5c,,
|
||||
0,0.0,0,104.0,27.0,1990.0,142.0,4.0,32.0,37.0,0.0,1.0,,27.0,05db9164,207b2d81,5d076085,862b5ba0,25c83c98,fbad5c96,17c22666,0b153874,a73ee510,534fc986,feb49a68,f24b551c,8978af5c,64c94865,32ec6582,b6d021e8,e5ba7672,25c88e42,21ddcdc9,b1252a9d,0e8585d2,,32c7478e,0d4a6d1a,001f3601,92c878de
|
||||
0,0.0,-1,63.0,40.0,1470.0,61.0,4.0,37.0,46.0,0.0,1.0,,40.0,68fd1e64,207b2d81,9dd3c4fc,a09fab49,25c83c98,,271190b7,5b392875,a73ee510,49d5fa15,26a64614,3c5900b5,51351dd6,b28479f6,c38116c9,0decd005,e5ba7672,d3303ea5,21ddcdc9,b1252a9d,7633c7c8,,32c7478e,17f458f7,001f3601,71236095
|
||||
0,0.0,370,4.0,1.0,1787.0,65.0,14.0,25.0,489.0,0.0,7.0,,25.0,05db9164,2a69d406,fcae8bfa,13508380,25c83c98,,cd846c62,0b153874,a73ee510,3b08e48b,0ec1e215,18917580,44af41ef,07d13a8f,3b2d8705,51b69881,3486227d,642f2610,55dd3565,b1252a9d,5c8dc711,,423fab69,45ab94c8,2bf691b1,c84c4aec
|
||||
1,19.0,10,30.0,10.0,1.0,3.0,33.0,47.0,126.0,3.0,5.0,,2.0,05db9164,403ea497,2cbec47f,3e2bfbda,30903e74,,7227c706,0b153874,a73ee510,5fcee6b1,9625b211,21a23bfe,dccbd94b,b28479f6,91f74a64,587267a3,e5ba7672,a78bd508,21ddcdc9,5840adea,c2a93b37,,32c7478e,1793a828,e8b83407,2fede552
|
||||
0,0.0,0,36.0,22.0,4684.0,217.0,9.0,35.0,135.0,0.0,1.0,0.0,43.0,8cf07265,0aadb108,c798ded6,91e6318a,25c83c98,fe6b92e5,2aef1419,0b153874,a73ee510,3b08e48b,d027c970,1b2022a0,00e20e7b,1adce6ef,2de5271c,b74e1eb0,e5ba7672,7ce63c71,,,af5dc647,,dbb486d7,1793a828,,
|
||||
0,2.0,11,8.0,23.0,30.0,11.0,2.0,8.0,23.0,1.0,1.0,,11.0,05db9164,58e67aaf,ea997bbe,72bea89f,384874ce,7e0ccccf,5b18f3d9,0b153874,a73ee510,012f45e7,720446f5,33ec1af8,034e5f3b,051219e6,d83fb924,4558136f,07c540c4,c21c3e4c,21ddcdc9,a458ea53,31c8e642,,c7dc6720,3e983c86,9b3e8820,d597922b
|
||||
0,2.0,1,190.0,25.0,8.0,26.0,2.0,27.0,25.0,1.0,1.0,,25.0,05db9164,e77e5e6e,c23785fe,67dd8a70,25c83c98,7e0ccccf,0c41b6a1,37e4aa92,a73ee510,78d5c363,4ba74619,d8acd6f9,879fa878,07d13a8f,2eb18840,df604f5b,e5ba7672,449d6705,6f3756eb,5840adea,07b6c66f,,423fab69,246f2e7f,e8b83407,350a6bdb
|
||||
0,,2,2.0,1.0,5533.0,1.0,41.0,1.0,33.0,,5.0,0.0,1.0,05db9164,d7988e72,25111132,d13862c2,25c83c98,6f6d9be8,84c427f0,5b392875,a73ee510,00f2b452,41b3f655,7c5cd1c7,ce5114a2,64c94865,846fb5bd,696fb81d,e5ba7672,0f2f9850,b6baba3f,a458ea53,06e40c52,8ec974f4,32c7478e,3fdb382b,e8b83407,49d68486
|
||||
0,0.0,5,,,18424.0,461.0,23.0,4.0,231.0,0.0,2.0,,,05db9164,ed7b1c58,b063fe4e,4b972461,25c83c98,7e0ccccf,afa309bd,5b392875,a73ee510,23de5a4a,77212bd7,8cdc4941,7203f04e,b28479f6,298421a5,3084c78b,e5ba7672,8814ed47,,,514b7308,,c7dc6720,2fd70e1c,,
|
||||
0,8.0,-1,,,732.0,2.0,22.0,2.0,2.0,1.0,4.0,,,68fd1e64,38a947a1,,,25c83c98,7e0ccccf,1c86e0eb,0b153874,a73ee510,e8f7c7e8,755e4a50,,5978055e,b28479f6,7ba31d46,,e5ba7672,9b82aca5,,,,,32c7478e,,,
|
||||
1,0.0,0,24.0,36.0,5022.0,436.0,25.0,32.0,192.0,0.0,9.0,0.0,36.0,5bfa8ab5,84b4e42f,45f68c2a,39547932,384874ce,fbad5c96,85e1a170,0b153874,a73ee510,2bf8bed1,a4ea009a,78a16776,1e9339bc,91233270,cdb87fb5,e15ad623,8efede7f,67bd0ece,,,78c1dd4b,,c7dc6720,4f7b7578,,
|
||||
0,,82,20.0,4.0,507333.0,,0.0,4.0,4.0,,0.0,,4.0,05db9164,38d50e09,5d0ec1e8,e63708e9,25c83c98,fbad5c96,bc324536,0b153874,7cc72ec2,f6540b40,2bcfb78f,506bb280,e6fc496d,07d13a8f,ee569ce2,81db2bec,e5ba7672,582152eb,21ddcdc9,5840adea,4a8f0a7f,c9d4222a,32c7478e,1989e165,001f3601,09929967
|
||||
0,,24,3.0,2.0,10195.0,,0.0,32.0,55.0,,0.0,,2.0,5a9ed9b0,68b3edbf,b00d1501,d16679b9,4cf72387,7e0ccccf,36b796aa,0b153874,a73ee510,8b7e0638,7373475d,e0d76380,cfbfce5c,b28479f6,f511c49f,1203a270,e5ba7672,752d8b8a,,,73d06dde,,3a171ecb,aee52b6f,,
|
||||
0,,105,4.0,1.0,2200.0,,0.0,1.0,1.0,,0.0,,1.0,05db9164,38d50e09,fc1cad4b,40ed41e5,25c83c98,7e0ccccf,88afd773,51d76abe,a73ee510,3b08e48b,c6cb726f,153ff04a,176d07bc,b28479f6,42b3012c,1bf03082,776ce399,582152eb,21ddcdc9,5840adea,84ec2c79,,be7c41b4,a415643d,001f3601,c4304c4b
|
||||
1,5.0,85,52.0,6.0,36.0,36.0,30.0,24.0,281.0,1.0,5.0,2.0,6.0,9a89b36c,1cfdf714,9d427ddf,4eadb673,25c83c98,7e0ccccf,2555b4d9,0b153874,a73ee510,4c89c3af,0e4ebdac,cf724373,779f824b,07d13a8f,f775a6d5,6512dce6,8efede7f,e88ffc9d,21ddcdc9,b1252a9d,361a1080,,423fab69,3fdb382b,cb079c2d,49d68486
|
||||
0,2.0,3,4.0,1.0,4.0,1.0,2.0,1.0,1.0,1.0,1.0,,1.0,68fd1e64,2eb7b10e,378112d3,684abf7b,25c83c98,fbad5c96,0d15142a,5b392875,a73ee510,ac473633,df7e8e0b,38176faa,84c02464,1adce6ef,0816fba2,f2c6a810,07c540c4,21eb63af,,,8b7fb864,,423fab69,45b2acf4,,
|
||||
0,,1,5.0,36.0,239721.0,,0.0,0.0,123.0,,0.0,,62.0,8cf07265,4f25e98b,a68b0bcf,c194aaab,25c83c98,fbad5c96,a2f7459e,0b153874,7cc72ec2,b393caa5,15eced00,ab1307ec,bd251a95,64c94865,40e29d2a,65a31309,e5ba7672,7ef5affa,738584ec,a458ea53,fca82615,,32c7478e,74f7ceeb,9d93af03,d14e41ff
|
||||
0,,4,,,1572.0,,0.0,17.0,55.0,,0.0,,,05db9164,8947f767,6bbe880c,feb6eb1a,4cf72387,7e0ccccf,3babeb61,0b153874,a73ee510,3b08e48b,565788d0,d06dc48e,8e7ad399,1adce6ef,ba8b8b16,30e6420c,776ce399,bd17c3da,ba92e49d,b1252a9d,65f3080f,,be7c41b4,42a310e6,010f6491,0eabc199
|
||||
0,0.0,0,,,1464.0,4.0,5.0,3.0,4.0,0.0,1.0,,,68fd1e64,38a947a1,dd8e6407,db4eb846,25c83c98,13718bbd,963d99df,062b5529,a73ee510,3b08e48b,bffe9c30,eb43b195,e62d6c68,07d13a8f,3d2c6113,de815c2d,776ce399,d3c7daaa,,,5def73cb,,32c7478e,aa5529de,,
|
||||
1,0.0,43,2.0,3.0,1700.0,21.0,6.0,10.0,21.0,0.0,1.0,,7.0,5a9ed9b0,46bbf321,c5d94b65,5cc8f91d,25c83c98,7e0ccccf,4157815a,1f89b562,a73ee510,4e979b5e,7056d78a,75c79158,08775c1b,e8dce07a,80d1ee72,208d4baf,e5ba7672,906ff5cb,,,6a909d9a,,3a171ecb,1f68c81f,,
|
||||
0,0.0,1,2.0,1.0,2939.0,39.0,17.0,3.0,437.0,0.0,7.0,,1.0,68fd1e64,38a947a1,98351ee6,811ce8e8,25c83c98,fbad5c96,4a6c02fb,37e4aa92,a73ee510,3b08e48b,0cb221d0,617c70e9,ea18ebd8,07d13a8f,31b59ad3,121f63c9,e5ba7672,065917ca,,,c3739d01,,423fab69,d4af2638,,
|
||||
1,9.0,1,2.0,5.0,18.0,5.0,9.0,5.0,5.0,1.0,1.0,0.0,5.0,5a9ed9b0,9819deea,6813d33b,f922efad,25c83c98,fbad5c96,34cbc0af,0b153874,a73ee510,bac95df6,88196a93,b99ddbc8,1211c647,b28479f6,1150f5ed,87acb535,07c540c4,7e32f7a4,,,a4b7004c,,32c7478e,b34f3128,,
|
||||
0,,1,2.0,16.0,14404.0,79.0,2.0,16.0,103.0,,1.0,,16.0,05db9164,38a947a1,5492524f,ae59cd56,25c83c98,7e0ccccf,7925e09b,5b392875,7cc72ec2,56c80038,1cba690a,e00462bb,1d0f2da8,64c94865,51c5d5ca,ebbb82d7,07c540c4,be5810bd,,,bd1f6272,c9d4222a,32c7478e,043a382b,,
|
||||
0,0.0,26,7.0,1.0,3412.0,104.0,10.0,2.0,6.0,0.0,1.0,1.0,1.0,05db9164,287130e0,5e25fa67,dd47ba3b,25c83c98,13718bbd,412cb2ce,0b153874,a73ee510,3b08e48b,b9ec9192,8ebd48c3,df5886ca,07d13a8f,10040656,e05d680b,3486227d,891589e7,ff6cdd42,a458ea53,a2b7caec,,c7dc6720,1481ceb4,e8b83407,988b0775
|
||||
0,8.0,-1,60.0,11.0,11.0,7.0,9.0,30.0,39.0,1.0,2.0,,7.0,2d4ea12b,d97d4ce8,c725873a,d0189e5a,25c83c98,fe6b92e5,07d75b52,1f89b562,a73ee510,4f1c6ae7,a2c1d2d9,49fee879,ea31804b,1adce6ef,46218630,3b87fa92,e5ba7672,fb342121,7be4df37,5840adea,d90f665b,,32c7478e,6c1cdd05,ea9a246c,1219b447
|
||||
0,,1,13.0,1.0,3150.0,163.0,1.0,1.0,32.0,,1.0,,1.0,39af2607,c44e8a72,3f7f3d24,8eb89744,4cf72387,7e0ccccf,86651165,0b153874,a73ee510,3b08e48b,39dd23e7,538a49e7,0159bf9f,b28479f6,1addf65e,0596b5be,07c540c4,456d734d,af1445c4,a458ea53,cf79f8fa,c9d4222a,3a171ecb,d5b4ea7d,010f6491,deffd9e3
|
||||
0,1.0,302,71.0,3.0,270.0,19.0,1.0,6.0,19.0,1.0,1.0,,19.0,68fd1e64,876465ad,da89f77a,37ee624b,43b19349,fe6b92e5,2b3ce8b7,5b392875,a73ee510,8a99abc1,4352b29b,8065cc64,5f4de855,b28479f6,9c382f7a,a14df6f7,d4bb7bd8,08154af3,21ddcdc9,5840adea,e7f0c6dc,,bcdee96c,3e30919e,f55c04b6,2fede552
|
||||
1,1.0,0,1.0,0.0,2.0,0.0,4.0,0.0,0.0,1.0,2.0,,0.0,241546e0,6887a43c,9b792af9,9c6d05a0,25c83c98,6f6d9be8,adbcc874,0b153874,a73ee510,fbbf2c95,46031dab,6532318c,377af8aa,1adce6ef,ef6b7bdf,2c9d222f,e5ba7672,8f0f692f,21ddcdc9,a458ea53,cc6a9262,,32c7478e,a5862ce8,445bbe3b,b6a3490e
|
||||
0,11.0,251,9.0,5.0,21.0,6.0,34.0,5.0,5.0,1.0,4.0,,5.0,05db9164,4322636e,e007dfac,77b99936,4ea20c7d,fe6b92e5,2be44e4e,25239412,a73ee510,18e09007,364e8b48,9c841b74,34cbb1bc,07d13a8f,14674f9b,9b3f7aa2,e5ba7672,9d3171e9,21ddcdc9,a458ea53,61b4555a,ad3062eb,32c7478e,38b97a31,ea9a246c,074bb89f
|
||||
1,10.0,1,4.0,4.0,1.0,0.0,10.0,4.0,4.0,1.0,1.0,,0.0,09ca0b81,4f25e98b,0b2640f7,4badfc0c,4cf72387,fe6b92e5,df5c2d18,0b153874,a73ee510,da272362,a7b606c4,33c282f5,eae197fd,07d13a8f,dfab705f,635c3e13,e5ba7672,7ef5affa,2f4b9dd2,b1252a9d,cff19dc6,,c7dc6720,8535db9f,001f3601,b98a5b90
|
||||
0,0.0,-1,1.0,23.0,3169.0,147.0,62.0,0.0,753.0,0.0,9.0,1.0,39.0,05db9164,942f9a8d,69b028e3,003ceb8c,25c83c98,7e0ccccf,3f4ec687,1f89b562,a73ee510,c5fe5cb9,c4adf918,424ba327,85dbe138,b28479f6,ac182643,169f1150,8efede7f,1f868fdd,1d04f4a4,b1252a9d,15414e28,,32c7478e,aa9b9ab9,9d93af03,c73ed234
|
||||
0,0.0,35,13.0,5.0,4939.0,140.0,1.0,22.0,61.0,0.0,1.0,,11.0,05db9164,4f25e98b,5e25fa67,dd47ba3b,a9411994,7e0ccccf,2e62d414,0b153874,a73ee510,4b415bb3,258875ea,8ebd48c3,dcc8f90a,07d13a8f,5be89da3,e05d680b,d4bb7bd8,bc5a0ff7,ff6cdd42,a458ea53,a2b7caec,,32c7478e,1481ceb4,e8b83407,988b0775
|
||||
0,,1,13.0,2.0,59865.0,292.0,0.0,2.0,87.0,,0.0,0.0,2.0,68fd1e64,287130e0,b87cffc0,ffacf4e8,43b19349,,04277bf9,5b392875,7cc72ec2,4ea0d483,7e2c5c15,5ea407f3,91a1b611,b28479f6,9efd8b77,9906d656,07c540c4,891589e7,55dd3565,a458ea53,37a23b2d,,32c7478e,3fdb382b,ea9a246c,49d68486
|
||||
1,,0,,1.0,16732.0,2.0,1.0,1.0,1.0,,1.0,,1.0,87552397,6e638bbc,598b72ce,3c7eb23c,25c83c98,fbad5c96,675e81f6,0b153874,a73ee510,d9b71390,4a77ddca,f21f7d11,dc1d72e4,07d13a8f,d4525f76,e2e3cf1c,d4bb7bd8,f6a2fc70,21ddcdc9,a458ea53,605776ee,,32c7478e,f93938dd,e8b83407,322cbe58
|
||||
1,0.0,212,,,1632.0,65.0,24.0,1.0,113.0,0.0,6.0,,,be589b51,b0d4a6f6,50a6bc33,335e428a,25c83c98,7e0ccccf,1171550e,1f89b562,a73ee510,23724df8,031ba22d,4baf63a1,bb7a2c12,32813e21,b0369b63,c73993da,e5ba7672,e01eacde,,,1d14288c,,3a171ecb,c9bc2384,,
|
||||
0,10.0,11,3.0,3.0,1026.0,3.0,88.0,3.0,131.0,1.0,15.0,0.0,3.0,9a89b36c,1cfdf714,8b14bdd6,3bf2df8b,25c83c98,,e807f153,0b153874,a73ee510,8627508e,1054ae5c,3cd57e51,d7ce3abd,b28479f6,d345b1a0,4d664c70,27c07bd6,e88ffc9d,712d530c,b1252a9d,9ecb9e0d,,bcdee96c,a8380e43,cb079c2d,37c5e077
|
||||
0,,5,22.0,5.0,10324.0,,0.0,5.0,13.0,,0.0,,5.0,f434fac1,40ed0c67,374195a1,6f5d5092,4cf72387,6f6d9be8,555d7949,1f89b562,a73ee510,3b08e48b,91e8fc27,752343e3,9ff13f22,1adce6ef,f8ebf901,c43b15fe,776ce399,2585827d,21ddcdc9,5840adea,a66e7b01,,be7c41b4,e33735a0,e8b83407,f95af538
|
||||
0,,779,1.0,1.0,676.0,,0.0,4.0,4.0,,0.0,,1.0,68fd1e64,e5fb1af3,9b953c56,7be07df9,25c83c98,7e0ccccf,5e4f7d2b,0b153874,a73ee510,3b08e48b,25f4f871,6bca71b1,e67cdf97,07d13a8f,b5de5956,fb8ca891,d4bb7bd8,13145934,55dd3565,b1252a9d,b1ae3ed2,ad3062eb,423fab69,3fdb382b,9b3e8820,49d68486
|
||||
0,,179,61.0,,3316.0,,,1.0,,,,,,f473b8dc,38a947a1,223b0e16,ca55061c,43b19349,7e0ccccf,7f2c5a6e,64523cfa,a73ee510,f6c6d9f8,d21494f8,156f99ef,f47f13e4,1adce6ef,0e78291e,5fbf4a84,1e88c74f,1999bae9,,,deb9605d,,32c7478e,e448275f,,
|
||||
0,1.0,1,5.0,7.0,1238.0,13.0,9.0,15.0,89.0,0.0,3.0,0.0,7.0,8cf07265,09e68b86,aa8c1539,85dd697c,25c83c98,7e0ccccf,92ce5a7d,37e4aa92,a73ee510,15fa156b,e0c3cae0,d8c29807,e8df3343,8ceecbc8,d2f03b75,c64d548f,8efede7f,63cdbb21,cf99e5de,5840adea,5f957280,c9d4222a,55dd3565,1793a828,e8b83407,b7d9c3bc
|
||||
0,2.0,72,20.0,11.0,4.0,11.0,24.0,14.0,69.0,1.0,7.0,,11.0,05db9164,09e68b86,6ef2aa66,20af9140,25c83c98,7e0ccccf,372a0c4c,0b153874,a73ee510,a08eee5a,ec88dd34,4df84614,94881fc3,b28479f6,52baadf5,cf3ec61f,3486227d,5aed7436,7be4df37,b1252a9d,98a79791,,bcdee96c,3fdb382b,e8b83407,49d68486
|
||||
0,,57,60.0,20.0,11862.0,20.0,1.0,19.0,20.0,,1.0,,20.0,5bfa8ab5,4f25e98b,15363e12,f9e8a6fb,384874ce,,65c53f25,0b153874,a73ee510,3b08e48b,ad2bc6f4,d63df4e6,39ccb769,b28479f6,8ab5b746,a694f6ce,d4bb7bd8,7ef5affa,21ddcdc9,a458ea53,a370fd83,,32c7478e,d5b01f55,9b3e8820,85cebe8c
|
||||
0,4.0,1,29.0,30.0,112.0,30.0,27.0,33.0,144.0,2.0,4.0,0.0,30.0,05db9164,58e67aaf,99815367,771966f0,4cf72387,6f6d9be8,cdc0ad95,5b392875,a73ee510,b0c25211,69926409,e802f466,2fc3058f,051219e6,d83fb924,f6613e51,e5ba7672,c21c3e4c,21ddcdc9,a458ea53,3aa05bfb,,32c7478e,9f0d87bf,9b3e8820,bde577f6
|
||||
0,2.0,4,53.0,14.0,1499.0,20.0,11.0,19.0,98.0,0.0,3.0,7.0,14.0,75ac2fe6,287130e0,b264d69e,ce831e6d,25c83c98,,5aef82b1,0b153874,a73ee510,7fdb06fe,010265ac,74138b6d,0e5bc979,f7c1b33f,42793602,b49f63ab,8efede7f,891589e7,55dd3565,b1252a9d,a1229e5f,,32c7478e,3fdb382b,ea9a246c,49d68486
|
||||
0,,5,3.0,5.0,17405.0,,0.0,8.0,8.0,,0.0,,6.0,05db9164,c5c1d6ae,8018e37d,d8660950,43b19349,fbad5c96,c1e20400,5b392875,a73ee510,3b08e48b,60a1c175,22cad86a,9b9e44d2,07d13a8f,b25845fd,2a27c935,776ce399,561cabfe,21ddcdc9,5840adea,d479575f,,be7c41b4,9b18ad04,7a402766,67ebe777
|
||||
0,,49,1.0,1.0,3116.0,72.0,3.0,1.0,48.0,,1.0,,1.0,7e5c2ff4,2c8c5f5d,13cd0697,352cefe6,25c83c98,7e0ccccf,4fb73f5f,985e3fcb,a73ee510,3b08e48b,6a447eb3,c3cdaf85,9dfda2b9,1adce6ef,5edc1a28,08514295,e5ba7672,f5f4ae5b,,,6387fda4,,55dd3565,d36c7dbf,,
|
||||
0,,2865,23.0,0.0,23584.0,,0.0,2.0,47.0,,0.0,,2.0,05db9164,0468d672,cedcacac,7967fcf5,25c83c98,7e0ccccf,33b15f2c,0b153874,a73ee510,0f6ee8ce,419d31d4,553e02c3,08961fd0,1adce6ef,4f3b3616,91a6eec5,1e88c74f,9880032b,21ddcdc9,5840adea,a97b62ca,,423fab69,727a7cc7,ea9a246c,6935065e
|
||||
0,,119,4.0,4.0,13528.0,,0.0,7.0,35.0,,0.0,,4.0,87552397,38a947a1,695a85e0,d502349a,25c83c98,7e0ccccf,82f666b6,0b153874,a73ee510,631ddef6,e51ddf94,67b31aac,3516f6e6,cfef1c29,d33de6b0,d2b0336b,07c540c4,48ce336b,,,ea6a0e31,,3a171ecb,da408463,,
|
||||
0,,25,5.0,4.0,0.0,,0.0,4.0,4.0,,0.0,,1.0,68fd1e64,71ca0a25,44e7b8ec,3b989466,307e775a,7e0ccccf,d0519bab,0b153874,a73ee510,3b08e48b,38914a66,d7cd5e08,c281c227,1adce6ef,ae3a9888,4032eea3,1e88c74f,9bf8ffef,21ddcdc9,5840adea,53def47b,c9d4222a,dbb486d7,8849cfac,001f3601,aa5f0a15
|
||||
0,2.0,180,94.0,7.0,151.0,38.0,2.0,30.0,26.0,1.0,1.0,,25.0,5bfa8ab5,421b43cd,33ebdbb6,29998ed1,25c83c98,fbad5c96,6ad82e7a,0b153874,a73ee510,451bd4e4,c1ee56d0,6aaba33c,ebd756bd,b28479f6,2d0bb053,b041b04a,e5ba7672,2804effd,,,723b4dfd,,32c7478e,b34f3128,,
|
||||
0,,2,0.0,,,,,0.0,,,,,,be589b51,38a947a1,4470baf4,8c8a4c47,307e775a,fe6b92e5,ae1dfa39,0b153874,7cc72ec2,3b08e48b,ee26f284,bb669e25,48b975db,b28479f6,717db705,2b2ce127,2005abd1,ade68c22,,,2b796e4a,,be7c41b4,8d365d3b,,
|
||||
0,,0,9.0,,17907.0,59.0,2.0,0.0,98.0,,1.0,,,68fd1e64,80e26c9b,ba1947d0,85dd697c,25c83c98,fe6b92e5,3d63f4e6,0b153874,a73ee510,94e68c1d,af6a4ffc,34a238e0,2a1579a2,b28479f6,a785131a,da441c7e,e5ba7672,005c6740,21ddcdc9,5840adea,8717ea07,,32c7478e,1793a828,e8b83407,b9809574
|
||||
0,7.0,84,,7.0,10.0,6.0,29.0,41.0,288.0,1.0,4.0,,5.0,05db9164,38a947a1,840eeb3a,f7263320,25c83c98,7e0ccccf,3baecfcb,0b153874,a73ee510,98d5faa2,96a54d80,317bfd7d,dbe5226f,07d13a8f,d4a5a2be,1689e4de,e5ba7672,5d961bca,,,dc55d6df,,423fab69,aa0115d2,,
|
||||
0,0.0,0,1.0,,3667.0,42.0,2.0,30.0,37.0,0.0,1.0,1.0,,05db9164,e5fb1af3,909286bb,252734c9,25c83c98,7e0ccccf,b28fa88b,0b153874,a73ee510,4b8a7639,9f0003f4,233fde4c,5afd9e51,b28479f6,23287566,1871ac47,8efede7f,13145934,1d1eb838,b1252a9d,23da7042,,bcdee96c,1be0cc0a,e8b83407,f89dfbcc
|
||||
0,5.0,1,46.0,6.0,1046.0,112.0,5.0,43.0,111.0,1.0,1.0,,6.0,05db9164,4f25e98b,f86649de,f56f6045,25c83c98,fe6b92e5,21c0ea1a,0b153874,a73ee510,cfa407de,bc862fb6,b9b3b7ef,4f487d87,07d13a8f,dfab705f,33301a0b,e5ba7672,7ef5affa,92524a76,a458ea53,d5a53bc3,c9d4222a,423fab69,3fdb382b,001f3601,79883c16
|
||||
0,,7,4.0,3.0,75211.0,,0.0,3.0,3.0,,0.0,,3.0,8cf07265,0468d672,00d3cdb7,d4125c6f,25c83c98,7e0ccccf,71ccc25b,0b153874,7cc72ec2,e89812b3,5cab60cb,d286aff3,ce418dc9,07d13a8f,a888f201,7d9d720d,1e88c74f,9880032b,21ddcdc9,5840adea,8443660f,,3a171ecb,52d7797f,e8b83407,ddf88ddd
|
||||
1,,54,1.0,1.0,,,0.0,1.0,1.0,,0.0,,1.0,68fd1e64,38a947a1,0d15d9b5,bfe24cb7,b0530c50,,d9aa9d97,0b153874,7cc72ec2,3b08e48b,6e647667,72a52d4c,85dbe138,b28479f6,06809048,58cacba8,2005abd1,670f513e,,,b7ba6151,,32c7478e,7b80ab11,,
|
||||
0,,0,34.0,3.0,,,0.0,3.0,3.0,,0.0,,3.0,68fd1e64,287130e0,38610f2f,28d2973d,25c83c98,,88002ee1,0b153874,7cc72ec2,3b08e48b,f1b78ab4,b345f76c,6e5da64f,b28479f6,9efd8b77,569a0480,2005abd1,891589e7,712d530c,b1252a9d,c2af6d9f,,32c7478e,58e38a64,ea9a246c,70451962
|
||||
1,,1,1.0,,7814.0,119.0,1.0,19.0,30.0,,1.0,,,05db9164,80e26c9b,eb08d440,f922efad,25c83c98,fe6b92e5,41e1828d,0b153874,a73ee510,3b08e48b,b6358cf2,654bb16a,61c65daf,1adce6ef,0f942372,87acb535,d4bb7bd8,005c6740,21ddcdc9,5840adea,a4b7004c,,32c7478e,b34f3128,e8b83407,9904c656
|
||||
0,2.0,5,11.0,9.0,24.0,9.0,110.0,9.0,148.0,1.0,10.0,0.0,9.0,be30ca83,8f5b4275,b009d929,c7043c4b,30903e74,fbad5c96,a90a99c5,51d76abe,a73ee510,e6003298,c804061c,3563ab62,1cc9ac51,1adce6ef,a6bf53df,b688c8cc,8efede7f,65c9624a,21ddcdc9,5840adea,2754aaf1,c9d4222a,55dd3565,3b183c5c,e8b83407,adb5d234
|
||||
0,,19,1.0,1.0,7476.0,9.0,9.0,1.0,9.0,,1.0,,1.0,8cf07265,537e899b,5037b88e,9dde01fd,25c83c98,fbad5c96,aafae983,0b153874,a73ee510,dc790dda,c3a20c8d,680d7261,7ce5cdf0,07d13a8f,6d68e99c,c0673b44,e5ba7672,b34aa802,,,e049c839,,32c7478e,6095f986,,
|
||||
0,4.0,0,131.0,1.0,0.0,1.0,14.0,10.0,40.0,1.0,3.0,,0.0,05db9164,80e26c9b,13193952,f922efad,25c83c98,fe6b92e5,124131fa,1f89b562,a73ee510,a1ee64a6,9ba53fcc,654bb16a,42156eb4,1adce6ef,0f942372,87acb535,e5ba7672,005c6740,21ddcdc9,5840adea,a4b7004c,ad3062eb,bcdee96c,b34f3128,e8b83407,9904c656
|
||||
1,0.0,5,2.0,1.0,1526.0,3.0,9.0,2.0,2.0,0.0,1.0,,1.0,05db9164,38a947a1,60c37737,8a77aa30,25c83c98,fe6b92e5,1c63b114,1f89b562,a73ee510,f6f942d1,67841877,94a1cc80,781f4d92,b28479f6,962bbefe,3eef319d,e5ba7672,0ad1cc71,,,1c63c71e,c9d4222a,3a171ecb,ad80aaa7,,
|
||||
0,1.0,1,5.0,18.0,475.0,63.0,15.0,4.0,803.0,1.0,4.0,,63.0,05db9164,3e4b7926,7442ec70,bb8645c3,0942e0a7,7e0ccccf,3a7402e7,51d76abe,a73ee510,aa91245c,b4bb4248,a5ab10e6,3eb2f9dc,07d13a8f,e6863a8e,1cdb3603,e5ba7672,e261f8d8,21ddcdc9,5840adea,1380864e,,32c7478e,be2f0db5,47907db5,68d9ada1
|
||||
0,,1,1.0,18.0,10791.0,,0.0,1.0,281.0,,0.0,,18.0,05db9164,46bbf321,c5d94b65,5cc8f91d,4cf72387,7e0ccccf,2773eaab,5b392875,a73ee510,1a428761,06474f17,75c79158,2ec4b007,91233270,cddd56a1,208d4baf,1e88c74f,906ff5cb,,,6a909d9a,ad3062eb,3a171ecb,1f68c81f,,
|
||||
0,1.0,-1,,,528.0,15.0,8.0,2.0,585.0,1.0,4.0,,,05db9164,ef69887a,3fea0364,9c32fadc,30903e74,,ec1a1856,0b153874,a73ee510,22a99f9d,a04e019f,cc606cbe,07a906b4,b28479f6,902a109f,0ab5ee0c,e5ba7672,4bcc9449,083e89d9,b1252a9d,6c38450e,,32c7478e,394c5a53,47907db5,1d7b6578
|
||||
0,,18,9.0,0.0,,,0.0,7.0,16.0,,0.0,,7.0,68fd1e64,38a947a1,2273663d,3beb8147,25c83c98,fbad5c96,88002ee1,985e3fcb,7cc72ec2,3b08e48b,f1b78ab4,c47972c1,6e5da64f,1adce6ef,8d3c9c0c,e638c51d,2005abd1,35176a17,,,0370bc83,ad3062eb,55dd3565,cde6fafb,,
|
||||
0,,5,,13.0,10467.0,170.0,4.0,13.0,96.0,,1.0,,13.0,be589b51,8084ee93,02cf9876,c18be181,0942e0a7,7e0ccccf,ad82323c,37e4aa92,a73ee510,bdfd8a02,7ca25fd2,8fe001f4,d3802338,b28479f6,b2ff8c6b,36103458,e5ba7672,52e44668,,,e587c466,,32c7478e,3b183c5c,,
|
||||
1,,27,,,27753.0,,,3.0,,,,,,05db9164,efb7db0e,bf05882d,9e3f04df,25c83c98,7e0ccccf,73e2fc5e,062b5529,a73ee510,f8f0e86f,4e46b019,9da0a604,07c072b7,b28479f6,5ab7247d,929eef3c,d4bb7bd8,a863ac26,,,fb19a39b,ad3062eb,3a171ecb,cc4079ea,,
|
||||
0,0.0,49,,,3732.0,20.0,1.0,3.0,20.0,0.0,1.0,,,17f69355,09e68b86,5be9b239,ace52998,25c83c98,,82cfb145,0b153874,a73ee510,9b8e7680,3f31bb3e,e5b118b4,c6378246,b28479f6,52baadf5,f68bd494,d4bb7bd8,5aed7436,21ddcdc9,a458ea53,ba3c688b,,32c7478e,3fdb382b,b9266ff0,49d68486
|
||||
1,1.0,19,18.0,16.0,178.0,32.0,34.0,34.0,200.0,0.0,9.0,,16.0,05db9164,ea3a5818,7ee60f5f,bebc14b3,25c83c98,6f6d9be8,4f900c22,f0e5818a,a73ee510,47e01053,7c4f062c,cc22efeb,76dfc898,b28479f6,0a069322,606df1fe,e5ba7672,a1d0cc4f,21ddcdc9,b1252a9d,aebdd3c2,8ec974f4,32c7478e,e4e10900,b9266ff0,7a1ac642
|
||||
1,0.0,1,2.0,5.0,6613.0,104.0,1.0,17.0,74.0,0.0,1.0,,5.0,8cf07265,8db5bc37,,,25c83c98,7e0ccccf,5a103f30,0b153874,a73ee510,3b08e48b,8487a168,,636195f8,64c94865,00e52733,,d4bb7bd8,821c30b8,,,,,32c7478e,,,
|
||||
0,,1,,,29111.0,,,0.0,,,,,,ae82ea21,5dac953d,d032c263,c18be181,384874ce,,6b406125,5b392875,a73ee510,f1311559,278636c9,dfbb09fb,b87a829f,b28479f6,78e3b025,84898b2a,e5ba7672,35a9ed38,,,0014c32a,c0061c6d,32c7478e,3b183c5c,,
|
||||
0,,58,,20.0,21659.0,1033.0,9.0,1.0,151.0,,2.0,,43.0,05db9164,80e26c9b,,,25c83c98,7e0ccccf,622305e6,5b392875,a73ee510,e70742b0,319687c9,,62036f49,07d13a8f,f3635baf,,e5ba7672,f54016b9,21ddcdc9,5840adea,,,3a171ecb,,e8b83407,00ed90d0
|
||||
0,0.0,11,11.0,5.0,4325.0,61.0,4.0,14.0,68.0,0.0,2.0,0.0,5.0,68fd1e64,d8fc04df,f652979e,32a55192,25c83c98,7e0ccccf,19d92932,5b392875,a73ee510,f710483a,d54a5851,ed5cfa27,a36387e6,b28479f6,9da6bb5f,3141102a,1e88c74f,cbadff99,21ddcdc9,5840adea,3df2213d,,3a171ecb,42998020,010f6491,dd8b4f5c
|
||||
1,,2560,2.0,0.0,63552.0,398.0,0.0,7.0,122.0,,0.0,,1.0,9a89b36c,39dfaa0d,a17519ab,5b392af8,25c83c98,fbad5c96,14ba4967,64523cfa,7cc72ec2,9ffc445a,c21c44c8,834b5edc,5b3fc509,07d13a8f,60fa10e5,e66306df,d4bb7bd8,df4fffb7,21ddcdc9,5840adea,9988d803,,c7dc6720,abe3a684,010f6491,f3737bd0
|
||||
0,0.0,30,2.0,15.0,2712.0,210.0,5.0,43.0,242.0,0.0,2.0,,15.0,05db9164,207b2d81,2b280564,ad5ffc6b,25c83c98,fe6b92e5,559eb1e1,0b153874,a73ee510,51e04895,91875c79,2a064dba,ea519e47,64c94865,11b2ae92,7d9b60c8,e5ba7672,395856b0,21ddcdc9,a458ea53,9c3eb598,,32c7478e,c0b8dfd6,001f3601,81be451e
|
||||
0,0.0,49,,3.0,1732.0,20.0,1.0,14.0,16.0,0.0,1.0,,3.0,8cf07265,e112a9de,4e1c9eda,22504558,25c83c98,fbad5c96,01620311,0b153874,a73ee510,66c281d9,922bbb91,23bc90a1,ad61640d,1adce6ef,6da7d68c,776f5665,e5ba7672,d495a339,,,5a5953a2,,32c7478e,8f079aa5,,
|
||||
0,,-1,,,357.0,,0.0,10.0,11.0,,0.0,,,68fd1e64,403ea497,2cbec47f,3e2bfbda,25c83c98,7e0ccccf,9d8d7034,0b153874,a73ee510,b3d657b8,51ef0313,21a23bfe,e8f6ccfe,07d13a8f,e3209fc2,587267a3,e5ba7672,a78bd508,21ddcdc9,5840adea,c2a93b37,,32c7478e,1793a828,e8b83407,2fede552
|
||||
0,2.0,7,,22.0,37.0,22.0,4.0,1.0,135.0,1.0,3.0,,22.0,98237733,b26462db,dad8b3db,06b1cf6e,25c83c98,7e0ccccf,ade953a9,5b392875,a73ee510,0eca1729,29e4ad33,422e8212,80467802,07d13a8f,72fbc65c,25b075e4,e5ba7672,35ee3e9e,,,a13bd40d,,3a171ecb,0ff91809,,
|
||||
0,,68,1.0,1.0,24513.0,43.0,4.0,12.0,62.0,,1.0,,1.0,fc9c62bb,80e26c9b,,,25c83c98,6f6d9be8,e746fe19,1f89b562,a73ee510,c9ac91cb,0bc63bd0,,ef007ecc,b28479f6,4c1df281,,e5ba7672,f54016b9,21ddcdc9,5840adea,,,32c7478e,,e8b83407,c4e4eabb
|
||||
1,0.0,304,1.0,,13599.0,0.0,1.0,0.0,0.0,0.0,1.0,0.0,,68fd1e64,064c8f31,70168f62,585ab217,25c83c98,fe6b92e5,b3a5258d,0b153874,a73ee510,7cda6c86,30b2a438,eb83af8a,aebdb575,07d13a8f,81d3f724,69f67894,3486227d,d4a314a2,21ddcdc9,5840adea,e1627e2c,,32c7478e,a6e7d8d3,001f3601,2fede552
|
||||
0,0.0,2,4.0,7.0,1568.0,70.0,4.0,42.0,117.0,0.0,1.0,,36.0,de4dac42,b7ca2abd,022a0b3c,d6b6e0bf,25c83c98,13718bbd,33cca6fa,0b153874,a73ee510,fb999b75,9f7c4fc1,05e68866,2b9fb512,07d13a8f,2f453358,6de617d3,e5ba7672,4771e483,,,df66957b,,3a171ecb,b34f3128,,
|
||||
0,,0,3.0,2.0,,,0.0,3.0,13.0,,0.0,,2.0,05db9164,38a947a1,d125aecd,82a61820,25c83c98,7e0ccccf,d18f8f99,0b153874,7cc72ec2,3b08e48b,6c27619d,49507531,61e43922,07d13a8f,bb1e9ca8,0fd6d3ca,2005abd1,e96a7df2,,,7eefff0d,,be7c41b4,cafb4e4d,,
|
||||
0,0.0,0,5.0,1.0,1751.0,37.0,1.0,8.0,11.0,0.0,1.0,,1.0,8cf07265,09e68b86,fc25ffd0,991a22ae,25c83c98,fbad5c96,6da2fbd6,f0e5818a,a73ee510,78ed0c4d,7bbe6c06,c35b992b,ea1f21b7,1adce6ef,dbc5e126,068a2c9f,e5ba7672,5aed7436,21ddcdc9,b1252a9d,df9de95c,,423fab69,3fdb382b,cb079c2d,49d68486
|
||||
1,3.0,22,7.0,9.0,269.0,11.0,12.0,15.0,573.0,1.0,7.0,,9.0,05db9164,558b4efb,1b5e2c32,8a2b280f,25c83c98,13718bbd,6d51a5b0,966033bc,a73ee510,2e48a61d,61af8052,733bbdf2,2f3ee7fb,64c94865,2cd24ac0,8ac5e229,e5ba7672,c68ebaa0,21ddcdc9,5840adea,0be61dd1,,32c7478e,3b183c5c,ea9a246c,9973f80f
|
||||
1,,1,,,14447.0,328.0,15.0,0.0,432.0,,9.0,0.0,,5bfa8ab5,26ece8a8,58ca7e87,3db5e097,25c83c98,fbad5c96,877d7f71,0b153874,a73ee510,afc4d756,5bd8a4ae,91f87a19,7a3043c0,07d13a8f,102fc449,834b85f5,3486227d,87fd936e,,,e339163e,,423fab69,c9a8db2a,,
|
||||
0,,1,4.0,1.0,235065.0,,0.0,3.0,1.0,,0.0,,1.0,5a9ed9b0,a8da270e,6392b1c1,4e1c036b,25c83c98,6f6d9be8,863329da,0b153874,7cc72ec2,fbc2dc95,a89c45cb,4ea4e9d5,a4fafa5b,b28479f6,f2252b1c,b7f61016,e5ba7672,130ebfcd,,,f15fe1ee,,32c7478e,2896ad66,,
|
||||
0,1.0,4,75.0,21.0,246.0,69.0,1.0,33.0,33.0,1.0,1.0,,31.0,3b65d647,512fdf0c,b3ee24fe,631a0f79,25c83c98,7e0ccccf,86b374da,1f89b562,a73ee510,3b08e48b,07678d3e,9b665b9c,0159bf9f,b28479f6,fc29c5a9,b7a016ed,e5ba7672,fd3919f9,21ddcdc9,5840adea,1df3ad93,,3a171ecb,3aebd96a,724b04da,56be3401
|
||||
1,,64,3.0,7.0,14747.0,38.0,4.0,16.0,25.0,,3.0,,17.0,05db9164,8b0005b7,62acd884,7736c782,25c83c98,fbad5c96,b01d50d5,5b392875,a73ee510,3b08e48b,cd1b7031,0b7afe9e,4d8657a2,07d13a8f,715f1291,7d0949a5,07c540c4,dff11f14,,,c12eabbb,,3a171ecb,af0cb2c3,,
|
||||
0,,0,2.0,,4317.0,0.0,8.0,0.0,0.0,,1.0,,,68fd1e64,09e68b86,29dbbee7,15c721d8,4cf72387,,f33e4fa1,5b392875,a73ee510,e5330e23,7b5deffb,526eb908,269889be,b28479f6,52baadf5,e71dfc2d,e5ba7672,5aed7436,39e30682,b1252a9d,b4770b64,,32c7478e,2f34b1ef,e8b83407,4a449e4c
|
||||
0,0.0,1,5.0,0.0,11738.0,490.0,10.0,13.0,140.0,0.0,1.0,,1.0,52f1e825,9819deea,a2b48926,f922efad,4cf72387,7e0ccccf,d385ea68,0b153874,a73ee510,3b08e48b,7940fc2a,b99ddbc8,00e20e7b,b28479f6,1150f5ed,87acb535,e5ba7672,7e32f7a4,,,a4b7004c,ad3062eb,32c7478e,b34f3128,,
|
||||
1,0.0,53,17.0,4.0,1517.0,87.0,1.0,5.0,11.0,0.0,1.0,0.0,4.0,05db9164,38d50e09,948ee031,b7ab56a2,384874ce,fbad5c96,879ccac6,0b153874,a73ee510,9ca0fba4,e931c5cd,42bee2f2,580817cd,b28479f6,06373944,67b3c631,e5ba7672,fffe2a63,21ddcdc9,b1252a9d,bd074856,,32c7478e,df487a73,001f3601,c27f155b
|
||||
0,,0,7.0,14.0,3751.0,646.0,0.0,37.0,432.0,,0.0,,14.0,0e78bd46,ae46a29d,770451b6,f922efad,25c83c98,fe6b92e5,01620311,0b153874,a73ee510,5a01afad,922bbb91,4bba7327,ad61640d,b28479f6,cccdd69e,e2e2fcd9,e5ba7672,e32bf683,,,b964dee0,c9d4222a,32c7478e,b34f3128,,
|
||||
0,1.0,1,14.0,1.0,118.0,1.0,4.0,1.0,32.0,1.0,1.0,,1.0,05db9164,4f25e98b,79bdb97a,bdbe850d,43b19349,,38eb9cf4,0b153874,a73ee510,49d1ad89,7f8ffe57,30ed85b5,46f42a63,07d13a8f,dfab705f,e75cb6ea,e5ba7672,7ef5affa,21ddcdc9,a458ea53,72c8ca0c,,32c7478e,3fdb382b,001f3601,49d68486
|
||||
0,3.0,1,25.0,9.0,1396.0,39.0,5.0,32.0,37.0,0.0,2.0,,10.0,05db9164,dde11b16,c6616b04,e6996139,25c83c98,3bf701e7,2e8a689b,0b153874,a73ee510,efea433b,e51ddf94,3a802941,3516f6e6,07d13a8f,e28388cc,f4944655,3486227d,43dfe9bd,,,81f8278e,,3a171ecb,772b286f,,
|
||||
0,,0,37.0,10.0,15.0,,0.0,10.0,10.0,,0.0,,10.0,05db9164,95e2d337,da3ad2bd,a95c56ca,25c83c98,fbad5c96,d7f3ff9f,1f89b562,a73ee510,3b08e48b,29473fc8,359d194a,aa902020,051219e6,003cf364,8023d5ba,776ce399,7b06fafe,d913d8f1,a458ea53,15bb899d,,32c7478e,6c25dad0,2bf691b1,59e91663
|
||||
0,,0,4.0,,11534.0,,0.0,0.0,1.0,,0.0,,,39af2607,78ccd99e,55f298ba,1de19bc2,25c83c98,fbad5c96,63b7fcf7,1f89b562,a73ee510,3b08e48b,779482a8,624029b0,7d65a908,051219e6,9917ad07,270e2a53,1e88c74f,e7e991cb,21ddcdc9,a458ea53,5ff5ac4a,ad3062eb,32c7478e,d65fa724,875ea8a7,86601e0a
|
||||
0,,498,,0.0,92.0,,0.0,0.0,0.0,,0.0,,0.0,5bfa8ab5,90081f33,fd22e418,36375a46,43b19349,fbad5c96,6c338953,0b153874,a73ee510,3b08e48b,553ebda3,fb991bf5,49fe3d4e,b28479f6,50b07d60,d1a4e968,776ce399,7da6ea7e,,,9fb07dd2,,be7c41b4,359dd977,,
|
||||
1,8.0,7,20.0,8.0,5.0,22.0,172.0,21.0,568.0,1.0,21.0,,0.0,05db9164,404660bb,97d1681e,ffe40d5f,25c83c98,7e0ccccf,1c86e0eb,1f89b562,a73ee510,f3b83678,755e4a50,7e7a6264,5978055e,1adce6ef,6ddbba94,e7af7559,e5ba7672,4b17f8a2,21ddcdc9,5840adea,5a49c6db,,32c7478e,faf5d8b3,f0f449dd,984e0db0
|
||||
0,,4,1.0,1.0,270.0,170.0,1.0,19.0,196.0,,1.0,0.0,1.0,3b65d647,4c2bc594,d032c263,c18be181,25c83c98,fbad5c96,cd98cc3d,0b153874,a73ee510,493b74f2,dcc84468,dfbb09fb,b72482f5,8ceecbc8,7ac43a46,84898b2a,e5ba7672,bc48b783,,,0014c32a,,55dd3565,3b183c5c,,
|
||||
0,,6,52.0,15.0,383.0,,0.0,21.0,21.0,,0.0,,15.0,05db9164,09e68b86,88290645,0676a23d,25c83c98,fe6b92e5,f14f1abf,0b153874,a73ee510,3b08e48b,7b5deffb,f6d35a1e,269889be,b28479f6,52baadf5,90d6ddcd,776ce399,5aed7436,21ddcdc9,b1252a9d,29d21ab1,,32c7478e,69e4f188,e8b83407,e001324a
|
||||
0,0.0,57,2.0,6.0,1683.0,550.0,5.0,48.0,412.0,0.0,1.0,0.0,102.0,39af2607,c5fe64d9,fda0b584,13508380,25c83c98,7e0ccccf,295cc387,0b153874,a73ee510,3b08e48b,7d5ece85,ffcedb7a,e4b5ce61,07d13a8f,52b49730,f39f1141,d4bb7bd8,c235abed,4cc48856,a458ea53,fdc724a8,,32c7478e,45ab94c8,46fbac64,c84c4aec
|
||||
0,,90,,0.0,1455.0,,0.0,6.0,10.0,,0.0,,2.0,05db9164,6f609dc9,d032c263,c18be181,25c83c98,7e0ccccf,315c76f3,37e4aa92,a73ee510,3b08e48b,e51ddf94,dfbb09fb,3516f6e6,07d13a8f,c169c458,84898b2a,776ce399,381bd833,,,0014c32a,,3a171ecb,3b183c5c,,
|
||||
0,,29,4.0,4.0,12245.0,,0.0,19.0,73.0,,0.0,,4.0,05db9164,3df44d94,d032c263,c18be181,4cf72387,7e0ccccf,81bb0302,5b392875,a73ee510,f918493f,b7094596,dfbb09fb,1f9d2c38,b28479f6,e0052e65,84898b2a,07c540c4,e7648a8f,,,0014c32a,,32c7478e,3b183c5c,,
|
||||
0,3.0,-1,3.0,2.0,285.0,5.0,6.0,8.0,30.0,1.0,4.0,,5.0,05db9164,73b37f46,cd82408a,eb45e6e4,25c83c98,7e0ccccf,ead731f4,0b153874,a73ee510,3b08e48b,e9c32980,d1fb0874,3fe840eb,ec19f520,f3a94039,6d87c0d4,07c540c4,d1605c46,,,ed01532f,,3a171ecb,8d49fa4b,,
|
||||
1,,2,3.0,,5091.0,0.0,6.0,0.0,3.0,,5.0,,,5a9ed9b0,4f25e98b,10ee5afb,1d29846e,db679829,,1971812a,0b153874,a73ee510,aed8755c,5307d8e2,5e76bfca,8368e64b,b28479f6,8ab5b746,5fb9ff62,07c540c4,7ef5affa,2e30f394,5840adea,e208a45f,,32c7478e,3fdb382b,001f3601,49d68486
|
||||
0,,78,8.0,,35203.0,853.0,2.0,0.0,98.0,,1.0,,,05db9164,c41a84c8,d627c43e,759c4a2e,25c83c98,fbad5c96,61beb1aa,0b153874,a73ee510,a5270a71,81a23494,2d15871c,3796b047,b28479f6,55d28d38,9243e635,07c540c4,2b46823a,,,ec5ac7c6,ad3062eb,32c7478e,590b856f,,
|
||||
1,37.0,113,2815.0,5.0,2.0,3.0,26.0,49.0,78.0,0.0,1.0,,3.0,05db9164,c5c1d6ae,b2de8002,f9a7e394,25c83c98,7e0ccccf,0d00feb3,0b153874,a73ee510,ff4776d6,640d8b63,76517c94,18041128,b28479f6,29a18ba0,afc96aa6,e5ba7672,836a67dd,21ddcdc9,5840adea,c0cd6339,78e2e389,32c7478e,7e60320b,7a402766,ba14bbcb
|
||||
0,5.0,1,28.0,22.0,11.0,24.0,5.0,22.0,22.0,3.0,3.0,,21.0,05db9164,89ddfee8,7e4ea1b2,bc17b20f,25c83c98,,a6624a99,5b392875,a73ee510,3b08e48b,f161ec47,49a5dd4f,1e18519e,051219e6,d5223973,9fa82d1c,e5ba7672,5bb2ec8e,4b1019ff,a458ea53,40b11f62,,32c7478e,eaa38671,f0f449dd,8b3e7faa
|
||||
0,,0,1.0,33.0,11774.0,,0.0,1.0,502.0,,0.0,,33.0,5a9ed9b0,2ae0a573,0739daa8,4fbef8bb,4cf72387,7e0ccccf,ca4fd8f8,0b153874,a73ee510,3b08e48b,a0060bca,9148b680,22d23aac,07d13a8f,413cc8c6,64e0265f,776ce399,f2fc99b1,,,38879cfe,ad3062eb,32c7478e,7836b4d5,,
|
||||
0,,1,14.0,3.0,3008.0,15.0,6.0,5.0,146.0,,3.0,,3.0,68fd1e64,a0e12995,b3693f43,f888df5a,25c83c98,7e0ccccf,fcf0132a,0b153874,a73ee510,aed3d80e,d650f1bd,63314ad3,863f8f8a,07d13a8f,73e2709e,ea1c4696,e5ba7672,1616f155,21ddcdc9,5840adea,67afd8d0,,c7dc6720,e3aea32f,9b3e8820,e75c9ae9
|
||||
1,0.0,1,27.0,38.0,1499.0,73.0,14.0,35.0,269.0,0.0,4.0,0.0,38.0,8cf07265,04e09220,b1ecc6c4,5dff9b29,4cf72387,fe6b92e5,53ef84c0,0b153874,a73ee510,267caf03,643327e3,2436ff75,478ebe53,07d13a8f,f6b23a53,f4ead43c,e5ba7672,6fc84bfb,,,4f1aa25f,,423fab69,ded4aac9,,
|
||||
0,,5,44.0,4.0,12143.0,,0.0,4.0,4.0,,0.0,,4.0,05db9164,38d50e09,0c7bb149,a35517fb,25c83c98,3bf701e7,e14874c9,0b153874,7cc72ec2,3b08e48b,636405ac,96fa9c01,31b42deb,07d13a8f,ee569ce2,7ce58da8,776ce399,582152eb,21ddcdc9,5840adea,d1d4f4a9,ad3062eb,3a171ecb,03955d00,001f3601,4e7af834
|
||||
1,3.0,2,37.0,87.0,190.0,90.0,3.0,49.0,88.0,2.0,2.0,,88.0,68fd1e64,38a947a1,,,43b19349,,d385ea68,0b153874,a73ee510,3b08e48b,7940fc2a,,00e20e7b,07d13a8f,7f1c4567,,d4bb7bd8,95f5c722,,,,,32c7478e,,,
|
||||
0,,8,8.0,5.0,25660.0,,0.0,3.0,5.0,,0.0,,5.0,05db9164,90081f33,fd22e418,36375a46,25c83c98,7e0ccccf,0bdc3959,0b153874,a73ee510,3b08e48b,c6cb726f,fb991bf5,176d07bc,b28479f6,13f8263b,d1a4e968,1e88c74f,c191a3ff,,,9fb07dd2,,32c7478e,359dd977,,
|
||||
0,0.0,0,35.0,4.0,190.0,85.0,43.0,18.0,177.0,0.0,3.0,1.0,8.0,05db9164,207b2d81,2b280564,ad5ffc6b,5a3e1872,7e0ccccf,4aa938fc,0b153874,a73ee510,efea433b,7e40f08a,2a064dba,1aa94af3,07d13a8f,0c67c4ca,7d9b60c8,3486227d,395856b0,21ddcdc9,a458ea53,9c3eb598,,32c7478e,c0b8dfd6,001f3601,7a2fb9af
|
||||
1,2.0,1,19.0,20.0,1.0,20.0,2.0,14.0,20.0,1.0,1.0,0.0,12.0,68fd1e64,06174070,a3829614,b0ed6de7,4cf72387,fe6b92e5,71c23d74,0b153874,a73ee510,c6c8dd7c,ae4c531b,3b917db0,01c2bbc7,cfef1c29,73438c3b,12e989e9,07c540c4,836a11e3,a34d2cf6,5840adea,9179411e,,32c7478e,1793a828,e8b83407,fa3124de
|
||||
0,1.0,1849,4.0,0.0,28.0,0.0,1.0,0.0,0.0,1.0,1.0,,0.0,be589b51,ef69887a,771a1642,2e946ee2,4cf72387,,5d7d417f,0b153874,a73ee510,50c56209,52d28861,77f29381,a4b04123,b28479f6,902a109f,9fe6f065,07c540c4,4bcc9449,566c492c,5840adea,7b6393e8,,32c7478e,3fdb382b,47907db5,2fc5e3d4
|
||||
0,0.0,65,,7.0,10346.0,67.0,1.0,16.0,67.0,0.0,1.0,0.0,7.0,8cf07265,68b3edbf,77f2f2e5,d16679b9,4cf72387,7e0ccccf,e465eb54,5b392875,a73ee510,f0c8b1be,01a88896,9f32b866,dfb2a8fa,07d13a8f,fd888b80,31ca40b6,d4bb7bd8,cf1cde40,,,dfcfc3fa,,93bad2c0,aee52b6f,,
|
||||
0,7.0,164,33.0,12.0,84.0,63.0,8.0,19.0,18.0,1.0,2.0,,18.0,87773c45,58e67aaf,104c93d5,90b69619,25c83c98,7e0ccccf,e3b8f237,0b153874,a73ee510,aed3d80e,1aa6cf31,61ea5878,3b03d76e,1adce6ef,d002b6d9,33a55538,e5ba7672,c21c3e4c,444a605d,b1252a9d,37c3d851,,32c7478e,364442f6,9b3e8820,bdc8589e
|
||||
0,,10,5.0,3.0,8913.0,68.0,2.0,42.0,168.0,,2.0,0.0,3.0,68fd1e64,1cfdf714,3f850fa0,db781543,25c83c98,7e0ccccf,2555b4d9,0b153874,a73ee510,f9065d00,98579192,3317996d,779f824b,d2dfe871,ca8b2a1a,bc3ccba9,27c07bd6,e88ffc9d,e27c6abe,a458ea53,6b4fc63c,,423fab69,c94ffa50,cb079c2d,d5ca783a
|
||||
0,,15,9.0,1.0,20553.0,,,12.0,,,,,4.0,05db9164,0b8e9caf,6858baef,3f647607,4cf72387,fbad5c96,b647358a,0b153874,a73ee510,3b08e48b,88731e13,f6148255,2723b688,b28479f6,5340cb84,03b5b1e2,07c540c4,ca6a63cf,,,3b66cfcf,,bcdee96c,08b0ce98,,
|
||||
0,0.0,-1,,,1539.0,115.0,17.0,20.0,276.0,0.0,5.0,,,68fd1e64,287130e0,9dfde63d,9c9a6068,25c83c98,6f6d9be8,32da4b59,5b392875,a73ee510,eff5602f,9ee336c5,1310a7dd,094e10ad,b28479f6,9efd8b77,b3dc5e07,e5ba7672,891589e7,bdffef68,b1252a9d,33706b2d,,32c7478e,88cba9eb,9b3e8820,1ba54abc
|
||||
0,0.0,3,,5.0,1920.0,22.0,50.0,5.0,98.0,0.0,4.0,0.0,5.0,68fd1e64,3df44d94,d032c263,c18be181,25c83c98,7e0ccccf,9ec884dc,5b392875,a73ee510,aa6da1ef,5b906b78,dfbb09fb,c95c9034,b28479f6,b96e7224,84898b2a,3486227d,79a92e0a,,,0014c32a,,bcdee96c,3b183c5c,,
|
||||
0,2.0,0,6.0,2.0,70.0,10.0,248.0,1.0,1034.0,1.0,32.0,,2.0,05db9164,404660bb,f1397040,09003f7b,25c83c98,7e0ccccf,1c86e0eb,0b153874,a73ee510,67eea4ef,755e4a50,0cdb9a18,5978055e,07d13a8f,633f1661,82708081,e5ba7672,4b17f8a2,21ddcdc9,5840adea,4c14738f,,32c7478e,a86c0565,f0f449dd,984e0db0
|
||||
1,,1,10.0,6.0,11665.0,,0.0,10.0,6.0,,0.0,,6.0,05db9164,38a947a1,7fd859b3,19ae4fbd,25c83c98,,16401b7d,0b153874,a73ee510,3b08e48b,20ec800a,6aa4c9a8,18a5e4b8,cfef1c29,cb0f0e06,b50d9336,1e88c74f,3c4f2d82,,,cc86f2c1,,32c7478e,1793a828,,
|
||||
0,12.0,1,1.0,15.0,548.0,24.0,12.0,18.0,20.0,2.0,2.0,,16.0,05db9164,0c0567c2,700014ea,560f248f,25c83c98,7e0ccccf,fe4dce68,0b153874,a73ee510,ab9e9acf,68357db6,093a009d,768f6658,07d13a8f,aa39dd42,9e6ff465,e5ba7672,bb983d97,,,5c859cae,,32c7478e,996f5a43,,
|
||||
1,0.0,152,3.0,3.0,1847.0,96.0,12.0,6.0,11.0,0.0,1.0,0.0,3.0,05db9164,4f25e98b,6d1384bc,74ce146b,4cf72387,7e0ccccf,26817995,a61cc0ef,a73ee510,cf500eab,8b92652b,a4b73157,c5bc951e,b28479f6,8ab5b746,19f6b83c,e5ba7672,7ef5affa,21ddcdc9,b1252a9d,9efd5ec7,,c7dc6720,3fdb382b,001f3601,49d68486
|
||||
0,0.0,1,9.0,0.0,6431.0,136.0,2.0,6.0,98.0,0.0,1.0,,2.0,05db9164,6887a43c,9b792af9,9c6d05a0,43b19349,,60d4eb86,e8663cb1,a73ee510,07c7b3f7,0ad37b4b,6532318c,f9d99d81,8ceecbc8,4e06592a,2c9d222f,e5ba7672,8f0f692f,21ddcdc9,b1252a9d,cc6a9262,,32c7478e,a5862ce8,445bbe3b,1793fb3f
|
||||
0,,-1,,,20646.0,,0.0,5.0,8.0,,0.0,,,9a89b36c,09e68b86,0271c22e,caa16f04,25c83c98,,47aa6d2e,0b153874,a73ee510,9d4b7dce,c30e7b00,f993725b,4f8670dc,1adce6ef,dbc5e126,1c3a7247,e5ba7672,5aed7436,21ddcdc9,5840adea,4d2b0d06,,32c7478e,3fdb382b,e8b83407,8ded0b41
|
||||
0,,14,3.0,2.0,306036.0,,0.0,2.0,105.0,,0.0,,2.0,68fd1e64,09e68b86,cce54c2c,6e8c7c0e,4cf72387,,c642e324,a6d156f4,7cc72ec2,b6900243,82af9502,9e82f486,90dca23e,07d13a8f,36721ddc,e3a83d5c,d4bb7bd8,5aed7436,2b558521,a458ea53,ebfa4c53,,32c7478e,a9d9c151,e8b83407,3a97b421
|
||||
0,,-1,,,,,,0.0,,,,,,5a9ed9b0,38a947a1,,,4cf72387,7e0ccccf,e7698644,66f29b89,7cc72ec2,3b08e48b,f9d0f35e,,b55434a9,07d13a8f,681a3f32,,2005abd1,19ef42ad,,,,c9d4222a,be7c41b4,,,
|
||||
1,1.0,2,6.0,2.0,8.0,9.0,1.0,2.0,2.0,1.0,1.0,0.0,2.0,05db9164,f0cf0024,619e87b2,cfc23926,384874ce,7e0ccccf,02914429,5b392875,a73ee510,575cd9b2,419d31d4,c0d8d575,08961fd0,1adce6ef,55dc357b,29a3715b,e5ba7672,b04e4670,21ddcdc9,a458ea53,e54f0804,,423fab69,936da3dd,ea9a246c,27029e68
|
||||
0,0.0,17,34.0,11.0,1784.0,50.0,1.0,25.0,102.0,0.0,1.0,0.0,11.0,68fd1e64,e77e5e6e,fdd14ae2,8b7d76a3,25c83c98,fbad5c96,15ce37bc,0b153874,a73ee510,25e9e422,ff78732c,07cecd0e,9b656adc,f862f261,903024b9,d08de474,e5ba7672,449d6705,1d1eb838,a458ea53,26e36622,,55dd3565,3fdb382b,33d94071,49d68486
|
||||
0,0.0,1,7.0,8.0,4501.0,184.0,2.0,4.0,184.0,0.0,1.0,,46.0,05db9164,58e67aaf,8b376137,270b5720,4cf72387,7e0ccccf,67b7679f,0b153874,a73ee510,19feb952,16faa766,8d526153,4422e246,b28479f6,62eca3c0,23c4fd37,07c540c4,c21c3e4c,6301e460,b1252a9d,632bf881,,bcdee96c,18109ace,9b3e8820,070f6cb2
|
||||
0,,183,3.0,3.0,5778.0,,0.0,3.0,9.0,,0.0,,3.0,39af2607,c5c1d6ae,027b4cc5,9affccc2,25c83c98,6f6d9be8,d2bfca2c,5b392875,a73ee510,3b08e48b,f72b4bd1,7e98747a,01f32ac8,07d13a8f,99153e7d,64223df7,776ce399,836a67dd,21ddcdc9,5840adea,301fc194,,be7c41b4,365def8b,7a402766,00efb483
|
||||
0,,13,3.0,10.0,48.0,16.0,11.0,10.0,163.0,,3.0,0.0,6.0,05db9164,40ed0c67,61b8caf0,5ef5cf67,25c83c98,7e0ccccf,a7565058,d7c4a8f5,a73ee510,567ba666,69afd526,765cb3ea,84def884,07d13a8f,622c34d8,5c646b1e,e5ba7672,2585827d,21ddcdc9,5840adea,c4c42074,,3a171ecb,42df8359,e8b83407,c0fca43d
|
||||
0,,1,25.0,22.0,39424.0,66.0,1.0,28.0,60.0,,0.0,,29.0,5a9ed9b0,9b25e48b,f25edca2,418ae7fb,25c83c98,7e0ccccf,a5a83bdd,5b392875,a73ee510,5ea6fa93,f697a983,ad46dc69,e5643e9a,07d13a8f,054ebda1,967bc626,3486227d,7d8c03aa,2442feac,a458ea53,30244f84,,c7dc6720,3a6f67d1,010f6491,f4642e0e
|
||||
0,,1,13.0,3.0,5646.0,49.0,3.0,3.0,59.0,,1.0,,3.0,8cf07265,558b4efb,40361716,f2159098,25c83c98,fbad5c96,6005554a,062b5529,a73ee510,b1442b2a,c19406bc,842839b9,07fdb6cc,07d13a8f,c1ddc990,9f1d1f70,27c07bd6,c68ebaa0,21ddcdc9,5840adea,16f71b82,ad3062eb,32c7478e,3b183c5c,ea9a246c,2f44e540
|
||||
1,0.0,1,2.0,2.0,1795.0,4.0,1.0,2.0,2.0,0.0,1.0,,2.0,05db9164,38a947a1,bd4d1b8d,097de257,25c83c98,,788ff59f,0b153874,a73ee510,3b08e48b,9c9d4957,3263408b,9325eab4,07d13a8f,456583e6,c57bda3a,d4bb7bd8,4b0f5ddd,,,6fb7987f,,32c7478e,9b7eed78,,
|
||||
1,1.0,2,603.0,11.0,2.0,11.0,2.0,11.0,11.0,1.0,2.0,,11.0,05db9164,58e67aaf,f5cdf14a,39cc9792,4cf72387,7e0ccccf,9ff9bbde,0b153874,a73ee510,8c8662e4,f89fe102,5d84eb4a,83e6ca2e,1adce6ef,d002b6d9,a98ec356,07c540c4,c21c3e4c,c79aad78,b1252a9d,ec4a835a,,423fab69,b44bd498,9b3e8820,8fd6bdd6
|
||||
1,9.0,1,39.0,6.0,48.0,14.0,13.0,30.0,68.0,2.0,4.0,,6.0,be589b51,4f25e98b,761d2b40,5f379ae0,4cf72387,fe6b92e5,9b98e9fc,0b153874,a73ee510,2a47dab8,7f8ffe57,beb94e00,46f42a63,07d13a8f,dfab705f,9066bcfb,e5ba7672,7ef5affa,49463d54,b1252a9d,822be048,c9d4222a,32c7478e,3fdb382b,001f3601,49d68486
|
||||
0,1.0,12,4.0,2.0,5.0,3.0,25.0,19.0,113.0,1.0,2.0,2.0,2.0,68fd1e64,a5b69ae3,0b793d71,813cb08c,4cf72387,7e0ccccf,468a0854,0b153874,a73ee510,3b08e48b,a60de4e5,f9bf526c,605bbc24,b28479f6,9703aa2f,9ee32e6f,8efede7f,a1654f4f,21ddcdc9,5840adea,7a380bd1,,32c7478e,08b0ce98,2bf691b1,984e0db0
|
||||
0,0.0,0,21.0,5.0,2865.0,,0.0,31.0,1.0,0.0,0.0,,31.0,ae82ea21,38d50e09,01a0648b,657dc3b9,25c83c98,7e0ccccf,0c41b6a1,0b153874,a73ee510,56ef22e9,4ba74619,11fcf7fa,879fa878,07d13a8f,fa321567,5e1b6b9d,e5ba7672,52b872ed,21ddcdc9,a458ea53,bfeb50f6,,423fab69,df487a73,e8b83407,c27f155b
|
||||
0,,-1,66.0,29.0,2940.0,87.0,69.0,35.0,82.0,,5.0,0.0,32.0,68fd1e64,1cfdf714,3cb0ff62,9b17f367,43b19349,7e0ccccf,e2de05d6,0b153874,a73ee510,1ce1e29d,b26d847d,59a625a9,38016f21,1adce6ef,f3002fbd,229bf6f4,3486227d,e88ffc9d,edb3d180,a458ea53,5362f5c3,,423fab69,f20c047e,cb079c2d,0facb2ea
|
||||
1,,370,,3.0,357.0,,0.0,4.0,5.0,,0.0,,3.0,68fd1e64,2ae0a573,af21d90e,dc0a11c7,4cf72387,,ed0714a0,1f89b562,a73ee510,f1b39deb,b85b416c,a4425bd8,c3f71b59,07d13a8f,413cc8c6,41bec2fe,d4bb7bd8,f2fc99b1,,,95ee3d7a,,32c7478e,7836b4d5,,
|
||||
0,0.0,237,1.0,1.0,4619.0,53.0,17.0,16.0,272.0,0.0,1.0,,1.0,f473b8dc,89ddfee8,f153af65,13508380,25c83c98,3bf701e7,c96de117,37e4aa92,a73ee510,995c2a7f,ad757a5a,99ec4e40,93b18cb5,07d13a8f,59a58e86,13ede1b5,3486227d,ae46962e,55dd3565,b1252a9d,8a93f0a1,ad3062eb,423fab69,45ab94c8,f0f449dd,c84c4aec
|
||||
0,,0,2.0,3.0,10327.0,648.0,11.0,3.0,127.0,,3.0,,3.0,39af2607,68b3edbf,ad4b77ff,d16679b9,25c83c98,7e0ccccf,b00f5963,c8ddd494,a73ee510,ac82cac0,b91c2548,a2f4e8b5,a03da696,b28479f6,12f48803,89052618,e5ba7672,cf1cde40,,,d4703ebd,,bcdee96c,aee52b6f,,
|
||||
1,,3,,24.0,1853.0,36.0,10.0,9.0,175.0,,2.0,,24.0,05db9164,38a947a1,03689820,21817e80,25c83c98,7e0ccccf,50a5390e,0b153874,a73ee510,0466803a,159499d1,79b98d3d,4ab361e1,b28479f6,72f85ad5,8e47fca6,e5ba7672,5ba7fffe,,,15fb7955,,32c7478e,71dc4ef2,,
|
||||
0,4.0,1,2.0,17.0,7.0,4.0,4.0,18.0,18.0,1.0,1.0,3.0,3.0,05db9164,0a519c5c,77f2f2e5,d16679b9,43b19349,fbad5c96,c78204a1,0b153874,a73ee510,3b08e48b,5f5e6091,9f32b866,aa655a2f,07d13a8f,b812f9f2,31ca40b6,27c07bd6,2efa89c6,,,dfcfc3fa,,3a171ecb,aee52b6f,,
|
||||
0,0.0,10,1.0,0.0,5781.0,164.0,5.0,6.0,160.0,0.0,5.0,,5.0,8cf07265,e112a9de,af5655e7,22504558,4cf72387,7e0ccccf,133643ef,0b153874,a73ee510,64145819,84bc66d0,252162ec,bcb2e77c,1adce6ef,11da3cff,776f5665,e5ba7672,a7cf409e,,,5c7c443c,,32c7478e,8f079aa5,,
|
||||
0,,2,2.0,3.0,3379.0,,0.0,5.0,4.0,,0.0,,3.0,09ca0b81,287130e0,20fb5e45,aafb54fa,25c83c98,fbad5c96,bf115338,56563555,a73ee510,3b08e48b,41516dc9,2ea11a49,8b11c4b8,1adce6ef,310d155b,b9a4d133,776ce399,891589e7,f30f7842,a458ea53,86a8e85e,c9d4222a,be7c41b4,bc491035,e8b83407,bd2ec696
|
||||
0,0.0,1,7.0,12.0,3011.0,126.0,5.0,41.0,121.0,0.0,2.0,,12.0,be589b51,d833535f,77f2f2e5,d16679b9,43b19349,fe6b92e5,6978304f,0b153874,a73ee510,fbbf2c95,78f92234,9f32b866,9be66b48,b28479f6,a66dcf27,31ca40b6,e5ba7672,7b49e3d2,,,dfcfc3fa,,3a171ecb,aee52b6f,,
|
||||
1,2.0,1,3.0,1.0,63.0,1.0,21.0,2.0,108.0,2.0,9.0,2.0,1.0,68fd1e64,e5fb1af3,be0a348d,e0e934af,25c83c98,13718bbd,372a0c4c,0b153874,a73ee510,e8e8c8ac,ec88dd34,7ac672aa,94881fc3,07d13a8f,b5de5956,e3d99bf0,27c07bd6,13145934,42e59f55,5840adea,8f78192f,,3a171ecb,198d16cc,e8b83407,0e2018ec
|
||||
0,,1,3.0,1.0,563.0,,0.0,5.0,3.0,,0.0,,1.0,05db9164,55e0a784,5b54e5b4,c5699aad,25c83c98,7e0ccccf,dcab49d9,0b153874,a73ee510,34dd9626,cd3a0eb4,c492212b,715b22a3,07d13a8f,45e17a48,1f55226d,1e88c74f,6c5555bd,21ddcdc9,b1252a9d,99712f38,,423fab69,167193c9,e8b83407,ae5fce01
|
||||
0,,1,4.0,2.0,8684.0,11.0,1.0,3.0,7.0,,1.0,,2.0,05db9164,e5fb1af3,c8b80f97,311f127a,25c83c98,fe6b92e5,372a0c4c,0b153874,a73ee510,6f0b6a04,2e15139e,9ffdd484,94881fc3,07d13a8f,b5de5956,5891d119,d4bb7bd8,13145934,cc4c70c1,a458ea53,cd11300e,ad3062eb,3a171ecb,cf300ce9,001f3601,814b9a6b
|
||||
0,8.0,1,3.0,14.0,351.0,50.0,8.0,35.0,37.0,1.0,1.0,,18.0,05db9164,e9b8a266,be3b6a18,62169fb6,0942e0a7,7e0ccccf,d55d70ca,5b392875,a73ee510,1d56e466,9cf09d42,6647ec34,f66b043c,b28479f6,fb67e61d,236709b9,e5ba7672,d452c287,,,77799c4f,c9d4222a,32c7478e,5fd07f39,,
|
||||
1,0.0,-1,,,1398.0,0.0,1.0,0.0,0.0,0.0,1.0,,,05db9164,512fdf0c,98bb788f,e0a2ecca,0942e0a7,7e0ccccf,d01ba955,7b6fecd5,a73ee510,3b08e48b,c0edaa76,167ba71f,34fc0029,07d13a8f,aa322bcf,5e622e84,d4bb7bd8,fd3919f9,21ddcdc9,5840adea,43d01030,,c7dc6720,4acb8523,724b04da,c986348f
|
||||
1,,74,3.0,4.0,17991.0,32.0,11.0,9.0,98.0,,10.0,,4.0,5a9ed9b0,8947f767,9ea04474,2b0aadf8,25c83c98,6f6d9be8,368f84ee,0b153874,a73ee510,3b08e48b,6dc69f41,4640585e,fca56425,f7c1b33f,7f758956,d8831736,e5ba7672,bd17c3da,bf212c4c,b1252a9d,d4f22efc,,32c7478e,0ac1b18a,010f6491,6d73203e
|
||||
0,,38,14.0,46.0,6426.0,888.0,12.0,9.0,862.0,,1.0,,46.0,05db9164,95e2d337,0d71b822,3fb81b62,30903e74,7e0ccccf,8f572b5e,0b153874,a73ee510,897188be,434d6c13,28283f53,7301027a,b28479f6,17a3bcd8,9e724f87,e5ba7672,7b06fafe,21ddcdc9,5840adea,07b818d7,,c7dc6720,b2df17ed,c243e98b,33757f80
|
||||
0,0.0,1,,2.0,14496.0,895.0,3.0,7.0,58.0,0.0,1.0,,2.0,05db9164,9a82ab91,d032c263,c18be181,25c83c98,7e0ccccf,d9f4e70f,0b153874,a73ee510,27f4bf82,da89cb9b,dfbb09fb,165642be,07d13a8f,33d2c881,84898b2a,07c540c4,004fdf10,,,0014c32a,,32c7478e,3b183c5c,,
|
||||
0,0.0,14,15.0,11.0,4108.0,125.0,4.0,35.0,111.0,0.0,1.0,,14.0,05db9164,e3a0dc66,2ba709bb,7be47200,25c83c98,fe6b92e5,8a850658,0b153874,a73ee510,3094253e,d9b1e3ff,fa5eca9d,cd98af01,07d13a8f,c251e774,22283336,e5ba7672,b608c073,,,fd0e41ce,c9d4222a,c7dc6720,f2e9f0dd,,
|
||||
1,,18,23.0,,42024.0,,,0.0,,,,,,05db9164,09e68b86,aa8c1539,85dd697c,25c83c98,,b87f4a4a,5b392875,a73ee510,e70742b0,319687c9,d8c29807,62036f49,07d13a8f,801ee1ae,c64d548f,e5ba7672,63cdbb21,cf99e5de,5840adea,5f957280,,32c7478e,1793a828,e8b83407,b7d9c3bc
|
||||
1,1.0,2,76.0,4.0,0.0,4.0,1.0,4.0,4.0,1.0,1.0,,4.0,05db9164,38a947a1,f1a544c6,9c65ce26,25c83c98,fbad5c96,df5c2d18,0b153874,a73ee510,903f1f14,a7b606c4,8f1a16da,eae197fd,b28479f6,b842e9bb,789e0e3e,e5ba7672,38f08461,,,79fe2943,,bcdee96c,325bcd40,,
|
||||
0,1.0,0,29.0,5.0,40.0,5.0,1.0,5.0,5.0,1.0,1.0,,5.0,8cf07265,09e68b86,8530c58f,abfc27b2,25c83c98,,197b4575,0b153874,a73ee510,6c47047a,606866a9,8a433ec1,e40e52ae,64c94865,91126f30,cc93bd1d,d4bb7bd8,5aed7436,6d82104d,a458ea53,c1429b47,,3a171ecb,a0634086,e8b83407,9c015713
|
||||
0,1.0,2921,,0.0,48.0,17.0,20.0,10.0,84.0,1.0,2.0,1.0,0.0,39af2607,4f25e98b,b0874fd0,b696e406,25c83c98,fbad5c96,dc7659bd,0b153874,a73ee510,03e48276,e51ddf94,6536f6f8,3516f6e6,b28479f6,8ab5b746,271d5b6c,27c07bd6,7ef5affa,21ddcdc9,a458ea53,a716bbe2,,3a171ecb,3fdb382b,001f3601,a39e1586
|
||||
0,,55,10.0,12.0,299.0,,0.0,23.0,26.0,,0.0,,26.0,17f69355,38a947a1,4470baf4,8c8a4c47,25c83c98,7e0ccccf,2a37bb01,5b392875,a73ee510,3b08e48b,61ba19ac,bb669e25,fa17cc68,b28479f6,a3443e75,2b2ce127,776ce399,ade68c22,,,2b796e4a,ad3062eb,be7c41b4,8d365d3b,,
|
||||
0,2.0,8,6.0,3.0,5.0,3.0,25.0,11.0,722.0,1.0,6.0,,3.0,05db9164,09e68b86,57231f4a,c38a1d7d,25c83c98,fbad5c96,968a6688,0b153874,a73ee510,e851ff7b,f25fe7e9,2849c511,dd183b4c,f7c1b33f,5726b2dc,2b7f6e55,e5ba7672,5aed7436,4a237258,b1252a9d,fd3ca145,c9d4222a,32c7478e,0ea7be91,e8b83407,f610730e
|
||||
1,1.0,493,155.0,2.0,1.0,0.0,8.0,7.0,45.0,1.0,7.0,,0.0,68fd1e64,78ccd99e,ac203f6f,13508380,25c83c98,7e0ccccf,e24d7cb8,0b153874,a73ee510,6f07d986,03458ded,2d72bfb9,8019075f,07d13a8f,162f3329,eedd265a,e5ba7672,e7e991cb,21ddcdc9,b1252a9d,56b58097,c9d4222a,423fab69,45ab94c8,e8b83407,c84c4aec
|
||||
0,,35,,,293044.0,,,7.0,,,,,,05db9164,38a947a1,1678e0d8,bd6ffe0f,25c83c98,7e0ccccf,e2ec9176,0b153874,7cc72ec2,3b08e48b,6fc6ad29,704629a2,b0c30eeb,b28479f6,443b0c0b,809c9e0e,e5ba7672,f0959f21,,,6a41d841,,be7c41b4,0ee762c3,,
|
||||
0,,8,8.0,12.0,39343.0,1820.0,0.0,19.0,318.0,,0.0,,12.0,05db9164,d57c0709,d032c263,c18be181,25c83c98,7e0ccccf,122c542a,0b153874,a73ee510,801e8634,7fee217f,dfbb09fb,6e2907f1,cfef1c29,487ddf17,84898b2a,e5ba7672,3ae505af,,,0014c32a,,423fab69,3b183c5c,,
|
||||
0,5.0,0,1.0,,92.0,0.0,5.0,0.0,0.0,1.0,1.0,,,05db9164,78ccd99e,bf30cf68,49c94103,30903e74,7e0ccccf,a1eeac3d,1f89b562,a73ee510,12bb8262,2e9d5aa6,975f89b0,0a9ac04c,f862f261,ada14dd8,a9b56248,e5ba7672,e7e991cb,21ddcdc9,a458ea53,0d7a15fd,,32c7478e,fb890da1,33d94071,86174332
|
||||
1,,0,1.0,,19088.0,11.0,11.0,0.0,89.0,,2.0,,,68fd1e64,c5fe64d9,01ac13ea,f6dbd8fb,4cf72387,6f6d9be8,6cdb3998,062b5529,a73ee510,b173a655,5874c9c9,16a886e7,740c210d,07d13a8f,52b49730,a249bde3,e5ba7672,c235abed,f30f7842,a458ea53,c4b9fb56,8ec974f4,32c7478e,44aeb111,33d94071,df46df55
|
||||
0,,248,1.0,1.0,79620.0,,,1.0,,,,,1.0,da4eff0f,d833535f,77f2f2e5,d16679b9,25c83c98,fe6b92e5,8f801a1a,1f89b562,7cc72ec2,3b08e48b,f295b28a,9f32b866,f5df7ab9,07d13a8f,943169c2,31ca40b6,d4bb7bd8,281769c2,,,dfcfc3fa,,3a171ecb,aee52b6f,,
|
||||
0,0.0,0,3.0,2.0,3150.0,21.0,4.0,3.0,24.0,0.0,2.0,,2.0,05db9164,80e26c9b,e346a5fd,85dd697c,4cf72387,,55fc227e,0b153874,a73ee510,b1aa986c,d8d7567b,539c5644,47d6a934,b28479f6,a785131a,aafa191e,e5ba7672,005c6740,21ddcdc9,5840adea,7e5b7cc4,,32c7478e,1793a828,e8b83407,b9809574
|
||||
0,,0,10.0,2.0,41706.0,84.0,0.0,5.0,49.0,,0.0,,2.0,8cf07265,942f9a8d,d1ffd05c,9df780c1,25c83c98,7e0ccccf,49b74ebc,1f89b562,a73ee510,0e9ead52,c4adf918,f0c1019c,85dbe138,b28479f6,ac182643,52bee03d,d4bb7bd8,1f868fdd,5b885066,a458ea53,35198a67,ad3062eb,32c7478e,30ab4eb4,e8b83407,85fd868a
|
||||
1,4.0,-1,6.0,6.0,872.0,31.0,37.0,42.0,334.0,1.0,16.0,,6.0,8cf07265,d4bd9877,a55127b0,90044821,4cf72387,3bf701e7,6a858837,0b153874,a73ee510,3b08e48b,eb9eb939,a0015d5d,2b54e95d,07d13a8f,10139ce3,b458da0e,e5ba7672,62acb0f3,,,d7a43622,,423fab69,dcba8699,,
|
||||
0,,38,,,43205.0,680.0,0.0,2.0,20.0,,0.0,0.0,,68fd1e64,2c8c5f5d,0f09a700,38aca36b,4cf72387,fbad5c96,91282309,0b153874,7cc72ec2,dcbc7c2b,9e511730,25644e7d,04e4a7e0,64c94865,c1124d0c,4c7535f3,3486227d,f5f4ae5b,,,5b6b6b73,,3a171ecb,1793a828,,
|
||||
0,,0,6.0,6.0,124027.0,,0.0,5.0,19.0,,0.0,,6.0,05db9164,38a947a1,acbabfa5,187dc42d,25c83c98,fbad5c96,e14874c9,51d76abe,7cc72ec2,ff5a1549,636405ac,8d2c704a,31b42deb,07d13a8f,55808bb2,c66a58da,e5ba7672,824dcc94,,,9308de7e,ad3062eb,3a171ecb,9d8b4082,,
|
||||
1,2.0,6,,,300.0,25.0,2.0,25.0,68.0,1.0,1.0,,,5a9ed9b0,38a947a1,b1b6f323,be4cb064,25c83c98,7e0ccccf,00dd27a6,0b153874,a73ee510,98bd7a24,55065437,d28c687a,80dcea18,1adce6ef,fc42663d,f2a191bd,e5ba7672,c9da8737,,,5911ddcb,,32c7478e,1335030a,,
|
||||
0,,27,,,112878.0,2106.0,0.0,2.0,95.0,,0.0,,,5a9ed9b0,38a947a1,2d8004c4,40ed41e5,25c83c98,7e0ccccf,4d9d55ae,5b392875,7cc72ec2,3b08e48b,55065437,ad972965,80dcea18,07d13a8f,c68ba31d,1206a8a1,d4bb7bd8,e96a7df2,,,54d8bb06,,3a171ecb,a415643d,,
|
||||
0,0.0,3001,2.0,,3134.0,47.0,1.0,0.0,1.0,0.0,1.0,0.0,,05db9164,403ea497,2cbec47f,3e2bfbda,25c83c98,,19672560,0b153874,a73ee510,a8d1ae09,2591ca7a,21a23bfe,9b7d472e,07d13a8f,e3209fc2,587267a3,3486227d,a78bd508,21ddcdc9,5840adea,c2a93b37,,c7dc6720,1793a828,e8b83407,2fede552
|
||||
1,0.0,179,5.0,1.0,1464.0,6.0,70.0,6.0,16.0,0.0,10.0,,3.0,68fd1e64,404660bb,f1397040,09003f7b,25c83c98,7e0ccccf,1c86e0eb,5b392875,a73ee510,67eea4ef,755e4a50,0cdb9a18,5978055e,1adce6ef,6ddbba94,82708081,e5ba7672,4b17f8a2,21ddcdc9,5840adea,4c14738f,,32c7478e,a86c0565,f0f449dd,984e0db0
|
||||
1,,1,7.0,2.0,2910.0,2.0,301.0,3.0,54.0,,15.0,0.0,2.0,8cf07265,942f9a8d,3a3d6eeb,eabe170f,25c83c98,6f6d9be8,49b74ebc,0b153874,a73ee510,0e9ead52,c4adf918,a66cfe4b,85dbe138,07d13a8f,a8e962af,a3d7b1d6,e5ba7672,1f868fdd,fc134659,a458ea53,bbcf650c,,32c7478e,75b9c133,9d93af03,e438a496
|
||||
0,0.0,0,8.0,6.0,125.0,122.0,5.0,34.0,107.0,0.0,3.0,,24.0,5a9ed9b0,c5e4f7c9,,,25c83c98,7e0ccccf,95402f9a,64523cfa,a73ee510,5162b19c,c82f1813,,949ea585,b28479f6,b16ae607,,e5ba7672,ac02dc99,,,,c9d4222a,32c7478e,,,
|
||||
0,0.0,0,5.0,6.0,6461.0,93.0,19.0,7.0,37.0,0.0,1.0,1.0,7.0,68fd1e64,09e68b86,5f8d9359,2628b8d6,25c83c98,13718bbd,53e14bd5,0b153874,a73ee510,97d3ddaa,319687c9,de2ecc9c,62036f49,cfef1c29,18847041,62675893,3486227d,5aed7436,b1fb78cc,a458ea53,be01d6b1,,3a171ecb,b1aad66f,e8b83407,3df61e3d
|
||||
1,0.0,2,1.0,11.0,2119.0,79.0,6.0,2.0,114.0,0.0,3.0,1.0,11.0,05db9164,2ae0a573,4993b2b2,9ab05b8f,25c83c98,7e0ccccf,9e8dab66,0b153874,a73ee510,5ba575e7,2d9eed4d,bdf9cff8,949ea585,07d13a8f,413cc8c6,fb2ac6b5,3486227d,f2fc99b1,,,0fbced35,ad3062eb,32c7478e,d91ea8bd,,
|
||||
0,0.0,17,5.0,7.0,6288.0,,0.0,42.0,1.0,0.0,0.0,,35.0,5a9ed9b0,62e9e9bf,,,25c83c98,7e0ccccf,f74ed3c0,0b153874,a73ee510,39046df2,e90cbbe1,,a4c7bffd,07d13a8f,de829bed,,e5ba7672,d2651d6e,,,,,32c7478e,,,
|
||||
0,,2,23.0,20.0,148.0,,0.0,20.0,20.0,,0.0,,20.0,68fd1e64,09e68b86,7edab412,f1d06e8a,43b19349,,16401b7d,0b153874,a73ee510,3b08e48b,20ec800a,0a02e48e,18a5e4b8,1adce6ef,dbc5e126,e2bc04da,776ce399,5aed7436,0053530c,a458ea53,1de5dd94,,32c7478e,43fe299c,f0f449dd,f3b1f00d
|
||||
0,,19,535.0,7.0,61968.0,,0.0,7.0,2.0,,0.0,,7.0,05db9164,8ab240be,145f2f75,82a61820,25c83c98,7e0ccccf,ff08f605,0b153874,7cc72ec2,ec4d75ea,6939835e,7161e106,dc1d72e4,1adce6ef,28883800,bb6d240e,e5ba7672,ca533012,21ddcdc9,5840adea,5fe17899,,72592995,cafb4e4d,e8b83407,99f4f64c
|
||||
0,,0,113.0,3.0,3036.0,575.0,2.0,3.0,214.0,,1.0,,3.0,05db9164,0468d672,628b07b0,b63c0277,25c83c98,7e0ccccf,0d339a25,c8ddd494,a73ee510,1722d4c8,7d756b25,0c87b3e9,6f833c7a,1adce6ef,4f3b3616,48af915a,07c540c4,9880032b,21ddcdc9,5840adea,34cc61bb,c9d4222a,32c7478e,e5ed7da2,ea9a246c,984e0db0
|
||||
1,0.0,1,1.0,1.0,1607.0,12.0,1.0,12.0,15.0,0.0,1.0,,12.0,be589b51,aa8fcc21,4255f8fd,7501d94a,25c83c98,fe6b92e5,0492c809,1f89b562,a73ee510,13ba96b0,ba0f9e8a,887a0c20,4e4dd817,07d13a8f,a4f91020,022714ba,1e88c74f,3972b4ed,,,d1aa4512,,32c7478e,9257f75f,,
|
||||
1,1.0,0,6.0,3.0,0.0,0.0,19.0,3.0,3.0,1.0,9.0,0.0,0.0,05db9164,09e68b86,db151f8b,f1b645fc,25c83c98,,b87f4a4a,0b153874,a73ee510,e70742b0,319687c9,af6ad6b6,62036f49,f862f261,1dca7862,05a97a3c,3486227d,5aed7436,54591762,a458ea53,4a2c3526,,32c7478e,1793a828,e8b83407,1a02cbe1
|
||||
0,0.0,22,6.0,22.0,203.0,153.0,80.0,18.0,508.0,0.0,11.0,0.0,22.0,05db9164,e5fb1af3,7e1ad1fe,46ec0a38,43b19349,7e0ccccf,24c48926,0b153874,a73ee510,afa26c81,9f0003f4,651d80c6,5afd9e51,07d13a8f,b5de5956,72401022,3486227d,13145934,55dd3565,5840adea,bf647035,,32c7478e,1481ceb4,e8b83407,988b0775
|
||||
0,1.0,-1,,,138.0,0.0,1.0,0.0,0.0,1.0,1.0,,,be589b51,b46aceb6,,,43b19349,,17cdc396,0b153874,a73ee510,75d852fc,d79cc967,,115d29f4,07d13a8f,217d99f2,,d4bb7bd8,908eaeb8,,,,,32c7478e,,,
|
||||
170
DeepRecommendationModel/代码/data/ml-1m/README
Normal file
@@ -0,0 +1,170 @@
|
||||
SUMMARY
|
||||
================================================================================
|
||||
|
||||
These files contain 1,000,209 anonymous ratings of approximately 3,900 movies
|
||||
made by 6,040 MovieLens users who joined MovieLens in 2000.
|
||||
|
||||
USAGE LICENSE
|
||||
================================================================================
|
||||
|
||||
Neither the University of Minnesota nor any of the researchers
|
||||
involved can guarantee the correctness of the data, its suitability
|
||||
for any particular purpose, or the validity of results based on the
|
||||
use of the data set. The data set may be used for any research
|
||||
purposes under the following conditions:
|
||||
|
||||
* The user may not state or imply any endorsement from the
|
||||
University of Minnesota or the GroupLens Research Group.
|
||||
|
||||
* The user must acknowledge the use of the data set in
|
||||
publications resulting from the use of the data set
|
||||
(see below for citation information).
|
||||
|
||||
* The user may not redistribute the data without separate
|
||||
permission.
|
||||
|
||||
* The user may not use this information for any commercial or
|
||||
revenue-bearing purposes without first obtaining permission
|
||||
from a faculty member of the GroupLens Research Project at the
|
||||
University of Minnesota.
|
||||
|
||||
If you have any further questions or comments, please contact GroupLens
|
||||
<grouplens-info@cs.umn.edu>.
|
||||
|
||||
CITATION
|
||||
================================================================================
|
||||
|
||||
To acknowledge use of the dataset in publications, please cite the following
|
||||
paper:
|
||||
|
||||
F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History
|
||||
and Context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4,
|
||||
Article 19 (December 2015), 19 pages. DOI=http://dx.doi.org/10.1145/2827872
|
||||
|
||||
|
||||
ACKNOWLEDGEMENTS
|
||||
================================================================================
|
||||
|
||||
Thanks to Shyong Lam and Jon Herlocker for cleaning up and generating the data
|
||||
set.
|
||||
|
||||
FURTHER INFORMATION ABOUT THE GROUPLENS RESEARCH PROJECT
|
||||
================================================================================
|
||||
|
||||
The GroupLens Research Project is a research group in the Department of
|
||||
Computer Science and Engineering at the University of Minnesota. Members of
|
||||
the GroupLens Research Project are involved in many research projects related
|
||||
to the fields of information filtering, collaborative filtering, and
|
||||
recommender systems. The project is lead by professors John Riedl and Joseph
|
||||
Konstan. The project began to explore automated collaborative filtering in
|
||||
1992, but is most well known for its world wide trial of an automated
|
||||
collaborative filtering system for Usenet news in 1996. Since then the project
|
||||
has expanded its scope to research overall information filtering solutions,
|
||||
integrating in content-based methods as well as improving current collaborative
|
||||
filtering technology.
|
||||
|
||||
Further information on the GroupLens Research project, including research
|
||||
publications, can be found at the following web site:
|
||||
|
||||
http://www.grouplens.org/
|
||||
|
||||
GroupLens Research currently operates a movie recommender based on
|
||||
collaborative filtering:
|
||||
|
||||
http://www.movielens.org/
|
||||
|
||||
RATINGS FILE DESCRIPTION
|
||||
================================================================================
|
||||
|
||||
All ratings are contained in the file "ratings.dat" and are in the
|
||||
following format:
|
||||
|
||||
UserID::MovieID::Rating::Timestamp
|
||||
|
||||
- UserIDs range between 1 and 6040
|
||||
- MovieIDs range between 1 and 3952
|
||||
- Ratings are made on a 5-star scale (whole-star ratings only)
|
||||
- Timestamp is represented in seconds since the epoch as returned by time(2)
|
||||
- Each user has at least 20 ratings
|
||||
|
||||
USERS FILE DESCRIPTION
|
||||
================================================================================
|
||||
|
||||
User information is in the file "users.dat" and is in the following
|
||||
format:
|
||||
|
||||
UserID::Gender::Age::Occupation::Zip-code
|
||||
|
||||
All demographic information is provided voluntarily by the users and is
|
||||
not checked for accuracy. Only users who have provided some demographic
|
||||
information are included in this data set.
|
||||
|
||||
- Gender is denoted by a "M" for male and "F" for female
|
||||
- Age is chosen from the following ranges:
|
||||
|
||||
* 1: "Under 18"
|
||||
* 18: "18-24"
|
||||
* 25: "25-34"
|
||||
* 35: "35-44"
|
||||
* 45: "45-49"
|
||||
* 50: "50-55"
|
||||
* 56: "56+"
|
||||
|
||||
- Occupation is chosen from the following choices:
|
||||
|
||||
* 0: "other" or not specified
|
||||
* 1: "academic/educator"
|
||||
* 2: "artist"
|
||||
* 3: "clerical/admin"
|
||||
* 4: "college/grad student"
|
||||
* 5: "customer service"
|
||||
* 6: "doctor/health care"
|
||||
* 7: "executive/managerial"
|
||||
* 8: "farmer"
|
||||
* 9: "homemaker"
|
||||
* 10: "K-12 student"
|
||||
* 11: "lawyer"
|
||||
* 12: "programmer"
|
||||
* 13: "retired"
|
||||
* 14: "sales/marketing"
|
||||
* 15: "scientist"
|
||||
* 16: "self-employed"
|
||||
* 17: "technician/engineer"
|
||||
* 18: "tradesman/craftsman"
|
||||
* 19: "unemployed"
|
||||
* 20: "writer"
|
||||
|
||||
MOVIES FILE DESCRIPTION
|
||||
================================================================================
|
||||
|
||||
Movie information is in the file "movies.dat" and is in the following
|
||||
format:
|
||||
|
||||
MovieID::Title::Genres
|
||||
|
||||
- Titles are identical to titles provided by the IMDB (including
|
||||
year of release)
|
||||
- Genres are pipe-separated and are selected from the following genres:
|
||||
|
||||
* Action
|
||||
* Adventure
|
||||
* Animation
|
||||
* Children's
|
||||
* Comedy
|
||||
* Crime
|
||||
* Documentary
|
||||
* Drama
|
||||
* Fantasy
|
||||
* Film-Noir
|
||||
* Horror
|
||||
* Musical
|
||||
* Mystery
|
||||
* Romance
|
||||
* Sci-Fi
|
||||
* Thriller
|
||||
* War
|
||||
* Western
|
||||
|
||||
- Some MovieIDs do not correspond to a movie due to accidental duplicate
|
||||
entries and/or test entries
|
||||
- Movies are mostly entered by hand, so errors and inconsistencies may exist
|
||||
55
DeepRecommendationModel/代码/data/ml-1m/data_helper.py
Normal file
@@ -0,0 +1,55 @@
|
||||
# /usr/bin/Python2
|
||||
#coding=utf8
|
||||
|
||||
import random
|
||||
|
||||
def loadfile(path):
|
||||
with open(path,"r") as f:
|
||||
for i,line in enumerate(f):
|
||||
yield line
|
||||
|
||||
def read_users(path = "users.dat"):
|
||||
"""
|
||||
返回user的list
|
||||
Args:
|
||||
path : 文件路径
|
||||
Return:
|
||||
user的list形式,格式为(userId,性别,年龄,职业)
|
||||
"""
|
||||
users = []
|
||||
for line in loadfile(path):
|
||||
users.append(line.split("::")[:-1])
|
||||
return users
|
||||
|
||||
def read_movies(path = "movies.dat"):
|
||||
"""
|
||||
返回movie的list
|
||||
Args:
|
||||
path : 文件路径
|
||||
Return:
|
||||
movie的list形式,格式为(movieId,电影名,类型)
|
||||
"""
|
||||
movies = []
|
||||
for line in loadfile(path):
|
||||
movies.append(line.split("::"))
|
||||
return movies
|
||||
|
||||
def read_ratings(path,pivot = 0.8):
|
||||
"""
|
||||
Return:
|
||||
点击的字典形式,格式为{userId : { movieId : rating}}
|
||||
"""
|
||||
train_set = dict()
|
||||
test_set = dict()
|
||||
|
||||
for line in loadfile(path):
|
||||
user,movie,rating,_ = line.split("::")
|
||||
if random.random() < pivot:
|
||||
train_set.setdefault(user,{})
|
||||
train_set[user][movie] = int(rating)
|
||||
else:
|
||||
test_set.setdefault(user,{})
|
||||
test_set[user][movie] = int(rating)
|
||||
|
||||
return train_set,test_set
|
||||
|
||||
3883
DeepRecommendationModel/代码/data/ml-1m/movies.dat
Normal file
1000209
DeepRecommendationModel/代码/data/ml-1m/ratings.dat
Normal file
6040
DeepRecommendationModel/代码/data/ml-1m/users.dat
Normal file
1380
DeepRecommendationModel/代码/data/movie_sample.txt
Normal file
201
DeepRecommendationModel/代码/data/movielens_sample.txt
Normal file
@@ -0,0 +1,201 @@
|
||||
user_id,movie_id,rating,timestamp,title,genres,gender,age,occupation,zip
|
||||
3299,235,4,968035345,Ed Wood (1994),Comedy|Drama,F,25,4,19119
|
||||
3630,3256,3,966536874,Patriot Games (1992),Action|Thriller,M,18,4,77005
|
||||
517,105,4,976203603,"Bridges of Madison County, The (1995)",Drama|Romance,F,25,14,55408
|
||||
785,2115,3,975430389,Indiana Jones and the Temple of Doom (1984),Action|Adventure,M,18,19,29307
|
||||
5848,909,5,957782527,"Apartment, The (1960)",Comedy|Drama,M,50,20,20009
|
||||
2996,2799,1,972769867,Problem Child 2 (1991),Comedy,M,18,0,63011
|
||||
3087,837,5,969738869,Matilda (1996),Children's|Comedy,F,1,1,90802
|
||||
872,3092,5,975273310,Chushingura (1962),Drama,M,50,1,20815
|
||||
4094,529,5,966223349,Searching for Bobby Fischer (1993),Drama,M,25,17,49017
|
||||
1868,3508,3,974694703,"Outlaw Josey Wales, The (1976)",Western,M,50,11,92346
|
||||
2913,1387,5,971769808,Jaws (1975),Action|Horror,F,35,20,98119
|
||||
380,3481,5,976316283,High Fidelity (2000),Comedy,M,25,2,92024
|
||||
2073,1784,5,974759084,As Good As It Gets (1997),Comedy|Drama,F,18,4,13148
|
||||
80,2059,3,977788576,"Parent Trap, The (1998)",Children's|Drama,M,56,1,49327
|
||||
3679,2557,1,976298130,I Stand Alone (Seul contre tous) (1998),Drama,M,25,4,68108
|
||||
2077,788,3,980013556,"Nutty Professor, The (1996)",Comedy|Fantasy|Romance|Sci-Fi,M,18,0,55112
|
||||
6036,2085,4,956716684,101 Dalmatians (1961),Animation|Children's,F,25,15,32603
|
||||
3675,532,3,966363610,Serial Mom (1994),Comedy|Crime|Horror,M,35,7,06680
|
||||
4566,3683,4,964489599,Blood Simple (1984),Drama|Film-Noir,M,35,17,19473
|
||||
2996,3763,3,972413564,F/X (1986),Action|Crime|Thriller,M,18,0,63011
|
||||
5831,2458,1,957898337,Armed and Dangerous (1986),Comedy|Crime,M,25,1,92120
|
||||
1869,1244,2,974695654,Manhattan (1979),Comedy|Drama|Romance,M,45,14,95148
|
||||
5389,2657,3,960328279,"Rocky Horror Picture Show, The (1975)",Comedy|Horror|Musical|Sci-Fi,M,45,7,01905
|
||||
1391,1535,3,974851275,Love! Valour! Compassion! (1997),Drama|Romance,M,35,15,20723
|
||||
3123,2407,3,969324381,Cocoon (1985),Comedy|Sci-Fi,M,25,2,90401
|
||||
4694,159,3,963602574,Clockers (1995),Drama,M,56,7,40505
|
||||
1680,1988,3,974709821,Hello Mary Lou: Prom Night II (1987),Horror,M,25,20,95380
|
||||
2002,1945,4,974677761,On the Waterfront (1954),Crime|Drama,F,56,13,02136-1522
|
||||
3430,2690,4,979949863,"Ideal Husband, An (1999)",Comedy,F,45,1,15208
|
||||
425,471,4,976284972,"Hudsucker Proxy, The (1994)",Comedy|Romance,M,25,12,55303
|
||||
1841,2289,2,974699637,"Player, The (1992)",Comedy|Drama,M,18,0,95037
|
||||
4964,2348,4,962619587,Sid and Nancy (1986),Drama,M,35,0,94110
|
||||
4520,2160,4,964883648,Rosemary's Baby (1968),Horror|Thriller,M,25,4,45810
|
||||
1265,2396,4,1011716691,Shakespeare in Love (1998),Comedy|Romance,F,18,20,49321
|
||||
2496,1278,5,974435324,Young Frankenstein (1974),Comedy|Horror,M,50,1,37932
|
||||
5511,2174,4,959787754,Beetlejuice (1988),Comedy|Fantasy,M,45,1,92407
|
||||
621,833,1,975799925,High School High (1996),Comedy,M,18,4,93560
|
||||
3045,2762,5,970189524,"Sixth Sense, The (1999)",Thriller,M,45,1,90631
|
||||
2050,2546,4,975522689,"Deep End of the Ocean, The (1999)",Drama,F,35,3,99504
|
||||
613,32,4,975812238,Twelve Monkeys (1995),Drama|Sci-Fi,M,35,20,10562
|
||||
366,1077,5,978471241,Sleeper (1973),Comedy|Sci-Fi,M,50,15,55126
|
||||
5108,367,4,962338215,"Mask, The (1994)",Comedy|Crime|Fantasy,F,25,9,93940
|
||||
4502,1960,4,965094644,"Last Emperor, The (1987)",Drama|War,M,50,0,01379
|
||||
5512,1801,5,959713840,"Man in the Iron Mask, The (1998)",Action|Drama|Romance,F,25,17,01701
|
||||
1861,2642,2,974699627,Superman III (1983),Action|Adventure|Sci-Fi,M,50,16,92129
|
||||
1667,1240,4,975016698,"Terminator, The (1984)",Action|Sci-Fi|Thriller,M,50,16,98516
|
||||
753,434,3,975460449,Cliffhanger (1993),Action|Adventure|Crime,M,1,10,42754
|
||||
1836,2736,5,974826228,Brighton Beach Memoirs (1986),Comedy,M,25,0,10016
|
||||
5626,474,5,959052158,In the Line of Fire (1993),Action|Thriller,M,56,16,32043
|
||||
1601,1396,4,978576948,Sneakers (1992),Crime|Drama|Sci-Fi,M,25,12,83001
|
||||
4725,1100,4,963369546,Days of Thunder (1990),Action|Romance,M,35,5,96707-1321
|
||||
2837,2396,5,972571456,Shakespeare in Love (1998),Comedy|Romance,M,18,0,49506
|
||||
1776,3882,4,1001558470,Bring It On (2000),Comedy,M,25,0,45801
|
||||
2820,457,2,972662398,"Fugitive, The (1993)",Action|Thriller,F,35,0,02138
|
||||
1834,2288,3,1038179198,"Thing, The (1982)",Action|Horror|Sci-Fi|Thriller,M,35,5,10990
|
||||
284,2716,4,976570902,Ghostbusters (1984),Comedy|Horror,M,25,12,91910
|
||||
2744,588,1,973215985,Aladdin (1992),Animation|Children's|Comedy|Musical,M,18,17,53818
|
||||
881,4,2,975264028,Waiting to Exhale (1995),Comedy|Drama,M,18,14,76401
|
||||
2211,916,3,974607067,Roman Holiday (1953),Comedy|Romance,M,45,6,01950
|
||||
2271,2671,4,1007158806,Notting Hill (1999),Comedy|Romance,M,50,14,13210
|
||||
1010,2953,1,975222613,Home Alone 2: Lost in New York (1992),Children's|Comedy,M,25,0,10310
|
||||
1589,2594,4,974735454,Open Your Eyes (Abre los ojos) (1997),Drama|Romance|Sci-Fi,M,25,0,95136
|
||||
1724,597,5,976441106,Pretty Woman (1990),Comedy|Romance,M,18,4,00961
|
||||
2590,2097,3,973840056,Something Wicked This Way Comes (1983),Children's|Horror,M,18,4,94044
|
||||
1717,1352,3,1009256707,Albino Alligator (1996),Crime|Thriller,F,50,6,30307
|
||||
1391,3160,2,974850796,Magnolia (1999),Drama,M,35,15,20723
|
||||
1941,1263,3,974954220,"Deer Hunter, The (1978)",Drama|War,M,35,17,94550
|
||||
3526,2867,4,966906064,Fright Night (1985),Comedy|Horror,M,35,2,62263-3004
|
||||
5767,198,3,958192148,Strange Days (1995),Action|Crime|Sci-Fi,M,25,2,75287
|
||||
5355,590,4,960596927,Dances with Wolves (1990),Adventure|Drama|Western,M,56,0,78232
|
||||
5788,156,4,958108785,Blue in the Face (1995),Comedy,M,25,0,92646
|
||||
1078,1307,4,974938851,When Harry Met Sally... (1989),Comedy|Romance,F,45,9,95661
|
||||
3808,61,2,965973222,Eye for an Eye (1996),Drama|Thriller,M,25,7,60010
|
||||
974,3897,4,975106398,Almost Famous (2000),Comedy|Drama,M,35,19,94930
|
||||
5153,1290,4,961972292,Some Kind of Wonderful (1987),Drama|Romance,M,25,7,60046
|
||||
5732,2115,3,958434069,Indiana Jones and the Temple of Doom (1984),Action|Adventure,F,25,11,02111
|
||||
4627,2478,3,964110136,Three Amigos! (1986),Comedy|Western,M,56,1,45224
|
||||
1884,1831,2,975648062,Lost in Space (1998),Action|Sci-Fi|Thriller,M,45,20,93108
|
||||
4284,517,4,965277546,Rising Sun (1993),Action|Drama|Mystery,M,50,7,40601
|
||||
1383,468,2,975979732,"Englishman Who Went Up a Hill, But Came Down a Mountain, The (1995)",Comedy|Romance,F,25,7,19806
|
||||
2230,2873,3,974599097,Lulu on the Bridge (1998),Drama|Mystery|Romance,F,45,1,60302
|
||||
2533,2266,4,974055724,"Butcher's Wife, The (1991)",Comedy|Romance,F,25,3,49423
|
||||
6040,3224,5,956716750,Woman in the Dunes (Suna no onna) (1964),Drama,M,25,6,11106
|
||||
4384,2918,5,965171739,Ferris Bueller's Day Off (1986),Comedy,M,25,0,43623
|
||||
5156,3688,3,961946487,Porky's (1981),Comedy,M,18,14,10024
|
||||
615,296,3,975805801,Pulp Fiction (1994),Crime|Drama,M,50,17,32951
|
||||
2753,3045,3,973198964,Peter's Friends (1992),Comedy|Drama,F,50,20,27516
|
||||
2438,1125,5,974259943,"Return of the Pink Panther, The (1974)",Comedy,M,35,1,22903
|
||||
5746,1242,4,958354460,Glory (1989),Action|Drama|War,M,18,15,94061
|
||||
5157,3462,5,961944604,Modern Times (1936),Comedy,M,35,1,74012
|
||||
3402,1252,5,967433929,Chinatown (1974),Film-Noir|Mystery|Thriller,M,35,20,30306
|
||||
76,593,5,977847255,"Silence of the Lambs, The (1991)",Drama|Thriller,M,35,7,55413
|
||||
2067,1019,3,974658834,"20,000 Leagues Under the Sea (1954)",Adventure|Children's|Fantasy|Sci-Fi,M,50,16,06430
|
||||
2181,2020,3,979353437,Dangerous Liaisons (1988),Drama|Romance,M,25,0,45245
|
||||
3947,593,5,965691680,"Silence of the Lambs, The (1991)",Drama|Thriller,M,25,0,90019
|
||||
546,218,4,976069421,Boys on the Side (1995),Comedy|Drama,F,25,0,37211
|
||||
1246,3030,5,1032056405,Yojimbo (1961),Comedy|Drama|Western,M,18,4,98225
|
||||
4214,3186,5,965319143,"Girl, Interrupted (1999)",Drama,F,25,0,20121
|
||||
2841,680,3,982805796,Alphaville (1965),Sci-Fi,M,50,12,98056
|
||||
4205,3175,4,965321085,Galaxy Quest (1999),Adventure|Comedy|Sci-Fi,F,25,15,87801
|
||||
1120,1097,4,974911354,E.T. the Extra-Terrestrial (1982),Children's|Drama|Fantasy|Sci-Fi,M,18,4,95616
|
||||
5371,3194,3,960481000,"Way We Were, The (1973)",Drama,M,25,11,55408
|
||||
2695,1278,5,973310827,Young Frankenstein (1974),Comedy|Horror,M,35,11,46033
|
||||
3312,520,2,976673070,Robin Hood: Men in Tights (1993),Comedy,F,18,4,90039
|
||||
5039,1792,1,962513044,U.S. Marshalls (1998),Action|Thriller,F,35,4,97068
|
||||
4655,2146,3,963903103,St. Elmo's Fire (1985),Drama|Romance,F,25,1,92037
|
||||
3558,1580,5,966802528,Men in Black (1997),Action|Adventure|Comedy|Sci-Fi,M,18,17,66044
|
||||
506,3354,1,976208080,Mission to Mars (2000),Sci-Fi,M,25,16,55103-1006
|
||||
3568,1230,3,966745594,Annie Hall (1977),Comedy|Romance,M,25,0,98503
|
||||
2943,1197,5,971319983,"Princess Bride, The (1987)",Action|Adventure|Comedy|Romance,M,35,12,95864
|
||||
716,737,3,982881364,Barb Wire (1996),Action|Sci-Fi,M,18,4,98188
|
||||
5964,454,3,956999469,"Firm, The (1993)",Drama|Thriller,M,18,5,97202
|
||||
4802,1208,4,996034747,Apocalypse Now (1979),Drama|War,M,56,1,40601
|
||||
1106,3624,4,974920622,Shanghai Noon (2000),Action,M,18,4,90241
|
||||
3410,2565,3,967419652,"King and I, The (1956)",Musical,M,35,1,20653
|
||||
1273,3095,5,974814536,"Grapes of Wrath, The (1940)",Drama,M,35,2,19123
|
||||
1706,1916,4,974709448,Buffalo 66 (1998),Action|Comedy|Drama,M,25,20,19134
|
||||
4889,590,5,962909224,Dances with Wolves (1990),Adventure|Drama|Western,M,18,4,63108
|
||||
4966,2100,3,962609782,Splash (1984),Comedy|Fantasy|Romance,M,50,14,55407
|
||||
4238,1884,4,965343416,Fear and Loathing in Las Vegas (1998),Comedy|Drama,M,35,16,44691
|
||||
5365,1042,3,960502974,That Thing You Do! (1996),Comedy,M,18,12,90250
|
||||
415,1302,3,977501743,Field of Dreams (1989),Drama,F,35,0,55406
|
||||
4658,1009,5,963966553,Escape to Witch Mountain (1975),Adventure|Children's|Fantasy,M,25,4,99163
|
||||
854,345,3,975357801,"Adventures of Priscilla, Queen of the Desert, The (1994)",Comedy|Drama,F,25,16,44092
|
||||
2857,436,4,972509362,Color of Night (1994),Drama|Thriller,M,25,0,10469
|
||||
1835,1330,4,974878241,April Fool's Day (1986),Comedy|Horror,M,25,19,11501
|
||||
1321,2240,3,974778494,My Bodyguard (1980),Drama,F,25,14,34639
|
||||
3274,3698,2,979767184,"Running Man, The (1987)",Action|Adventure|Sci-Fi,M,25,20,02062
|
||||
5893,2144,3,957470619,Sixteen Candles (1984),Comedy,M,25,7,02139
|
||||
3436,2724,3,967328026,Runaway Bride (1999),Comedy|Romance,M,35,0,98503
|
||||
3315,2918,5,967942960,Ferris Bueller's Day Off (1986),Comedy,M,25,12,78731
|
||||
5056,2700,5,962488280,"South Park: Bigger, Longer and Uncut (1999)",Animation|Comedy,M,45,1,16673
|
||||
5256,208,2,961271616,Waterworld (1995),Action|Adventure,M,25,16,30269
|
||||
4290,1193,4,965274348,One Flew Over the Cuckoo's Nest (1975),Drama,M,25,17,98661
|
||||
1010,1379,2,975220259,Young Guns II (1990),Action|Comedy|Western,M,25,0,10310
|
||||
829,904,4,975368038,Rear Window (1954),Mystery|Thriller,M,1,19,53711
|
||||
5953,480,4,957143581,Jurassic Park (1993),Action|Adventure|Sci-Fi,M,1,10,21030
|
||||
4732,3016,4,963332896,Creepshow (1982),Horror,M,25,14,24450
|
||||
4815,3181,5,972240802,Titus (1999),Drama,F,50,18,04849
|
||||
1164,1894,2,1004486985,Six Days Seven Nights (1998),Adventure|Comedy|Romance,F,25,19,90020
|
||||
4373,3167,5,965180829,Carnal Knowledge (1971),Drama,M,50,12,32920
|
||||
5293,1374,4,961055887,Star Trek: The Wrath of Khan (1982),Action|Adventure|Sci-Fi,M,25,12,95030
|
||||
1579,3101,4,981272057,Fatal Attraction (1987),Thriller,M,25,0,60201
|
||||
2600,3147,5,973804787,"Green Mile, The (1999)",Drama|Thriller,M,25,14,19312
|
||||
1283,480,4,974793389,Jurassic Park (1993),Action|Adventure|Sci-Fi,F,18,1,94607
|
||||
3242,3062,5,968341175,"Longest Day, The (1962)",Action|Drama|War,M,50,13,94089
|
||||
3618,3374,3,967116272,Daughters of the Dust (1992),Drama,M,56,17,22657
|
||||
3762,1337,4,966434517,"Body Snatcher, The (1945)",Horror,M,50,6,11746
|
||||
1015,1184,3,975018699,Mediterraneo (1991),Comedy|War,M,35,3,11220
|
||||
4645,2344,5,963976808,Runaway Train (1985),Action|Adventure|Drama|Thriller,F,50,6,48094
|
||||
3184,1397,4,968709039,Bastard Out of Carolina (1996),Drama,F,25,18,21214
|
||||
1285,1794,4,974833328,Love and Death on Long Island (1997),Comedy|Drama,M,35,4,98125
|
||||
5521,3354,2,959833154,Mission to Mars (2000),Sci-Fi,F,25,6,02118
|
||||
1472,2278,3,974767792,Ronin (1998),Action|Crime|Thriller,M,25,7,90248
|
||||
5630,21,4,980085414,Get Shorty (1995),Action|Comedy|Drama,M,35,17,06854
|
||||
3710,3033,5,966272980,Spaceballs (1987),Comedy|Sci-Fi,M,1,10,02818
|
||||
192,761,1,977028390,"Phantom, The (1996)",Adventure,M,18,1,10977
|
||||
1285,1198,5,974880310,Raiders of the Lost Ark (1981),Action|Adventure,M,35,4,98125
|
||||
2174,1046,4,974613044,Beautiful Thing (1996),Drama|Romance,M,50,12,87505
|
||||
635,1270,4,975768106,Back to the Future (1985),Comedy|Sci-Fi,M,56,17,33785
|
||||
910,412,5,975207742,"Age of Innocence, The (1993)",Drama,F,50,0,98226
|
||||
1752,2021,4,975729332,Dune (1984),Fantasy|Sci-Fi,M,25,3,96813
|
||||
1408,198,4,974762924,Strange Days (1995),Action|Crime|Sci-Fi,M,25,0,90046
|
||||
4738,1242,4,963279051,Glory (1989),Action|Drama|War,M,56,1,23608
|
||||
1503,1971,2,974748897,"Nightmare on Elm Street 4: The Dream Master, A (1988)",Horror,M,25,12,92688
|
||||
3053,1296,3,970601837,"Room with a View, A (1986)",Drama|Romance,F,25,3,55102
|
||||
3471,3614,2,973297828,Honeymoon in Vegas (1992),Comedy|Romance,M,18,4,80302
|
||||
678,1972,3,988638700,"Nightmare on Elm Street 5: The Dream Child, A (1989)",Horror,M,25,0,34952
|
||||
3483,2561,3,986327282,True Crime (1999),Crime|Thriller,F,45,7,30260
|
||||
3910,3108,5,965756244,"Fisher King, The (1991)",Comedy|Drama|Romance,M,25,20,91505
|
||||
182,1089,1,977085647,Reservoir Dogs (1992),Crime|Thriller,M,18,4,03052
|
||||
1755,1653,3,1036917836,Gattaca (1997),Drama|Sci-Fi|Thriller,F,18,4,77005
|
||||
3589,70,2,966658567,From Dusk Till Dawn (1996),Action|Comedy|Crime|Horror|Thriller,F,45,0,80010
|
||||
471,3481,4,976222483,High Fidelity (2000),Comedy,M,35,7,08904
|
||||
1141,813,2,974878678,Larger Than Life (1996),Comedy,F,25,3,84770
|
||||
5227,1196,2,961476022,Star Wars: Episode V - The Empire Strikes Back (1980),Action|Adventure|Drama|Sci-Fi|War,M,18,10,64050
|
||||
1303,2344,2,974837844,Runaway Train (1985),Action|Adventure|Drama|Thriller,M,25,19,94111
|
||||
5080,3102,5,962412804,Jagged Edge (1985),Thriller,F,50,12,95472
|
||||
2023,1012,4,1006290836,Old Yeller (1957),Children's|Drama,M,18,4,56001
|
||||
3759,2151,5,966094413,"Gods Must Be Crazy II, The (1989)",Comedy,M,35,6,54751
|
||||
1685,2664,2,974709721,Invasion of the Body Snatchers (1956),Horror|Sci-Fi,M,35,12,95833
|
||||
4715,1221,4,963508830,"Godfather: Part II, The (1974)",Action|Crime|Drama,M,25,2,97205
|
||||
1591,350,5,974742941,"Client, The (1994)",Drama|Mystery|Thriller,M,50,7,26501
|
||||
4227,3635,3,965411938,"Spy Who Loved Me, The (1977)",Action,M,25,19,11414-2520
|
||||
1908,36,5,974697744,Dead Man Walking (1995),Drama,M,56,13,95129
|
||||
5365,1892,4,960503255,"Perfect Murder, A (1998)",Mystery|Thriller,M,18,12,90250
|
||||
1579,2420,4,981272235,"Karate Kid, The (1984)",Drama,M,25,0,60201
|
||||
1866,3948,5,974753321,Meet the Parents (2000),Comedy,M,25,7,94043
|
||||
4238,3543,4,965415533,Diner (1982),Comedy|Drama,M,35,16,44691
|
||||
3590,2000,5,966657892,Lethal Weapon (1987),Action|Comedy|Crime|Drama,F,18,15,02115
|
||||
3401,3256,5,980115327,Patriot Games (1992),Action|Thriller,M,35,7,76109
|
||||
3705,540,2,966287116,Sliver (1993),Thriller,M,45,7,30076
|
||||
4973,1246,3,962607149,Dead Poets Society (1989),Drama,F,56,2,949702
|
||||
4947,380,4,962651180,True Lies (1994),Action|Adventure|Comedy|Romance,M,35,17,90035
|
||||
2346,1416,4,974413811,Evita (1996),Drama|Musical,F,1,10,48105
|
||||
1427,3596,3,974840560,Screwed (2000),Comedy,M,25,12,21401
|
||||
3868,1626,3,965855033,Fire Down Below (1997),Action|Drama|Thriller,M,18,12,73112
|
||||
249,2369,3,976730191,Desperately Seeking Susan (1985),Comedy|Romance,F,18,14,48126
|
||||
5720,349,4,958503395,Clear and Present Danger (1994),Action|Adventure|Thriller,M,25,0,60610
|
||||
877,1485,3,975270899,Liar Liar (1997),Comedy,M,25,0,90631
|
||||
BIN
DeepRecommendationModel/代码/imgs/AFM.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 69 KiB |
BIN
DeepRecommendationModel/代码/imgs/DCN.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 101 KiB |
BIN
DeepRecommendationModel/代码/imgs/DIEN.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 270 KiB |
BIN
DeepRecommendationModel/代码/imgs/DIN.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 76 KiB |
BIN
DeepRecommendationModel/代码/imgs/DeepCrossing.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 71 KiB |
BIN
DeepRecommendationModel/代码/imgs/DeepFM.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 139 KiB |
BIN
DeepRecommendationModel/代码/imgs/NCF.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 74 KiB |
BIN
DeepRecommendationModel/代码/imgs/NFM.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 114 KiB |
BIN
DeepRecommendationModel/代码/imgs/PNN.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 36 KiB |
BIN
DeepRecommendationModel/代码/imgs/Wide&Deep.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 122 KiB |
6
DeepRecommendationModel/代码/utils.py
Normal file
@@ -0,0 +1,6 @@
|
||||
from collections import namedtuple
|
||||
|
||||
# 使用具名元组定义特征标记
|
||||
SparseFeat = namedtuple('SparseFeat', ['name', 'vocabulary_size', 'embedding_dim'])
|
||||
DenseFeat = namedtuple('DenseFeat', ['name', 'dimension'])
|
||||
VarLenSparseFeat = namedtuple('VarLenSparseFeat', ['name', 'vocabulary_size', 'embedding_dim', 'maxlen'])
|
||||
242
DeepRecommendationModel/深度学习推荐系统模型搭建基础.md
Normal file
@@ -0,0 +1,242 @@
|
||||
# 深度学习推荐系统模型搭建基础
|
||||
|
||||
## 编程基础(Keras函数式API编程)
|
||||
|
||||
本项目中所有代码都通过Tensorflow2.x实现,所以熟悉Tensorflow的基础操作,以及tf2中keras的使用(与早期的keras的使用基本上是一致的),对于TF及keras的基础这里不做太多的介绍,大家可以参考相关的资料进行学习。这里主要说一下keras函数式编程的基本用法。
|
||||
|
||||
keras搭建模型主要有两种模式,一种是Sequential API,另外一种是Functional API。前者主要是通过层的有序堆叠形成一个模型,在大多数情况下可以快速的搭建一个模型,但是搭建的模型更适合简单的堆叠模型,对于复杂模型(多输入、多输出、共享层)的搭建就比较困难,所以后者函数式API可以更加灵活的搭建复杂网络,函数式API搭建模型是通过创建层的实例并将将层与层之间连接在一起,最后只需要指定模型的输入和输出就可以完成模型的搭建,不同层的实例可以表示不同的操作,搭建模型的时候只需要考虑层与层之间的关系,以及复杂层的搭建就可以很方便的搭建起一个复杂网络。
|
||||
|
||||
**回顾Sequential API搭建模型:**
|
||||
|
||||
```python
|
||||
import tensorflow as tf
|
||||
from tensorflow import keras
|
||||
from tensorflow.keras import layers
|
||||
|
||||
# 定义一个3层的序列模型
|
||||
model = keras.Sequential(
|
||||
[
|
||||
layers.Dense(2, activation="relu", name="layer1"),
|
||||
layers.Dense(3, activation="relu", name="layer2"),
|
||||
layers.Dense(4, name="layer3"),
|
||||
]
|
||||
)
|
||||
|
||||
# 与上述的搭建的模型效果是一致的
|
||||
# model = keras.Sequential(name="my_sequential")
|
||||
# model.add(layers.Dense(2, activation="relu", name="layer1"))
|
||||
# model.add(layers.Dense(3, activation="relu", name="layer2"))
|
||||
# model.add(layers.Dense(4, name="layer3"))
|
||||
|
||||
# 定义数据
|
||||
x = tf.random.normal((3, 4))
|
||||
y = model(x)
|
||||
```
|
||||
|
||||
|
||||
|
||||
可以看到上述搭建网络直接使用keras中的层直接堆叠即可,但是函数式API与其不太一样,首先需要定义模型的输入层Input(), 并在Input层中指定输入的数据的维度 ,如下定义一个输入层,输入数据的维度是784, 不需要考虑数据的Batch size维度,定义的输入层可以认为是数据在模型所表示的层,接下来就是要将数据进行相应的转换,也就是将输入层输入到下一个层中,将数据进行转换,
|
||||
|
||||
```python
|
||||
# 定义输入层(可以看成数据层)
|
||||
inputs = keras.Input(shape=(784,))
|
||||
|
||||
# 定义模型逻辑层(将输入数据进行转换)
|
||||
x = layers.Dense(64, activation="relu")(inputs)
|
||||
|
||||
# 注意:
|
||||
# layers.Dense(64, activation="relu")表示的是一个Dense层实例,括号中的参数就是创建Dense实例的参数,将inputs输入到layers.Dense(64, activation="relu")实例中,会自动的调用实例的__call__()方法,这样就把输入和层与层之间的逻辑给确定了
|
||||
|
||||
# 所以函数API搭建模型的基本操作就是,将输入数据输入到层的实例中,层对象就会调用该层的call方法完成该层的计算并产生新的输出,接下来再将产生的新的输出输入到下一个层实例中产生新的输出,一直不断的构建层的实例并得到新的输出,进而构建一个复杂的模型。
|
||||
|
||||
# 定义输出层,这里其实和其他的层没有区别,只不过是最后认定这一层作为输出层而已
|
||||
outputs = layers.Dense(10)(x)
|
||||
|
||||
# 定义整个模型,通过制定模型的输入和输出,按照前面所说的构建模型的流程,产生最终的模型结构
|
||||
model = Model(inputs=inputs,outputs=outputs)
|
||||
```
|
||||
|
||||
|
||||
|
||||
上面简单的说明了通过函数式API构建模型的流程,下面再了解一下如何使用函数式API的方式构建多输入、多输出及共享层的模型:
|
||||
|
||||
例如,如果您正在构建一个按优先级排列客户问题通知单并将其发送到正确部门的系统,那么该模型将有三个输入:
|
||||
|
||||
1. 票证的标题(文本输入)
|
||||
|
||||
2. 票证的文本正文(文本输入)
|
||||
|
||||
3. 用户添加的任何标记(分类输入)
|
||||
|
||||
该模型将有两个输出:
|
||||
|
||||
1. 优先级得分介于0和1之间(标量sigmoid输出),以及
|
||||
|
||||
2. 应处理票证的部门(部门集合上的softmax输出)。
|
||||
|
||||
```python
|
||||
num_tags = 12 # 标记数量
|
||||
num_words = 10000 # 文本的字典大小
|
||||
num_departments = 4 # 部门数量
|
||||
|
||||
# 定义可变长的序列,表示标题
|
||||
title_input = keras.Input(shape=(None,), name="title")
|
||||
# 定义可变长的序列,表示文本正文
|
||||
body_input = keras.Input(shape=(None,), name="body")
|
||||
# 定义tag的输入,是一个onehot编码向量
|
||||
tags_input = keras.Input(shape=(num_tags,), name="tags")
|
||||
|
||||
# 定义共享层
|
||||
shared_embedding_layer = layers.Embedding(num_words, 64, name='shared_embedding_layer')
|
||||
# 将输入的标题中的每个次转换成64维的向量
|
||||
title_features = shared_embedding_layer(title_input)
|
||||
# 将输入的正文中的每个词转换成64维的向量
|
||||
body_features = shared_embedding_layer(body_input)
|
||||
|
||||
# # 将输入的标题中的每个次转换成64维的向量
|
||||
# title_features = layers.Embedding(num_words, 64)(title_input)
|
||||
# # 将输入的正文中的每个词转换成64维的向量
|
||||
# body_features = layers.Embedding(num_words, 64)(body_input)
|
||||
|
||||
# 使用LSTM将标题序列转换成一个128维的向量
|
||||
title_features = layers.LSTM(128)(title_features)
|
||||
# 使用LSTM将正文序列转换成一个32维的向量
|
||||
body_features = layers.LSTM(32)(body_features)
|
||||
|
||||
# 将多个特征进行拼接
|
||||
x = layers.concatenate([title_features, body_features, tags_input])
|
||||
|
||||
# 将拼接后的特征转换成输出后的单值表示优先级
|
||||
priority_pred = layers.Dense(1, name="priority")(x)
|
||||
|
||||
# 将拼接后的特征转换成一个向量,表示每个部门的概率(这里不是严格的概率,因为没有softmax),
|
||||
department_pred = layers.Dense(num_departments, name="department")(x)
|
||||
|
||||
# 构建多输入,多输出模型
|
||||
model = keras.Model(
|
||||
inputs=[title_input, body_input, tags_input],
|
||||
outputs=[priority_pred, department_pred],
|
||||
)
|
||||
|
||||
# 画模型结构图
|
||||
keras.utils.plot_model(model, "multi_input_and_output_model.png", show_shapes=True)
|
||||
```
|
||||
|
||||

|
||||
|
||||
从上面这个图就可以看出,模型多输入,多输出,共享层的结构,并且也会发现搭建的过程也是非常的简单。
|
||||
|
||||
上面的代码参考的是[Keras官网案例](https://keras.io/guides/functional_api/#shared-layers),在原始案例的基础上加上了共享层,省的重新再去写一个案例
|
||||
|
||||
|
||||
|
||||
==当特征比较多的时候如何构建多输入模型呢?==
|
||||
|
||||
先说答案:将输入的数据转换成字典的形式,定义输入层的时候让输入层的name和字典中特征的key一致,就可以使得输入的数据和对应的Input层对应,后面搭建模型就是和上面介绍的一样的了。
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210226175546548.png" alt="image-20210226175546548" style="zoom: 50%;" />
|
||||
|
||||
直接看个例子吧:
|
||||
|
||||
```python
|
||||
from keras.models import Model
|
||||
from keras.layers import *
|
||||
from keras.utils import plot_model
|
||||
import numpy as np
|
||||
|
||||
# 定义三维特征
|
||||
x = {'f1': np.random.random((5,1)),
|
||||
'f2': np.random.random((5,1)),
|
||||
'f3': np.random.random((5,1))}
|
||||
|
||||
y = np.array([0, 1, 0, 1, 1])
|
||||
|
||||
# 定义输入层:这里层的名称和特征的名称是相同的,所以在模型训练的时候直接输入这个
|
||||
# 字典形式的数据就可以
|
||||
inputs = [Input(shape=(1, ), name=key) for key, _ in x.items()]
|
||||
|
||||
# 将多个输入拼接之后,在经过一个Dense层输出
|
||||
concat_feat = Concatenate(axis=1)(inputs)
|
||||
|
||||
# 将输入特征映射成1维
|
||||
output = Dense(1, activation='sigmoid')(concat_feat)
|
||||
|
||||
# 构建模型
|
||||
model = Model(inputs, output)
|
||||
|
||||
model.summary()
|
||||
|
||||
# 编译模型
|
||||
model.compile(optimizer='adam', loss='binary_crossentropy', metrics='acc')
|
||||
|
||||
# 模型训练和验证
|
||||
model.fit(x, y, batch_size=1, epochs=2, validation_split=0.2)
|
||||
|
||||
# 将模型的结构画出来
|
||||
keras.utils.plot_model(model, "multi_input_and_output_model.png", show_shapes=True)
|
||||
```
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210226181357167.png" alt="image-20210226181357167" />
|
||||
|
||||
上面就是举了个简单的例子说明,当多输入特别多的时候,构建模型我们可以将数据转换成字典的形式,然后字典中特征的名称与其对应的Input层的名称一致就行,这里是为了后面搭建复杂模型打基础。
|
||||
|
||||
## 统一视角看推荐模型
|
||||
|
||||
相信大家对DeepCTR开源项目应该是有点了解,DeepCTR通过对现有的基于深度学习的点击率预测模型的结构进行抽象总结,在设计过程中采用模块化的思路,各个模块自身具有高复用性,各个模块之间互相独立。 基于深度学习的点击率预测模型按模型内部组件的功能可以划分成以下4个模块:输入模块,嵌入模块,特征提取模块,预测输出模块。关于DeepCTR的介绍可以参考这个文章[DeepCTR:易用可扩展的深度学习点击率预测算法包](https://zhuanlan.zhihu.com/p/53231955)
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210221193056946.png" alt="image-20210221193056946" style="zoom:50%;" />
|
||||
|
||||
这个开源项目做的非常好反而不是特别适合初学者学习,但是又非常适合推荐系统领域的小白去学习,所以本次内容设计我们借鉴了DeepCTR的设计思想,复现课程中的代码,复现的代码中包含了大量的注释,使得学习者在了解了上述所说的函数式API构建模型的基础上,快速看懂源码的设计,以及模型的原理。下面主要说一下我们代码参考DeepCTR项目实现需要注意的几个点。
|
||||
|
||||
|
||||
|
||||
==特征表示的统一==
|
||||
|
||||
看过DeepCTR源码的人可能就会知道,项目中输入分成三大类,分别是SparseFeat, DenseFeat, VarLenSparseFeat,并且使用类进行了封装,其中也考虑到效率的问题做了一些优化,这里不说具体的类的实现及优化是什么,我先来思考一下使用这三类特征可以表示大多数推荐场景下的特征嘛?
|
||||
|
||||
- SparseFeat: 稀疏特征的标记,一般是用来表示id类特征
|
||||
|
||||
- DenseFeat: 表示数值型特征,可以是一维的也可以是多维的
|
||||
|
||||
- VarLenSparseFeat: 可变长的id类特征,就是id序列特征
|
||||
|
||||
这三类特征在实际的推荐系统应用中包含了绝大多数的特征类型,在石塔西大佬的[推荐算法的"五环之歌"](https://zhuanlan.zhihu.com/p/336643635)中也说到,类别特征才是推荐系统中的一等公民,也就是说大部分的特征都是类别特征,也可能会有一些其他的比如图像、视频等其它特征,虽然实际存不存在,但是我感觉如果要是用这些特征就需要将其转换成向量的形式去使用,也就是DenseFeat多维度的情况。
|
||||
|
||||
那么有了这三个统一的标志有什么用呢?答案是用来更好的构建输入层!
|
||||
|
||||
|
||||
|
||||
==通过特征标记构造输入层==
|
||||
|
||||
在前面的函数式API构建模型最后说到过,可以使用字典的形式构建输入,最后只要将对应Input层的名字与字典中特征的key相对应就可以。在定义Input层的时候,除了name以外还有一个重要的属性就是shape
|
||||
|
||||
然而所有特征Input层的shape其实只有4种情况:
|
||||
|
||||
1. 数值特征,1维的数值特征shape=(1, )
|
||||
2. 多维的数值特征shape=(dimension, )
|
||||
3. 类别特征,shape=(1,), 为什么类别特征的shape维度是1呢,因为输入的就是一个id,在类别型特征的Input后面还需要接一个Embedding层,将id转化成稠密的向量
|
||||
4. 可变长的序列特征,shape=(maxlen, 1), 序列的输入往往需要定义一个最大长度,这样不至于序列长度之间相差太大,这个最大长度可以是实际数据中的最大长度,也可以是根据经验定义的最大长度。需要注意的是,序列特征中的每个元素其实也是一个id类特征,在最后转换成Embedding的时候,不是一个Embedding向量,而是一个矩阵。
|
||||
|
||||
**上面说了Input层的四种情况有什么用呢?**
|
||||
|
||||
当特征维度特别多的时候,比如成百上千维特征,如果没有这种标记的话,我们就需要挨个定义每个特征对应的Input层,当然有人可能会说可以提前分组然后再给不同的Input层,其实本质上是一样的。
|
||||
|
||||
|
||||
|
||||
==Embedding层的注意点==
|
||||
|
||||
在构建模型的时候Embedding相关的需要注意两点:
|
||||
|
||||
1. Embedding层的参数问题
|
||||
2. Embedding层之间的拼接问题
|
||||
|
||||
上面在说了类别特征和可变长的序列特征,在这两个Input层之后都需要将其转化成Embedding向量或者Embedding矩阵,在keras中转化成Embedding向量和Embedding矩阵只是相差一个参数的问题
|
||||
|
||||
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/图片image-20210226191552184.png" alt="image-20210226191552184" style="zoom:67%;" />
|
||||
|
||||
|
||||
|
||||
==如何在linear层引入onehot特征==
|
||||
|
||||
如果要将类别型特征的onehot表示输入到linear层中,第一个想法就是直接把特征转换成onehot向量不就行了吗?的确是可以,但是我们知道在推荐场景中id类特征是一等公民,在实际的场景中如果将所有的特征都转换成onehot类型,维度很可能超出想象。这里有个更好的做法就是,给id类特征转换成一个一维的Embedding矩阵,只需要将这个Embedding保存下来,然后有id类特征输入直接在Embedding中进行查找,找到那个对应的值其实就是onehot向量已经乘完权重的值,因为onehot向量只有0和1,只有非零的才是有效的,而1乘以权重还是权重本身,所以这种方式来获取onehot向量中的非零元素的值,相比直接使用onehot向量乘以一个权重更好一些。
|
||||
|
||||
73
readme.md
@@ -1,21 +1,17 @@
|
||||
## 动手学习推荐系统 (Dive-into-RS)
|
||||
# FunRec
|
||||
|
||||
本项目《动手学习推荐系统》是Datawhale推荐系统小组近期推动的一个重点项目,受李沐老师的[《动手学深度学习》](https://zh.d2l.ai/)及Datawhale CV小组发起的[《动手学CV-Pytorch版》](https://github.com/datawhalechina/dive-into-cv-pytorch),我们旨在构建一个动手学推荐系统的项目,项目中的每个小节的内容都会详细的代码实现,帮助学习入门推荐系统的人可以更加直观的理解算法和模型。
|
||||
|
||||
|
||||
|
||||
**内容设计上主要分为三个阶段,分别是推荐系统基础、推荐系统进阶和推荐系统应用。**
|
||||
FunRec推荐系统项目主要分为三个阶段,分别是推荐系统基础、推荐系统进阶和推荐系统应用,每个阶段的具体内容如下:
|
||||
|
||||
- 推荐系统基础,这部分内容旨在让初学者了解推荐系统是什么,有哪些经典的推荐算法以及经典算法的实现,这一部分也是推荐系统非常核心的部分。对于基础部分,已经完成了基础推荐算法,接下来是完成深度学习推荐相关的算法模型。
|
||||
- 推荐系统进阶,这部分内容是在了解了推荐系统基础之后,在架构层面去了解推荐系统如何实现的,这里的内容会参考王喆老师的[《深度学习推荐系统》](https://book.douban.com/subject/35013197/)这本书及[SparrowRecSys](https://github.com/wzhe06/SparrowRecSys)开源项目,搭建一个完整的推荐系统框架。目前打算是基于最新的MIND数据集搭建一个新闻推荐的项目,在进阶部分除了推荐系统框架以外还有一个关于竞赛的实践内容,这部分内容是一个比较完整的推荐系竞赛入门的教程,将推荐系统中的召回和排序连在一起可以作为进阶部门的基础。
|
||||
- 推荐系统应用,这一部分是基于基础和进阶之上,在推荐系统细分领域上做的内容,例如信息流推荐、视频推荐、音乐推荐等。这一部分需要一些对这些细分领域比较熟悉的人来协助共同完成,如果对这部分内容的贡献感兴趣的可以联系我们,一起来完善这个项目。
|
||||
|
||||
|
||||
项目在Datawhale的组队学习过程中不断的迭代和优化,通过大家的反馈来修正或者补充相关的内容,如果项目对项目内容设计有更好的意见欢迎给我们反馈。
|
||||
|
||||
## 内容目录
|
||||
|
||||
- [第一章 推荐系统基础](https://github.com/datawhalechina/team-learning-rs/tree/master/RecommendationSystemFundamentals)
|
||||
|
||||
|
||||
- 1.1 基础推荐算法
|
||||
- [x] [1.1.1 推荐系统概述](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommendationSystemFundamentals/01%20%E6%A6%82%E8%BF%B0.md)
|
||||
- [x] [1.1.2 协同过滤](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommendationSystemFundamentals/02%20%E5%8D%8F%E5%90%8C%E8%BF%87%E6%BB%A4.md)
|
||||
@@ -23,43 +19,44 @@
|
||||
- [x] [1.1.4 FM](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommendationSystemFundamentals/04%20FM.md)
|
||||
- [x] [1.1.5 GBDT+LR](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommendationSystemFundamentals/06%20GBDT%2BLR.md)
|
||||
- 1.2 基于深度组合的深度推荐算法
|
||||
- [ ] 1.2.1 NeuralCF
|
||||
- [ ] 1.2.2 Deep Crossing
|
||||
- [ ] 1.2.3 PNN
|
||||
- [x] 深度学习模型搭建基础
|
||||
- [x] 1.2.1 NeuralCF
|
||||
- [x] 1.2.2 Deep Crossing
|
||||
- [x] 1.2.3 PNN
|
||||
- [x] [1.2.3 Wide&Deep](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommendationSystemFundamentals/05%20Wide%26Deep.md)
|
||||
- [ ] 1.2.4 DeepFM
|
||||
- [ ] 1.2.5 Deep&Cross
|
||||
- [ ] 1.2.6 NFM
|
||||
- [x] 1.2.4 DeepFM
|
||||
- [x] 1.2.5 Deep&Cross
|
||||
- [x] 1.2.6 NFM
|
||||
- 1.3 深度推荐算法前沿
|
||||
- [ ] 1.3.1 AFM
|
||||
- [ ] 1.3.2 DIN
|
||||
- [ ] 1.3.3 DIEN
|
||||
- [ ] 1.3.4 DRN
|
||||
- [x] 1.3.1 AFM
|
||||
- [x] 1.3.2 DIN
|
||||
- [x] 1.3.3 DIEN
|
||||
- [ ] ...
|
||||
|
||||
|
||||
- 第二章 推荐系统进阶
|
||||
|
||||
- 2.1 推荐系统架构
|
||||
- 2.1 [竞赛实践(天池入门赛-新闻推荐)](https://github.com/datawhalechina/team-learning-rs/tree/master/RecommandNews)
|
||||
|
||||
- [ ] 2.1.1 基础架构
|
||||
- [ ] 2.1.2 数据处理
|
||||
- [ ] 2.1.3 特征工程
|
||||
- [ ] 2.1.4 多路召回
|
||||
- [ ] 2.1.5 排序模型
|
||||
- [ ] 2.1.6 模型评估
|
||||
- [ ] 2.1.7 线上服务
|
||||
- 2.2 [竞赛实践(天池入门赛-新闻推荐)](https://github.com/datawhalechina/team-learning-rs/tree/master/RecommandNews)
|
||||
|
||||
- [x] [2.2.1 赛题理解](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E8%B5%9B%E9%A2%98%E7%90%86%E8%A7%A3%2BBaseline.ipynb)
|
||||
- [x] [2.2.2 Baseline](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E8%B5%9B%E9%A2%98%E7%90%86%E8%A7%A3%2BBaseline.ipynb)
|
||||
- [x] [2.2.3 数据分析](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90.ipynb)
|
||||
- [x] [2.2.4 多路召回](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E5%A4%9A%E8%B7%AF%E5%8F%AC%E5%9B%9E.ipynb)
|
||||
- [x] [2.2.5 特征工程](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E7%89%B9%E5%BE%81%E5%B7%A5%E7%A8%8B.ipynb)
|
||||
- [x] [2.2.6 排序模型](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E6%8E%92%E5%BA%8F%E6%A8%A1%E5%9E%8B%2B%E6%A8%A1%E5%9E%8B%E8%9E%8D%E5%90%88.ipynb)
|
||||
- [x] [2.2.7 模型集成](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E6%8E%92%E5%BA%8F%E6%A8%A1%E5%9E%8B%2B%E6%A8%A1%E5%9E%8B%E8%9E%8D%E5%90%88.ipynb)
|
||||
- [x] [2.1.1 赛题理解](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E8%B5%9B%E9%A2%98%E7%90%86%E8%A7%A3%2BBaseline.ipynb)
|
||||
- [x] [2.1.2 Baseline](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E8%B5%9B%E9%A2%98%E7%90%86%E8%A7%A3%2BBaseline.ipynb)
|
||||
- [x] [2.1.3 数据分析](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90.ipynb)
|
||||
- [x] [2.1.4 多路召回](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E5%A4%9A%E8%B7%AF%E5%8F%AC%E5%9B%9E.ipynb)
|
||||
- [x] [2.1.5 特征工程](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E7%89%B9%E5%BE%81%E5%B7%A5%E7%A8%8B.ipynb)
|
||||
- [x] [2.1.6 排序模型](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E6%8E%92%E5%BA%8F%E6%A8%A1%E5%9E%8B%2B%E6%A8%A1%E5%9E%8B%E8%9E%8D%E5%90%88.ipynb)
|
||||
- [x] [2.1.7 模型集成](https://github.com/datawhalechina/team-learning-rs/blob/master/RecommandNews/%E6%8E%92%E5%BA%8F%E6%A8%A1%E5%9E%8B%2B%E6%A8%A1%E5%9E%8B%E8%9E%8D%E5%90%88.ipynb)
|
||||
- 2. 2推荐系统架构
|
||||
|
||||
- [ ] 2.2.1 基础架构
|
||||
- [ ] 2.2.2 数据处理
|
||||
- [ ] 2.2.3 特征工程
|
||||
- [ ] 2.2.4 多路召回
|
||||
- [ ] 2.2.5 排序模型
|
||||
- [ ] 2.2.6 模型评估
|
||||
- [ ] 2.2.7 线上服务
|
||||
- 2.3 新闻推荐架构实践
|
||||
|
||||
- [ ] 计划中...
|
||||
|
||||
|
||||
- 第三章 推荐系统应用
|
||||
|
||||
- [ ] 信息流推荐
|
||||
@@ -75,8 +72,6 @@
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 致谢(贡献者)
|
||||
|
||||
### 内容设计
|
||||
|
||||