diff --git a/docs/_sidebar.md b/docs/_sidebar.md
index e283b165..d5592305 100644
--- a/docs/_sidebar.md
+++ b/docs/_sidebar.md
@@ -1,6 +1,6 @@
-- [目录](README.md)
+- [目录](README)
- [第一章 推荐系统概述]()
- [1.1 推荐系统的意义](ch01/1.1)
- [1.2 推荐系统架构](ch01/1.2)
@@ -10,7 +10,7 @@
- [2.1.1 基于协同过滤的召回]()
- [UserCF]()
- [ItemCF]()
- - [Swing(Graph-based)](/推荐算法基础/经典召回模型/基于协同过滤的召回/Swing(Graph-based))
+ - [Swing(Graph-based)](ch02/ch2.2/ch2.2.1/Swing)
- [矩阵分解系列(ALS,SVD++)]()
- [2.1.2 基于向量的召回]()
- [FM召回]()
@@ -23,32 +23,32 @@
- [Youtube双塔]()
- [MOBIUS]()
- [2.1.3 基于图的召回]()
- - [EGES](/推荐算法基础/经典召回模型/基于图的召回/EGES)
+ - [EGES](ch02/ch2.1/ch2.1.3/EGES)
- [PinSAGE]()
- [2.1.4 基于序列的召回]()
- - [MIND](/推荐算法基础/经典召回模型/基于序列的召回/MIND模型)
- - [SDM](/推荐算法基础/经典召回模型/基于序列的召回/SDM模型)
+ - [MIND](ch02/ch2.1/ch2.1.4/MIND)
+ - [SDM](ch02/ch2.1/ch2.1.4/SDM)
- [2.1.5 基于树模型的召回]()
- [TDM]()
- [2.2 经典排序模型]()
- - [2.2.1 GBDT+LR](/推荐算法基础/经典排序模型/GBDT+LR)
+ - [2.2.1 GBDT+LR](ch02/ch2.2/ch2.2.1)
- [2.2.2 特征交叉]()
- - [FM](/推荐算法基础/经典排序模型/特征交叉/FM)
- - [PNN](/推荐算法基础/经典排序模型/特征交叉/PNN)
- - [DCN](/推荐算法基础/经典排序模型/特征交叉/DCN)
+ - [FM](ch02/ch2.2/ch2.2.2/FM)
+ - [PNN](ch02/ch2.2/ch2.2.2/PNN)
+ - [DCN](ch02/ch2.2/ch2.2.2/DCN)
- [AutoInt]()
- [FiBiNet]()
- [2.2.3 Wide&Deep系列]()
- - [Wide&Deep](/推荐算法基础/经典排序模型/Wide&Deep系列/Wide&Deep)
+ - [Wide&Deep](ch02/ch2.2/ch2.2.3/WideNDeep)
- [改进Deep侧]()
- - [NFM](/推荐算法基础/经典排序模型/Wide&Deep系列/NFM)
- - [AFM](/推荐算法基础/经典排序模型/Wide&Deep系列/AFM)
+ - [NFM](ch02/ch2.2/ch2.2.3/NFM.md)
+ - [AFM](ch02/ch2.2/ch2.2.3/AFM)
- [改进Wide侧]()
- - [DeepFM](/推荐算法基础/经典排序模型/Wide&Deep系列/DeepFM)
+ - [DeepFM](ch02/ch2.2/ch2.2.3/DeepFM)
- [xDeepFM]()
- [2.2.4 序列模型]()
- - [DIN](/推荐算法基础/经典排序模型/序列模型/DIN)
- - [DIEN](/推荐算法基础/经典排序模型/序列模型/DIEN)
+ - [DIN](ch02/ch2.2/ch2.2.4/DIN)
+ - [DIEN](ch02/ch2.2/ch2.2.4/DIEN)
- [DISN]()
- [BST]()
- [2.2.5 多任务学习]()
diff --git a/docs/推荐算法基础/经典召回模型/基于协同过滤的召回/Swing(Graph-based).md b/docs/ch02/ch2.1/ch2.1.1/Swing.md
similarity index 100%
rename from docs/推荐算法基础/经典召回模型/基于协同过滤的召回/Swing(Graph-based).md
rename to docs/ch02/ch2.1/ch2.1.1/Swing.md
diff --git a/docs/推荐算法基础/经典召回模型/基于协同过滤的召回/readme.md b/docs/ch02/ch2.1/ch2.1.1/readme.md
similarity index 100%
rename from docs/推荐算法基础/经典召回模型/基于协同过滤的召回/readme.md
rename to docs/ch02/ch2.1/ch2.1.1/readme.md
diff --git a/docs/推荐算法基础/经典召回模型/基于向量的召回/readme.md b/docs/ch02/ch2.1/ch2.1.2/readme.md
similarity index 100%
rename from docs/推荐算法基础/经典召回模型/基于向量的召回/readme.md
rename to docs/ch02/ch2.1/ch2.1.2/readme.md
diff --git a/docs/推荐算法基础/经典召回模型/基于图的召回/EGES.md b/docs/ch02/ch2.1/ch2.1.3/EGES.md
similarity index 98%
rename from docs/推荐算法基础/经典召回模型/基于图的召回/EGES.md
rename to docs/ch02/ch2.1/ch2.1.3/EGES.md
index cab5cd97..5811940c 100644
--- a/docs/推荐算法基础/经典召回模型/基于图的召回/EGES.md
+++ b/docs/ch02/ch2.1/ch2.1.3/EGES.md
@@ -1,398 +1,398 @@
-# Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
-
-这篇论文是阿里巴巴在18年发表于KDD的关于召回阶段的工作。该论文提出的方法是在基于图嵌入的方法上,通过引入side information来解决实际问题中的数据稀疏和冷启动问题。
-
-## 动机
-
-在电商领域,推荐已经是不可或缺的一部分,旨在为用户的喜好提供有趣的物品,并且成为淘宝和阿里巴巴收入的重要引擎。尽管学术界和产业界的各种推荐方法都取得了成功,如协同过滤、基于内容的方法和基于深度学习的方法,但由于用户和项目的数十亿规模,传统的方法已经不能满足于实际的需求,主要的问题体现在三个方面:
-
-- 可扩展性:现有的推荐方法无法扩展到在拥有十亿的用户和二十亿商品的淘宝中。
-- 稀疏性:存在大量的物品与用户的交互行为稀疏。即用户的交互到多集中于以下部分商品,存在大量商品很少被用户交互。
-- 冷启动:在淘宝中,每分钟会上传很多新的商品,由于这些商品没有用户行为的信息(点击、购买等),无法进行很好的预测。
-
-针对于这三个方面的问题, 本文设计了一个两阶段的推荐框架:**召回阶段和排序阶段**,这也是推荐领域最常见的模型架构。而本文提及的EGES模型主要是解决了匹配阶段的问题,通过用户行为计算商品间两两的相似性,然后根基相似性选出topK的商品输入到排序阶段。
-
-为了学习更好的商品向量表示,本文通过用户的行为历史中构造一个item-item 图,然后应用随机游走方法在item-item 图为每个item获取到一个序列,然后通过Skip-Gram的方式为每个item学习embedding(这里的item序列类似于语句,其中每个item类比于句子中每个word),这种方式被称为图嵌入方法(Graph Embedding)。文中提出三个具体模型来学习更好的物品embedding,更好的服务于召回阶段。
-
-## 思路
-
-根据上述所面临的三个问题,本文针对性的提出了三个模型予以解决:Base Graph Embedding(BGE);Graph Embedding with Side Information(GES);Enhanced Graph Embedding with Side Information(EGES)。
-
-考虑可扩展性的问题,图嵌入的随机游走方式可以在物品图上捕获**物品之间高阶相似性**,即Base Graph Embedding(BGE)方法。其不同于CF方法,除了考虑物品的共现,还考虑到了行为的序列信息。
-
-考虑到稀疏性和冷启物品问题,在图嵌入的基础上,考虑了节点的属性信息。希望具有相似属性的物品可以在空间上相似,即希望通过头部物品,提高属性信息的泛化能力,进而帮助尾部和冷启物品获取更加准确的embedding,即Graph Embedding with Side Information(GES)方法。
-
-考虑到不同属性信息对于学习embedding的贡献不同,因此在聚合不同的属性信息时,动态的学习不同属性对于学习节点的embedding所参与的重要性权重,即Enhanced Graph Embedding with Side Information(EGES)。
-
-## 模型结构与原理
-
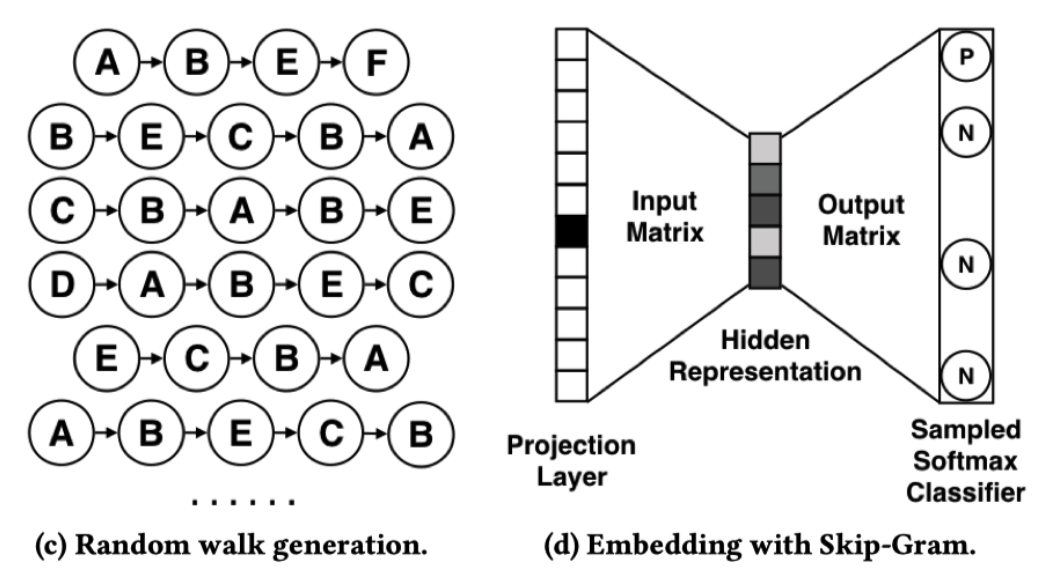
-文中所提出的方法是基于经典的图嵌入模型DeepWalk进行改进,其目标是通过物品图G,学习一个映射函数$f:V -> R^d$ ,将图上节点映射成一个embedding。具体的步骤包括两步:1.通过随机游走为图上每个物品生成序列;2.通过Skip-Gram算法学习每个物品的embedding。因此对于该方法优化的目标是,在给定的上下文物品的前提下,最大化物品v的条件概率,即物品v对于一个序列里面的其他物品要尽可能的相似。接下来看一些每个模型具体内容。
-
-### 构建物品图
-
-在介绍三个模型之前,我们首先需要构建好item-item图。由于基于CF的方法仅考虑物品之间的共现,忽略了行为的序列信息(即序列中相邻的物品之间的语义信息),因此item-item图的构建方式如下图所示。
-
-
-

-
-

-
-
-
-

-
-

-
-

-
-

-
-

-
-

-
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+