diff --git a/docs/README.md b/docs/README.md
index d74ec733..255fd66e 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -61,10 +61,10 @@
- AutoInt【完成一半,待优化】
- FiBiNET【完成一半,待优化】
- **WideNDeep系列**
- - Wide&Deep【已完成】
+ - [Wide&Deep](/推荐算法基础/经典排序模型/Wide&Deep系列/Wide&Deep)
- 改进Deep侧
- - NFM【已完成】
- - AFM【已完成】
+ - [NFM](/推荐算法基础/经典排序模型/Wide&Deep系列/NFM)
+ - [AFM](/推荐算法基础/经典排序模型/Wide&Deep系列/AFM)
- 改进Wide侧
- DeepFM【已完成】
- xDeepFM【未完成】
diff --git a/docs/_sidebar.md b/docs/_sidebar.md
index c481dc0b..a4c3b3b9 100644
--- a/docs/_sidebar.md
+++ b/docs/_sidebar.md
@@ -40,10 +40,10 @@
* [AutoInt]()
* [FiBiNet]()
* [Wide&Deep系列]()
- * [Wide&Deep]()
+ * [Wide&Deep](/推荐算法基础/经典排序模型/Wide&Deep系列/Wide&Deep)
* [改进Deep侧]()
- * [NFM]()
- * [AFM]()
+ * [NFM](/推荐算法基础/经典排序模型/Wide&Deep系列/NFM)
+ * [AFM](/推荐算法基础/经典排序模型/Wide&Deep系列/AFM)
* [改进Wide侧]()
* [DeepFM]()
* [xDeepFM]()
diff --git a/docs/推荐算法基础/经典排序模型/Wide&Deep系列/AFM.md b/docs/推荐算法基础/经典排序模型/Wide&Deep系列/AFM.md
new file mode 100644
index 00000000..82164853
--- /dev/null
+++ b/docs/推荐算法基础/经典排序模型/Wide&Deep系列/AFM.md
@@ -0,0 +1,127 @@
+# AFM
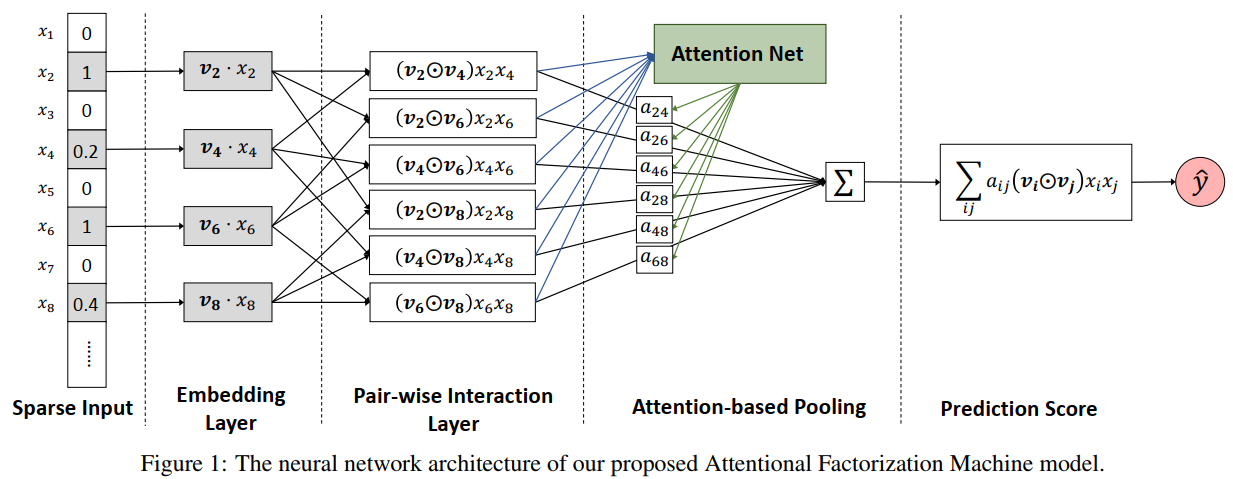
+## AFM提出的动机
+
+AFM的全称是Attentional Factorization Machines, 从模型的名称上来看是在FM的基础上加上了注意力机制,FM是通过特征隐向量的内积来对交叉特征进行建模,从公式中可以看出所有的交叉特征都具有相同的权重也就是1,没有考虑到不同的交叉特征的重要性程度:
+$$
+y_{fm} = w_0+\sum_{i=1}^nw_ix_i+\sum_{i=1}^{n}\sum_{i+1}^n\lt v_i,v_j\gt x_ix_j
+$$
+如何让不同的交叉特征具有不同的重要性就是AFM核心的贡献,在谈论AFM交叉特征注意力之前,对于FM交叉特征部分的改进还有FFM,其是考虑到了对于不同的其他特征,某个指定特征的隐向量应该是不同的(相比于FM对于所有的特征只有一个隐向量,FFM对于一个特征有多个不同的隐向量)。
+
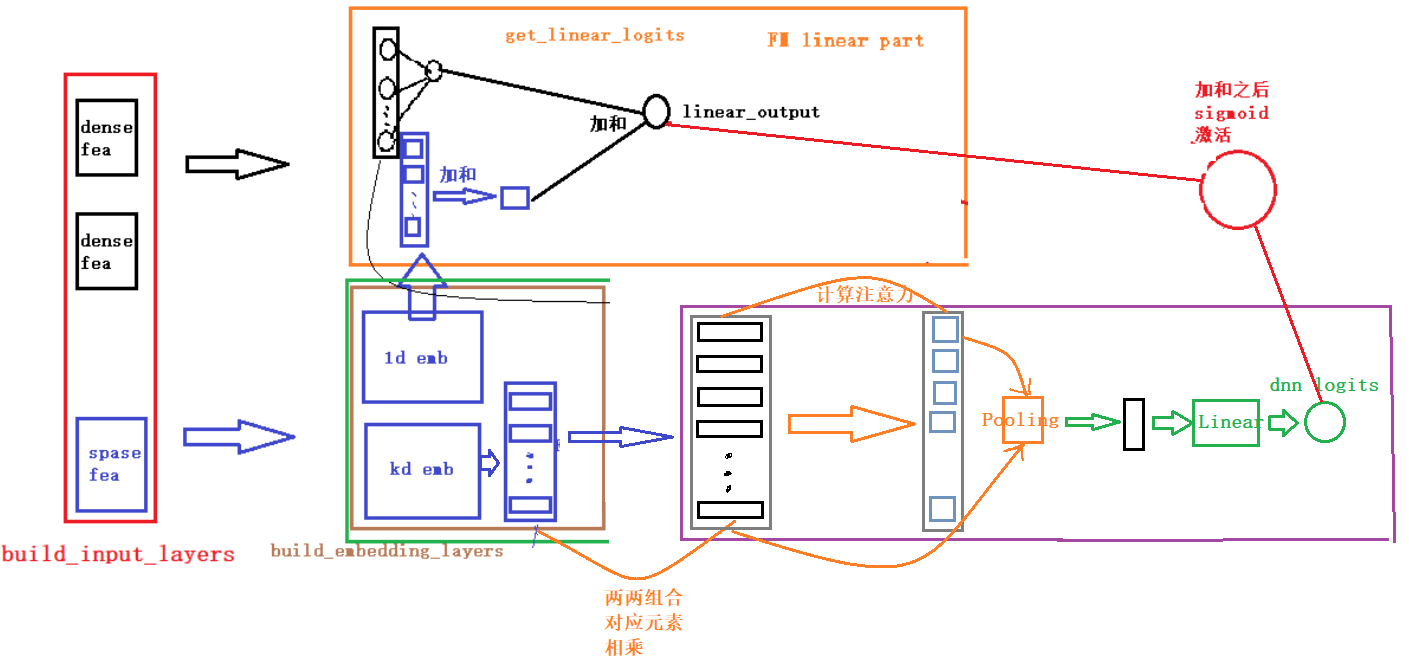
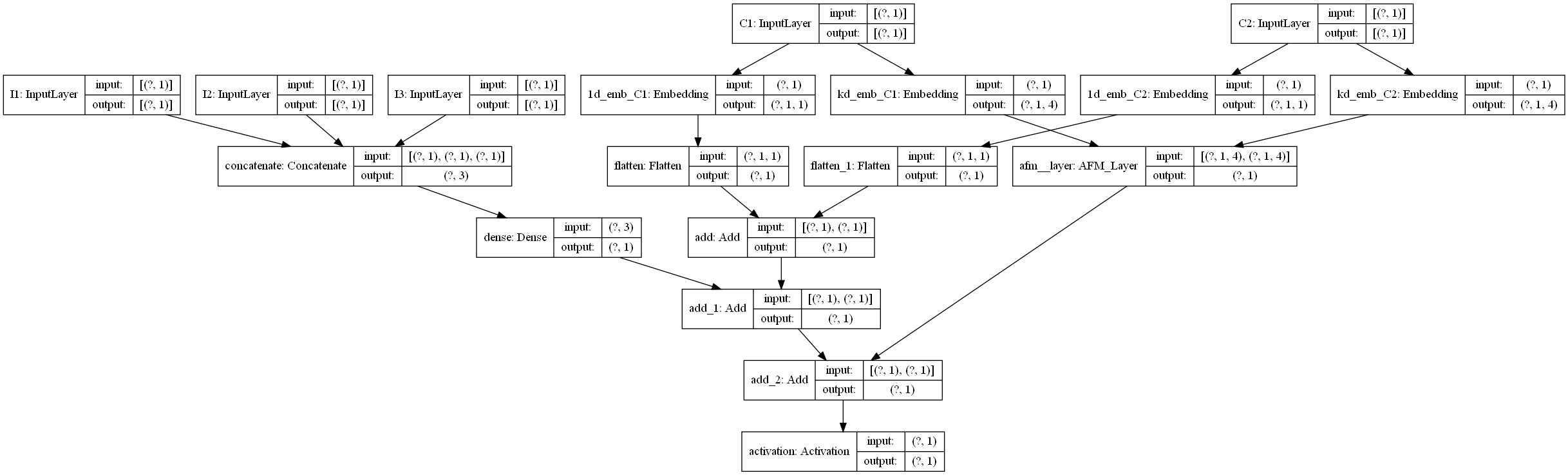
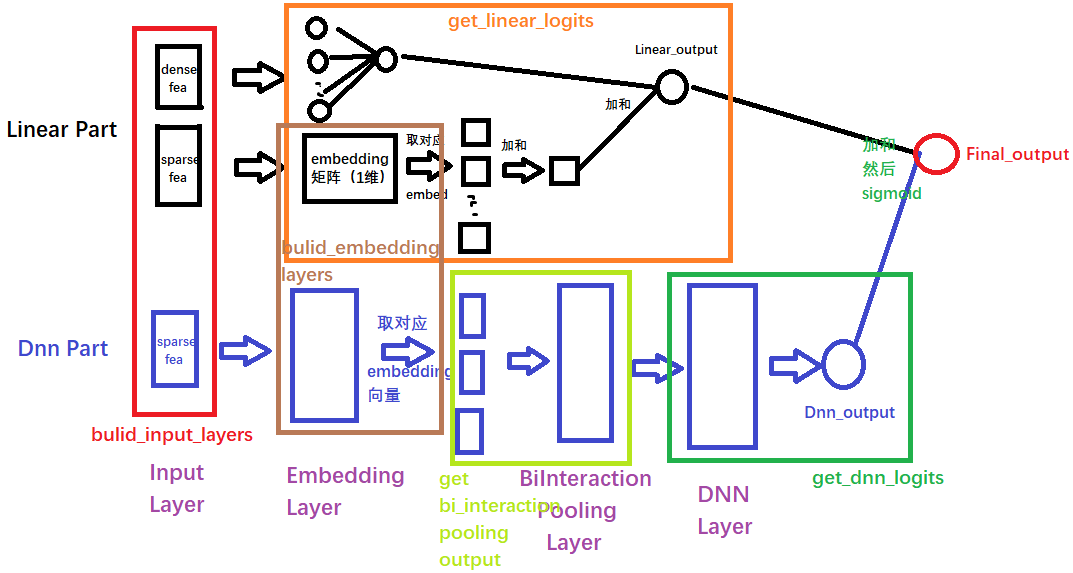
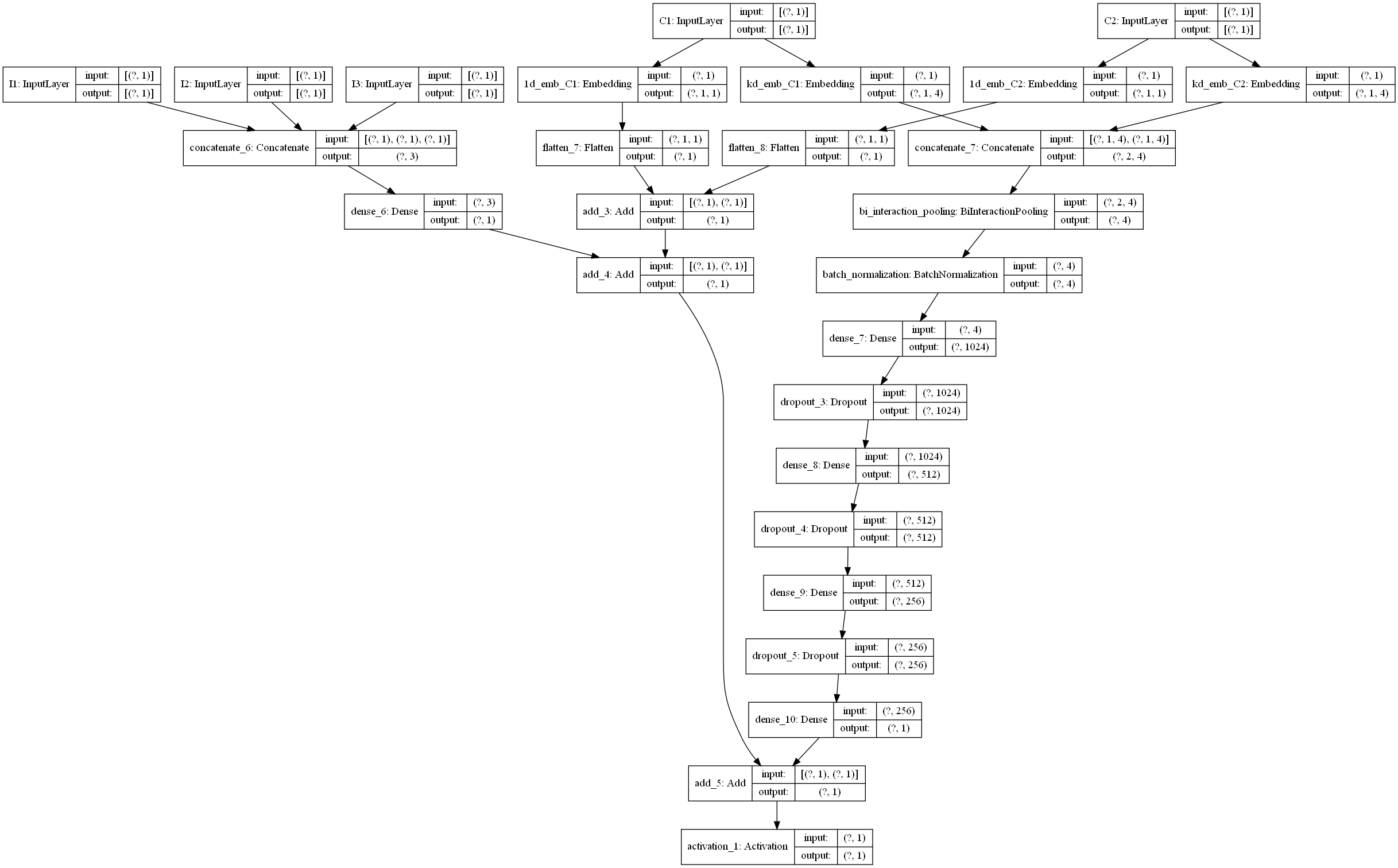
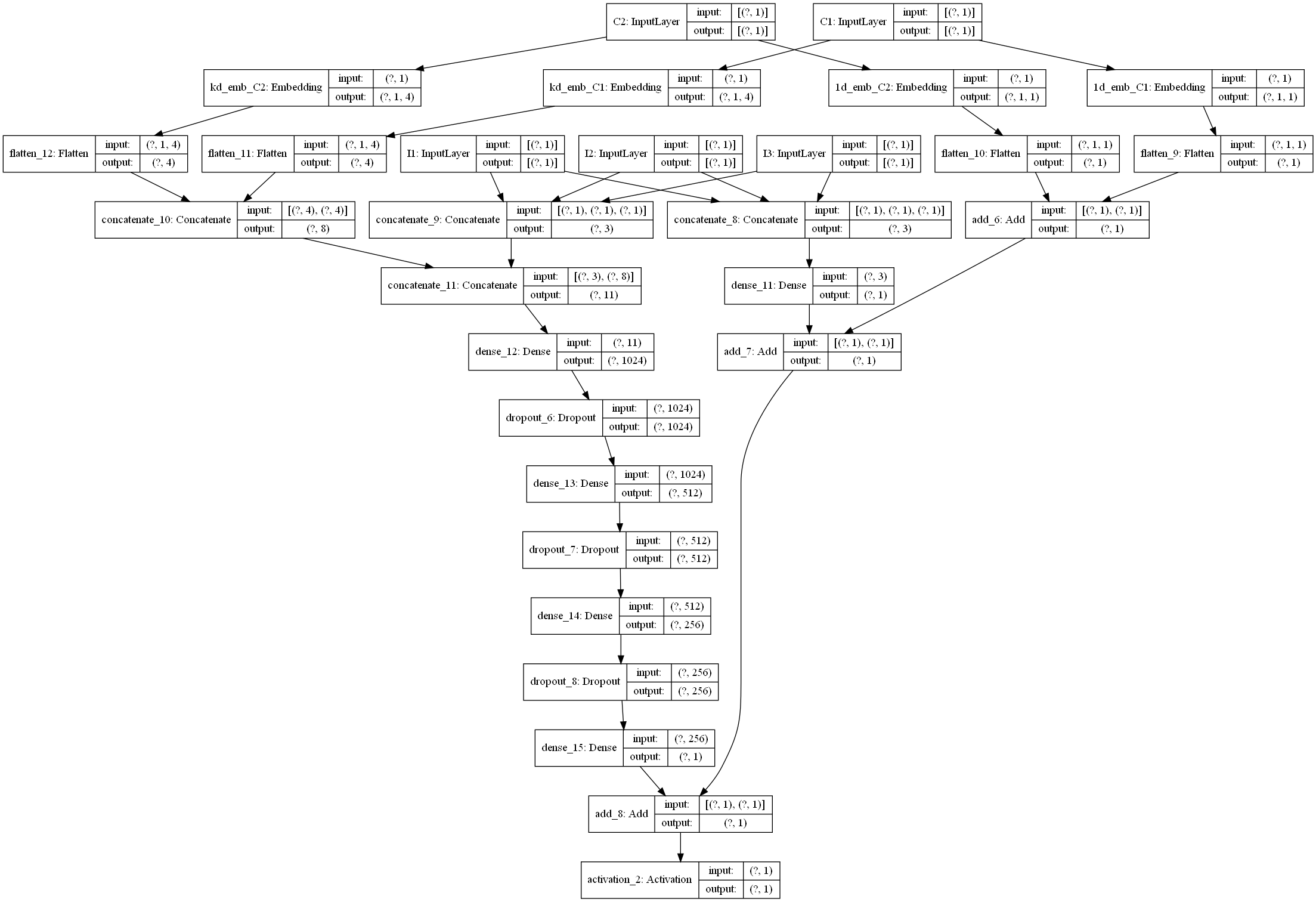
+## AFM模型原理
+
+
+
+
+
+
+
+

+
+

+
+
+
+
+
+
+
+
+
+
+